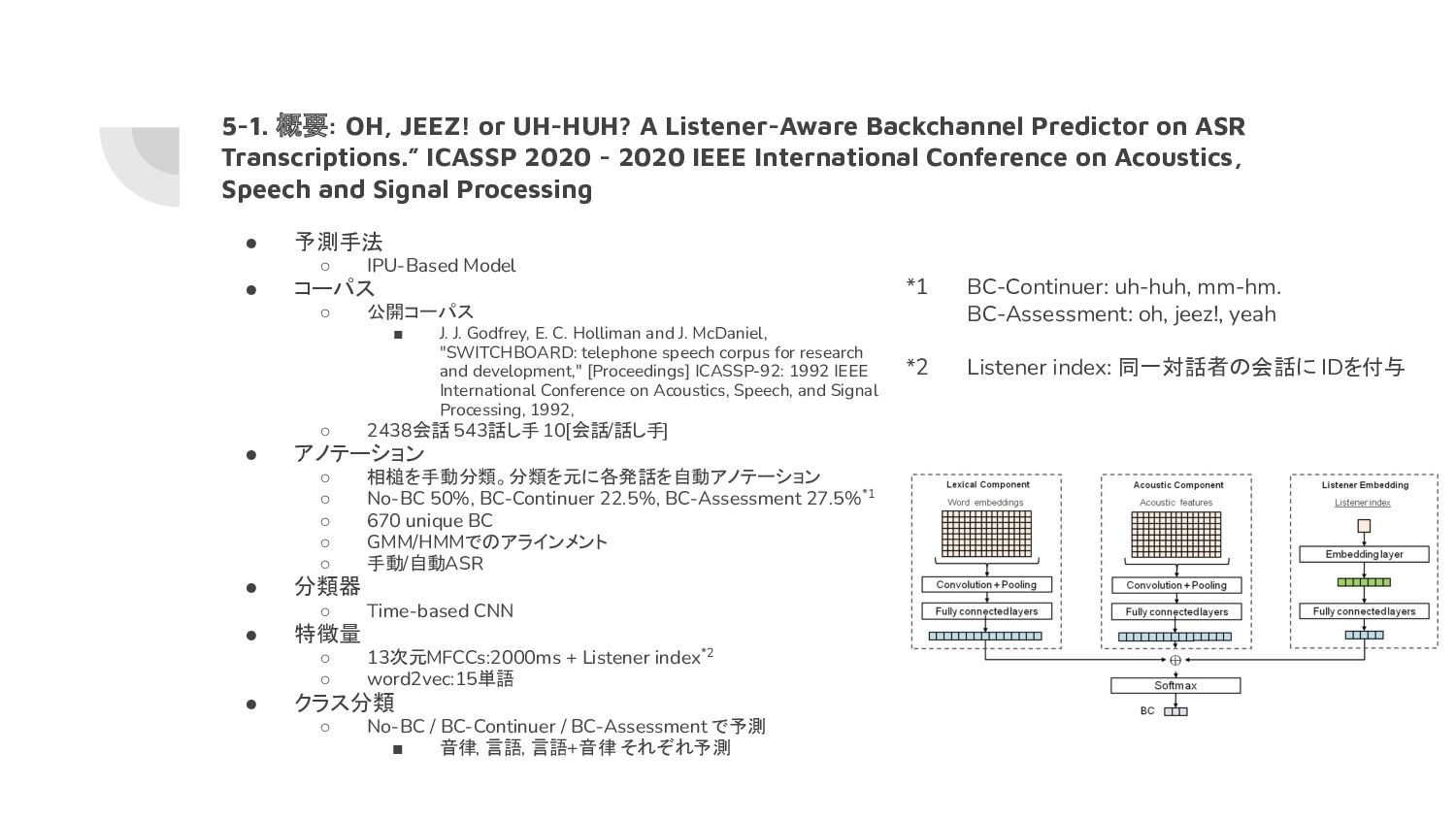
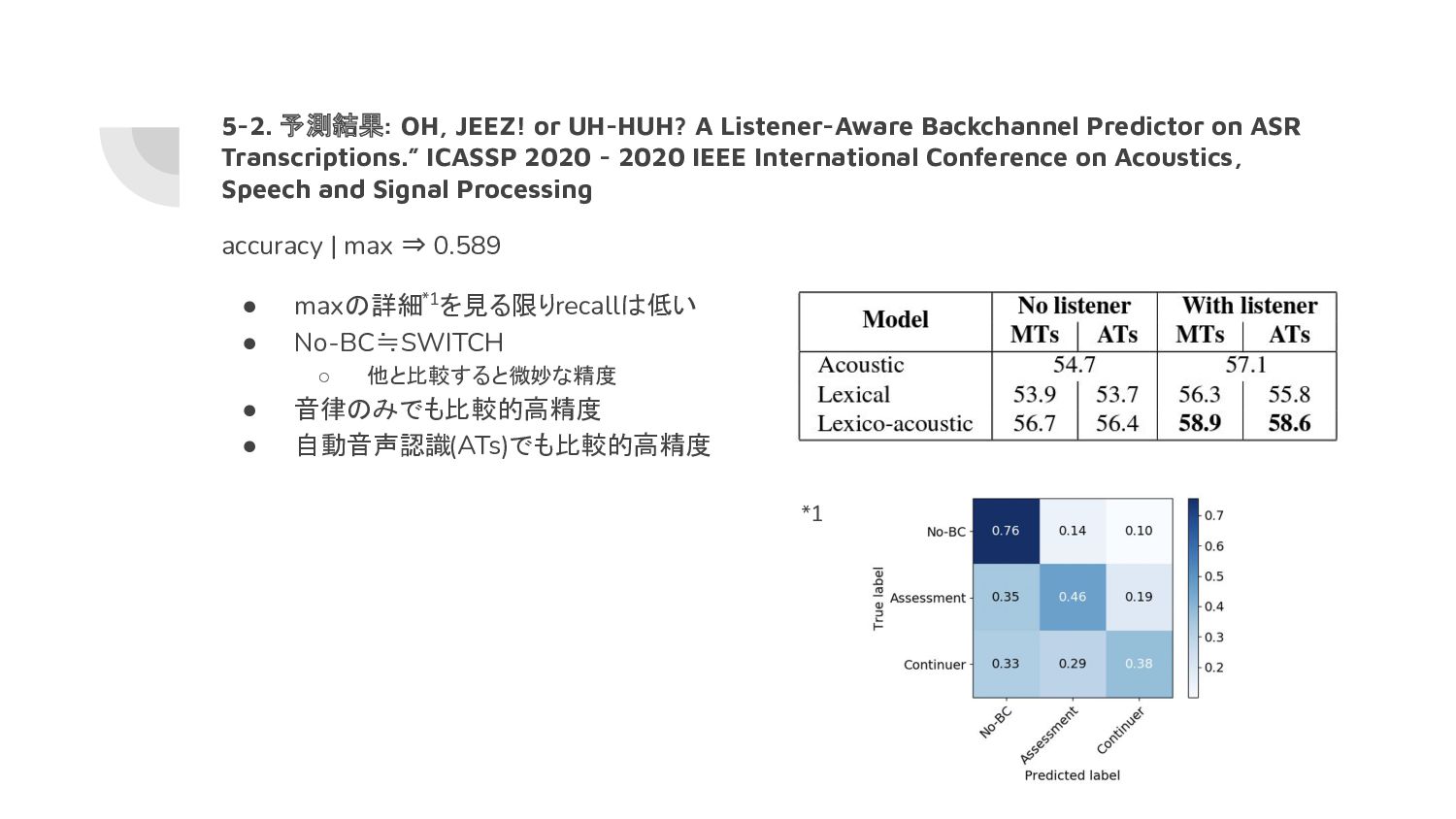
on ASR Transcriptions.” ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing • 予測手法 ◦ IPU-Based Model • コーパス ◦ 公開コーパス ▪ J. J. Godfrey, E. C. Holliman and J. McDaniel, "SWITCHBOARD: telephone speech corpus for research and development," [Proceedings] ICASSP-92: 1992 IEEE International Conference on Acoustics, Speech, and Signal Processing, 1992, ◦ 2438会話 543話し手 10[会話/話し手] • アノテーション ◦ 相槌を手動分類。分類を元に各発話を自動アノテーション ◦ No-BC 50%, BC-Continuer 22.5%, BC-Assessment 27.5%*1 ◦ 670 unique BC ◦ GMM/HMMでのアラインメント ◦ 手動/自動ASR • 分類器 ◦ Time-based CNN • 特徴量 ◦ 13次元MFCCs:2000ms + Listener index*2 ◦ word2vec:15単語 • クラス分類 ◦ No-BC / BC-Continuer / BC-Assessment で予測 ▪ 音律, 言語, 言語+音律 それぞれ予測 *1 BC-Continuer: uh-huh, mm-hm. BC-Assessment: oh, jeez!, yeah *2 Listener index: 同一対話者の会話に IDを付与
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}