worked, what broke, and why review is the new bottleneck WHOAMI Egor Karbutov · Application Security Guy · Ex-Pentester · Ex-Yandex Bug hunter (Apple, Oracle, DOMPurify…) · M1mo_croc Podcast Ferret Security Research Group · Singapore AGENDA why this matters a3f1c2 the AI productivity paradox security/bottleneck b8e20a review is the chokepoint feature/skills c19d3f agent skills open standard feature/structure d42b1e skills matrix for security feature/go-subagent e7f89c go security subagent · 13 min HEAD · main 5 topics · 44 min · Apr 18 2026
Views expressed are my own — not my employer's All experiments conducted on personal time, in non- production environments Only publicly available code was used — no proprietary systems or confidential data All cited CVEs are from publicly disclosed sources Scope & Limitations Third-party tool mentions are for technical context only — not endorsements This is educational and informational — not security advice for your systems Conduct your own assessment before applying any approach in production Reflects the state of the field as of 18 Apr 2026. AI tooling evolves rapidly; some details may be outdated.
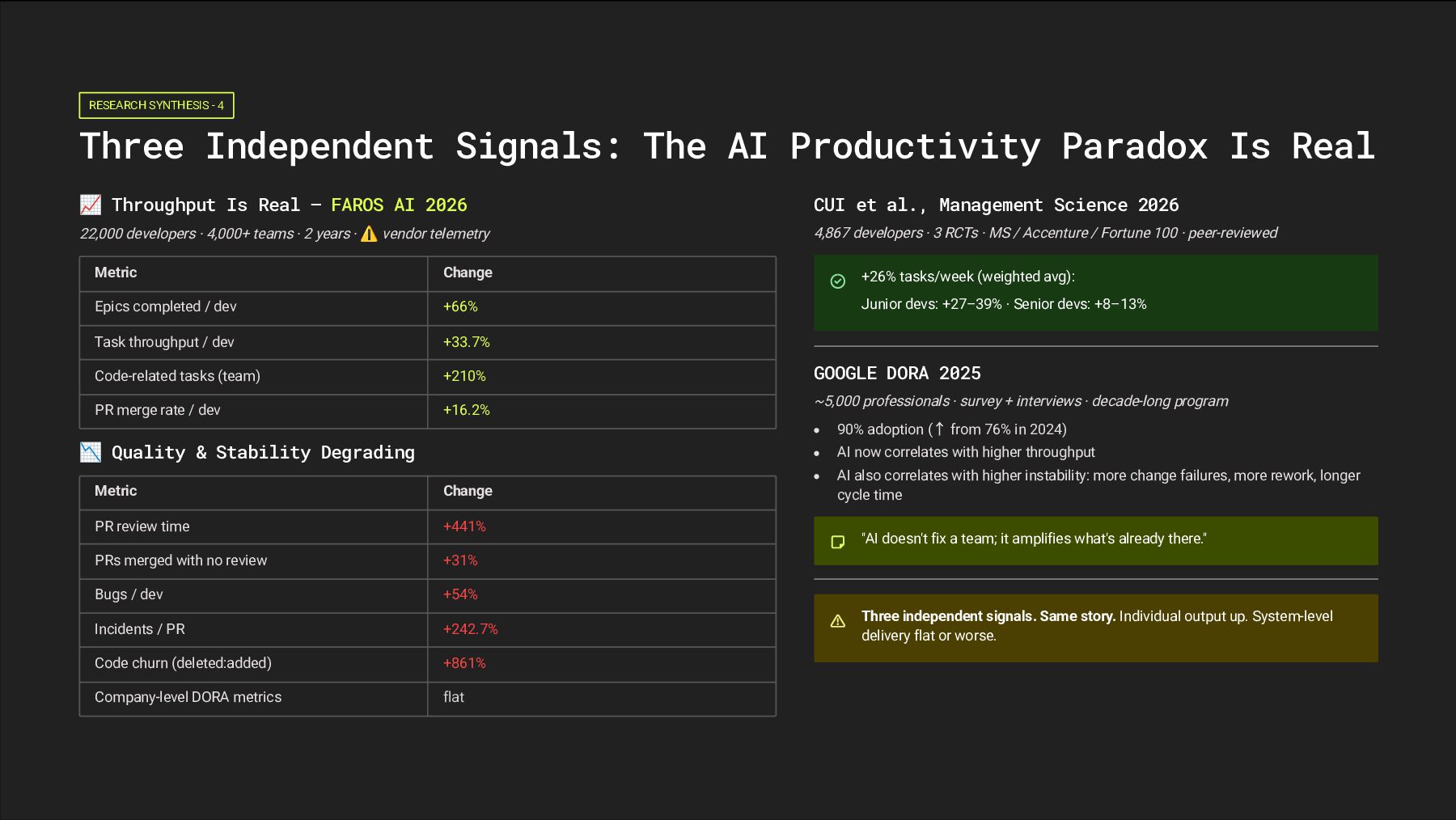
— every vendor, 2024–2026 What does the data say? Three independent research signals tell a more complicated story — one where individual output rises while system-level delivery stays flat or gets worse.
Paradox Is Real ý Throughput Is Real — FAROS AI 2026 22,000 developers · 4,000+ teams · 2 years · ⚠ vendor telemetry Metric Change Epics completed / dev +66% Task throughput / dev +33.7% Code-related tasks (team) +210% PR merge rate / dev +16.2% þ Quality & Stability Degrading Metric Change PR review time +441% PRs merged with no review +31% Bugs / dev +54% Incidents / PR +242.7% Code churn (deleted:added) +861% Company-level DORA metrics flat CUI et al., Management Science 2026 4,867 developers · 3 RCTs · MS / Accenture / Fortune 100 · peer-reviewed +26% tasks/week (weighted avg): Junior devs: +27–39% · Senior devs: +8–13% GOOGLE DORA 2025 ~5,000 professionals · survey + interviews · decade-long program 90% adoption ( ↑ from 76% in 2024) AI now correlates with higher throughput AI also correlates with higher instability: more change failures, more rework, longer cycle time "AI doesn't fix a team; it amplifies what's already there." Three independent signals. Same story. Individual output up. System-level delivery flat or worse.
16 experienced devs · 246 real tasks · avg 5 yrs experience, 1M+ LOC · Cursor Pro + Claude 3.5/3.7 Sonnet Predicted (before) +24% Developers expected AI to speed them up before starting Perceived (after) +20% Developers still felt faster after completing tasks with AI Measured (actual) −19% Rigorous measurement showed tasks actually took 19% longer ⚠ 39 percentage points between what developers believed and what actually happened. Feb 2026 update — METR ran a follow-up with 57 developers. The 19% slowdown shrunk; AI probably isn't a net slowdown on average anymore. But 30–50% of developers refused to participate without AI, making rigorous measurement nearly impossible. The 39-point perception gap held across both studies.
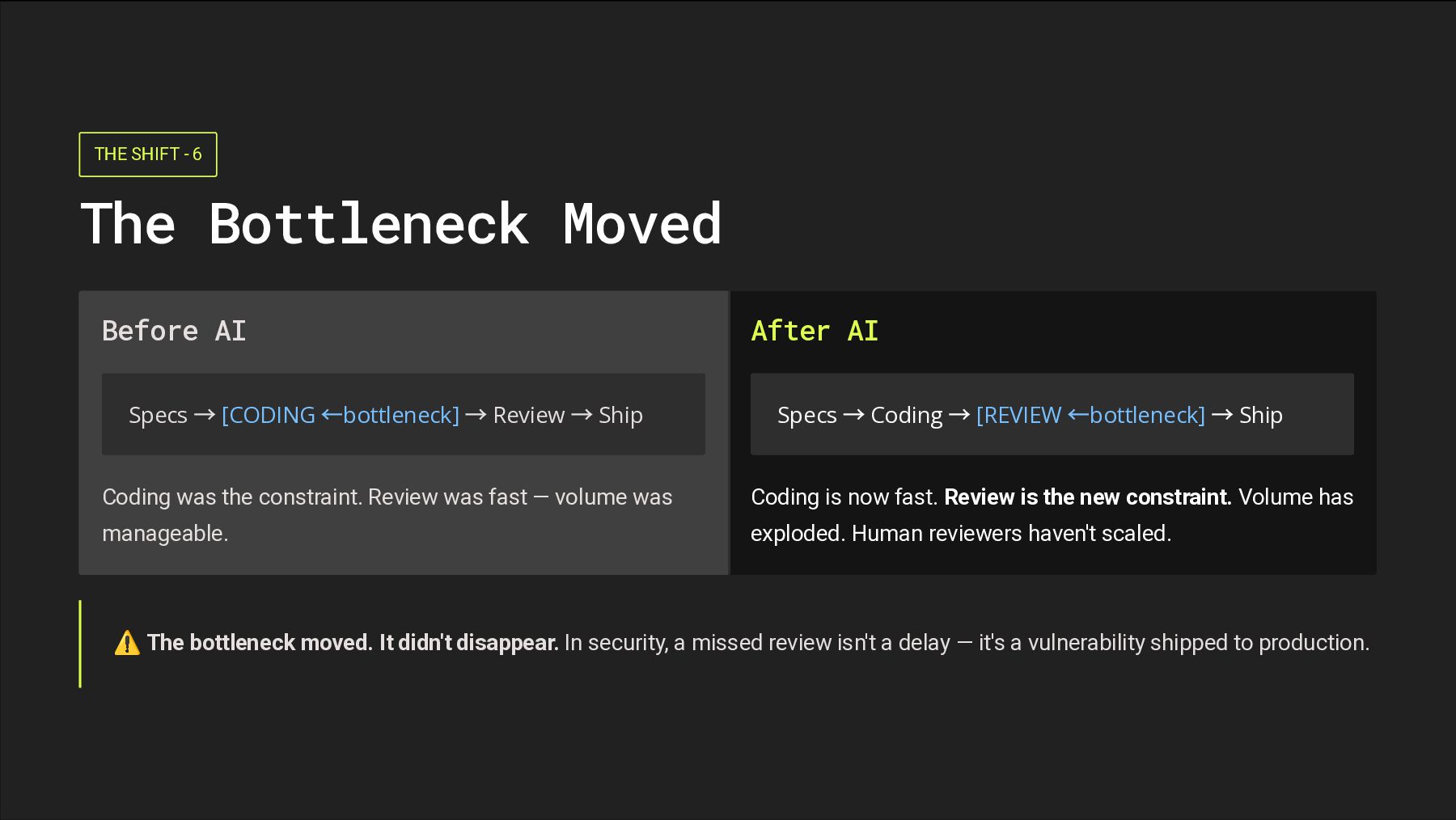
→ [CODING ←bottleneck] → Review → Ship Coding was the constraint. Review was fast — volume was manageable. After AI Specs → Coding → [REVIEW ←bottleneck] → Ship Coding is now fast. Review is the new constraint. Volume has exploded. Human reviewers haven't scaled. ⚠ The bottleneck moved. It didn't disappear. In security, a missed review isn't a delay — it's a vulnerability shipped to production.
findings from early 2026 — one independent, one from a vendor red team — reveal AI systems discovering security flaws at a depth and speed no human team has matched. AISLE — January 2026 12 of 12 CVEs Found Every security issue in OpenSSL's January 2026 coordinated release — discovered autonomously, without human guidance. Decades-Old Bugs Some vulnerabilities had been lurking in the codebase for over two decades — invisible to every prior audit. Patches Adopted AISLE's proposed fixes were adopted or directly informed the official patch for 5 of 12 CVEs. 6 more caught before any release shipped. Anthropic Red Team — February 2026 Opus 4.6 discovered 500+ previously-unknown high-severity vulnerabilities in open-source code — no specialized scaffolding, no fine-tuning, straight out of the box. GhostScript — Reasoning Across History Claude read the Git commit history, identified an old security patch, and reasoned that the same bug class must exist at other call sites that were never patched. It found one in a completely different file — then built a working proof-of-concept crash to confirm it. CGIF — Defeating Coverage-Guided Fuzzing Claude understood the LZW compression algorithm deeply enough to craft an input where the "compressed" output exceeded the uncompressed input — triggering a buffer overflow that is mathematically impossible to find via coverage-guided fuzzing, even at 100% code coverage.
same models that find bugs also write them. The numbers are not directional — they are measured. < 12% Correct AND Secure DualGauge · 10 frontier models 9.2% Correct + Secure Fixes SecureAgentBench · real codebase + real CVE > 20% "Correct" Fixes That Open a New Vuln SecureAgentBench · the patch passed — and introduced a new hole "Same" models. Best vulnerability finders in history. Secure-coders less than 12% of the time.
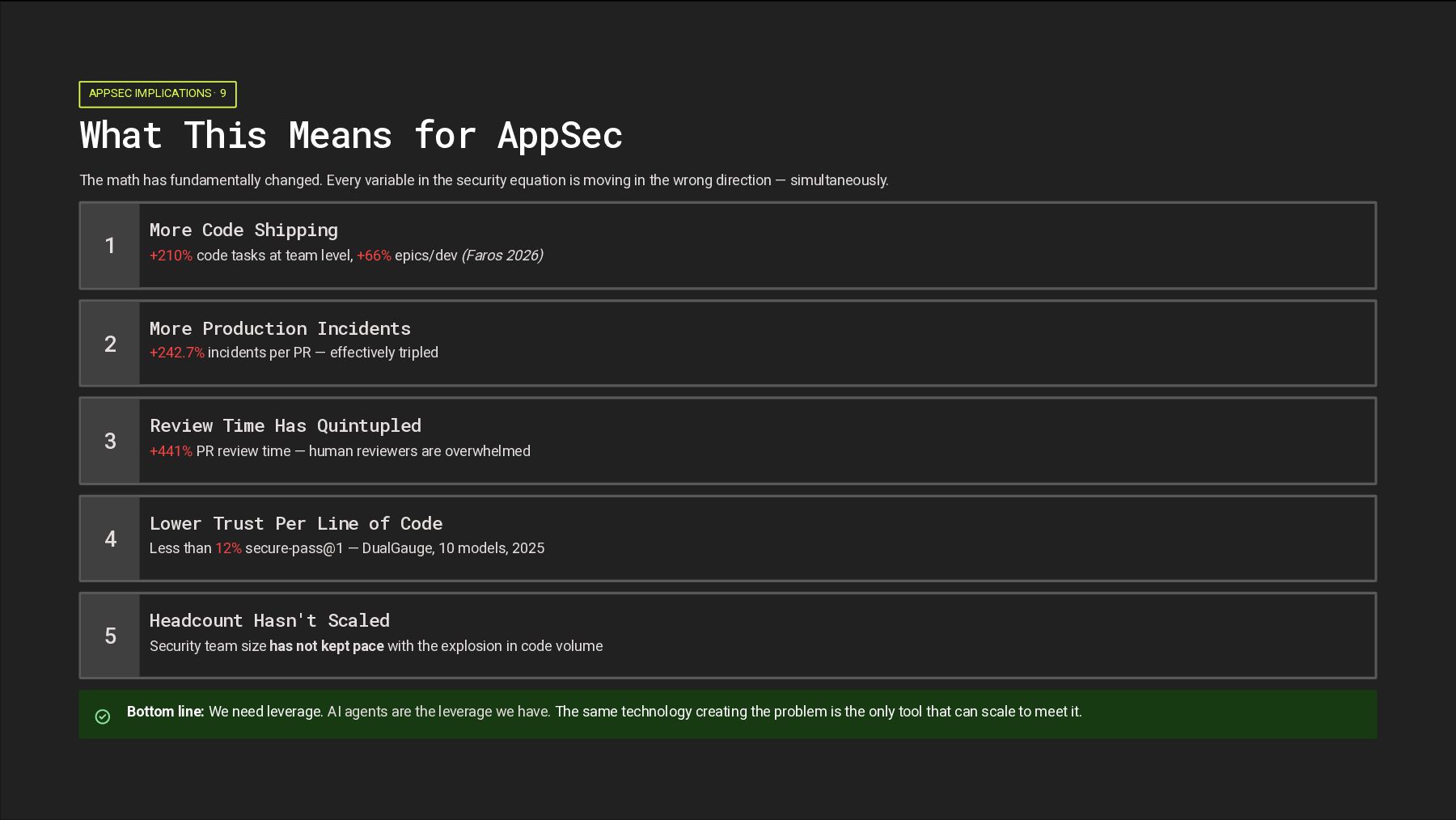
math has fundamentally changed. Every variable in the security equation is moving in the wrong direction — simultaneously. 1 More Code Shipping +210% code tasks at team level, +66% epics/dev (Faros 2026) 2 More Production Incidents +242.7% incidents per PR — effectively tripled 3 Review Time Has Quintupled +441% PR review time — human reviewers are overwhelmed 4 Lower Trust Per Line of Code Less than 12% secure-pass@1 — DualGauge, 10 models, 2025 5 Headcount Hasn't Scaled Security team size has not kept pace with the explosion in code volume Bottom line: We need leverage. AI agents are the leverage we have. The same technology creating the problem is the only tool that can scale to meet it.
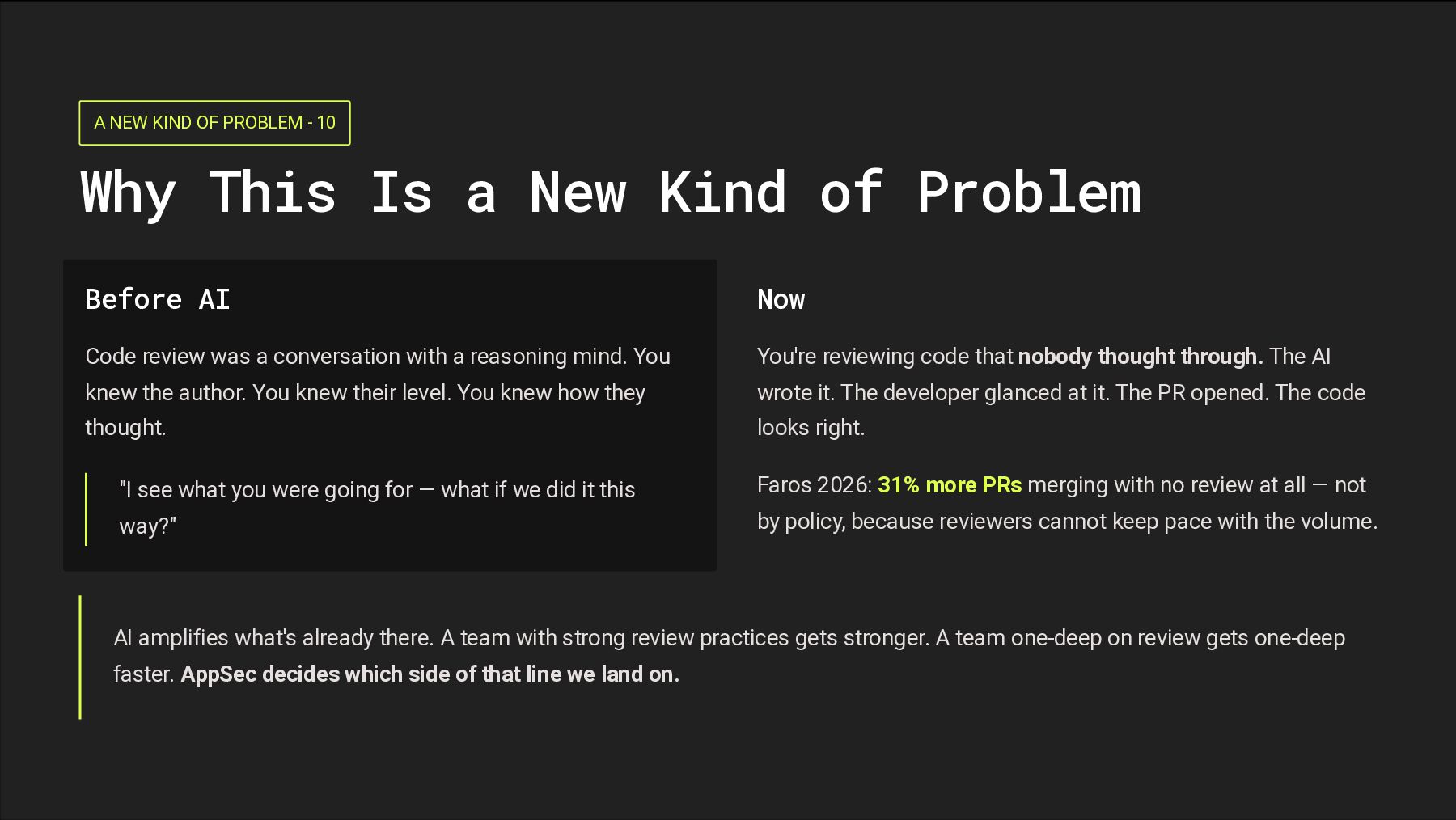
a New Kind of Problem Before AI Code review was a conversation with a reasoning mind. You knew the author. You knew their level. You knew how they thought. "I see what you were going for — what if we did it this way?" Now You're reviewing code that nobody thought through. The AI wrote it. The developer glanced at it. The PR opened. The code looks right. Faros 2026: 31% more PRs merging with no review at all — not by policy, because reviewers cannot keep pace with the volume. AI amplifies what's already there. A team with strong review practices gets stronger. A team one-deep on review gets one-deep faster. AppSec decides which side of that line we land on.
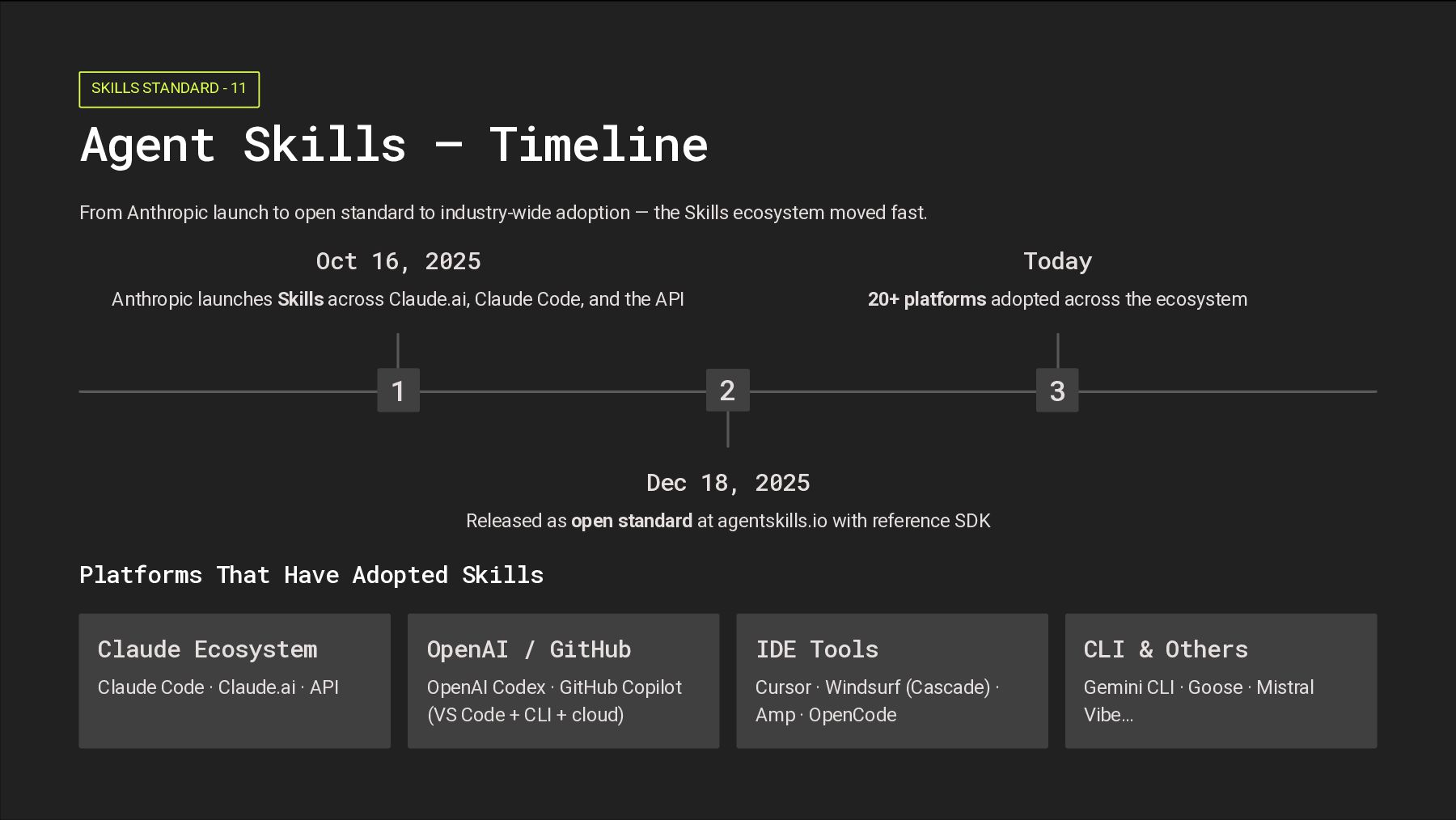
launch to open standard to industry-wide adoption — the Skills ecosystem moved fast. 1 Oct 16, 2025 Anthropic launches Skills across Claude.ai, Claude Code, and the API 2 Dec 18, 2025 Released as open standard at agentskills.io with reference SDK 3 Today 20+ platforms adopted across the ecosystem Platforms That Have Adopted Skills Claude Ecosystem Claude Code · Claude.ai · API OpenAI / GitHub OpenAI Codex · GitHub Copilot (VS Code + CLI + cloud) IDE Tools Cursor · Windsurf (Cascade) · Amp · OpenCode CLI & Others Gemini CLI · Goose · Mistral Vibe…
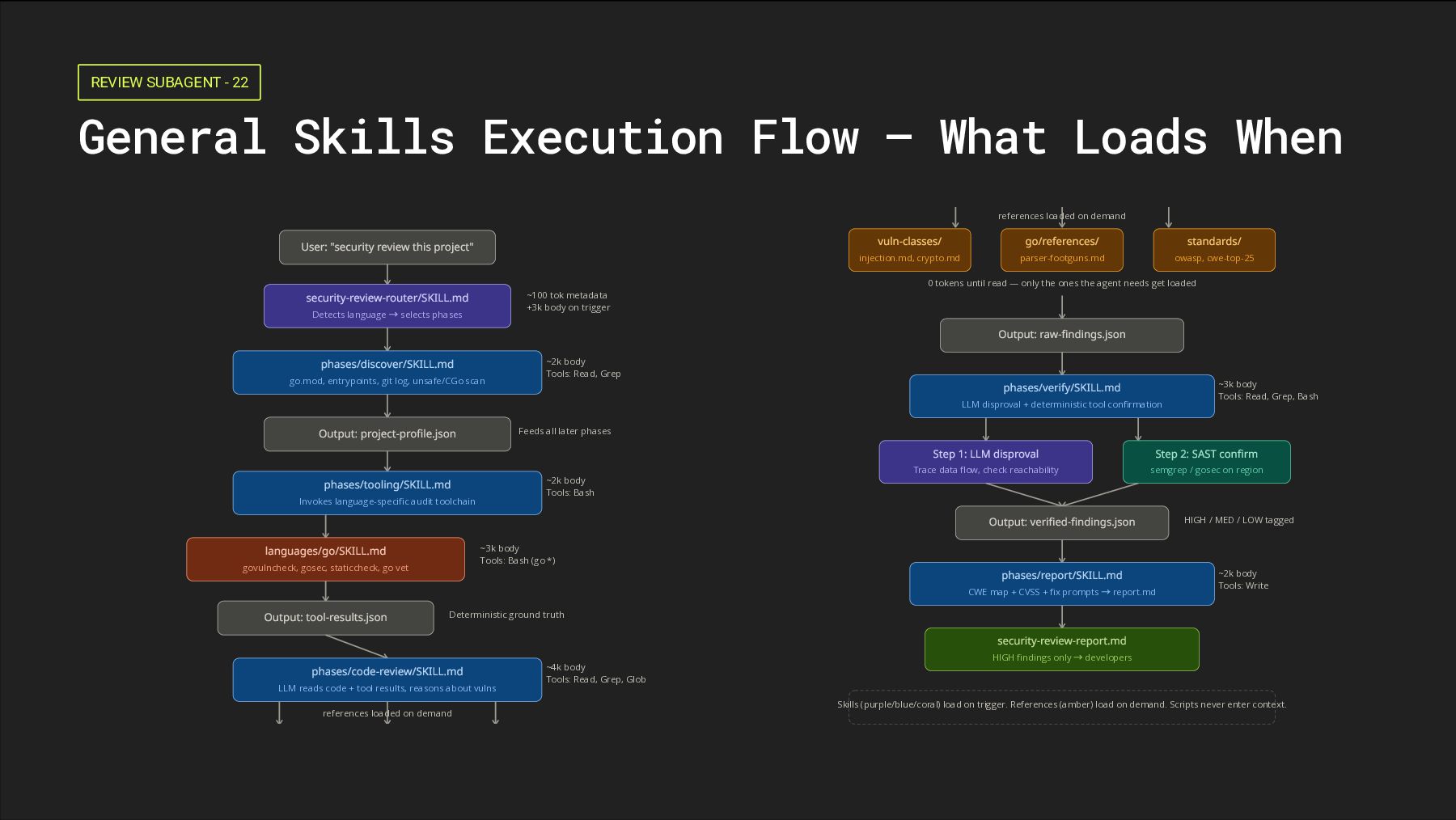
my-skill/ ├── SKILL.md ← YAML frontmatter + markdown body ├── references/ ← loaded on demand │ ├── examples.md │ └── cve-patterns.md ├── scripts/ ← executed, never read into context │ └── analyze.py └── assets/ ← used in output, never enter context └── report-template.md SKILL.md Frontmatter --- name: go-security-review description: Review Go code for security vulnerabilities. Use when the user asks for a security audit of a Go project, or when reviewing PRs touching HTTP handlers, SQL queries, or crypto in Go. --- # Go Security Review (instructions...) SKILL.md YAML frontmatter defines the trigger. Markdown body holds procedural knowledge, workflow, and decisions. references/ Loaded on demand when the skill body explicitly requests them. Practically unbounded depth. scripts/ Executed directly — never read into context. Zero token cost for running tools: semgrep, gosec, or govulncheck.
vs MCP AGENTS.md The Constitution Project-wide rules and conventions. Always loaded. Example: "Always run tests before committing" Skills (SKILL.md) The Playbooks Specific reusable workflows. Loaded on trigger. Example: "How we do a security review" MCP The Communication Channels Live access to external systems. Tools always available. Example: "Connect to Postgres / Confluence / Snyk" Token Cost Per Conversation Turn Approach What sits in context Typical cost MCP — traditional Every connected server's full tool schemas, every turn 5 servers × ~50 tools ≈ 55,000 tokens before you type anything. Anthropic internal: up to 134K tokens. MCP — Tool Search (Nov 2025) Only small search tool + always-on tools 134K → 5K preloaded (~85% reduction). Accuracy improved. Skills Metadata only — name + description ~100 tokens per skill. Body loads on trigger. References load on demand. Scripts never enter context. When to Use Which Use MCP Live, authenticated, stateful systems — Jira, GitHub API, Postgres, Snyk, Confluence Use Skills Local binaries (semgrep, gosec, govulncheck, grep, git), multi-step workflows, bundled references, cross- agent portability Use Both Together Security-review skill that orchestrates MCP tools for ticket creation at the end
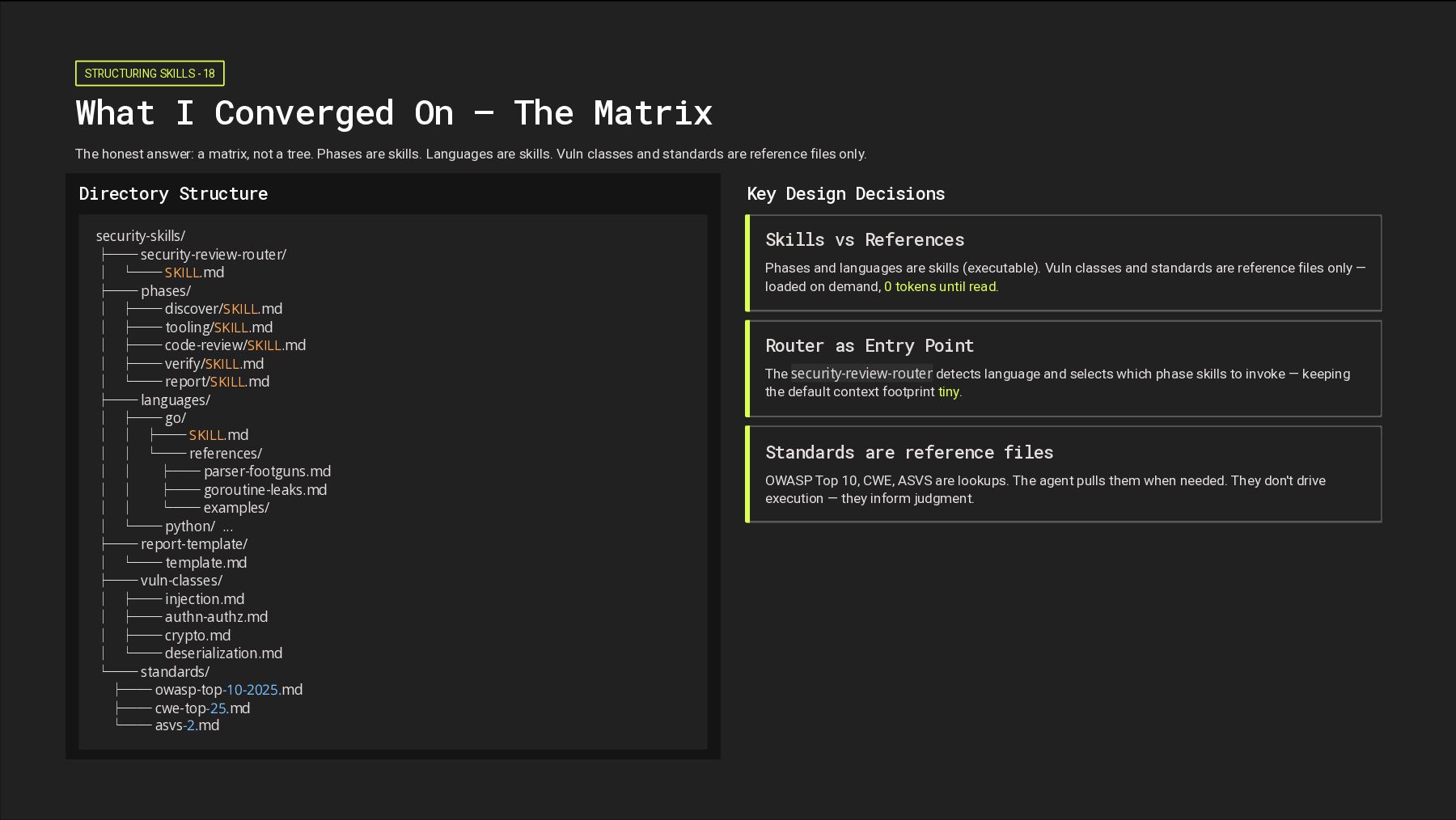
The choice of organizing axis has real consequences for coverage, duplication, and maintainability. There is no obvious answer. How do you organize security skills? By Vulnerability Type SQLi, XSS, IDOR, … By Language / Stack Go, Rust, Python, JS, … By Framework React, Next.js, Django, … By Review Phase Discover, audit, report, … By Standard OWASP Top 10, CWE Top 25, ASVS, … By Roles Security Reviewer, Variant Analysis, Tools Runner, …
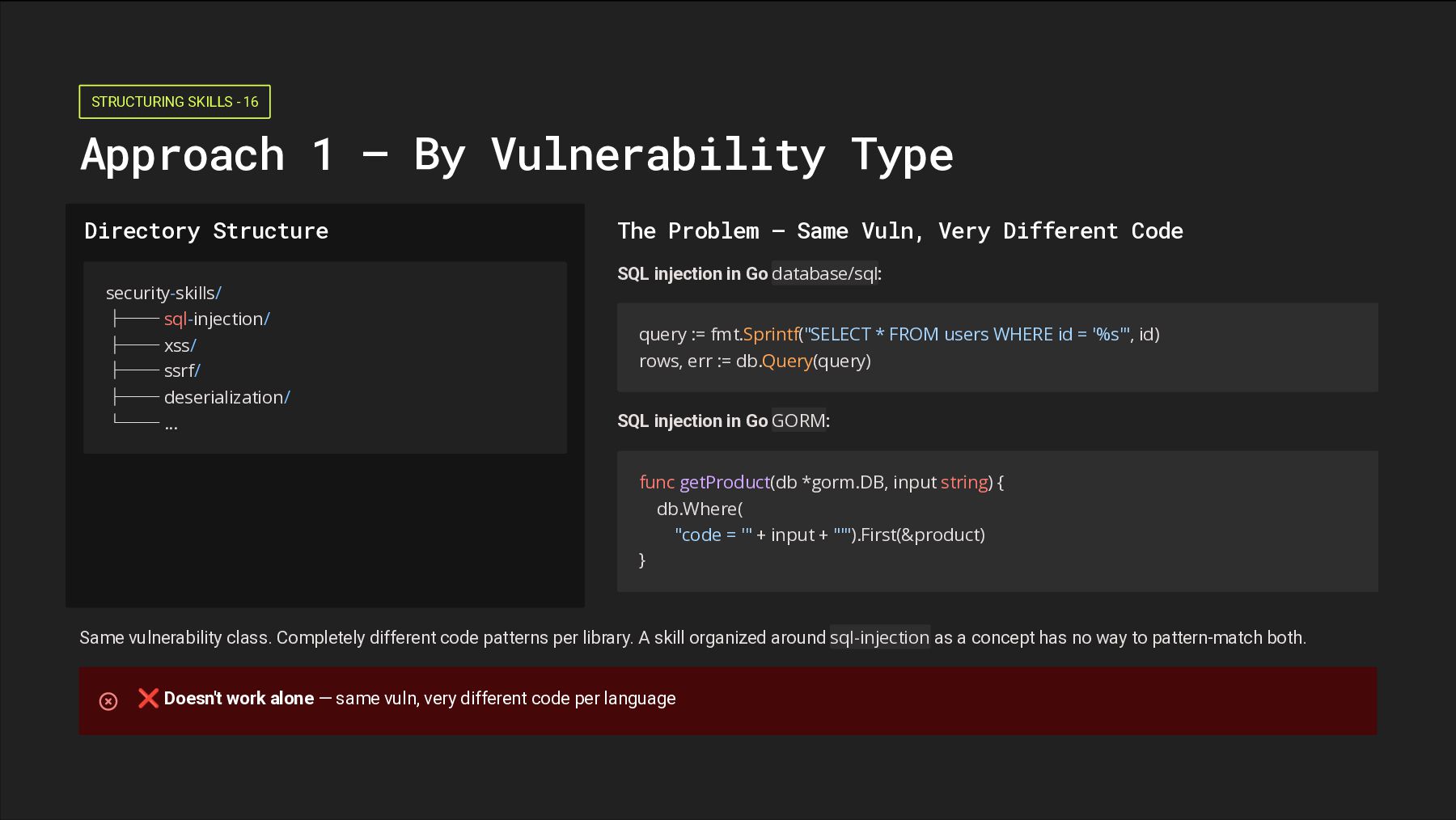
Directory Structure security-skills/ ├── sql-injection/ ├── xss/ ├── ssrf/ ├── deserialization/ └── ... The Problem — Same Vuln, Very Different Code SQL injection in Go database/sql: query := fmt.Sprintf("SELECT * FROM users WHERE id = '%s'", id) rows, err := db.Query(query) SQL injection in Go GORM: func getProduct(db *gorm.DB, input string) { db.Where( "code = '" + input + "'").First(&product) } Same vulnerability class. Completely different code patterns per library. A skill organized around sql-injection as a concept has no way to pattern-match both. ❌ Doesn't work alone — same vuln, very different code per language
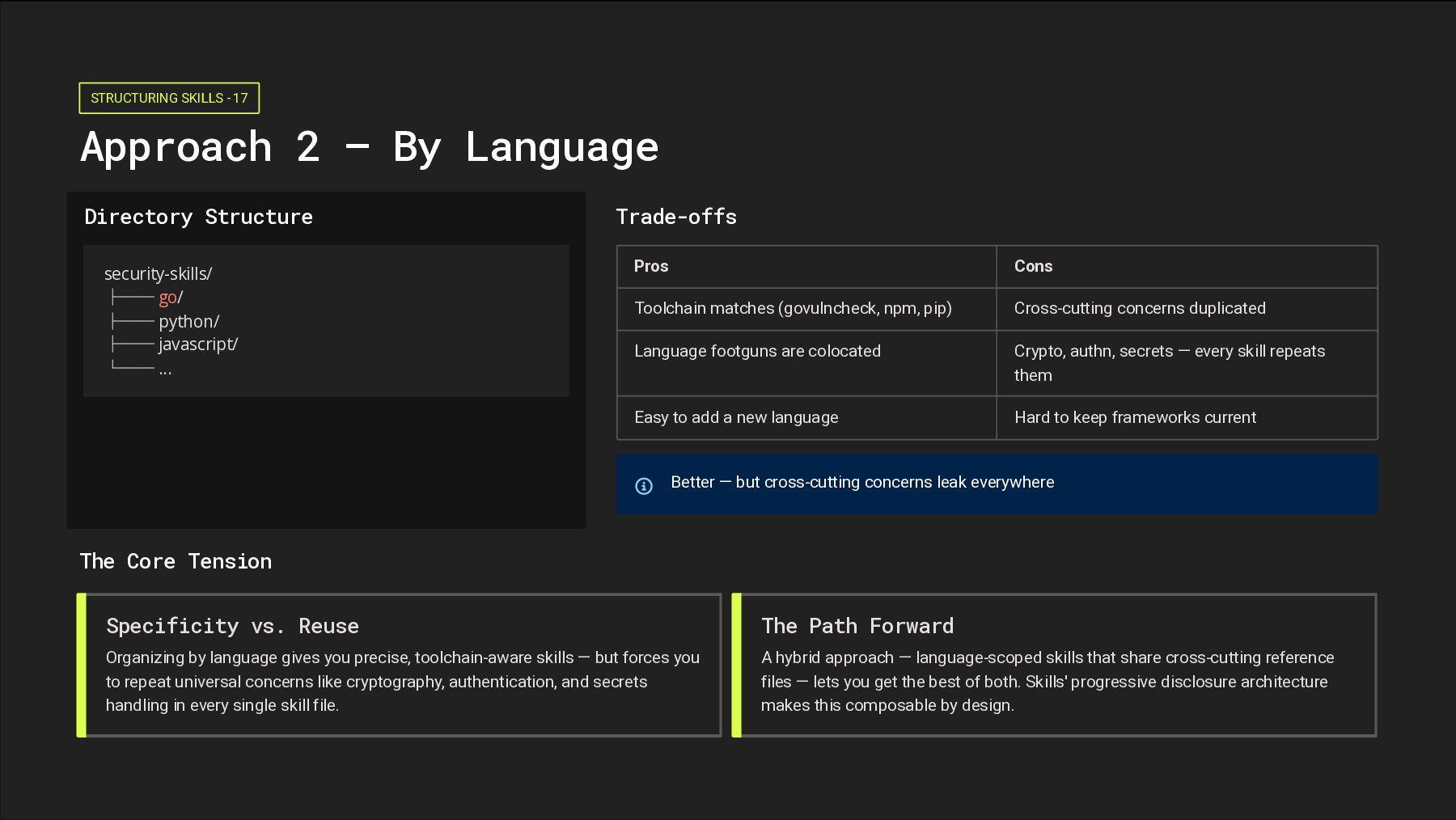
Structure security-skills/ ├── go/ ├── python/ ├── javascript/ └── ... Trade-offs Pros Cons Toolchain matches (govulncheck, npm, pip) Cross-cutting concerns duplicated Language footguns are colocated Crypto, authn, secrets — every skill repeats them Easy to add a new language Hard to keep frameworks current Better — but cross-cutting concerns leak everywhere The Core Tension Specificity vs. Reuse Organizing by language gives you precise, toolchain-aware skills — but forces you to repeat universal concerns like cryptography, authentication, and secrets handling in every single skill file. The Path Forward A hybrid approach — language-scoped skills that share cross-cutting reference files — lets you get the best of both. Skills' progressive disclosure architecture makes this composable by design.
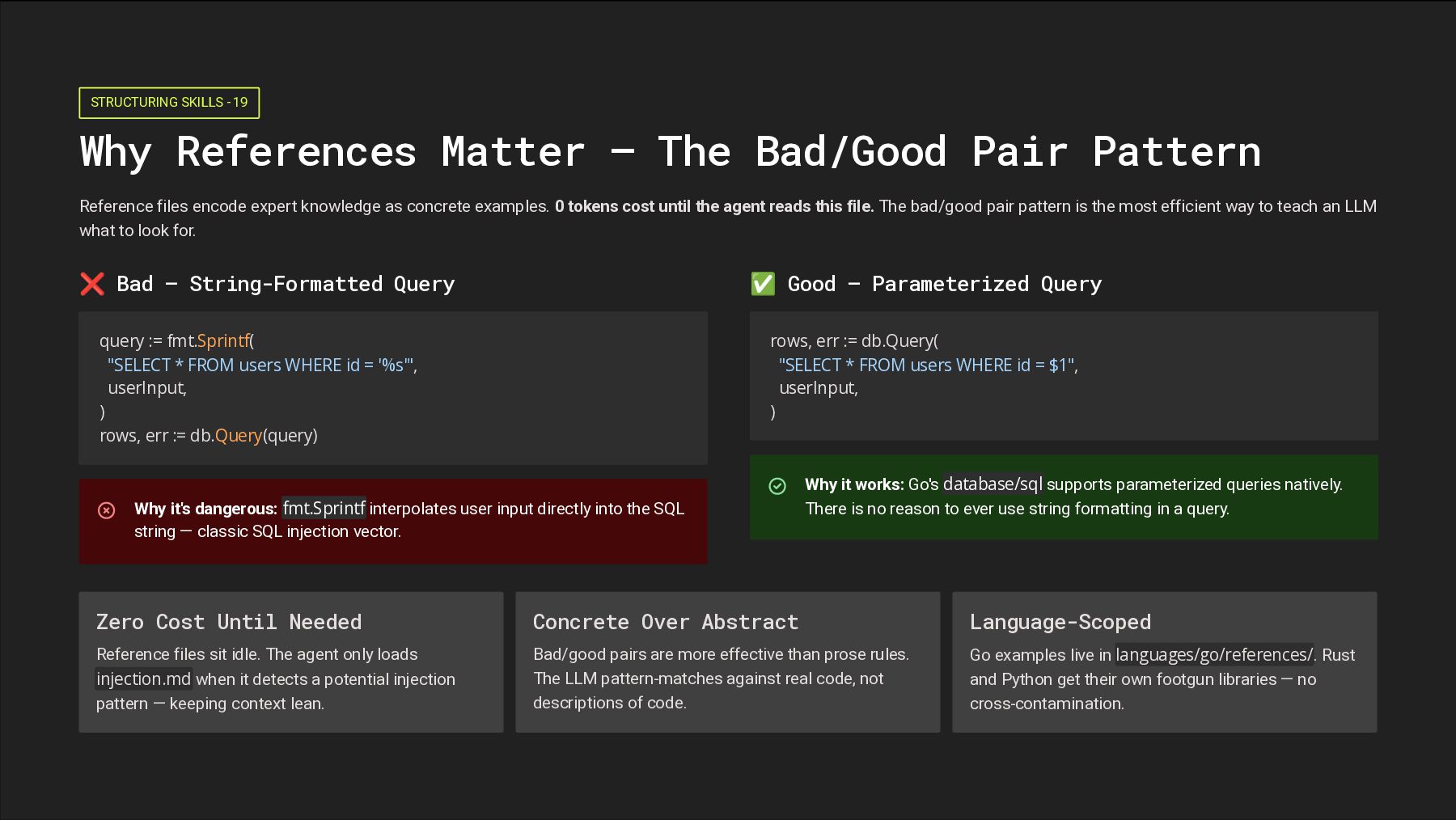
Pair Pattern Reference files encode expert knowledge as concrete examples. 0 tokens cost until the agent reads this file. The bad/good pair pattern is the most efficient way to teach an LLM what to look for. ❌ Bad — String-Formatted Query query := fmt.Sprintf( "SELECT * FROM users WHERE id = '%s'", userInput, ) rows, err := db.Query(query) Why it's dangerous: fmt.Sprintf interpolates user input directly into the SQL string — classic SQL injection vector. ✅ Good — Parameterized Query rows, err := db.Query( "SELECT * FROM users WHERE id = $1", userInput, ) Why it works: Go's database/sql supports parameterized queries natively. There is no reason to ever use string formatting in a query. Zero Cost Until Needed Reference files sit idle. The agent only loads injection.md when it detects a potential injection pattern — keeping context lean. Concrete Over Abstract Bad/good pairs are more effective than prose rules. The LLM pattern-matches against real code, not descriptions of code. Language-Scoped Go examples live in languages/go/references/. Rust and Python get their own footgun libraries — no cross-contamination.
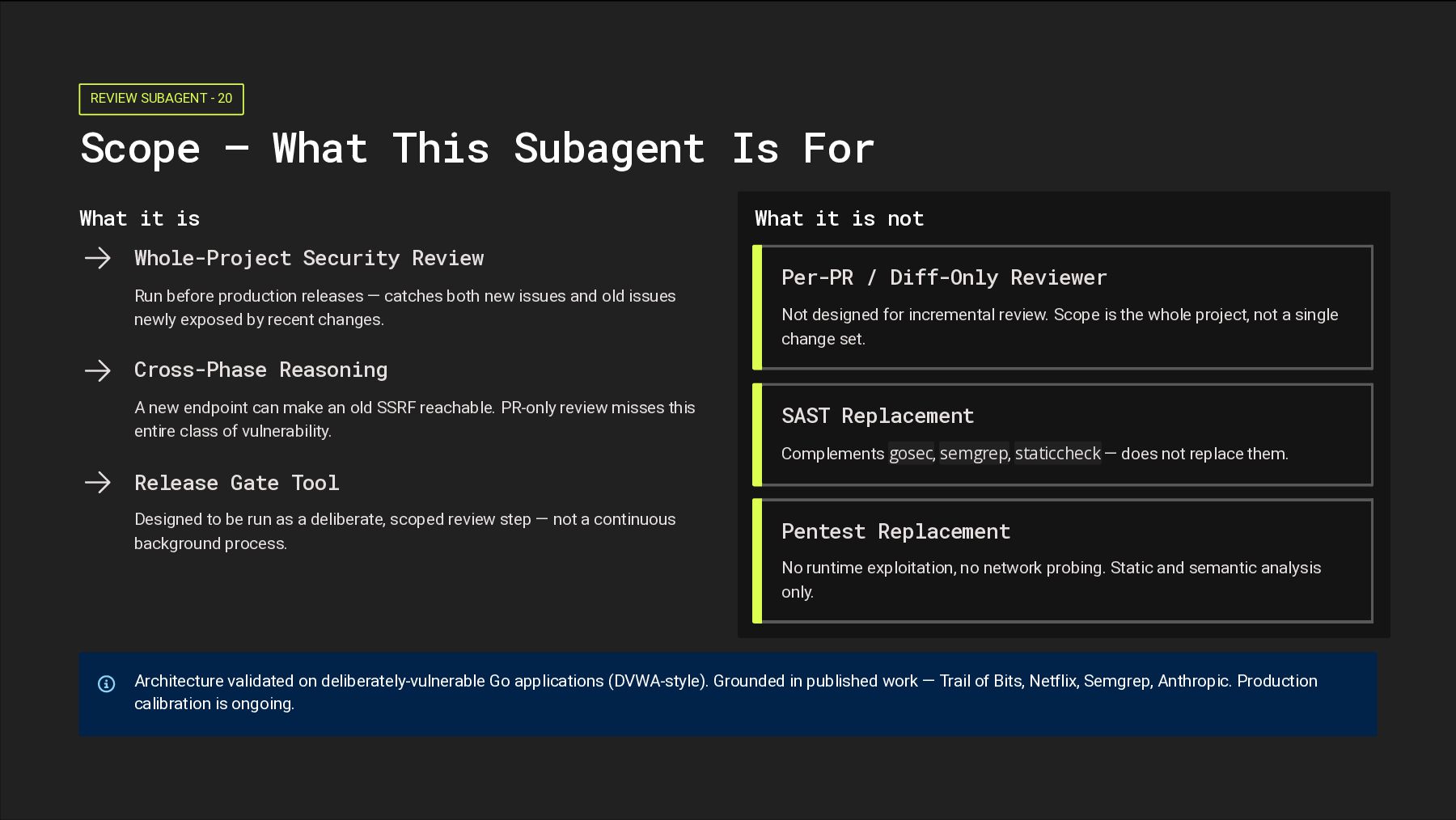
For What it is Whole-Project Security Review Run before production releases — catches both new issues and old issues newly exposed by recent changes. Cross-Phase Reasoning A new endpoint can make an old SSRF reachable. PR-only review misses this entire class of vulnerability. Release Gate Tool Designed to be run as a deliberate, scoped review step — not a continuous background process. What it is not Per-PR / Diff-Only Reviewer Not designed for incremental review. Scope is the whole project, not a single change set. SAST Replacement Complements gosec, semgrep, staticcheck — does not replace them. Pentest Replacement No runtime exploitation, no network probing. Static and semantic analysis only. Architecture validated on deliberately-vulnerable Go applications (DVWA-style). Grounded in published work — Trail of Bits, Netflix, Semgrep, Anthropic. Production calibration is ongoing.
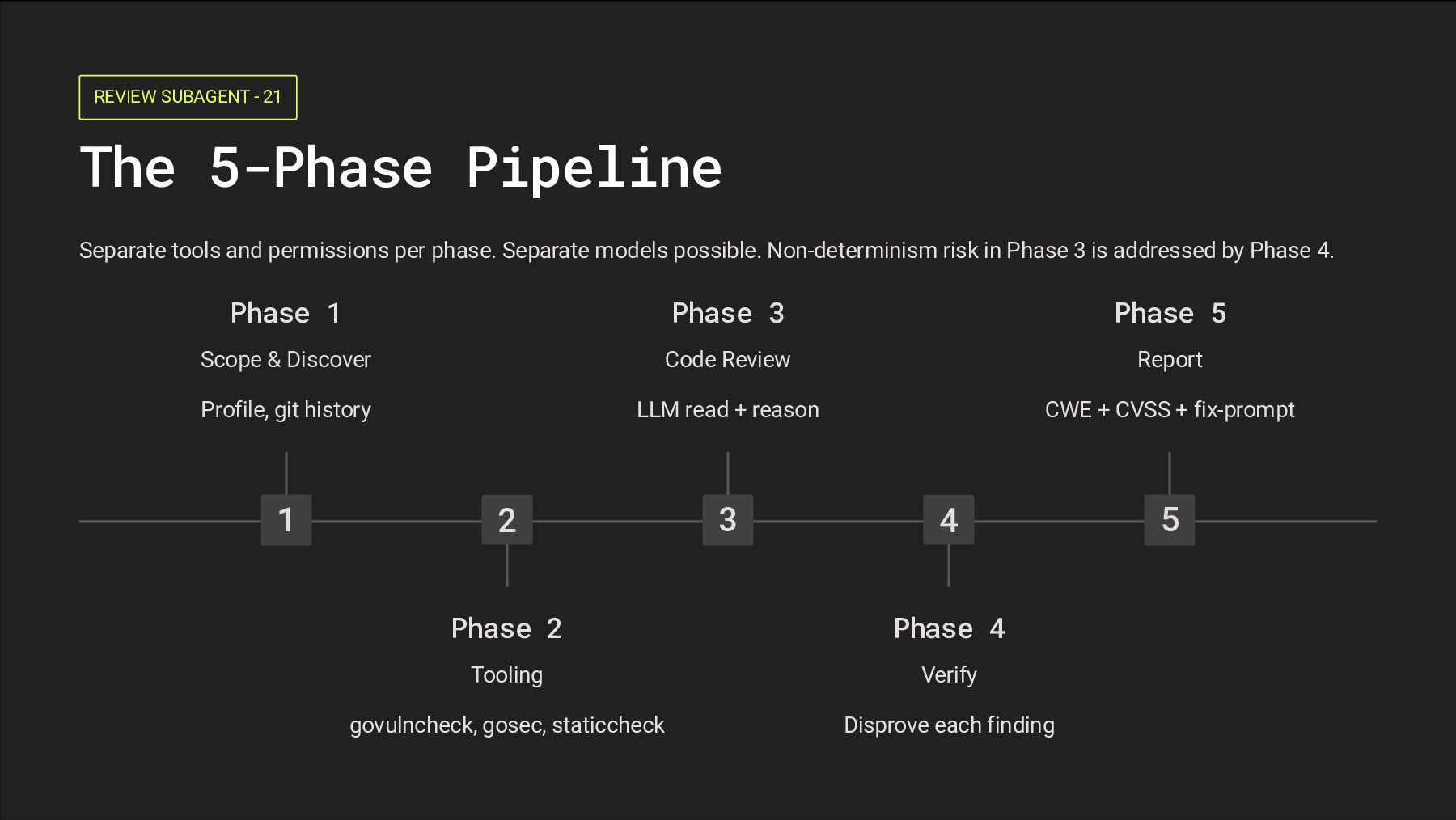
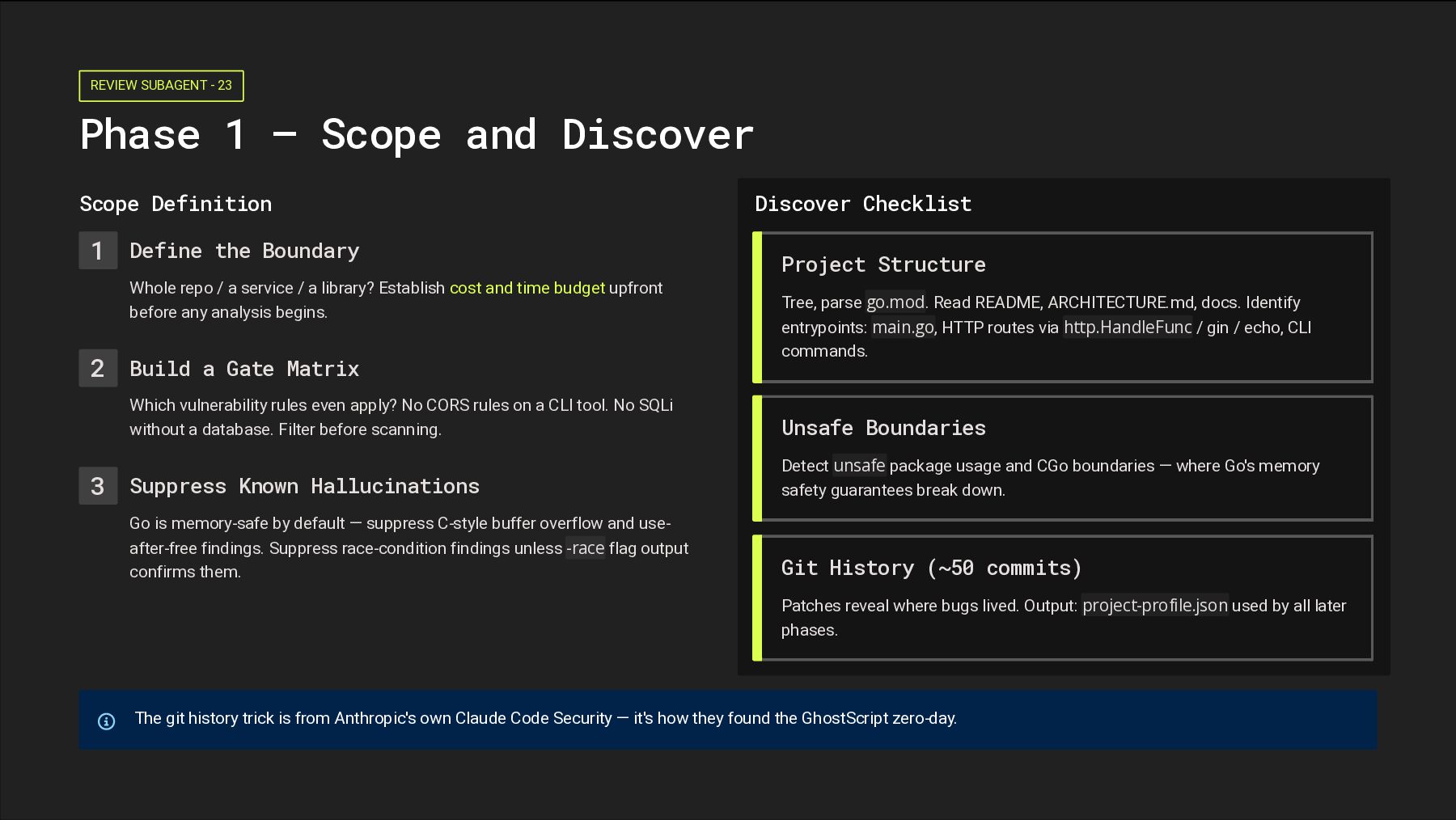
Scope Definition 1 Define the Boundary Whole repo / a service / a library? Establish cost and time budget upfront before any analysis begins. 2 Build a Gate Matrix Which vulnerability rules even apply? No CORS rules on a CLI tool. No SQLi without a database. Filter before scanning. 3 Suppress Known Hallucinations Go is memory-safe by default — suppress C-style buffer overflow and use- after-free findings. Suppress race-condition findings unless -race flag output confirms them. Discover Checklist Project Structure Tree, parse go.mod. Read README, ARCHITECTURE.md, docs. Identify entrypoints: main.go, HTTP routes via http.HandleFunc / gin / echo, CLI commands. Unsafe Boundaries Detect unsafe package usage and CGo boundaries — where Go's memory safety guarantees break down. Git History (~50 commits) Patches reveal where bugs lived. Output: project-profile.json used by all later phases. The git history trick is from Anthropic's own Claude Code Security — it's how they found the GhostScript zero-day.
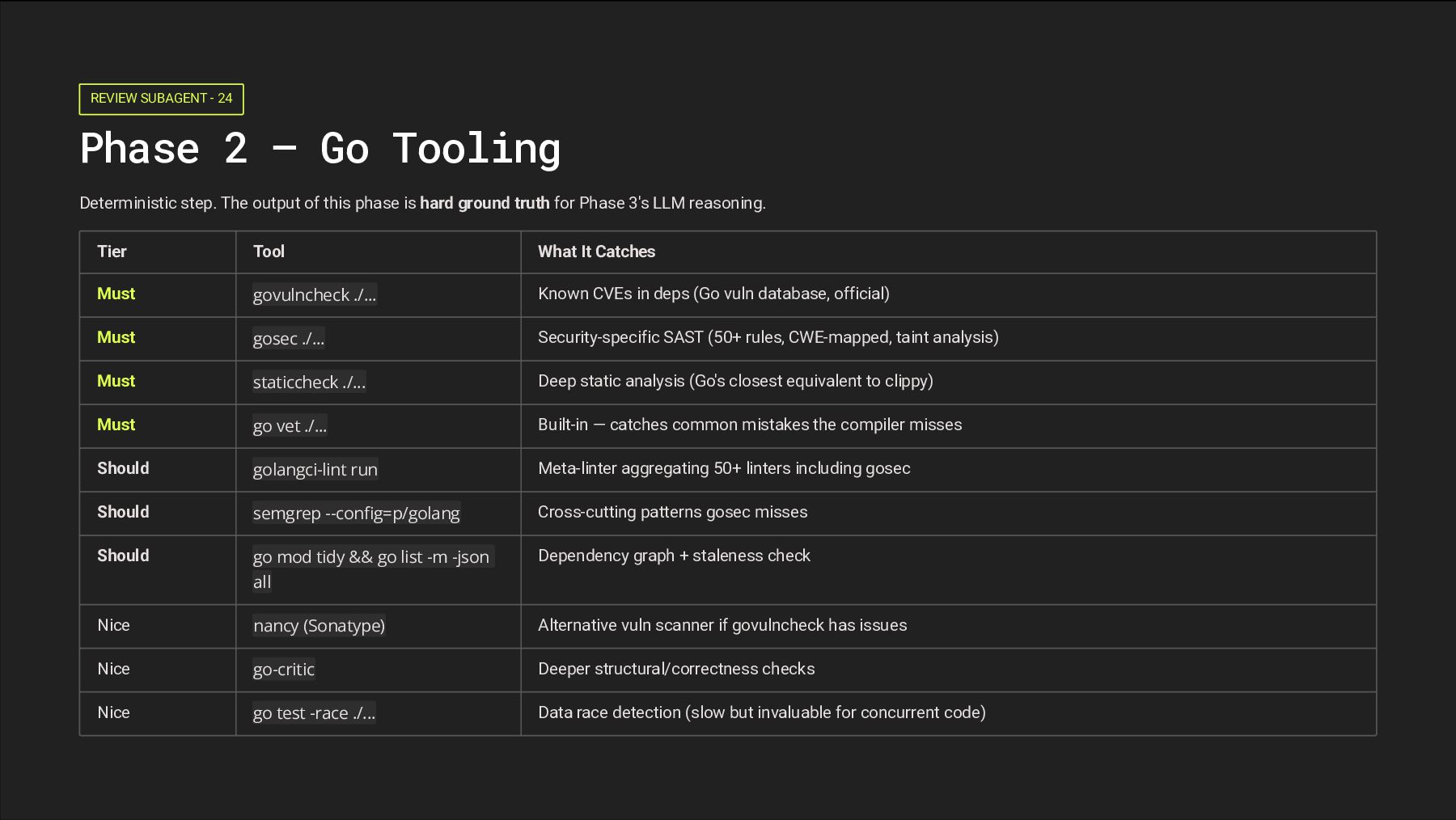
step. The output of this phase is hard ground truth for Phase 3's LLM reasoning. Tier Tool What It Catches Must govulncheck ./... Known CVEs in deps (Go vuln database, official) Must gosec ./... Security-specific SAST (50+ rules, CWE-mapped, taint analysis) Must staticcheck ./... Deep static analysis (Go's closest equivalent to clippy) Must go vet ./... Built-in — catches common mistakes the compiler misses Should golangci-lint run Meta-linter aggregating 50+ linters including gosec Should semgrep --config=p/golang Cross-cutting patterns gosec misses Should go mod tidy && go list -m -json all Dependency graph + staleness check Nice nancy (Sonatype) Alternative vuln scanner if govulncheck has issues Nice go-critic Deeper structural/correctness checks Nice go test -race ./... Data race detection (slow but invaluable for concurrent code)
Fleet Design A: Single Review Agent [Phase 3 Agent] scope: Read, Grep, Glob refs: go skill + vuln-class refs loops over modules outputs findings JSON Advantages Simple, cheap (~1x token cost), deterministic-ish across runs, easy to debug. Disadvantages Gets tunnel vision, slower wall-clock on big codebases, may miss niche vuln classes. Recommendation: Start with single. Fan out to fleet at ~100+ files or for niche vuln classes. Design B: Fleet of Specialized Subagents [Orchestrator] ├─→ [handler-auditor] refs/http-*.md ├─→ [taint-tracer] refs/injection.md ├─→ [crypto-reviewer] refs/crypto.md └─→ [authn-reviewer] refs/authn-authz.md ↓ [Aggregator] dedups, ranks Advantages Faster wall-clock, tighter focus per agent, easier to debug individual specialists. Disadvantages 3–5x token cost, dedup is non-trivial, more moving parts to orchestrate. Single agent wins when Fleet wins when Repo fits in context (<100–150 files) Repo exceeds context limits Task is reasoning-dominated Task is coverage-dominated Cost predictability matters Accuracy dominates cost Simple pipeline, less to debug Niche expertise needed (crypto, goroutine safety) Netflix Railguard: super-agent reaches 80–90% of 12-agent recall at 25–35% of the cost. AIxCC finalist BugBuster (single-agent) found 41 vulns — 2nd-highest in the field. Trail of Bits runs 84 specialist agents and reports ~200 bugs/week vs ~15/week baseline.
Killer) Phase 4 is a three-step hybrid that transforms probabilistic LLM findings into high-confidence, actionable results. Don't skip it. It is the single biggest lever for reducing false positives. Why Phase 4 Exists Without verification, 86% of findings are noise. Developers stop trusting the tool. The whole pipeline collapses. Phase 4 is what makes the output something a team will actually act on. Reachability check eliminates unreachable paths immediately LLM disproval stress-tests each finding against itself Deterministic cross-reference anchors confidence in hard evidence Output Routing Each finding exits Phase 4 with a confidence tier and explicit reasoning: HIGH → Surface directly to developers MED → Route to AppSec team for triage LOW → Drop. Do not surface. Inspired by Anthropic's /security-review multi-stage verification architecture. 1 Reachability Trace source → sink. Can untrusted input actually reach this code path? Unreachable → demote to LOW immediately. 2 LLM Disproval Prompt: "Try to DISPROVE this finding. Check if validated upstream. Check edge cases and false positive patterns." + ad-hoc static tools run per finding 3 Cross-Reference Did Phase 2 tools flag this? govulncheck / gosec / semgrep agree? Both flag → confidence UP. Only LLM → confidence DOWN.
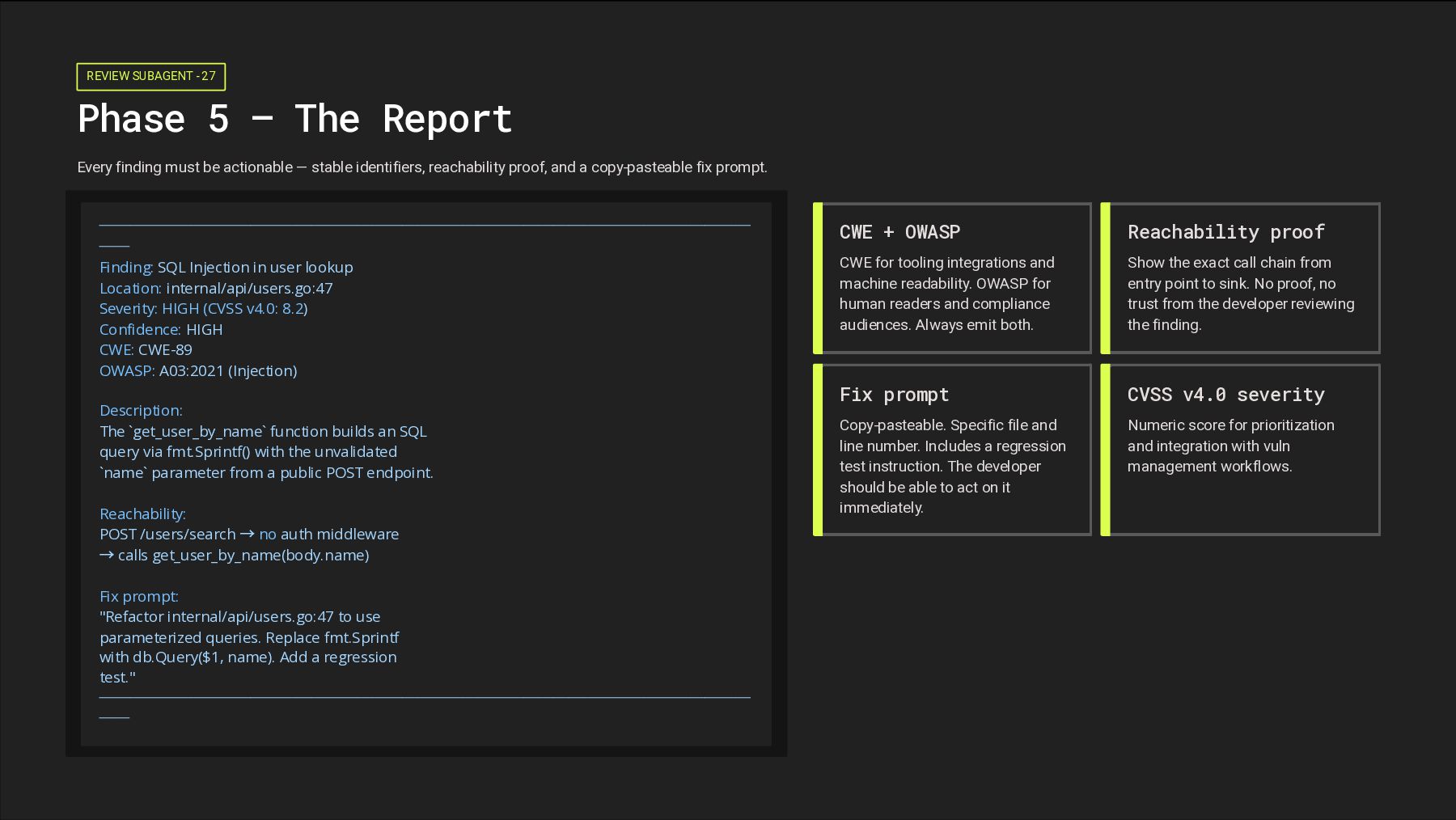
finding must be actionable — stable identifiers, reachability proof, and a copy-pasteable fix prompt. ─────────────────────────────────────────── ── Finding: SQL Injection in user lookup Location: internal/api/users.go:47 Severity: HIGH (CVSS v4.0: 8.2) Confidence: HIGH CWE: CWE-89 OWASP: A03:2021 (Injection) Description: The `get_user_by_name` function builds an SQL query via fmt.Sprintf() with the unvalidated `name` parameter from a public POST endpoint. Reachability: POST /users/search → no auth middleware → calls get_user_by_name(body.name) Fix prompt: "Refactor internal/api/users.go:47 to use parameterized queries. Replace fmt.Sprintf with db.Query($1, name). Add a regression test." ─────────────────────────────────────────── ── CWE + OWASP CWE for tooling integrations and machine readability. OWASP for human readers and compliance audiences. Always emit both. Reachability proof Show the exact call chain from entry point to sink. No proof, no trust from the developer reviewing the finding. Fix prompt Copy-pasteable. Specific file and line number. Includes a regression test instruction. The developer should be able to act on it immediately. CVSS v4.0 severity Numeric score for prioritization and integration with vuln management workflows.
design is where most pipelines fail silently. Vague roles produce vague findings. Unconstrained tool access creates accidental risk. These principles are what separate a 14%-TPR pipeline from one a team trusts. Narrow the Role "You are a Go HTTP security auditor. Not a general code reviewer." Specificity forces the model to stay in scope and enumerate the right threat classes. Enumerate Language Footguns Parser differentials, goroutine leaks, missing HTTP timeouts, unvalidated redirects, race conditions in shared state. Don't assume the model knows your language's failure modes. Demand Fixed JSON Schema Forces discipline in output. Makes Phase 4 verification mechanically possible. Prevents the model from hedging findings into prose. Scope Tools Per Phase Read+Grep+Glob for review. Bash only for tooling. Write only for report. A subagent that can't write to disk can't accidentally break the codebase. Right Model Per Phase Opus for orchestration, review and verify. Sonnet/Haiku for discover, tooling, and report. Match reasoning depth to task complexity — and cost. Explicit FP Instruction "Drop low-confidence findings. False positives cost trust." Say it explicitly. The model will optimize for what you reward. A reviewer subagent that can't run Bash can't accidentally exfiltrate. Minimal permissions are a security control, not just a best practice.
code. Same prompt. Different findings. This is uniquely dangerous in a security context — not just an inconvenience. "I scanned for X" stops being a guarantee. Inconsistent findings break vuln management workflows. A passing run on Tuesday says nothing about Thursday. Compliance auditors cannot accept probabilistic evidence chains. Run 1 Run 2 Run 3 Found IDOR in /orders/{id} Found IDOR in /users/{id}/profile Found IDOR in /orders/{id} AND /admin/users Missed /admin/users Missed /orders/{id} Missed /users/{id}/profile Mitigations Ensemble Runs Run Phase 3 multiple times. Take the union of findings across runs. Deterministic Anchor Phase 2 catches the boring stuff reliably. Don't ask the LLM to reason about what a script can check. Verification Phase Turns probabilistic findings into more-confident, cross-referenced ones. Hard-Code Critical Checks Things you must catch → scripts the agent runs, not things it reasons about.
the pipeline can't do is as important as knowing what it can — here are the boundaries worth internalizing. Prompt Injection Anthropic's /security-review Action is explicitly "not hardened against prompt injection — only use to review trusted PRs." Scope the agent's reachable filesystem and never run it against arbitrary third-party repos or unknown contributors. Skill Supply Chain Snyk ToxicSkills (Feb 2026): 36% of published agent skills contain security flaws, with 76 carrying active malicious payloads. Treat skills like code — audit before installing, and never curl | sh from unknown repos. AI Finds and Introduces Vulns DualGauge shows less than 12% secure-pass@1; SecureAgentBench finds more than 20% of correct fixes introduce new vulnerabilities. Verify fixes with the same rigor you apply to findings. Not a Replacement for SAST/DAST/Pentest This pipeline is a complement, not a substitute — systematic deterministic analysis remains your foundation, and no reasoning model produces the auditable evidence chain a compliance auditor requires. Patterns not yet tried (exploratory): AST-tree context step · Revision loops (scan-fix-rescan until clean) · Cross-model ensemble with majority vote (49– 172% TPR improvement at 5% FPR) · Per-project memory (Semgrep Memories → 2.8× FP improvement) · SQLite checkpointing for crash recovery (Netflix Railguard) · Self improvement loop from new issues
Forensic Analysis Now You're no longer reviewing someone's reasoning. The author is a model. The code looks right. There's no conversation to be had. That changes what security review means — and it's why the bottleneck moved to us. 02 — Structure Beats Prompting. Every Time. Phase pipeline. Language-scoped skills. Vuln-class references. Scoped tool permissions. Verification step. The naive version gives you 86% false positives. The structured version gives you something a developer team will actually act on. 03 — This Is a Probabilistic Instrument Same code, same prompt, different findings. Never trust, always verify. Anchor with deterministic tools. Hard- code the things you must catch. Use this like a sharp, fast, occasionally- wrong junior reviewer — not a guarantee. The structured pipeline is not about making AI smarter. It's about making the system reliable despite AI's limitations.
2026 — The Acceleration Whiplash Faros AI Productivity Paradox (2025 original) Faros AI Key Takeaways from DORA 2025 Cui et al. / Management Science The Effects of Generative AI on High-Skilled Work Management Science journal DOI Google DORA Report 2025 METR RCT July 2025 + Feb 2026 follow-up AISLE 12/12 OpenSSL CVEs (January 2026) AI Security Capabilities Anthropic Red Team Claude Opus 4.6 — 500+ zero-days methodology DualGauge (arXiv) DualGauge benchmark paper (arXiv 2511.20709) DualGauge HTML full paper SecureAgentBench (arXiv) SecureAgentBench paper (arXiv 2509.22097) SecureAgentBench HTML Semgrep: Finding vulnerabilities in modern web apps using Claude Code and Codex Agent & MCP & Skills Anthropic — Introducing Agent Skills agentskills.io spec Anthropic Tool Search Tool Anthropic engineering — code execution with MCP Anthropic Agent Skills Structuring Security Skills Community security skill repos agamm/claude-code-owasp (OWASP Top 10 + ASVS + 20 languages) netresearch/security-audit-skill (PHP, 19 reference files) getsentry/skills (Sentry's production skills) afiqiqmal/claude-security-audit (OWASP Top 10:2025 + NIST CSF 2.0): AgentSecOps/SecOpsAgentKit (25+ skills) mukul975/Anthropic-Cybersecurity-Skills (754 skills, 5 frameworks): VoltAgent/awesome-claude-code-subagents (security category): wshobson/agents Trail of Bits Trail of Bits skills repo Trail of Bits dimensional-analysis plugin blog How we made Trail of Bits AI-native Snyk Top 9 Claude Skills for Cybersecurity ToxicSkills — 36% of skills contain security flaws Practitioner reviews TimOnWeb — "I Checked 5 Security Skills, Only One Is Worth Installing": DEV.to — afiqiqmal slash command writeup Standards and taxonomies OWASP ASVS GitHub OWASP Secure Code Review Cheat Sheet Structuring Security Skills Community security skill repos agamm/claude-code-owasp (OWASP Top 10 + ASVS + 20 languages) netresearch/security-audit-skill (PHP, 19 reference files) getsentry/skills (Sentry's production skills) afiqiqmal/claude-security-audit (OWASP Top 10:2025 + NIST CSF 2.0): AgentSecOps/SecOpsAgentKit (25+ skills) mukul975/Anthropic-Cybersecurity-Skills (754 skills, 5 frameworks): VoltAgent/awesome-claude-code-subagents (security category): wshobson/agents Trail of Bits Trail of Bits skills repo Trail of Bits dimensional-analysis plugin blog How we made Trail of Bits AI-native Snyk Top 9 Claude Skills for Cybersecurity ToxicSkills — 36% of skills contain security flaws Practitioner reviews TimOnWeb — "I Checked 5 Security Skills, Only One Is Worth Installing": DEV.to — afiqiqmal slash command writeup Standards and taxonomies OWASP ASVS GitHub OWASP Secure Code Review Cheat Sheet Subagent architecture Anthropic Anthropic /security-review GitHub Action How and when to use subagents in Claude Code - https://claude.com/blog/subagents-in-claude-code Claude Code automated security reviews Netflix Netflix-Skunkworks/railguard-skill (fleet-vs-single experiment) Trail of Bits — AIxCC Trail of Bits Buttercup wins 2nd place AIxCC: Team Atlanta — AIxCC Team Atlanta post-AIxCC writeup VulAgent (arXiv) VulAgent hypothesis-validation multi-agent paper (arXiv 2509.11523) Google Project Naptime / Big Sleep Project Naptime (Project Zero) Evaluating Threats & Automating Defense at Google | [un]prompted 2026 Semgrep Semgrep Assistant overview Semgrep — zero false positive SAST with AI memory SonarSource Getting started with SonarQube agentic analysis + Claude Code SonarSource thoughts on Claude Code Security Snyk remediation Snyk — Claude Code: a welcome evolution in the remediation loop GitHub Copilot Autofix GitHub blog — Found means fixed (Copilot Autofix + CodeQL) tl;dr sec tl;dr sec #319 — Netflix Source-to-Sink, fleet-vs-single tl;dr sec #311 — Slack security agents, Trail of Bits skills AIxCC SoK paper SoK: DARPA AIxCC (arXiv 2602.07666) Hybrid verification / FPR reduction IRIS: LLM-Assisted Static Analysis (OpenReview): Go security tooling Trail of Bits — Unexpected security footguns in Go's parsers Cato CTRL — Weaponizing Claude Skills with MedusaLocker
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}