Borin, C. de Souza et G. Araujo : Efficient datapath merging for partially reconfigurable architectures. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 24(7):969–980, 2005. - Corazao (1996) : M. R. Corazao, M. A. Khalaf, L. M. Guerra, M. Potkonjak et J. M. Rabaey : Performance optimization using template mapping for datapath-intensive high-level synthesis. IEEE Transactions on Computer- Aided Design of Integrated Circuits and Systems, 15:877–888, 1996. [Martin10] : K. Martin : Génération automatique d’extensions de jeux d’instructions de processeurs. Thèse de doctorat, Université de Rennes 1, 2010. - [DSD09] : C. Wolinski, K. Kuchcinski, E. Raffin et F. Charot : Architecture-driven synthesis of reconfigurable cells. In Proceedings of the 12th EUROMICRO Conference on Digital System Design Architectures, Methods and Tools (DSD ’09), 2009. - [TODAES10] : C. Wolinski, K. Kuchcinski et E. Raffin : Automatic design of application specific reconfigurable processor extensions with UPaK synthesis kernel. ACM Transactions on Design Automation of Electronic Systems (TODAES), 15:1–36, 2009. - [Raf10] : E. Raffin, C.Wolinki, F. Charot, K. Kuchcinski, S. Guyetant, S. Chevobbe et E. Casseau : Scheduling, binding and routing system for a run-time reconfigurable operator based multimedia architecture. In Proceedings of IEEE Conference on Design and Architectures for Signal and Image Processing (DASIP), October 2010.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![26 Contexte DURASE [Martin10] : Generic Environment for Design and](https://files.speakerdeck.com/presentations/798f9827bcf44f67a2d9af7ffeaf6f21/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
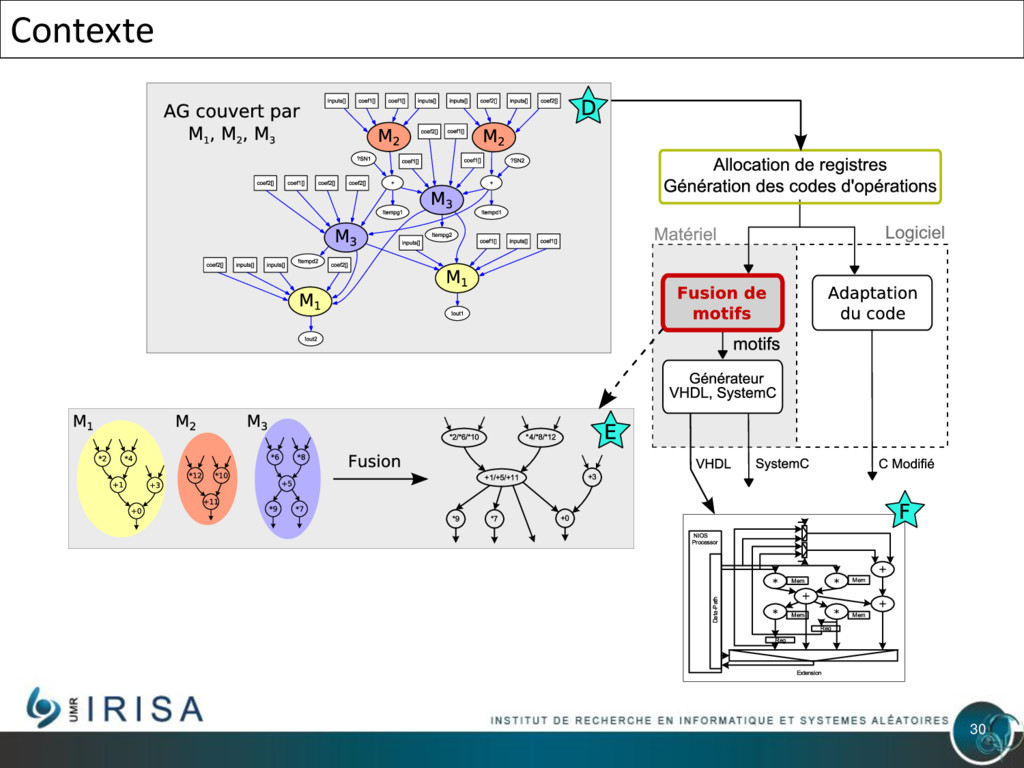{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
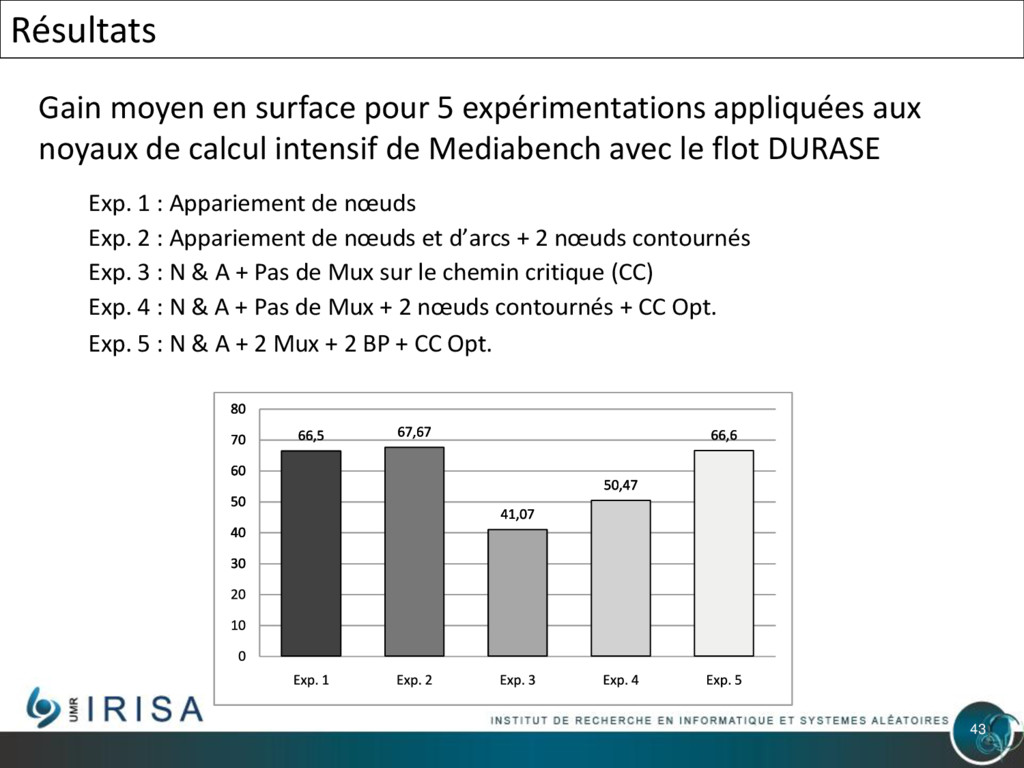{kind=link}
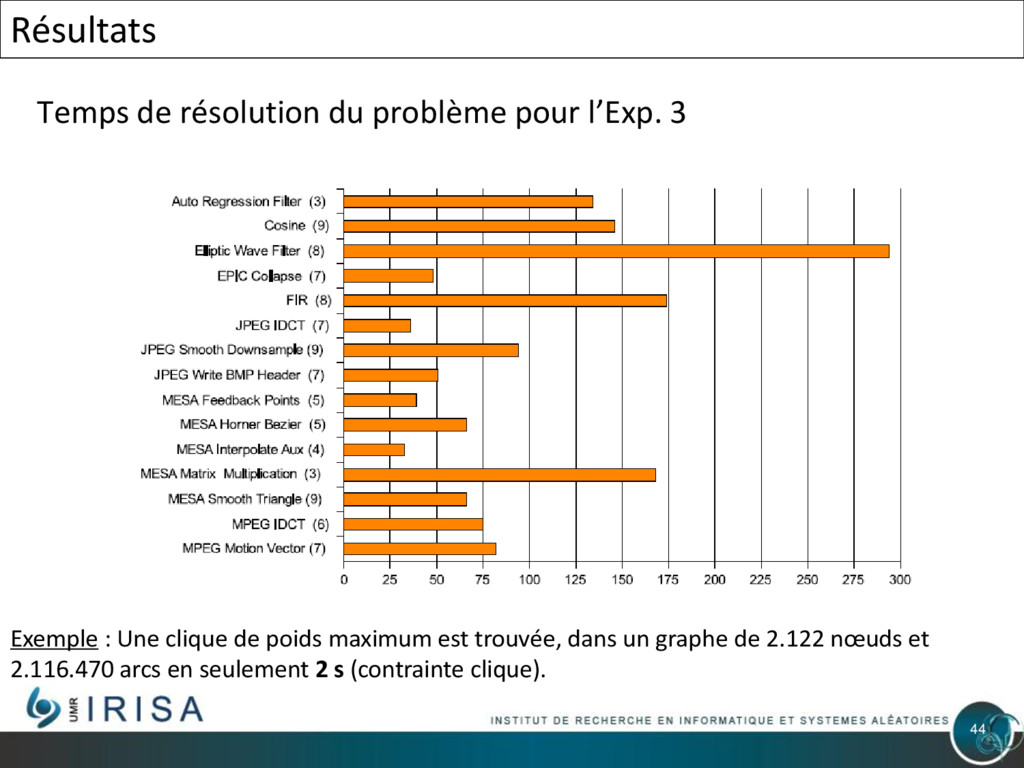{kind=link}
{kind=link}
{kind=link}
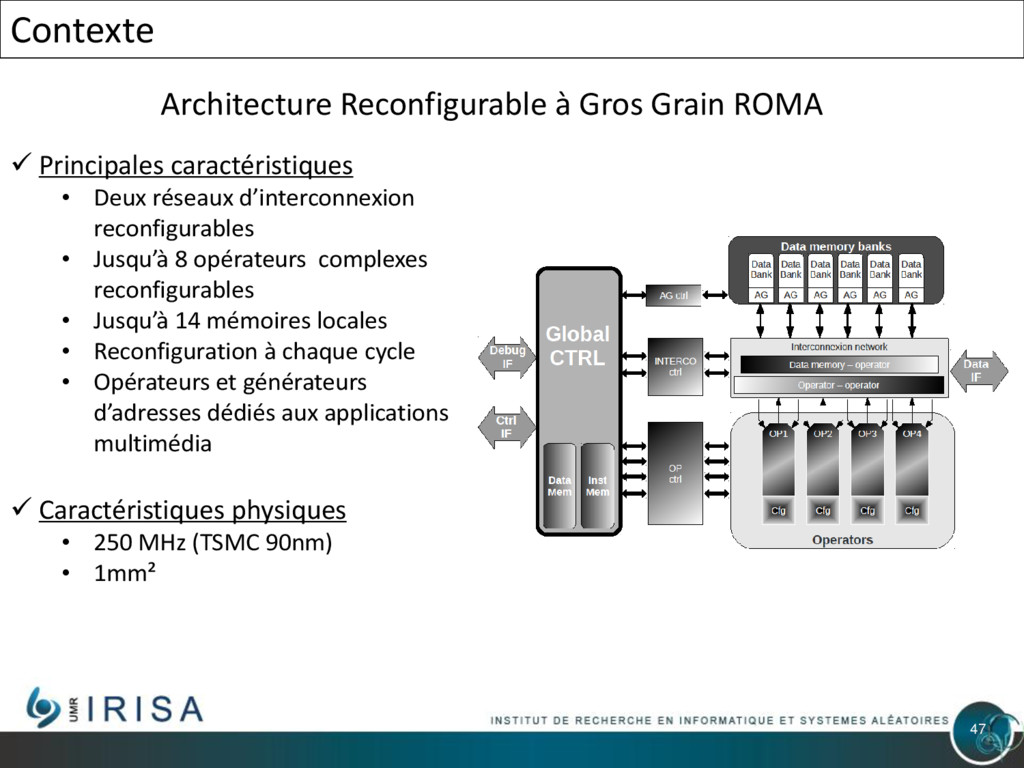{kind=link}
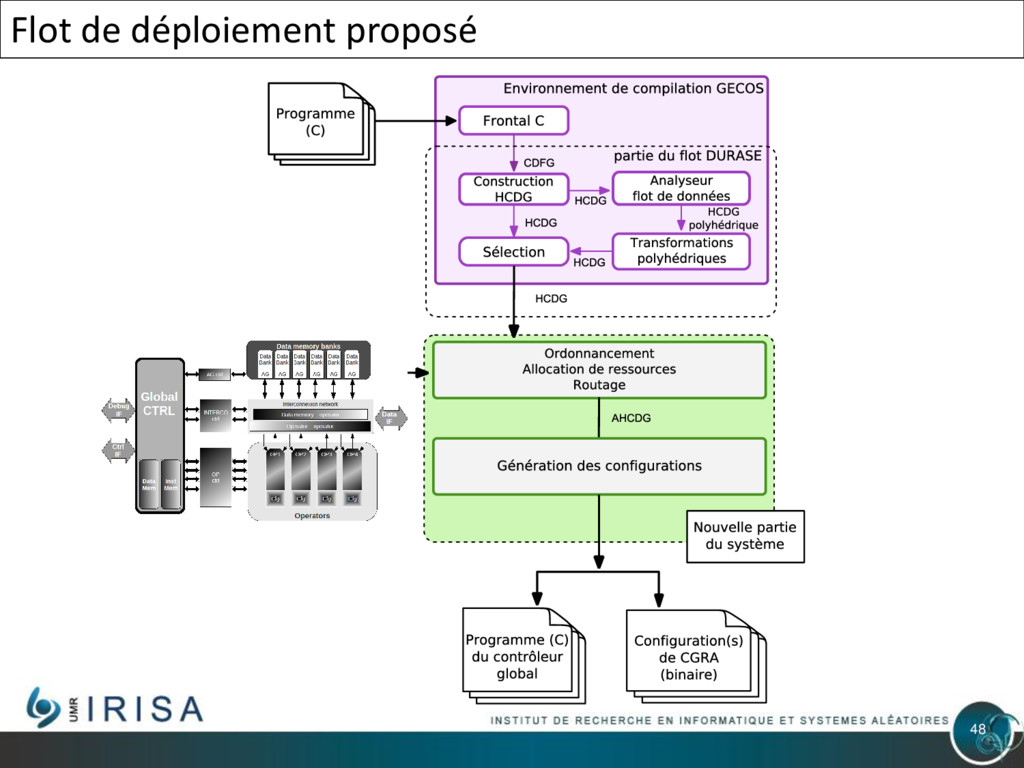{kind=link}
{kind=link}
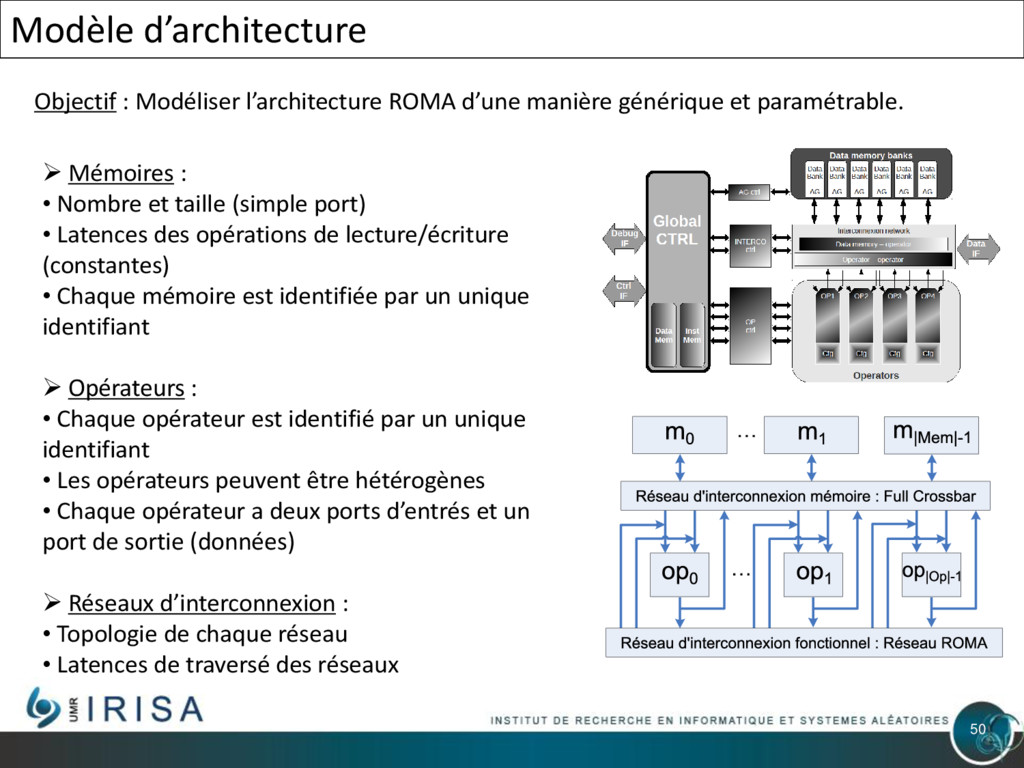{kind=link}
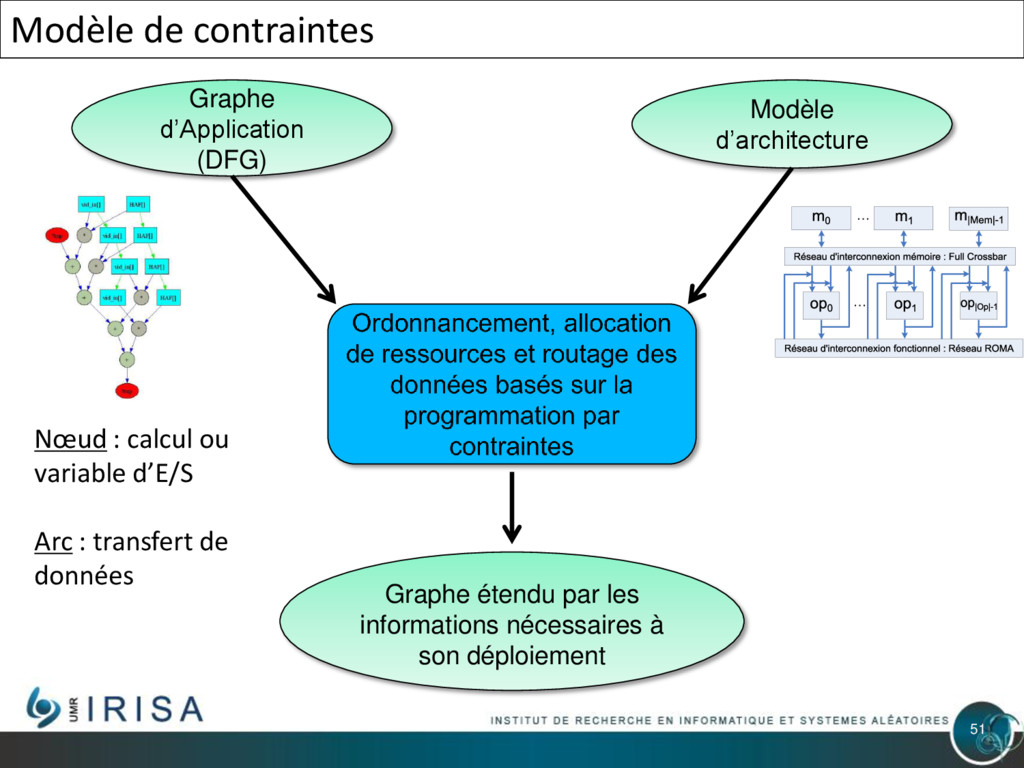{kind=link}
{kind=link}
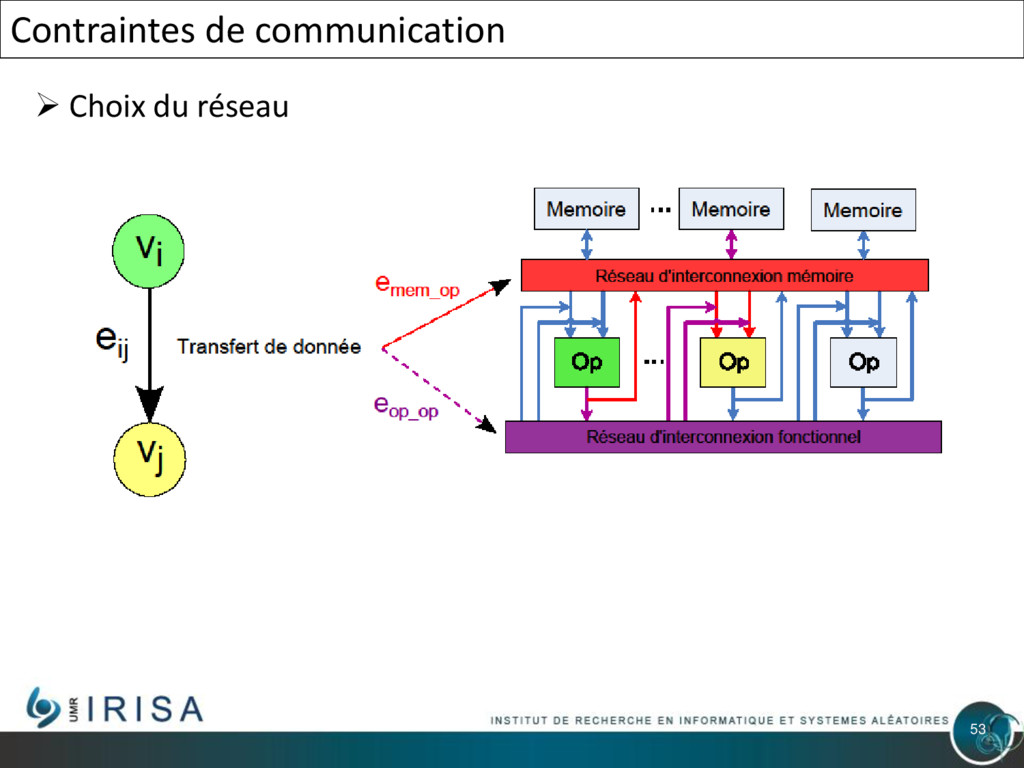{kind=link}
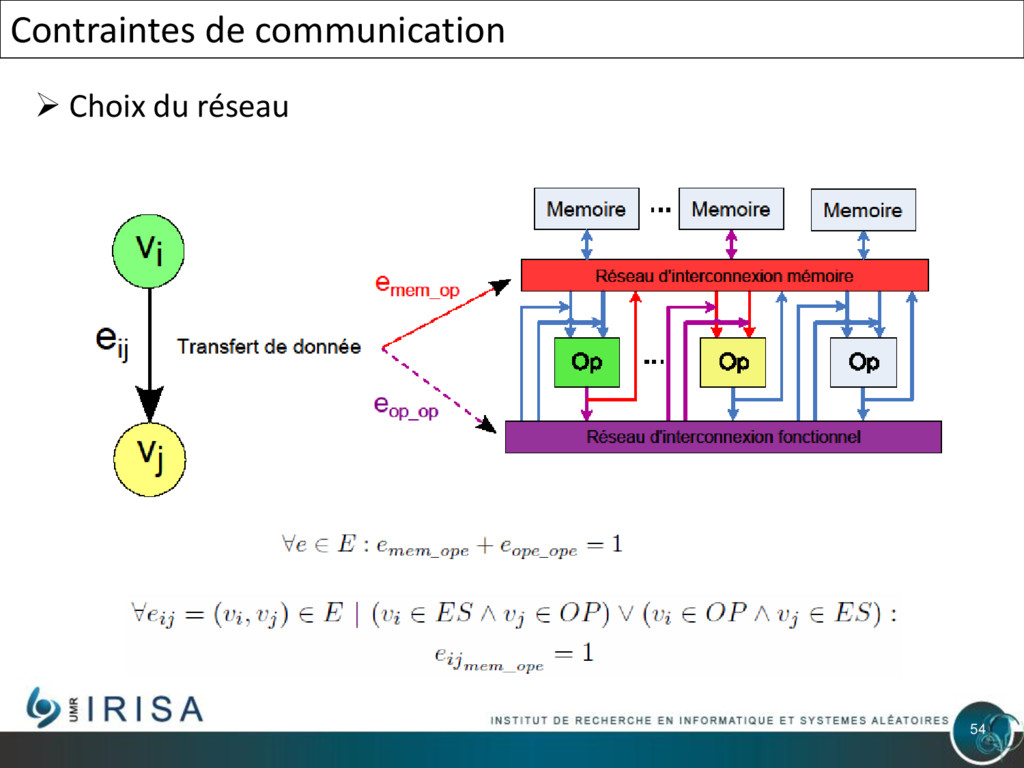{kind=link}
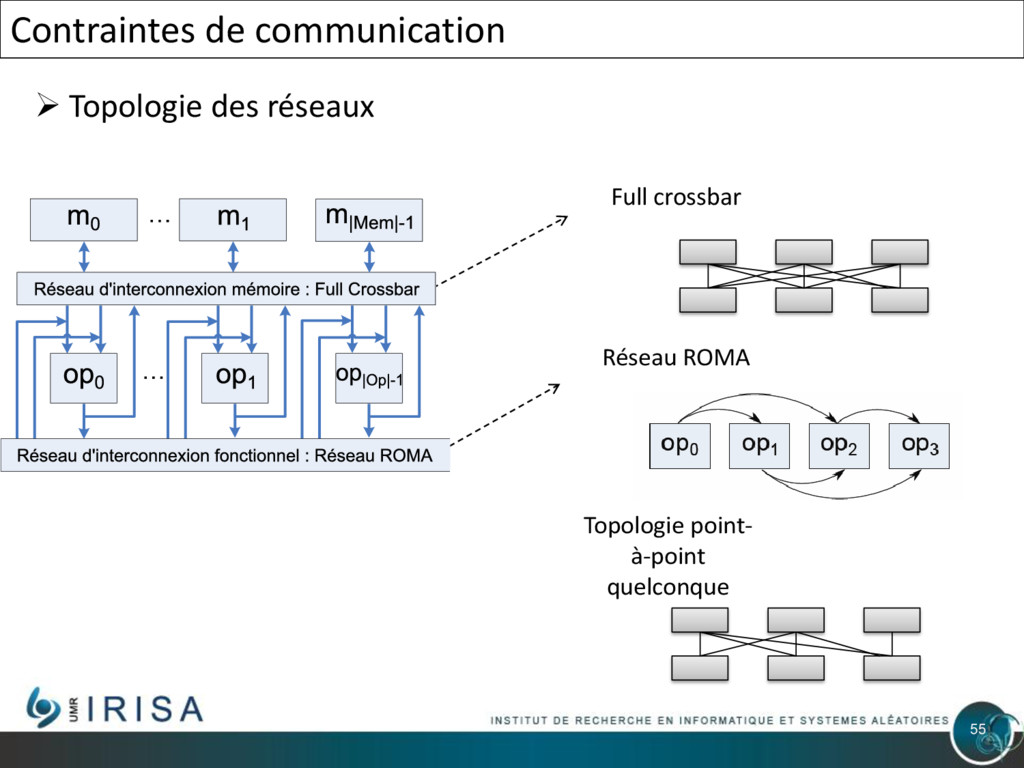{kind=link}
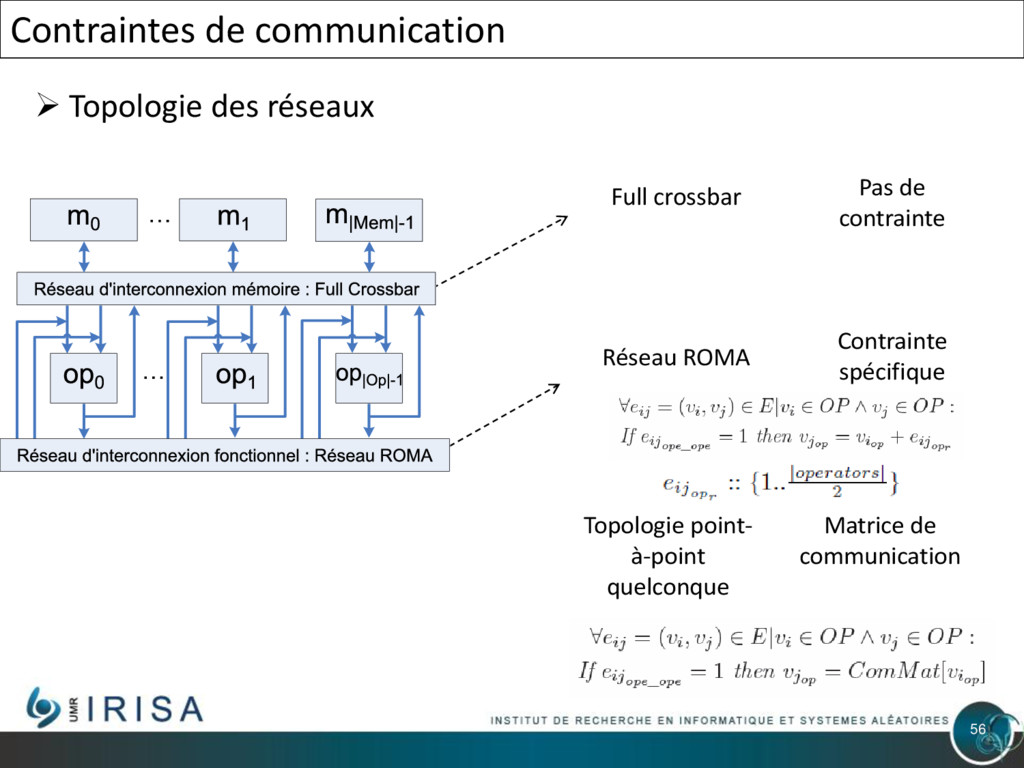{kind=link}
{kind=link}
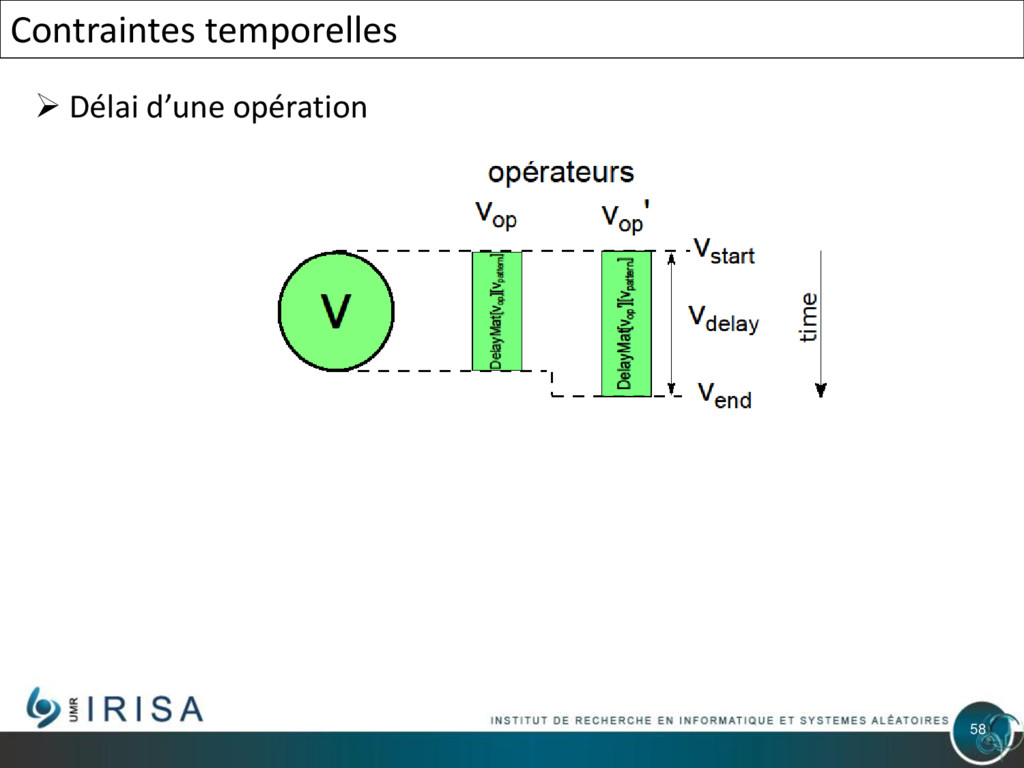{kind=link}
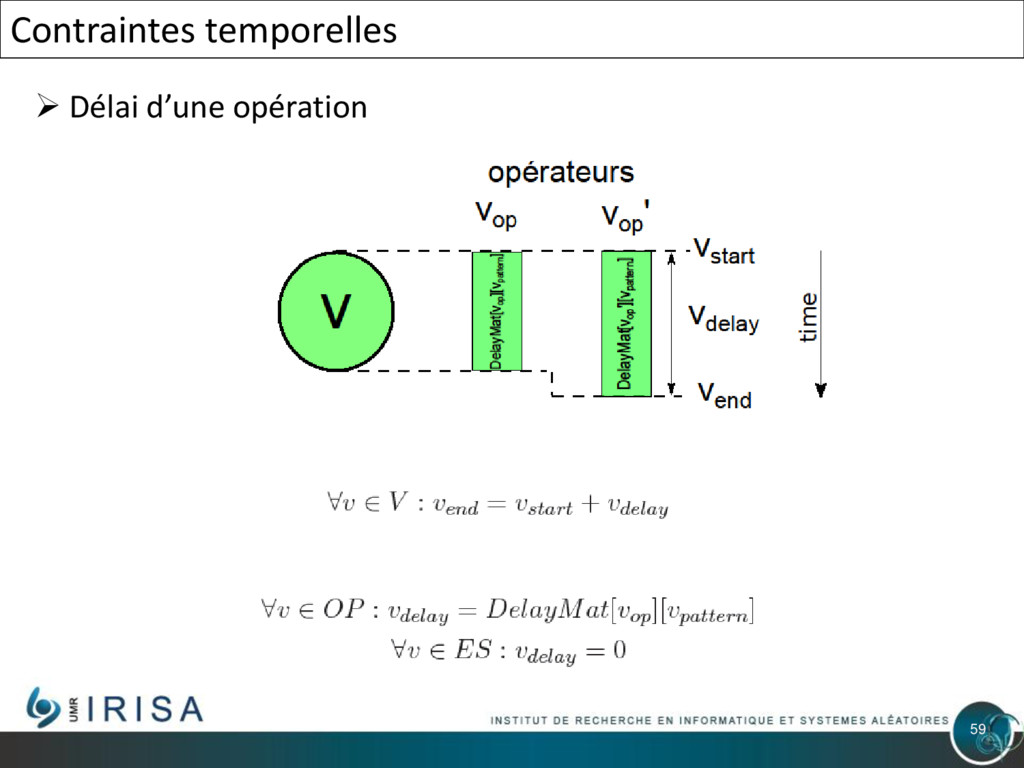{kind=link}
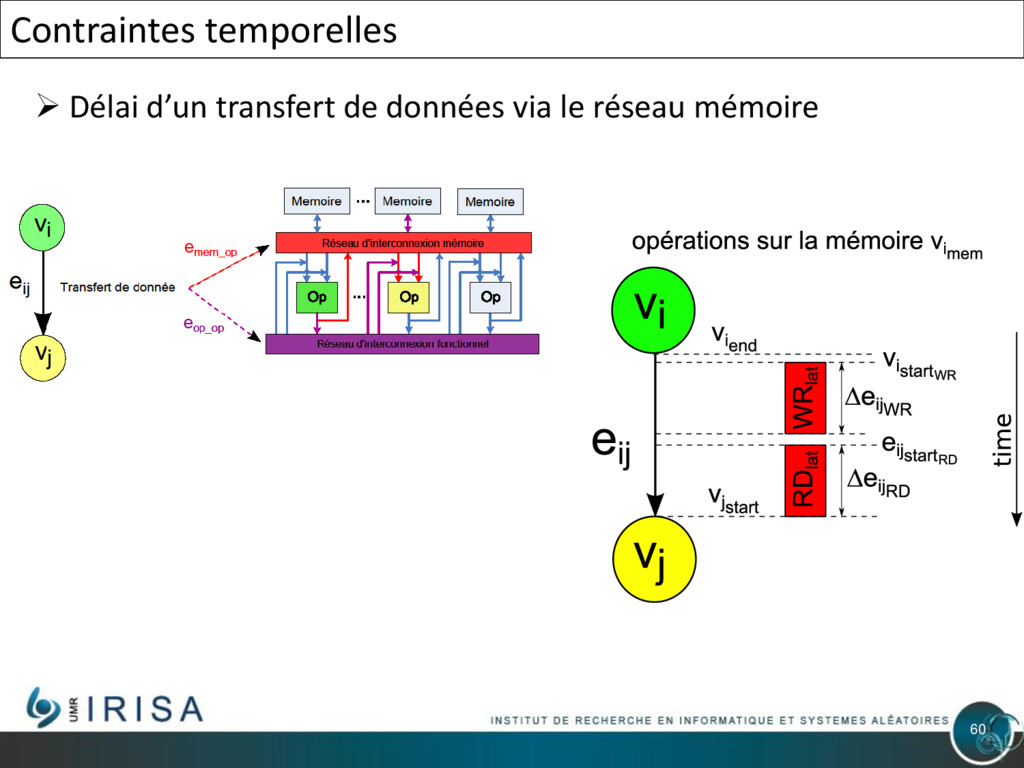{kind=link}
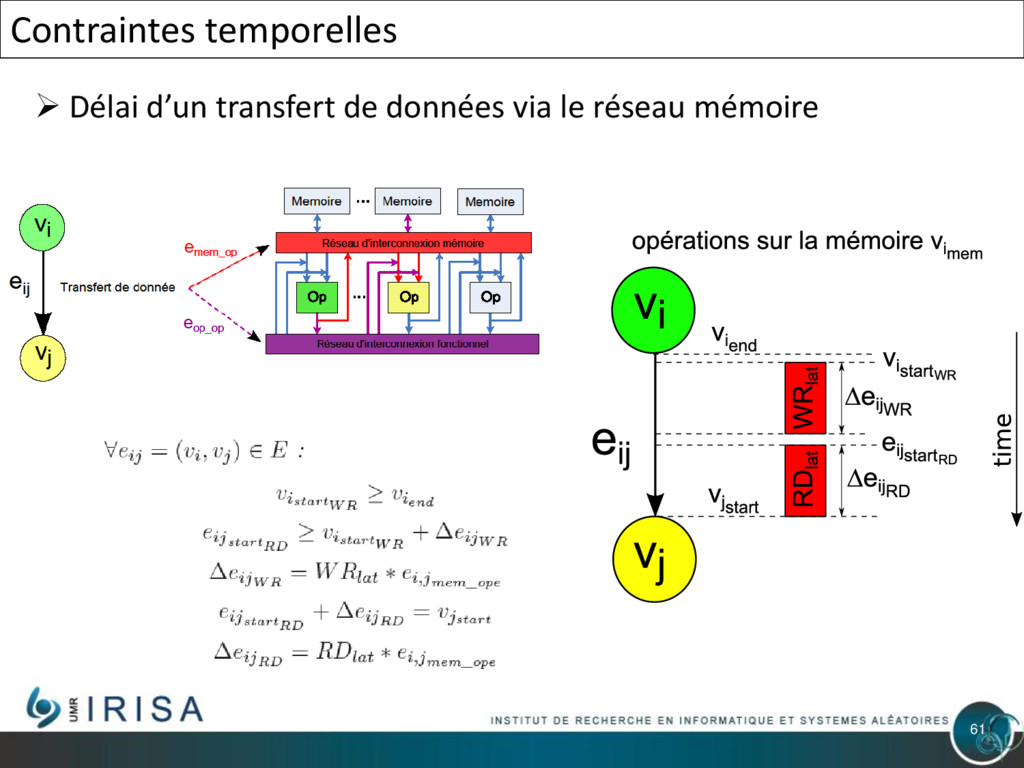{kind=link}
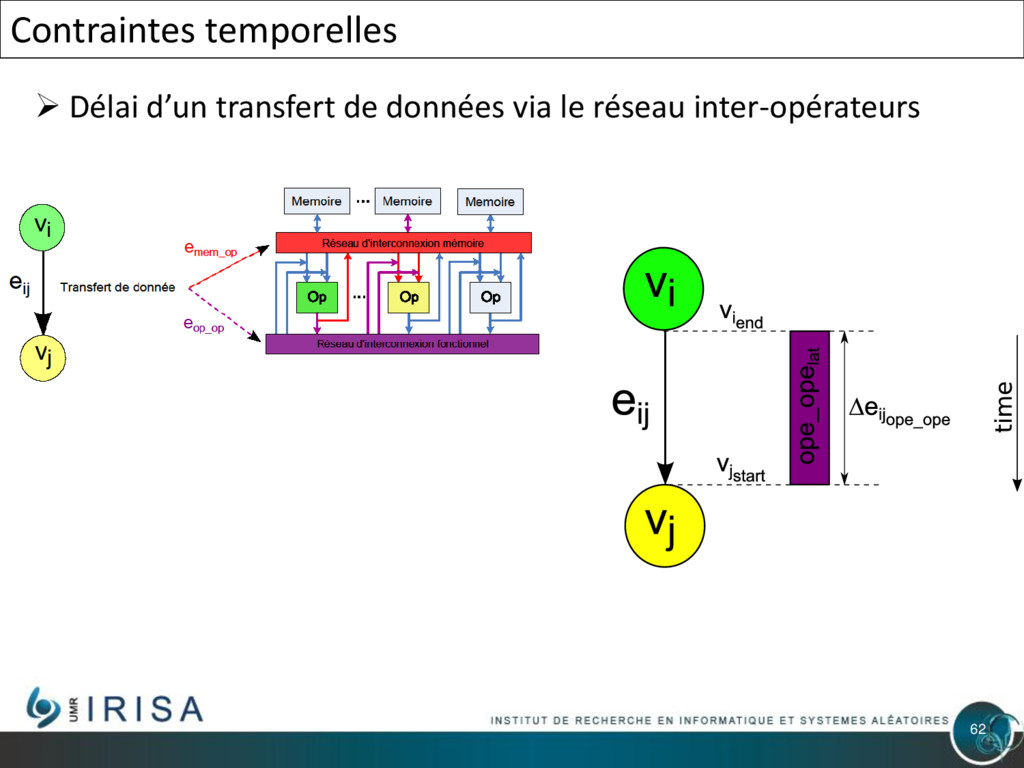{kind=link}
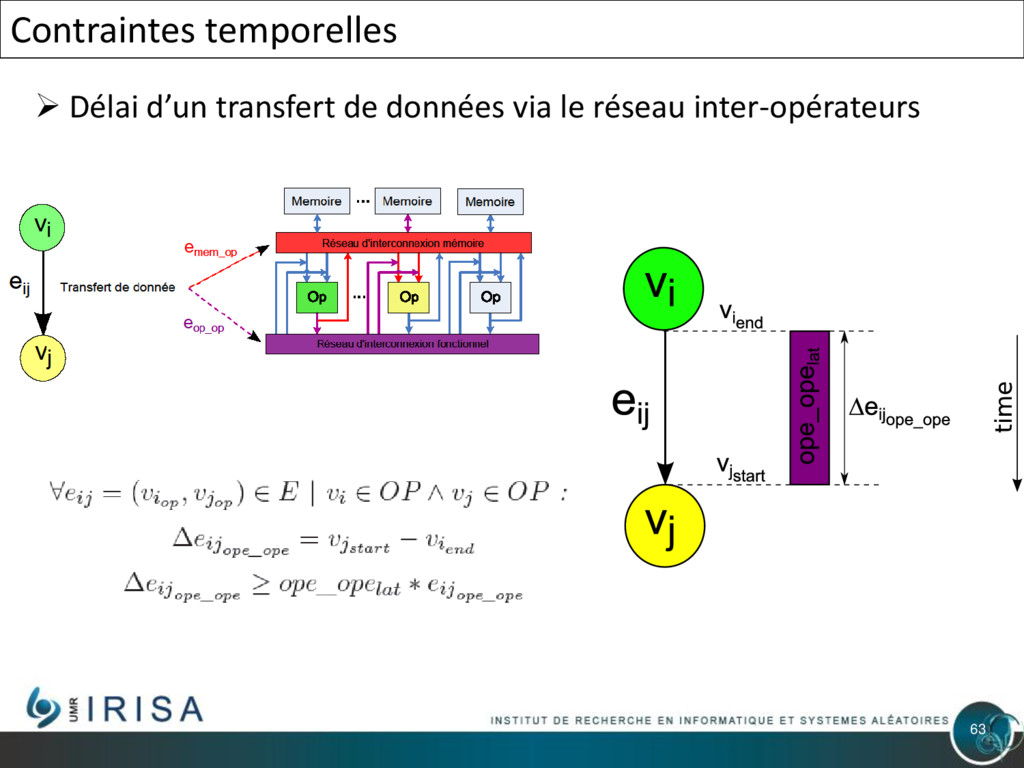{kind=link}
{kind=link}
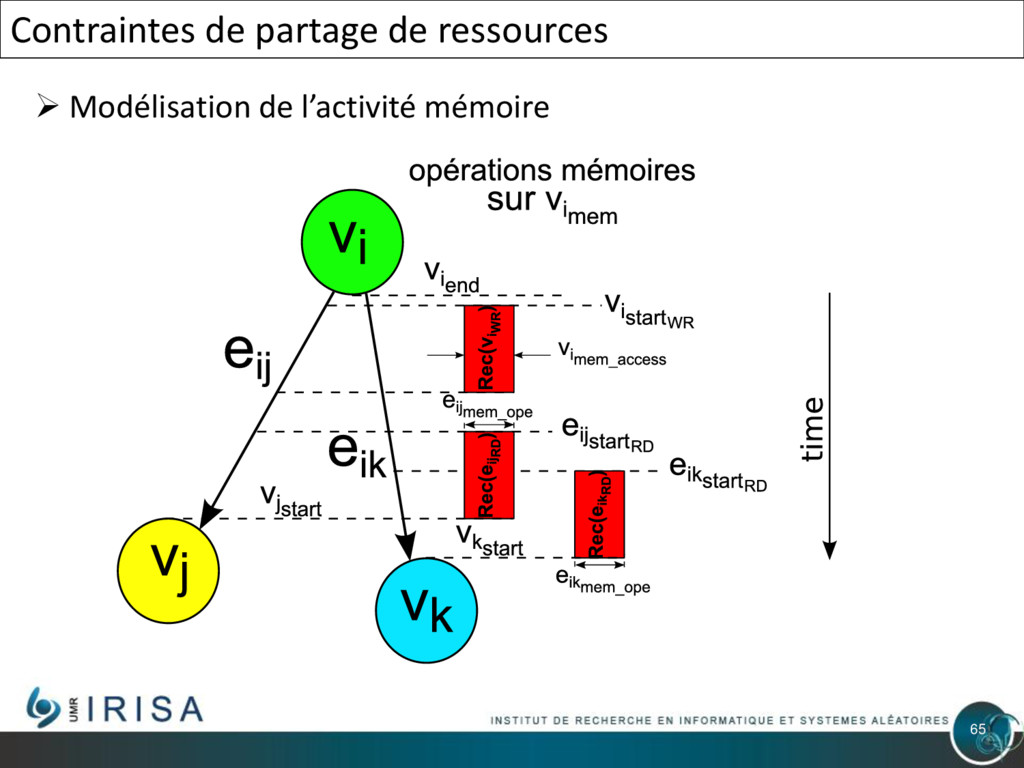{kind=link}
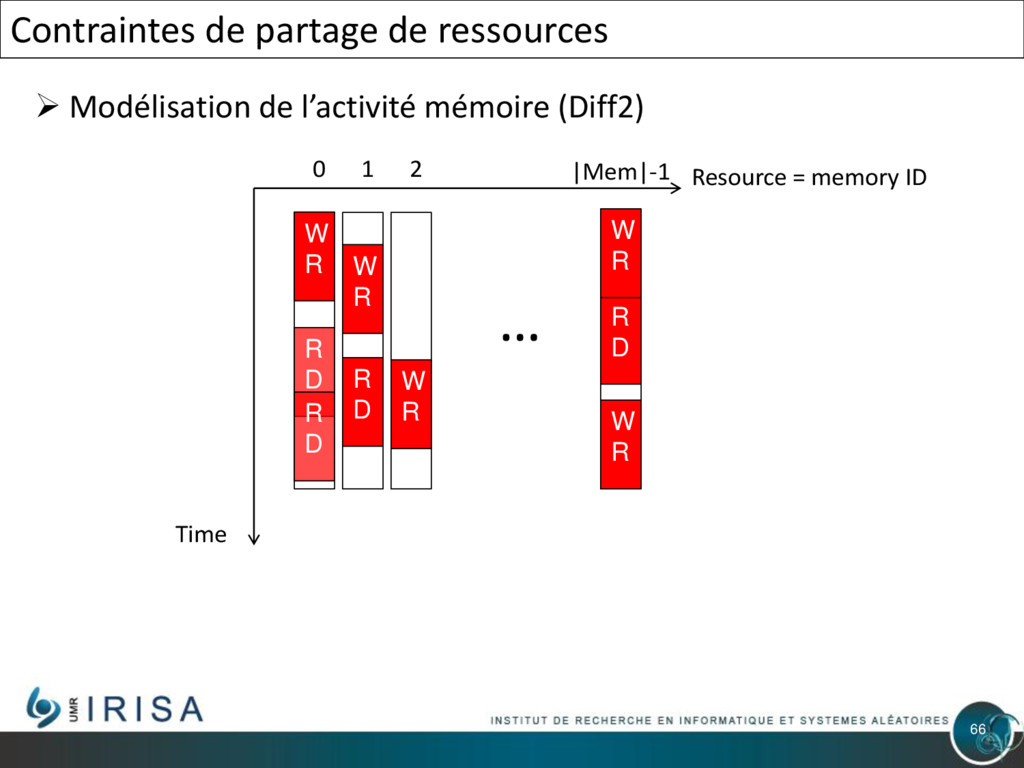{kind=link}
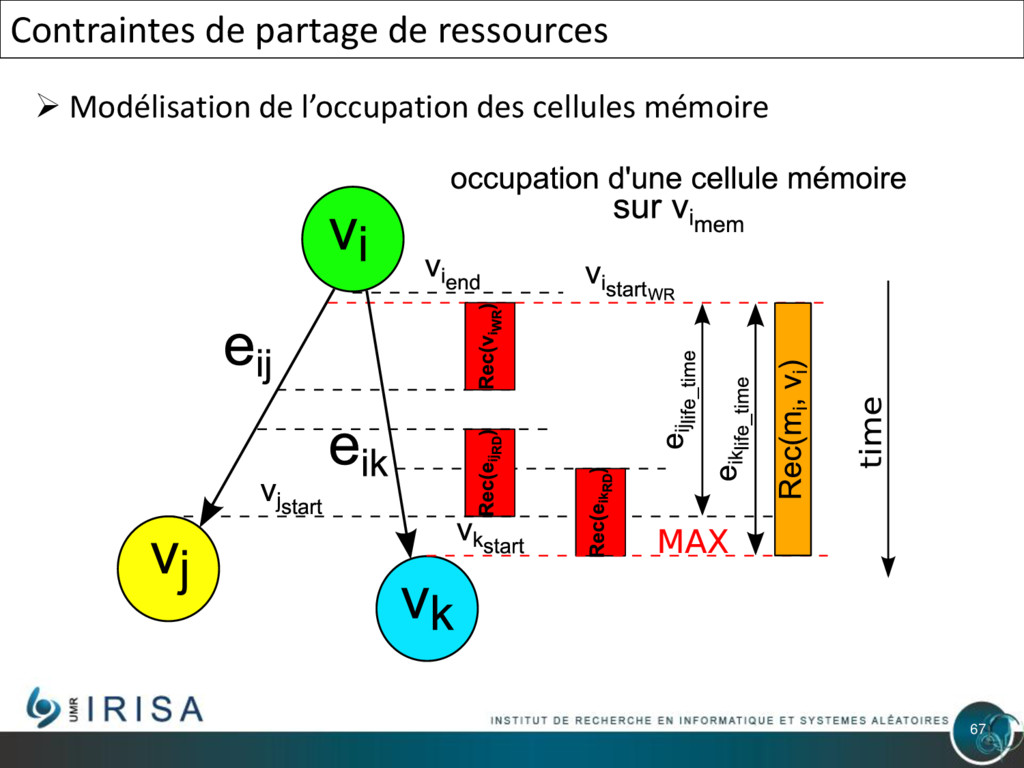{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}