Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
5.6 以前の InnoDB Flushing
Search
Takanori Sejima
March 07, 2015
Technology
17
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
5.6 以前の InnoDB Flushing
InnoDB のお話です
Takanori Sejima
March 07, 2015
More Decks by Takanori Sejima
See All by Takanori Sejima
(きっとたぶん)人材育成や教育のような何かの話
sejima
0
990
互換性のある(らしい)DBへの移行など考えるにあたってたいへんざっくり
sejima
1
3.8k
NAND Flash から InnoDB にかけての話(仮)
sejima
0
29
InnoDBのすゝめ(仮)
sejima
0
35
さいきんのMySQLに関する取り組み(仮)
sejima
0
26
sysloadや監視などの話(仮)
sejima
0
25
さいきんの InnoDB Adaptive Flushing (仮)
sejima
0
28
TIME_WAITに関する話
sejima
0
37
MySQLやSSDとかの話 その後
sejima
0
27
Other Decks in Technology
See All in Technology
システム監視入門
grimoh
5
740
2026年のソフトウェア開発を考える(2026/07版) / Agentic Software Engineering 2026-07 Findy Edition
twada
PRO
31
20k
データ活用研修 データマネジメント【MIXI 26新卒技術研修】
mixi_engineers
PRO
4
770
事業成長とAI活用を止めないデータ基盤アーキテクチャの設計思想
hiracky16
0
770
AIQAのナレッジ構築について
qatonchan
1
120
ソフトウェアアーキテクチャ研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
2
980
MCPをつなげて作る組織横断のAIエージェント基盤
tsubakimoto_s
0
300
実践が先生だった— 新卒サーバーエンジニア1年目のリアル
mixi_engineers
PRO
0
200
AIとハーネスで育てるトランスコンパイラ / 20260722 Yasushi Katayama
shift_evolve
PRO
4
1.1k
StepFunctionsとGraphRAGを活用した暗黙知活用のためのRAG基盤
yakumo
0
180
自己解決や回答速度を上げる、サポート業務へのAIの組み込み方【SORACOM Discovery 2026】
soracom
PRO
0
100
AIがコードを書く時代、人間は何を保証するのか———馬場さんと考える、開発者に求められる新しい責任と価値 - TECH PLAY
netmarkjp
0
320
Featured
See All Featured
"I'm Feeling Lucky" - Building Great Search Experiences for Today's Users (#IAC19)
danielanewman
230
23k
No one is an island. Learnings from fostering a developers community.
thoeni
21
3.8k
Distributed Sagas: A Protocol for Coordinating Microservices
caitiem20
333
23k
Information Architects: The Missing Link in Design Systems
soysaucechin
0
1k
Lightning Talk: Beautiful Slides for Beginners
inesmontani
PRO
2
610
Agile Actions for Facilitating Distributed Teams - ADO2019
mkilby
0
230
Statistics for Hackers
jakevdp
799
230k
Ten Tips & Tricks for a 🌱 transition
stuffmc
0
160
For a Future-Friendly Web
brad_frost
183
10k
The Power of CSS Pseudo Elements
geoffreycrofte
82
6.5k
Become a Pro
speakerdeck
PRO
31
6k
A Guide to Academic Writing Using Generative AI - A Workshop
ks91
PRO
1
360
Transcript
5.6 以前の InnoDB Flushing 瀬島 貴則
免責事項 - 本資料は個人の見解であり、私が所属する組 織の見解とは必ずしも一致しません。 - 内容の一部に偏ったものがあるかもしれません が、各自オトナの判断でよろしくお願いします。
自己紹介 - わりとMySQLでごはんたべてます - 3.23.58 あたりから使ってます - 一時期は Resource Monitoring
もよくやってま した - Twitter: @ts4th
今日のお題 - SSDはたくさん書いたら壊れます - checkpoint や InnoDB Adaptive Flushing や
double write buffer によって発生する書き込み 処理を踏まえ - 要件を整理し - 減らせるところは書き込みを減らして - SSDの寿命を延ばせないか考えます
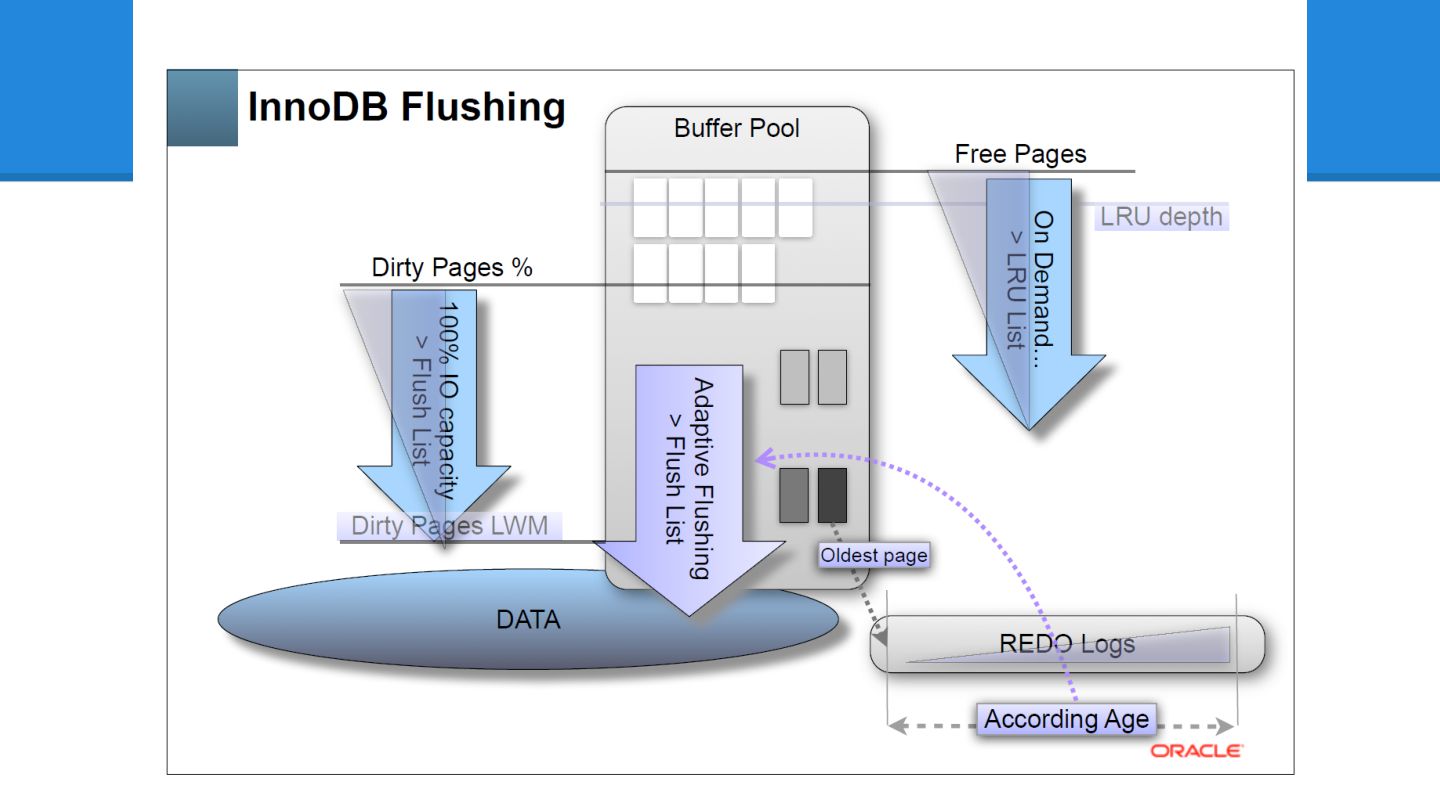
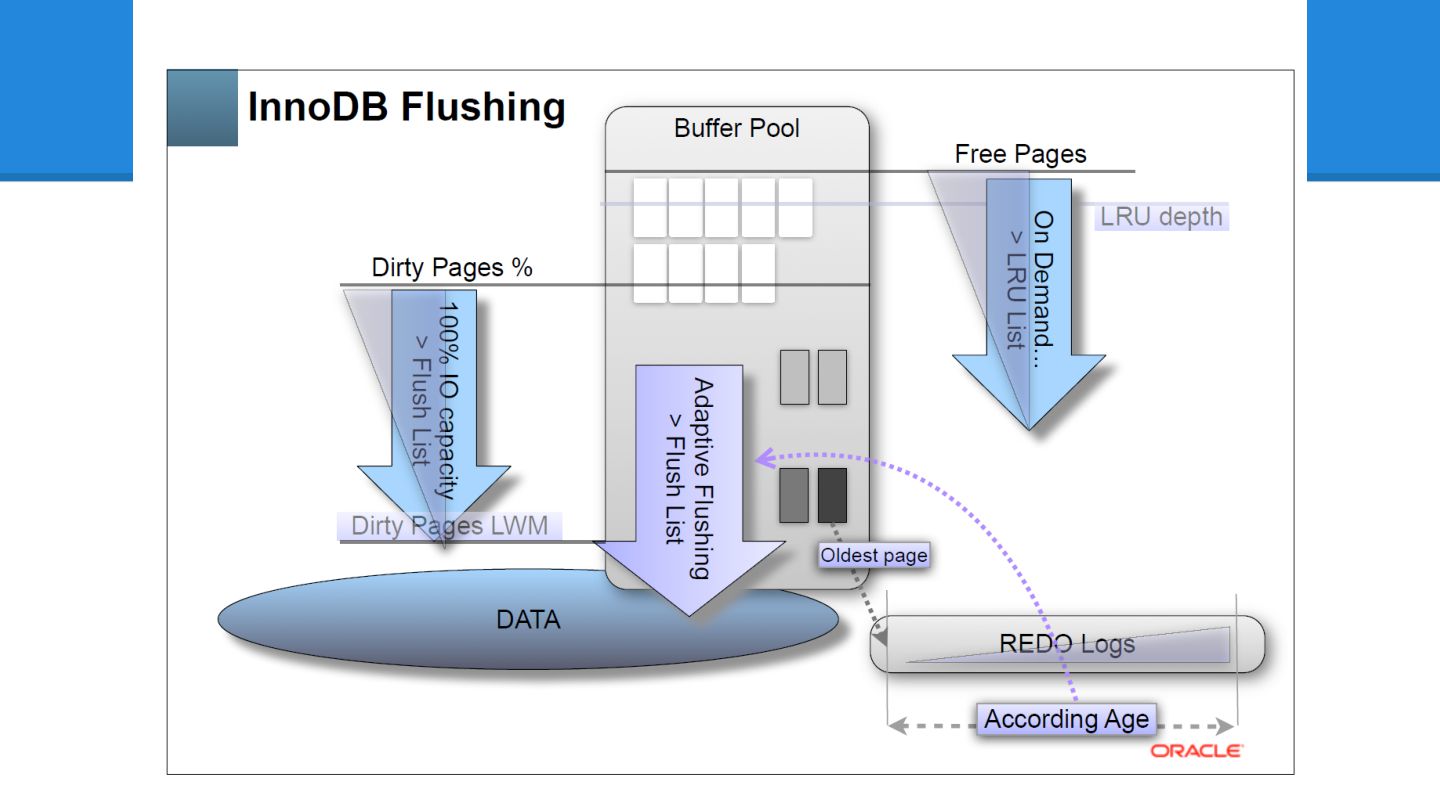
InnoDB Adaptive Flushing - かつてInnoDB Plugin 1.0.4 で追加されました - MySQL5.5
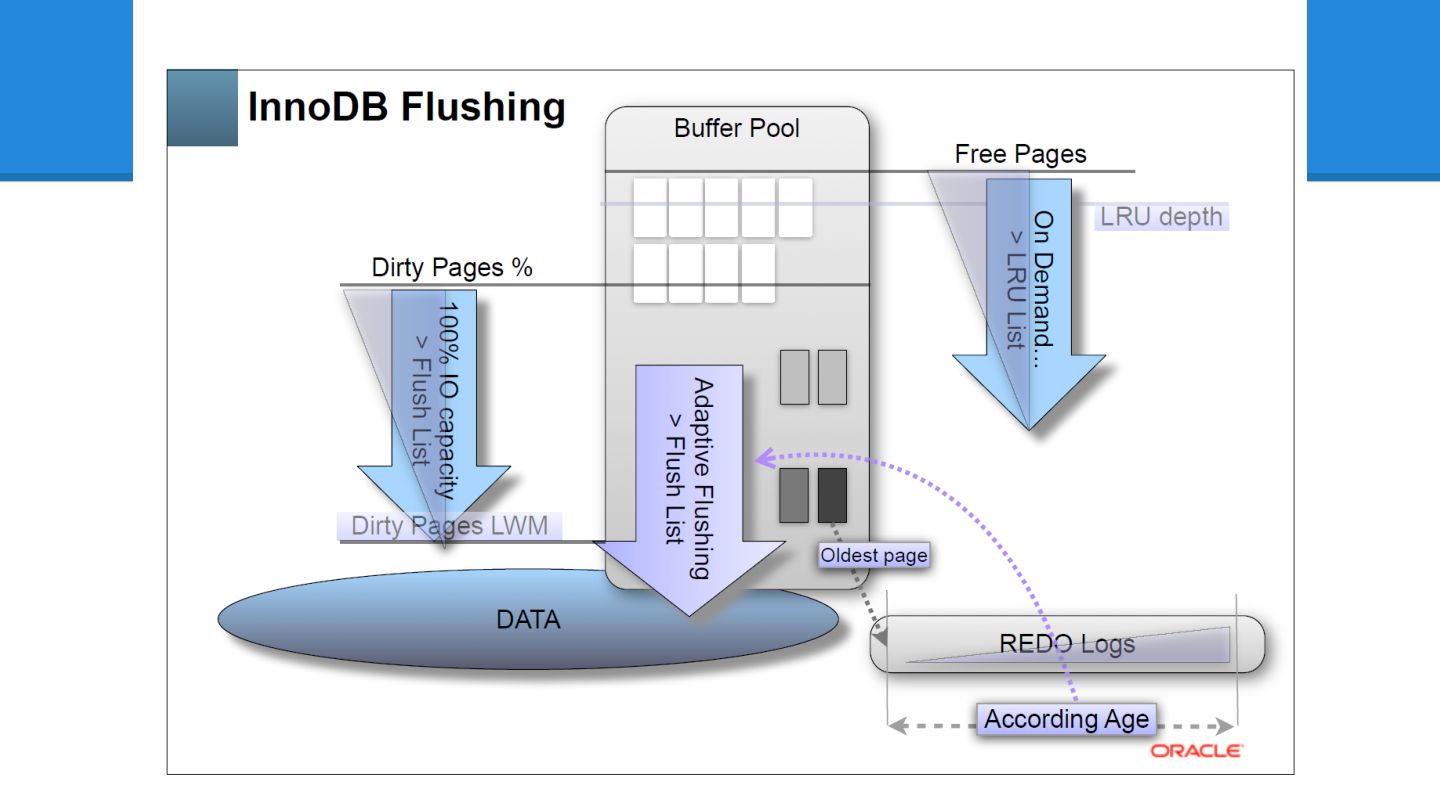
でInnoDB本体に組み込まれました - 当時としては、わりと画期的だったんですが - 5.6 でかなり良くなりました - 次の資料から図を拝借すると、現状こうです - MySQL Performance: Demystified Tuning and Best Practices [CON5097]
None
一つ一つ 見て行きましょう
InnoDBのファイル群 - ibdata1 - internal data dictionary・・・tableやindexのメタデータ - double write
buffer・・・耐障害性上げるためのバッファ - undo log・・・rollback segment - ib_log_file* - transaction log・・・ redo logs、 write ahead log - *.ibd - table space・・・ table のdataや index
redo log(write ahead log) - 更新内容は先ず log に書いて、 table space
に はあとでゆっくり反映 - 他のRDBMS でも用いられる手法 - logへの書き込みは sequential write になるの で、HDDでも速い - table space に反映するとき更新処理がまとめ られることも。 write combining
Log Sequence Number(LSN) - transaction log(ib_log_file*) のサイズは InnoDB の起動時に innodb_log_file_size
で 指定して決める(固定長) - transaction log は ring buffer というか cyclic というか circular fashion - InnoDB が transaction log を初期化して以降、 log の buffer に書いてきたバイト数が Log Sequence Number。
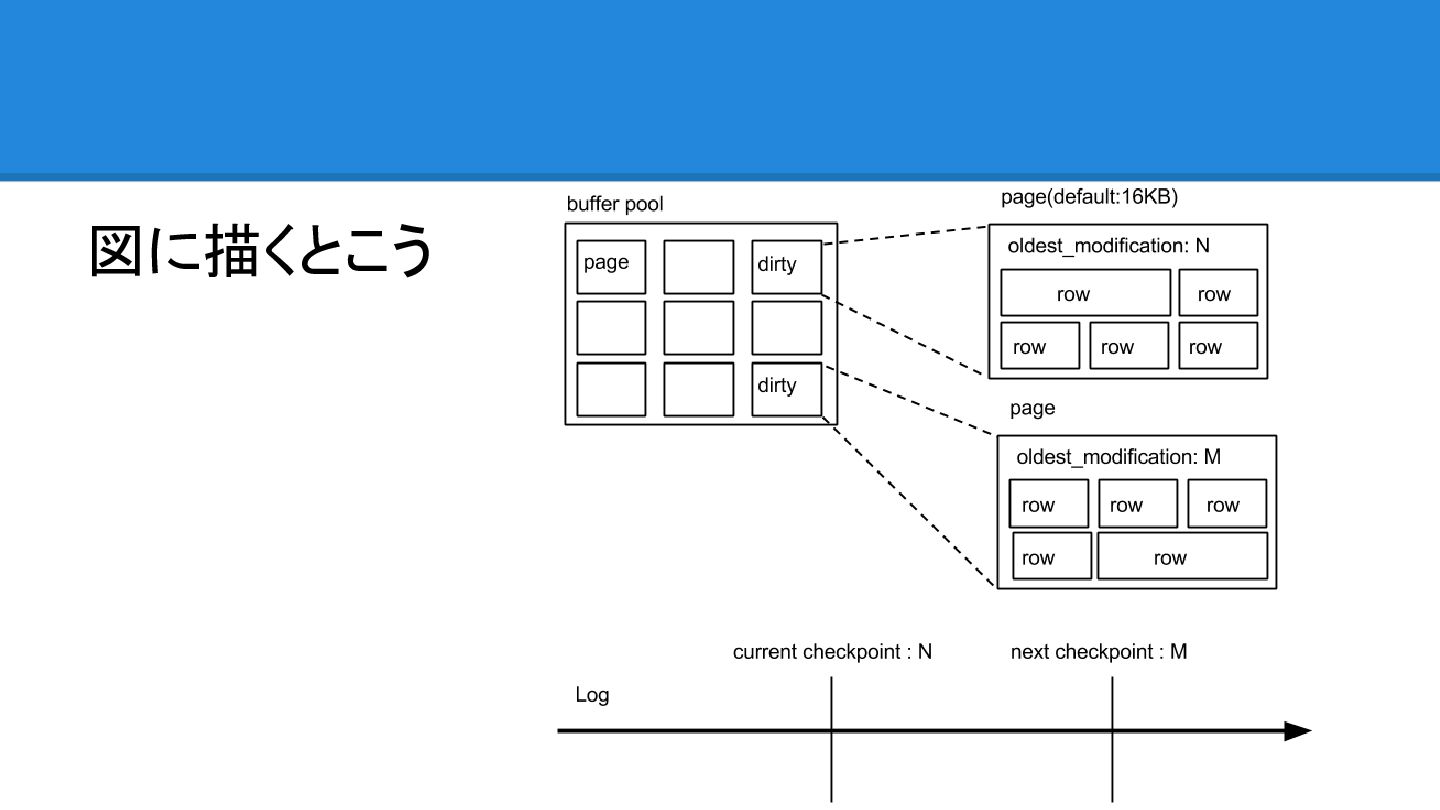
oldest_modification - page には oldest_modification というメンバ変 数がある - その page
が dirty になった最初のイベントが 書かれている log の position(LSN) が oldest_modification - dirty page をflushしてdiskに同期させると、そ の page の oldest_modification は 0 でリセッ ト
Last checkpoint at - buffer pool 上にある更新内容を、LSN 的に *. ibd
にどこまで書きだしたか示すものが Last checkpoint at。 - SHOW ENGINE INNODB STATUS で見える やつ
write combining - Last checkpoint at の進み方と disk I/O は必
ずしも比例しない - 同一の page への更新は まとめて disk に flush できる - 同一の page に格納されている複数の row への更新を、一回で disk に書けることも - log に溜めこみ、まとめて flush できるとお得
図に描くとこう
InnoDB Adaptive Flushing - log は有限なので使いきってはいけない - 具体的に言うと、(LSN - Last
checkpoint at) が max_modified_age_sync(75%くらい)を超え ると強制的に dirty page の flush 走る - 75%というのは定数ではなく、 log/log0log.cc の log_calc_max_ages() で計算してる - なるべく強制 flush 走らないように、 adaptive に flushing する機能
InnoDB Adaptive Flushing ない時代 - InnoDB Adaptive Flushing がない頃、いずれ かの状況にならないと
flush されにくかった - buffer pool 上で dirty page の比率が innodb_max_dirty_pages_pct(昔はdefault90、いまは default 75)を超える - redo log の使用率が max_modified_age_sync 超える
原初の InnoDB Adaptive Flushing - 5.1や5.5 の InnoDB Adaptive flushing
は、 master_thread という background で動いてる thread が、 innodb_io_capacity に応じて 他の タスクの合間に flush してた - むかしの master_thread は goto たのしいのでいちどよ んでみるとよいです
5.5以前のinnodb_io_capacity - io_capacity は正確にいうと iops ではない - master thread が一秒間にいくつ
page の i/o してもいいかという閾値 - 昔は、(select が多いなどして) disk read が多 いときは、 dirty page の flush を手加減してた - 例えば、ピークタイムに dirty page をあまり flush しない ことがあったとしたら、それは read が多いことが原因 だったり
- 5.5 以前の InnoDB Adaptive Flushing は、 io_capacity の範囲内で flush
してたので - 高速なストレージだからといって io_capacity 上げすぎ ると、 write combining が効かない - redo logを溜めずにつどつどflushしてしまう
もったいない
ここでもう一度、 Dimitri さんの図を 思い出してみましょう
None
5.6 で何が変わったのか - 公式ドキュメントとコードの乖離が激しくなった - コード読もう - InnoDB team blog
には意外と説明が書いてある - back ground thread の種類が劇的に増えた - 5.5以前だと master_thread でこなしていたタスクが複 数の thread で分散 - purge や dirty page の flush など特定のタスクが重 い場合、他のタスクがそれに引っ張られてしまうケー スがあったが、それが軽減された
- 関連する parameter が増えた - 重要なのはこのへん - innodb_adaptive_flushing_lwm(lwmは low water
mark の略) - innodb_io_capacity - innodb_io_capacity_max - MySQL5.6 の公式ドキュメントに書いてある io_capacity 関係の記述は説明不足感 - innodb_max_dirty_pages_pct_lwm
page cleaner thread - MySQL5.5までは、 InnoDB で master thread と呼ばれる
thread がいろいろやってた - dirty page の flush - change buffering - purge - 5.6 でこれらの機能が複数の thread に分割 - 5.6 で追加された thread の一つが page cleaner thread blogだと このへん
flush list と LRU list - buffer pool 上の page
は、昔から二種類の list で管理されている - flush list は更新された順(oldest_modification 順)に dirty page を管理 - LRU list はすべてのpage を対象に、参照され た順に管理 - 5.6 ではpage cleaner thread がこれらに対し てback ground でタスクをこなす
5.5以前の LRU list - 5.5 以前で LRU list が参照されるケースの一 つは、
buffer pool の page があふれたとき - disk 上のデータを読み込むとき、最も参照されていない page を破棄 - もし、そのpageがdirtyだったら、diskにflushしてから破 棄 - foreground の thread でも flush 終わるまで待たされる
page cleaner thread のタスク・その一 - 5.5以前は buffer pool をぜんぶ使い切る仕様 だったが、
5.6 からは innodb_lru_scan_depth で指定されただけ、 buffer pool の free page を残すようになった - 関数的には buf_flush_LRU_tail()
buf_flush_LRU_tail() - page cleaner thread は一定間隔でLRU listを 参照し、 innodb_lru_scan_depth で指定され
ただけ free page を確保しようとする。その際、 参照されてない page から破棄する。 - page を破棄する際、 その page が dirty であ れば disk に flush する。複数あればまとめて flush する
- 他のthreadは free page 確保するために dirty page の flush を待たなくて良くなった
- innodb_lru_scan_depth は、 free page 枯渇し ないなら、そんなに上げなくてもよいのでは? - buffer pool の miss hit が多い場合は検討して もよいかも
page cleaner thread のタスク・その二 - flush list を見て dirty page
を flush する - 5.6でここのアルゴリズムが賢くなった - 関数的には page_cleaner_flush_pages_if_needed()
page_cleaner_flush_pages_if_needed() - 一秒間にflush する page の数を redo log の 残量に合わせてコントロールするようになった
- redo log の使用率がinnodb_adaptive_flushing_lwm を超えない限りは積極的に flush しないので、write combining 狙いやすい - innodb_io_capacity_max 重要 - redo log の使用率が 60% くらいいくと io_capacity_max で指定しただけ flush する
- redo log の残量に比例して flush が激しくなる == io_capacity_max に近づくので、書き込み の多いサーバに高性能なストレージを割り当て
ると、 default の設定でもそこそこ flush するよ うになった
innodb_max_dirty_pages_pct_lwm - default の 0 じゃないなら - これ と これ
の比較をしてflush の頻度が変わ る - transaction log より buffer poolの方がサイズ 大きいケースがほとんどだと思うので、そこまで 意識しなくてもいい気がする
しかし5.6の page cleaner は未完成 - page_cleaner: aggressive background flushing -
いやーしょーじきビミョーだけど - idle気味なとき、 io_capacity(maxではない)全 開まで flush してしまうケースがありえるそうな
- make dirty page flushing more adaptive - すごいざっくりいうと -
いまの Adaptive Flushing は flush list 優先の 仕組みで、 ほとんどのケースはうまくいくんだけ ど、 状況に応じて LRU list の flush をもっと優 先できるといいよね
なるほど
中の人がドキュメントで 説明したくない気持ちが わかった
(めんどくさい)
しょうじき 言いたい かもしれない
///) /,.=゙''"/ / i f ,.r='"-‐'つ____ こまけぇこたぁいいんだよ!! / / _,.-‐'~/⌒ ⌒\ / ,i ,二ニ⊃(
•). (•)\ / ノ il゙フ::::::⌒(__人__)⌒::::: \ ,イ「ト、 ,!,!| |r┬-| | / iトヾヽ_/ィ"\ `ー'´ /
これらを踏まえて もう一度
None
とりあえず、 5.6 では - 5.5 以前から 5.6 に移行するだけで、 Adaptive Flushing
が賢くなる - SSD使ってるなら 5.6 にした方がよい - innodb_log_file_size を増やしたり、 innodb_adaptive_flushing_lwm を上げたりす るのは、SSDの書き込み寿命を伸ばすのに効 果的ですねきっと
ただ、やりすぎは禁物で - innodb_log_file_size や、 innodb_adaptive_flushing_lwm を増やすと、 クラッシュリカバリの時間ふえます。 - log_file_size がデカすぎると
page cache 持っ て行かれます - innodb_io_capacity_max はうまく使いましょう
あるいは、平滑化したいのであれば - innodb_flushing_avg_loops - innodb_adaptive_flushing_lwm 上げ過ぎない ほうがいいかも - 実際に検証するのが一番なんだけど -
page_cleaner_flush_pages_if_needed() 読む のオススメ
次に
double write buffer - 耐障害性を上げるための機能 - 具体的には torn page 対策
- double write するからといって、 iops が倍にな るというわけではない。ほぼバッファリングされ る - 書き込まれる量は倍くらいになる - 詳しくは buf/buf0dblwr.cc
- double write buffer は 合計 64*2 page、 page cleaner
が主に使うのはそのうちの 120 page - page cleaner が LRU list や flush list から page を flush するとき、対象の page を buf_dblwr_add_to_batch() して double write buffer にためて、最後に ibdata1 と *.ibd に書 き出す。
- LRU list や flush list から buf_dblwr_add_to_batch() で double
write buffer buffer にのせてる最中に 120 page 使 いきったら、その時点で buffer から flush する
やや細かく言うと - 120 page を ibdata1 に書くときは 64*16KB と (64-8)*16KB
の二回に分けて。 - メモリ上の double write buffer から ibdata1 に 書きだしたら、次は *.ibd へ io_submit() - このへんから - 最後に io_handler_thread が更新された *.ibd を fsync() して終わり
閑話休題 - innodb_flush_method - O_DIRECT で fsync() する? - O_DIRECT_NO_FSYNC
- filesystem 過信しない
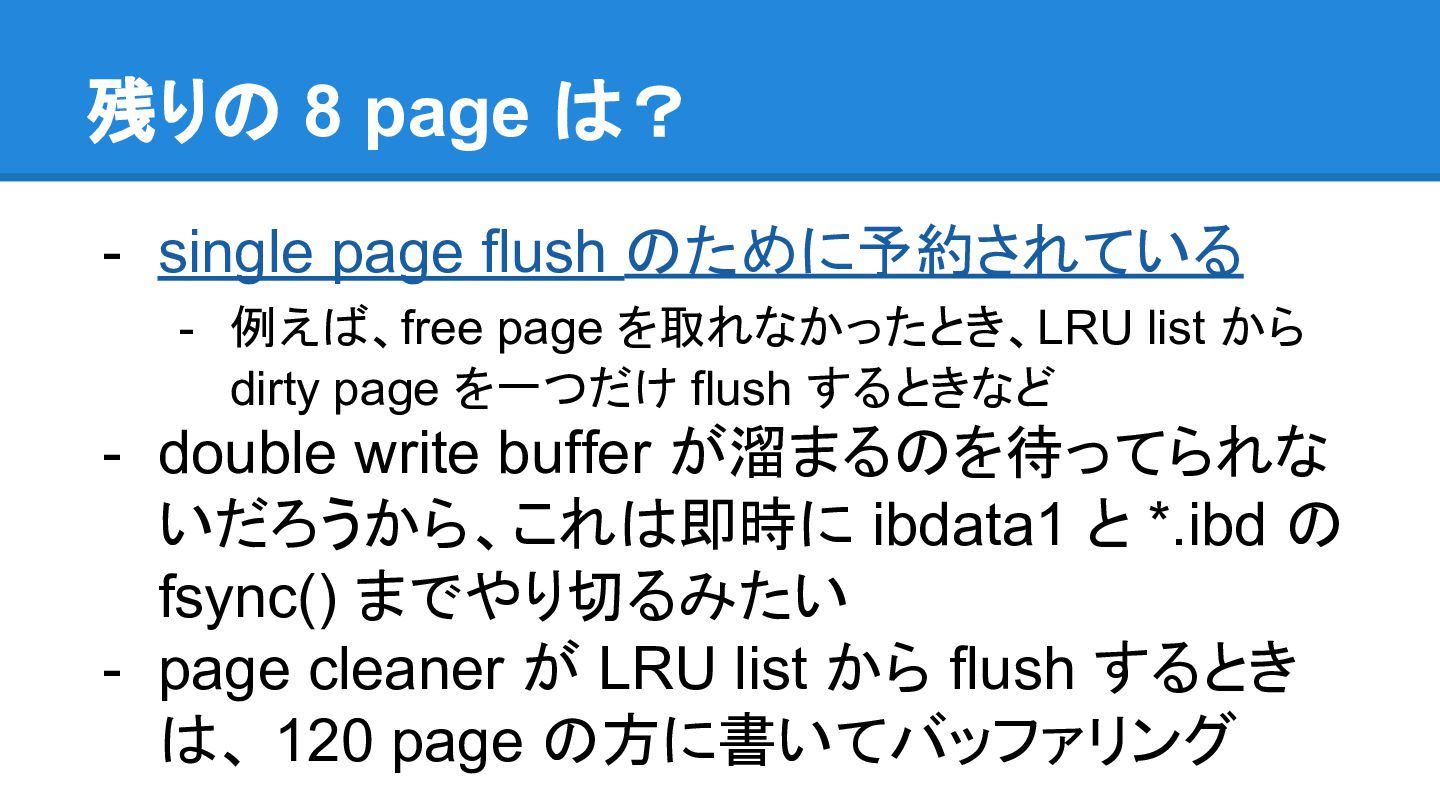
残りの 8 page は? - single page flush のために予約されている -
例えば、free page を取れなかったとき、LRU list から dirty page を一つだけ flush するときなど - double write buffer が溜まるのを待ってられな いだろうから、これは即時に ibdata1 と *.ibd の fsync() までやり切るみたい - page cleaner が LRU list から flush するとき は、 120 page の方に書いてバッファリング
つまるところ - page cleaner が buffer pool から *.ibd に
flush するところは、 buffering されている - disk へ書き出すところは double write buffer によって serialize されてる - single page flush で double write buffer を flush してるとき、 page cleaner は待たされる 可能性がある。逆もある。
補足 - 5.6 の page cleaner は buffer pool instance
の数だけループを回しているところがあるんで すが、 LRU list からの flush や flush list から の flush は、そのループの中で実行されてい て、 double write buffer から ibdata1 への flush も、その中で行われるので、 instance 多 いと fsync() ふえます。
考えうる残念なシナリオ - page cleaner が flush list から大量に flush し
まくってるとき(120page*N回 flush してるとき) に single page flush がくると、 single page flush と mutex 取り合いになりそう
performance killer? - Dimitri さんが double write buffer がボトルネッ クだと言うのもわかる気がする
- buf_dblwr_add_to_batch() は 120 page 溜ま ると、それがはけるまで buf_dblwr->mutex とり あう可能性がある - よっぽど write intensive なときだろうけど
時代が変わった - HDDだと double write buffer 良かったと思う - いまはPCI-e SSD、コアたくさんのCPUとかあ
るので、よもやまさかのボトルネックになる可能 性 - ただ、性能面に関していうと、 Dimitri さん未来 に生きてるから - 彼は未来に備えてボトルネックとなりうる要素を潰さない といけないと思うから
- 現時点では、ほんとにまずいかどうか、各自検 証してから見なおせばいい - そもそも、そんなに書き込み激しい master だっ たとしたら、 slave 追いつけないかもしれないし
double write buffer でみるところ - どれくらいの頻度で double write buffer から
disk に flush されてるか気になるなら Innodb_dblwr_writes や Innodb_dblwr_pages_written を見ればOK - single page flush でも +1 されるので、 free page たりなくって Innodb_dblwr_writes 増えて るなら、 innodb_lru_scan_depth 見なおすとか
double write buffer 無効化する前に - 以下の対応で性能改善できるかも - single page flush
を抑制するために、 free page が枯 渇しないよう、 innodb_lru_scan_depth みなおす - flush list からの flush を最適化(write combining)する ために、 innodb_log_file_size を大きくする。 - innodb_adaptive_flushing_lwm 見直す - SSD なら innodb_flush_neighbors = 0 - 古くない page なら double write buffer に書き込む のを先送りしても良い感
5.7 の Atomic Write - Fusion-io 使うなら、MySQL5.7から Atomic Write が使えるようになる
- すごいざっくり言うと、 double write しなくても書 き込みの完全性が保証される - double write buffer の代わりに atomic write 使えば、Fusion-io への書き込み減らせるし性 能も改善されるようだし良いコトずくめ
ext4 の data=journal - double write buffer の代わりに file system
に 頑張ってもらう案 - Dimitri さんオススメ percona の人も検証してた - percona の人も言ってるけど、環境に依存する から、ちゃんとテストしてから使ったほうがいい - filesystem からだって bug は出ることがある
- あと、 data=journal にしちゃうと O_DIRECT 使えないそうな - https://www.kernel. org/doc/Documentation/filesystems/ext4.txt -
Enabling this mode will disable delayed allocation and O_DIRECT support.
あと、5.7ではこれが入る - innodb_log_write_ahead_size - 詳しくは (4) Avoiding the ‘read-on-write’ during
transaction log writing - facebook も percona もやってた件ですね - これで page cache に載り切らないくらい redo log を大きくしたときの性能が改善するので - とにかくでかくして flush 減らすのもありかも
ここから先は、 人によって見解が分かれる (はずなので) 自己責任でお願いします
skip-innodb-doublewrite - innodb_flush_log_at_trx_commit={0,2} なら - そもそも、 commit 時に disk への
sync が保証 されてないので、 skip しても良いのでわ - これで書き込む量ほぼ半分 - master がHAクラスタなら、slaveは検討しても よいのでわ - あるいはMHA使ってるなら
innodb_log_group_home_dir - slave がクラッシュセーフでなくてもいいならば - redo log は disk 上になくてもいいんじゃない?
- innodb_log_group_home_dir=/dev/shm - log_file_size は InnoDB 起動時にサイズが固 定されるので、 tmpfs 向き - もともと redo log は O_DIRECT で open され ないので、 page cache でメモリ持っていくし
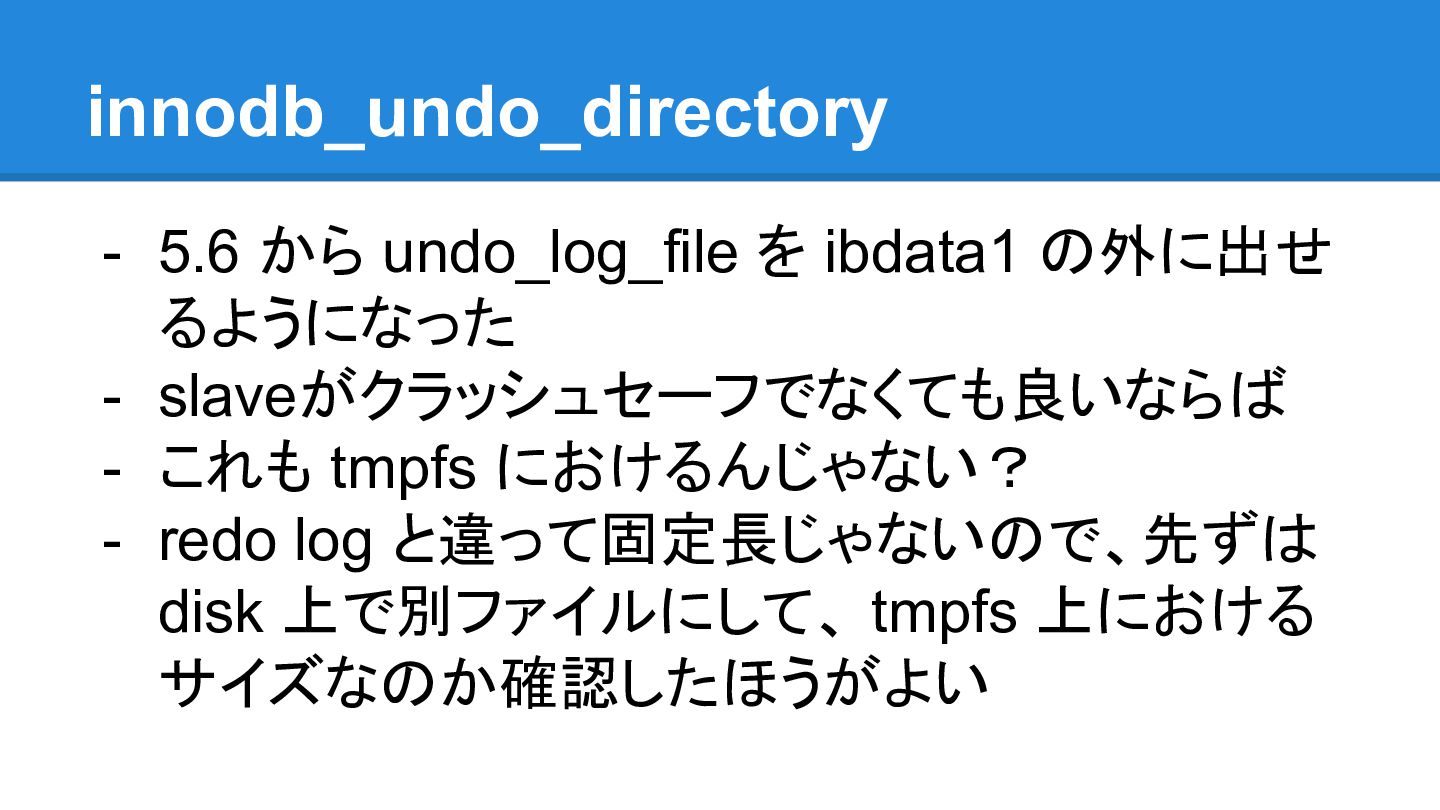
innodb_undo_directory - 5.6 から undo_log_file を ibdata1 の外に出せ るようになった -
slaveがクラッシュセーフでなくても良いならば - これも tmpfs におけるんじゃない? - redo log と違って固定長じゃないので、先ずは disk 上で別ファイルにして、 tmpfs 上における サイズなのか確認したほうがよい
- undo log を ibdata1 の外に出そうとすると ibdata1 作りなおしなので、試すのがめんどくさ いけど -
skip-innodb-doublewrite や redo log を tmpfs に移動するだけなら、 mysqld 再起動だけで済 むので、運用上試しやすい
おまけ - 今後気になることは、このblogに書かれてる - http://mysqlserverteam.com/mysql-5-7-improves- dml-oriented-workloads/ - Future improvements -
Implementing improvements to the adaptive flushing algorithm (suggestion by Dimitri Kravtchuk) - これは実装されたらコード読みたい
参考 - Configuring InnoDB for MySQL 5.6: innodb_io_capacity, innodb_lru_scan_depth -
MySQL 5.6: IO-bound, update-only workloads - InnoDB adaptive flushing in MySQL 5.6: checkpoint age and io capacity
まとめ - 5.6 の Adaptive Flushing オススメです - SSD使ってる人は5.6以降にあげましょう -
log_file_size や adaptive_flushing_lvm 意識しましょう - double write buffer 切る前に - I/O減らせる要素はあります - Dimitri さんは未来に生きてます(きっと) - ともあれ、じっさいに検証しましょう
おわり
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}