Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Unified Language Model Pre-training for Natural...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Scatter Lab Inc.
April 10, 2020
Research
2.3k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Unified Language Model Pre-training for Natural Language Understanding and Generation
Scatter Lab Inc.
April 10, 2020
More Decks by Scatter Lab Inc.
See All by Scatter Lab Inc.
zeta introduction
scatterlab
0
1.9k
SimCLR: A Simple Framework for Contrastive Learning of Visual Representations
scatterlab
0
4.4k
Adversarial Filters of Dataset Biases
scatterlab
0
2.3k
Sparse, Dense, and Attentional Representations for Text Retrieval
scatterlab
0
2.3k
Weight Poisoning Attacks on Pre-trained Models
scatterlab
0
2.2k
Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval
scatterlab
0
2.6k
Beyond Accuracy: Behavioral Testing of NLP Models with CheckList
scatterlab
0
2.3k
Open-Retrieval Conversational Question Answering
scatterlab
0
2.3k
What Can Neural Networks Reason About?
scatterlab
0
2.3k
Other Decks in Research
See All in Research
PGDM: Physically Guided Diffusion Model for L Downscaling
satai
3
350
(SIGQS17) Frasco-VS:フラグメントに基づく薬剤候補化合物選抜の量子アニーリングによる実現
keisukeyanagisawa
PRO
0
160
長時間動画QAにおけるマルチエージェント推論 ・SVAgent: Storyline-Guided Long Video Understanding via Cross-Modal Multi-Agent Collaboration
murakawatakuya
1
160
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
shunk031
4
1.1k
Sequences of Logits Reveal the Low Rank Structure of Language Models
sansantech
PRO
1
280
ScoreMatchingRiesz for Automatic Debiased Machine Learning and Policy Path Estimation with an Application to Japanese Monetary Policy Evaluation
masakat0
0
300
Cross-Media Human-Information Interaction
signer
PRO
0
120
重要だけど測れていないもの:高齢者ケアの見えない課題
theoriatec2024
0
410
National high-resolution cropland classification of Japan with agricultural census information and multi-temporal multi-modality datasets
satai
3
370
業界横断 副業コンプライアンス調査 三者(副業者・本業先・発注者)におけるトラブル認知ギャップの構造分析
fkske
0
1.3k
【中間報告】国会議員の立法・政策実務を支える環境を巡る現状と課題
polipoli
0
310
LLM Compute Infrastructure Overview
karakurist
2
1.5k
Featured
See All Featured
Digital Ethics as a Driver of Design Innovation
axbom
PRO
1
340
How GitHub (no longer) Works
holman
316
150k
Un-Boring Meetings
codingconduct
0
350
How To Speak Unicorn (iThemes Webinar)
marktimemedia
1
510
No one is an island. Learnings from fostering a developers community.
thoeni
21
3.8k
Leveraging Curiosity to Care for An Aging Population
cassininazir
1
390
Responsive Adventures: Dirty Tricks From The Dark Corners of Front-End
smashingmag
254
22k
Claude Code のすすめ
schroneko
67
230k
Speed Design
sergeychernyshev
33
1.9k
Site-Speed That Sticks
csswizardry
13
1.3k
Docker and Python
trallard
47
4k
ピンチをチャンスに:未来をつくるプロダクトロードマップ #pmconf2020
aki_iinuma
128
56k
Transcript
Unified Language Model Pre-training for Natural Language Understanding and Generation
Li Dong et al., NeurIPS 2019 (Microsoft) ࢲ࢚ (ML Research Scientist, Pingpong)
ݾର ݾର 1. Pre-training Language Model ѐਃ 2. Unified Language
Model 1. Method 2. Pre-training step 3. Fine-tuning step 3. Experiments 1. NLG Task 2. NLU Task
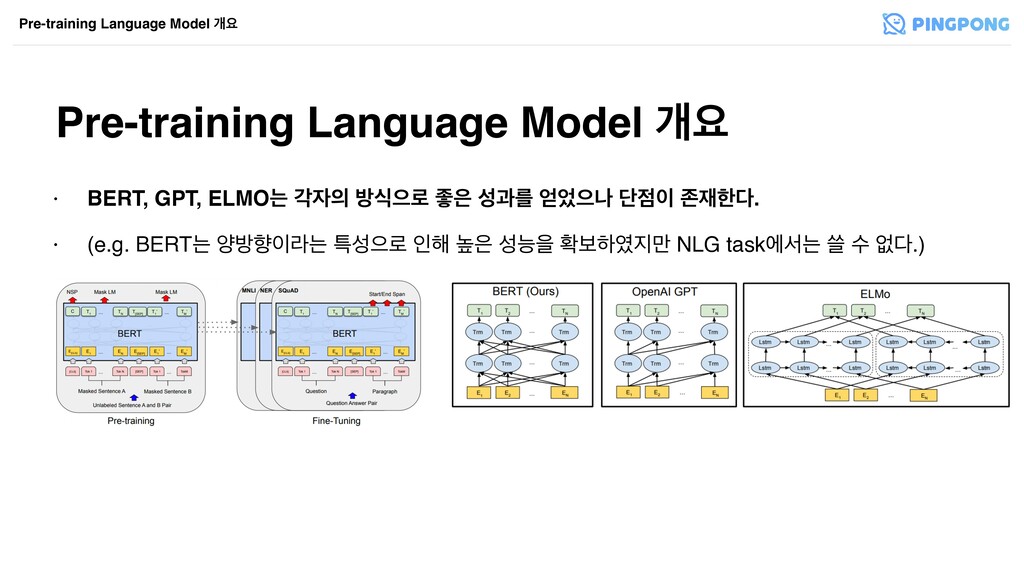
Pre-training Language Model ѐਃ Pre-training Language Model ѐਃ
Pre-training Language Model ѐਃ Pre-training Language Model ѐਃ • BERT,
GPT, ELMOח п ߑधਵ۽ જ ࢿҗܳ ਵա ױ ઓೠ. • (e.g. BERTח নߑೱۄח ౠࢿਵ۽ ੋ೧ ֫ ࢿמਸ ഛࠁೞ݅ NLG taskীࢲח ॶ ࣻ হ.)
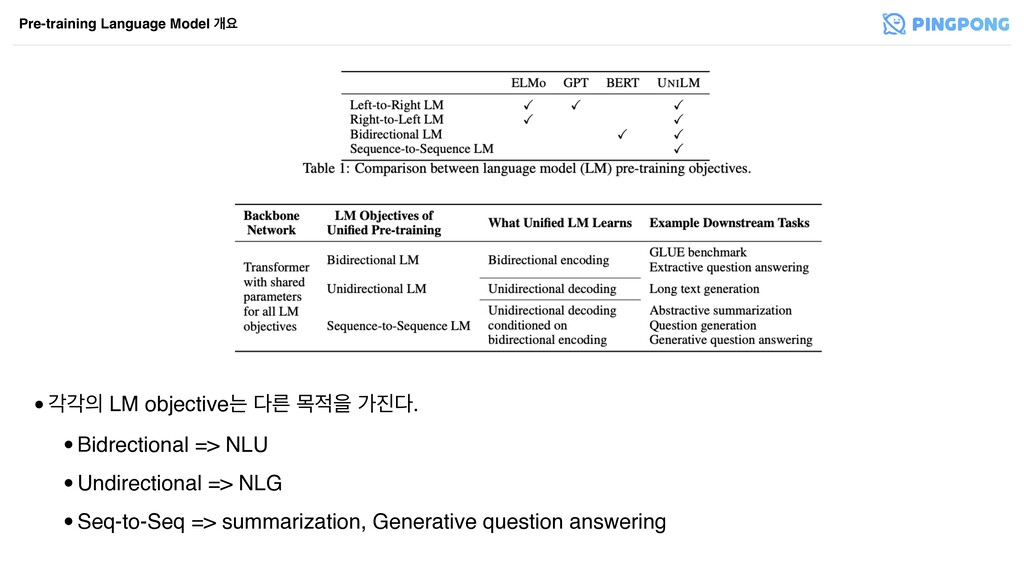
•пп LM objectiveח ܲ ݾਸ о. •Bidrectional => NLU •Undirectional
=> NLG •Seq-to-Seq => summarization, Generative question answering Pre-training Language Model ѐਃ
Unified Language Model Pre-training Language Model ѐਃ
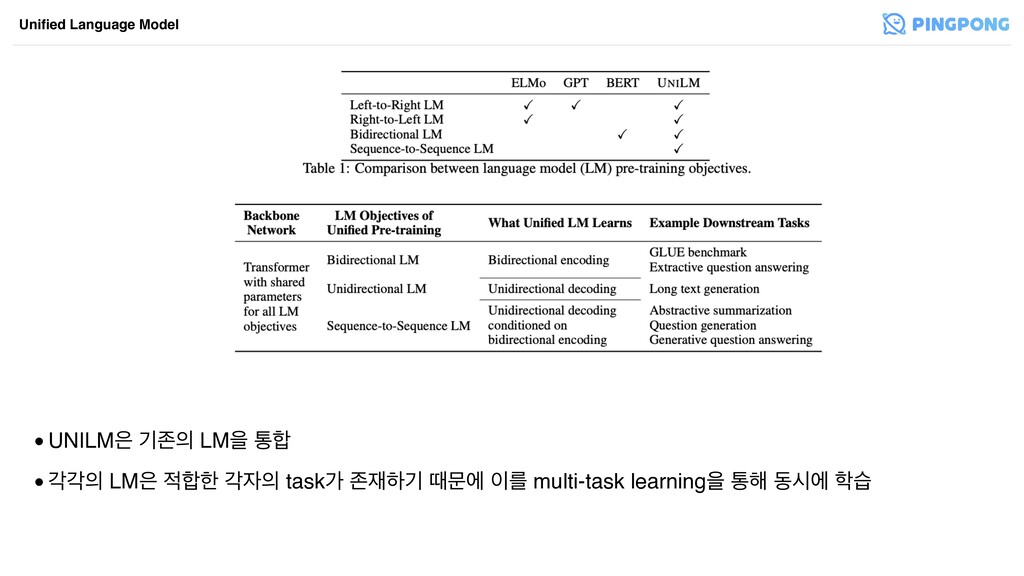
Unified Language Model Unified Language Model •unified pre-training ৈ۞ ఋੑ
LMਸ ਤೠ parameterܳ ҕਬೞӝ ٸޙী single transformer݅ ਸ ਃ۽ ೞҊ ৈ۞ LMܳ ߹ب णೡ ਃо হ. •parameter ҕਬо text അਸ ખ ؊ general ೞѱ णೡ ࣻ ѱ ೠ. (زदী optimizeೞӝ ٸ ޙী single LMী ೞৈ ؏ overfitting) •NLU৬ NLG ܳ زदী ࢎਊ оמ
•UNILM ӝઓ LMਸ ా •пп LM ೠ п taskо ઓೞӝ
ٸޙী ܳ multi-task learningਸ ా೧ زदী ण Unified Language Model
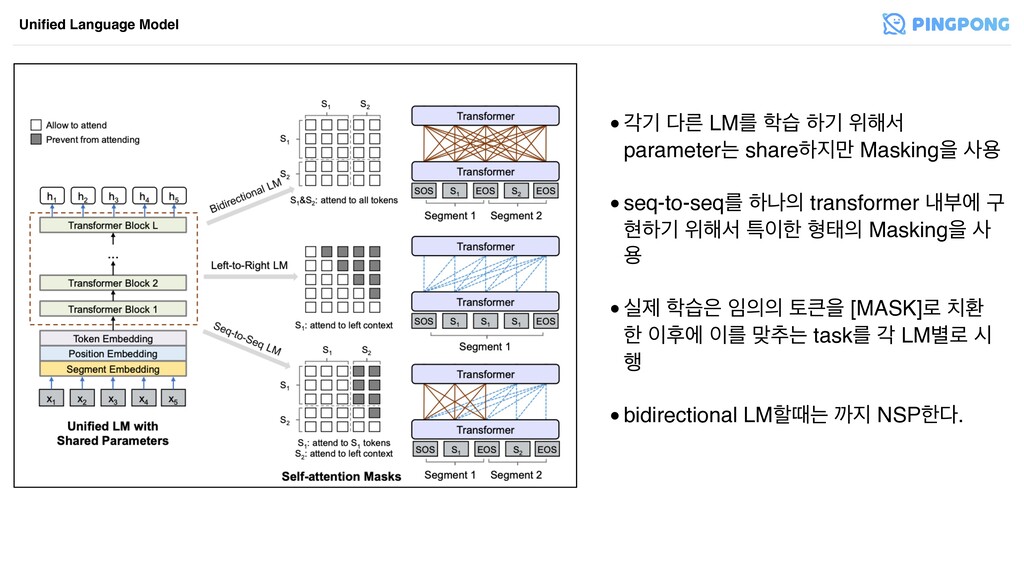
•пӝ ܲ LMܳ ण ೞӝ ਤ೧ࢲ parameterח shareೞ݅ Maskingਸ ࢎਊ
•seq-to-seqܳ ೞա transformer ղࠗী ҳ അೞӝ ਤ೧ࢲ ౠೠ ഋక Maskingਸ ࢎ ਊ •पઁ ण షਸ [MASK]۽ ജ ೠ റী ܳ ݏ୶ח taskܳ п LM߹۽ द ೯ •bidirectional LMೡٸח ө NSPೠ. Unified Language Model
•[SOS]ח scpecial start-of-sequence •[EOS]ח NLU task ޙ ҃҅ scpecial end-of-sequence
•Embedding BERTܳ ٮܰݴ textח WordPieceܳ ా೧ tokenize •пп LM task߹۽ ܲ segment embedding ࢎਊػ. Unified Language Model
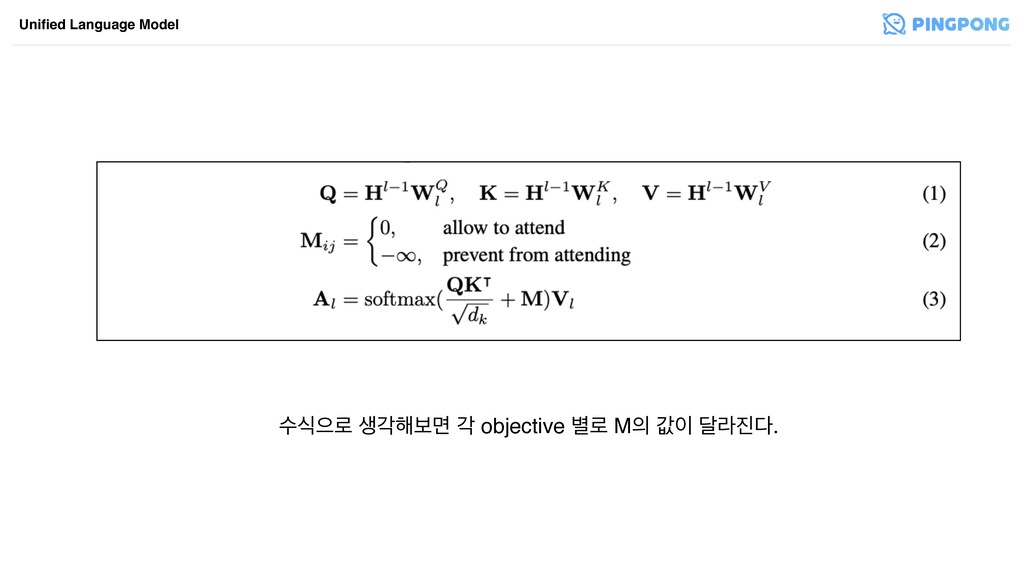
ࣻधਵ۽ ࢤп೧ࠁݶ п objective ߹۽ M ч ׳ۄ. Unified Language
Model
Pre-training Setup Unified Language Model • training objectiveח п LM
sum •ೞա ߓ ղীח নߑೱ LM objectiveܳ 1/3, द௫झ-द௫झ LM objectiveܳ 1/3, left-to- right and right-to-left LM objectiveח 1/6 ࠺ਯ۽ ࢠ݂ • ۄఠח BERT_largre۽ ୡӝച •pre-trainingীח English Wikipedia2৬ BookCorpusܳ ࢎਊ
Pre-training Setup Unified Language Model •vocabulary size is 28, 996,
maximum length of input sequence is 512, batch size 330 •15% tokenਸ ࣁ о case ೞա۽ ജ • 80% ҃ : tokenਸ [MASK]۽ ജ •10% ҃ : tokenਸ random word۽ ߄Է •10% ҃ : tokenਸ ਗې ױয۽ Ӓ۽ م •݃झఊ दఃח ߑߨ BERTی Ѣ زੌೞա ೞաо ୶оػ Ѫ 80%ח ݒߣ ೞա షਸ ݃झఊೞҊ 20%ח bigramա trigramਸ ݃झఊೠ. •770, 000 stepө ण೮Ҋ 7 hoursبݶ 1݅ stepب ت ( 8ѐ V100ীࢲ)
Fine-tuning on Downstream NLU and NLG Tasks Unified Language Model
•NLUীࢲ fine-tuning दীח [SOS] షਸ representationਵ۽ ࢎਊ ( BERT [CLS] ৬ زੌ ) •NLGܳ fine-tuning दীח target sequenceী ೠ maskingਸ ೞҊ ݏ୶ח taskܳ ೯ೠ. • җীࢲ [EOS] ژೠ ਕ ࣻ ӝ ٸޙী ݽ؛ ઁ [EOS]ܳ ஏ೧ঠ ೞחب ߓ ࣻ Ҋ ೠ.
Experiments Experiments
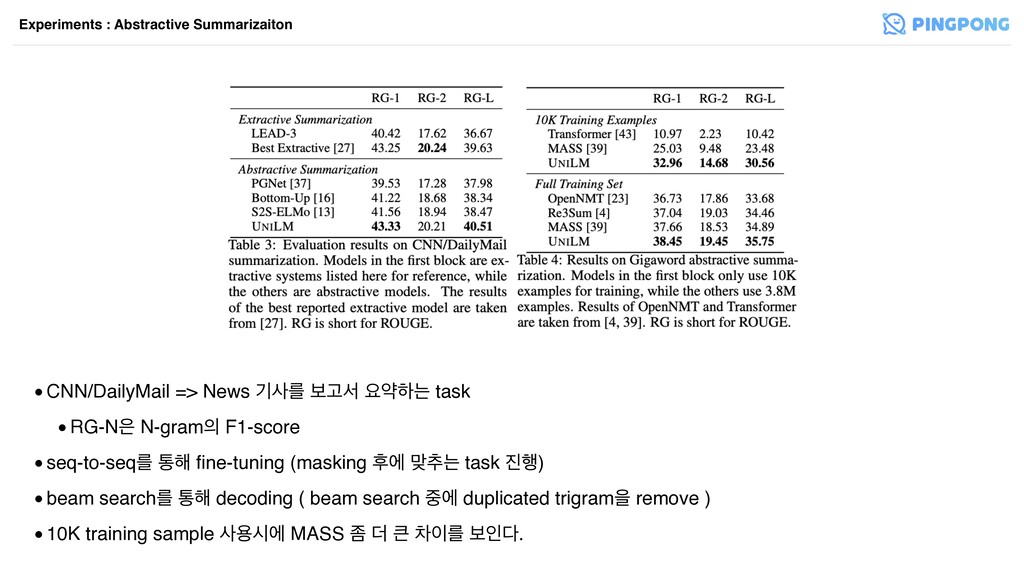
•CNN/DailyMail => News ӝࢎܳ ࠁҊࢲ ਃডೞח task •RG-N N-gram F1-score
•seq-to-seqܳ ా೧ fine-tuning (masking റী ݏ୶ח task ೯) •beam searchܳ ా೧ decoding ( beam search ী duplicated trigramਸ remove ) •10K training sample ࢎਊदী MASS ખ ؊ ରܳ ࠁੋ. Experiments : Abstractive Summarizaiton
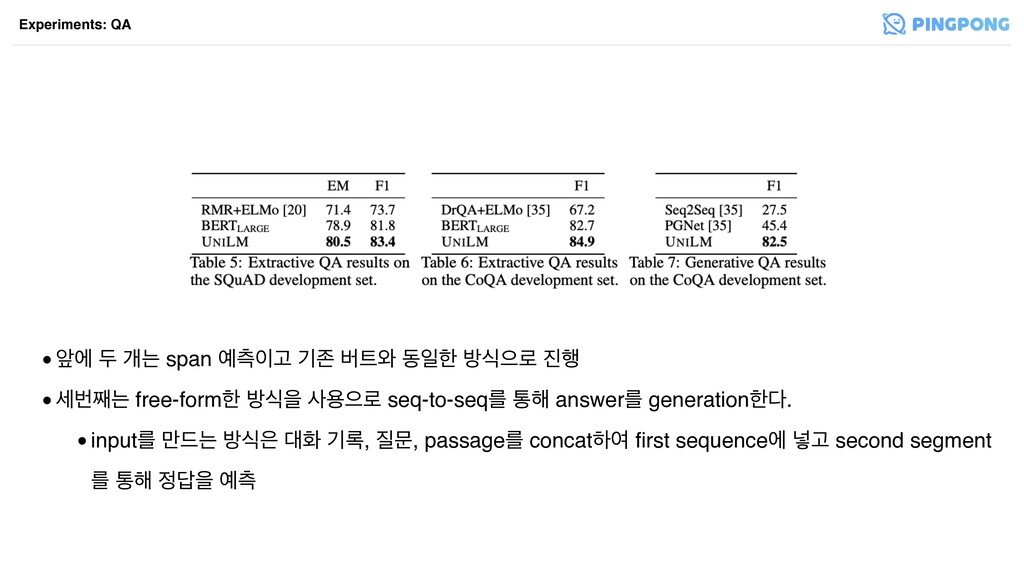
•খী ف ѐח span ஏҊ ӝઓ ߡ৬ زੌೠ ߑधਵ۽ ೯
•ࣁߣ૩ח free-formೠ ߑधਸ ࢎਊਵ۽ seq-to-seqܳ ా೧ answerܳ generationೠ. •inputܳ ݅٘ח ߑध ച ӝ۾, ޙ, passageܳ concatೞৈ first sequenceী ֍Ҋ second segment ܳ ా೧ ਸ ஏ Experiments: QA
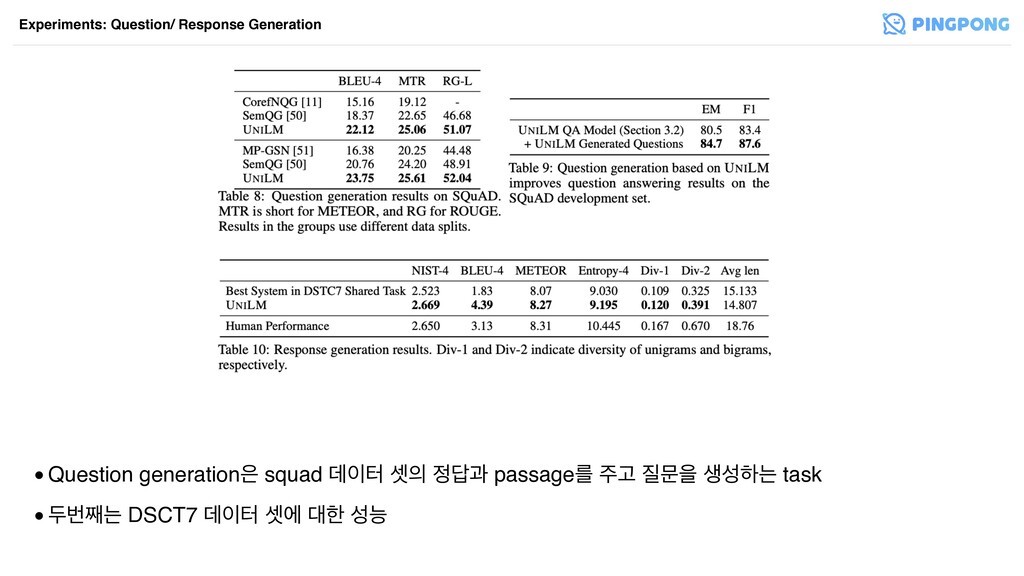
•Question generation squad ؘఠ ࣇ җ passageܳ Ҋ ޙਸ ࢤࢿೞח
task •فߣ૩ח DSCT7 ؘఠ ࣇী ೠ ࢿמ Experiments: Question/ Response Generation
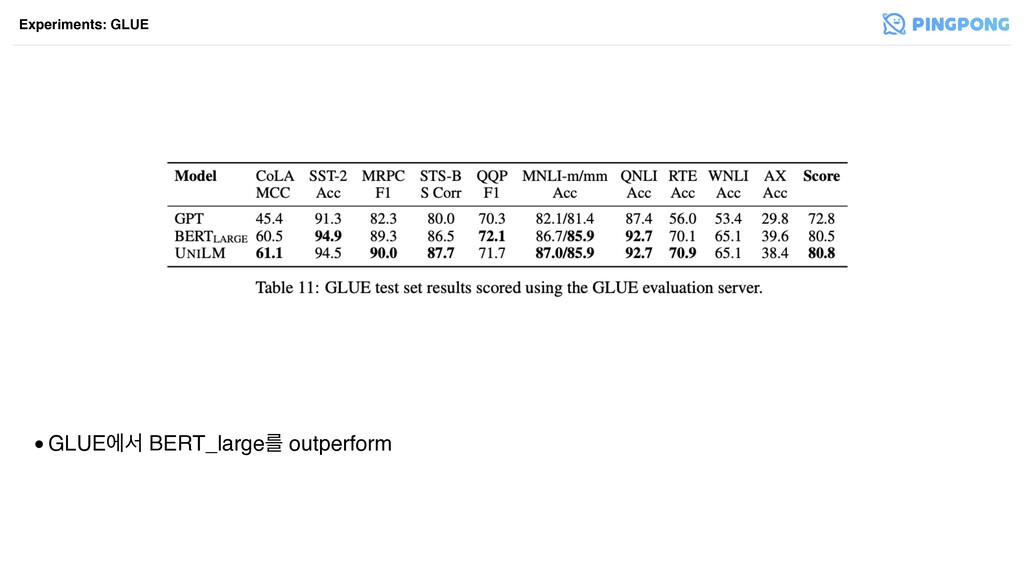
•GLUEীࢲ BERT_largeܳ outperform Experiments: GLUE
хࢎפ✌ ୶о ޙ ژח ҾӘೠ ݶ ઁٚ ইې োۅ۽
োۅ ࣁਃ! ࢲ࢚ (ML Research Scientist, Pingpong)
[email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![•[SOS]ח scpecial start-of-sequence •[EOS]ח NLU task ޙ ҃҅ scpecial end-of-sequence](https://files.speakerdeck.com/presentations/d408dc301b454f158663783a87182e1b/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}