Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
第一章-AIブームとAI【数学嫌いと学ぶデータサイエンス・統計的学習入門】
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Ringa_hyj
June 15, 2020
Technology
190
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
第一章-AIブームとAI【数学嫌いと学ぶデータサイエンス・統計的学習入門】
第一章【数学嫌いと学ぶデータサイエンス・統計的学習入門】
Ringa_hyj
June 15, 2020
More Decks by Ringa_hyj
See All by Ringa_hyj
DVCによるデータバージョン管理
ringa_hyj
0
410
deeplakeによる大規模データのバージョン管理と深層学習フレームワークとの接続
ringa_hyj
0
120
Hydraを使った設定ファイル管理とoptunaプラグインでのパラメータ探索
ringa_hyj
0
240
ClearMLで行うAIプロジェクトの管理(レポート,最適化,再現,デプロイ,オーケストレーション)
ringa_hyj
0
270
Catching up with the tidymodels.[Japan.R 2021 LT]
ringa_hyj
3
880
多次元尺度法MDS
ringa_hyj
0
420
因子分析(仮)
ringa_hyj
0
210
階層、非階層クラスタリング
ringa_hyj
0
160
tidymodels紹介「モデリング過程料理で表現できる説」
ringa_hyj
0
690
Other Decks in Technology
See All in Technology
数値で見る Microsoft MVP 〜Spec Kit と GitHub Copilot Agent で作るデータ可視化ダッシュボード〜
yutakaosada
0
150
なぜMIXIはゼロトラスト基盤として クラウドフレアを選んだのか - Cloudflare Peer Point SASE User Voices
mixi_engineers
PRO
2
100
データと地図で読む 大井町の「かわるもの、かわらないもの」
yoshiyama_hana
0
440
脱Jenkins、インターン生が挑んだCIツールGitHubActions移行
mixi_engineers
PRO
1
150
OPENLOGI Company Profile for engineer
hr01
1
75k
AI研修(Day2)【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
940
Claude Mythos、Fable...フロンティアAIの最新動向と企業のセキュリティ対策
flatt_security
0
150
AI時代の開発生産性を捉え直す — 経営と現場をつなぐ「開発組織のオブザーバビリティ」— / AI Dev Ex Conference 2026
tkyowa
1
1.7k
現場との対話から始める “作る前に問い直す”業務改善
mochico50
2
320
StepFunctionsとGraphRAGを活用した暗黙知活用のためのRAG基盤
yakumo
0
180
「待ち時間」の消滅と「自我消耗」の加速:生成AI時代のエンジニアを救うメンタル・リソース管理
poropinai1966
0
230
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
Featured
See All Featured
Chasing Engaging Ingredients in Design
codingconduct
0
240
Max Prin - Stacking Signals: How International SEO Comes Together (And Falls Apart)
techseoconnect
PRO
0
330
Introduction to Domain-Driven Design and Collaborative software design
baasie
1
910
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
570
Keith and Marios Guide to Fast Websites
keithpitt
413
23k
Discover your Explorer Soul
emna__ayadi
2
1.2k
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.7k
実際に使うSQLの書き方 徹底解説 / pgcon21j-tutorial
soudai
PRO
201
75k
Designing for Performance
lara
611
70k
How STYLIGHT went responsive
nonsquared
100
6.2k
Unsuck your backbone
ammeep
672
58k
StorybookのUI Testing Handbookを読んだ
zakiyama
31
6.9k
Transcript
第一章 第一章 日本一の数学嫌いと学ぶ データサイエンス ~第一章:AIブームとAI~ @Ringa_hyj
第一章 第一章 対象視聴者: 数式や記号を見ただけで 教科書を閉じたくなるレベル 2
第一章 第一章 AIブームをふりかえる 3
第一章 第一章 AI : artificial intelligence 人工知能 - コンピュータによって知能を研究する分野のこと -
知能を持った機構そのもの - (明確な定義はない) e.g. ヒトはどうやって物を認識しているのか? 視 → 脳 → 認識 機械ではどうやって認識させられるのか? ヒトの認識機構研究をコンピュータにさせてみよう 4
第一章 第一章 AIの歴史 今のブームはここから (出典)総務省「ICTの進化が雇用と働き方に及ぼす影響に関する調査研究」(平成28年) 5
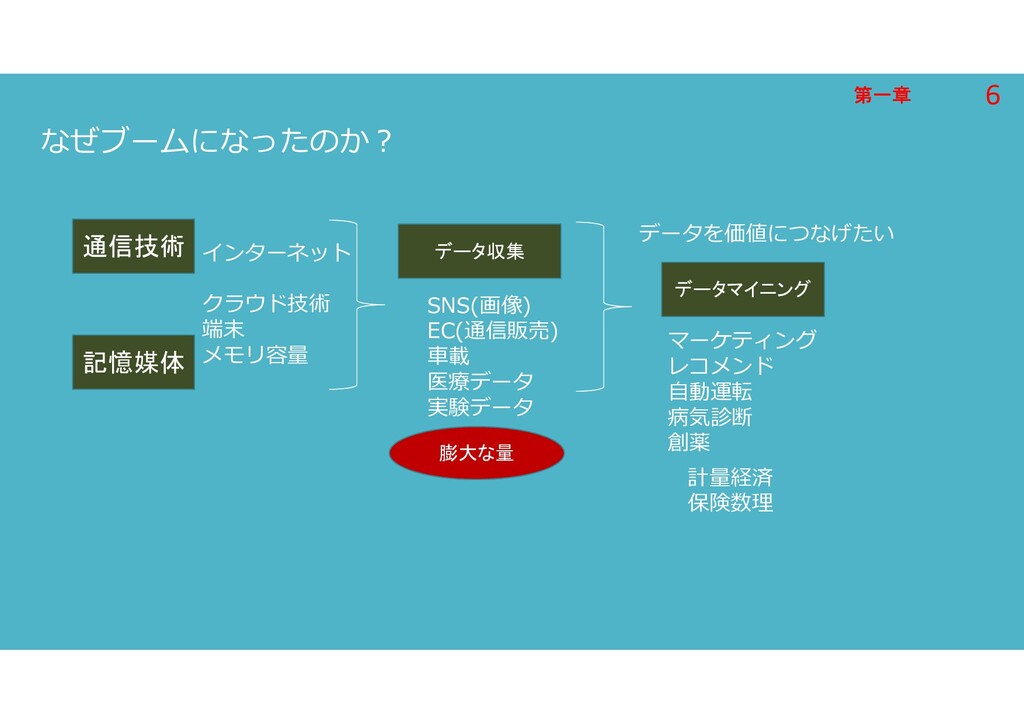
第一章 第一章 なぜブームになったのか? 通信技術 記憶媒体 データ収集 インターネット クラウド技術 端末 メモリ容量
マーケティング レコメンド 自動運転 病気診断 創薬 データを価値につなげたい データマイニング 膨大な量 SNS(画像) EC(通信販売) 車載 医療データ 実験データ 計量経済 保険数理 6
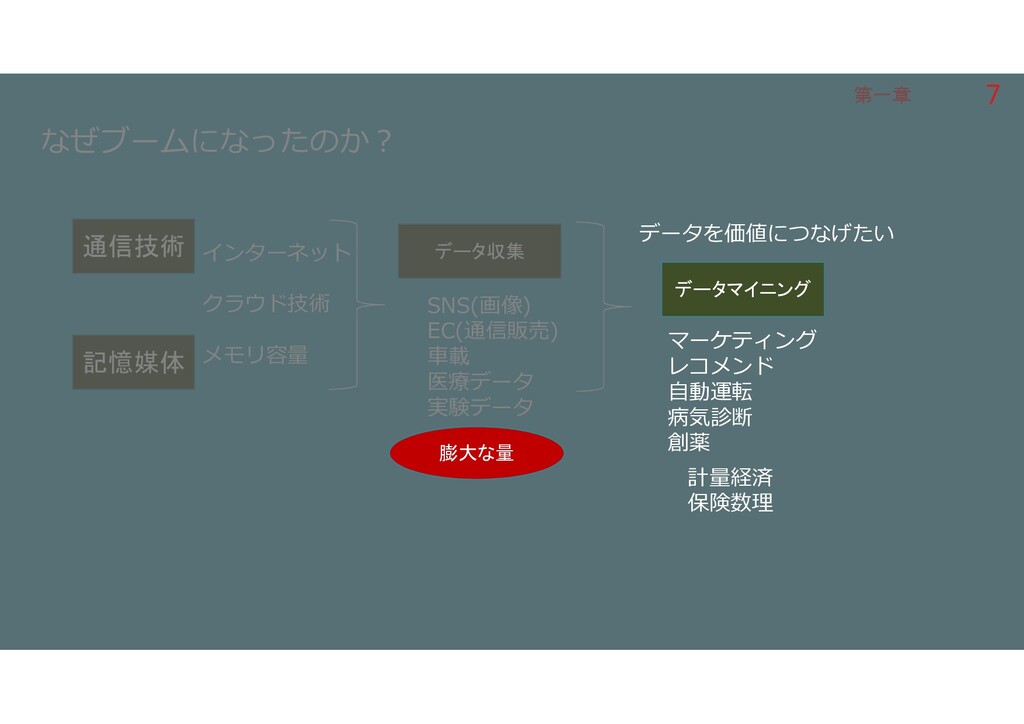
第一章 第一章 なぜブームになったのか? 通信技術 記憶媒体 データ収集 インターネット クラウド技術 メモリ容量 SNS(画像)
EC(通信販売) 車載 医療データ 実験データ マーケティング レコメンド 自動運転 病気診断 創薬 データを価値につなげたい データマイニング 計量経済 保険数理 膨大な量 7
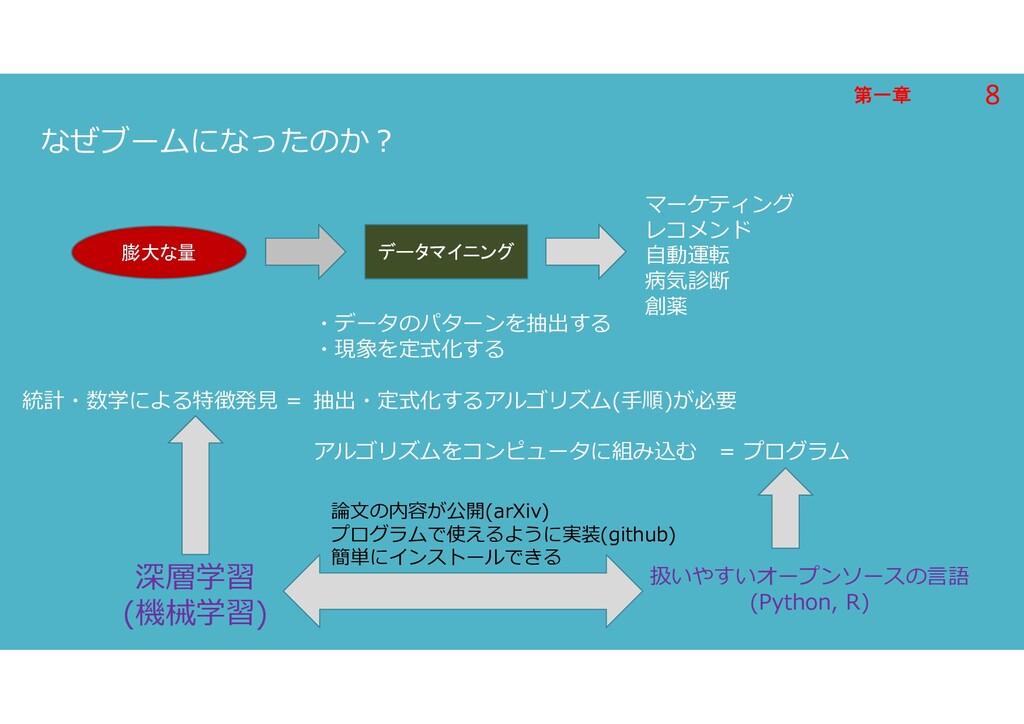
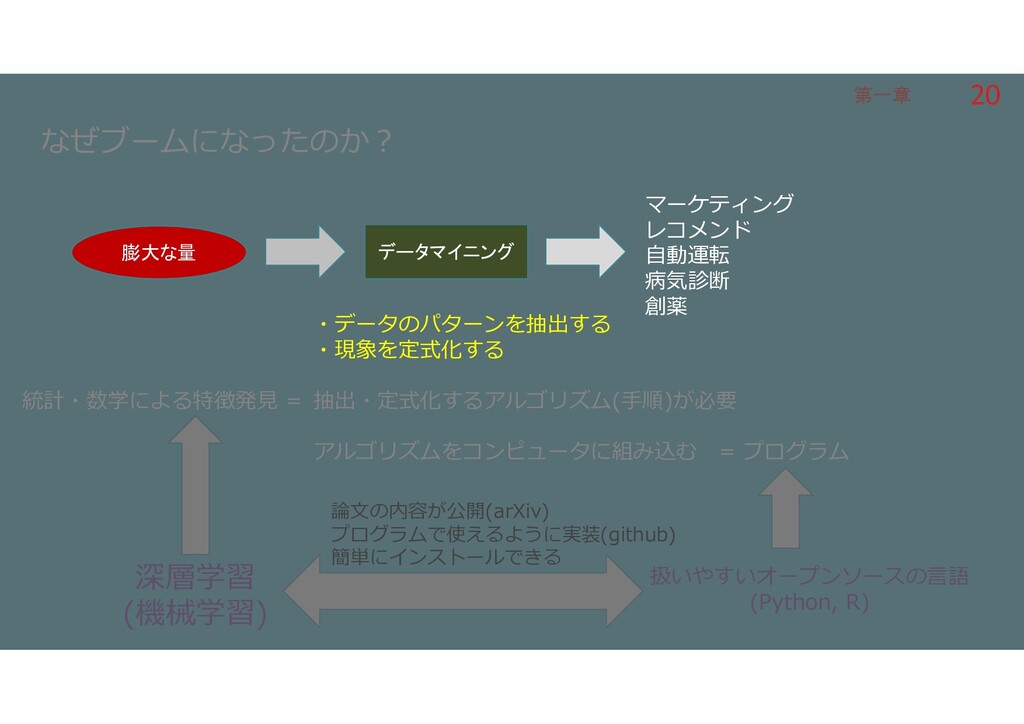
第一章 第一章 なぜブームになったのか? 膨大な量 マーケティング レコメンド 自動運転 病気診断 創薬 データマイニング
・データのパターンを抽出する ・現象を定式化する 抽出・定式化するアルゴリズム(手順)が必要 アルゴリズムをコンピュータに組み込む = プログラム 統計・数学による特徴発見 = 深層学習 (機械学習) 扱いやすいオープンソースの言語 (Python, R) 論文の内容が公開(arXiv) プログラムで使えるように実装(github) 簡単にインストールできる 8
第一章 第一章 故に「Python」や「深層学習」が人気の的となる (出典)ian goodfellow 「deep learning」 ch9 fig9.3 「深層学習」は何者?
9
第一章 第一章 AI・機械学習・ 深層学習 の違い 10
第一章 第一章 AI : - コンピュータによって知能を研究する分野のこと - 知能を持った機構そのもの - (明確な定義はない)
機械学習(machine learning:ML) : - パターン認識・推論を行うアルゴリズムや統計モデルのこと (クラスタリング・線形回帰) 深層学習(deep learning:DL) : - 機械学習の一つ、いくつかの層構造を持つアルゴリズムのこと 特に深層学習は 「データからの自動的な特徴抽出」と 「(質の良いデータであれば)データ量に比例して精度が今までのアルゴリズムより向上しやすい」 という点からビックデータと相性が良い 深層学習ブームの発端となったのは、今まで困難だった画像認識の分野で効果を発揮した事 11
第一章 第一章 「データサイエンティスト」 とは何者か? 12
第一章 第一章 データサイエンティストに必要な3つのスキル (出典)2019年 データサイエンティスト協会 スキル委員会資料より 13
第一章 第一章 データサイエンティストに必要な3つのスキル ビジネス スキル サイエンス スキル エンジニアリング スキル AI(アルゴリズム・統計モデル)を適応して、
価値判断と価値につなげたい分野に精通していること AI(アルゴリズム・統計モデル)の理論を知り、 手法を選択・使用・説明できること AI(アルゴリズム・統計モデル)を使ったシステムを作り、 価値 14
第一章 第一章 (出典)2019年 データサイエンティスト協会 スキルチェックリストver3より データサイエンス力は数学が必要 統計 (確率分布・時系列) 微積分 (最適化・学習・更新)
線形代数 (並列計算・次元削減) 15
第一章 第一章 機械学習に数学が使われている以上 「データサイエンティスト」 は数学と関係深い 16
第一章 第一章 数学アレルギーでも 親しみやすい「すうがく」を! そんな気持ちでデータサイエンスの理論理解 につなげていきます 17
第一章 第一章 機械学習とは、 データマイニングなどで使われている アルゴリズムのこと として説明を進める 18
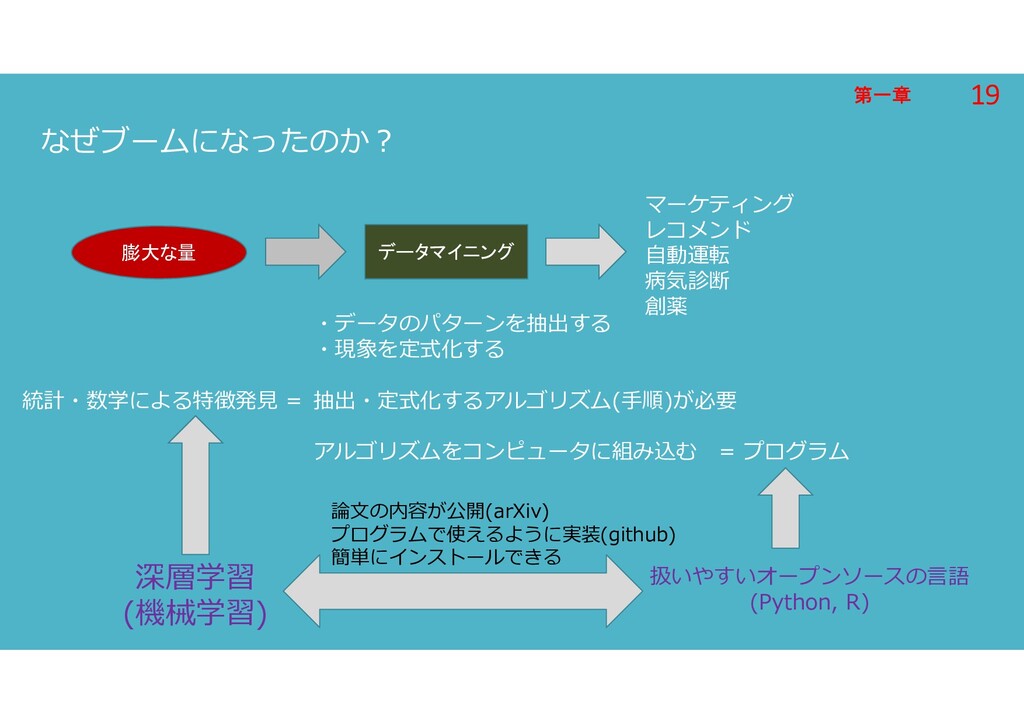
第一章 第一章 なぜブームになったのか? 膨大な量 マーケティング レコメンド 自動運転 病気診断 創薬 データマイニング
・データのパターンを抽出する ・現象を定式化する 抽出・定式化するアルゴリズム(手順)が必要 アルゴリズムをコンピュータに組み込む = プログラム 統計・数学による特徴発見 = 深層学習 (機械学習) 扱いやすいオープンソースの言語 (Python, R) 論文の内容が公開(arXiv) プログラムで使えるように実装(github) 簡単にインストールできる 19
第一章 第一章 なぜブームになったのか? 抽出・定式化するアルゴリズム(手順)が必要 アルゴリズムをコンピュータに組み込む = プログラム 統計・数学による特徴発見 = 深層学習
(機械学習) 扱いやすいオープンソースの言語 (Python, R) 論文の内容が公開(arXiv) プログラムで使えるように実装(github) 簡単にインストールできる 膨大な量 マーケティング レコメンド 自動運転 病気診断 創薬 データマイニング ・データのパターンを抽出する ・現象を定式化する 20
第一章 第一章 ・データからパターンを抽出 ・現象を定式化 簡単な例で説明 21
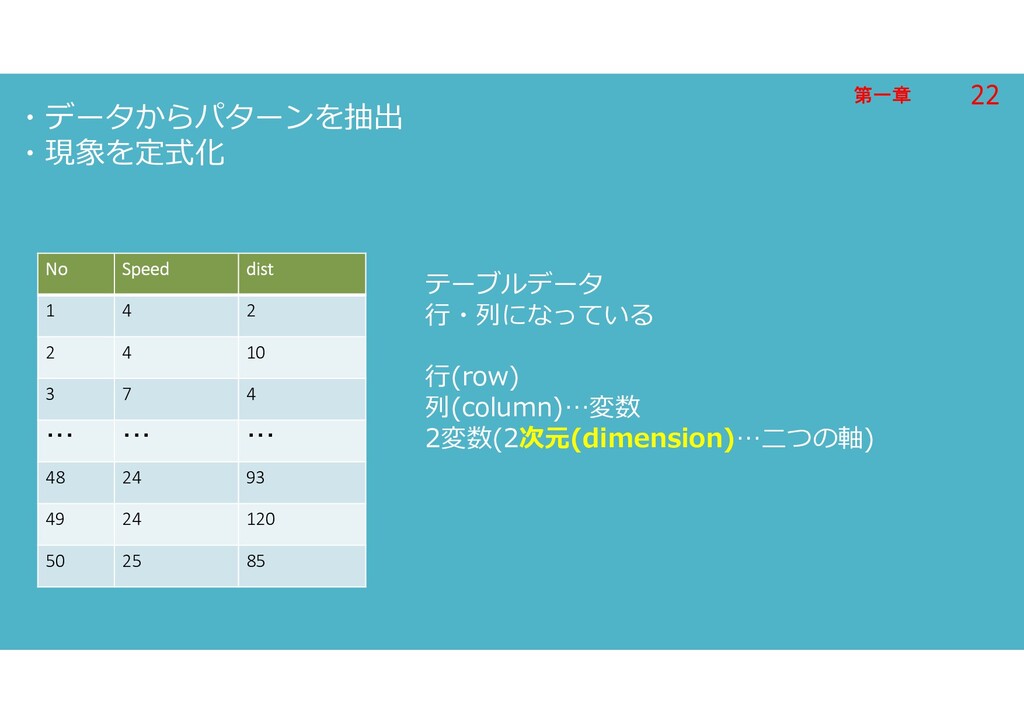
第一章 第一章 ・データからパターンを抽出 ・現象を定式化 No Speed dist 1 4 2
2 4 10 3 7 4 ・・・ ・・・ ・・・ 48 24 93 49 24 120 50 25 85 テーブルデータ 行・列になっている 行(row) 列(column)…変数 2変数(2次元(dimension)…二つの軸) 22
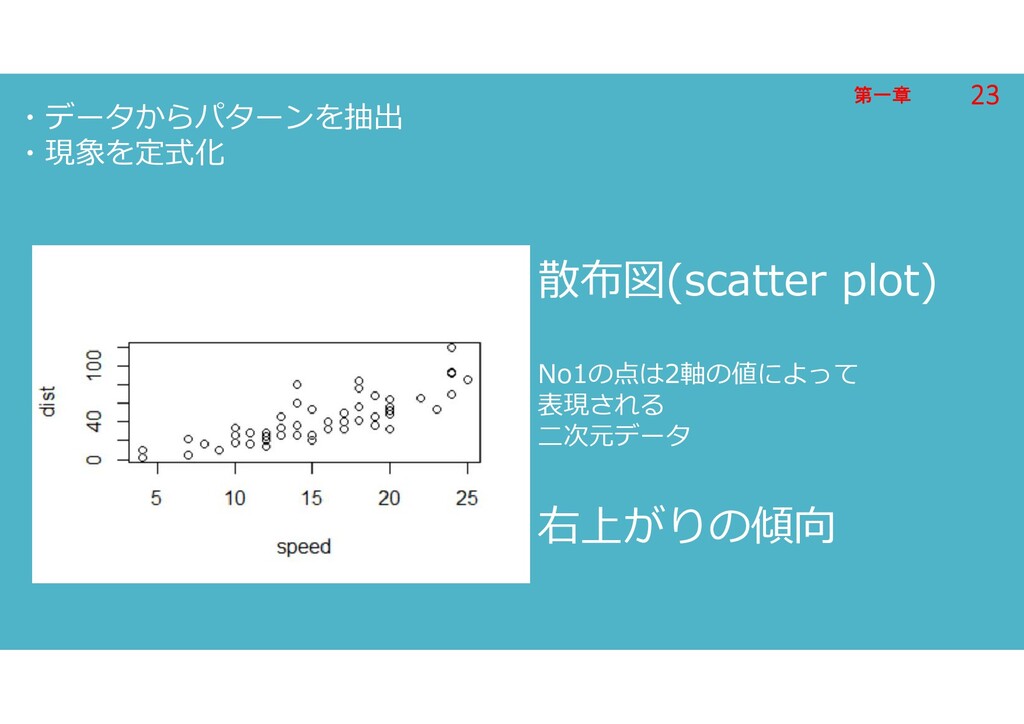
第一章 第一章 ・データからパターンを抽出 ・現象を定式化 散布図(scatter plot) No1の点は2軸の値によって 表現される 二次元データ 右上がりの傾向
23
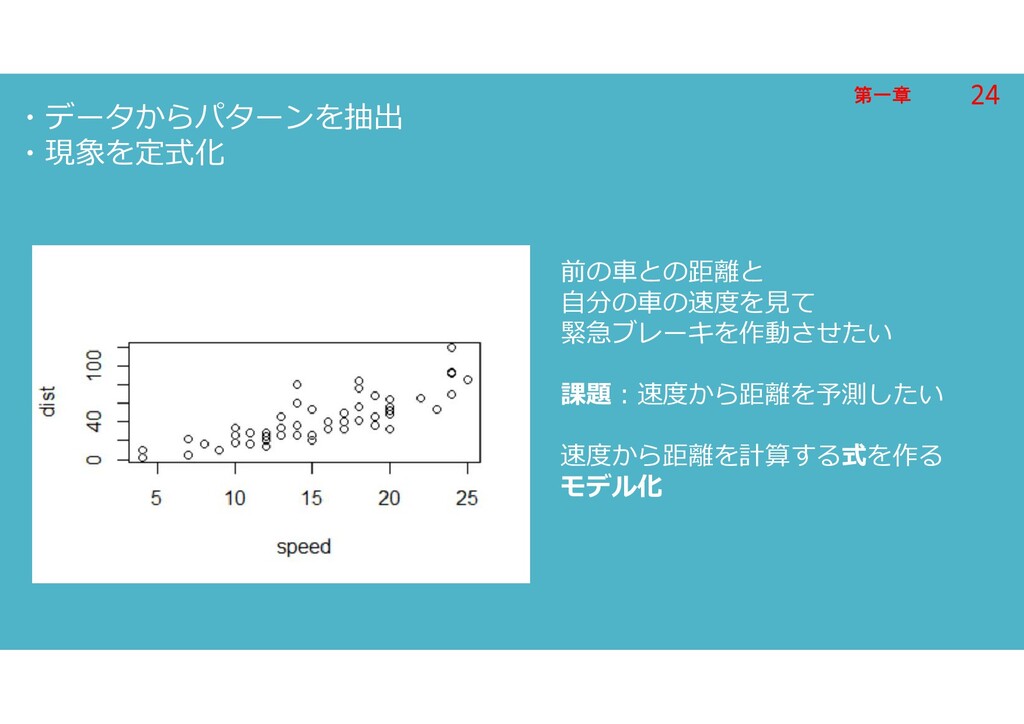
第一章 第一章 ・データからパターンを抽出 ・現象を定式化 前の車との距離と 自分の車の速度を見て 緊急ブレーキを作動させたい 課題:速度から距離を予測したい 速度から距離を計算する式を作る モデル化
24
第一章 第一章 ・データからパターンを抽出 ・現象を定式化 停止距離 = 速度 + ? もしくは
停止距離 = 速度×A という式を見つけたい 多項 項 変数(valiable)・特徴量(feature)・変項 係数 単項 25
第一章 第一章 ・データからパターンを抽出 ・現象を定式化 停止距離 = 速度 + ? No
Speed dist 1 4 2 2 4 10 3 7 4 ・・・ ・・・ ・・・ 48 24 93 49 24 120 50 25 85 予測に使う変数 従属変数 目的変数 被説明変数 予測したい変数 説明変数 独立変数 入力変数 26
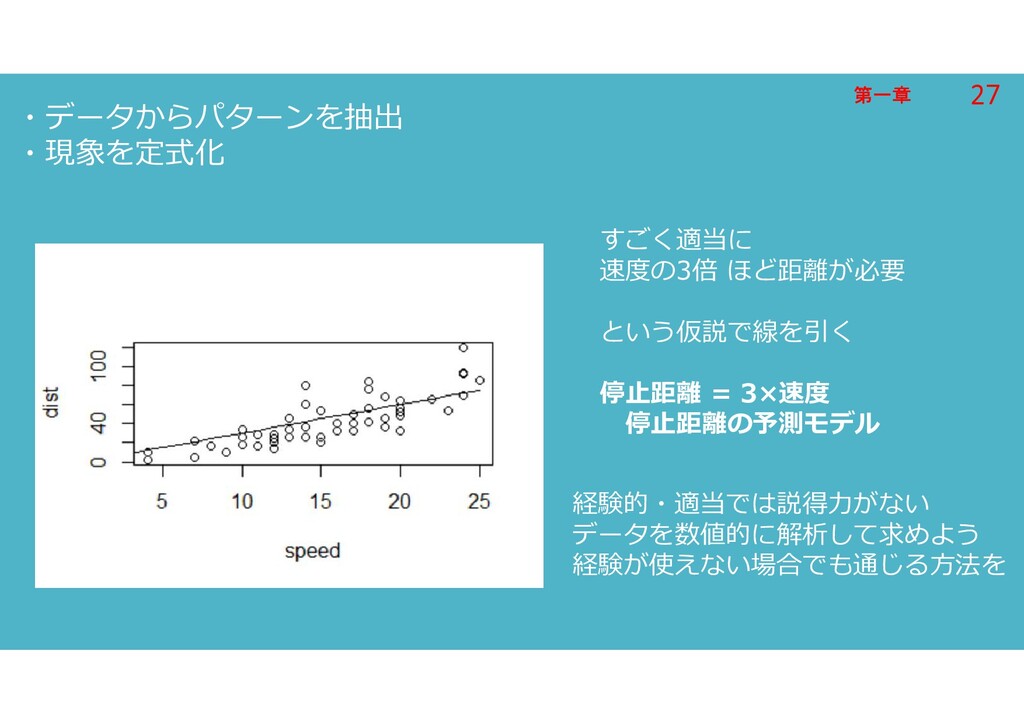
第一章 第一章 ・データからパターンを抽出 ・現象を定式化 すごく適当に 速度の3倍 ほど距離が必要 という仮説で線を引く 停止距離 =
3×速度 停止距離の予測モデル 経験的・適当では説得力がない データを数値的に解析して求めよう 経験が使えない場合でも通じる方法を 27
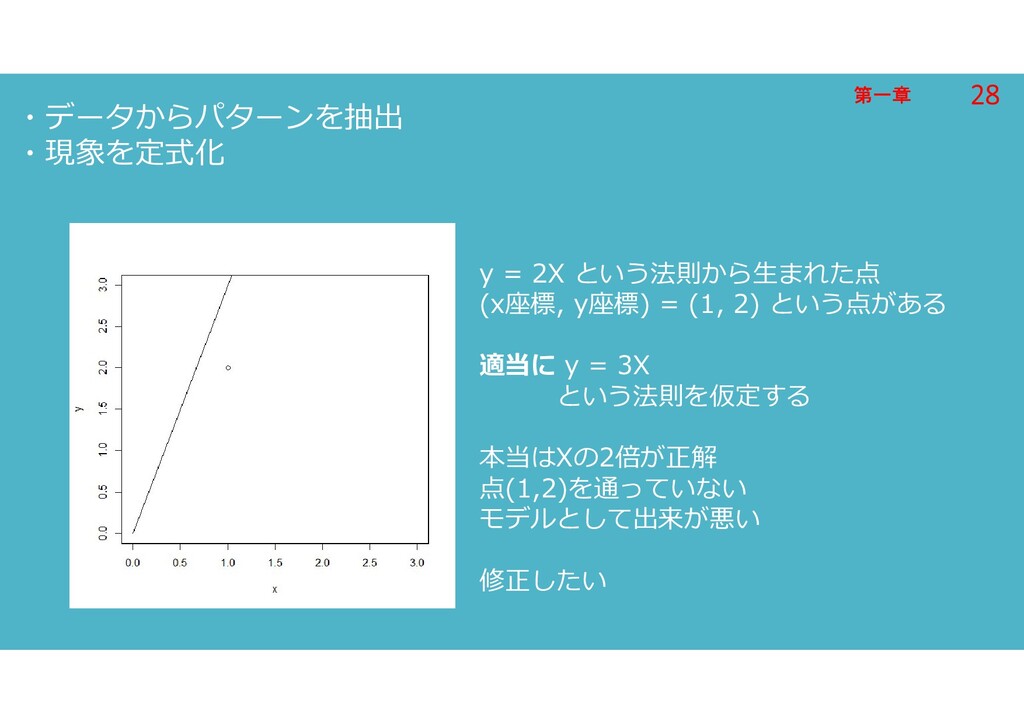
第一章 第一章 ・データからパターンを抽出 ・現象を定式化 y = 2X という法則から生まれた点 (x座標, y座標)
= (1, 2) という点がある 適当に y = 3X という法則を仮定する 本当はXの2倍が正解 点(1,2)を通っていない モデルとして出来が悪い 修正したい 28
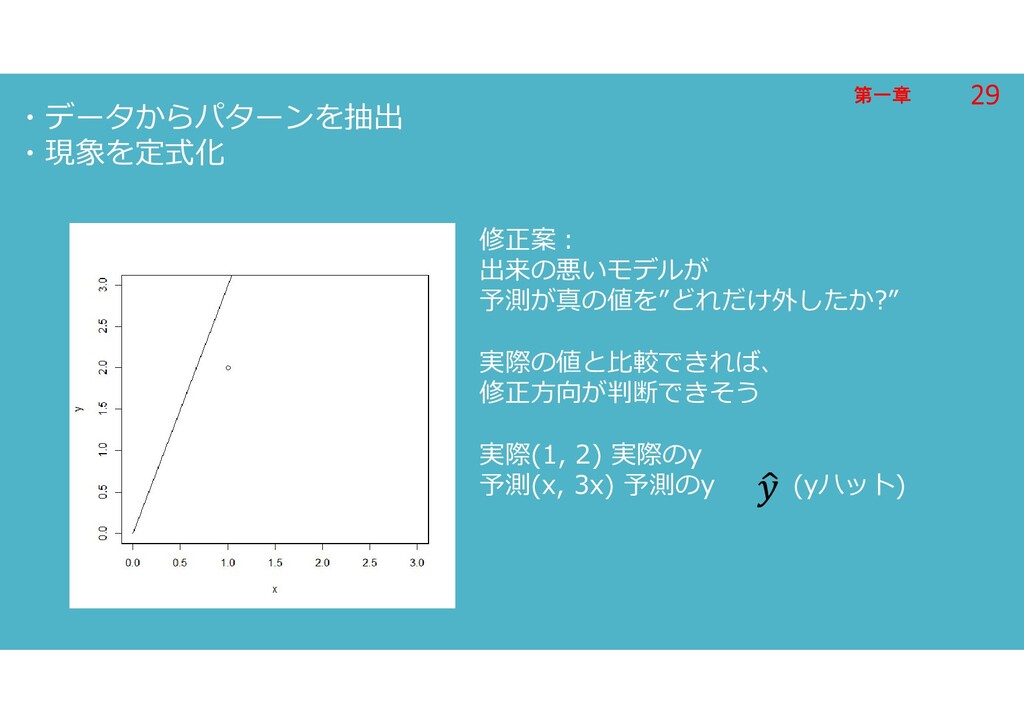
第一章 第一章 ・データからパターンを抽出 ・現象を定式化 修正案: 出来の悪いモデルが 予測が真の値を”どれだけ外したか?” 実際の値と比較できれば、 修正方向が判断できそう 実際(1,
2) 実際のy 予測(x, 3x) 予測のy (yハット) 29
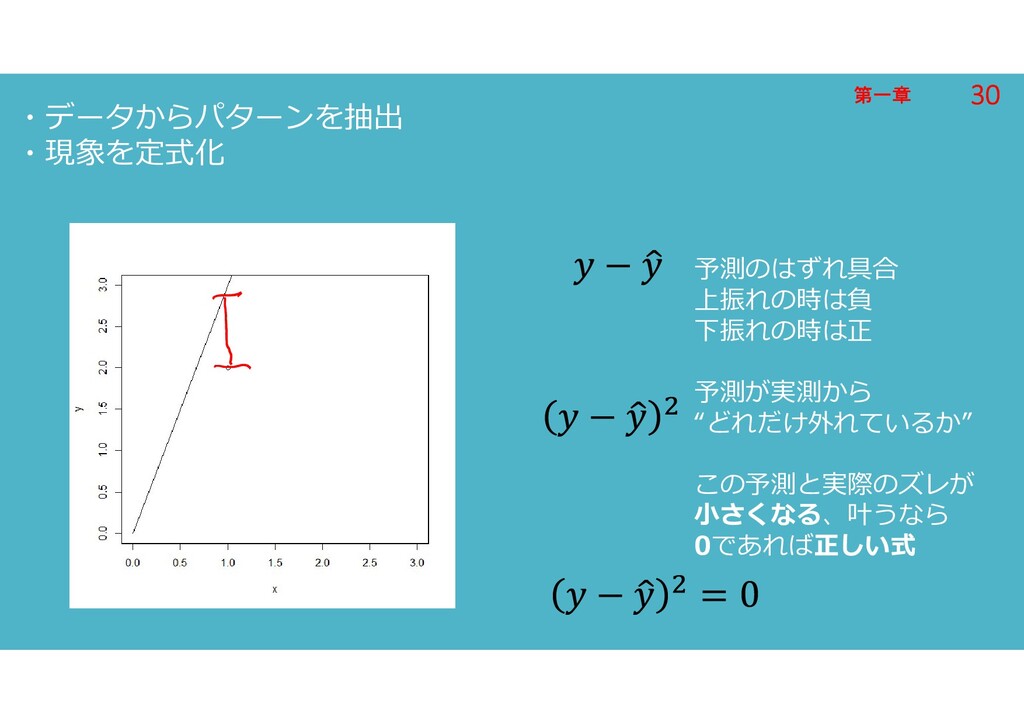
第一章 第一章 ・データからパターンを抽出 ・現象を定式化 予測のはずれ具合 上振れの時は負 下振れの時は正 予測が実測から “どれだけ外れているか” この予測と実際のズレが
小さくなる、叶うなら 0であれば正しい式 30
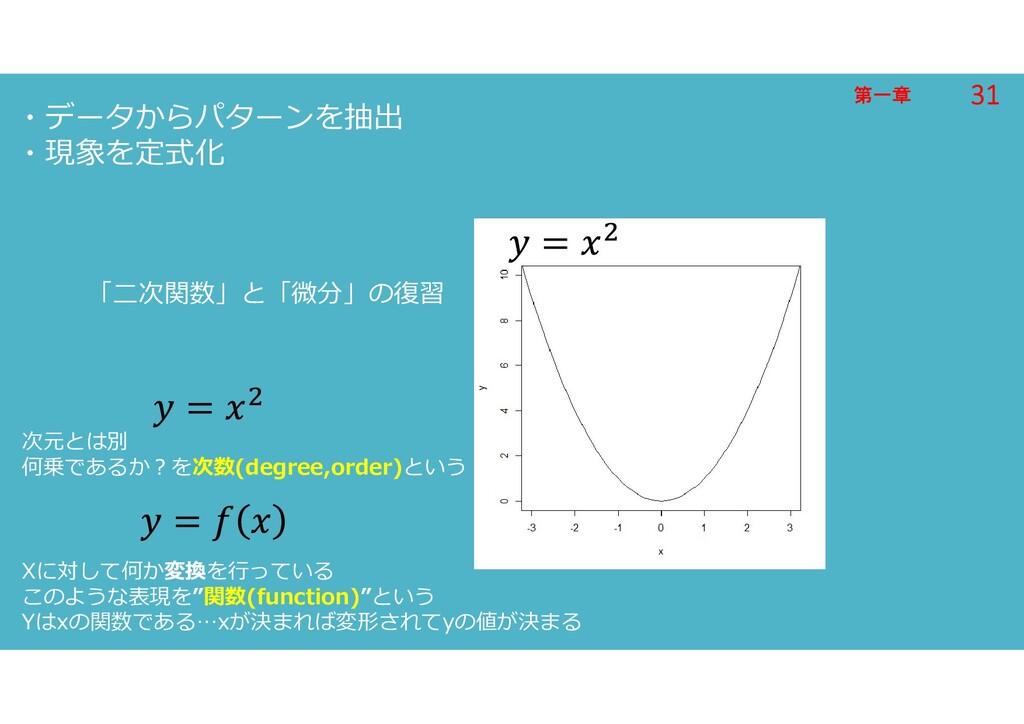
第一章 第一章 ・データからパターンを抽出 ・現象を定式化 「二次関数」と「微分」の復習 次元とは別 何乗であるか?を次数(degree,order)という Xに対して何か変換を行っている このような表現を”関数(function)”という Yはxの関数である…xが決まれば変形されてyの値が決まる
31
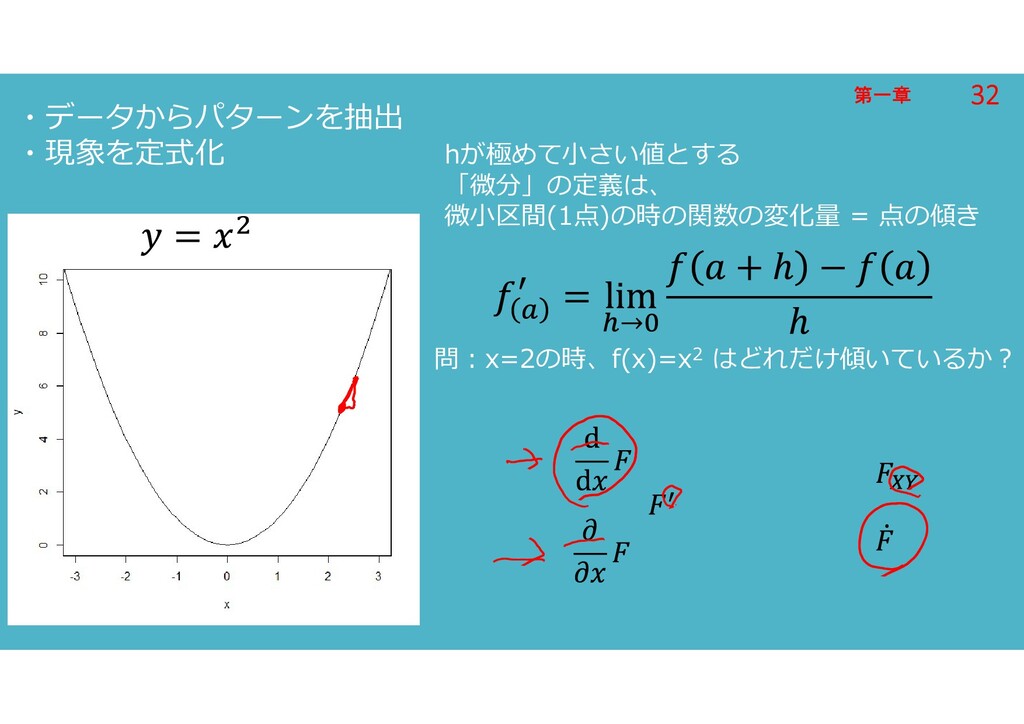
第一章 第一章 ・データからパターンを抽出 ・現象を定式化 hが極めて小さい値とする 「微分」の定義は、 微小区間(1点)の時の関数の変化量 = 点の傾き 問:x=2の時、f(x)=x2
はどれだけ傾いているか? 32
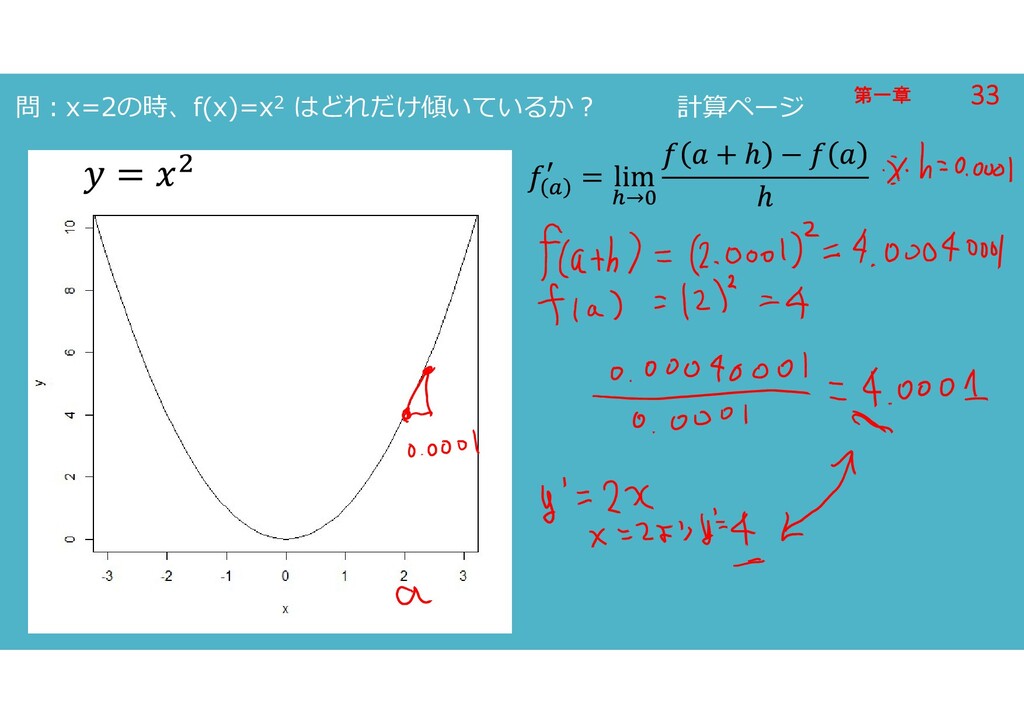
第一章 第一章 問:x=2の時、f(x)=x2 はどれだけ傾いているか? 計算ページ 33
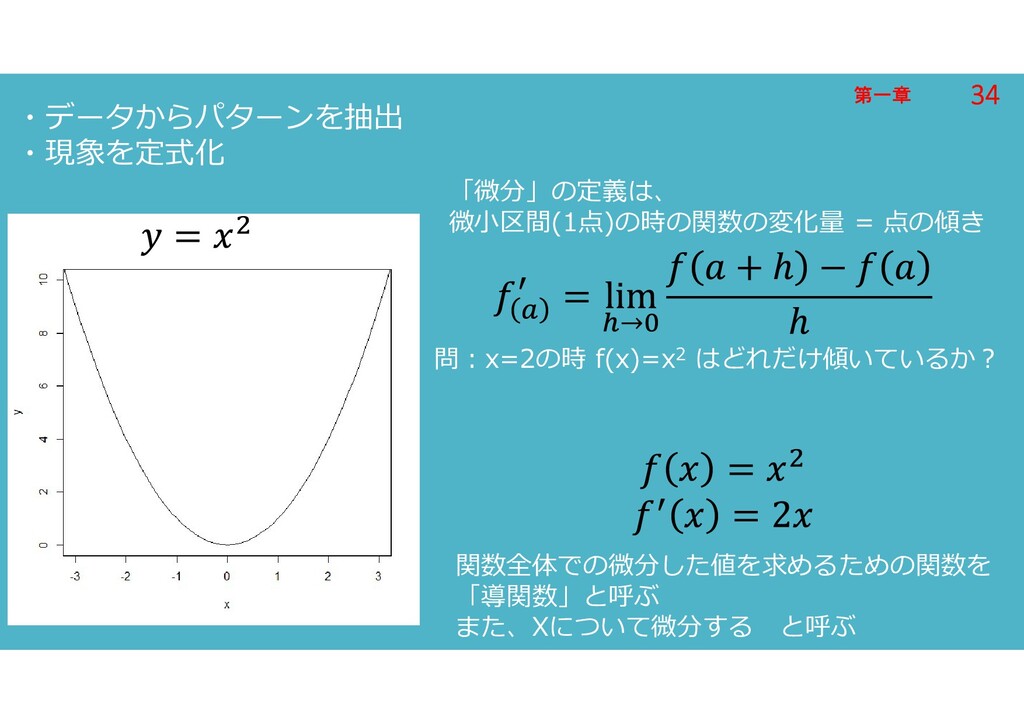
第一章 第一章 ・データからパターンを抽出 ・現象を定式化 「微分」の定義は、 微小区間(1点)の時の関数の変化量 = 点の傾き 問:x=2の時 f(x)=x2
はどれだけ傾いているか? 関数全体での微分した値を求めるための関数を 「導関数」と呼ぶ また、Xについて微分する と呼ぶ 34
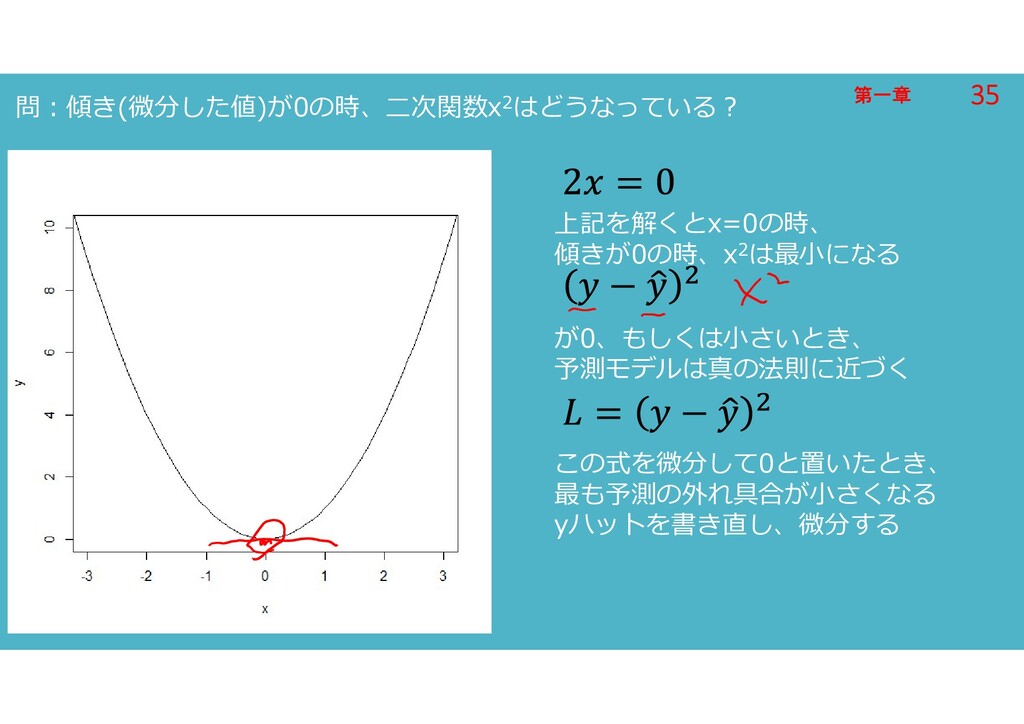
第一章 第一章 問:傾き(微分した値)が0の時、二次関数x2はどうなっている? 上記を解くとx=0の時、 傾きが0の時、x2は最小になる が0、もしくは小さいとき、 予測モデルは真の法則に近づく この式を微分して0と置いたとき、 最も予測の外れ具合が小さくなる yハットを書き直し、微分する
35
第一章 第一章 本当のモデルを求めたいので、 傾きは適当でなく、未知の変数Aとする 真のモデルから得られている点(x=1,y=2)というデータを与える Aについての二次関数の最小を求めるためには、微分して0とおく Aについて解くと、A=2となる。 36
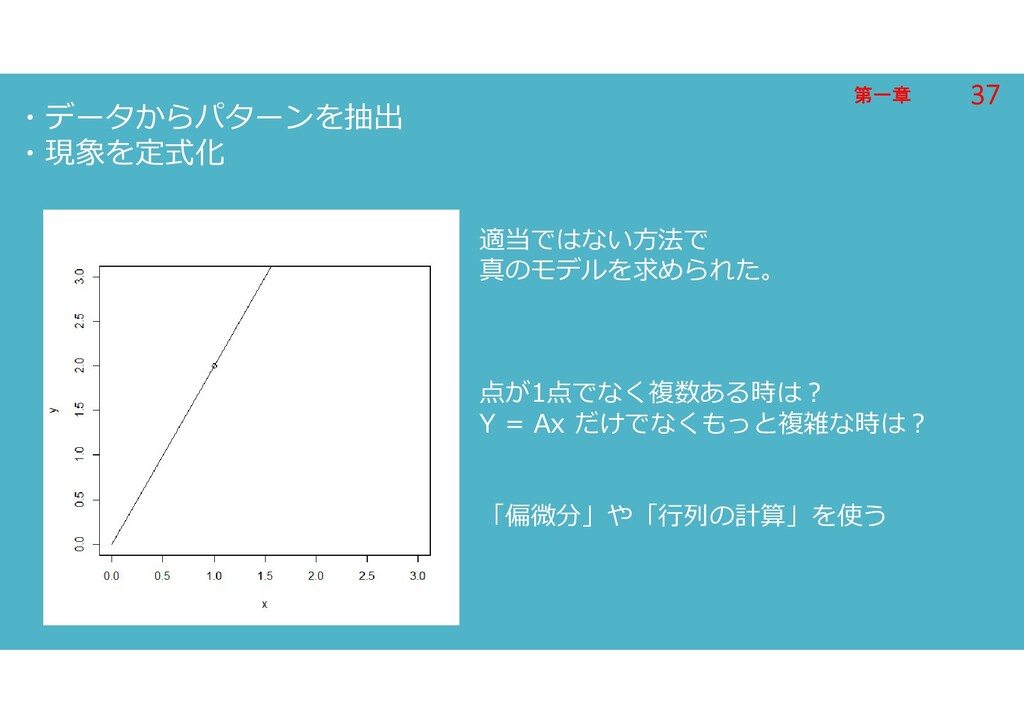
第一章 第一章 ・データからパターンを抽出 ・現象を定式化 適当ではない方法で 真のモデルを求められた。 点が1点でなく複数ある時は? Y = Ax
だけでなくもっと複雑な時は? 「偏微分」や「行列の計算」を使う 37
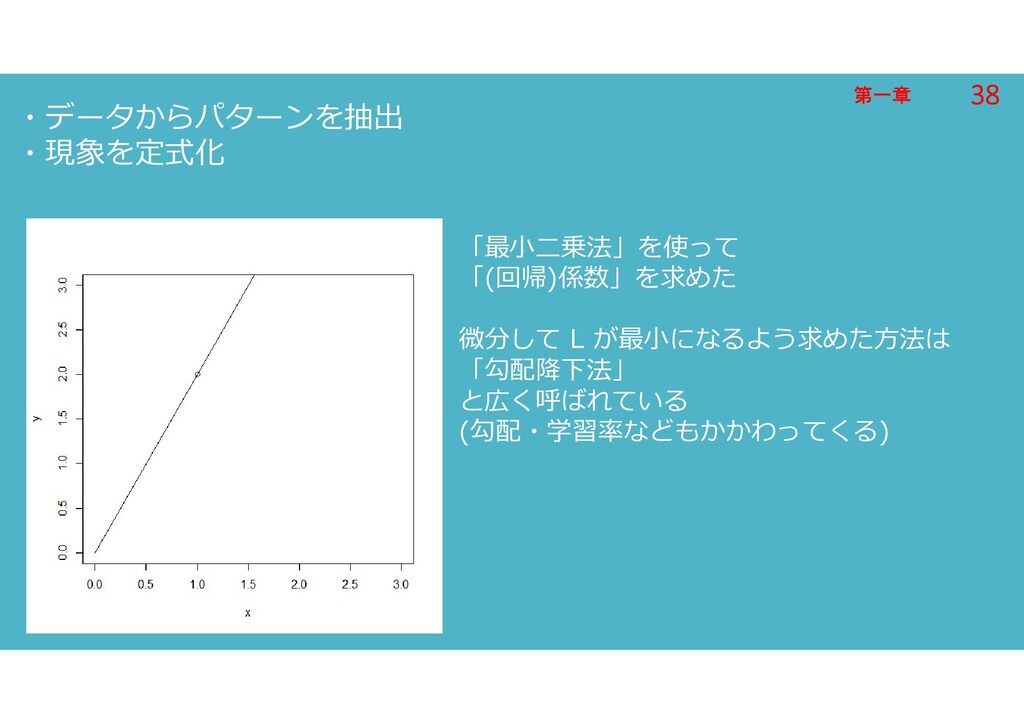
第一章 第一章 ・データからパターンを抽出 ・現象を定式化 「最小二乗法」を使って 「(回帰)係数」を求めた 微分して L が最小になるよう求めた方法は 「勾配降下法」
と広く呼ばれている (勾配・学習率などもかかわってくる) 38
第一章 第一章 なんでここにスライドが? 39
第一章 第一章 回帰(regression) 教師あり・なし 簡単な線形代数 パラメトリック・ノンパラメトリック モデルのバイアス、バリアンス モデル評価 評価できない問題 40
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}