지식을 기반으로, 주어진 쿼리에 대해 적절한 응답을 하는 것 ◦ 일반적인 사실 (factoid) 혹은, 주어진 컨텍스트 상의 사실에 대한 질의응답에 초점을 맞춤 • 예시 ◦ Q: 라디오헤드의 보컬 이름은? A: Thom Yorke ◦ Q: 형태소란 무엇인가? A: 언어에서 의미를 갖는 최소 단위 ◦ Q: 왜 하늘은 푸른색일까? A: 파장이 짧은 파란색 빛이 더 크게 산란하기 때문 ◦ Q: 오늘 퇴근하면 뭐할거야? A: 잘거야 ◦ Q: 오늘 저녁 뭐 먹고 싶어? A: 평양냉면
집합으로부터 관련 문서 및 어절을 retrieval해서 문서 내에서 정답에 해당하는 범위 (spans)를 검출 • Knowledge Base QA ◦ 질문 문장을 논리적인 형태로 변환하여 구조화된 지식 베이스로부터 검색 ◦ 예: ‘When was Barack Obama born?’ → birth-year(‘Barack Obama’,?x) ◦ 정확도는 높으나, 오픈 도메인의 경우 매우 큰 지식 베이스가 필요하다는 단점이 존재 • Hybrid QA ◦ 위의 2가지 방법을 혼합하여 사용 ◦ IBM’s Watson의 DeepQA 시스템이 대표적인 예 ◦ 지식 베이스 및 IR-retrieval 각각을 통해 후보 응답들을 추출하고, 후보들을 리랭킹
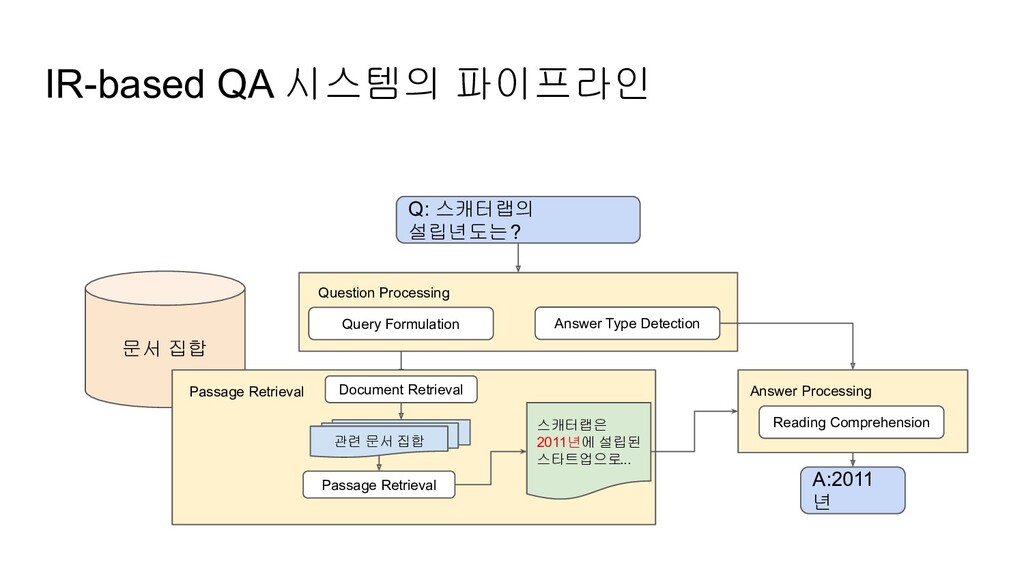
Processing Query Formulation Answer Type Detection A:2011 년 Passage Retrieval Document Retrieval 관련 문서 집합 Passage Retrieval 스캐터랩은 2011년에 설립된 스타트업으로... Answer Processing Reading Comprehension
과정 • query formulation: 더 정확한 정보를 인덱싱하기 위해 질문문을 쿼리로 변환 ◦ ‘경기도에서 어떤 도시의 인구가 제일 많나요?’ → ‘경기도에서 인구가 제일 많은 도시’ ◦ hand-written rules ▪ wh-word did A verb B?→A verb+ed B ◦ 번역과 유사한 형태의 Data-driven rewriting 등등 ... • answer type: 답변의 타입을 판별 ◦ (사람, 위치, 시간) 등과 같은 엔티티일 수도 있고, 정의 (definition), 이유 등의 타입이 될 수도 있음 ◦ answer type의 집합을 설정하고 hand-written rules나 machine learning-based 방법을 이용하여 쿼리에 대한 answer type을 판별 • 그 밖에도, question type 판별 및 focusing word 판별 등을 위한 다양한 서브 모듈이 추가될 수 있음
검색 후, 관련 문서로부터 관련 passage를 검색하는 과정 • 문서가 passage 단위로 분할되어 있지 않은 문서라면 passage segmentation 알고리즘이 요구됨 • 룰 베이스 및 머신러닝 모델 등을 이용하여 필터링 ◦ 사용될 수 있는 features ▪ 답변 타입에 알맞는 named entities ▪ question keywords (focusing words)의 수 ▪ n-grams overlap ▪ pos ▪ tf-idf 등
찾는 방식으로 모델링 • 가장 심플한 베이스라인 수법은 후보 passages들에 NER을 돌려서 answer type과 일치하는 단어들을 추출하고 각종 프로세싱으로 후보들을 줄여나가는 방식 ◦ 그러나, 정의 질문 등과 같은 경우는 이러한 방법을 적용하기 어려움 • Feature-based 방식 ◦ 답변 타입 매치, 패턴 매치 등의 각종 피쳐를 이용하여 모델을 학습 • Neural Answer Extraction ◦ SQuAD로 대표되는 태스크 ◦ BERT, XL-net 등등…
변환하는게 룰베이스로는 한계가 있을 거고 ◦ answer type을 식별하려면 NER도 필요할거고, 질문의 Intent도 알아야 할거고… • Passage Retrieval ◦ Web처럼 매우 큰 문서 집합에서 빠른 검색을 하려면 효율적인 검색 방법이 필요할테고 ◦ 정확한 검색을 위해서는 리랭킹 같은 테크닉도 사용될테고 ◦ Passage Segmentation을 해야될 경우도 있을테고 • Answer Processing ◦ Passage의 의미를 파악하려면 충분히 긴 컨텍스트에 대한 Machine Comprehension 능력이 요구되겠지...
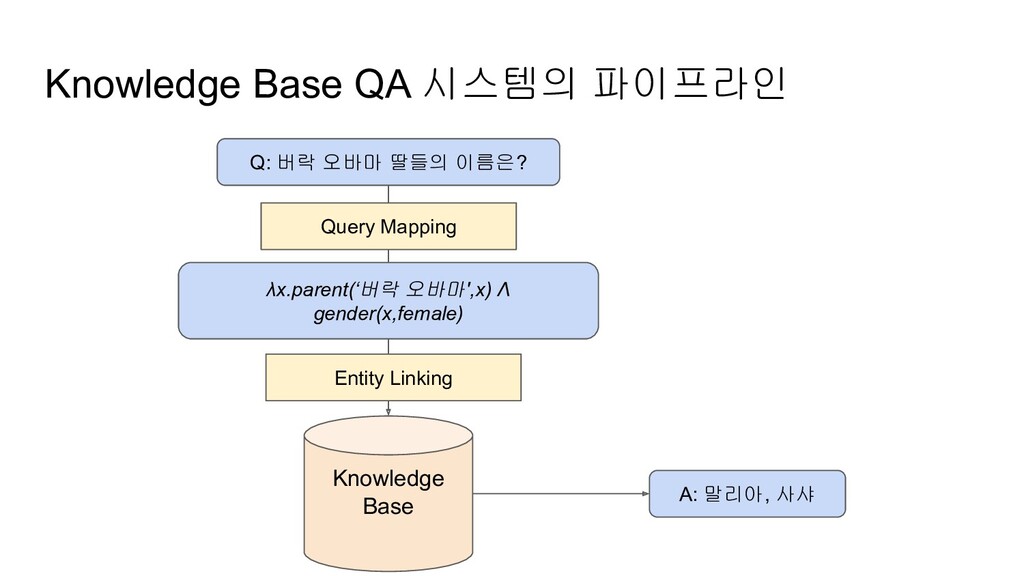
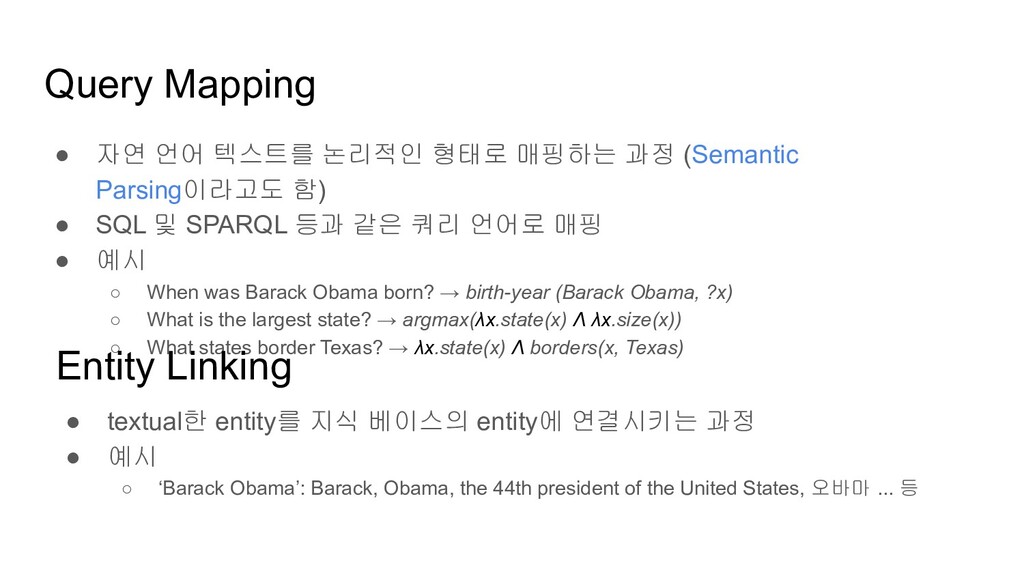
(Semantic Parsing이라고도 함) • SQL 및 SPARQL 등과 같은 쿼리 언어로 매핑 • 예시 ◦ When was Barack Obama born? → birth-year (Barack Obama, ?x) ◦ What is the largest state? → argmax(λx.state(x) Λ λx.size(x)) ◦ What states border Texas? → λx.state(x) Λ borders(x, Texas) Entity Linking • textual한 entity를 지식 베이스의 entity에 연결시키는 과정 • 예시 ◦ ‘Barack Obama’: Barack, Obama, the 44th president of the United States, 오바마 ... 등
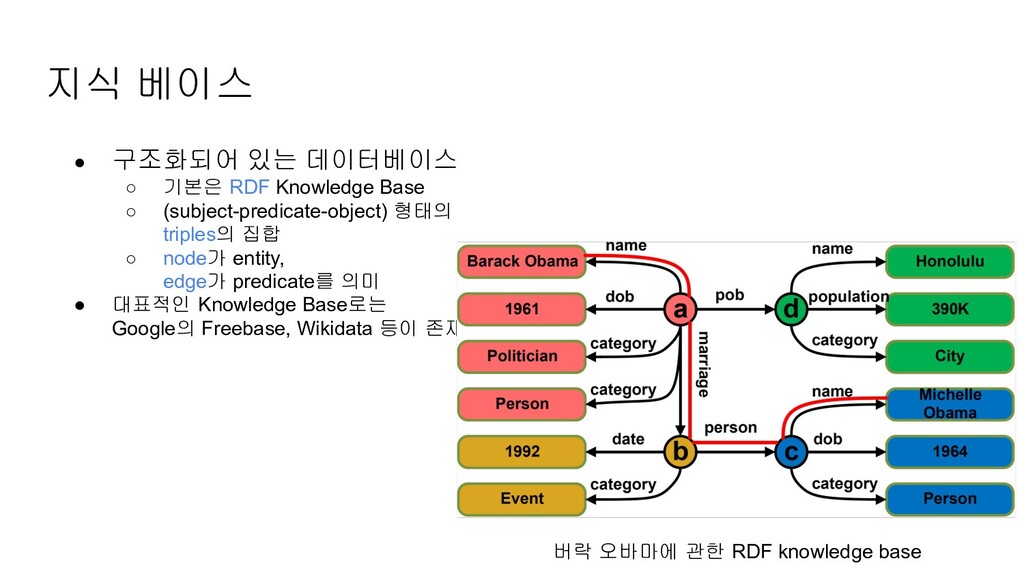
Base ◦ (subject-predicate-object) 형태의 triples의 집합 ◦ node가 entity, edge가 predicate를 의미 • 대표적인 Knowledge Base로는 Google의 Freebase, Wikidata 등이 존재 버락 오바마에 관한 RDF knowledge base
자연언어 형태의 문장은 한 가지 문장이 여러가지 쿼리로 변환될 수도 있고 여러 문장이 한 가지 쿼리로 변환되기도 함→ 따라서, many-to-many에 해당하는 태스크 ◦ 이걸 잘하려면, NER도 필요할거고, dependency parsing도 필요할거고… • Entity Linking ◦ 이 태스크 역시 many-to-many에 해당됨 ◦ (Michael Jordan, Michael, Jordan) ↔ (Michael J. Jordan (농구선수), Michael I. Jordan (정치가)) • Knowledge Base ◦ 복수 도메인의 지식 베이스를 혼합하여 사용한다거나 ◦ 지식이 생기면, Real-time으로 지식 베이스에 지식을 추가하여 지식 베이스를 확장한다거나
방식이 일반적으로 Precision은 높은 편이지만, 오픈 도메인 지식 베이스가 구축되어야 하므로 개발 코스트가 큼 ◦ IR-based를 서비스에 사용하기 위해선 검색 코스트를 해결해야 함 • QA 시스템의 응용 ◦ factoid 질문에 대한 답변 ◦ 구체적인 답변 ◦ 상식을 담거나 이해하는 답변 • 요구되는 기술들 ◦ factoid 질문/일반 대화 판별 모듈 (IDOOD 비슷한 느낌의) ◦ retrieval된 지식을 핑퐁 답변에 녹여내기 위한 프로세싱 ◦ QA 시스템을 만들기 위해서는 Gunrock과 같은 대화 모델처럼 다양한 프로세싱이 전제되어야 하므로 각종 모듈들을 채워넣는 것이 우선이 아닐까?
Improving Question Answering Systems by Query Reformulation and Answer Validation (2008, World Academy of Science, Engineering and Technology) ◦ Real-Time Open-Domain Question Answering with Dense-Sparse Phrase Index (2019, ACL) • Knowledge Base ◦ A Joint Model for Question Answering over Multiple Knowledge Bases (2016, AAAI) ◦ Deep Learning Approaches for Question Answering on Knowledge Bases: an evaluation of architectural design choices (2018, arXiv) ◦ Modeling Semantics with Gated Graph Neural Networks for Knowledge Base Question Answering (2018, COLING) ◦ KBQA: Learning Question Answering over QA Corpora and Knowledge Bases (2019, VLDB) ◦ Knowledge Base Question Answering via Encoding of Complex Query Graphs (2018, EMNLP)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}