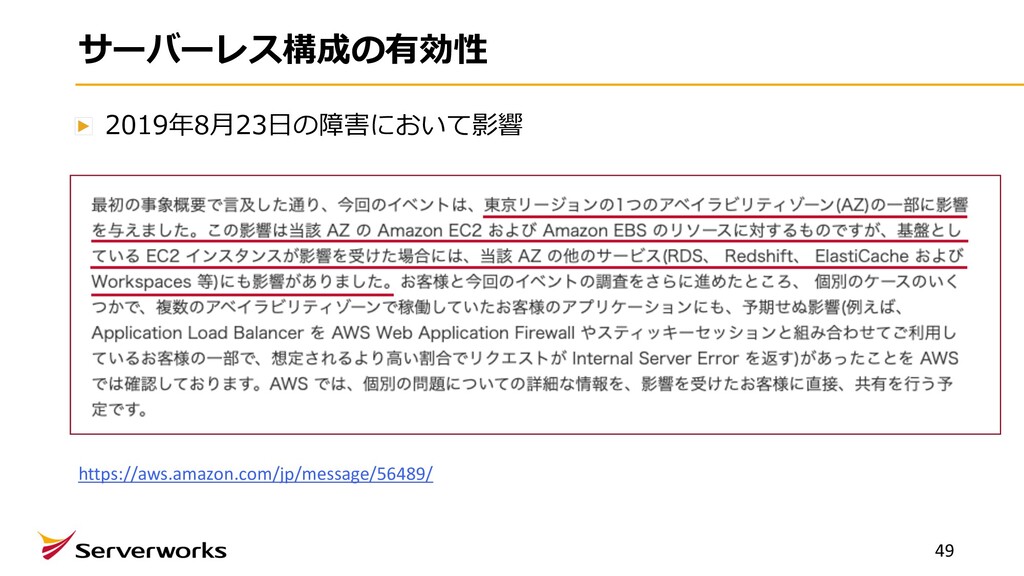
we experienced a cooling failure in a single Availability Zone in the Tokyo (AP- NORTHEAST-1) Region, which has caused one or more of your volumes listed in the 'Affected Resources' tab, to be inaccessible. The cooling failure resulted in hardware failure on one or more storage servers that store your volume(s). We are working to resolve the hardware failures; however, if you have the ability to restore your volume(s) from a recent スナップショット, we recommend that you do so. Given the nature of the hardware failures, we anticipate that recovery will be prolonged as we work to replace the failed components in the affected servers. 訳)8⽉22⽇、東京(AP-NORTHEAST-1)リージョンの単⼀のアベイラビリティーゾーンで冷却障害が発⽣ し、「影響を受けるリソース」タブにリストされている1つ以上のボリュームにアクセスできなくなりました。 冷却障害により、ボリュームを保存する1つ以上のストレージサーバーでハードウェア障害が発⽣しました。 ハードウェア障害の解決に取り組んでいます。 ただし、最新のスナップショットからボリュームを復元できる 場合は、復元することをお勧めします。 ハードウェア障害の性質を考えると、影響を受けるサーバーの障害の あるコンポーネントを交換するために作業するため、復旧が⻑くなることが予想されます。 25 ※Personal Health Dashboardは特定のリソースの状態についてお知らせしてくれるダッシュボードです
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}