This is a talk I held at the AWS Summit in Stockholm 2014, telling the story of QuizUp, the choices that were made and why, and how those choices impacted the success of QuizUp (and our lives) during the days after launch.
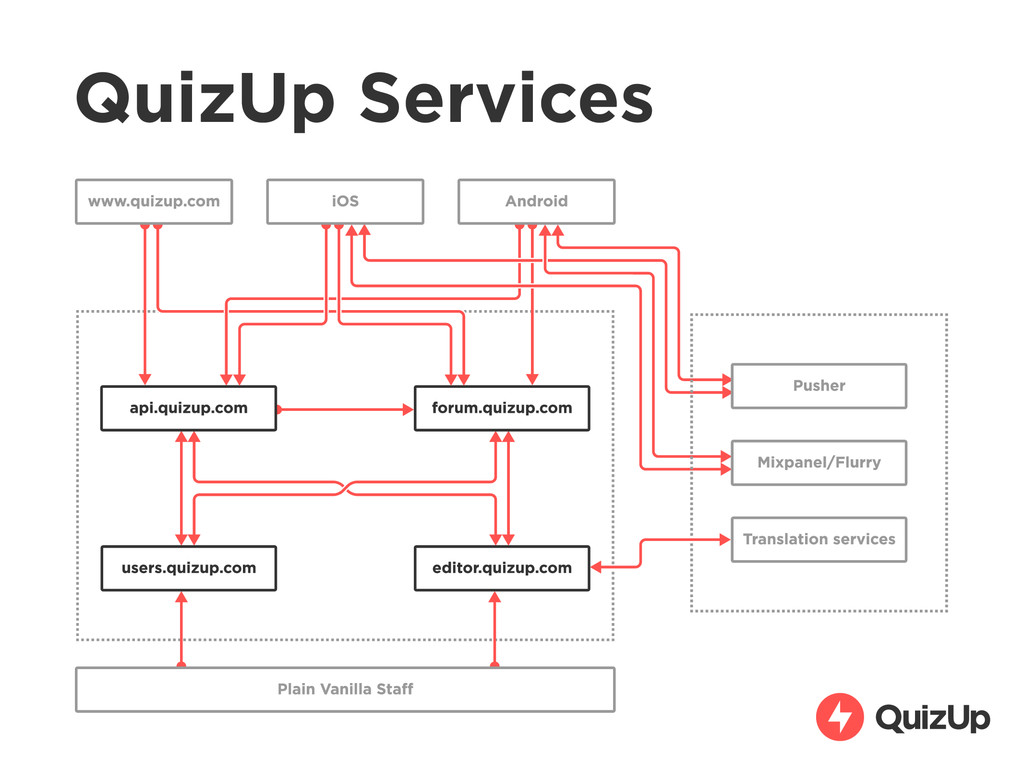
• such as: • Eurovision QuizUp • Twilight QuizUp • Math QuizUp • NatGeo QuizUp • First: proof-of-concepts for investors • Then: Satellites to pull users to QuizUp network
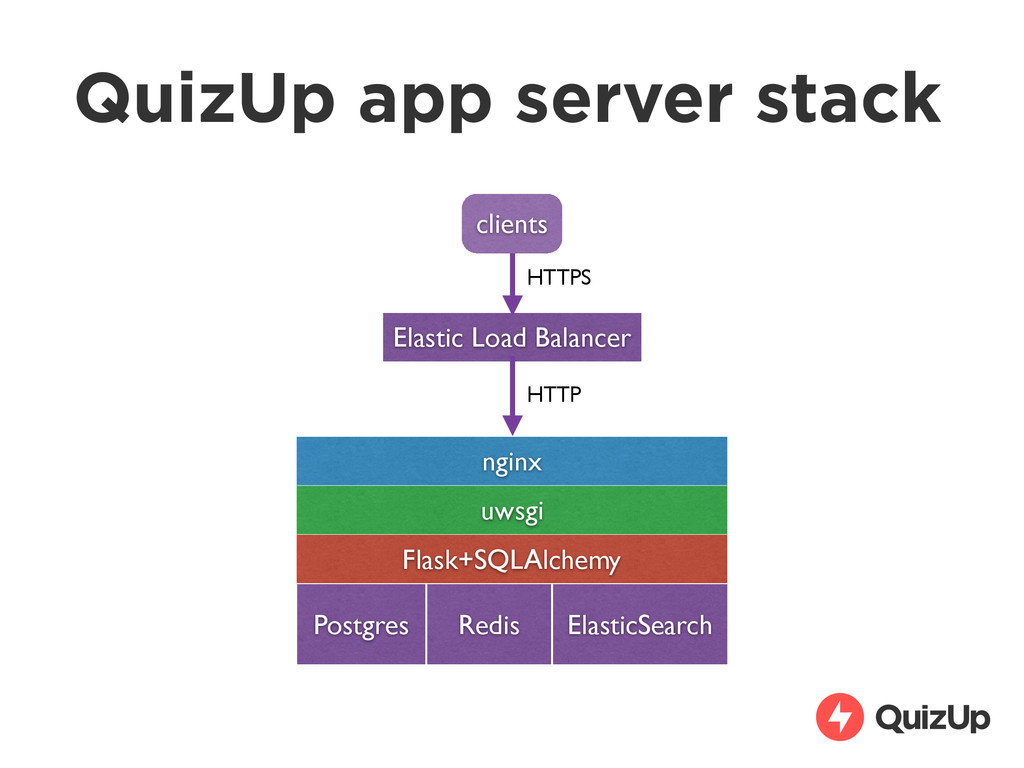
fashion (aws) • Prefer SaaS to in-house solutions • Allows a small team to accomplish a lot quickly • We also use Heroku for many internal apps • Intended to use more PaaS
freeze — an entire *week* before launch! • Load testing (locust, 20x m1.small nodes) • 5 weeks of beta • Force-update and graceful maintenance features built into API and clients • Coordinate with Infrastructure vendor: • prewarm ELBs • Increased instance limits
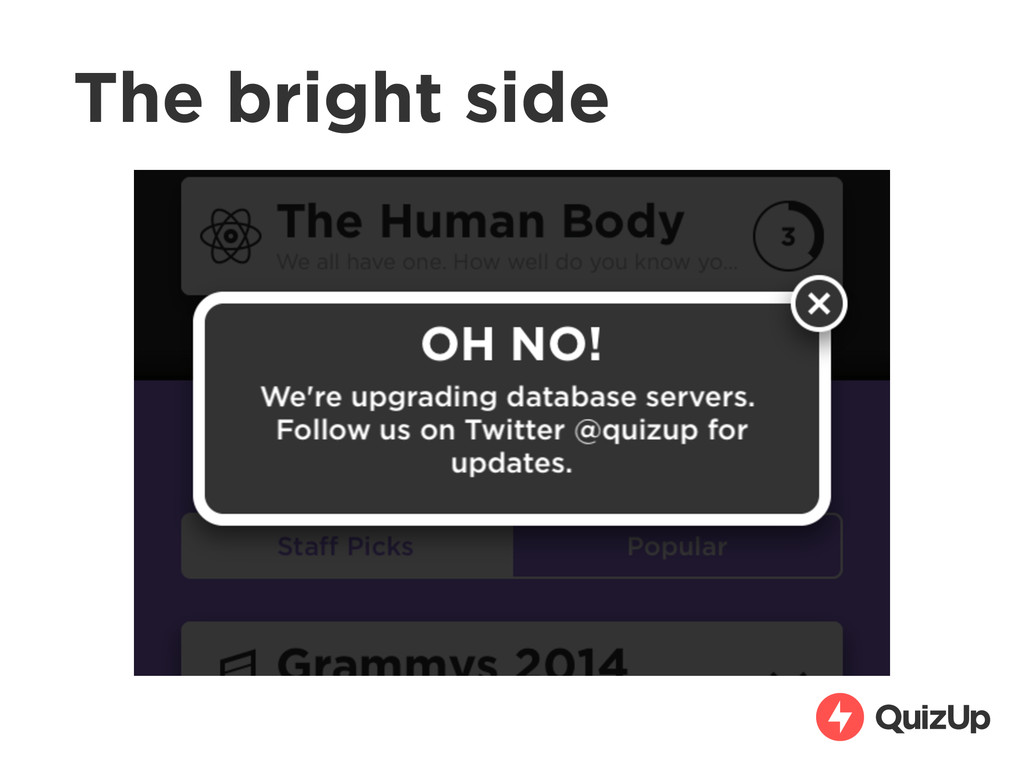
in 6 days. • Yes there was downtime: • First db sharding ~2 days after launch (29m) • Second sharding 5 days after launch (90m) • Third sharding 6 days after launch (40m)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}