do with future networks and communications in Ireland. IoT Wireless Cellular Fixed hardware, software, infrastructure, architecture, management, applications, services …
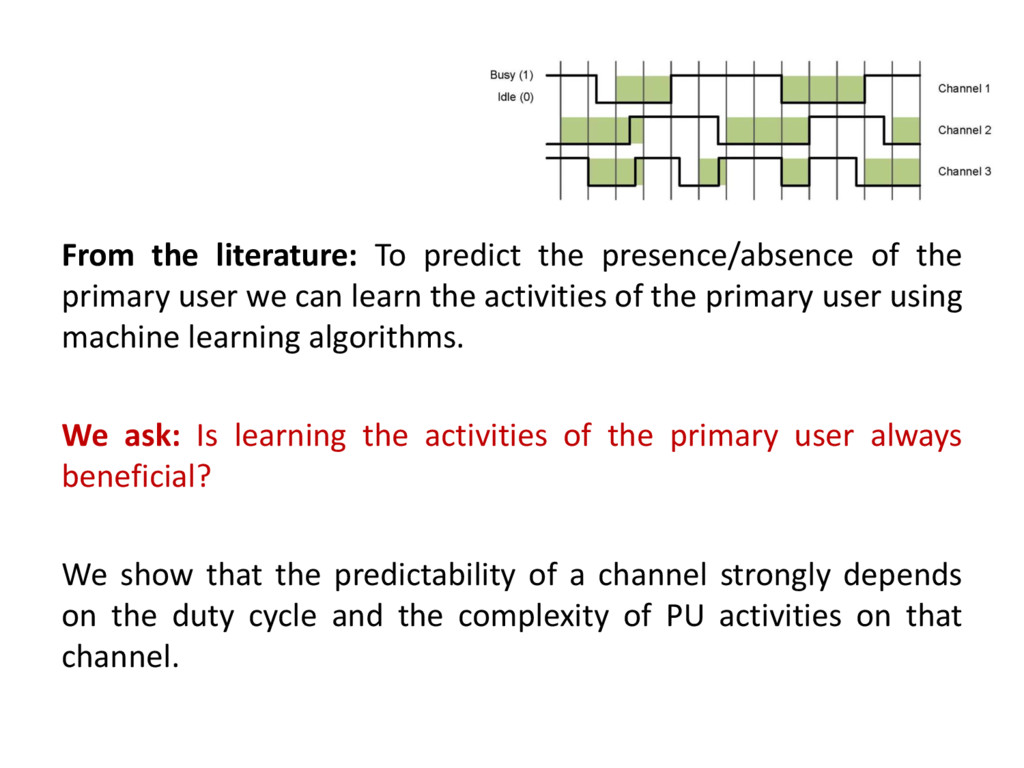
user we can learn the activities of the primary user using machine learning algorithms. We ask: Is learning the activities of the primary user always beneficial? We show that the predictability of a channel strongly depends on the duty cycle and the complexity of PU activities on that channel.
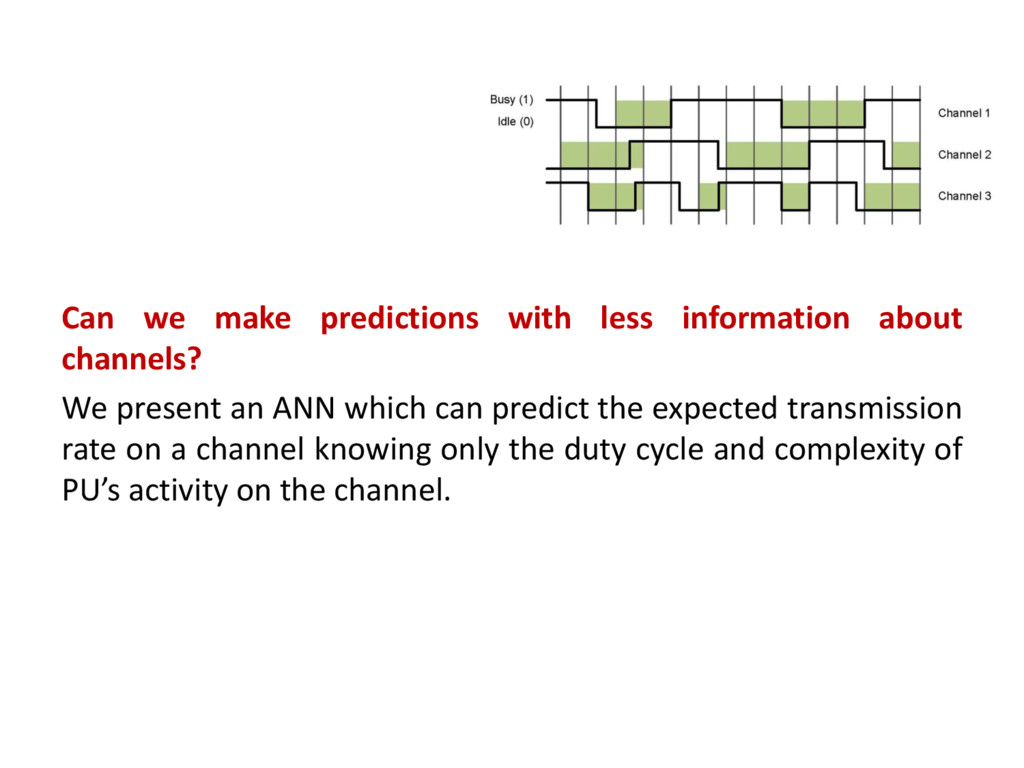
present an ANN which can predict the expected transmission rate on a channel knowing only the duty cycle and complexity of PU’s activity on the channel.
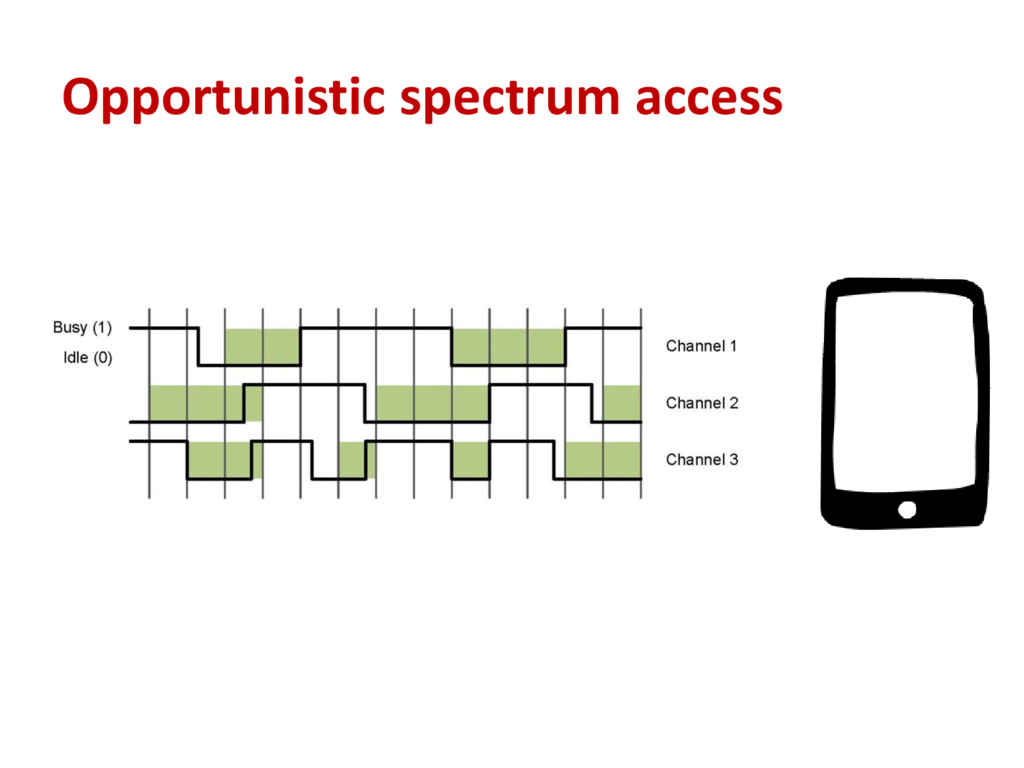
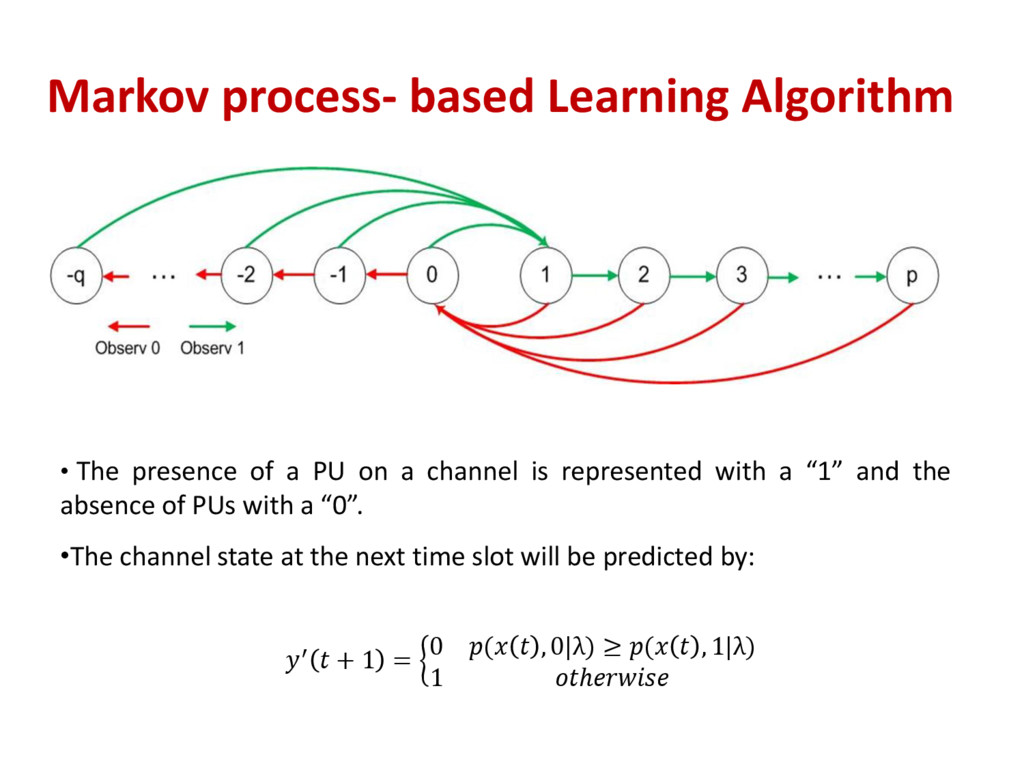
PU on a channel is represented with a “1” and the absence of PUs with a “0”. •The channel state at the next time slot will be predicted by: ′ + 1 = 0 ( , 0|λ) ≥ ( , 1|λ) 1 ℎ
can be characterized in terms of the observed DC and the complexity of the PU activity. • Each channel is the realization of a 2-state first order Markov chain (MC). • For an ergodic source the Lempel-Ziv complexity equals the entropy rate of the source, which for a Markov chain X is given by: ℎ = − log
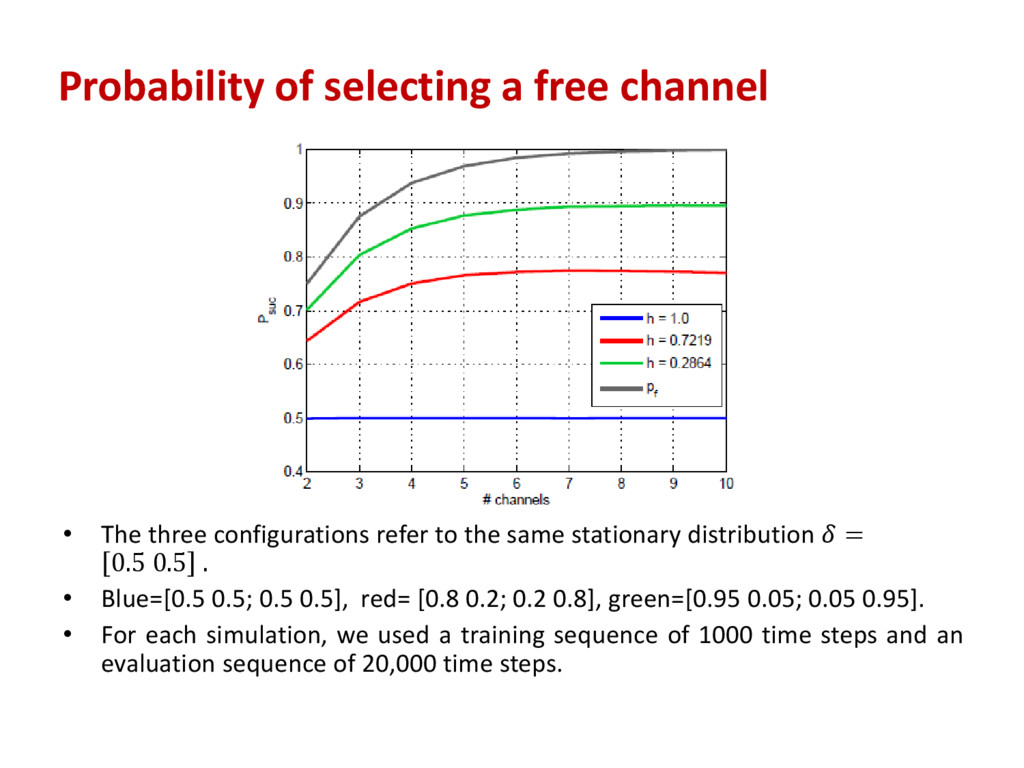
We considered 5 possible δ0 values in the range 0.5, … , 0.9. For each of these values, we considered 5 transition probability matrices, each corresponding to a different value of entropy rate. • At each point K = 3 channels. • Pf is the probability of at least one free channel existing.
refer to the same stationary distribution = 0.5 0.5 . • Blue=[0.5 0.5; 0.5 0.5], red= [0.8 0.2; 0.2 0.8], green=[0.95 0.05; 0.05 0.95]. • For each simulation, we used a training sequence of 1000 time steps and an evaluation sequence of 20,000 time steps.
entropy rate of a sequence if we compute it over infinite samples. • We conducted 1000 independent simulations and computed the LZ complexity values of binary sequences generated according to four different channel transition matrices.
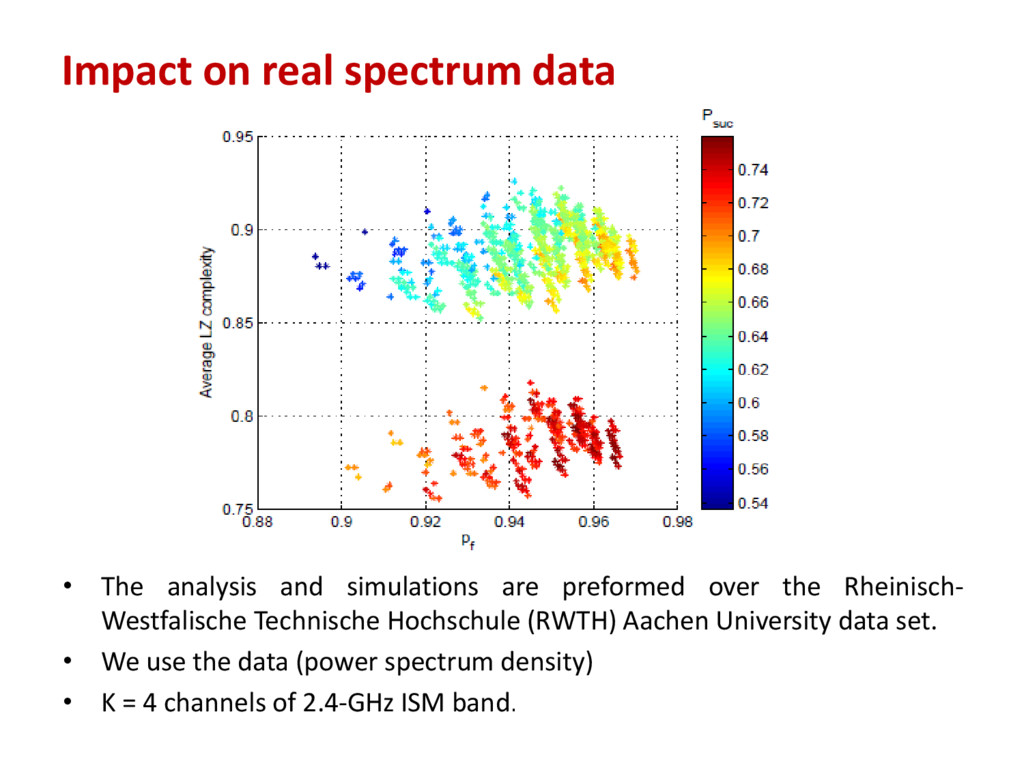
Westfalische Technische Hochschule (RWTH) Aachen University data set. • We use the data (power spectrum density) • K = 4 channels of 2.4-GHz ISM band Impact on real spectrum data
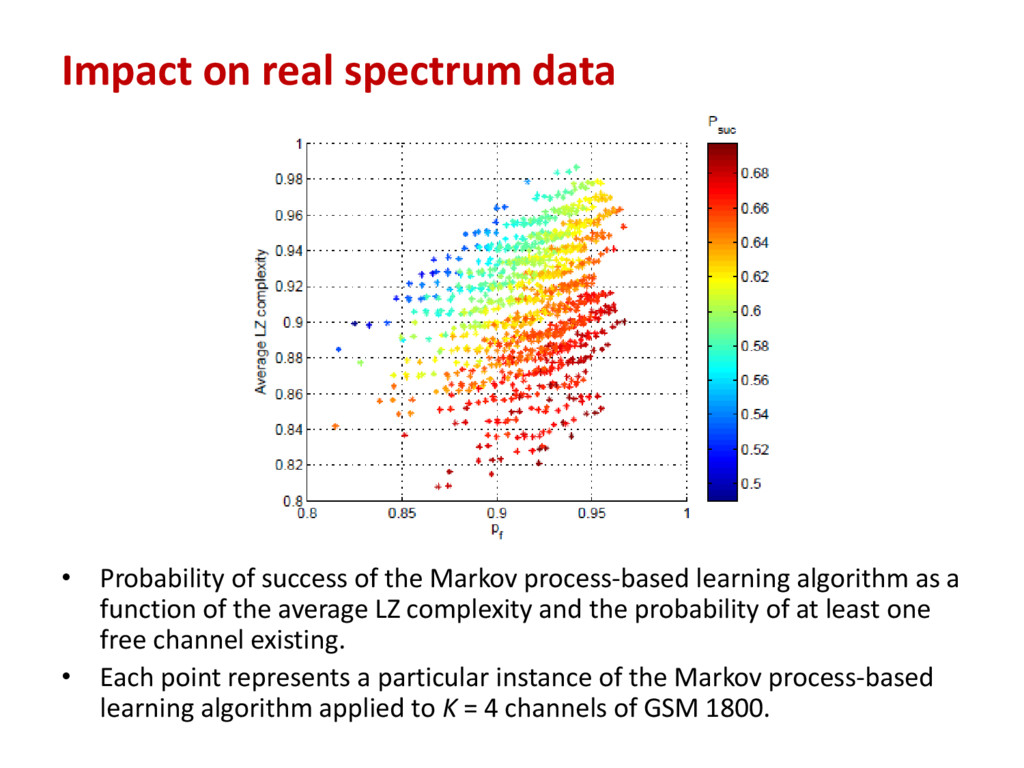
as a function of the average LZ complexity and the probability of at least one free channel existing. • Each point represents a particular instance of the Markov process-based learning algorithm applied to K = 4 channels of GSM 1800. Impact on real spectrum data
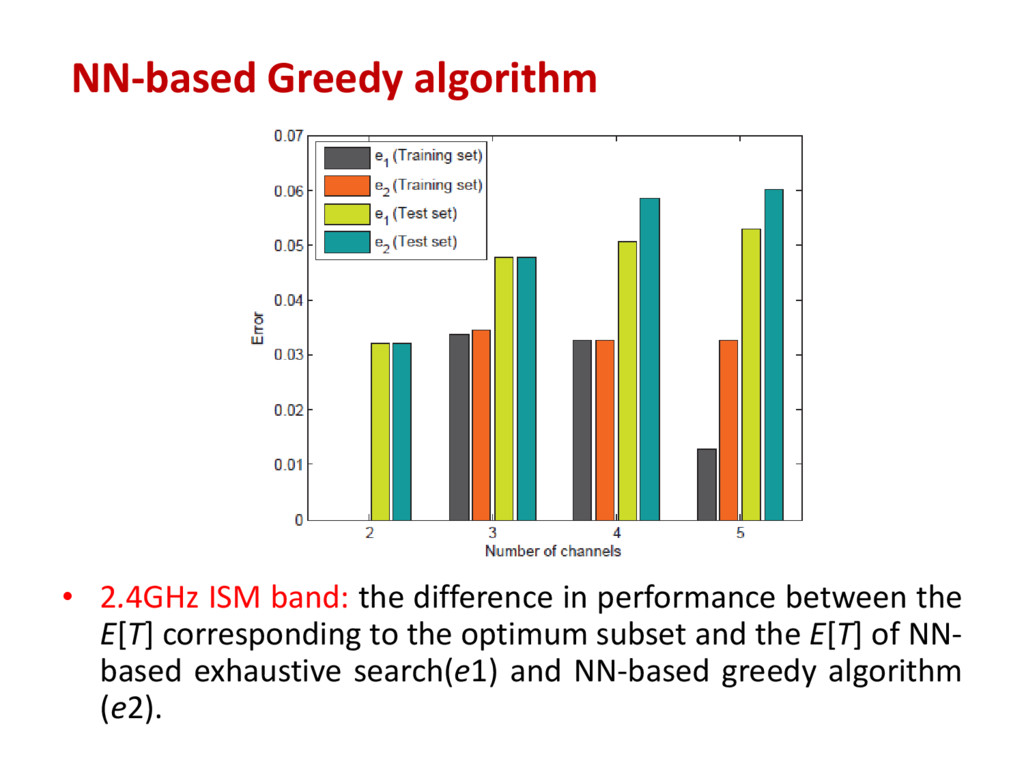
rate (E[T]) • We use a feed forward neural network with a single layer of hidden units. • The number of inputs to each network is 2 × |C|, with |C| ∈ {2, 3, . . . , k}. • We tested the accuracy of the proposed approach relying on both an idealized mathematical model of PU behaviour and on actual PU activity data. Success rate prediction with neural networks
considered 7 possible δ0 values in the range 0.2, . . . , 0.8. For each of these values, we considered p11 (or p00 ) values of 0.1, 0.3, 0.5, 0.7, 0.9 if δ0 >= 0.5 (if δ0 < 0.5), obtaining 35 different transition probability matrices. • Test data set: we considered 7 additional possible δ0 values in the range 0.15, . . . , 0.75. For each of these values, we considered p11 (or p00 ) values of 0.1, 0.3, 0.5, 0.7, 0.9 if δ0 >= 0.5 (if δ0 < 0.5), obtaining 35 different transition probability matrices.
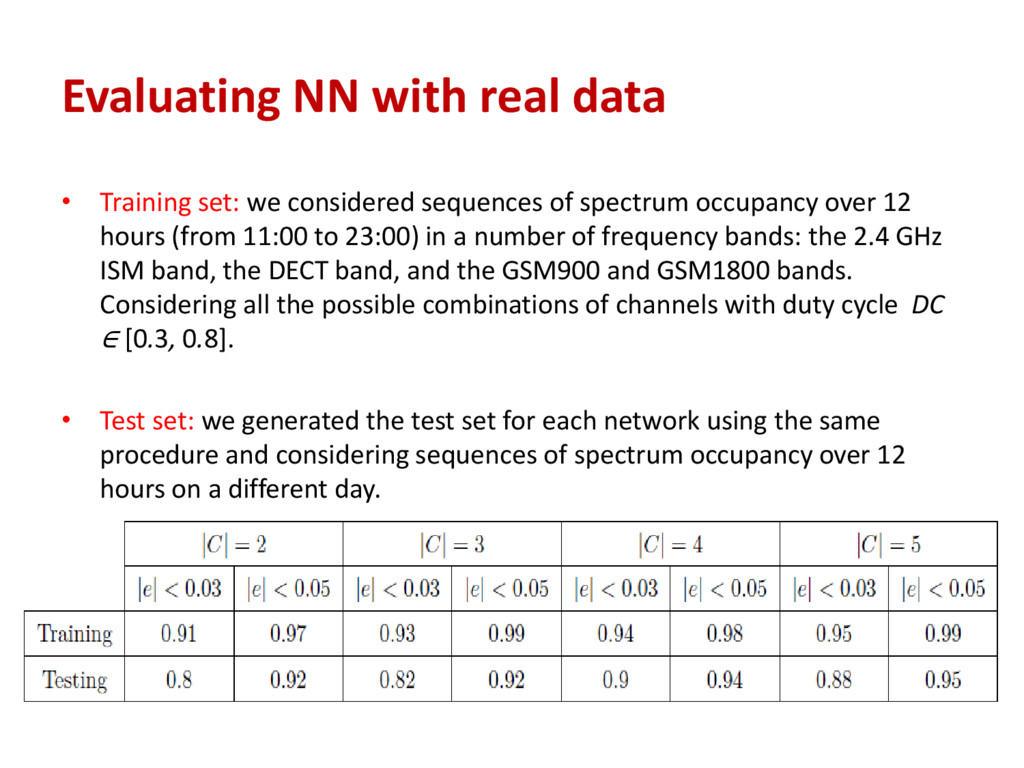
sequences of spectrum occupancy over 12 hours (from 11:00 to 23:00) in a number of frequency bands: the 2.4 GHz ISM band, the DECT band, and the GSM900 and GSM1800 bands. Considering all the possible combinations of channels with duty cycle DC ∈ [0.3, 0.8]. • Test set: we generated the test set for each network using the same procedure and considering sequences of spectrum occupancy over 12 hours on a different day.
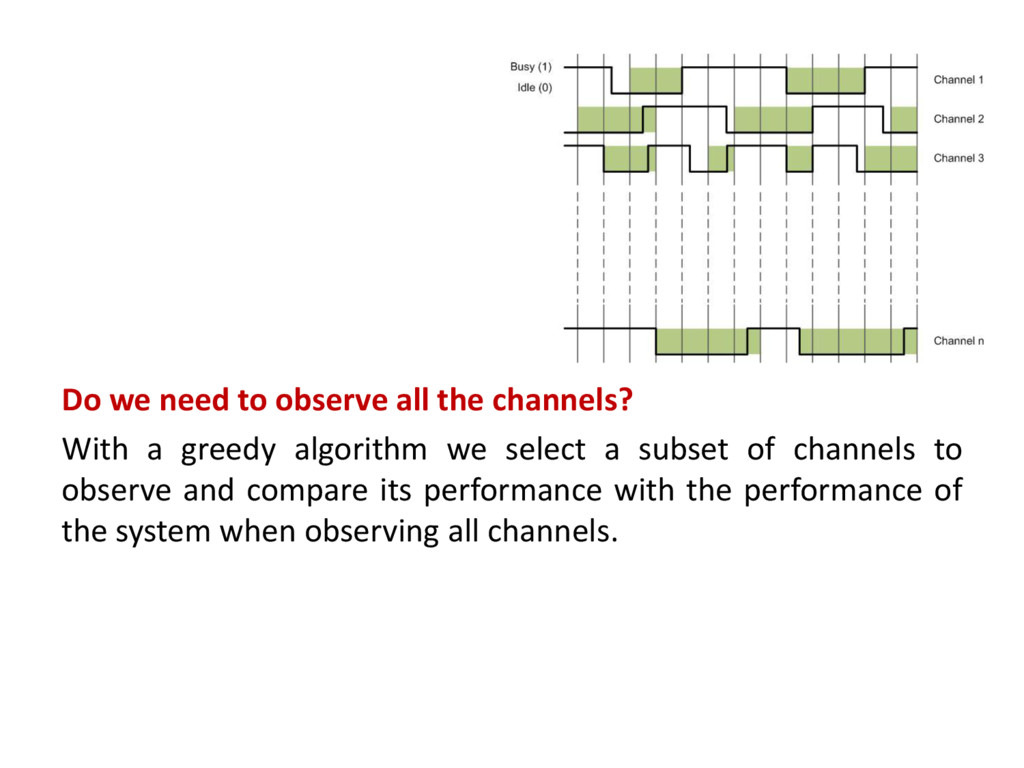
• Consider a set S of channels within which a CR has to identify a subset of at most k channels to be later exploited using a dynamic channel selection (DCS) approach. • The selection of the optimal subset of channels can be formulated as: • where u(C) denotes the performance of the DCS approach corresponding to the set of channels C and Pk (S) is the set of subsets of S with cardinality |C| ∈ {2, . . . , k}. • The dimension of the search space is
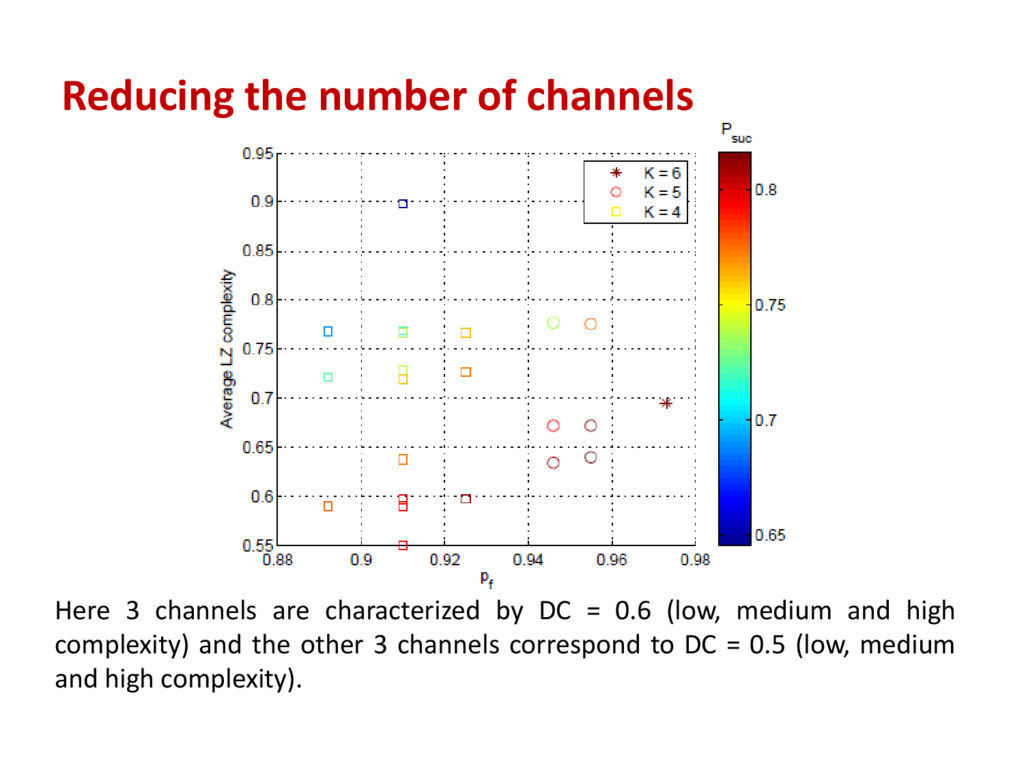
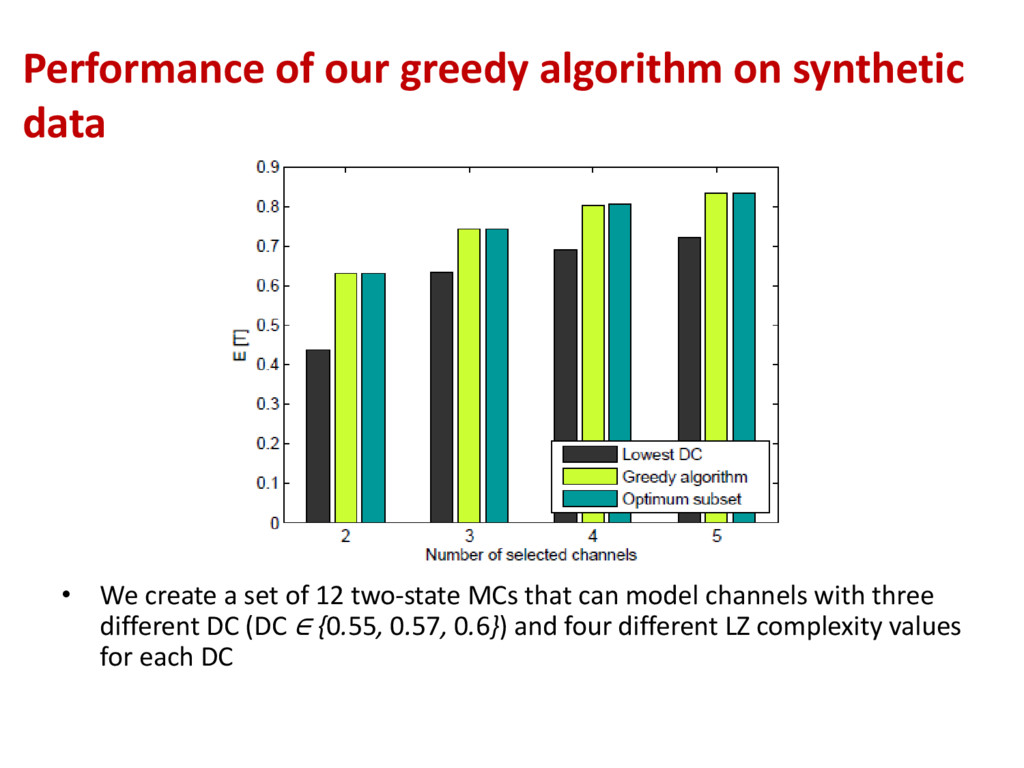
create a set of 12 two-state MCs that can model channels with three different DC (DC ∈ {0.55, 0.57, 0.6}) and four different LZ complexity values for each DC
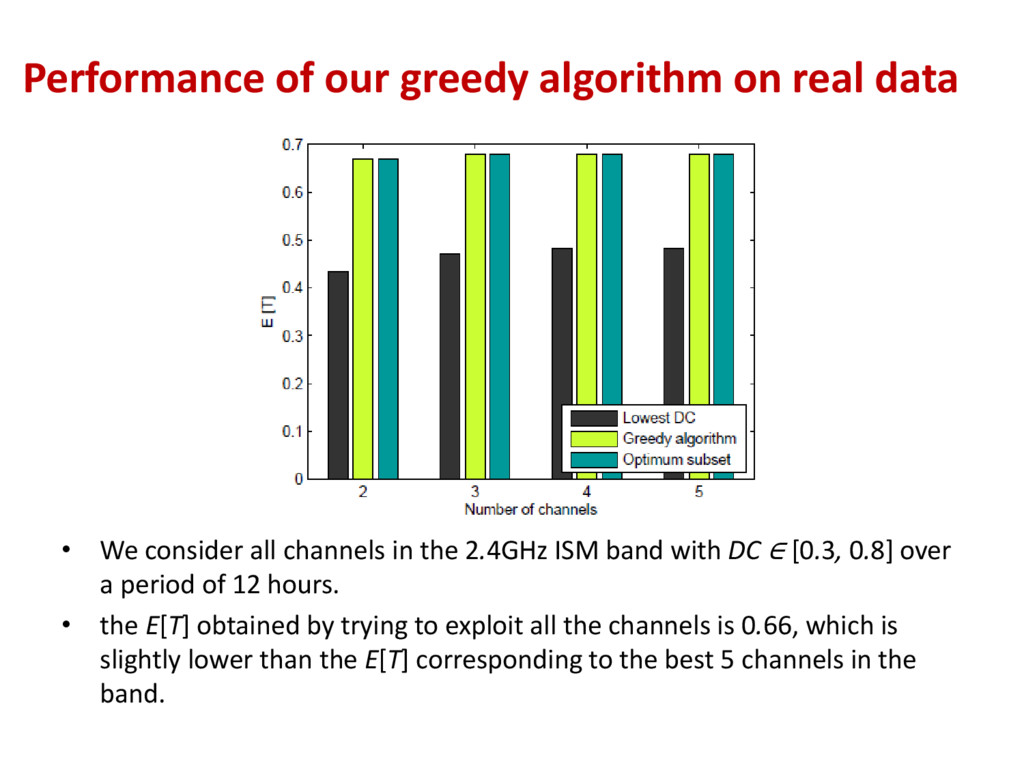
consider all channels in the 2.4GHz ISM band with DC ∈ [0.3, 0.8] over a period of 12 hours. • the E[T] obtained by trying to exploit all the channels is 0.66, which is slightly lower than the E[T] corresponding to the best 5 channels in the band.
Markov process-based learning algorithm on the optimum subsets and the subsets of channels with Lowest DC (LDC). We consider 3 users, 10 channels with high LZ and base-DC, and 10 channels with low LZ and DC=base-DC+Δ.
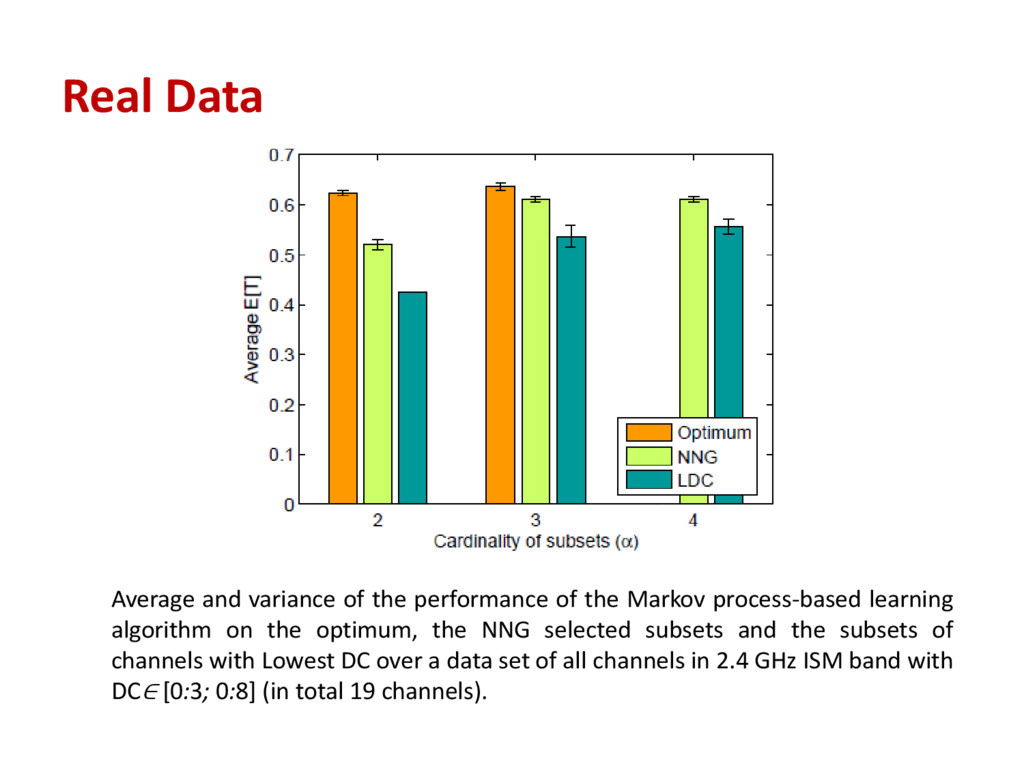
Markov process-based learning algorithm on the optimum, the NNG selected subsets and the subsets of channels with Lowest DC over a data set of all channels in 2.4 GHz ISM band with DC∈ [0:3; 0:8] (in total 19 channels).
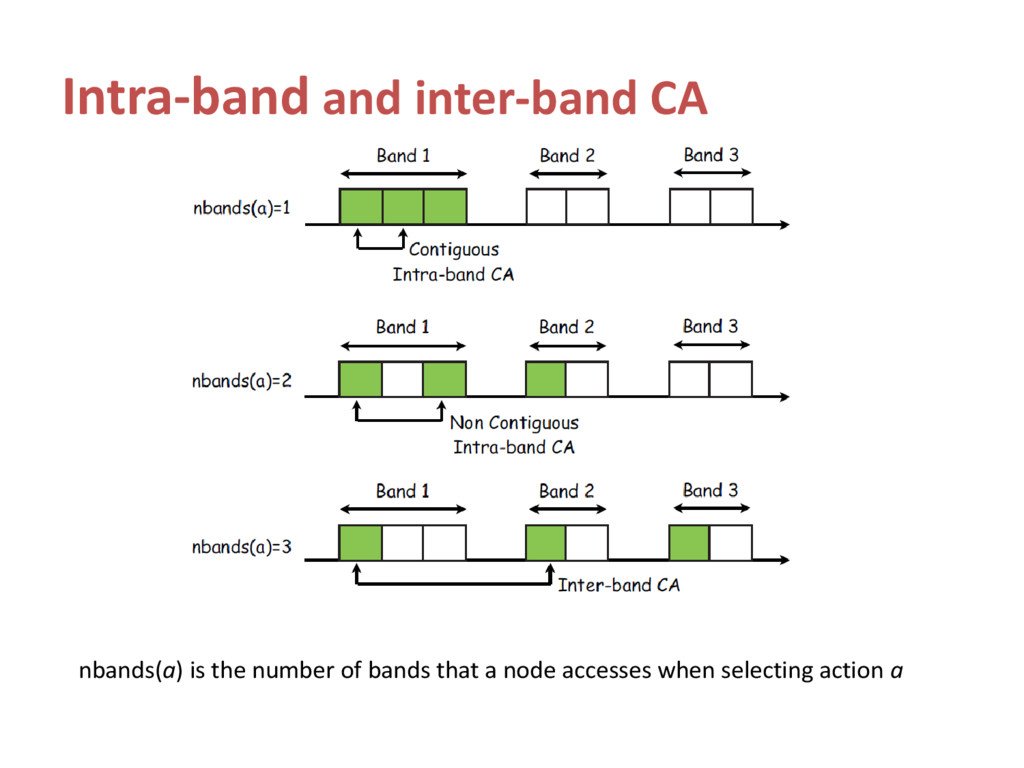
has been explored recently • Dynamic CA is possible in a distributed manner • Few works allow each network to aggregate non-contiguous channels in multiple frequency bands • Effect of out-of-channel (OOC) interference in adjacent frequency channels is not considered in existing works Ahmadi H, Macaluso I, DaSilva L.A, “Carrier aggregation as a repeated game: learning algorithms for efficient convergence to a Nash equilibrium”, Accepted in IEEE Globcom’13.
aggregation • Assign a higher cost to the inter-band CA • Model the problem of dynamic CA as a non-cooperative game • Propose learning algorithms that converge to a pure NE within a reasonable number of iterations under the conditions of incomplete and imperfect information
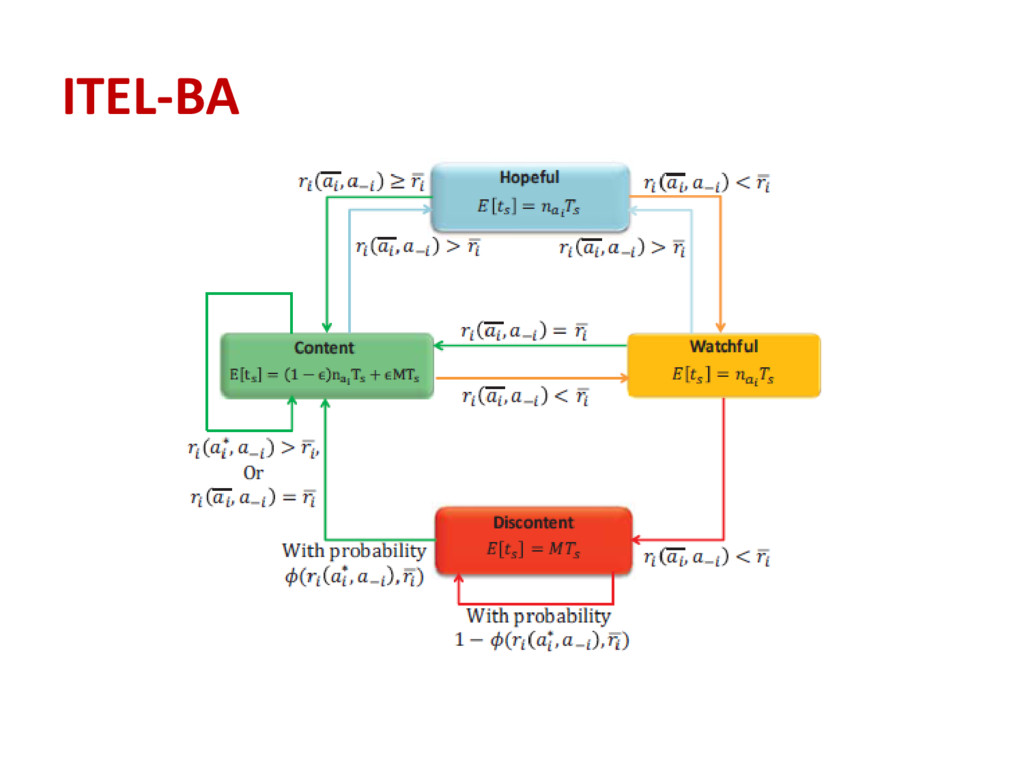
bands, each band has Kb channels • The cardinality of each network’s action space is: • The reward function of network i is • Distributed CA problem as a game denoted by G = (N,A, r)
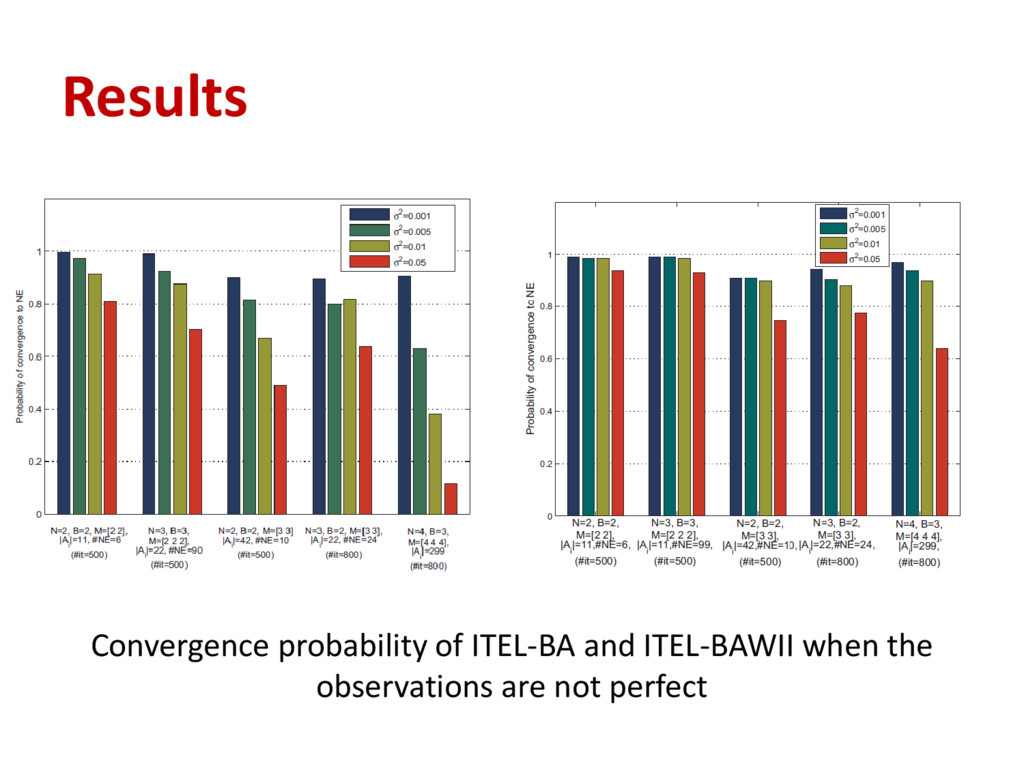
each player computes the received and hypothetical payoffs and then updates () using an n-sample weighted moving average • In ITEL-BAWII, when a player experiments with new actions either in content or discontent mood, she will select the action that maximizes the average estimated payoff () • The expected sensing time is TsM for all the states
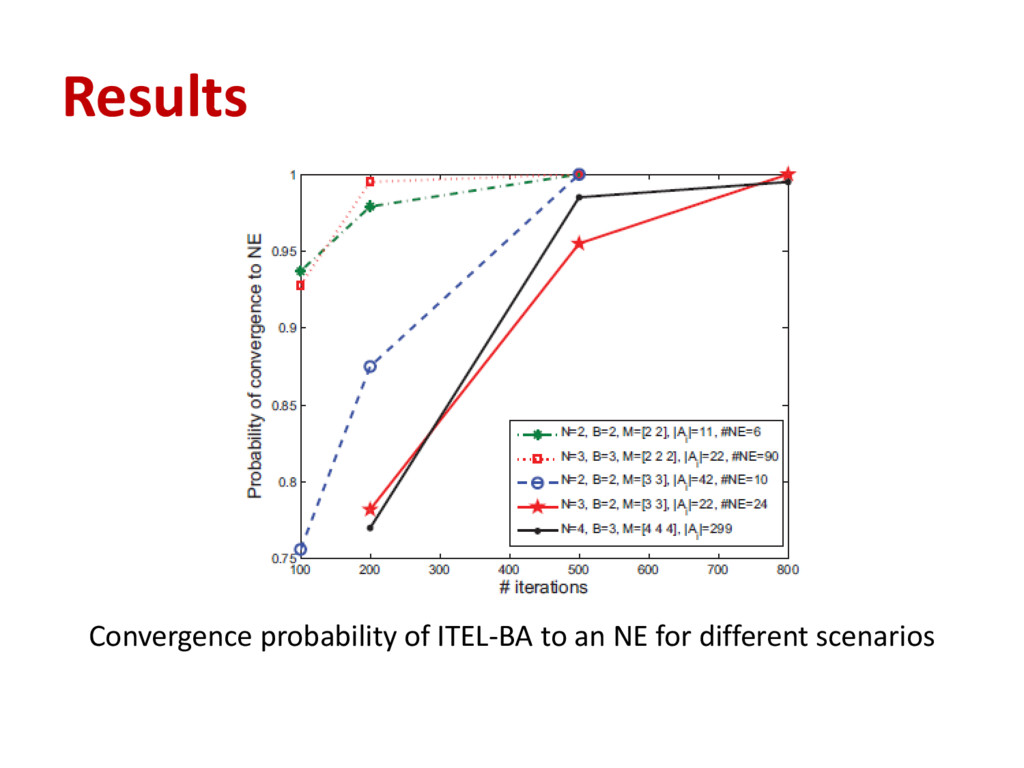
in shared spectrum as a repeated game • We proposed learning algorithms that efficiently converge to an NE without the need for complete or even perfect information • Our results show that the algorithm, which effectively converges to an NE with incomplete information (ITEL-BA), is not efficient in the case of imperfect information • Our algorithm that effectively deals with imperfect and incomplete information (ITELBAWII) requires additional sensing and computational resources
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}