Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
20160422 文献紹介
Search
Yuta
April 22, 2016
Education
180
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
20160422 文献紹介
Yuta
April 22, 2016
More Decks by Yuta
See All by Yuta
NLP2016 報告
sudo
0
200
NLP2016 発表スライド
sudo
0
230
20160218 文献紹介
sudo
0
270
20150909 発表資料
sudo
0
150
20150820 文献紹介
sudo
0
200
20150708 文献紹介
sudo
0
170
20150610 文献紹介
sudo
0
200
20150512 文献紹介
sudo
0
190
20150415 文献紹介
sudo
1
240
Other Decks in Education
See All in Education
SL AMIGOS 教育格差と私たちの取り組み - スリランカの支援学校への支援プロジェクト:リシンドゥ リオ 氏 (別府溝部学園短期大学 ビジネス観光コース 留学生):2720 Japan O.K. ロータリーEクラブ2026年4月6日卓話
2720japanoke
0
630
2026年度春学期 統計学 第7回 データの関係を知る(2)ー 回帰と決定係数 (2026. 5. 21)
akiraasano
PRO
0
160
Case Studies - Lecture 12 - Information Visualisation (4019538FNR)
signer
PRO
0
150
Estimating Group × Time Interaction in Scale-Transformed CEFR-J Self-Assessment Scores: A Case in Study-Abroad Research
uranoken
0
110
2026年度春学期 統計学 第9回 確からしさを記述する ー 確率 (2026. 5. 28)
akiraasano
PRO
0
110
Course Review - Lecture 13 - Information Visualisation (4019538FNR)
signer
PRO
1
2.6k
輻射安全管理系統2.0暨輻防e++學園平台說明會
aecrp
0
1k
自己紹介 / who-am-i
yasulab
6
7k
モブ社員がモブエンジニアを名乗って得られたこと_20260413
masakiokuda
4
540
[2026前期火5] 論理学(京都大学文学部 前期 第2回)「論理的な正しさはどこにあるのか」
yatabe
0
980
0415
cbtlibrary
0
220
「機械学習と因果推論」入門 ② 回帰分析から因果分析へ
masakat0
0
720
Featured
See All Featured
Refactoring Trust on Your Teams (GOTO; Chicago 2020)
rmw
35
3.5k
Heart Work Chapter 1 - Part 1
lfama
PRO
8
36k
The Art of Programming - Codeland 2020
erikaheidi
57
14k
Stop Working from a Prison Cell
hatefulcrawdad
274
21k
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
790
Navigating Team Friction
lara
192
16k
Let's Do A Bunch of Simple Stuff to Make Websites Faster
chriscoyier
508
140k
Ruling the World: When Life Gets Gamed
codingconduct
0
260
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
180
Optimizing for Happiness
mojombo
378
71k
Product Roadmaps are Hard
iamctodd
PRO
55
12k
WENDY [Excerpt]
tessaabrams
11
38k
Transcript
文献紹介 長岡技術科学大学 自然言語処理研究室 須戸 悠太 1
紹介文献 • Emmanuel Morin; Amir Hazem; Florian Boudin; Elizaveta Loginova-Clouet
• LINA: Identifying Comparable Documents from Wikipedia • Proceedings of the Eighth Workshop on Building and Using Comparable Corpora – PP.88-91 2
概要 • BUCC2015で発表したLINAシステム • hapax words の数を収集することにより、同等 の文書を識別 • 分類棚の推論とクロスリンガル情報を用いて,
上記の方法を拡張 – 約60%の精度で同等の文書が特定できた 3
導入 • 統計的機械翻訳において重要なパラレル コーパス • 同等のリソースを識別するための既存のアプ ローチの評価 – Wikipedia等 •
言語にとらわれないアプローチ 4
基本的な手法 • 文書内で1度しか出現しないかつ4文字以上 の単語(hapax words)を含む文書をbags of words で索引付けする • hapax
wordsを最も多く共有する文書は並列 であると考えられる. – Wikipediaで並列文書を検出する際に非常によく 機能する. 5
hapax words の例 • Hapax words の ほとんどは固有 名詞や数値に 関係するもの
– 今回はURLや 特殊文字も保 持 6
文書のペアの選択 • ソース-ターゲット文書のペアを検索するた めに,ソース言語(EN)の文書ごとにhapax wordsの最大数を共有するターゲット言語(FR, DE)の文書を20文ずつ選択する(baseline) 7
分類棚の利用 • 多重に割り当てられたソース文書が多いため, 削っていく必要がある.(baseline) • 共有の単語(以下分類棚)の最大数と文書の ペアを保持することによって潜在的な複数の ソースドキュメントを削除する. – 60%→10%と激減した.(+pigeonhole)
8
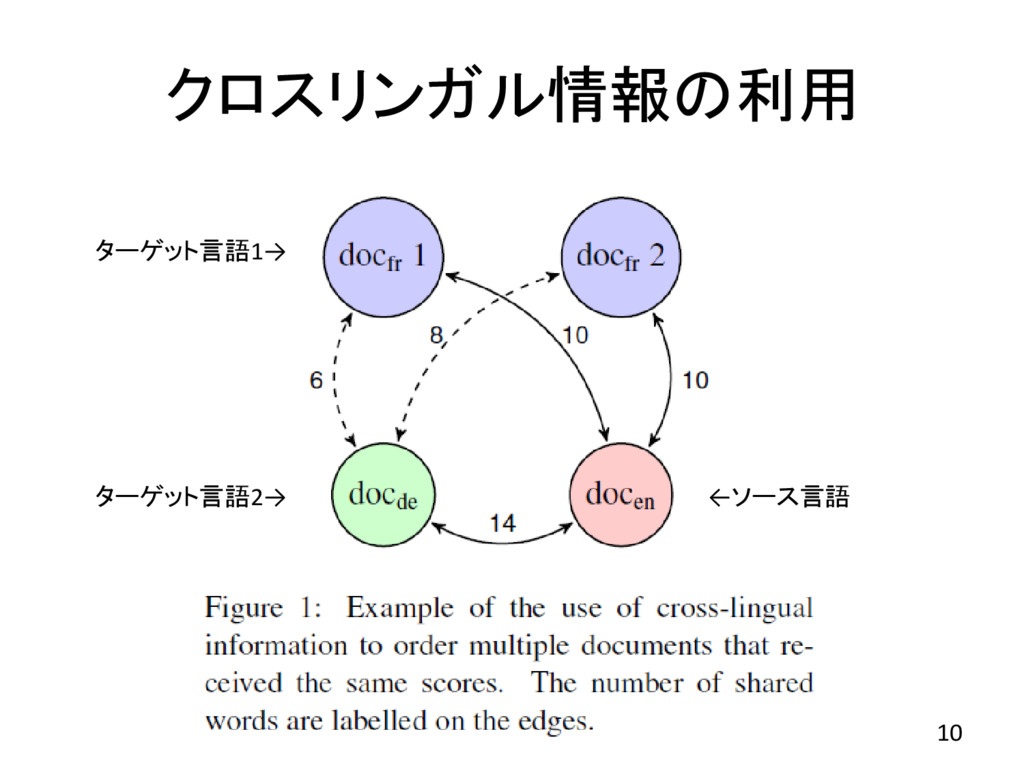
クロスリンガル情報の利用 • ソース-ターゲット言語と異なる言語でソース 言語とペアリングしている文書を利用 • ターゲット文書とhapax words の共有数を比 較し最大となるターゲット文書を選択する. •
多重に割り当てられたソース文書は10% →4%未満に減少(cross-lingual) 9
クロスリンガル情報の利用 10 ←ソース言語 ターゲット言語1→ ターゲット言語2→
実験 • フランス語-英語、ドイツ語―英語のペアで 実験 • 以下の3つの尺度で評価 – 平均精度(MAP) – 正解率(Succ)
– 上位5文の精度(P@5) 11
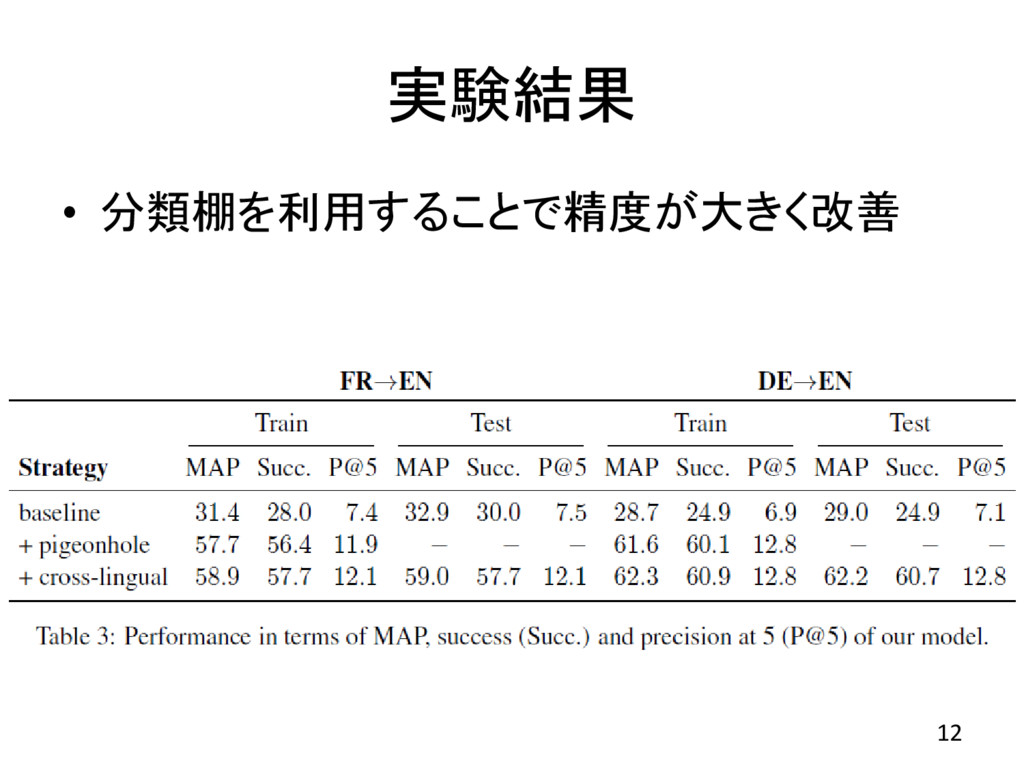
実験結果 • 分類棚を利用することで精度が大きく改善 12
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}