Data Analysis Juan Roa – Software Engineer, MSc in Computer Science. Dr. Aicardo Roa-Espinosa – CEO Soilnet LLC Sue Byram – Financial Officer Soilnet LLC Dr. Hien Nguyen – Project Advisor Michelle Pham – MSc in Environmental Science Camilo Perez – PhD in Mechanical Engineering Samuel Roa-Lauby, Lab Manager Soilnet LLC Alexander Seyfarth – Global XRF Technology Manager at SGS Tatiana Quiñonez – Mathematics, MSc in Statistics
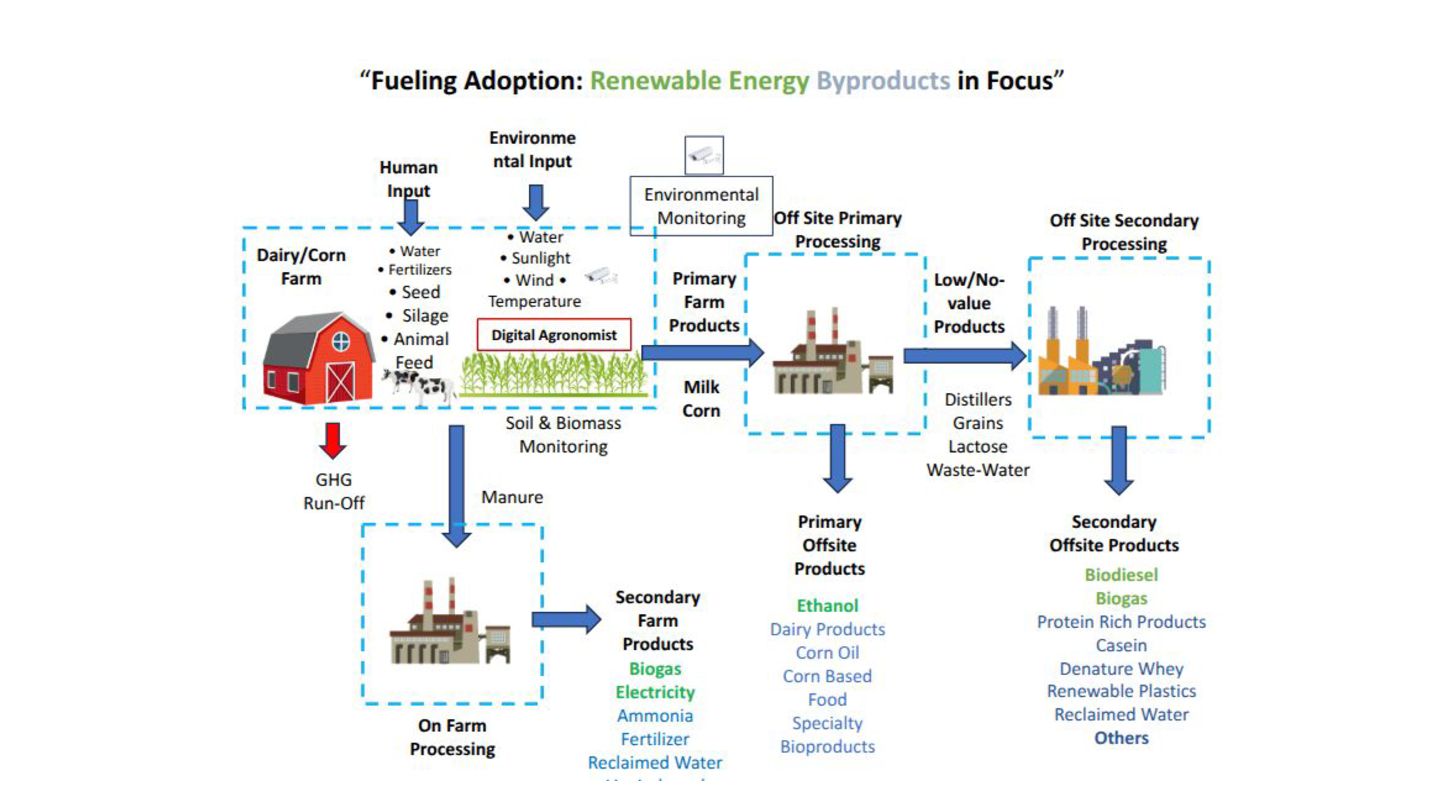
reliant on continuous technological advancements for sustainability and efficiency. • Challenges: The industry grapples with high costs and complexities in soil nutrient analysis, directly hampers optimal agricultural productivity. • By reducing the costs associated with nutrient analysis and improving data accuracy, this initiative aims to enhance crop yield predictions and soil management—paving the way for more innovative, economical agricultural practices.
analytics and machine learning for enhanced soil and plant nutrient analysis. • Core Activities: ◦ Data Collection: Gathering extensive soil and plant data from diverse sources to ensure comprehensive analysis capabilities. ◦ Machine Learning Application: Utilizing machine learning models to accurately predict nutrient levels and provide actionable insights for soil management. • Outcome: The project aims to reduce the complexity and costs associated with traditional soil and plant analysis methods, thus enabling more precise and cost-effective agricultural practices. Project Definition
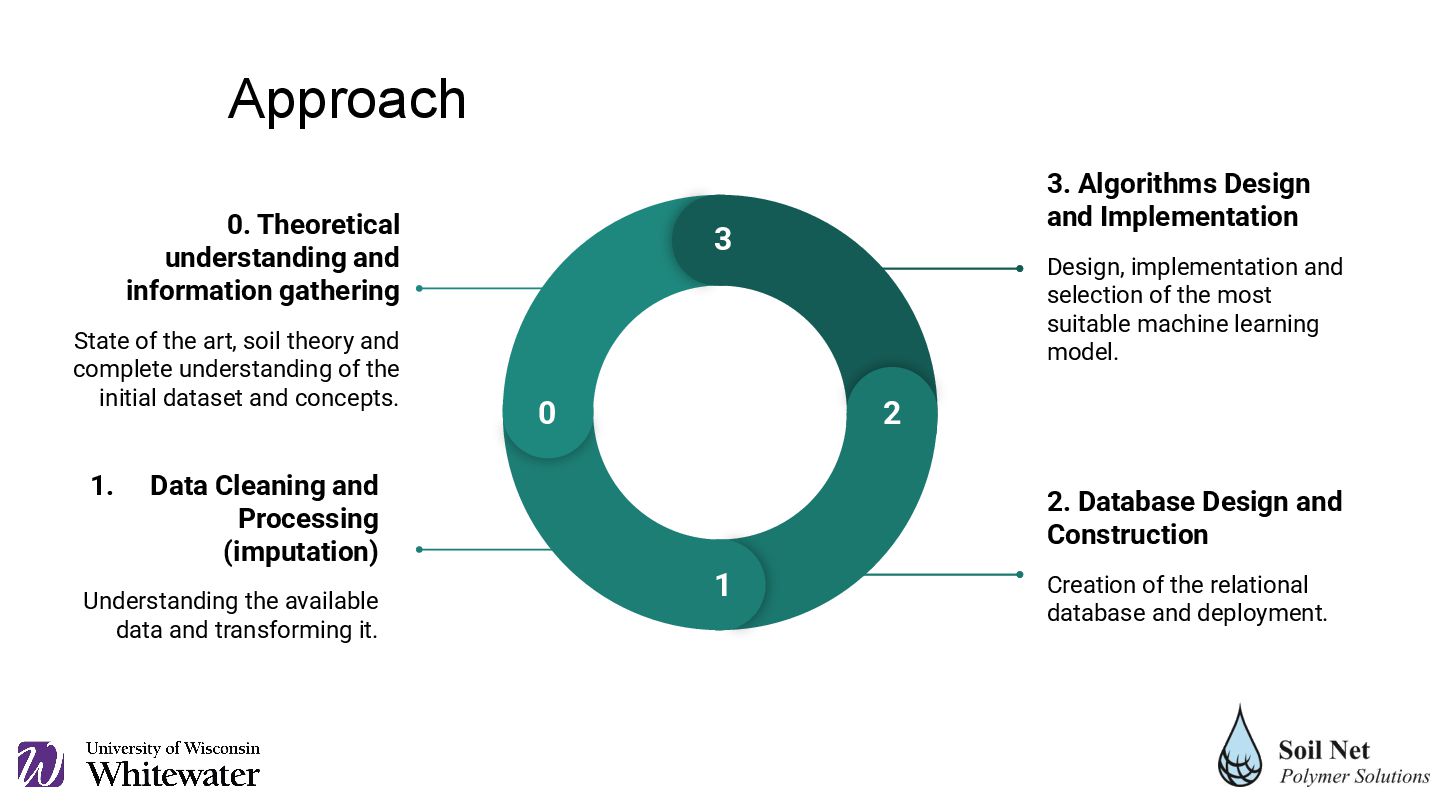
and transforming it. 2. Database Design and Construction Creation of the relational database and deployment. 3. Algorithms Design and Implementation Design, implementation and selection of the most suitable machine learning model. 0. Theoretical understanding and information gathering State of the art, soil theory and complete understanding of the initial dataset and concepts. 0 1 2 3 Approach
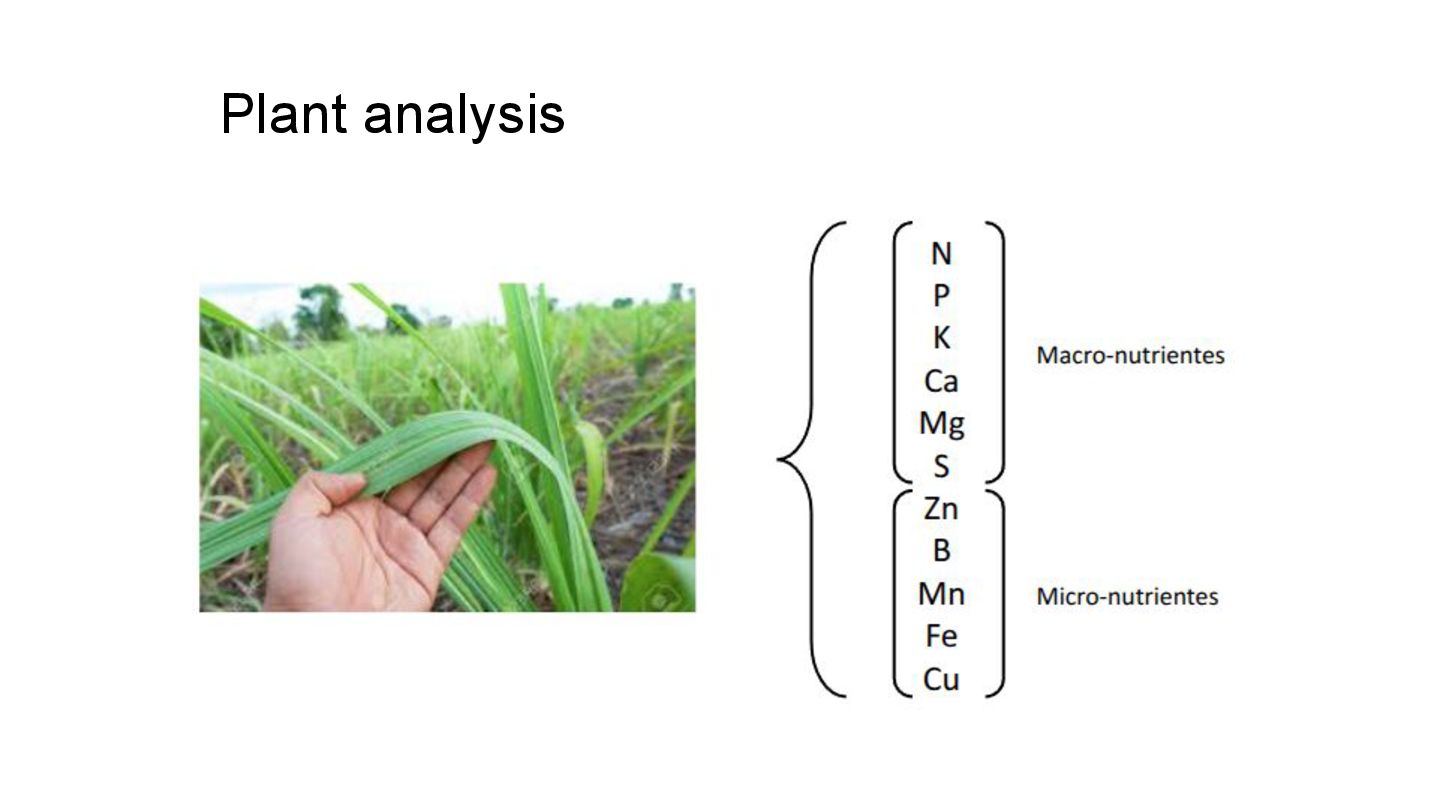
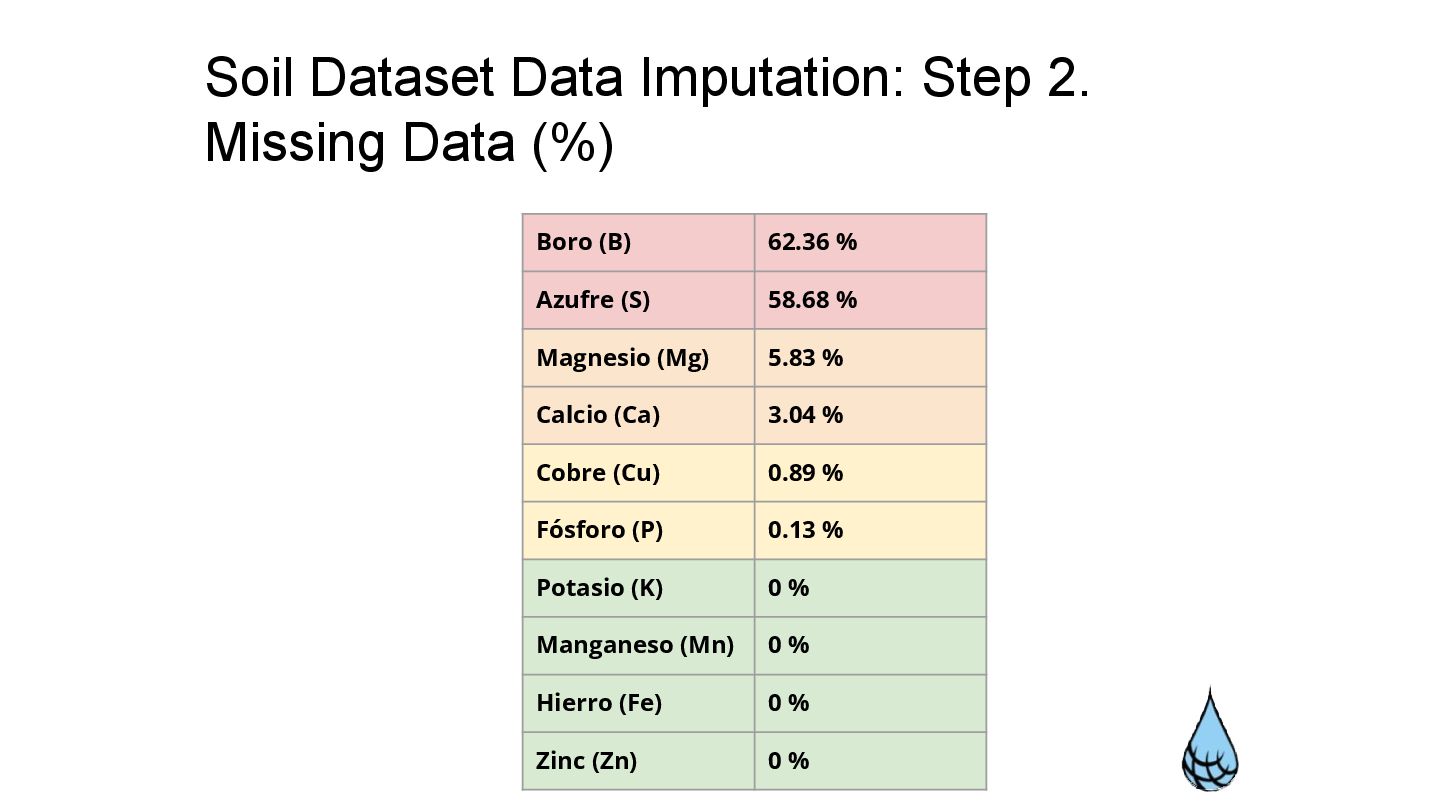
Evaluate non-numeric / label data. • Data Transformation ◦ Imputation analysis for missing data. ◦ Python Script construction for data transformation. ◦ Pre-imputation analysis. • Missing Data Imputation ◦ Theoretical imputation. ◦ Implementation of robust imputation algorithms. ◦ Imputation evaluation and algorithm selection. Stage 1 - Data Cleaning and Processing
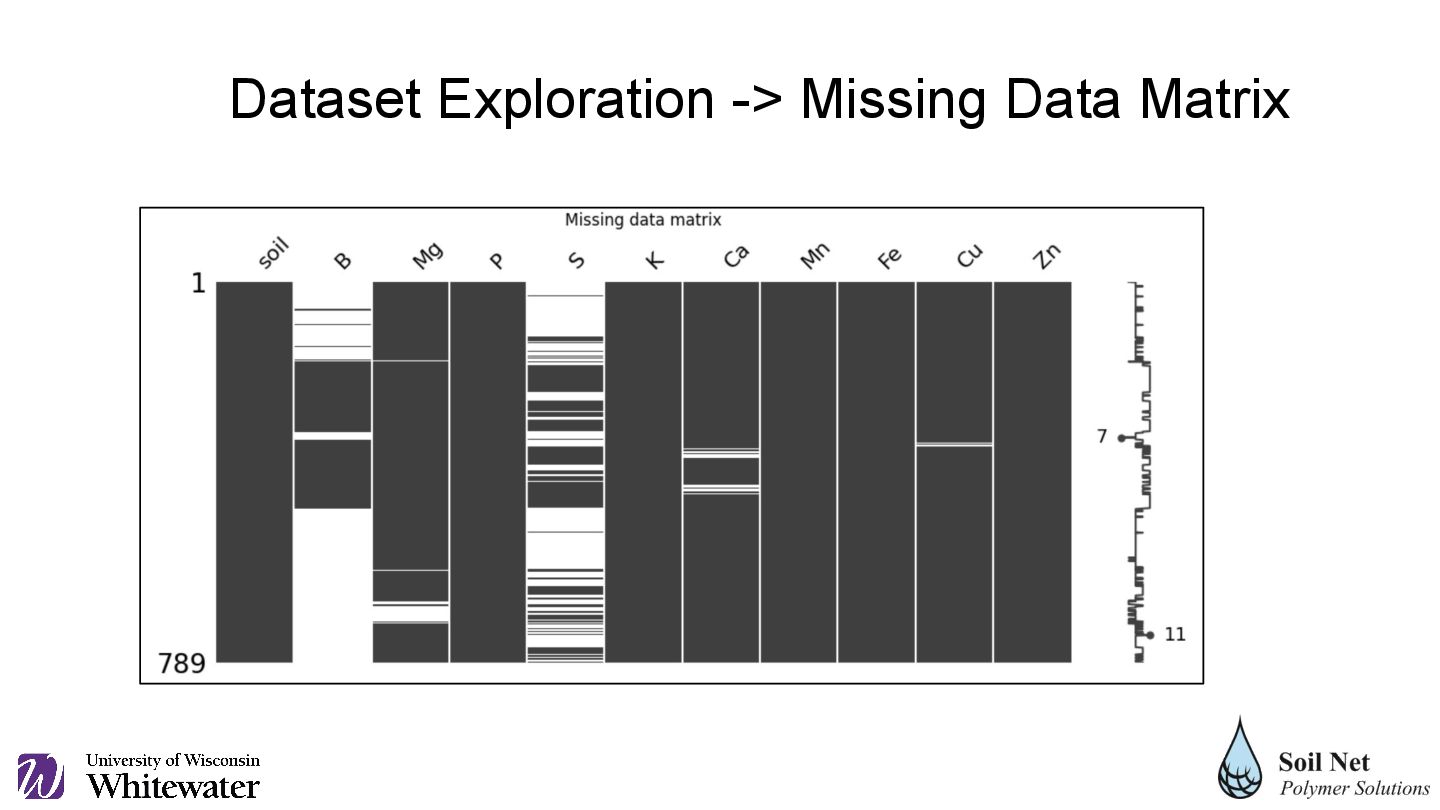
statistical methods and imputed with two algorithms, the best being K-Nearest Neighbors (KNN). Correlation of the 'soil' variable The level of correlation between the categorical variable 'soil' and the other variables was evaluated. It was decided to include it in the analyses. Evaluation of missing data What type of behavior the missing data had and how it was distributed was reviewed. Imputation and evaluation 7 imputation techniques were applied in a sequence of 3 staggered imputations, choosing the best according to several evaluation methods. Final dataset The final dataset was created with the appropriate imputations for each column.
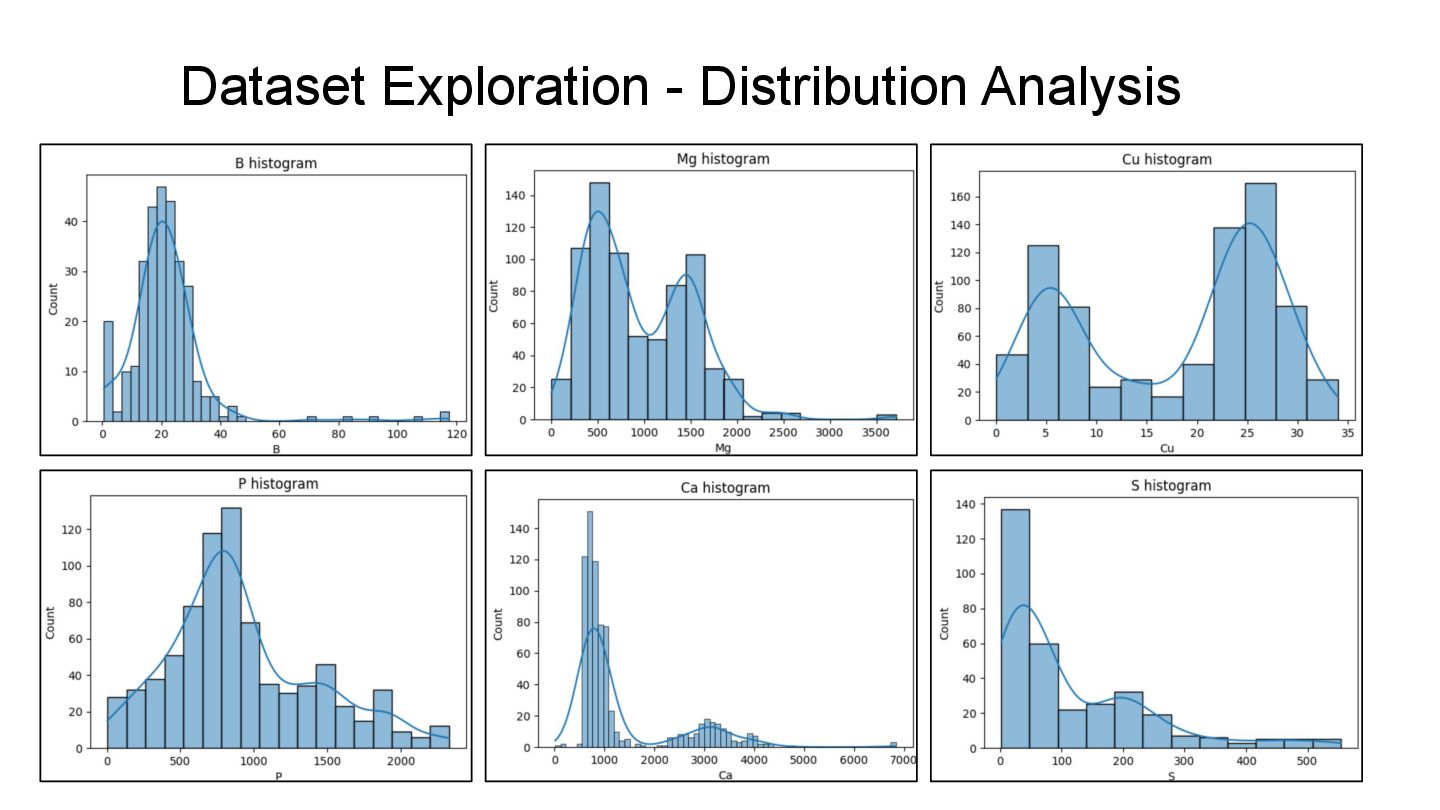
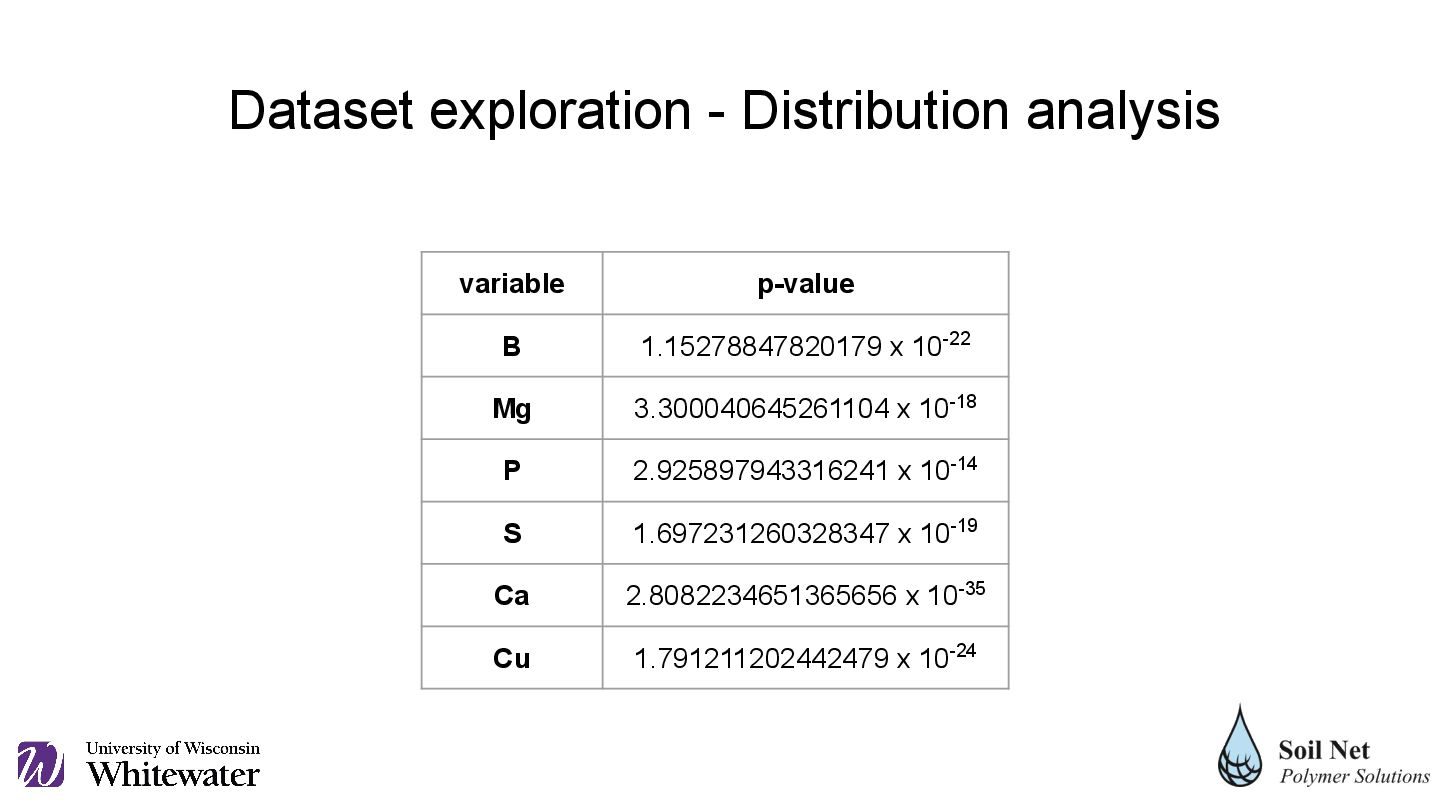
P 2.925897943316241 x 10-14 S 1.697231260328347 x 10-19 Ca 2.8082234651365656 x 10-35 Cu 1.791211202442479 x 10-24 Dataset exploration - Distribution analysis
We have many data points(rows) and features (columns) ◦ Remember how easy it was to multiply a 2×2 matrix? ◦ Now imagine working with higher dimensions—it could take ages. ◦ Operating on (m) rows by (n) columns is computationally expensive. Machine Learning is a lot of Linear Algebra and Statistics
the data 1 2 1. The df_missing dataframe is created where each value is converted to binary, indicating whether the original value was absent ('1') or present ('0'), via the isnull() method, followed by .astype(int) to convert booleans into integers. 2. An empty list is initialized to store the results of the logistic regressions that will be performed for each variable as the dependent variable. Dataset Exploration -> Nature of Missing Data
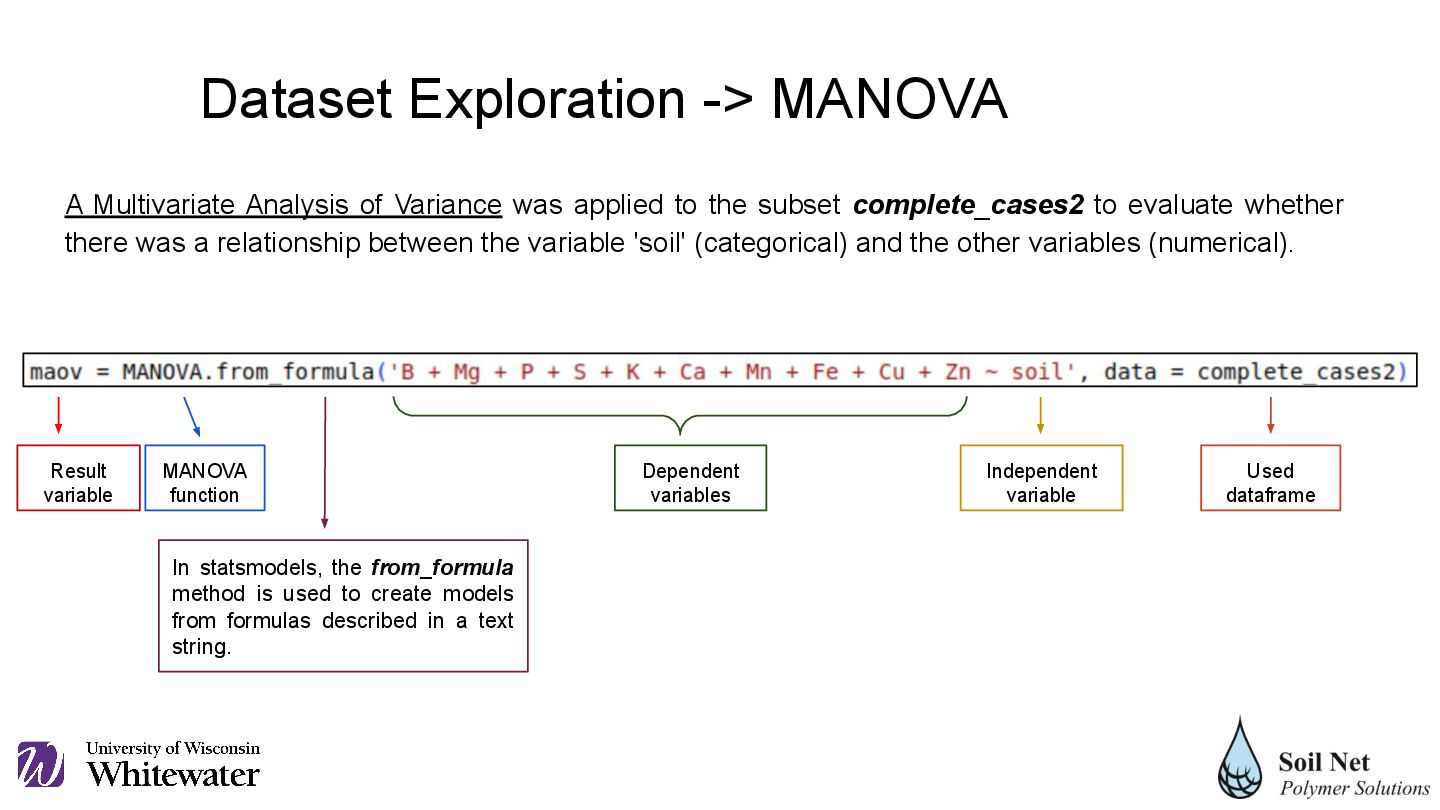
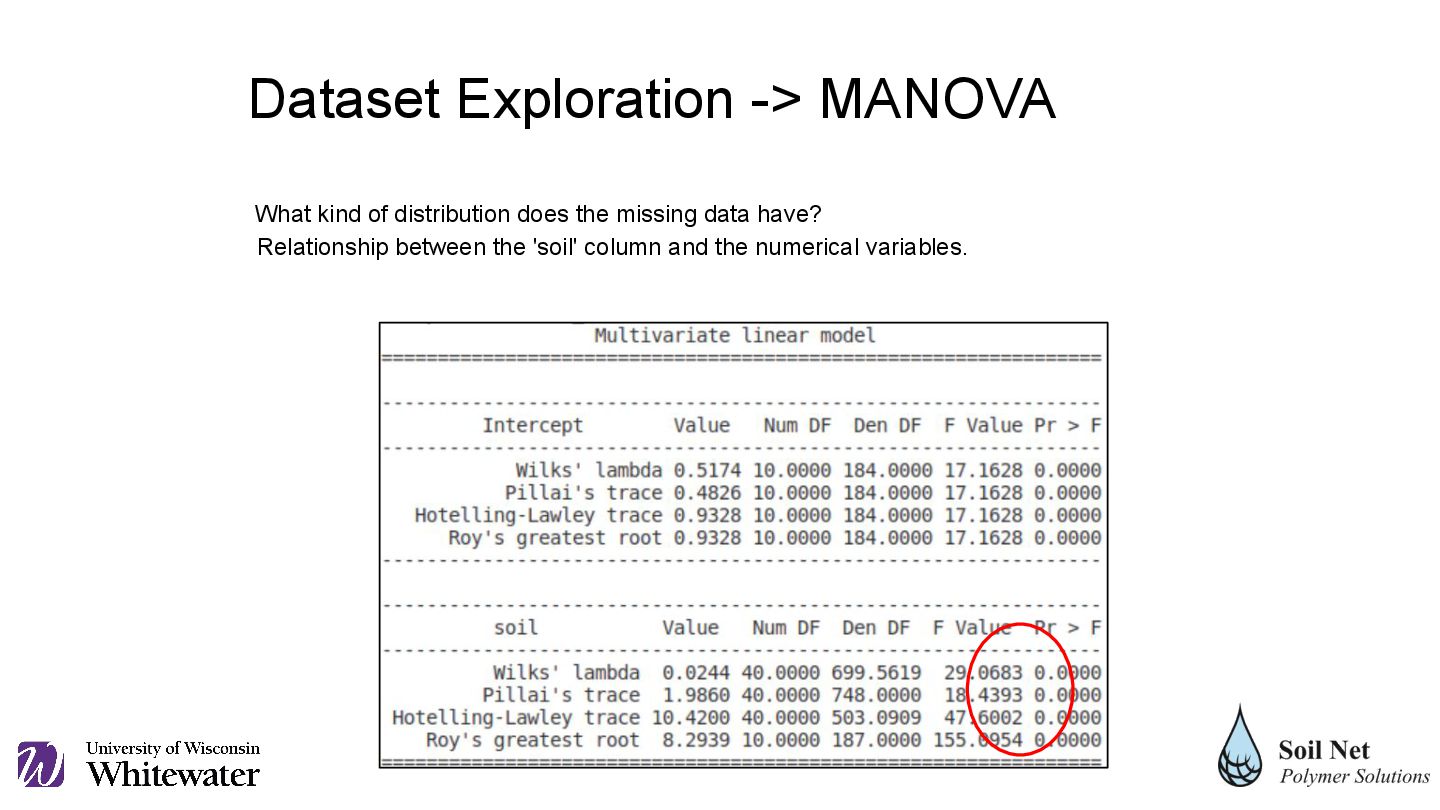
complete_cases2 to evaluate whether there was a relationship between the variable 'soil' (categorical) and the other variables (numerical). Result variable MANOVA function In statsmodels, the from_formula method is used to create models from formulas described in a text string. Dependent variables Independent variable Used dataframe Dataset Exploration -> MANOVA
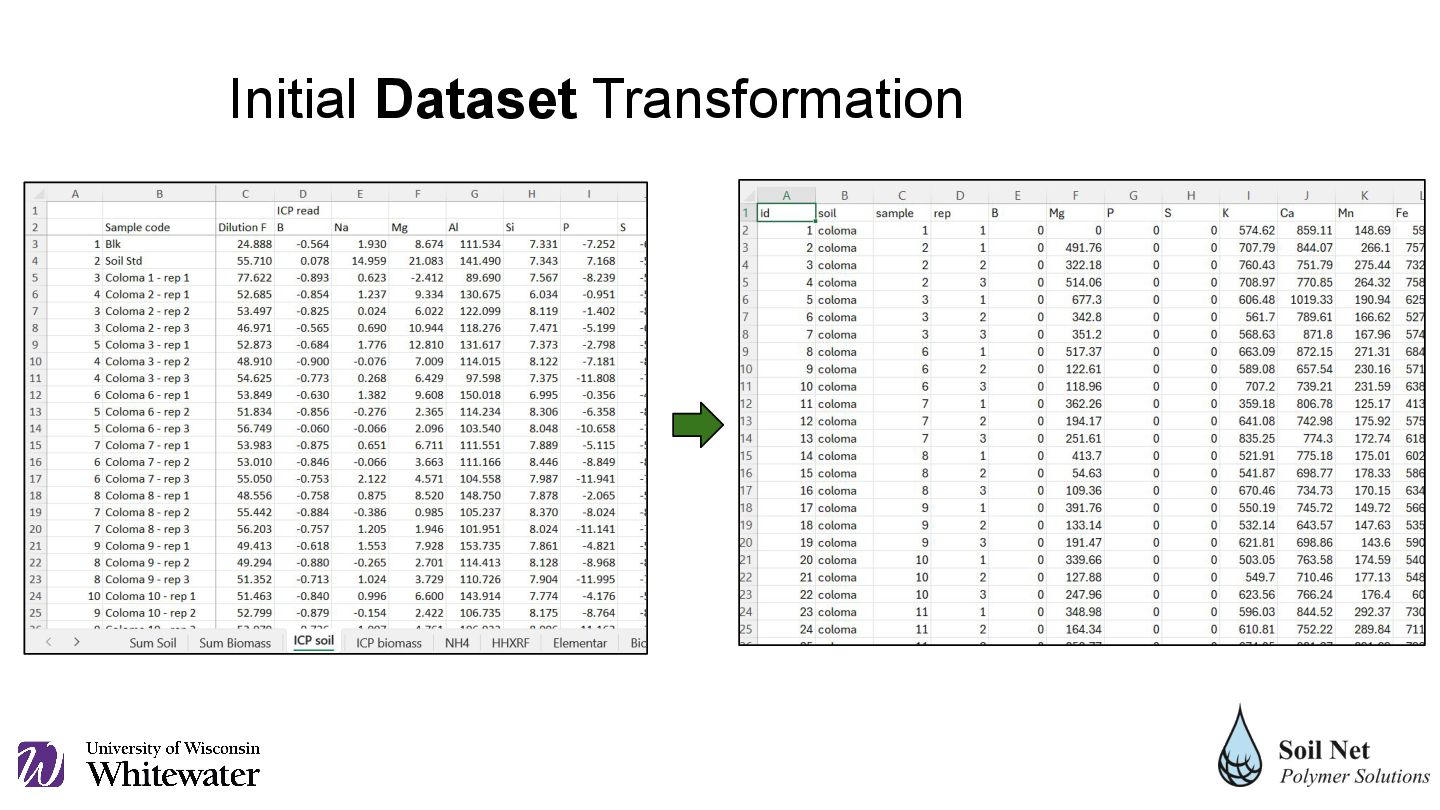
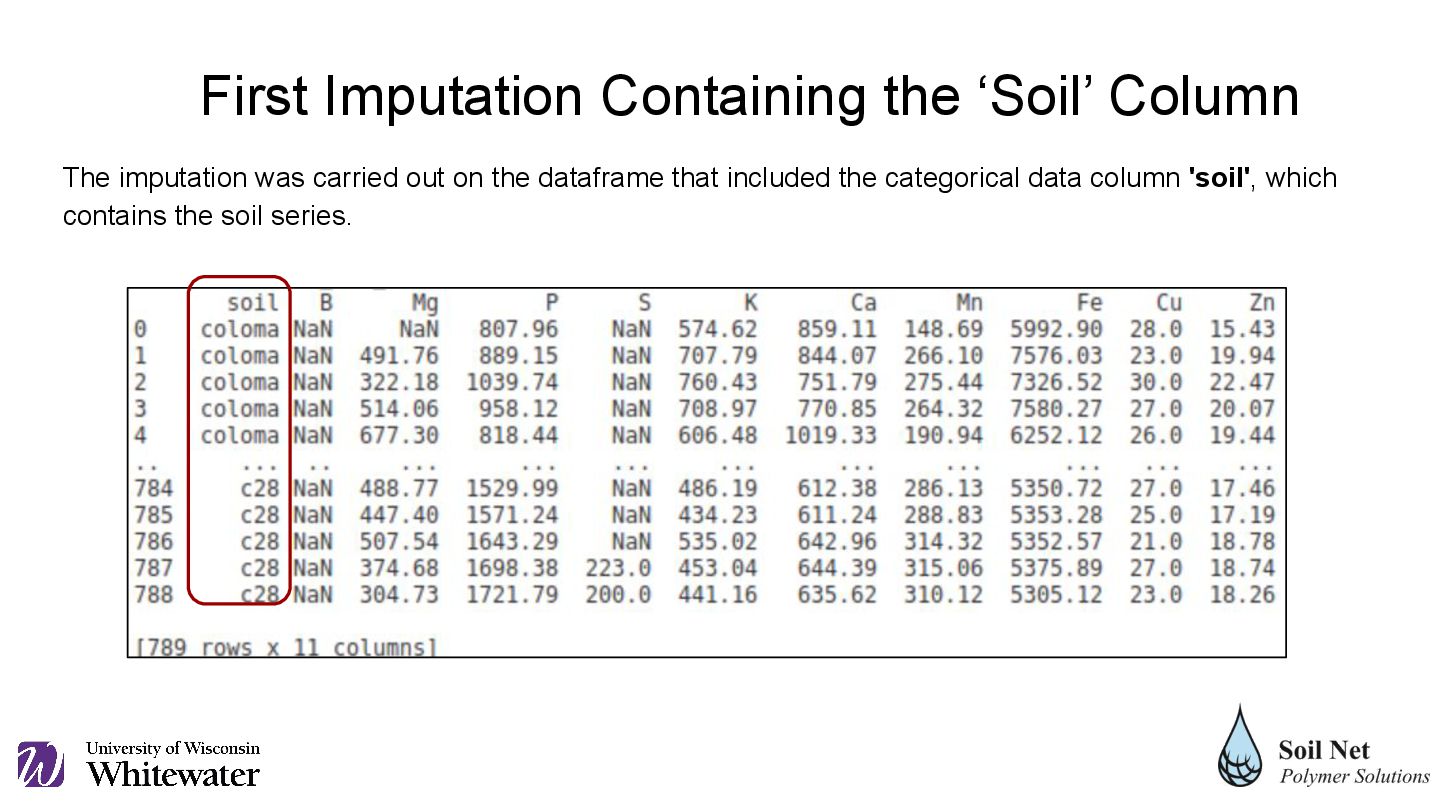
the etl_soil.py script, after a theoretical imputation of the data from the HHXRF analytical method on the ICP data. There are two dataframes that are generated, one without all the categorical columns 'soil', 'sample' and 'rep', and another that includes the column 'soil' which contains the soil series to which the sample belongs. Dataframe Preparation
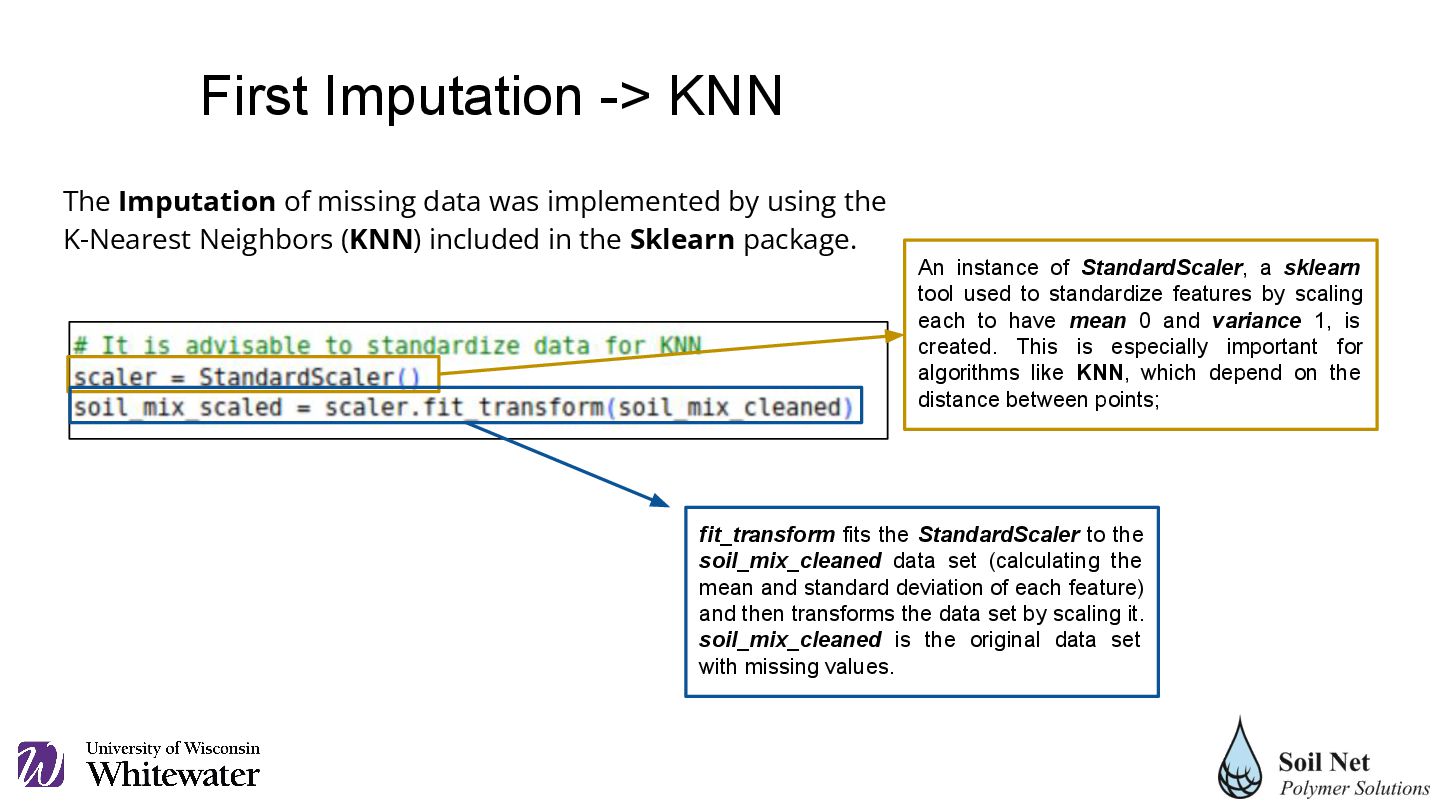
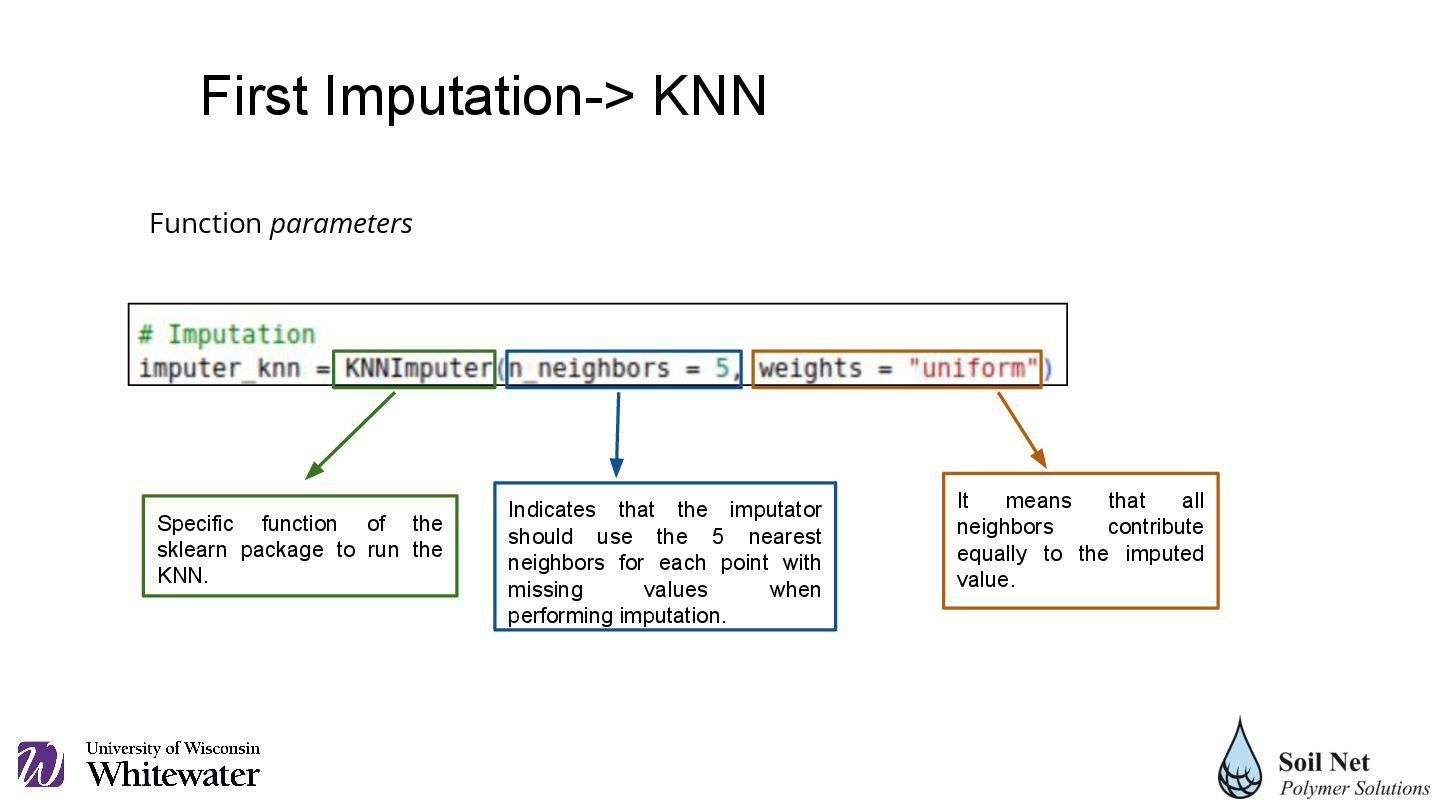
K-Nearest Neighbors (KNN) included in the Sklearn package. An instance of StandardScaler, a sklearn tool used to standardize features by scaling each to have mean 0 and variance 1, is created. This is especially important for algorithms like KNN, which depend on the distance between points; fit_transform fits the StandardScaler to the soil_mix_cleaned data set (calculating the mean and standard deviation of each feature) and then transforms the data set by scaling it. soil_mix_cleaned is the original data set with missing values. First Imputation -> KNN
Indicates that the imputator should use the 5 nearest neighbors for each point with missing values when performing imputation. It means that all neighbors contribute equally to the imputed value. Function parameters First Imputation-> KNN
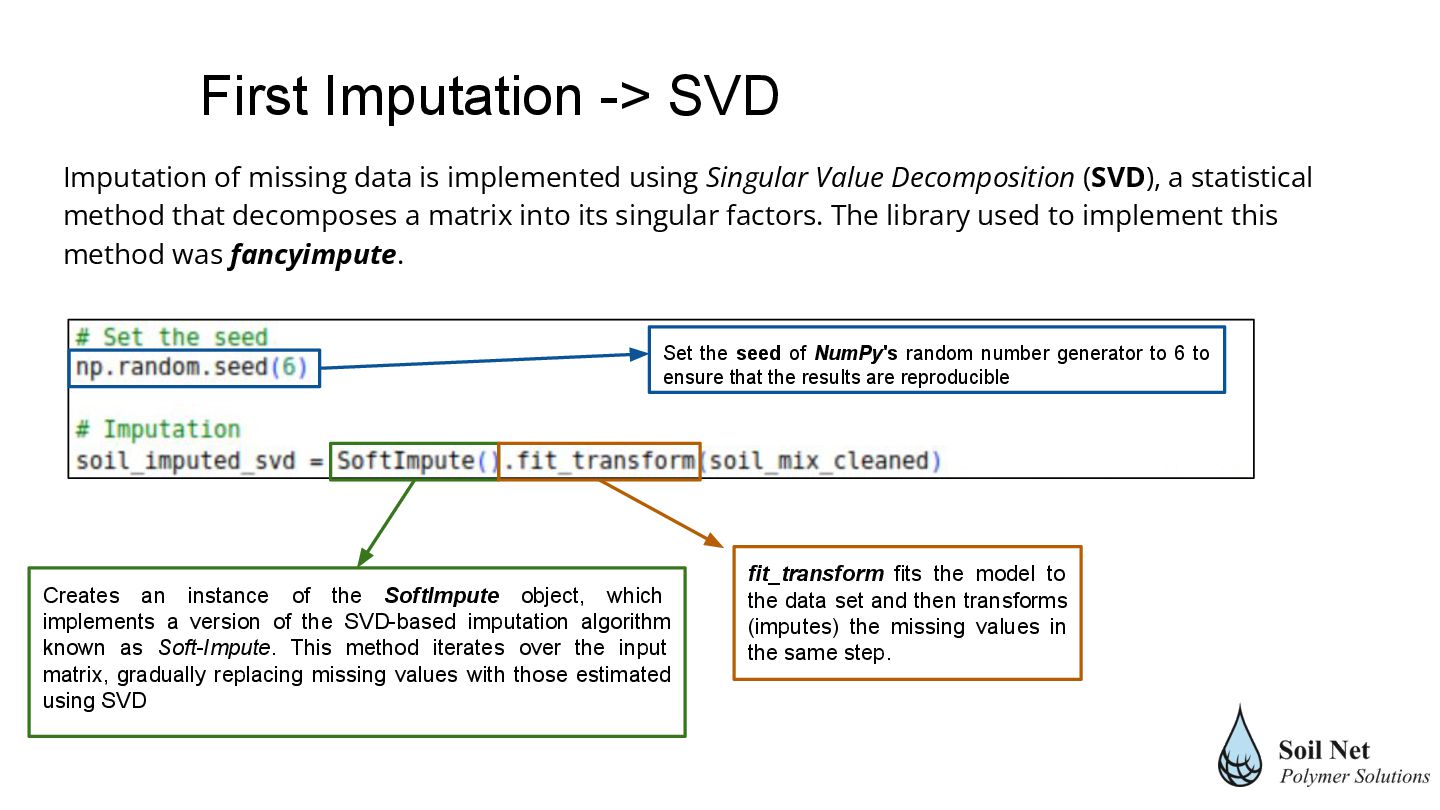
(SVD), a statistical method that decomposes a matrix into its singular factors. The library used to implement this method was fancyimpute. Creates an instance of the SoftImpute object, which implements a version of the SVD-based imputation algorithm known as Soft-Impute. This method iterates over the input matrix, gradually replacing missing values with those estimated using SVD Set the seed of NumPy's random number generator to 6 to ensure that the results are reproducible fit_transform fits the model to the data set and then transforms (imputes) the missing values in the same step. First Imputation -> SVD
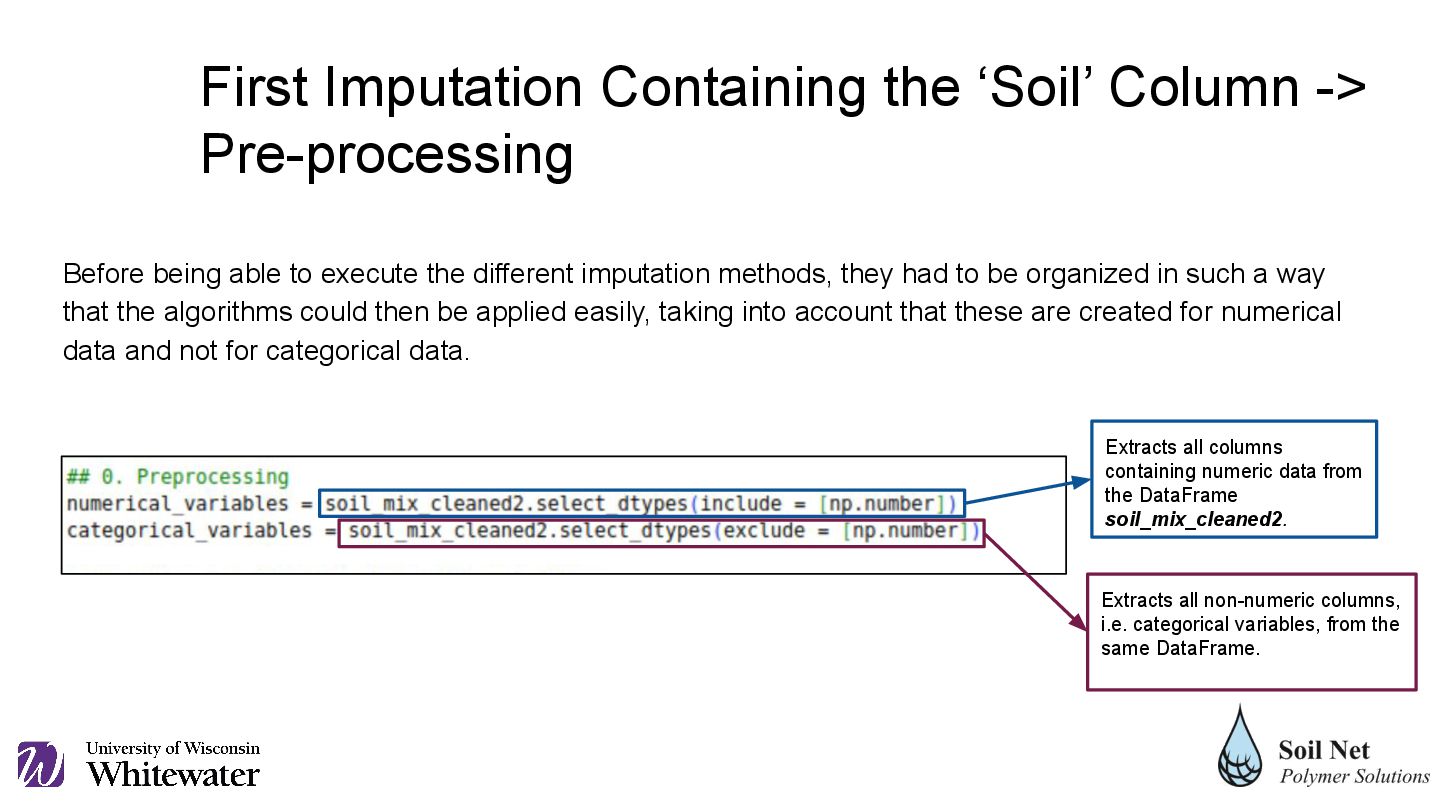
had to be organized in such a way that the algorithms could then be applied easily, taking into account that these are created for numerical data and not for categorical data. Extracts all columns containing numeric data from the DataFrame soil_mix_cleaned2. Extracts all non-numeric columns, i.e. categorical variables, from the same DataFrame. First Imputation Containing the ‘Soil’ Column -> Pre-processing
a format that can be provided to machine learning algorithms, which typically require numerical input. This is a scikit-learn class used to convert categorical variables into a numerical form that can be more easily used by machine learning models. It does this by creating a new binary column for each unique category in the original column. During data transformation, it may occur that categories appear that were not present in the original data set during encoder training. By default, OneHotEncoder returns a sparse array to save memory, especially useful when there are many categories. However, by setting sparse=False, the encoder will return a dense array of NumPy. First Imputation Containing the ‘Soil’ Column -> Pre-processing
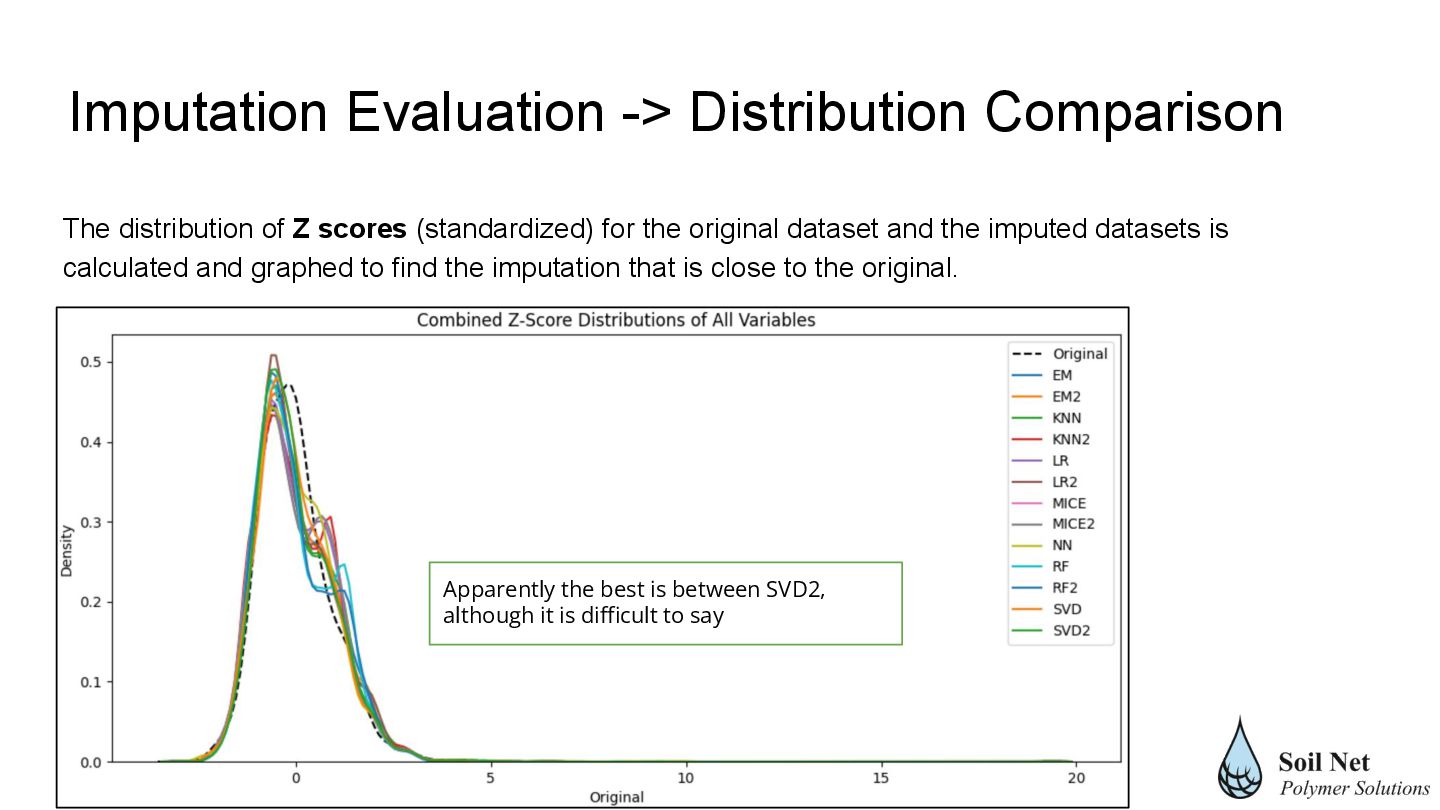
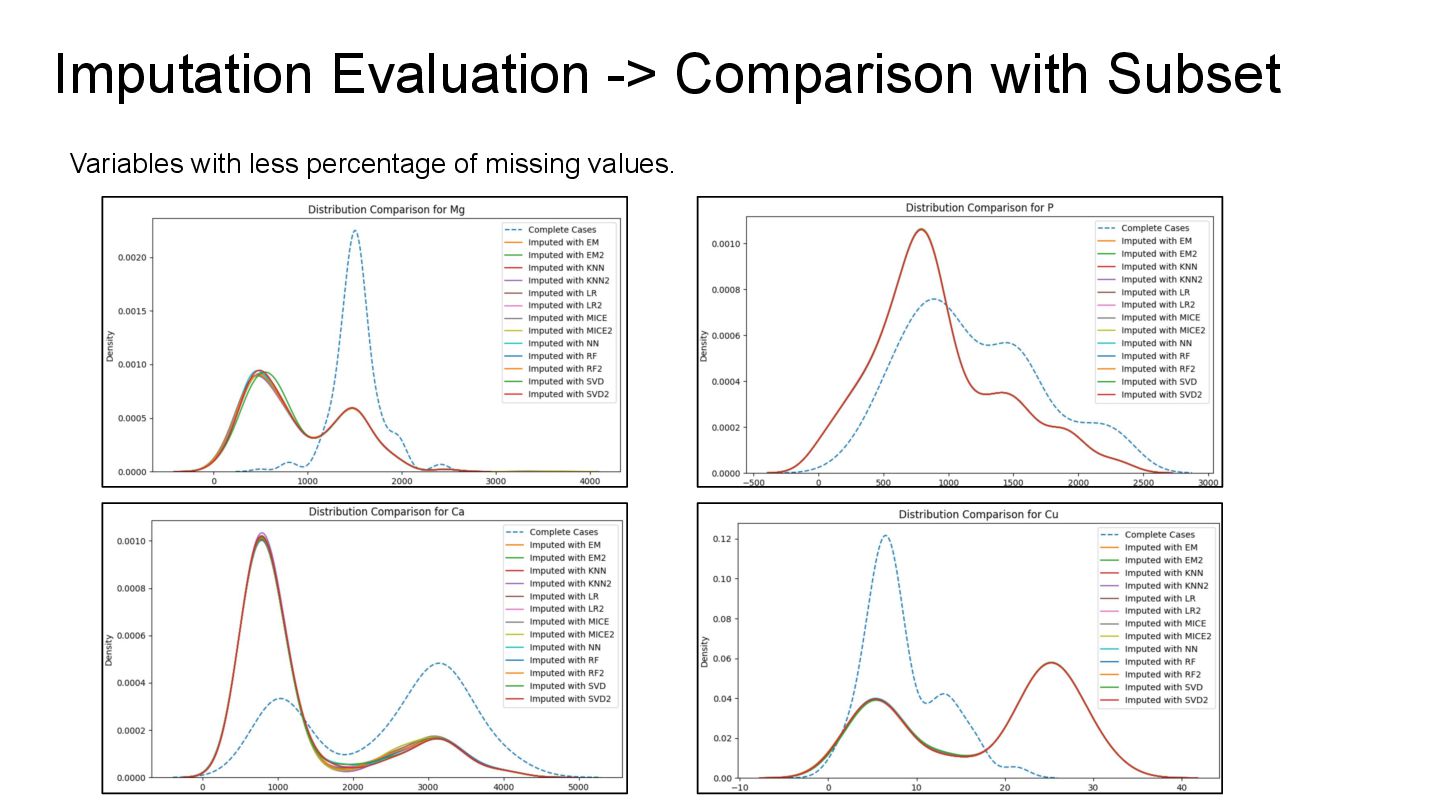
and the imputed datasets is calculated and graphed to find the imputation that is close to the original. Apparently the best is between SVD2, although it is difficult to say Imputation Evaluation -> Distribution Comparison
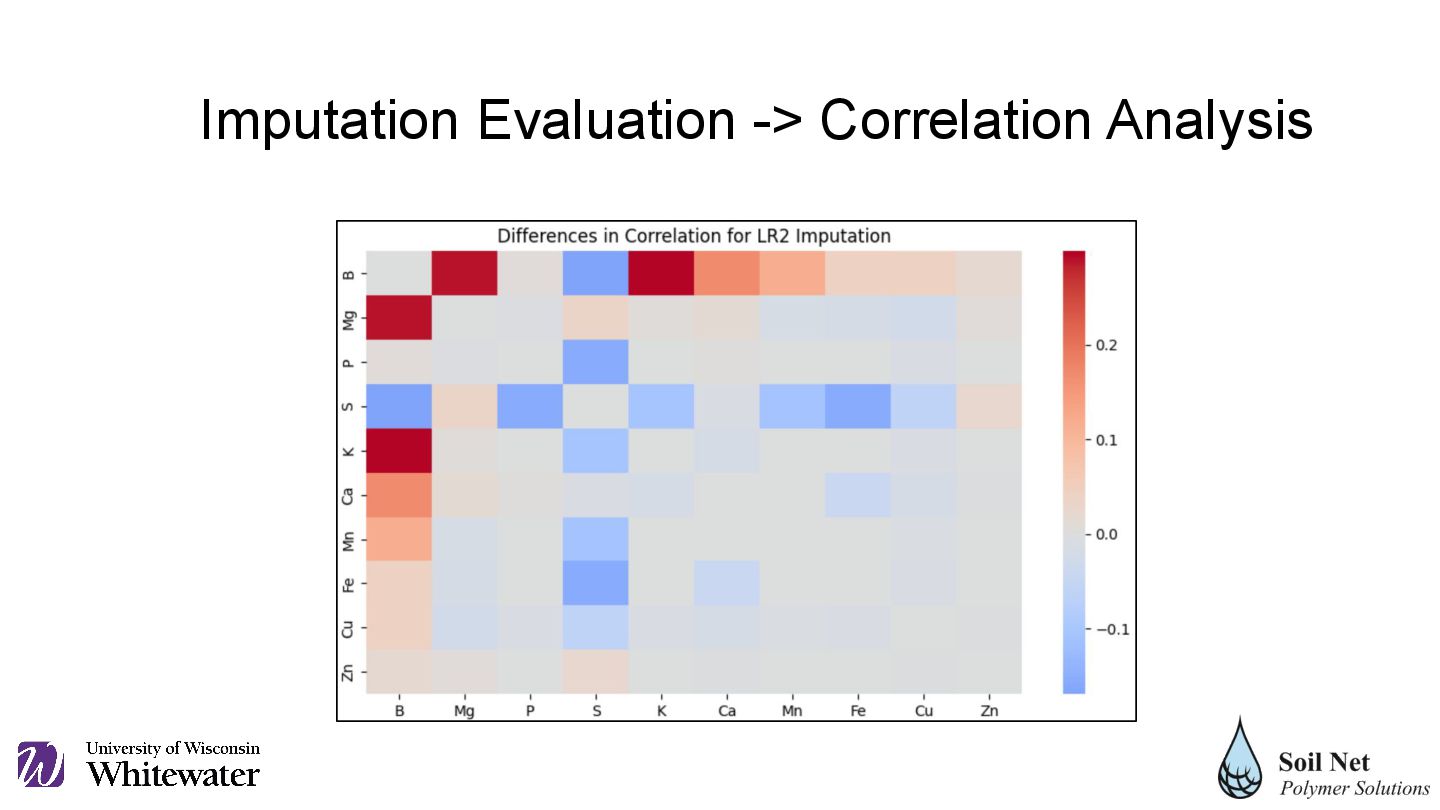
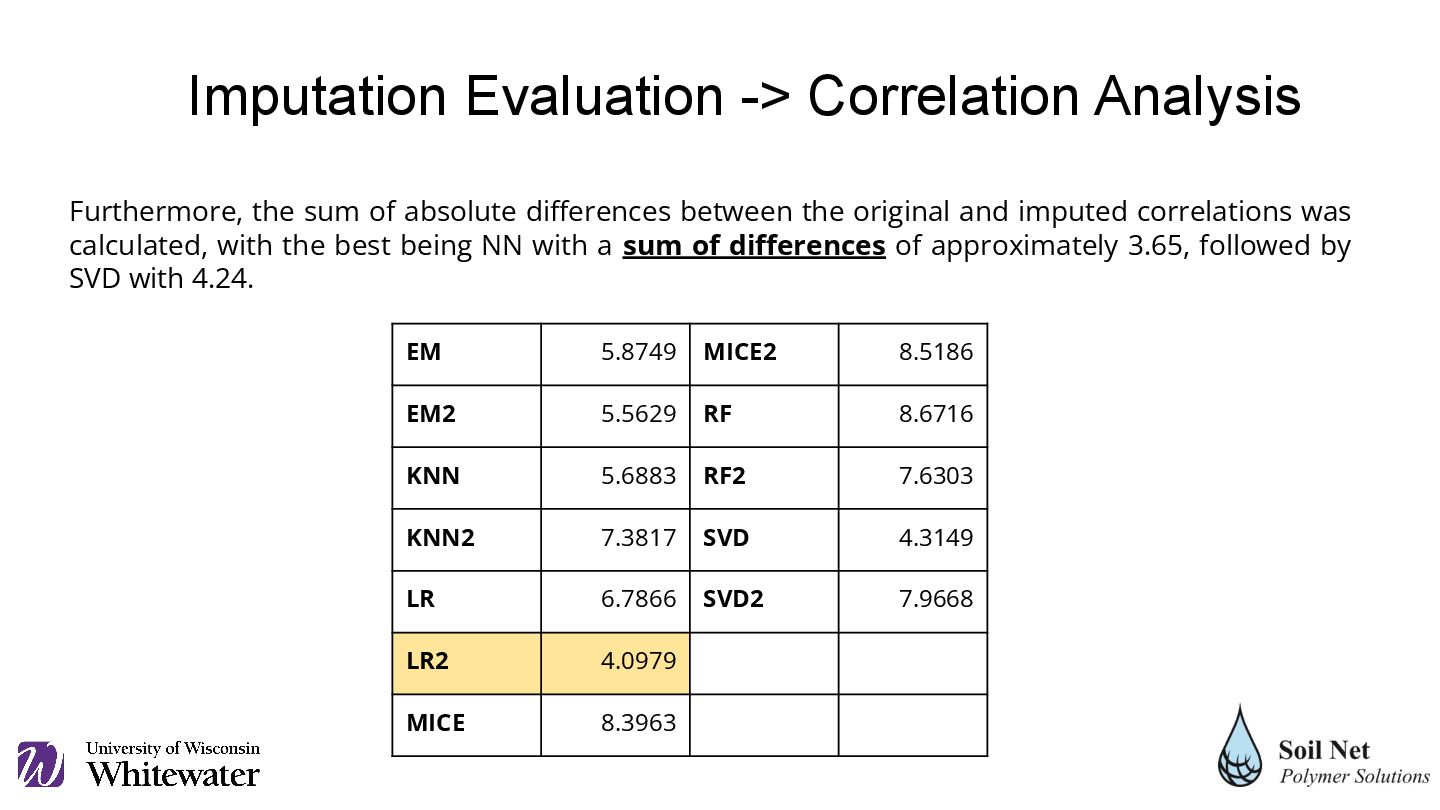
imputed correlations was calculated, with the best being NN with a sum of differences of approximately 3.65, followed by SVD with 4.24. EM 5.8749 MICE2 8.5186 EM2 5.5629 RF 8.6716 KNN 5.6883 RF2 7.6303 KNN2 7.3817 SVD 4.3149 LR 6.7866 SVD2 7.9668 LR2 4.0979 MICE 8.3963 Imputation Evaluation -> Correlation Analysis
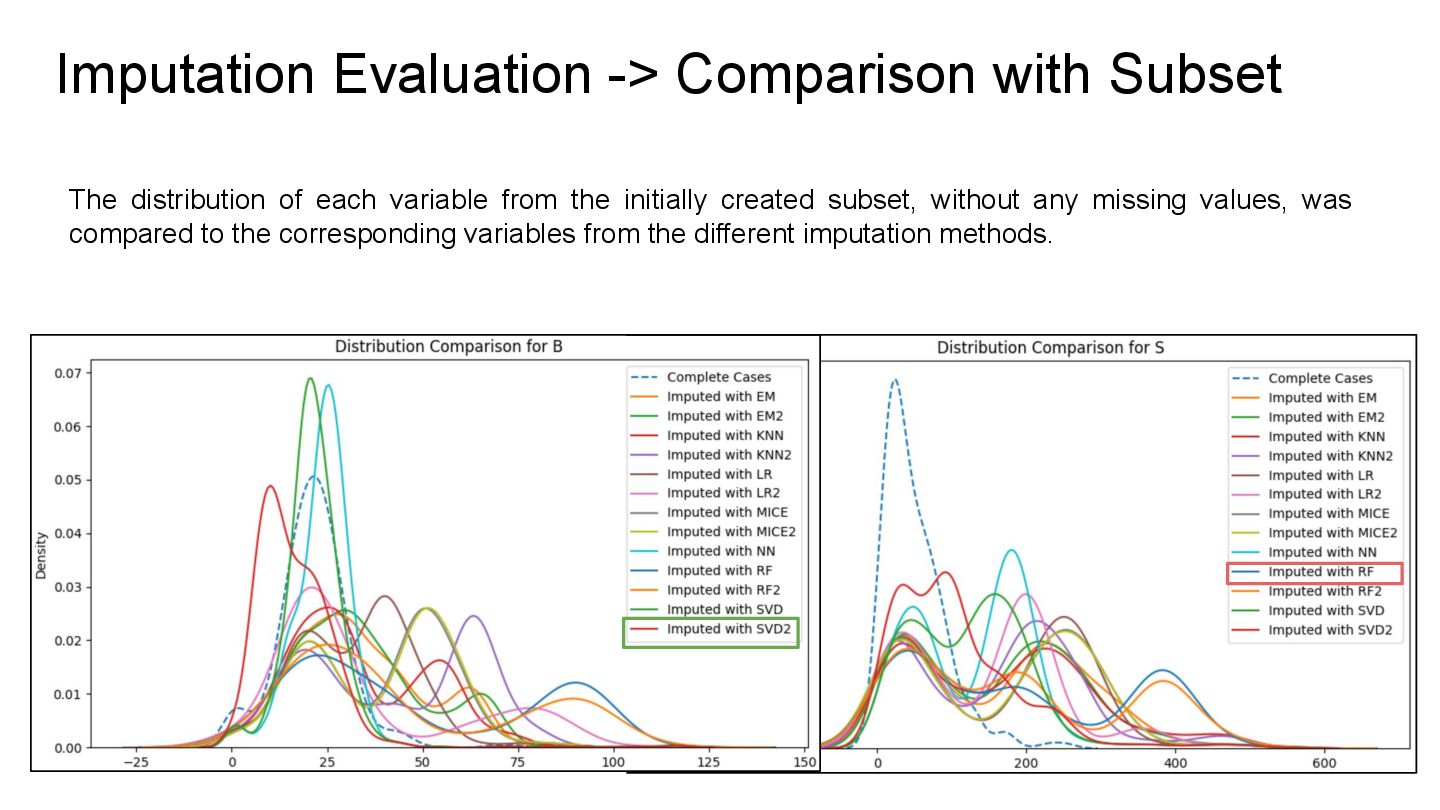
without any missing values, was compared to the corresponding variables from the different imputation methods. Imputation Evaluation -> Comparison with Subset
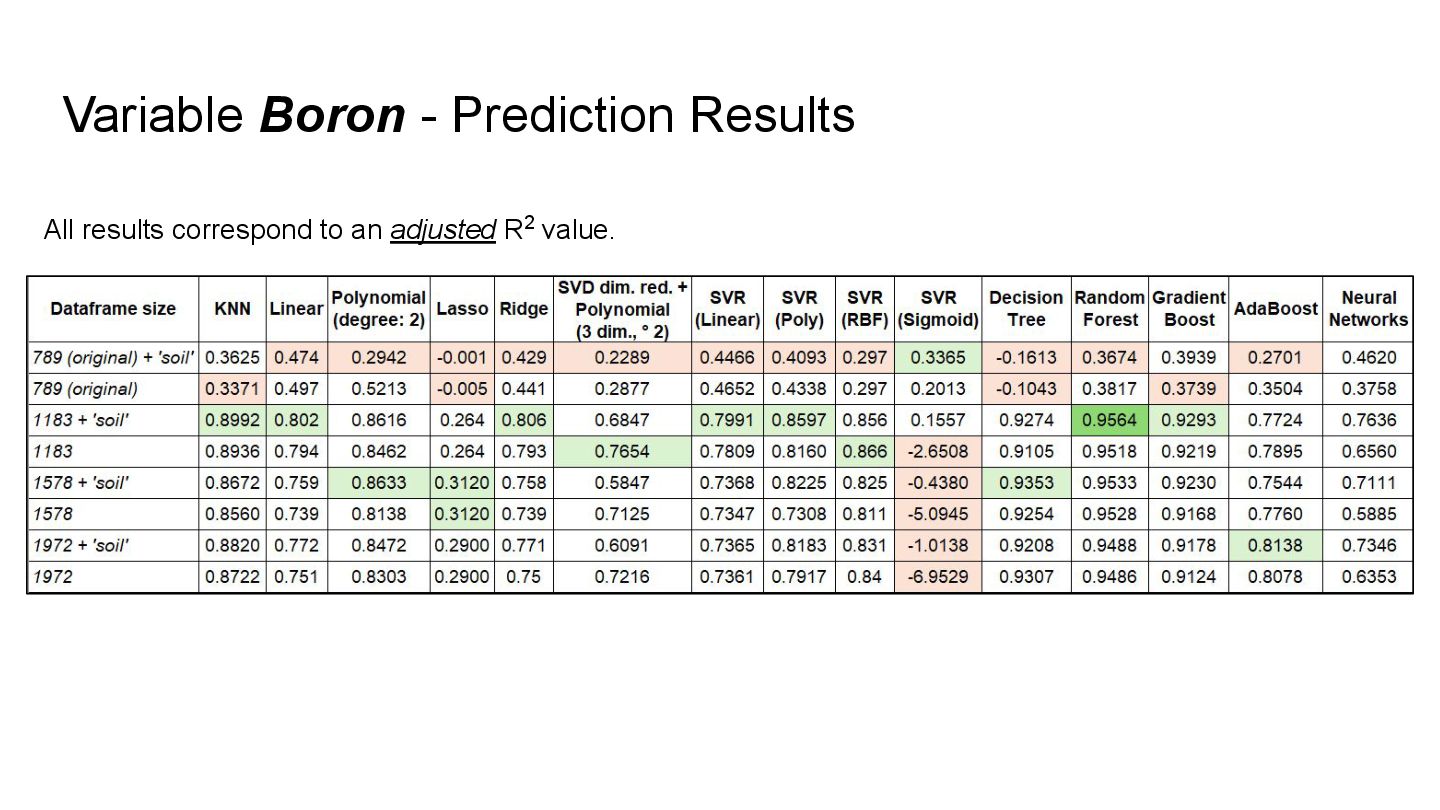
imputations, the final dataset is constructed by replacing the columns of the 6 variables that had missing values with the corresponding columns of the methods that gave the best results for each variable. 3rd Imputation Result for the variable Sulfur. 1st Imputation Results of the variables with the least missing values: Copper, Calcium, Phosphorus, and Magnesium. 2nd Imputation Results for the variable Boron. Missing Data Imputation
the final dataset was built by replacing the columns of the six variables with missing values using the corresponding imputed data. • B -> SVD from the second imputation. • Mg -> SVD from the first imputation. • P -> MICE from the first imputation. • S -> SVD2 from the third imputation. • Ca -> KNN2 from the first imputation. • Cu -> KNN from the first imputation.
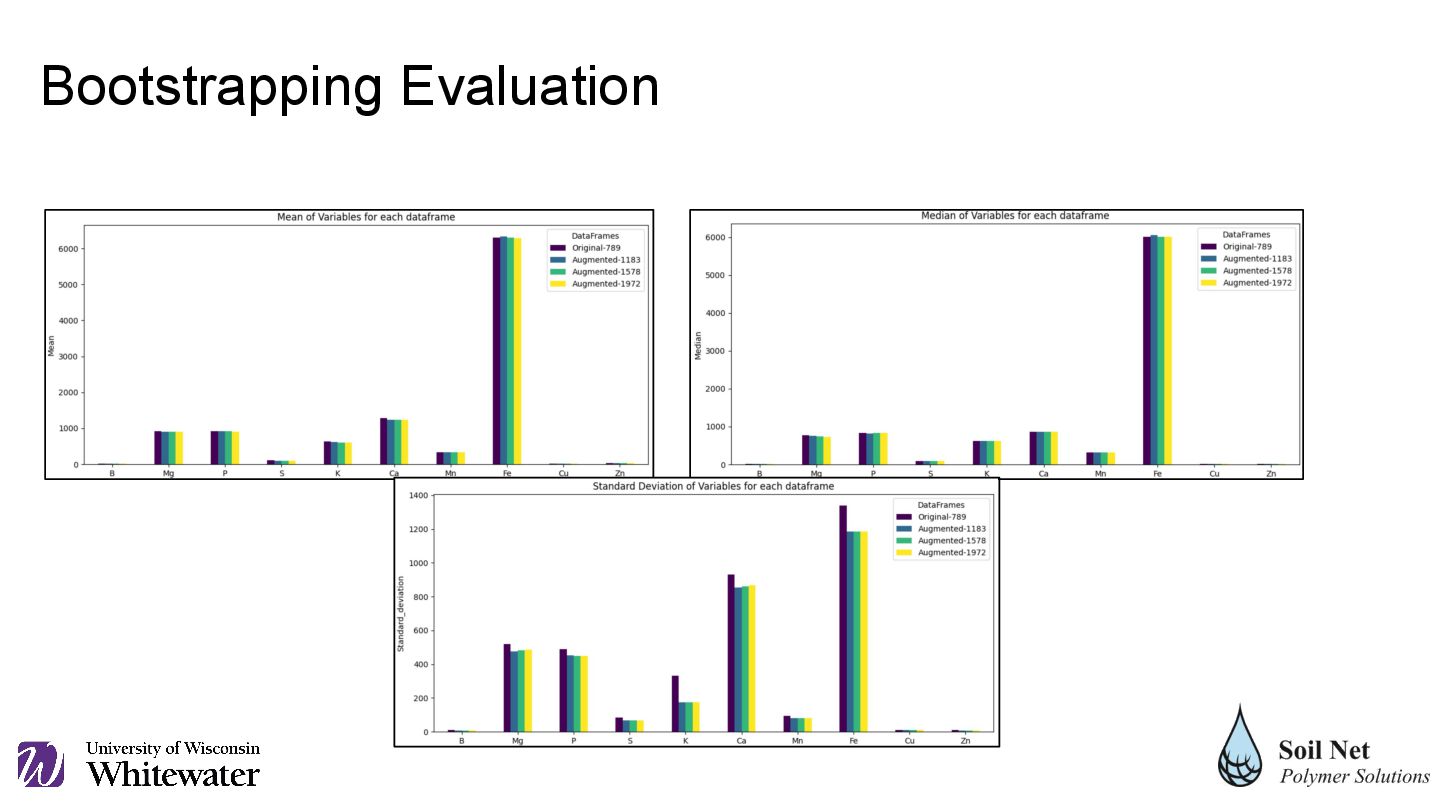
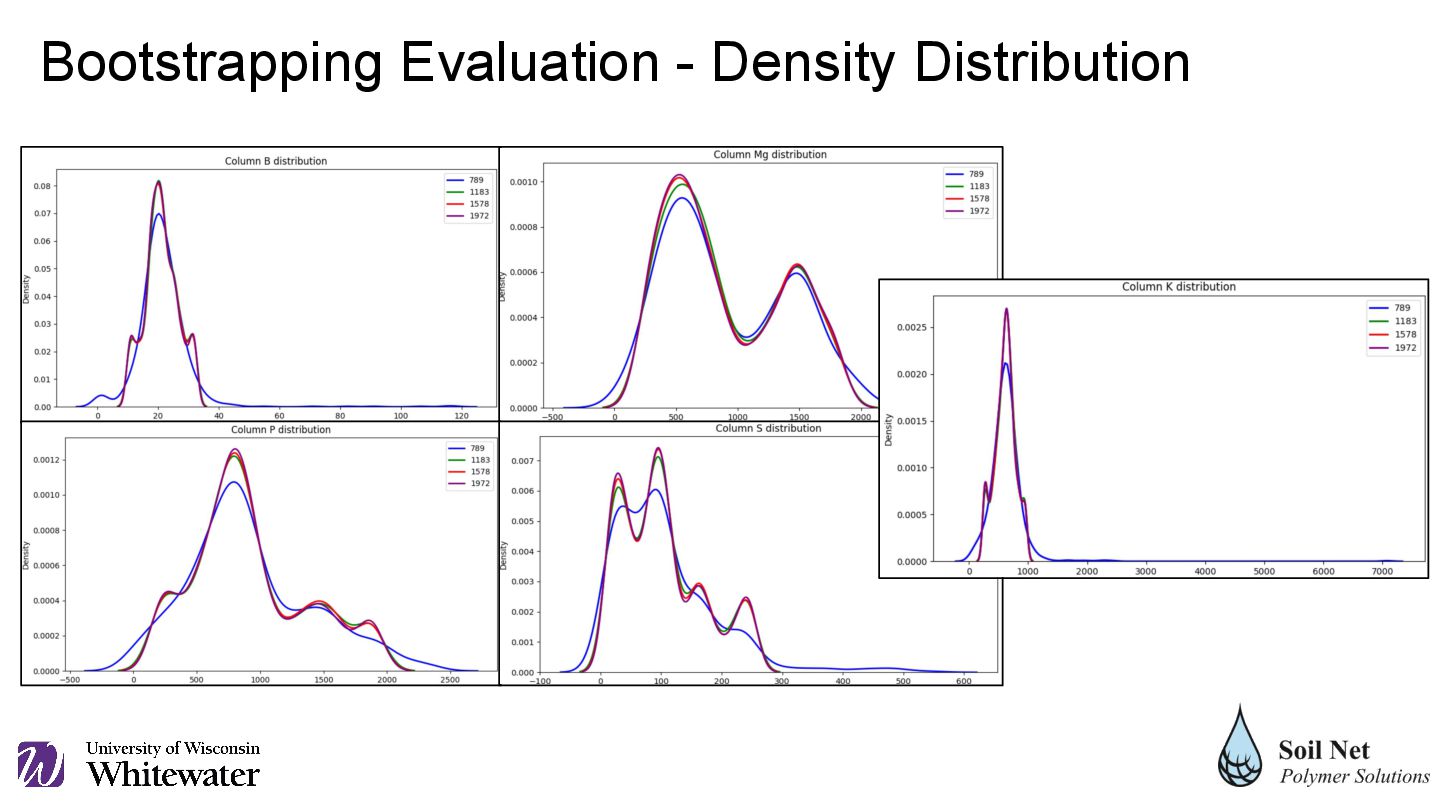
original python pandas dataframes of 789 rows (with and without the categorical variable 'soil'), three more sizes were constructed, represented in six dataframes of 1.5, 2 and 2.5 times the size of the original dataframe.
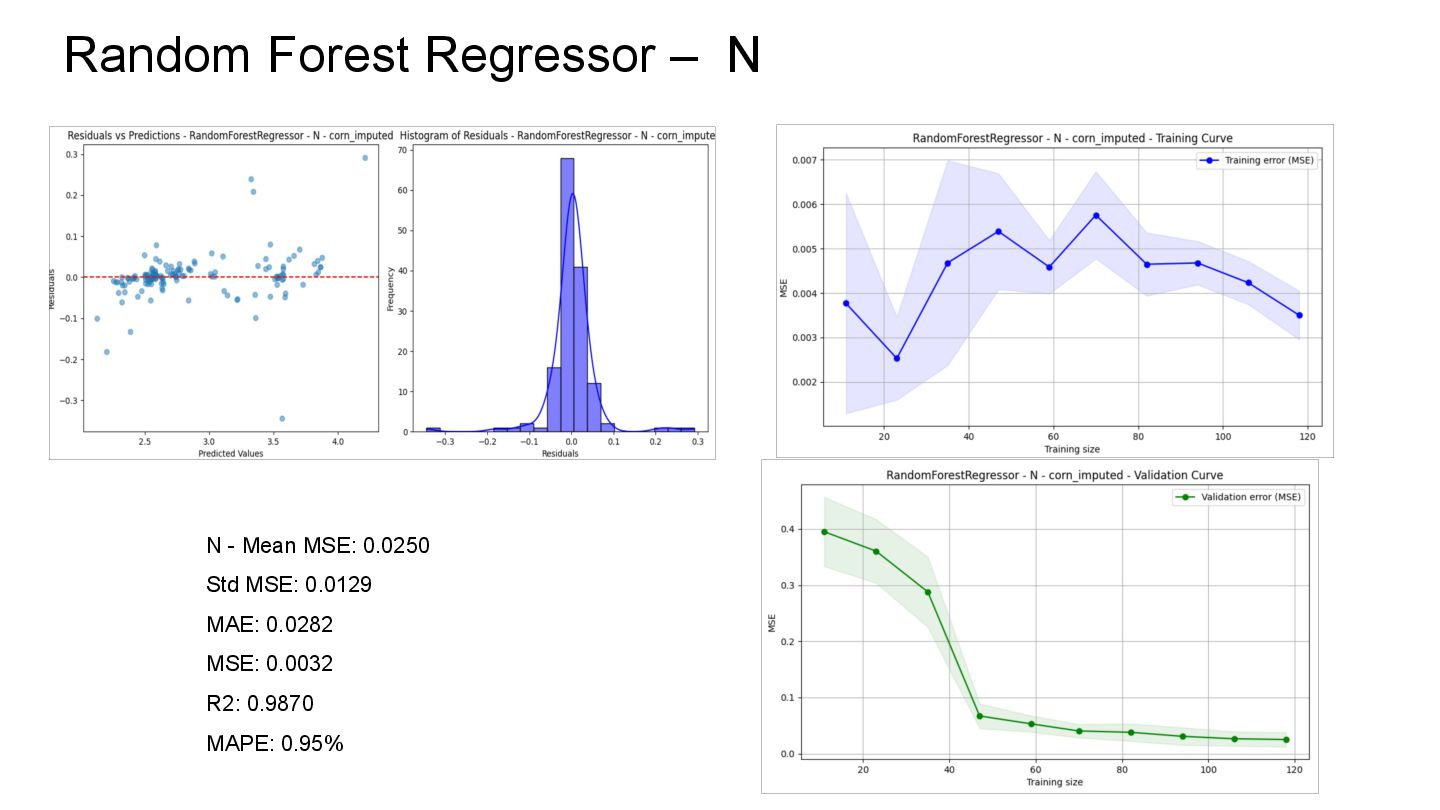
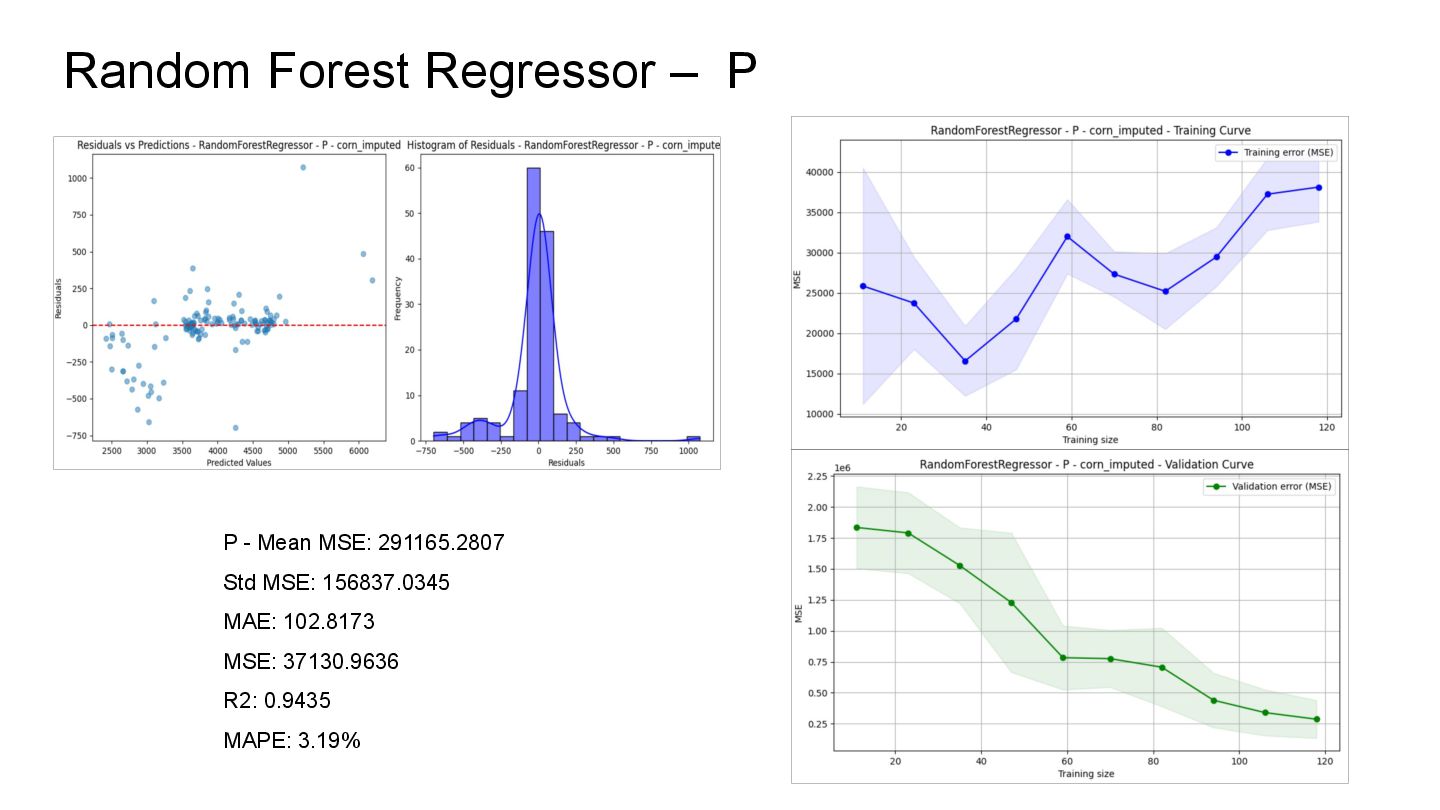
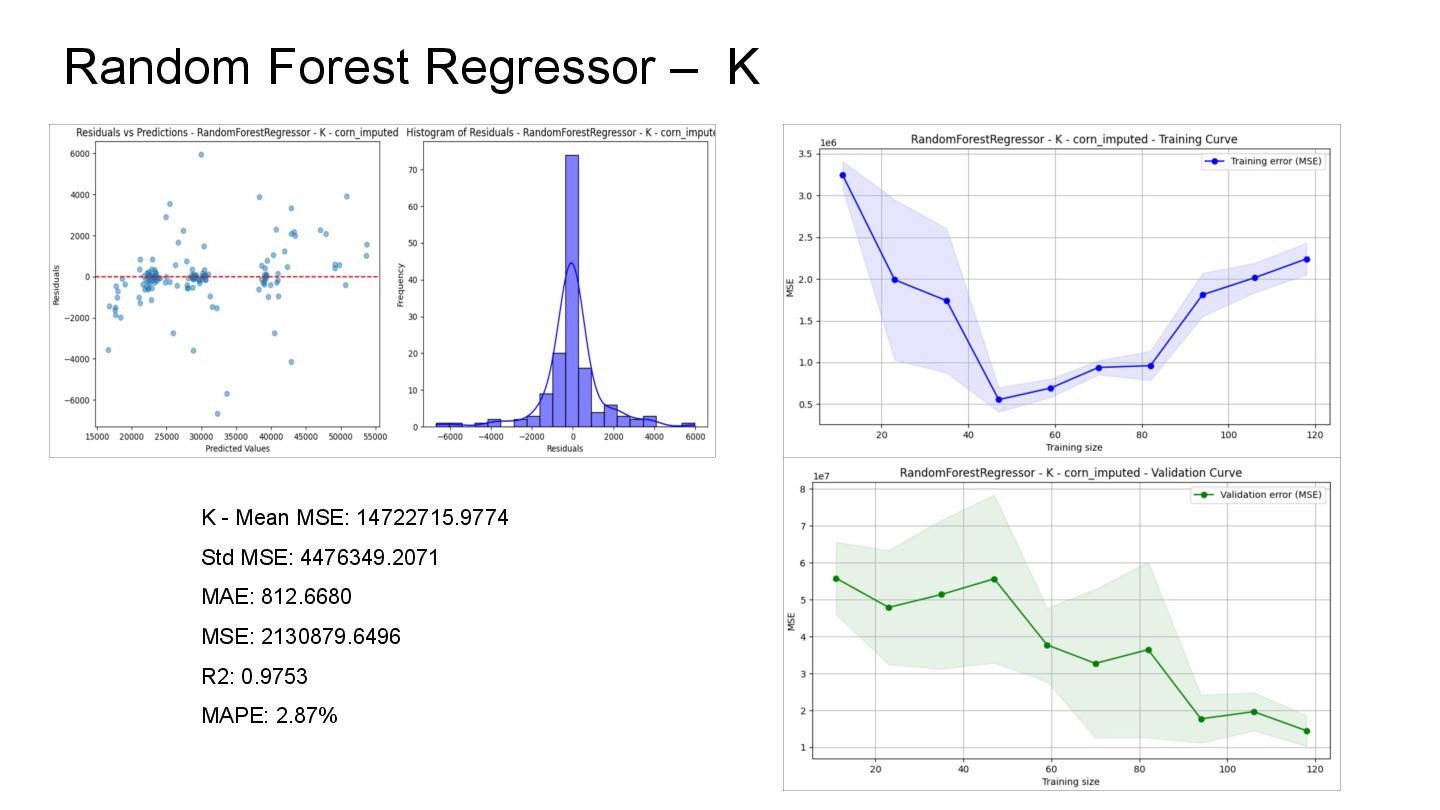
the dataset with fewer missing values than at the beginning. Imputation The result of this process was the complete dataset, without missing values. Database Design Functional, scalable, and accessible database for executing queries as needed. Machine Learning The result shows that the best model applied is Random Forest
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}