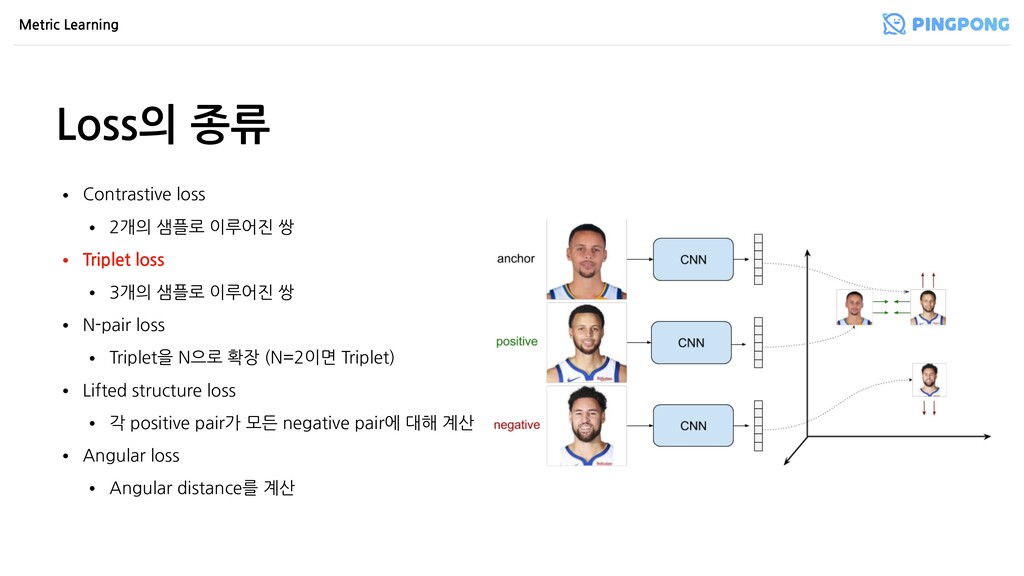
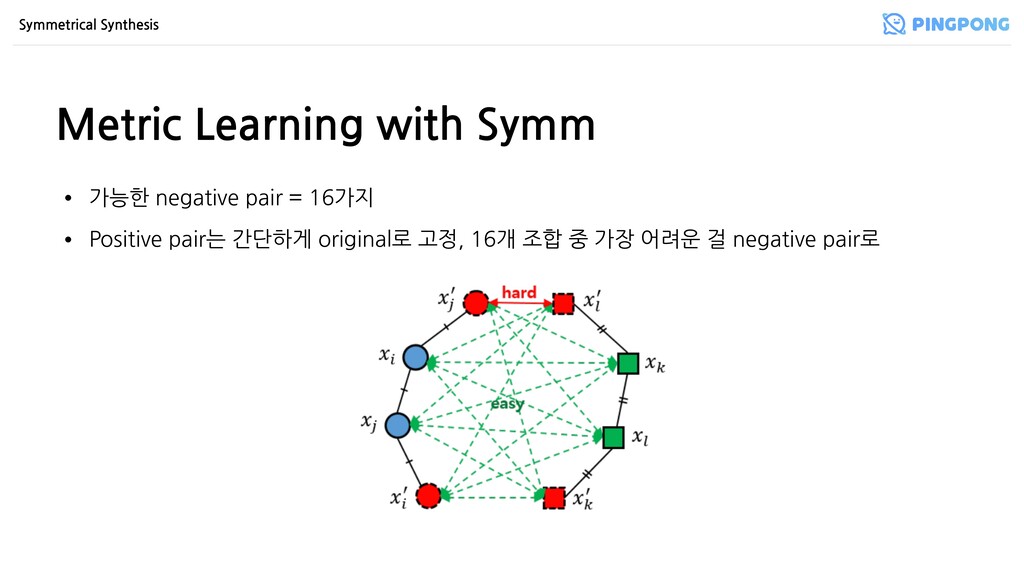
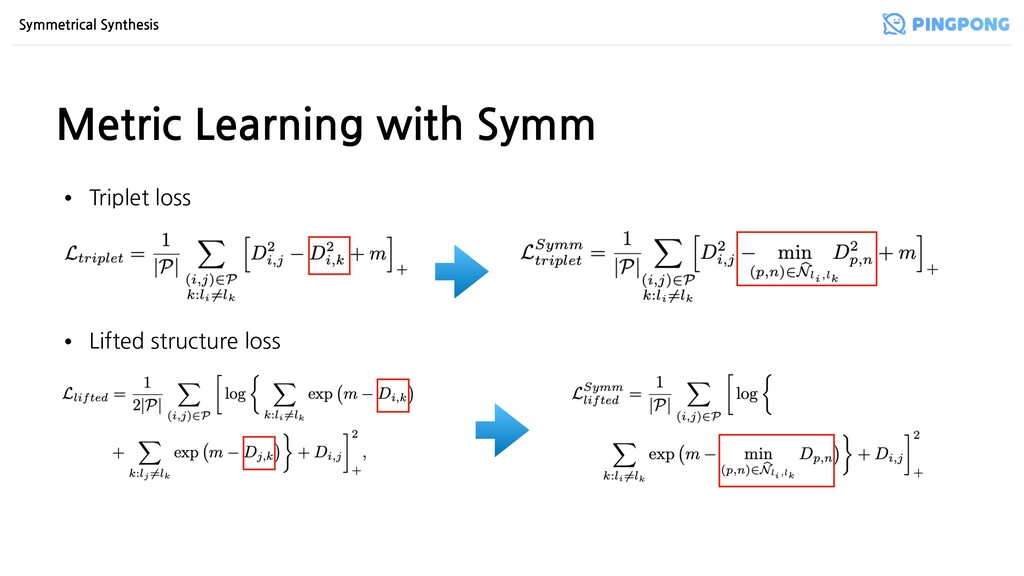
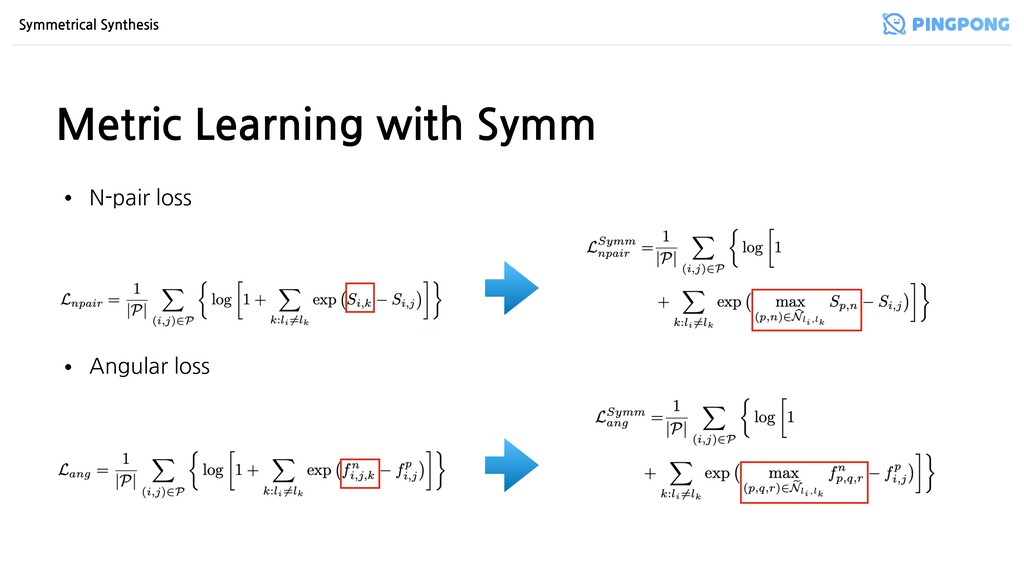
이루어진 쌍 • Triplet loss • 3개의 샘플로 이루어진 쌍 • N-pair loss • Triplet을 N으로 확장 (N=2이면 Triplet) • Lifted structure loss • 각 positive pair가 모든 negative pair에 대해 계산 • Angular loss • Angular distance를 계산
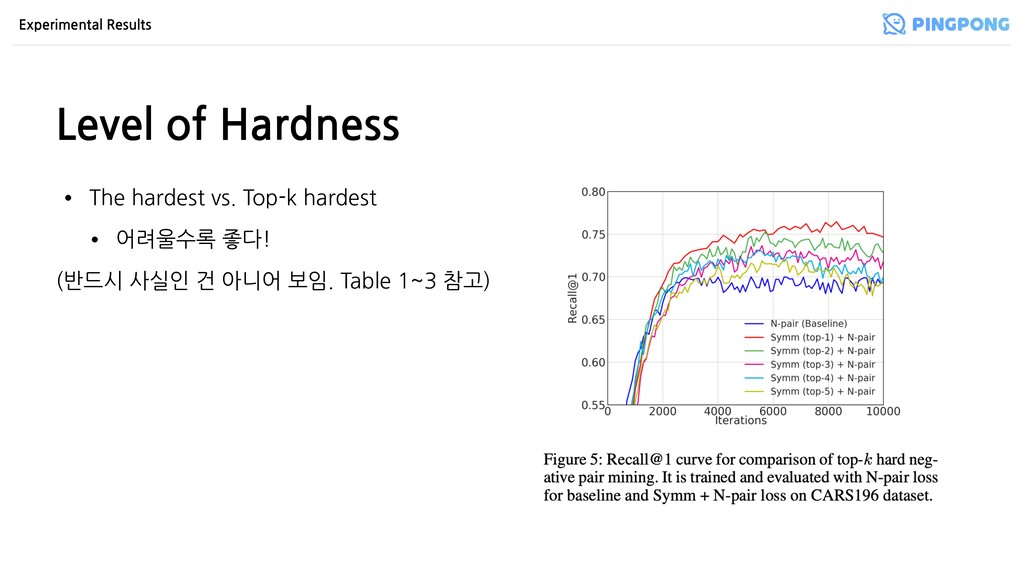
학습된 모델이 고른 hard negative에 대해 iterative fine-tune • Online • 배치 별로 가장 어려운(hardest) P-N pair 선택 • Semi-hard • 너무 어려우면 오히려 noise가 될 수 있으니 적당히 어려운 걸 고르자 문제: 선택된 소수의 샘플만 고려하므로 bias가 생길 가능성
이용해 hard negative를 직접 생성 • Deep adversarial metric learning (DAML) • GAN을 사용해 hard negative, hard triplet 생성 • Hardness-aware deep metric learning (HDML) • AE 사용해 P-P or N-N 샘플 만들고 난이도 조절 가능 문제: 추가적인 네트워크 구조 필요 → 학습 시간↑, GAN은 학습도 어려움
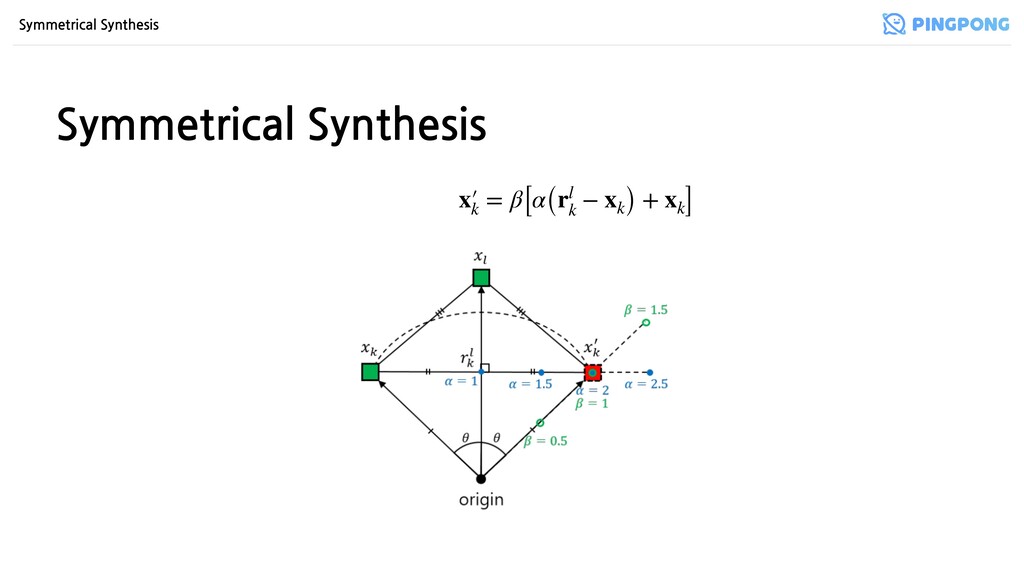
간 Euclidean distance, Cosine similarity 불변 ( ) → Loss의 positive 부분에 영향 X 2. Synthetic은 original과 norm이 항상 같음 → -normalize (Triplet): synthetic도 동일한 hyper-sphere 상에 위치 → non -normalize (N-pair, Angular): 유클리드 공간 상에서 norm이 같음 xk ↔ xl = x′ k ↔ xl = xk ↔ x′ l l2 l2
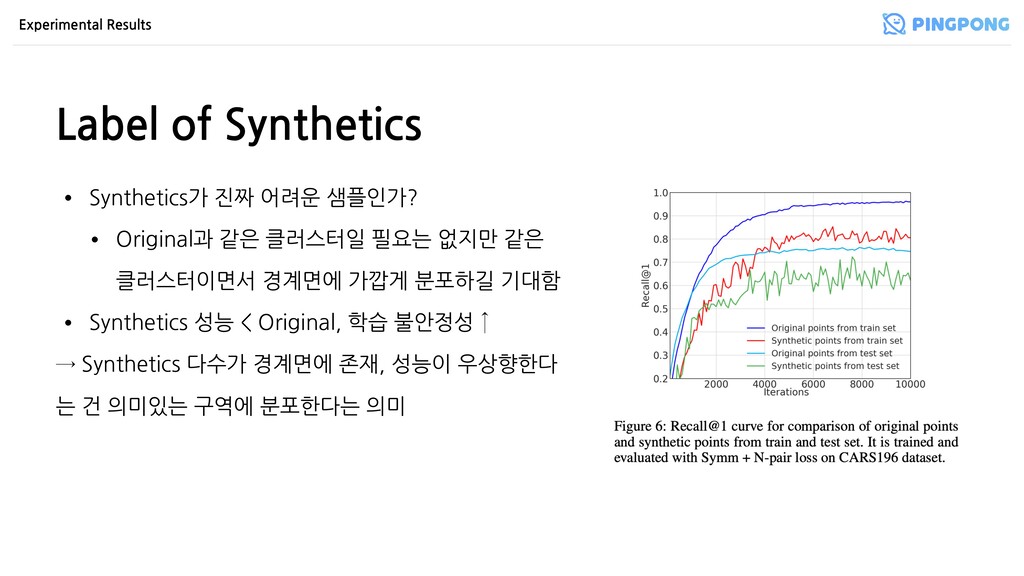
• Original과 같은 클러스터일 필요는 없지만 같은 클러스터이면서 경계면에 가깝게 분포하길 기대함 • Synthetics 성능 < Original, 학습 불안정성 ↑ → Synthetics 다수가 경계면에 존재, 성능이 우상향한다 는 건 의미있는 구역에 분포한다는 의미
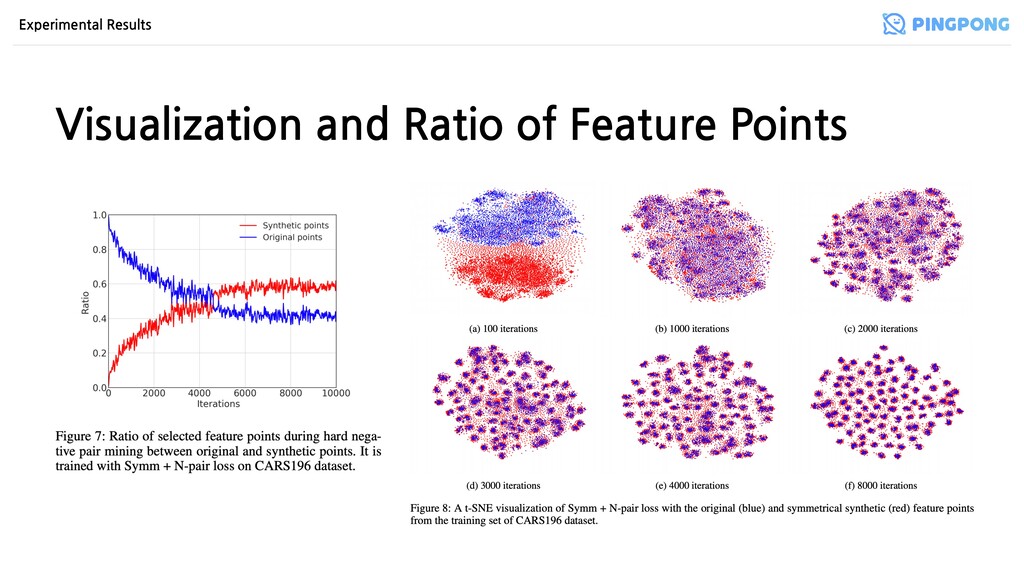
진행될수록 생성된 샘플이 negative sample로 선택되는 비율 • 학습 과정 시각화 by t-SNE → 처음에는 같은 클래스 샘플끼리 가깝지 않으니 의미 없는 synthetics가 만들어지다가 점점 클러 스터 경계면에 분포하도록 만들어지면서 hard negative의 역할을 함
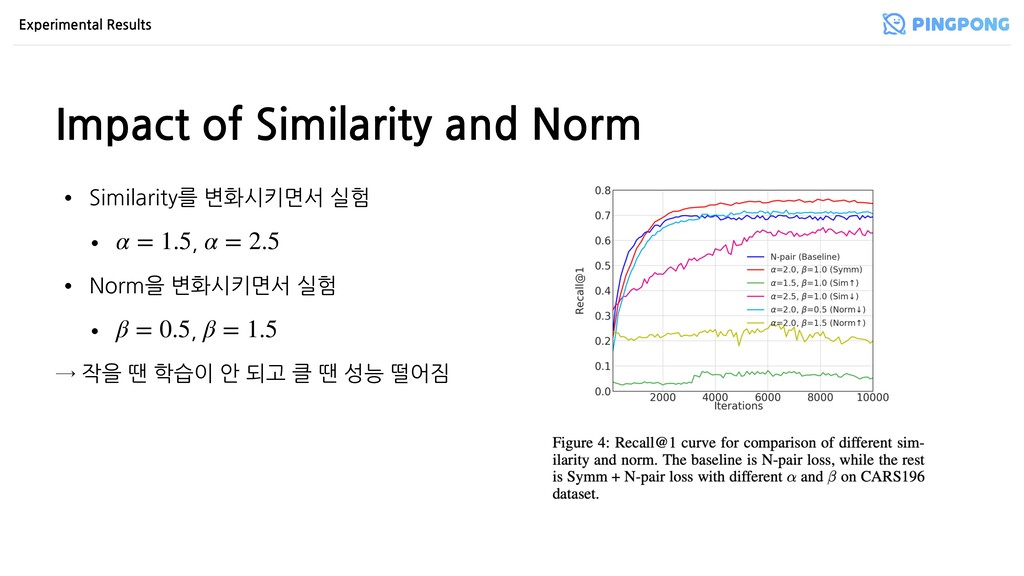
더 좋은 성능 → Euclidean + normalization을 하는 loss (triplet, lifted structure)와 Cos-sim + non- 인 loss (N-pair, angular)에 모두 적용 가능 • 다른 sample generation 방식(DAML, HDML)은 큰 데이터셋(SOP)에서 성능 향상폭 ↓ → 반면 Symm은 데이터셋 크기에 상관 없이 성능 향상폭 ↑ (심지어 CARS196에서 HDML이 이긴 것도 공정한 비교를 위해 하이퍼파라미터 튜닝을 안 했기 때문) l2 l2
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}