Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
NLP2016 発表スライド
Search
Yuta
March 22, 2016
Education
230
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
NLP2016 発表スライド
Yuta
March 22, 2016
More Decks by Yuta
See All by Yuta
20160422 文献紹介
sudo
0
180
NLP2016 報告
sudo
0
200
20160218 文献紹介
sudo
0
270
20150909 発表資料
sudo
0
150
20150820 文献紹介
sudo
0
200
20150708 文献紹介
sudo
0
170
20150610 文献紹介
sudo
0
200
20150512 文献紹介
sudo
0
190
20150415 文献紹介
sudo
1
240
Other Decks in Education
See All in Education
Visionary Initiative: Future Intelligence 「未来の知性と社会の礎を築く」|Science Tokyo(東京科学大学)
sciencetokyo
PRO
0
530
2026年度春学期 統計学 第1回 イントロダクション ー 統計的なものの見方・考え方について (2026. 4. 9)
akiraasano
PRO
0
170
Estimating Group × Time Interaction in Scale-Transformed CEFR-J Self-Assessment Scores: A Case in Study-Abroad Research
uranoken
0
110
Data Physicalisation - Lecture 9 - Next Generation User Interfaces (4018166FNR)
signer
PRO
1
1.1k
면접관 눈에 띄는 데이터 분석 포트폴리오 만드는 법 | 2026년 5월 세미나
datarian
0
850
JAWS-UG初心者支部#81 GWにEduJAWSと何か作ろうもくもく会!
otsuki
0
140
生成AIを授業の相棒にするデータサイエンス入門(「デジタル✕探究」イノベーターズフォーラム テクニカルセッション講演資料)
datascientistsociety
PRO
0
310
コミュニティを通じた_キャリア設計のススメ_20260424.pdf
masakiokuda
0
330
2026年度春学期 統計学 第5回 分布をまとめるー記述統計量(平均・分散など) (2026. 5. 7)
akiraasano
PRO
0
150
[2026前期火5] 論理学(京都大学文学部 前期 第4回)「 ならば(→)の導入と証明ネット」
yatabe
0
480
2026年度春学期 統計学 第9回 確からしさを記述する ー 確率 (2026. 5. 28)
akiraasano
PRO
0
110
Stardy 会社紹介資料
stardy
0
1.5k
Featured
See All Featured
JavaScript: Past, Present, and Future - NDC Porto 2020
reverentgeek
52
6k
How To Speak Unicorn (iThemes Webinar)
marktimemedia
1
490
The Curse of the Amulet
leimatthew05
2
13k
Product Roadmaps are Hard
iamctodd
PRO
55
12k
SERP Conf. Vienna - Web Accessibility: Optimizing for Inclusivity and SEO
sarafernandez
2
1.5k
Test your architecture with Archunit
thirion
1
2.3k
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
Hiding What from Whom? A Critical Review of the History of Programming languages for Music
tomoyanonymous
2
870
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
The Cost Of JavaScript in 2023
addyosmani
55
10k
Dealing with People You Can't Stand - Big Design 2015
cassininazir
367
27k
Building Flexible Design Systems
yeseniaperezcruz
330
40k
Transcript
“個性に着目した対話システム”の 自然性の評価実験 須戸 悠太†,高椋 琴美† †,谷田 泰郎† †,山本 和英† ††シナジーマーケティング株式会社
†長岡技術科学大学 1
背景 (1/2) • シナジーマーケティング社では、Societas※という価 値観モデルによって個人の個性を規定し,個性の違 いによる人の行動・興味・人間関係の持ち方などの モデル化を目指している. • 特定の人の発話を学習して発話を生成する“個性” を持たせたロボットと人が雑談することによって得ら
れる対話データを収集したい. 2 ※アンケートや行動などから性格診断ができるようなもの
背景 (2/2) • 先行研究で対話システムの「個性性」と「自然性」に ついての評価を行ってきたが,自然性が担保されて いないと個性性の評価が難しい. • 対話の自然性を上げるには学習データの数を増や すことが一番取り組みやすい. –
個性性を確保しながらデータ数を増やす必要がある. • 本研究では,どれくらいのデータ数があれば自然性 を担保できるのかの評価実験を行った. 3
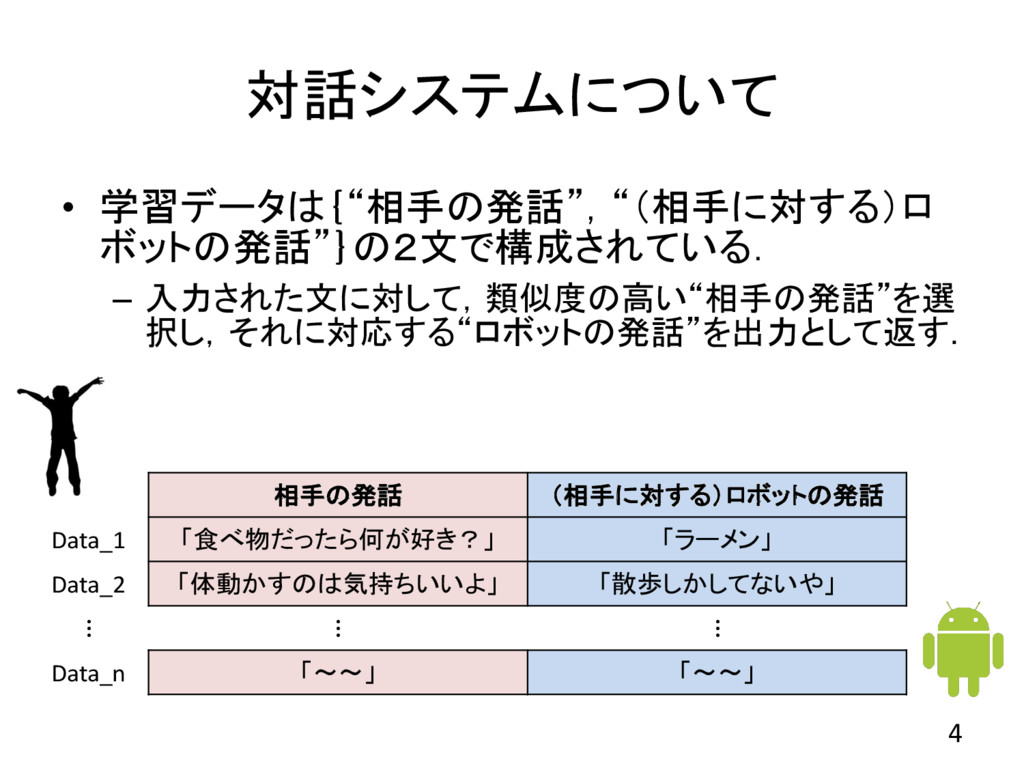
対話システムについて • 学習データは{“相手の発話”,“(相手に対する)ロ ボットの発話”}の2文で構成されている. – 入力された文に対して,類似度の高い“相手の発話”を選 択し,それに対応する“ロボットの発話”を出力として返す. 4 相手の発話 (相手に対する)ロボットの発話
Data_1 「食べ物だったら何が好き?」 「ラーメン」 Data_2 「体動かすのは気持ちいいよ」 「散歩しかしてないや」 ⋮ ⋮ ⋮ Data_n 「~~」 「~~」
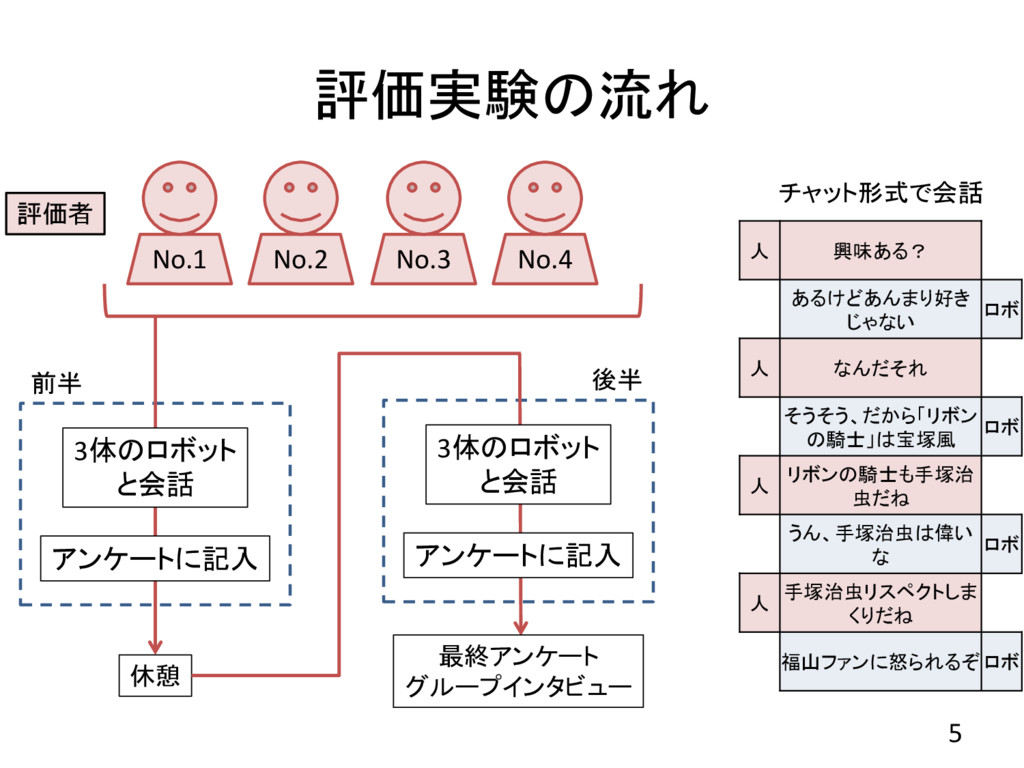
評価実験の流れ 5 No.1 評価者 No.2 No.3 No.4 3体のロボット と会話 アンケートに記入
休憩 前半 3体のロボット と会話 アンケートに記入 後半 最終アンケート グループインタビュー チャット形式で会話 人 興味ある? あるけどあんまり好き じゃない ロボ 人 なんだそれ そうそう、だから「リボン の騎士」は宝塚風 ロボ 人 リボンの騎士も手塚治 虫だね うん、手塚治虫は偉い な ロボ 人 手塚治虫リスペクトしま くりだね 福山ファンに怒られるぞ ロボ
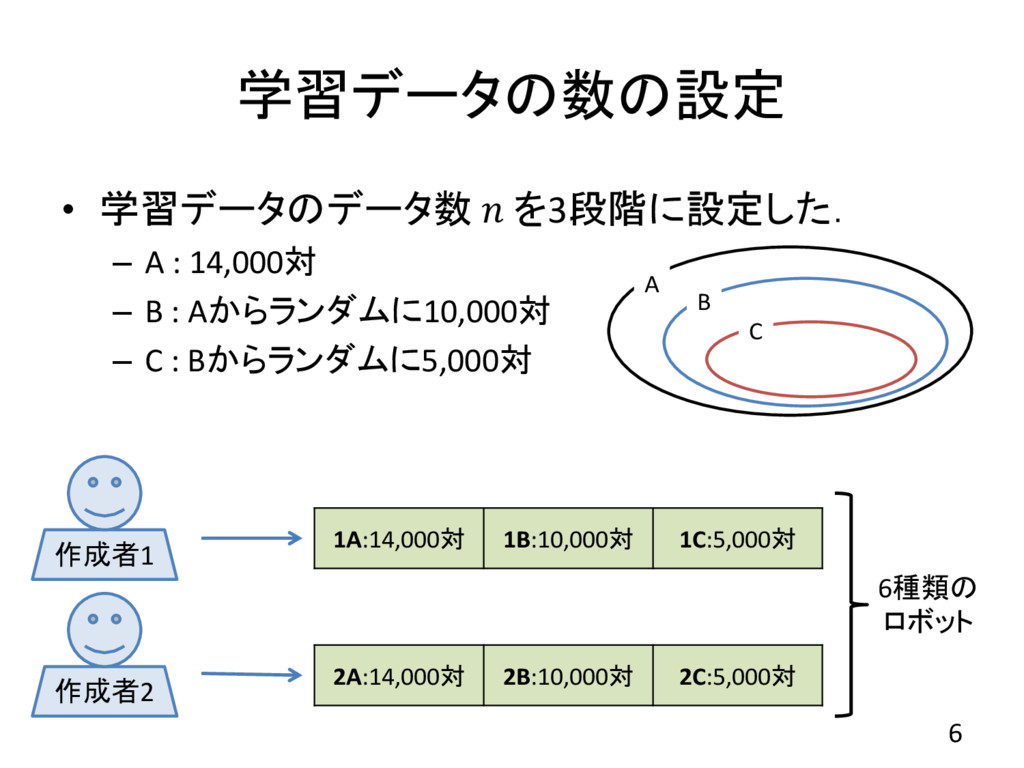
学習データの数の設定 • 学習データのデータ数 を3段階に設定した. – A : 14,000対 – B
: Aからランダムに10,000対 – C : Bからランダムに5,000対 6 1A:14,000対 1B:10,000対 1C:5,000対 2A:14,000対 2B:10,000対 2C:5,000対 A B C 作成者1 作成者2 6種類の ロボット
自然性評価の質問項目 • 各質問項目にそれぞれ10 点満点で評価してもらう. • 評価基準等はこちらからは 指定せず,被験者に判断を 任せた. 7 1.
会話がつながる 2. あなたの発言の意味を理解している 3. 受け答えが自然である 4. 突拍子もない発言が少ない 5. 会話が一方的にならない 6.表現が多様である 7.言い回しに違和感がない 8.話題が豊富である 9. 会話が楽しかった 10. また話したいと思う
アンケート結果の標準化 • 以下の理由から各被験者,前半後半で分けて標準 化を行った. – 各被験者の評価に対する考え方の違い – 前半・後半での実験への慣れなどの環境の変化 – 前半・後半で会話の形式を変えたことで評価が変わった
人もいた • 以下の式で標準化を行い,その合計スコアを求めた. 1. = 1 − 2 =1 2. = − 8 :標準偏差 :評価点 :平均値 :データ数 :標準化された値
結果 9 -8 -6 -4 -2 0 2 4 6
8 10 12 合計スコア 学習データ数 type-1 type-2 5,000 10,000 14,000 考察 (2/2) 考察 (1/2)
考察 (1/2) • 学習データ数5,000から10,000ではマイナス評価の 数が減っている. • 一方で、10,000から14,000ではほとんど差はない. • 作成コスト等を考慮すると,今回使用した対話シス テムでは学習データの数は10,000あれば十分では
ないか. 10
考察 (2/2) • データ数10,000で極端に高評価な箇所について. – データ数10,000のロボットと話した時に出てきた話題が面 白かった. – 会話が成り立ちにくかったロボットとの会話の後に、相性 のいいロボットと話し高評価であった.
• 会話によって引き出される話題やロボットとの相性 も評価に影響されていると考えられる. 11
おわりに • 個性性評価のためには自然性をある程度担保する 必要がある. • 自然性担保に必要なデータ数の評価実験を行った. • 今回使用した対話システムでは,学習データの数は 10,000あれば十分ではという結論が得られた. 12
対話システムを体験することができますので, Synergy Marketingのスポンサーブースにも ぜひ足を運んでみてください!
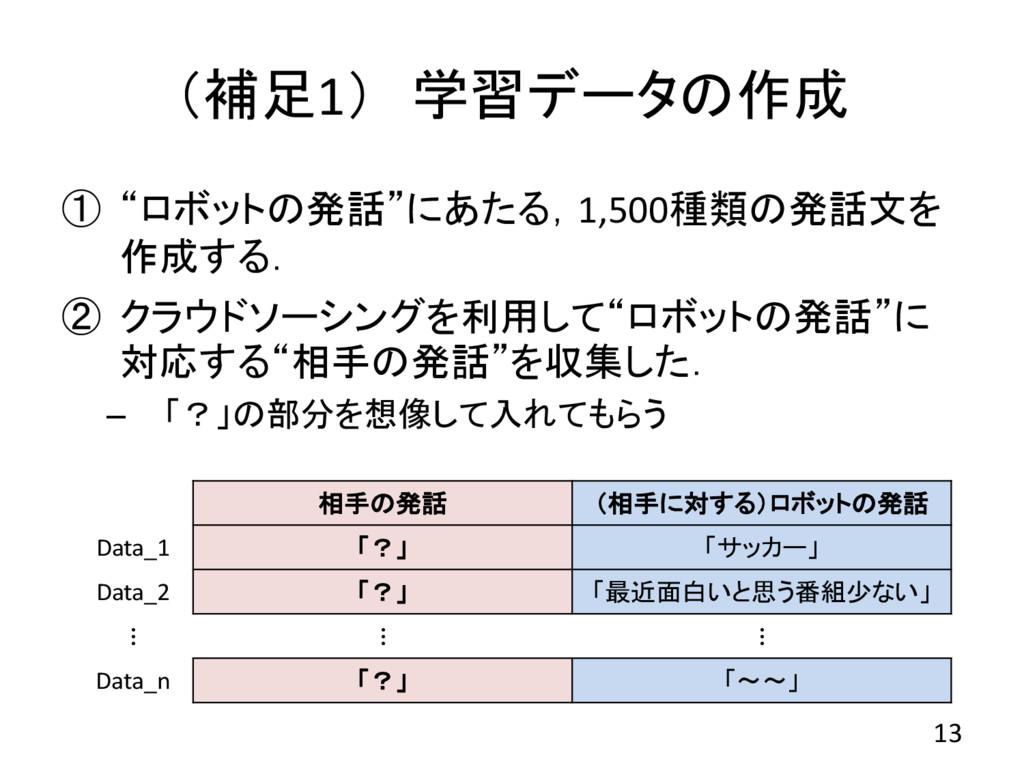
(補足1) 学習データの作成 ① “ロボットの発話”にあたる,1,500種類の発話文を 作成する. ② クラウドソーシングを利用して“ロボットの発話”に 対応する“相手の発話”を収集した. – 「?」の部分を想像して入れてもらう
13 相手の発話 (相手に対する)ロボットの発話 Data_1 「?」 「サッカー」 Data_2 「?」 「最近面白いと思う番組少ない」 ⋮ ⋮ ⋮ Data_n 「?」 「~~」
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}