Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
EthernetやCPUなどの話
Search
Takanori Sejima
October 22, 2015
Technology
24
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
EthernetやCPUなどの話
EthernetやCPUなどのお話です
Takanori Sejima
October 22, 2015
More Decks by Takanori Sejima
See All by Takanori Sejima
(きっとたぶん)人材育成や教育のような何かの話
sejima
0
990
互換性のある(らしい)DBへの移行など考えるにあたってたいへんざっくり
sejima
1
3.8k
NAND Flash から InnoDB にかけての話(仮)
sejima
0
29
InnoDBのすゝめ(仮)
sejima
0
35
さいきんのMySQLに関する取り組み(仮)
sejima
0
26
sysloadや監視などの話(仮)
sejima
0
25
さいきんの InnoDB Adaptive Flushing (仮)
sejima
0
28
TIME_WAITに関する話
sejima
0
37
MySQLやSSDとかの話 その後
sejima
0
27
Other Decks in Technology
See All in Technology
現場との対話から始める “作る前に問い直す”業務改善
mochico50
2
340
大 AI 時代におけるC# の事情 ~ぶっちゃけトークを交えながら~
nenonaninu
1
530
AIQAのナレッジ構築について
qatonchan
1
130
StepFunctionsとGraphRAGを活用した暗黙知活用のためのRAG基盤
yakumo
0
190
新たなDBアーキテクチャ「LTAP」にDeep Dive!!
inoutk
0
150
書籍セキュアAPIについて
riiimparm
0
380
エンタープライズデータへ安全につなぐ Production-ready なエージェント設計 ― AI × MCP リファレンスアーキテクチャ ― #AIDevDay
cdataj
1
260
QAと開発の両側から進める AI活用 -QAプロセスAI支援ツールキットと Inner Loop / Outer Loopの取り組み-
legalontechnologies
PRO
2
360
AIエージェントの知識表現と推論に なぜグラフが使われるのか - 記号的AIの復権とニューラルAIとの統合
yohei1126
1
200
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
Claude Code並行開発環境の ムダ‧ムラ‧ムリを見直した話
muranakaaa
0
300
事業成長とAI活用を止めないデータ基盤アーキテクチャの設計思想
hiracky16
0
770
Featured
See All Featured
Marketing to machines
jonoalderson
1
5.6k
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
200
Art, The Web, and Tiny UX
lynnandtonic
304
22k
The Pragmatic Product Professional
lauravandoore
37
7.4k
Practical Tips for Bootstrapping Information Extraction Pipelines
honnibal
25
2k
DevOps and Value Stream Thinking: Enabling flow, efficiency and business value
helenjbeal
1
270
How to Build an AI Search Optimization Roadmap - Criteria and Steps to Take #SEOIRL
aleyda
1
2.1k
Facilitating Awesome Meetings
lara
57
7k
Understanding Cognitive Biases in Performance Measurement
bluesmoon
32
3k
Data-driven link building: lessons from a $708K investment (BrightonSEO talk)
szymonslowik
1
1.2k
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.5k
Learning to Love Humans: Emotional Interface Design
aarron
275
41k
Transcript
EthernetやCPUなどの話 sejima
免責事項 - 本資料において示される見解は、私自身の見 解であって、私が所属する組織の見解を必ずし も反映したものではありません。ご了承くださ い。
自己紹介 - そこそこ MySQL でご飯食べてます - ことし書いた資料 - いまの会社に入る前は、MMORPGのDB設計 などもしてまして
- 一時期は Resource Monitoring や KVS にも 力入れてました - Linuxとハードウェアは嗜む程度 - disk I/O にはむかしから興味あります
さて今回は - Linux を前提に - サーバサイドエンジニアの観点から、 Ethernet などのサーバの I/O に関する状況を見渡して
- これから先のことを考えてみることにします - マサカリ歓迎します
先ず参考書籍 - 最近、今年の6月に和訳された 詳説 イーサネッ ト 第2版 を読んだんですが - すべてのインフラエンジニアやサーバサイドエン
ジニアが、この書籍を読む必要性があるかとい うと、微妙 - MMORPGみたいに、ネットワークの要件が厳し いコンテンツ作る人は、読んでいいかも
先ず振り返ってみましょう - Ethernet はどれくらい進化 してきたのか? - 100Base-TX は 90年代、 GbE
が普及してきた のは 21世紀に入ってきてからかな? - 2010年代、現代においては、 サーバでは 10GbE がだいぶ普及してきたという実感がある - 十年周期くらいの進歩と捉えたら、2020年代に は、やっぱ次の規格が普及するんじゃん?
最近、いろいろ Ethernet のことを 調べてて思ったのは
光ってスゲェ
最初に光ファイバーで実装される - Ethernet で新しい仕様が策定されたとき、最初 に光ファイバーで製品化されるとのこと - ノイズに強い(というか電磁的なノイズの影響受 けない)し、伝送距離長いし - 伝送距離長いので、一番帯域が不足するバック
ボーンネットワークで使われるようになる - 取り回しがめんどくさいのと、良いお値段するの が難。光トランシーバが別途必要だし
ツイストペア対応した頃に普及する - ツイストペアケーブルで実現されるのは、光ファ イバーで製品化された後になる - オンボードのNICが対応すれば、追加のハード ウェアを購入しなくても、新しいEthernetの仕様 に対応できるようになる。なので普及しやすい - その頃には、
switch などの価格もこなれてるっ てことでしょうな
近年、10GBASE-Tが普及してきたのは - 最初はPHYの消費電力的に厳しかったみたい - エラーレート下げるために導入したLDPCが電気食う - 2006-2008年頃だと、48ポートのスイッチを作ろうとした ら下手すると1KW近い消費電力になってたらしい - 微細化が進んで、PHYの消費電力が減って、こ
こ数年で10GBASE-T 普及してきたそうな - Siemonのホワイトペーパー にもそのように
今後は - 100GbE まではすでに製品がある - 流石に100GbEはツイストペアケーブルやらないらしい - 400GbE は2017年に仕様決まるらしい -
40GbE はいまのところ光ファイバーのみだけ ど、 40GBASE-T を実現するための Category 8 Cable がいま作成中とのこと - (月並みだけど)Category 8 が来るころには、 40GbE の普及率上がってくるんじゃない?
40GBASE-Tが普及するのって - 10GBASE-T のときは、 2006 年に標準化完了 して、2009年にはアキバに出回り始めた - 実際にデータセンターで普及し始めたのは、 2010年に入ってからとしても
- 40GBASE-Tが2016年くらいに標準化完了し て、もし同じペースで普及するとしたら、2020年 あたりから出回り始めるんじゃないかなぁ
いやホント光ってすごいですね - 銅線だとエラーレート高いから、改善するために 導入したLDPCがPHYの電力食うから - シリコンの微細化を待ってる間に、何年も経って しまった。微細化して改善したのもすごいけど - 最終的に、銅線の10GBASE-Tが普及しつつあ るとしても
- 光ファイバーだと、銅線の何年も先の技術を使 えるという
と、いうわけで - いま10GbE で動いてるところが、2020年代に は 4倍以上帯域が太くなってる可能性がありま す。いま GbE なら40倍以上です -
40GbEはすでにある技術ですが、例によって、 Web業界のサーバには、他所である程度普及 した後、お下がりのようにやってくると思います - 40GBASE-T がWeb業界に来るのに備えて、 それを活かす準備をしたいものです
Ethernet のことを調べてて思ったのは - ここ数年で「40GbE普及する」「日本は40GbEス キップして100GbEが普及する」という話をされ てる方の多くは - サーバサイドエンジニアじゃなくって、ネットワー クエンジニアさんじゃないかな? -
サーバと Rack Of Top のswitchの間じゃなく、 DC内のネットワークについて話されてるんだと
個人的に、 私の感覚で 言わせてもらうと
Ethernet で 100Gbps分の フレーム受信してたら、 サーバはCPUを ガンガン使っちゃうんすよ
ネットワークの進化とCPUの進化 - 今後、NIC が進化したら、NICは数十Gps以上 のトラフィック送受信できるようになりますが - そんだけのデータ受信しつつ、CPUがいろいろ 処理できるかは別問題 - たくさんフレーム受信するのはとにかくCPU的に重い
- いろいろ改善するために、 Linux やハードウェ アベンダーさんは取り組んでますが - 参考: syuuさんのありがたい資料
それでも、むかしよりは良くなった - MSI-X 対応のNIC出たてのころ、個人的に、ま ともに動く気がしなかった - 最近だと動くようになってるから、技術の進歩マジすごい - むかしは disable_msi
とか設定してたのに・・・ - 余談だけど、Windows は Vista の時点で MSI-X をデ フォルトで有効にしてたらしい。 Windows さすが。 - Receive Side Scaling (RSS)の存在も大きい - ただ、RSSはハードウェアの制限がある
RSS意識するときは注意しよう - I350のデータシート P.45 の表を見てみると、 I350 はRSSのキューが 8 つまで、 82599
は 16 まで。つまり、NICがサポートしてるキューの 数までしか、CPUのCore分散できない。 - また、 最近のXeonは選択肢が数多くあるの で、 Xeon E5-2637 v3 のようにクロック高いけ ど Core が少ないCPUでは、16個もキューが あっても使い切れない
オンプレでNICの選定ってかなり重要 - むかし、出たてのNICは冗談抜きでストールす ることがあった - 数年前、私は諦念とともに disable_msi を設定した - どんなNICでもスループットは出せるかもしれな
い。でも、ショートパケットを大量にさばけるか は、NICによって異なる。RSS対応してて欲しい - 用途を考えて評価し、最適なものを選択するこ とが重要
では、 10GbE でどれくらいCPU使うのか - むかし同僚に教えてもらった uperf と - 次の組み合わせで試しました -
Xeon E5-2630 v3 - 10GbE(Intel 82599) - 保守的にMTU1500で - Ubuntu 14.04.3 LTS - kernel 3.13 x86_64 - glibc 2.19 - gcc 4.8.4
めも - uperf 1.0.4 をビルドするのにここだけいじりまし た - https://gist.github. com/sejima/c5207d539969c56ca6d0 -
あとは - $ ./configure --disable-sctp --enable-cpc
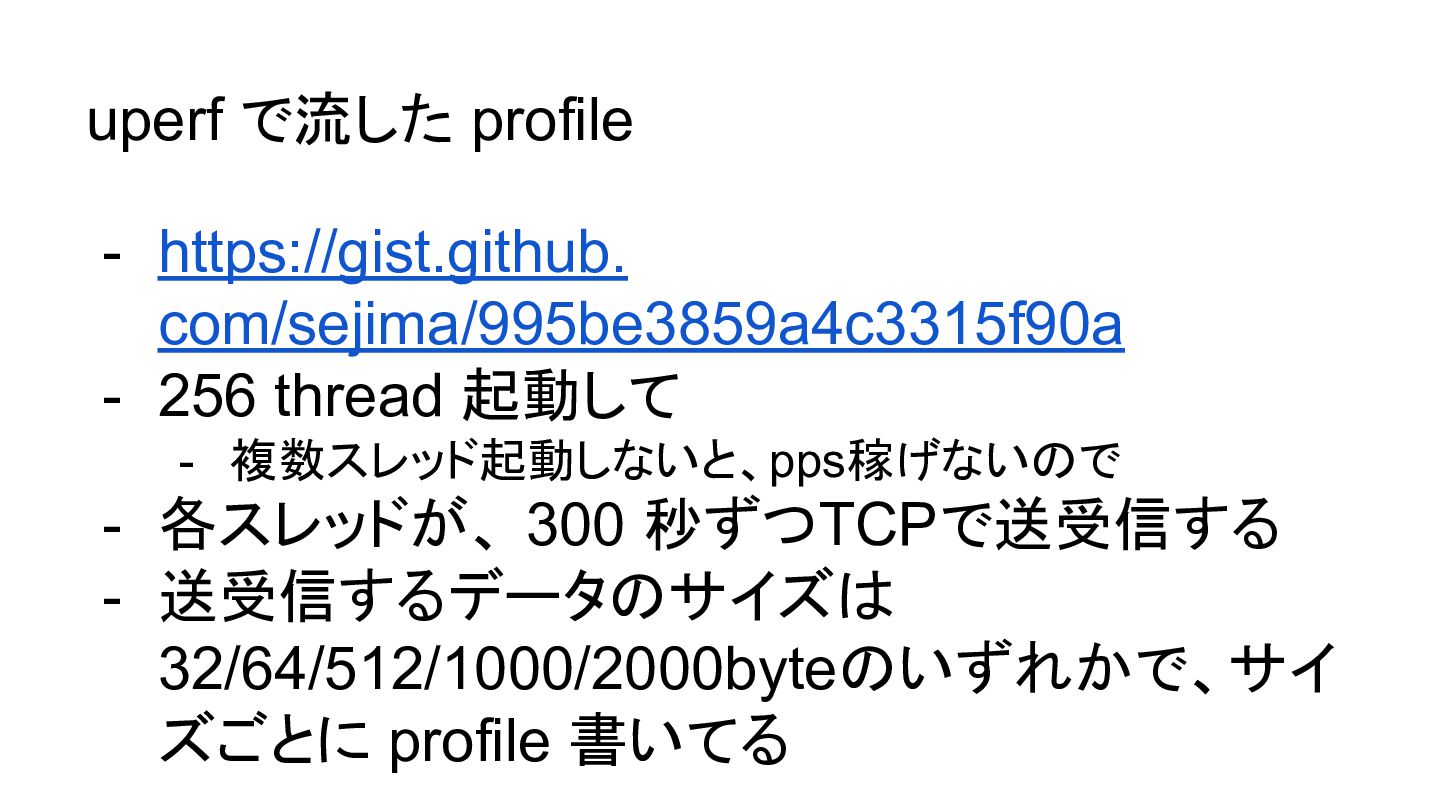
uperf で流した profile - https://gist.github. com/sejima/995be3859a4c3315f90a - 256 thread 起動して
- 複数スレッド起動しないと、pps稼げないので - 各スレッドが、 300 秒ずつTCPで送受信する - 送受信するデータのサイズは 32/64/512/1000/2000byteのいずれかで、サイ ズごとに profile 書いてる
CPU Scaling Governor など - scaling_governor は performance と ondemand
で比較します - あと、 kernel の boot parameter でintel_idle. max_cstate=1
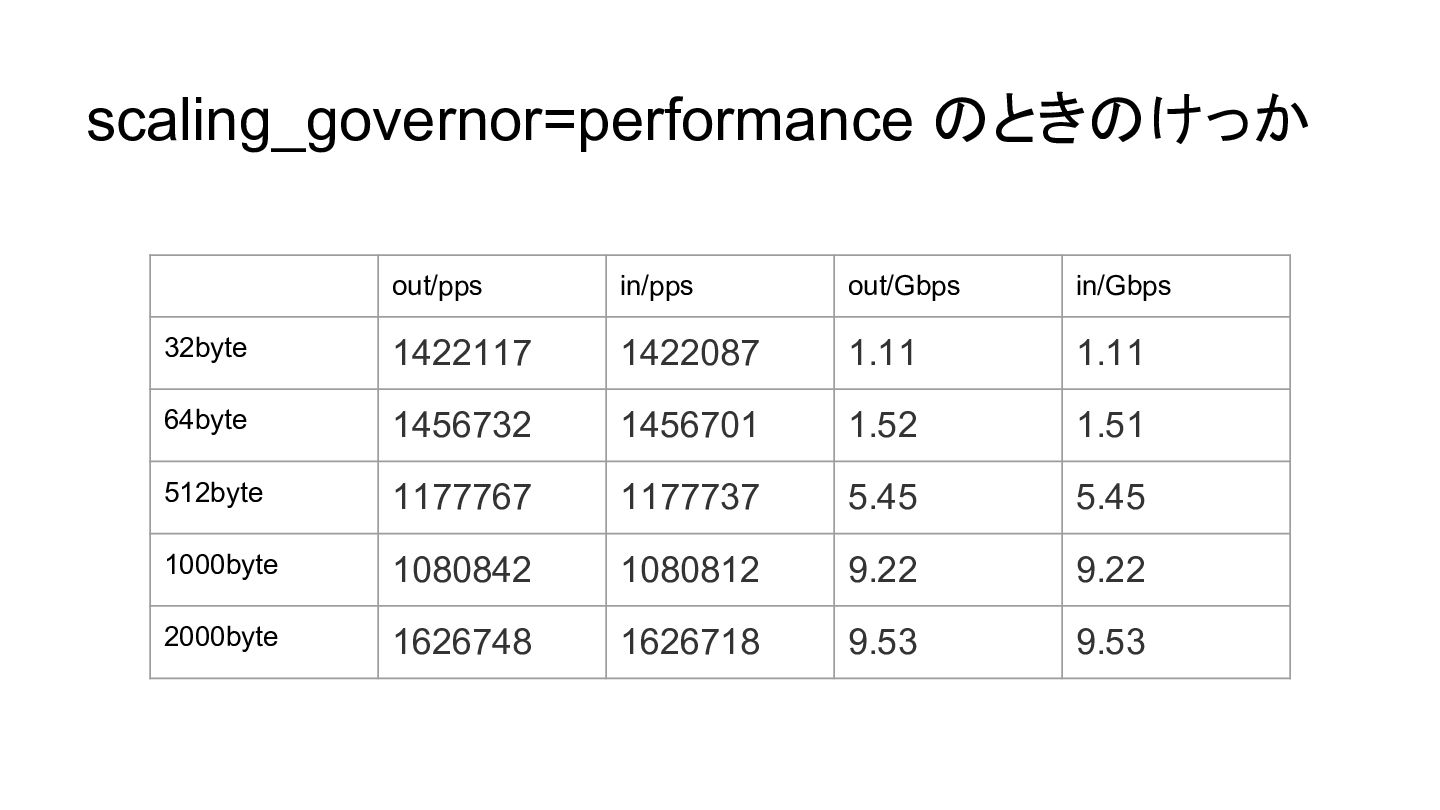
scaling_governor=performance のときのけっか out/pps in/pps out/Gbps in/Gbps 32byte 1422117 1422087 1.11
1.11 64byte 1456732 1456701 1.52 1.51 512byte 1177767 1177737 5.45 5.45 1000byte 1080842 1080812 9.22 9.22 2000byte 1626748 1626718 9.53 9.53
None
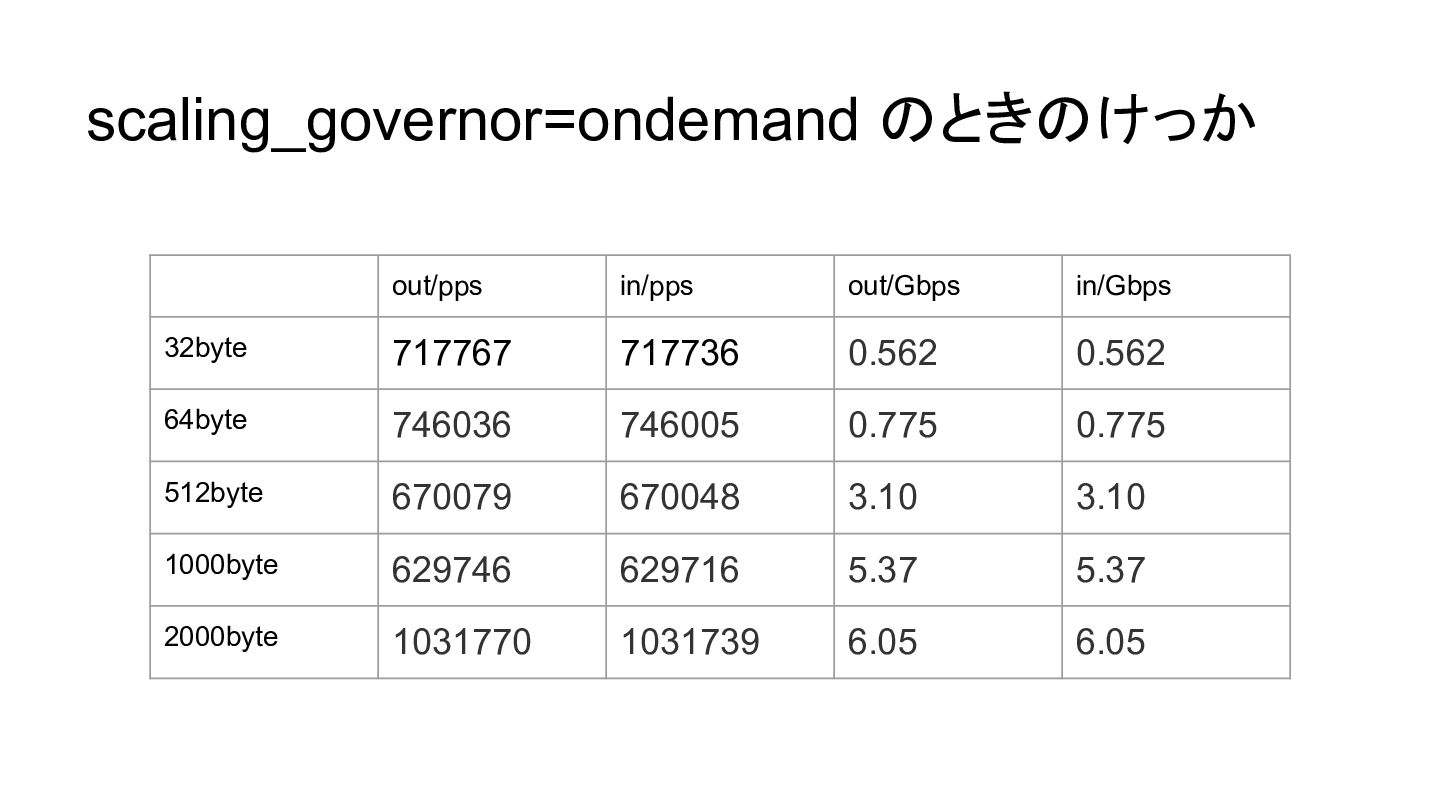
scaling_governor=ondemand のときのけっか out/pps in/pps out/Gbps in/Gbps 32byte 717767 717736 0.562
0.562 64byte 746036 746005 0.775 0.775 512byte 670079 670048 3.10 3.10 1000byte 629746 629716 5.37 5.37 2000byte 1031770 1031739 6.05 6.05
None
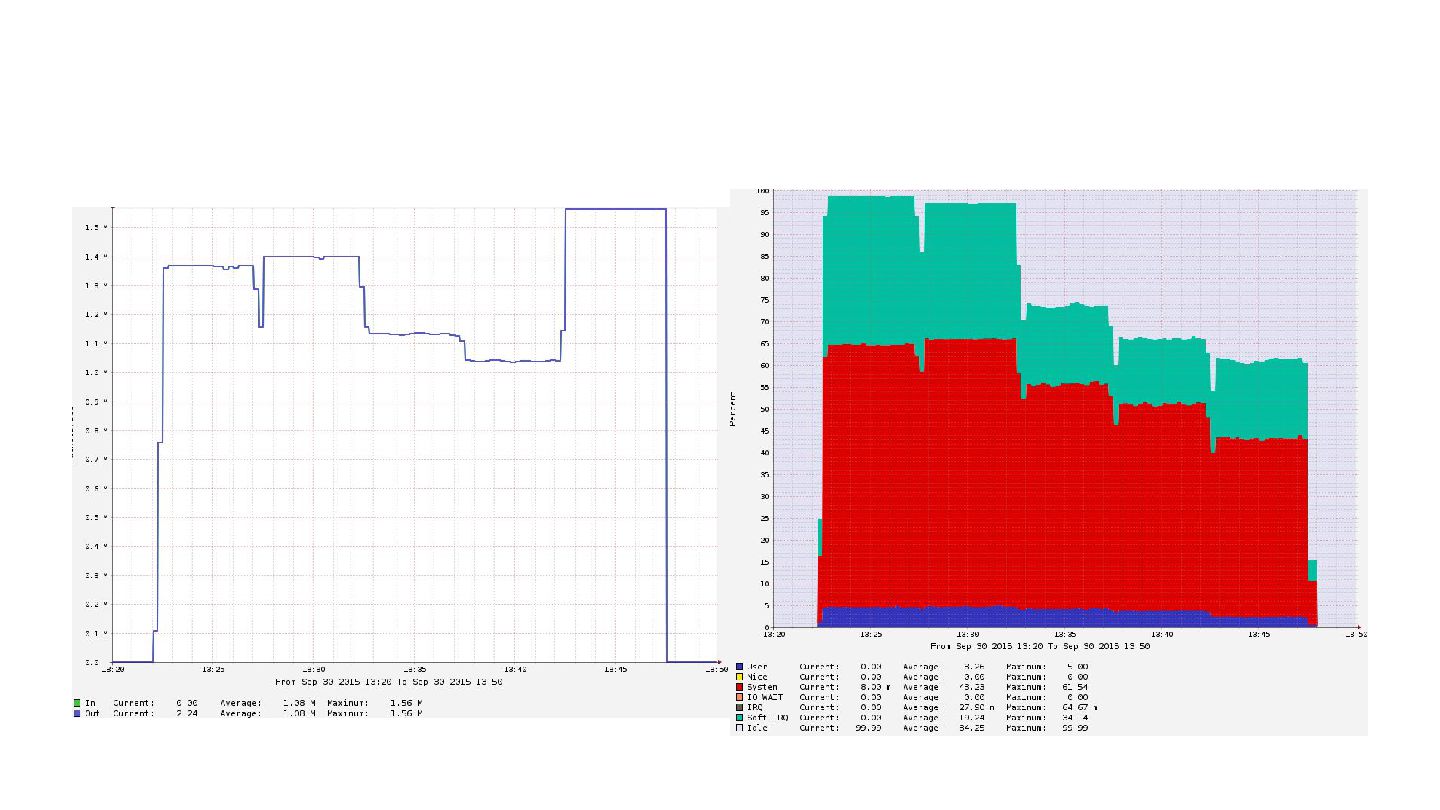
さいきんは TurboBoostも重要 - clock 次第で NIC の性能引き出せないことも - scaling_governor=performance にして
2.6GHz まで 引き上げた状態だと、 9.5Gbps までスループット出せて る。ほぼワイヤースピード - しかし、ondemand だと 6 Gbps 程度しか出なかったり する - このへんはワークロードに依存するところもあるだろうけ ど、NIC酷使したいなら TurboBoost 意識する方が無難
まず TurboBoost の用途として - アプリケーションサーバなどCPUバウンドなもの でも TurboBoost 有効ですけど、それ以外では - 現時点では、ネットワークの性能改善に使うの
がよさそう - RSS用にキューたくさんあるNICなら、どうせた くさんCore使うんだから、ぜんぶのCoreの clock を引き上げてしまえばいい
ただ、気をつけてください - Brendan Gregg のスライド を見ると、彼は rdmsr で温度もとってますよね? - そうです、いまの
TurboBoost は、温度次第な んです - CPUに温度センサーついてて、 TCase の範囲 内で clock 上げるのが、現在の TurboBoost 2.0 なんです
なので TurboBoost 酷使したい人は - CPU の温度もモニタリングするのがオススメ - できれば常時観測しましょう - scaling_governor=performance
にすると、 clock は上がりますが、C1 state (Halt)に入る と、温度下がります - C0 のときにだけ温度上がる == Core ぶん回っ てるときだけ温度上がるので、ちゃんと排熱でき てるか観測するのがよいです
閑話休題・1 - Ubuntu はデフォルトで /etc/init.d/ondemand が起動時に実行されるそうな - ネットワークの性能が大事なら、無効化しましょ う -
参考: http://askubuntu.com/questions/3924/disable- ondemand-cpu-scaling-daemon
閑話休題・2 - Skylake では SpeedShift っていう新しい省電 力機構が来るのですが - CPU側で自動制御するとか、OS側といろいろ 協調するとか、今までと比べてクロック/電圧制
御が拡張されてるようなので - Xeon に SpeedShift が来たときに備えて、OS 側でクロックなど制御するのに、慣れといたほう がいいかなと思ってます
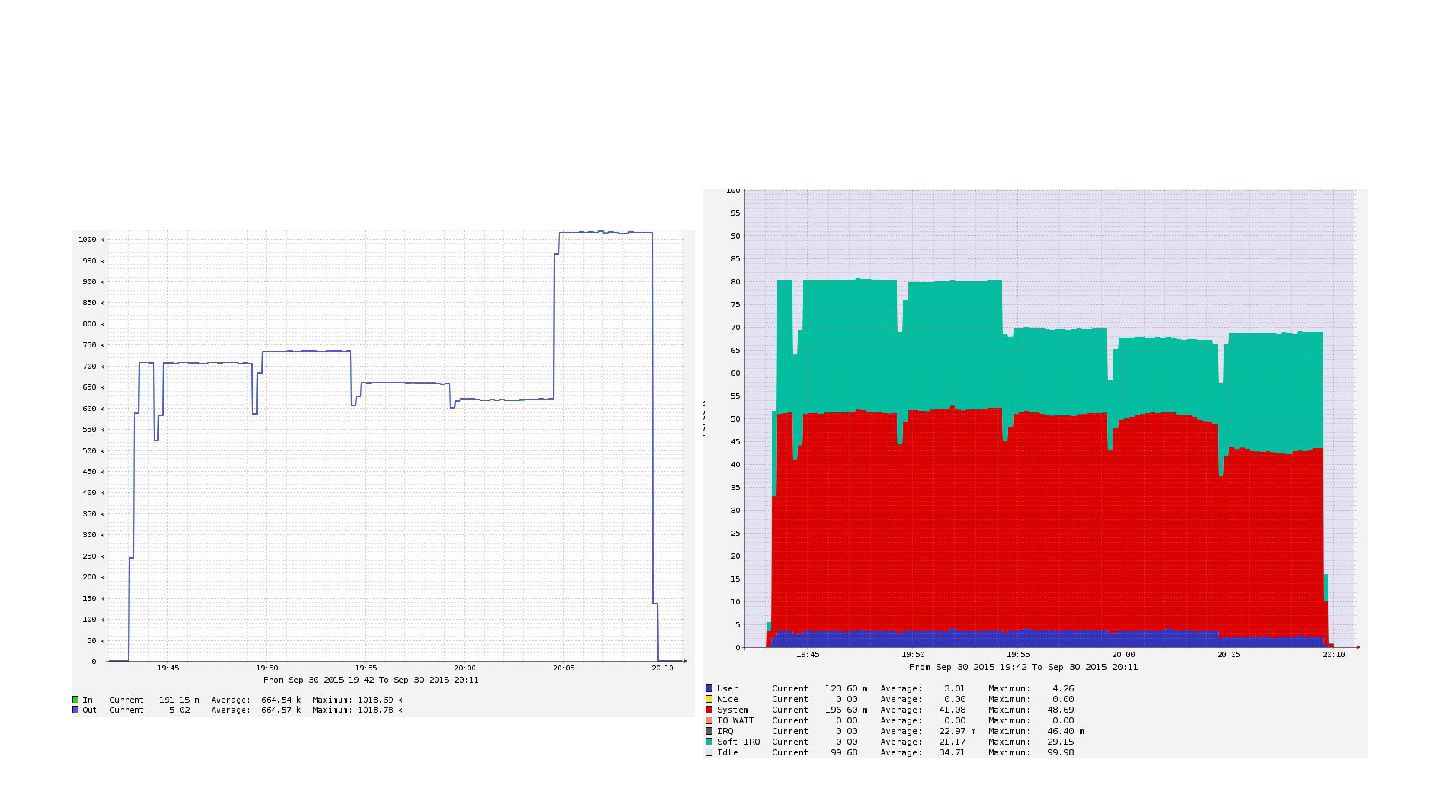
ここでEthernet に対する不満を一つだけ - 個人的な不満なんですけどね - こちらの松本さんのスライド の、こちらの図 をよ く御覧ください -
なにか気づきませんか? - そう
256byteのときと、 512byteのときで、 ppsがほとんど変わらない
大量にパケット扱うのは とにかく重い
個人的に、10GbE以降は - GbEまでは、まだ良かったと思うけど - 10GbE 以降は、Jumbo Frame を標準化して ほしかった -
最近の Linux はデフォルトで gro とか gso が 有効になってて、パケットまとめて処理してるん ですよ - なので、 tcpdump すると、(そのレイヤーでは) 1500 byte よりでかいパケット扱ってるのが見えるんですが
それなら 最初から
Ethernetで でかいフレーム 扱いたい
今のご時世 - 1500byte 超えるデータって、当たり前のように 扱うと思うんですよ - AWS の EBS 上で
InnoDB 動かす場合、扱う データの単位はほとんど 16KB 以上なわけで すよ - それもあってか、最近の EC2 では Jumbo Frame デフォルトで有効なんですよね
ただ、適材適所というか - Ethernet で扱うフレームが大きすぎると、 Ethernet の FCS は 4byte しかないので、エ
ラーの検出率が下がってしまうと - よって、 Jumbo Frame 使うとしても、MTUはほ どほどにして、最終的には gro や gso などの機 能も組み合わせられる方が、効率よいのかなと 思います
そして 振り返って みてみると
ブロックデバイスも ネットワークも CPUを取り巻くI/Oは、 劇的な進化を遂げてます
ブロックデバイスの進化はめざましい - Fusion-IO が ioDrive をリリースしてから「CPU がボトルネックになった」と言われましたが - 3D NAND
が実用化されたので、 NAND flash のバイト単価はこれからも下がり続けます - PCI-e SSD はシーケンシャルリードが数 GB/secの時代に突入し、 3D Xpoint があれ ば、 NVMe のインターフェースのままで、 NAND Flash の 7 倍の性能が出るように
ブロックデバイスの躍進を支えたのは - かつてはとにかくHDDが遅くって、システムは HDDの遅さに律速されていたけど - ブロックデバイスをHDD以外のものに置き換え ていくことで、劇的な進化を遂げた - HDDのままだったら、ここまでブロックデバイス の
I/O は速くなってなかっただろうし、CPUがボ トルネックにはなりにくかっただろう
サーバのネットワークも2020年代には - 40Gbps 以上のなんらかのインターフェースが、 サーバについてくる時代になると予測されます - そうなると、CPUを取り囲むI/O全部が、2000年 代と比べて桁違いに速くなっちゃう
個人的な見解としては - 40GbE になったら、 Jumbo Frame 標準化され てないけど、使わないと活かせないかも - 何が遅いってDRAMが遅いから、サーバはそん
なにたくさんのフレームを捌けない - 40GbEの時代になってもオンプレミス環境を持 つならば、そのへんを意識した方がいいかも - 一方、AWSはすでにMTU9001の世界に行って いる
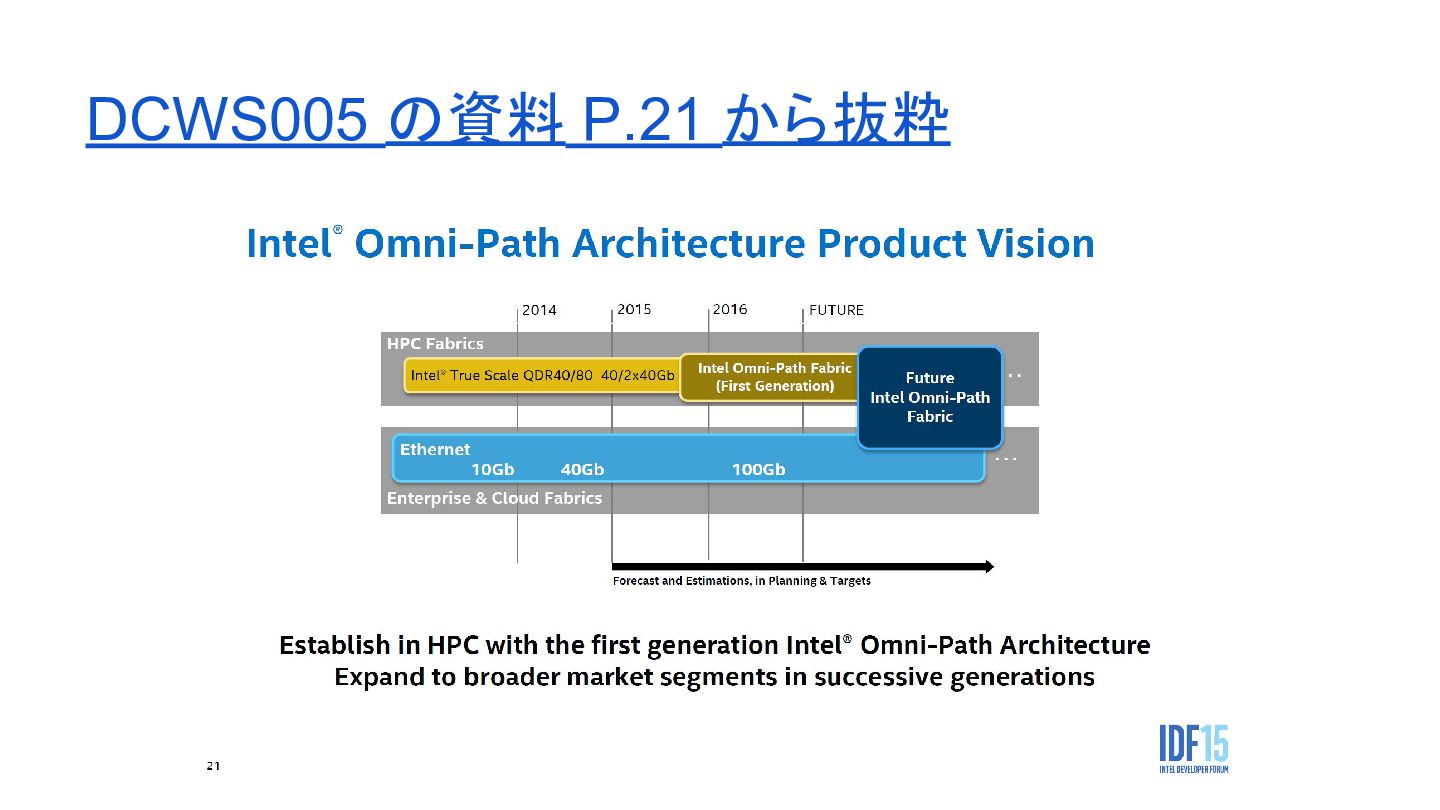
一方その頃 Intelさんは
ここで IDF 2015 - San Francisco の資料を振り返ってみましょう
DCWS005 の資料 P.21 から抜粋
Omni-Path? - こちらの記事 などを参考に - 2014-2015年あたりからデータセンターに 40GbE が導入されるという予測はさておき - Omni-Path
で、最初はHPC向けのインターコネ クトを InfiniBand から置き換えて、最終的に Ethernet も一部置き換えたいみたい - 10GBASE-T がしんどかったんですかねぇ
というわけで、なんにせよ - 2020年代には、サーバに繋がるネットワークの 帯域は、 10GbE より太くなっていくんじゃない でしょうか - 40GBASE-T が流行るのか、
100Gbps の Omni-Path が流行るかはまだわからないとして - InfiniBand 製品売ってる会社としても、シェアとられたく ないでしょうしね。そしたら競争原理働いて、各製品の低 価格化が進むんじゃないかなラッキー
40Gbps までは Ethernet だとしても - 私見ですが、そこから先は、別のものでも良い んじゃないでしょうか? - 少なくとも、データセンター内は -
ブロックデバイスでHDDの代わりが見つかった ように - 少なくとも、ツイストペアケーブルだとエラーレー ト高くて効率悪いし、FCSが4byteだから、あまり 大きなフレームは扱いにくい
2020年あたりを想定すると - NAND Flash の次として、 (インターフェースが NVMeでも)7倍以上速い3D Xpoint が実用化 できそう
- 10GBASE-Tの次として、4倍以上の帯域をもつ 40GBASE-Tか何かが実用化できそう - では、CPUやDRAMは4倍以上の進化をとげる ことができるのか?
閑話休題・3 - ネットワークが40Gbpsを超えるような頃、(個人 的に)CPUは今よりもっと貴重なリソースになっ てる気がしてる - ブロックデバイスやネットワークの進化に見合う ために、CPUはGPGPUや Xeon Phi、FPGAに
一部処理を移譲する時代になるのかも - うわめっちゃCELLっぽい - ただ、なんでも移譲できるとは思えない
- 雑にいうと、ベクトル演算はそういった環境変化 に追随しやすいけど、スカラ演算は難しいんじゃ ないだろうか - DB的にいうと、OLAPだと上手くいきそうな気が するけど、OLTPだと難しい気がしている - そして、Webやオンラインゲームのサーバは、 スカラ演算が速いと嬉しいケースの方が多いだ
ろうし
閑話休題・4 - ついでに脱線すると、個人的に、この数年で x86 に追加された命令セットの中で、最も人類 に貢献したのは、 AES-NI だと思ってます - 暗号化の次に有用なのは、圧縮だと思うんです
が、これはまだアルゴリズム発展途上なので、 最初はFPGAなどで最適化されるはず - 簡単にハードウェアアクセラレーション効くように なると良いなぁ。圧縮は、DBでも使うし
2020年ごろ、パブリッククラウドは多分 - ネットワークの帯域が40Gbps超えたりすると、 ブロックデバイスとの帯域がそれだけ増えて るってこと - そうなれば、オンプレの優位性がまた少し減る - いま AWSのEBSはレイテンシとスループットで
PCI-e SSD に勝ててない が、今後、スループッ トの差はある程度うまってくる
ただ、2020年代を待たなくとも - クラウド事業者がEthernet以外の選択肢を取れ ば、40Gbps以上の帯域を得ることができるだろ うし、レイテンシも改善する可能性はある - 事実、すでに Azure は一部 InfiniBand
を使う ことができる - ひょっとしたら、将来、どこかのクラウド事業者 が、 Omni-Path を一括導入するかもしれない
いまでこそEC2で10Gbps普通だけど - かつて 10Gbps のインスタンスは HPC向け だった - いまでこそ普及して、 ここで挙げられてるような
HPC以外の用途 でも活用されてるだろうけど - 40Gbps 以上のインターフェースが付けば、 EC2でHPCやる人が増えて、結果として、そう いうインスタンスが当たり前になるかもしれない
AWSでNIC強化されると - オンプレと違って、最近はブロックデバイスへの アクセスもネットワーク経由なんで、メリット大 - EBSの帯域強化できるってことだろうから、 Auroraでだってメリットあるし - EBS Optimized
なしでも、充分な帯域が確保で きるようになるかもしれない - そうすると、コストメリット出てきそう - 要注意
最後に - 自分たちでサーバを買って使うなら、3-5年は使 い続けることになるだろうけど - 三年後の進化を予測できなければ、せっかく 買ったサーバが陳腐化してしまうかもしれない - オンプレミス環境はメリットもあるけれど、ハード ウェアの進化を理解して準備しなければ、その
メリットは活かせなくなることだってある
未来のハードウェアを 活かすため、 今のうちに準備し、 変化を受け入れる
おわり
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}