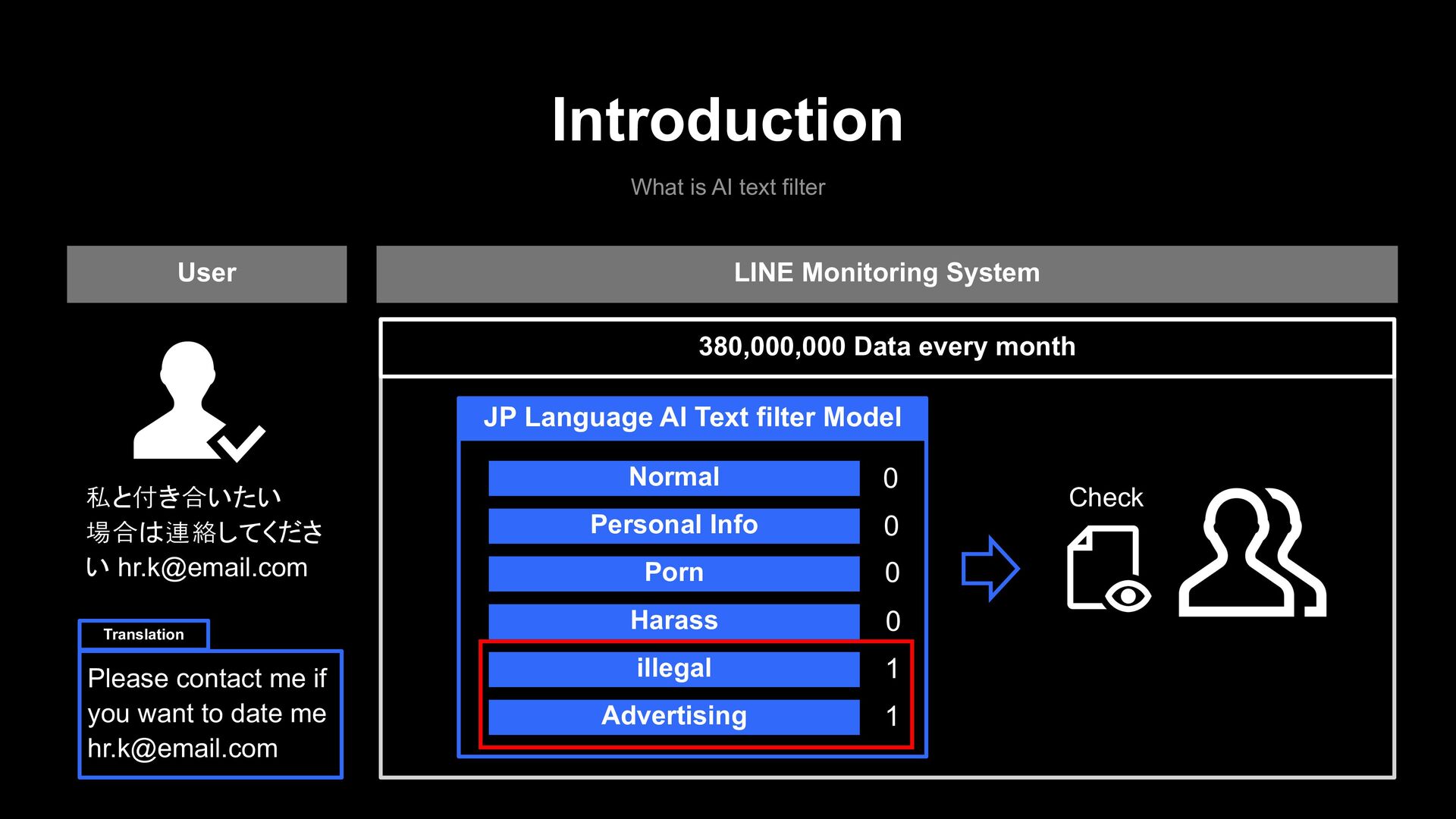
私と付き合いたい 場合は連絡してくださ い [email protected] Please contact me if you want to date me [email protected] Translation Check 380,000,000 Data every month Normal Personal Info Porn Harass illegal Advertising 0 0 0 1 1 JP Language AI Text filter Model 0
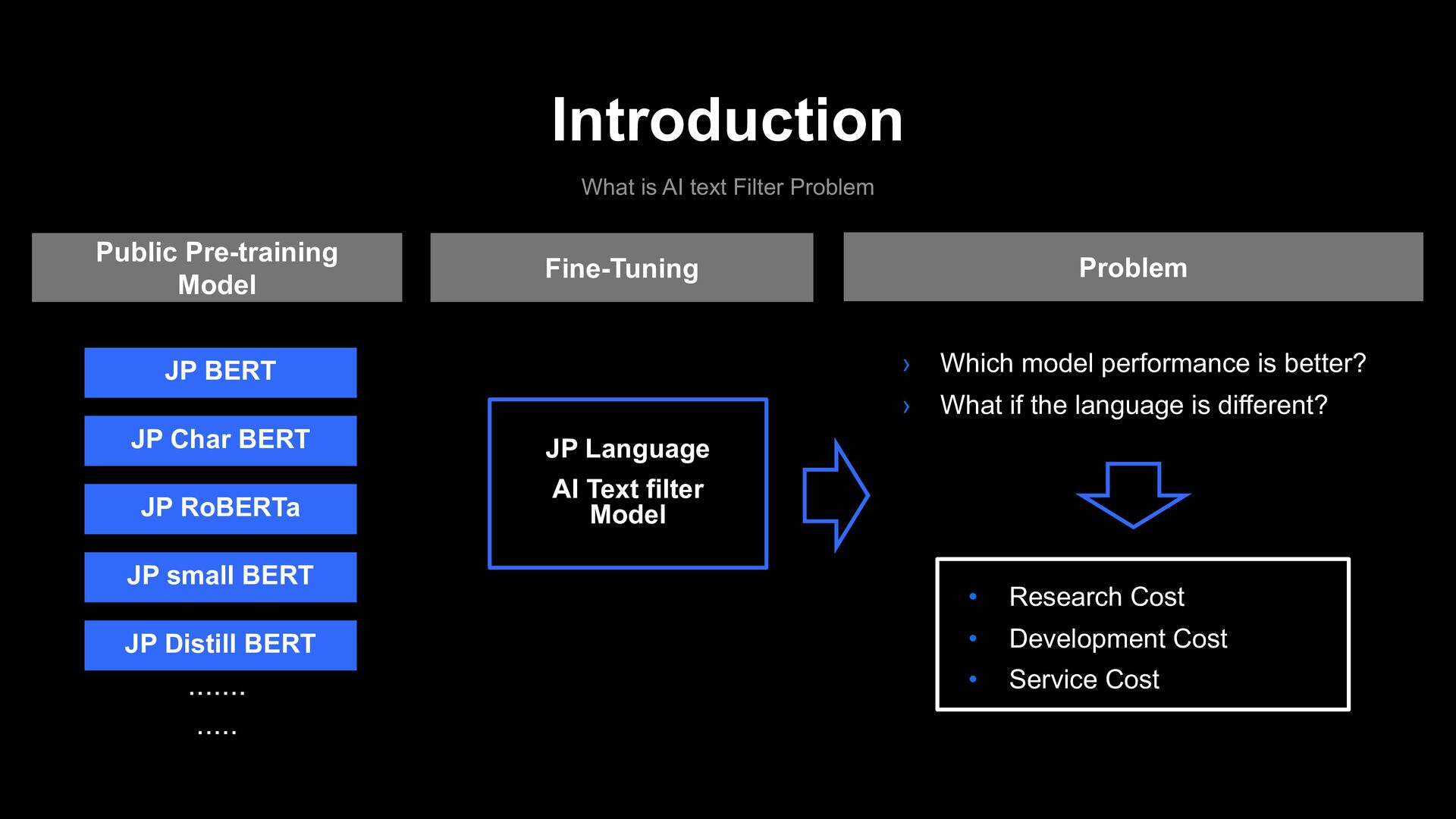
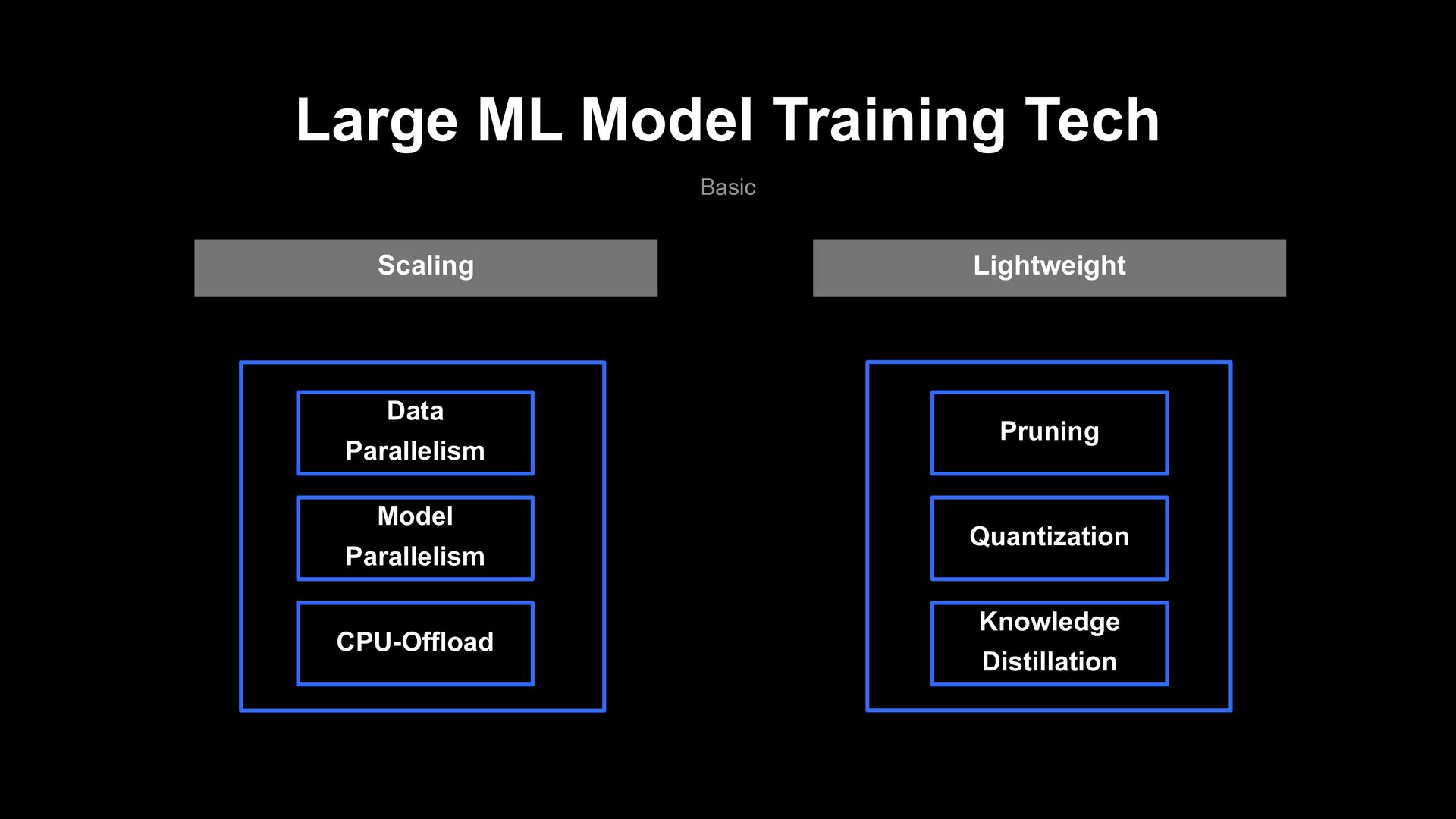
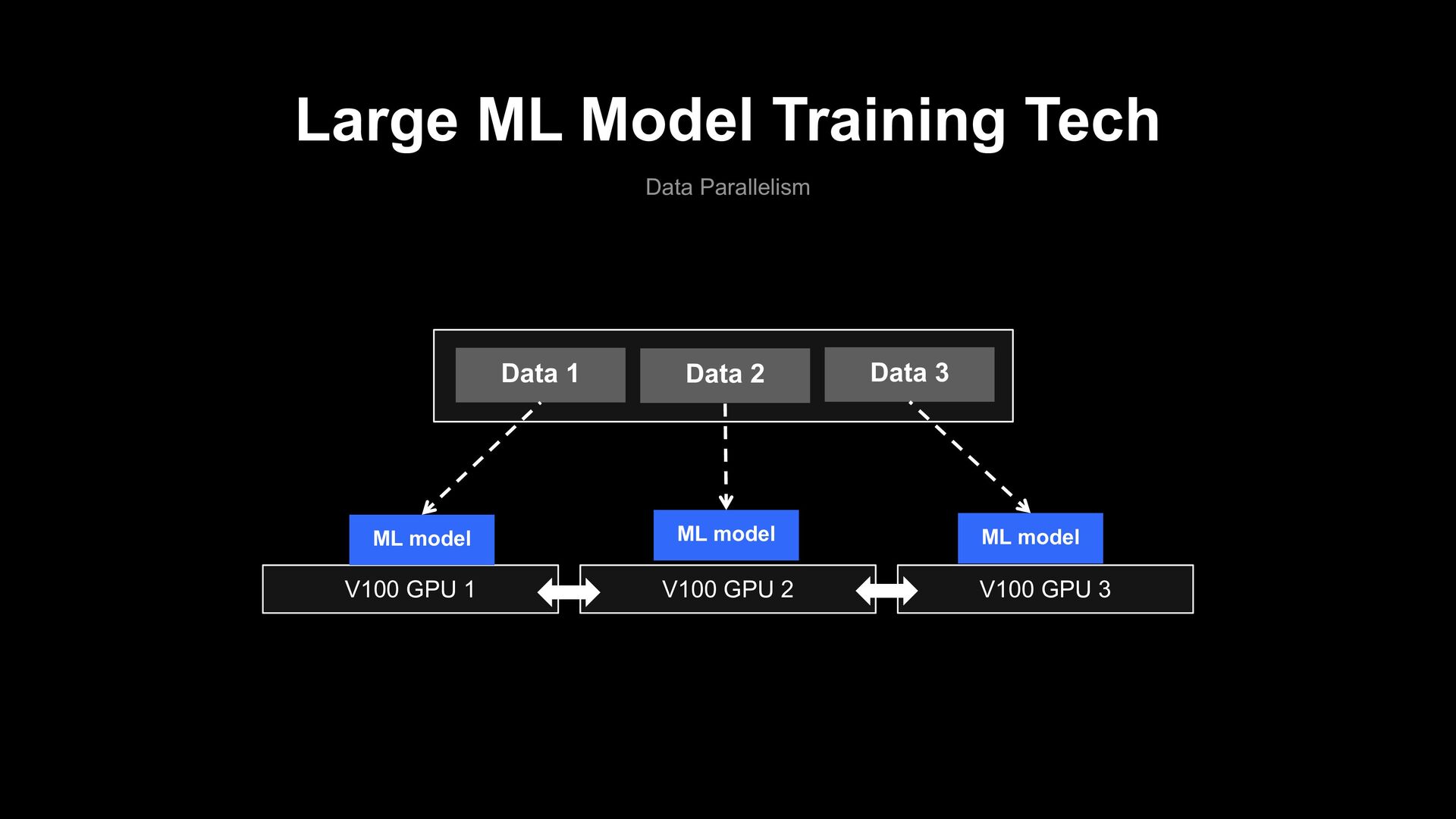
Text filter Model › Which model performance is better? › What if the language is different? • Research Cost • Development Cost • Service Cost Fine-Tuning Problem JP BERT JP Char BERT JP RoBERTa JP small BERT JP Distill BERT ....... ..... Public Pre-training Model
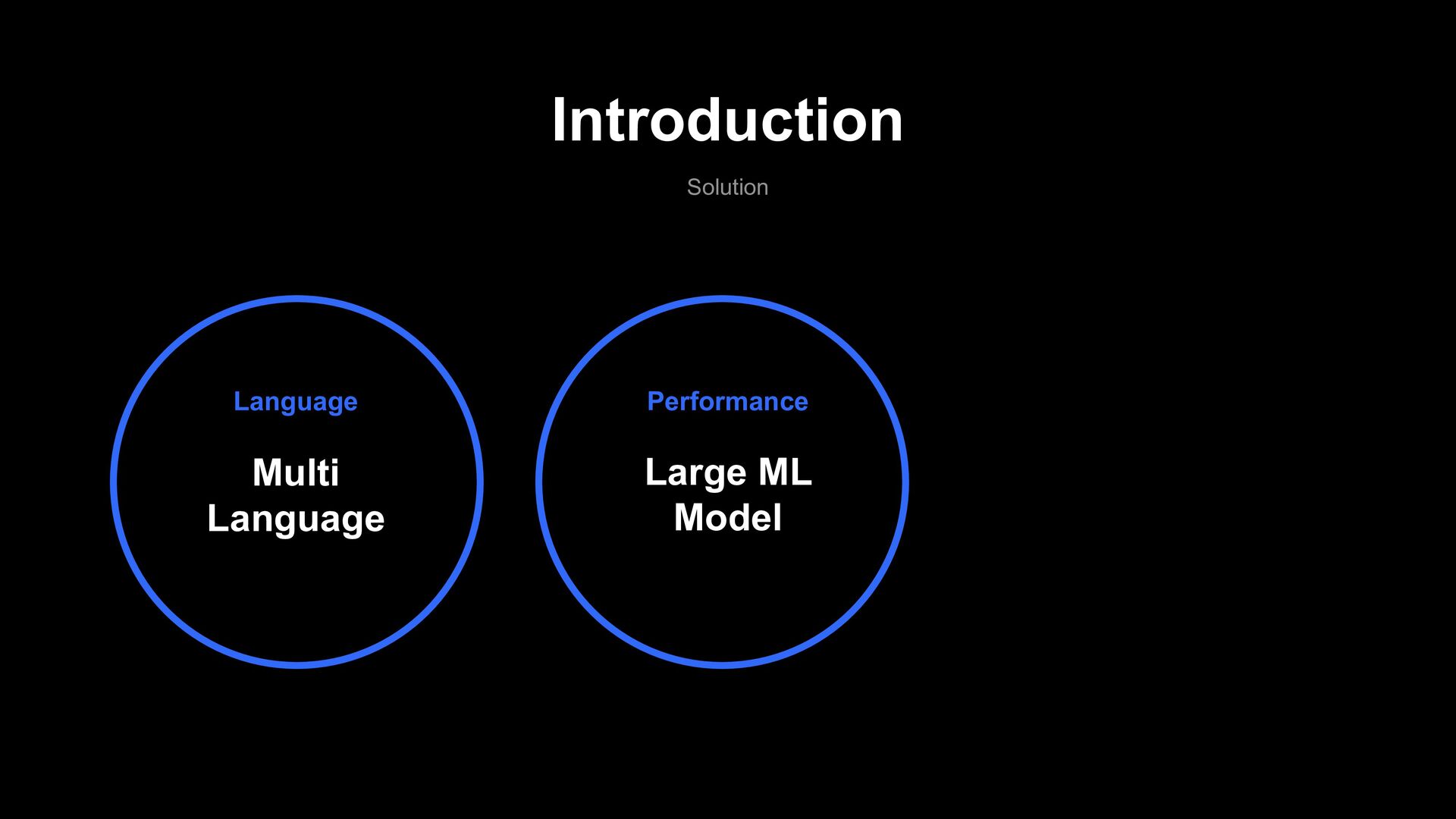
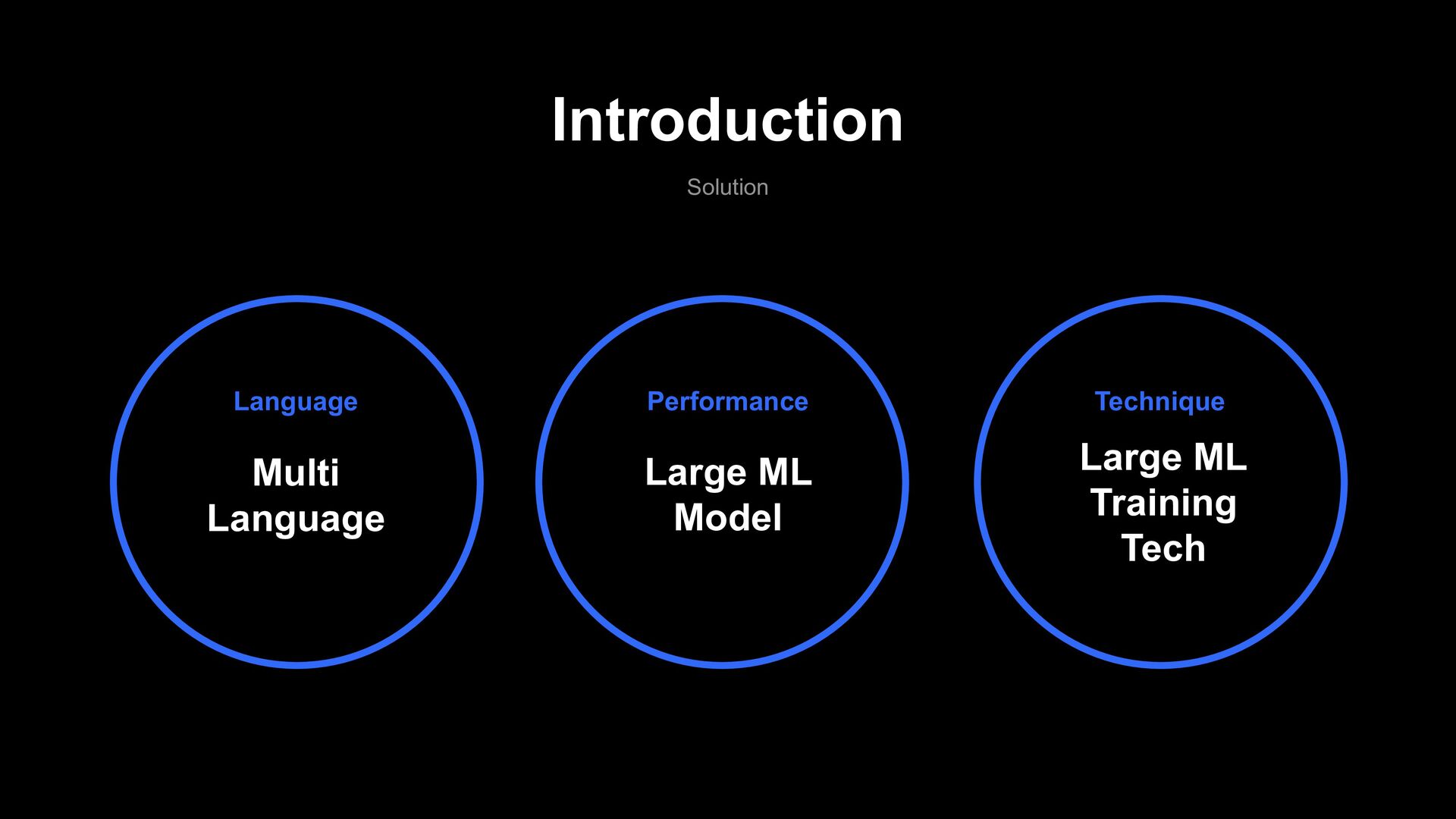
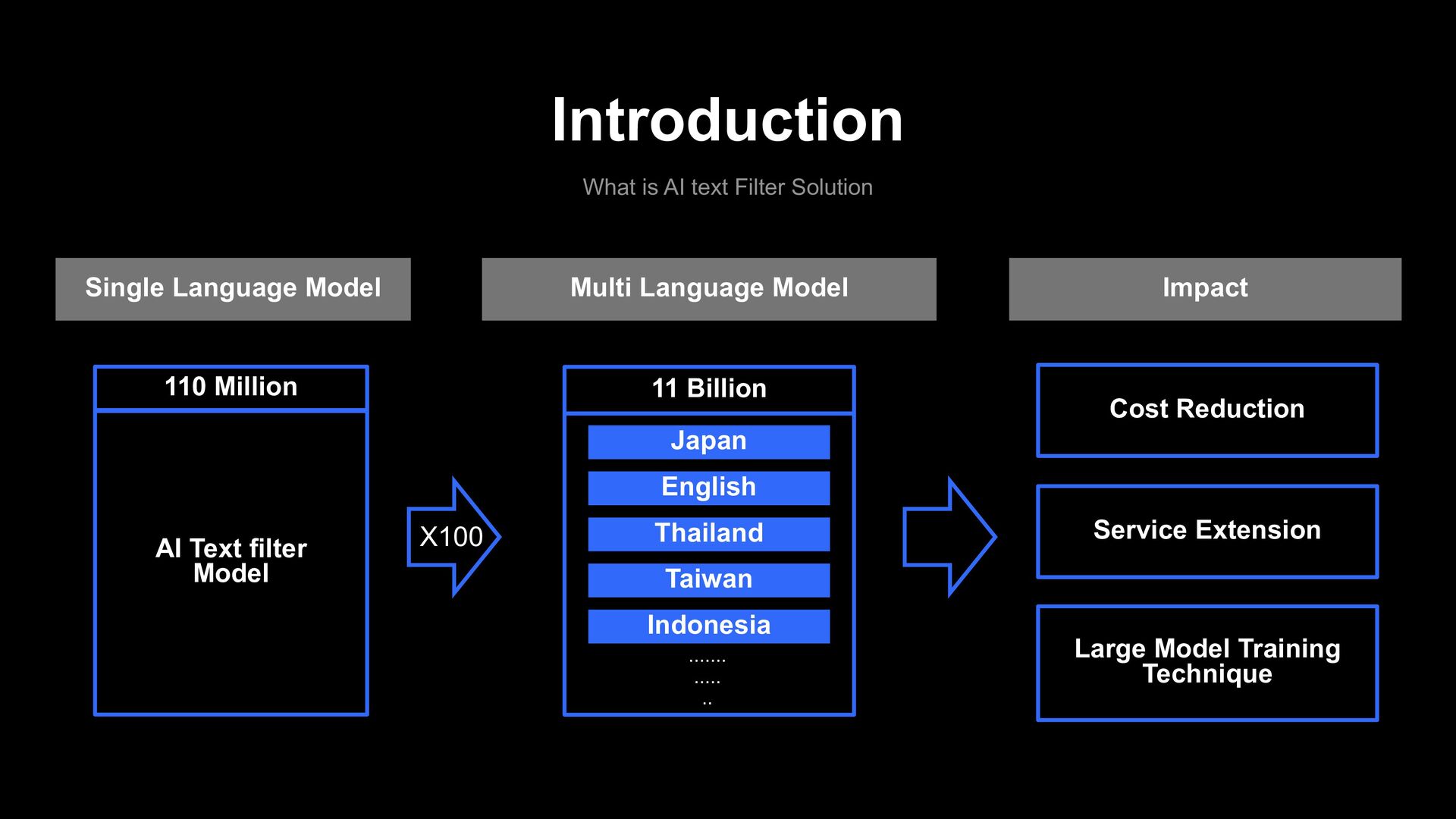
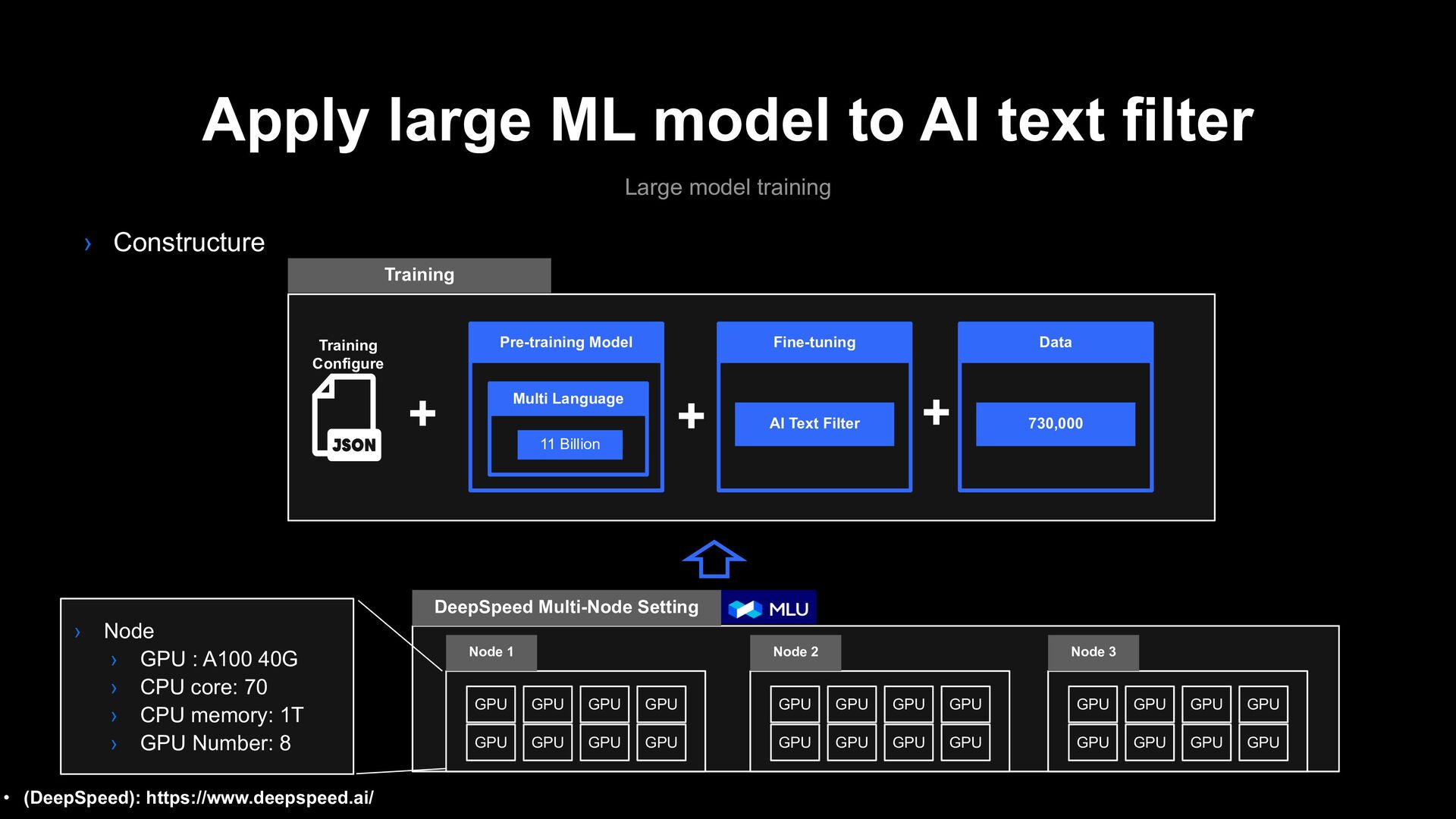
Multi Language Model Impact X100 Cost Reduction Service Extension AI Text filter Model 110 Million Japan English Thailand Taiwan Indonesia ....... ..... .. 11 Billion Large Model Training Technique
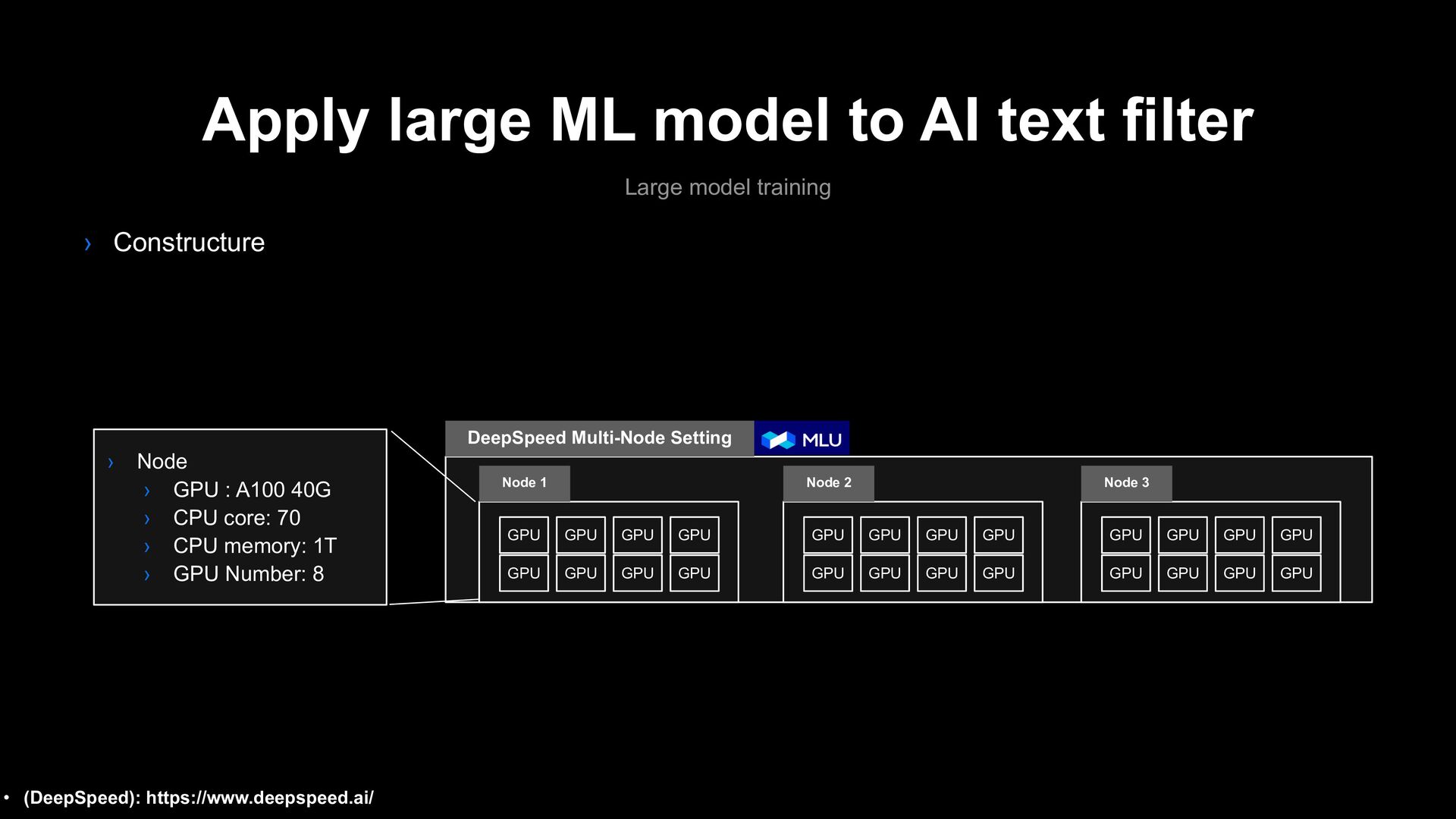
training technology › AI text filter advancement using large multi-language model › With MLU team of LINE MLOps › Model serving › With MLU serving team of LINE ML service
› Framework › Why choose DeepSpeed › Open Source › CPU offload › Supported best method from ML Tech • (ICML2022 Big model tutorial): https://icml.cc/virtual/2022/tutorial/18440 • (DeepSpeed):https://www.deepspeed.ai
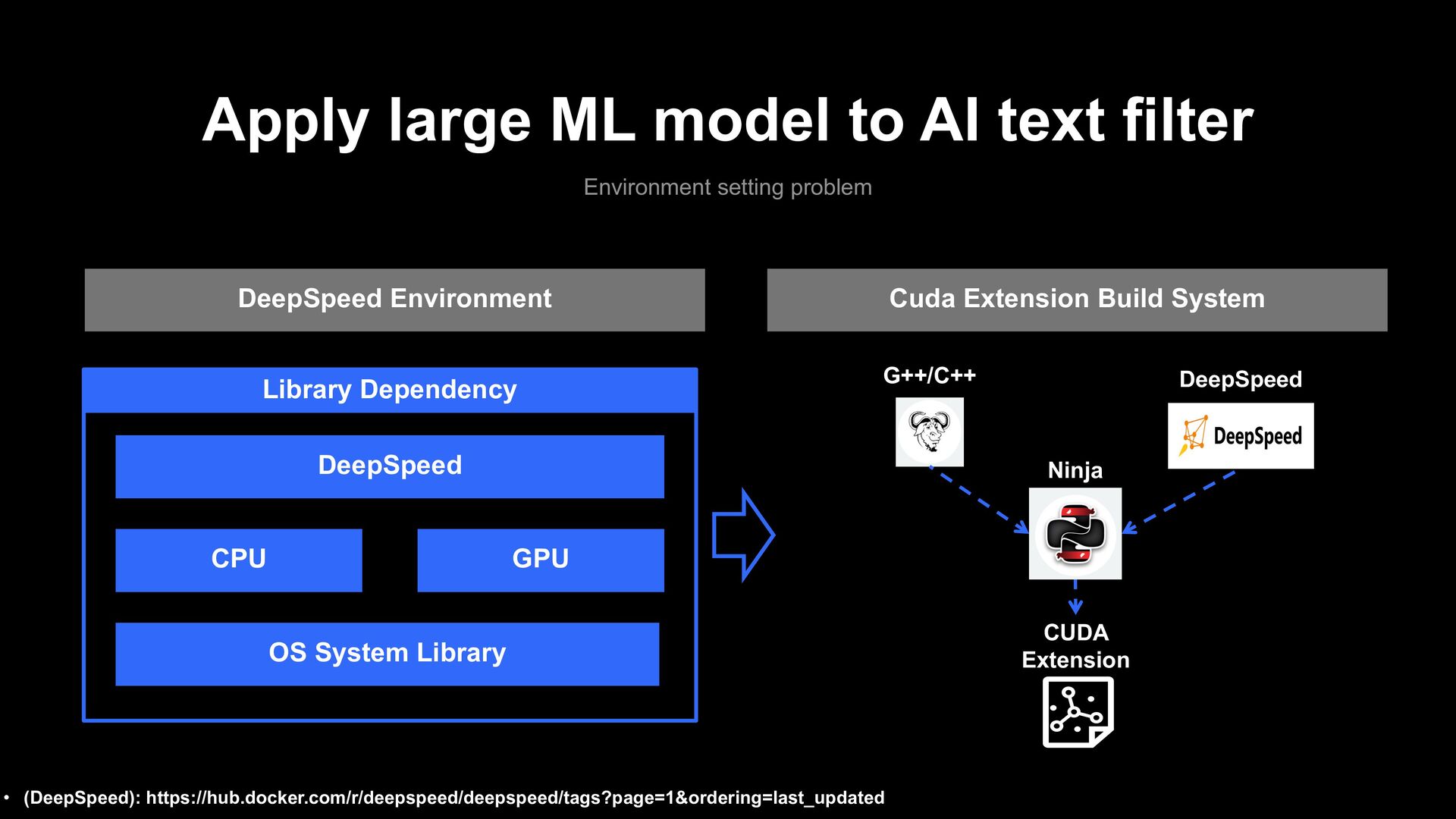
problem • (DeepSpeed): https://hub.docker.com/r/deepspeed/deepspeed/tags?page=1&ordering=last_updated DeepSpeed Environment CPU GPU Library Dependency DeepSpeed OS System Library
problem • (DeepSpeed): https://hub.docker.com/r/deepspeed/deepspeed/tags?page=1&ordering=last_updated DeepSpeed Environment CPU GPU Library Dependency DeepSpeed OS System Library Cuda Extension Build System CUDA Extension Ninja G++/C++ DeepSpeed
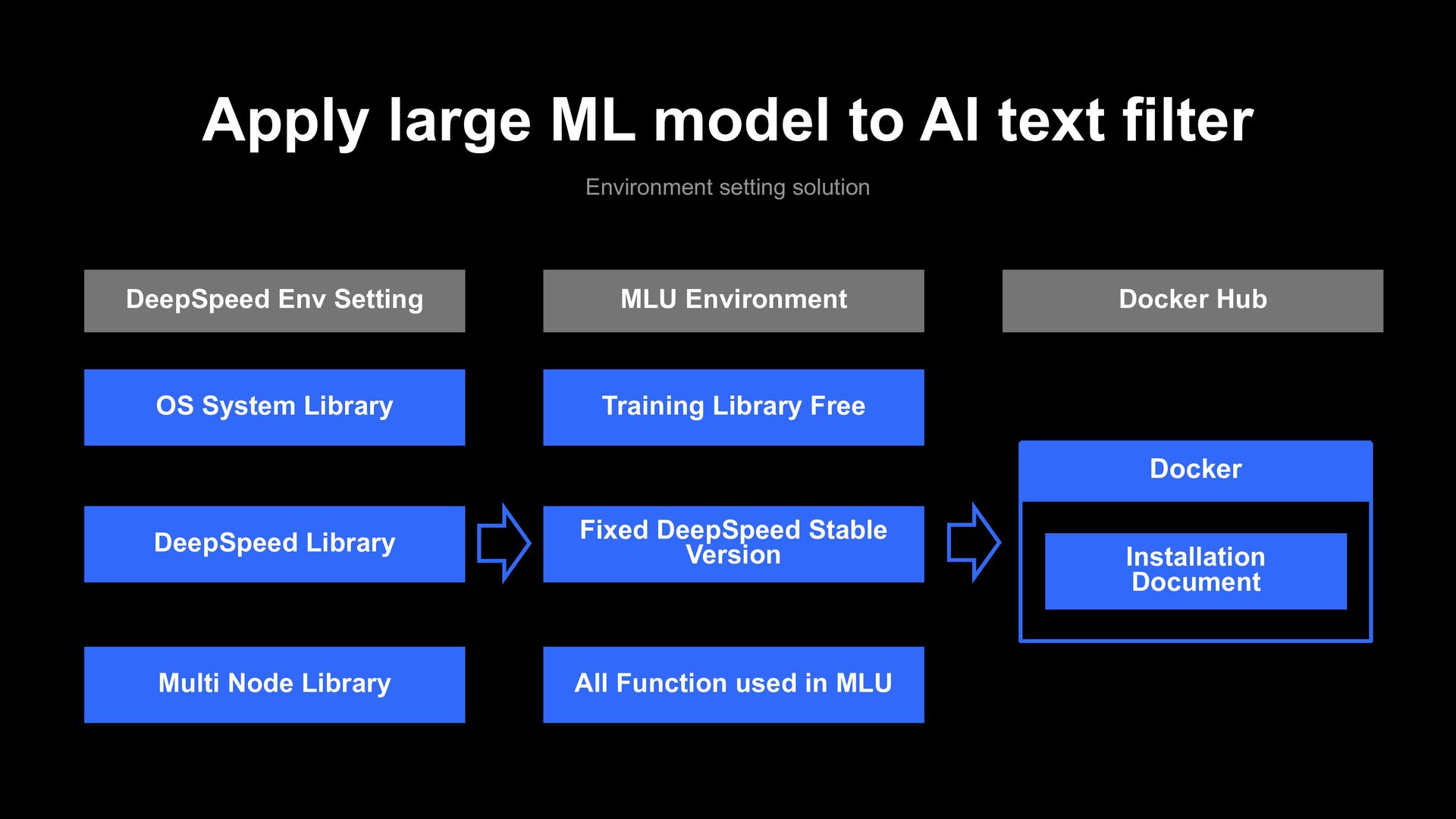
solution All Function used in MLU Fixed DeepSpeed Stable Version Training Library Free MLU Environment DeepSpeed Env Setting OS System Library DeepSpeed Library Multi Node Library
solution All Function used in MLU Fixed DeepSpeed Stable Version Training Library Free MLU Environment Docker Installation Document Docker Hub DeepSpeed Env Setting OS System Library DeepSpeed Library Multi Node Library
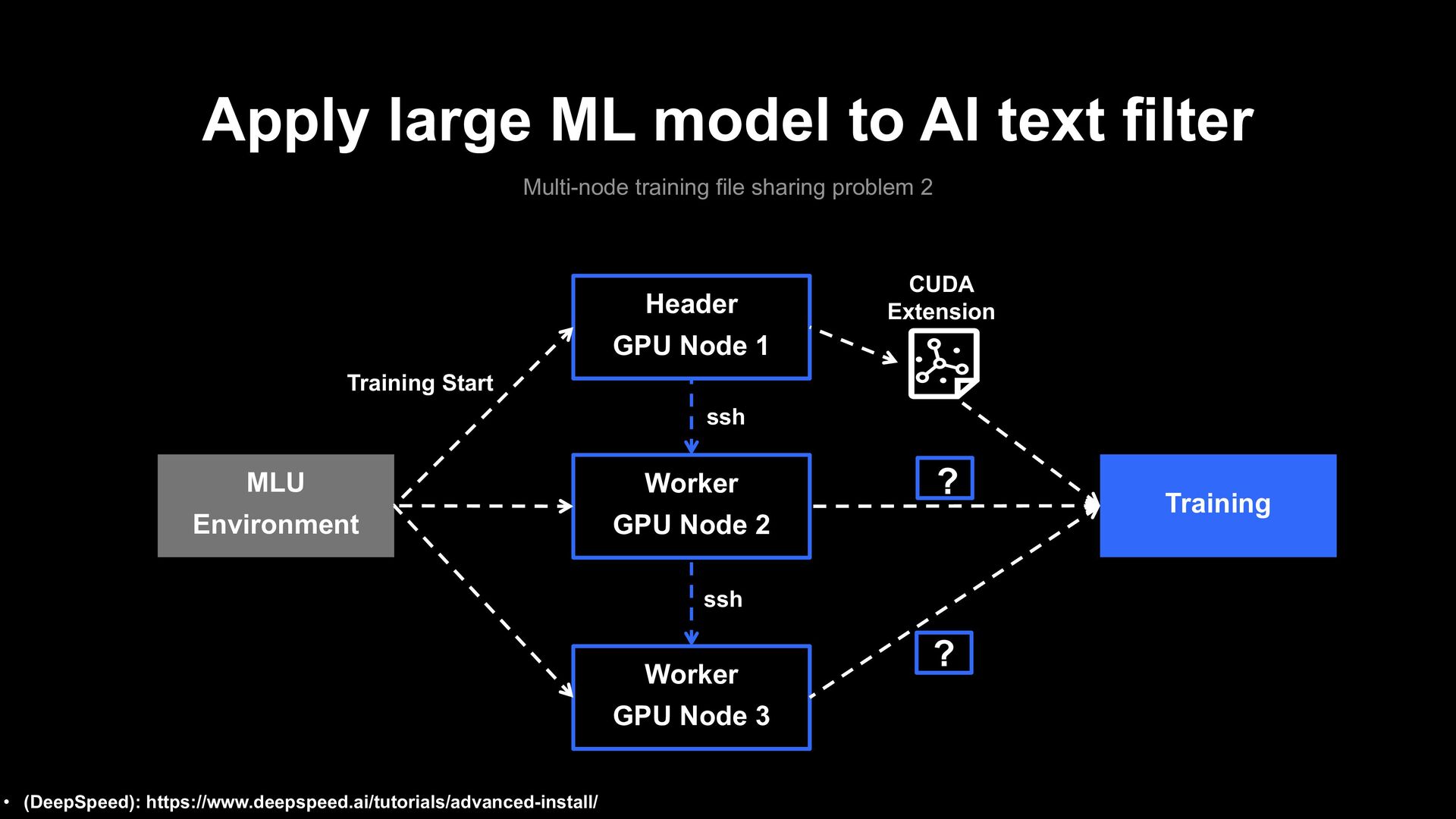
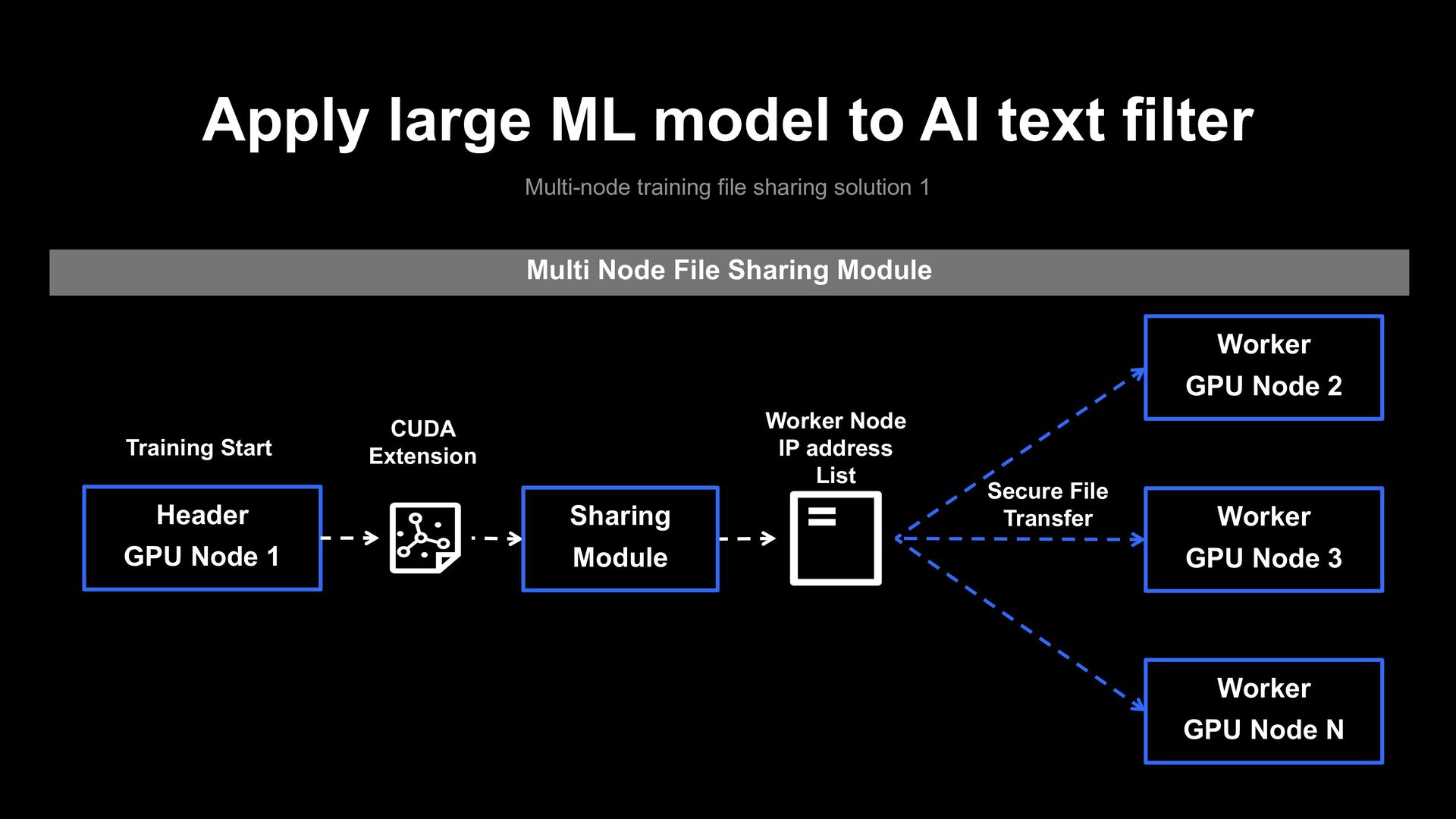
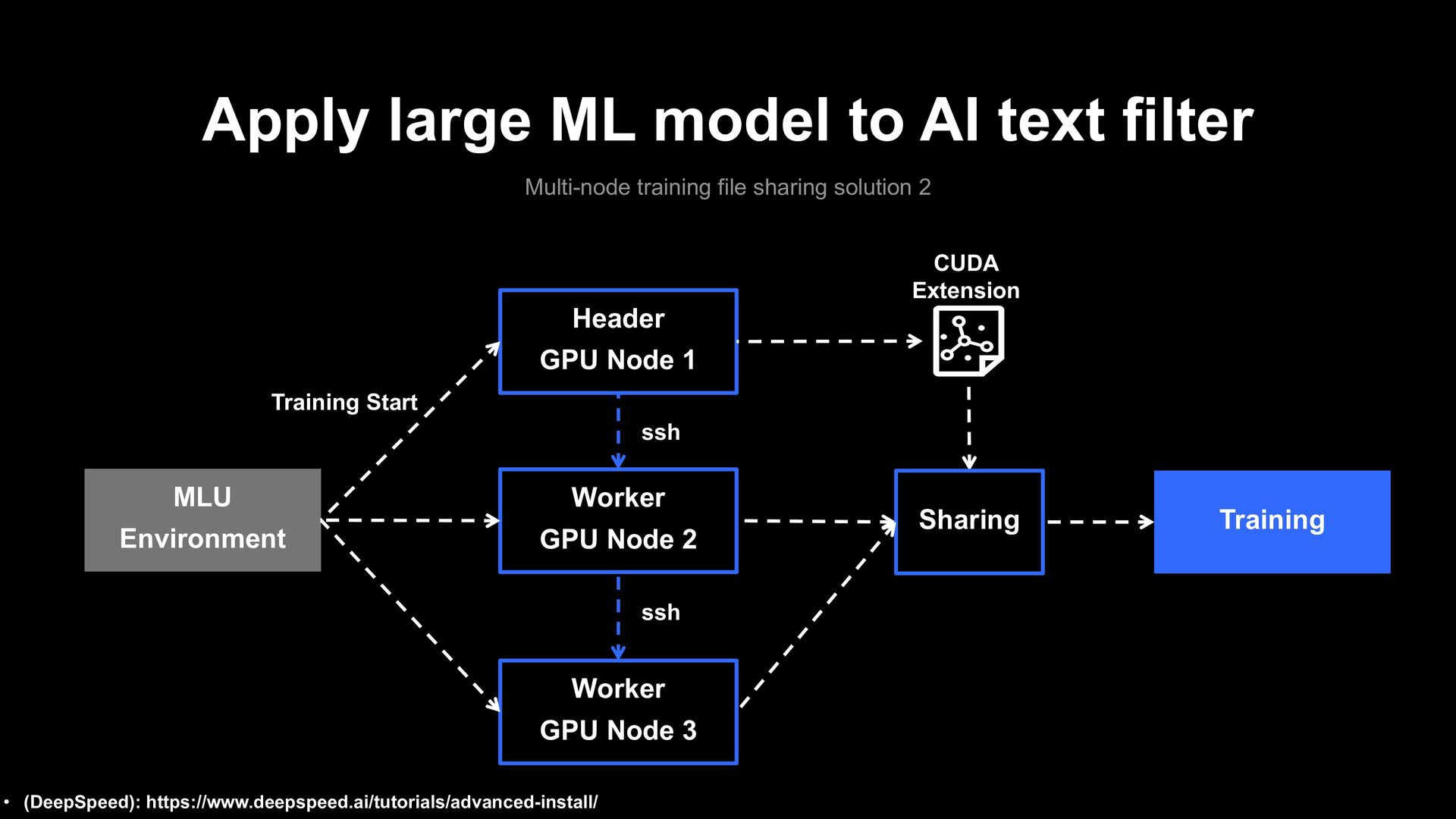
file sharing problem 1 Training MLU Environment GPU Server First Training Start CUDA Extension GPU Accelerator • (DeepSpeed): https://www.deepspeed.ai/tutorials/advanced-install/
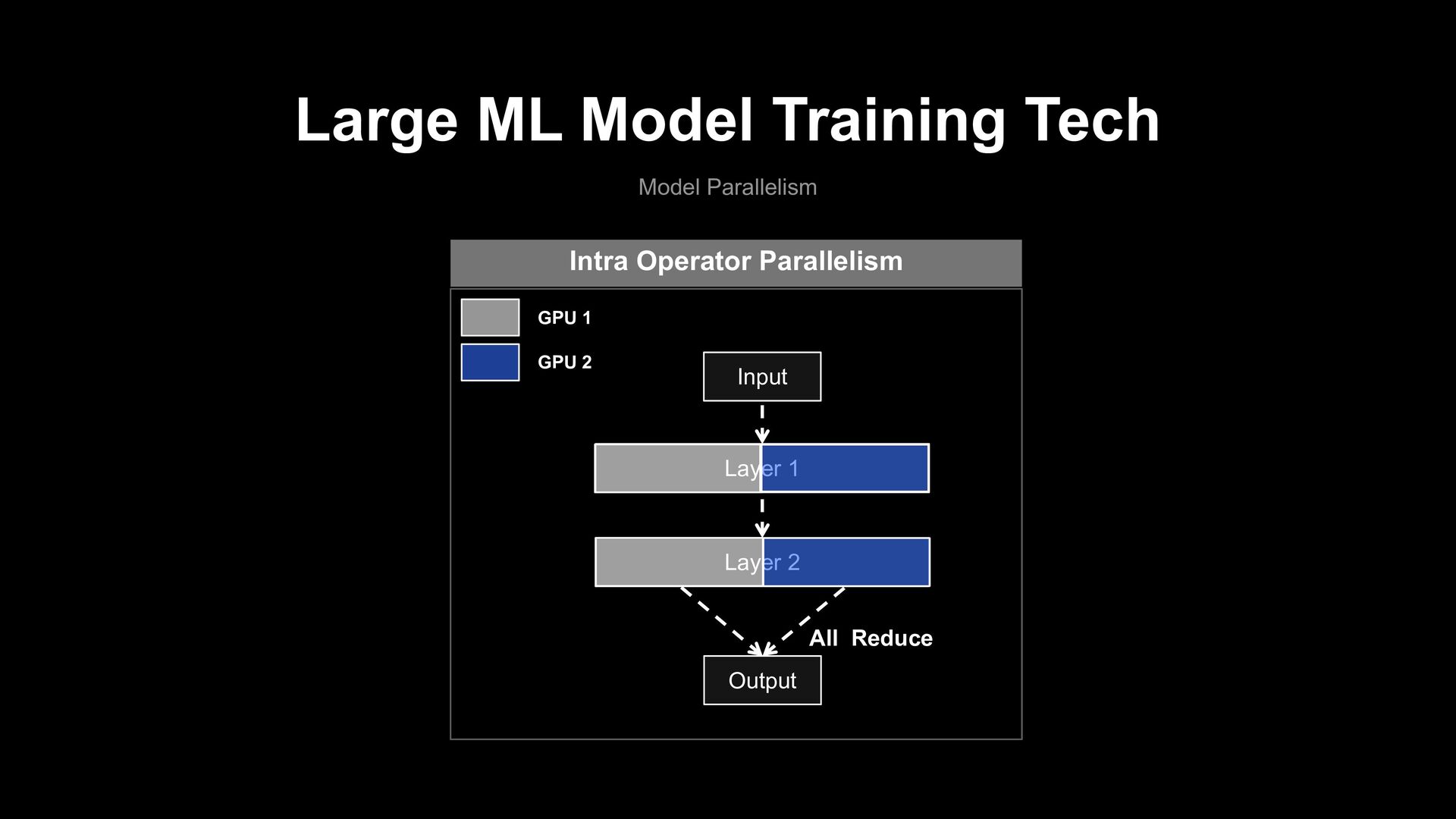
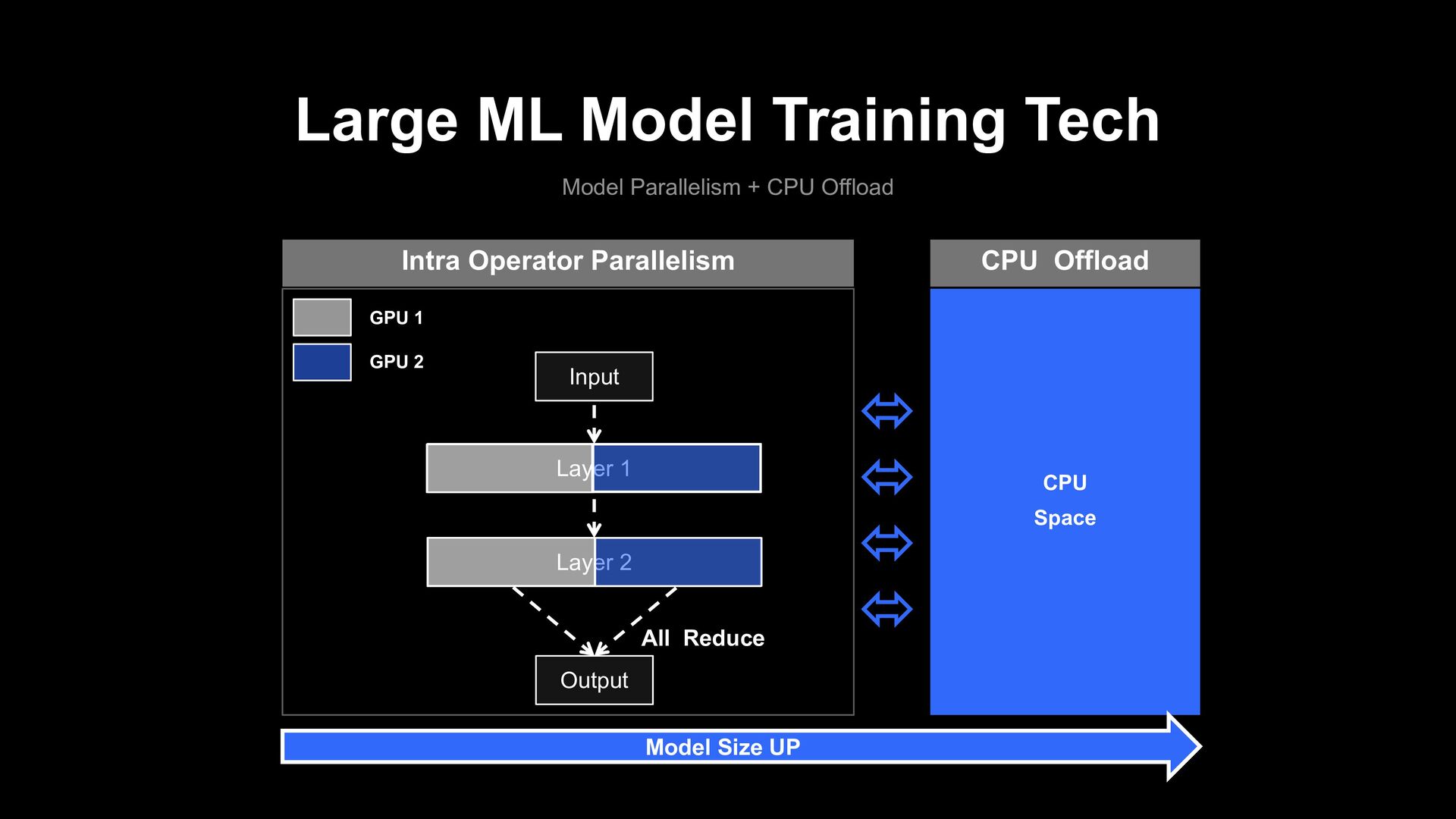
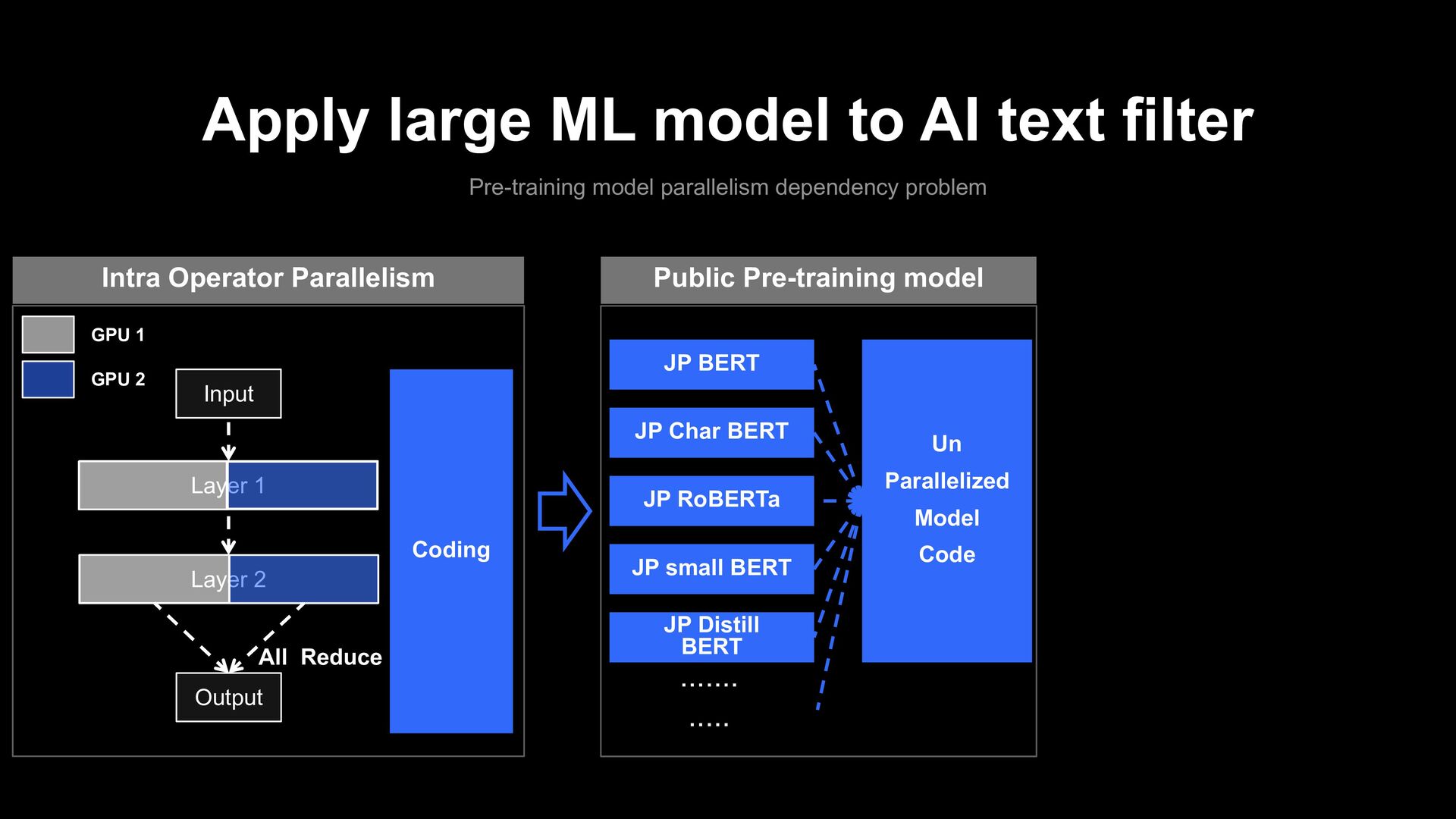
parallelism dependency problem Public Pre-training model JP BERT JP Char BERT JP RoBERTa JP small BERT JP Distill BERT ....... ..... Un Parallelized Model Code Input Layer 1 Layer 2 Output GPU 1 GPU 2 Intra Operator Parallelism All Reduce Coding
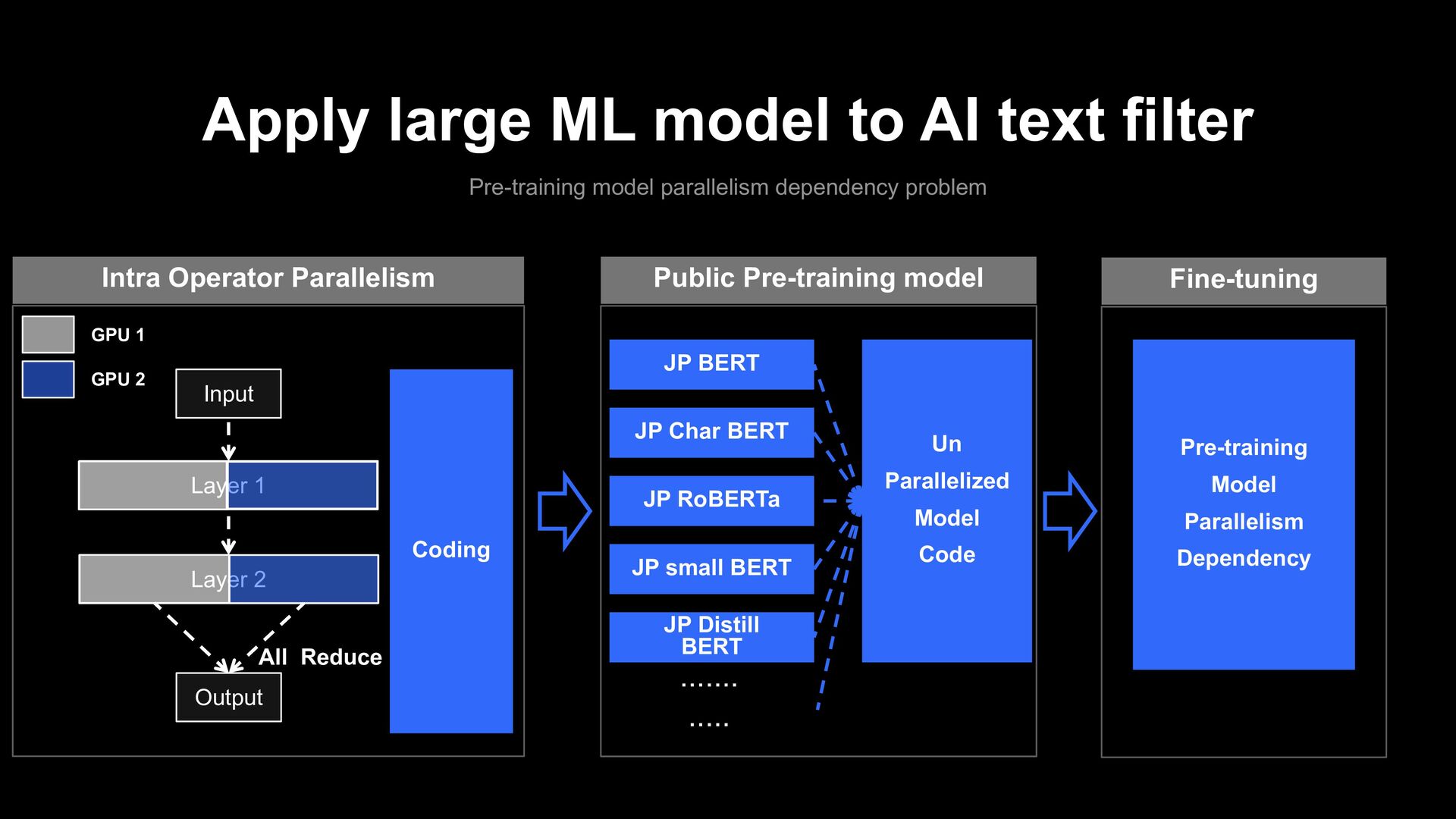
parallelism dependency problem Public Pre-training model JP BERT JP Char BERT JP RoBERTa JP small BERT JP Distill BERT ....... ..... Un Parallelized Model Code Pre-training Model Parallelism Dependency Fine-tuning Input Layer 1 Layer 2 Output GPU 1 GPU 2 Intra Operator Parallelism All Reduce Coding
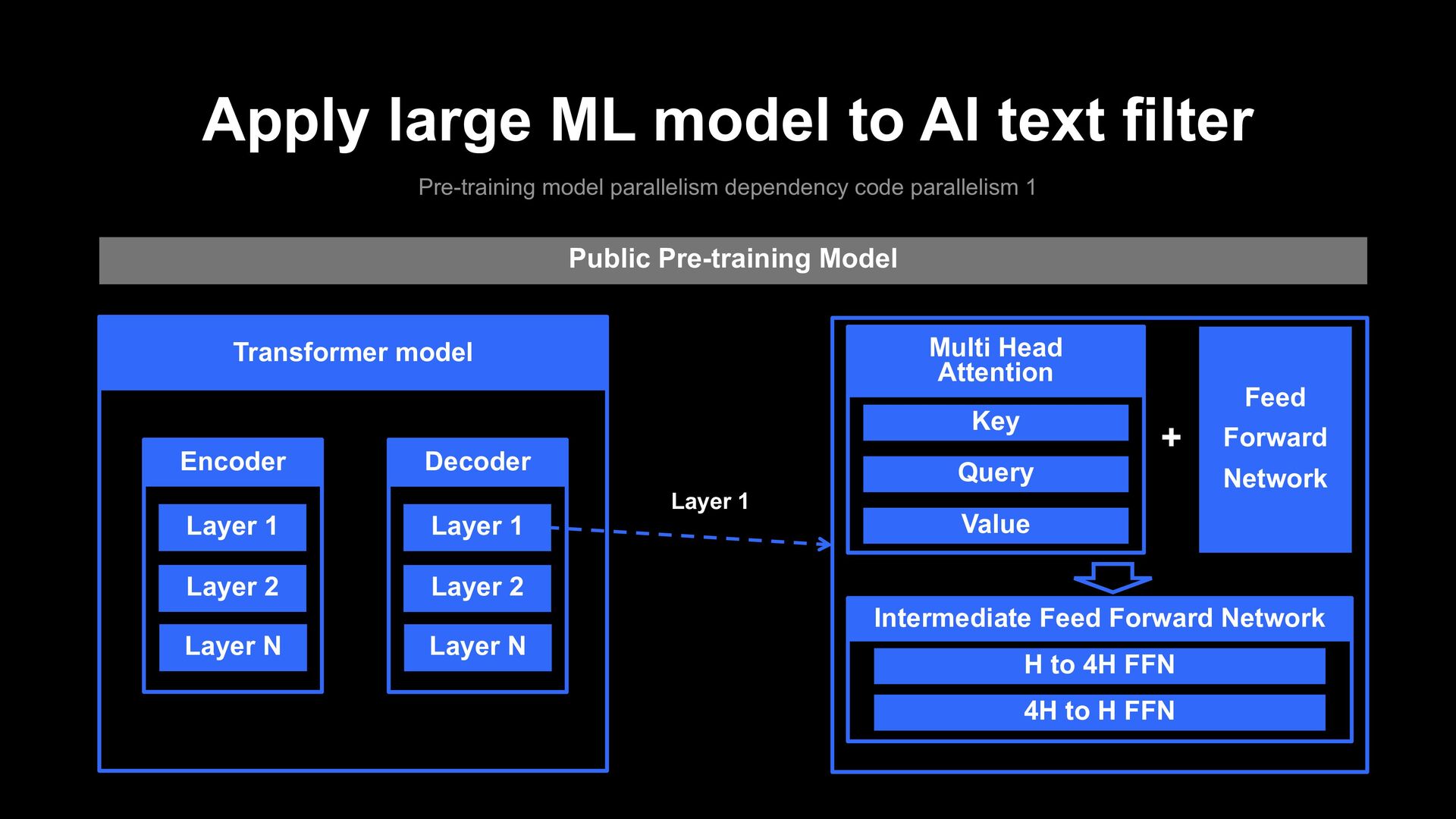
parallelism dependency code parallelism 1 Public Pre-training Model Transformer model Encoder Layer 1 Layer 2 Layer N Decoder Layer 1 Layer 2 Layer N Layer 1 Multi Head Attention Key Query Value Feed Forward Network + Intermediate Feed Forward Network H to 4H FFN 4H to H FFN
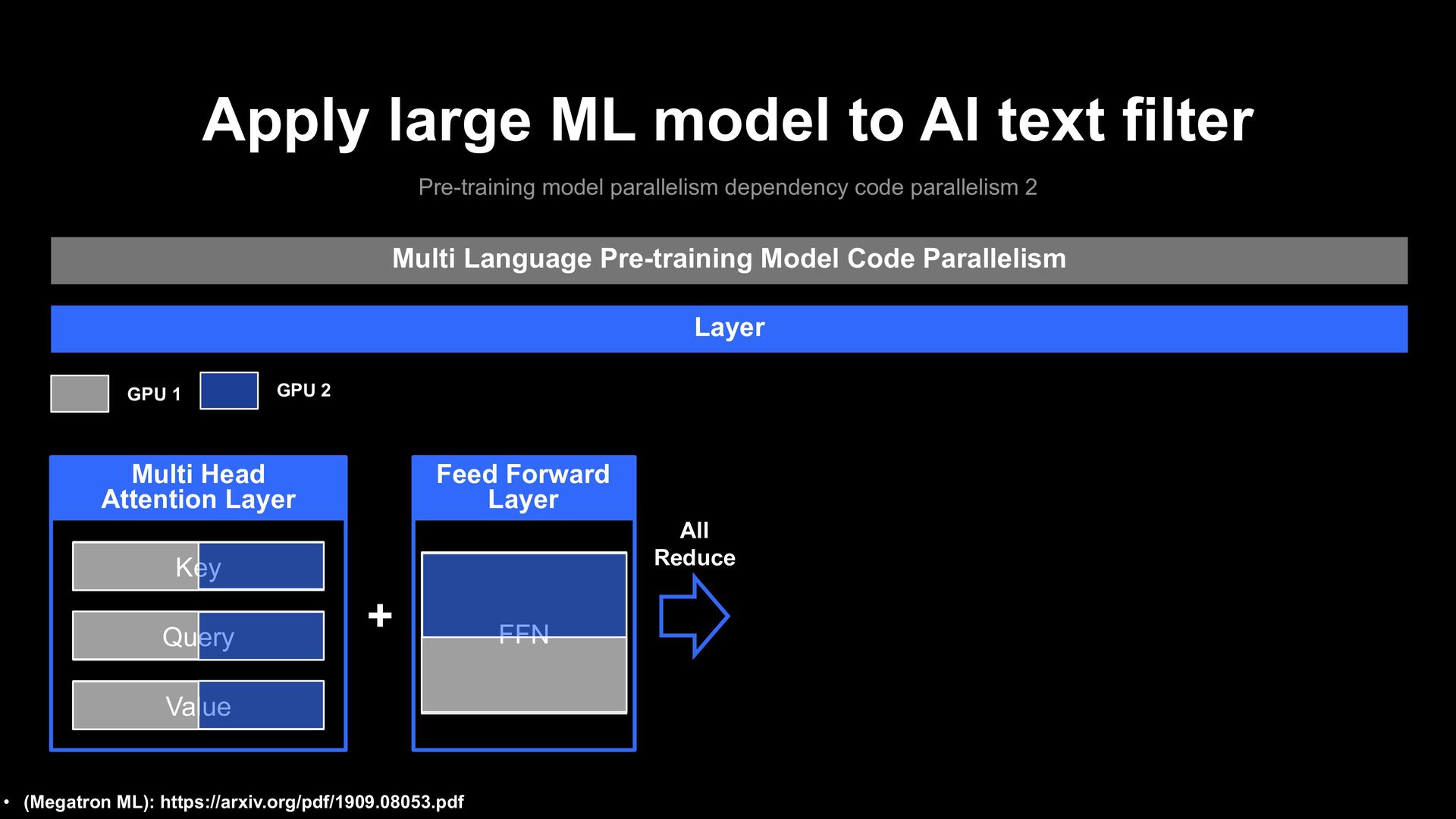
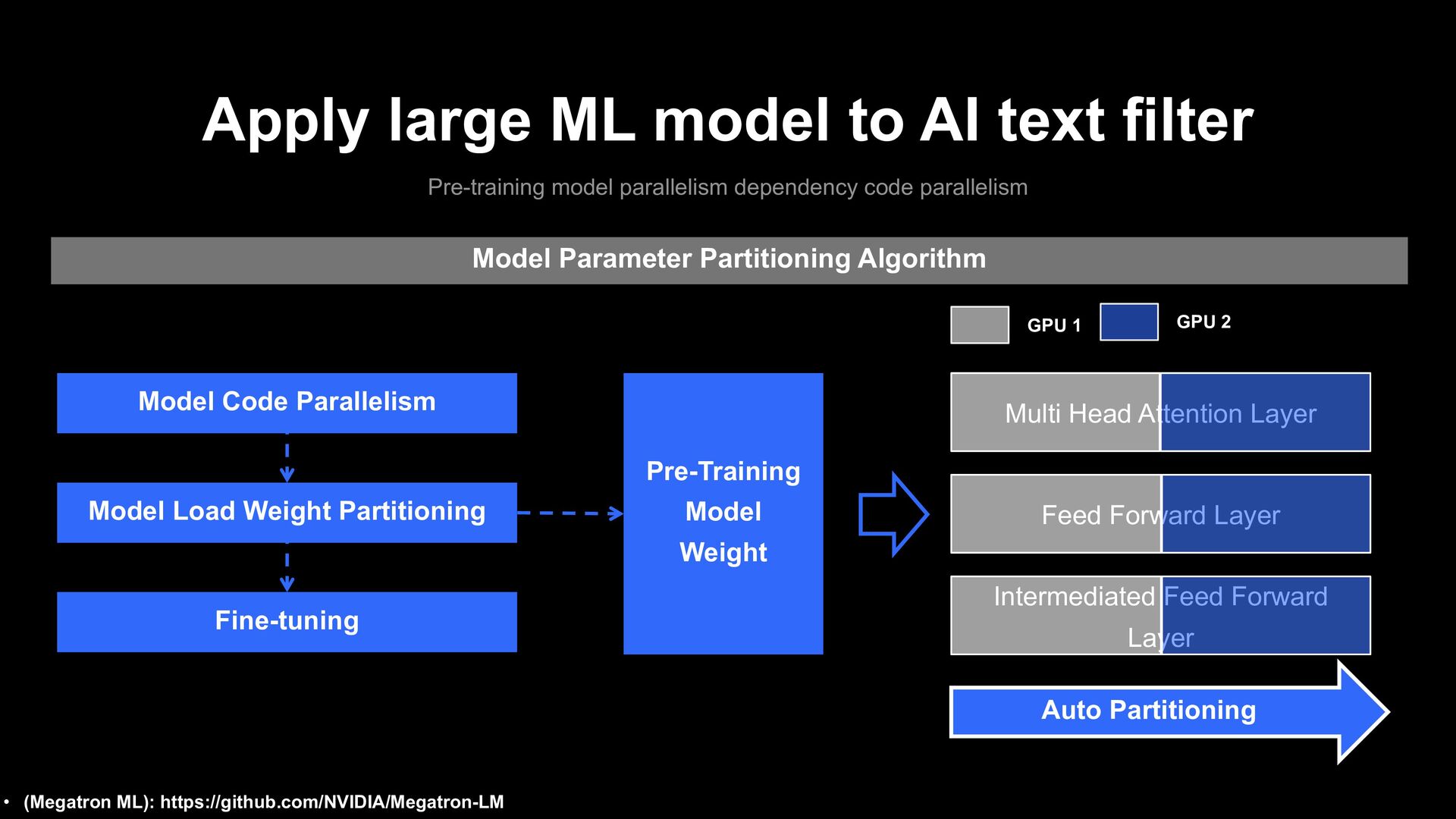
parallelism dependency code parallelism 2 Multi Language Pre-training Model Code Parallelism Layer GPU 1 GPU 2 Key Query Multi Head Attention Layer Value + All Reduce • (Megatron ML): https://arxiv.org/pdf/1909.08053.pdf FFN Feed Forward Layer
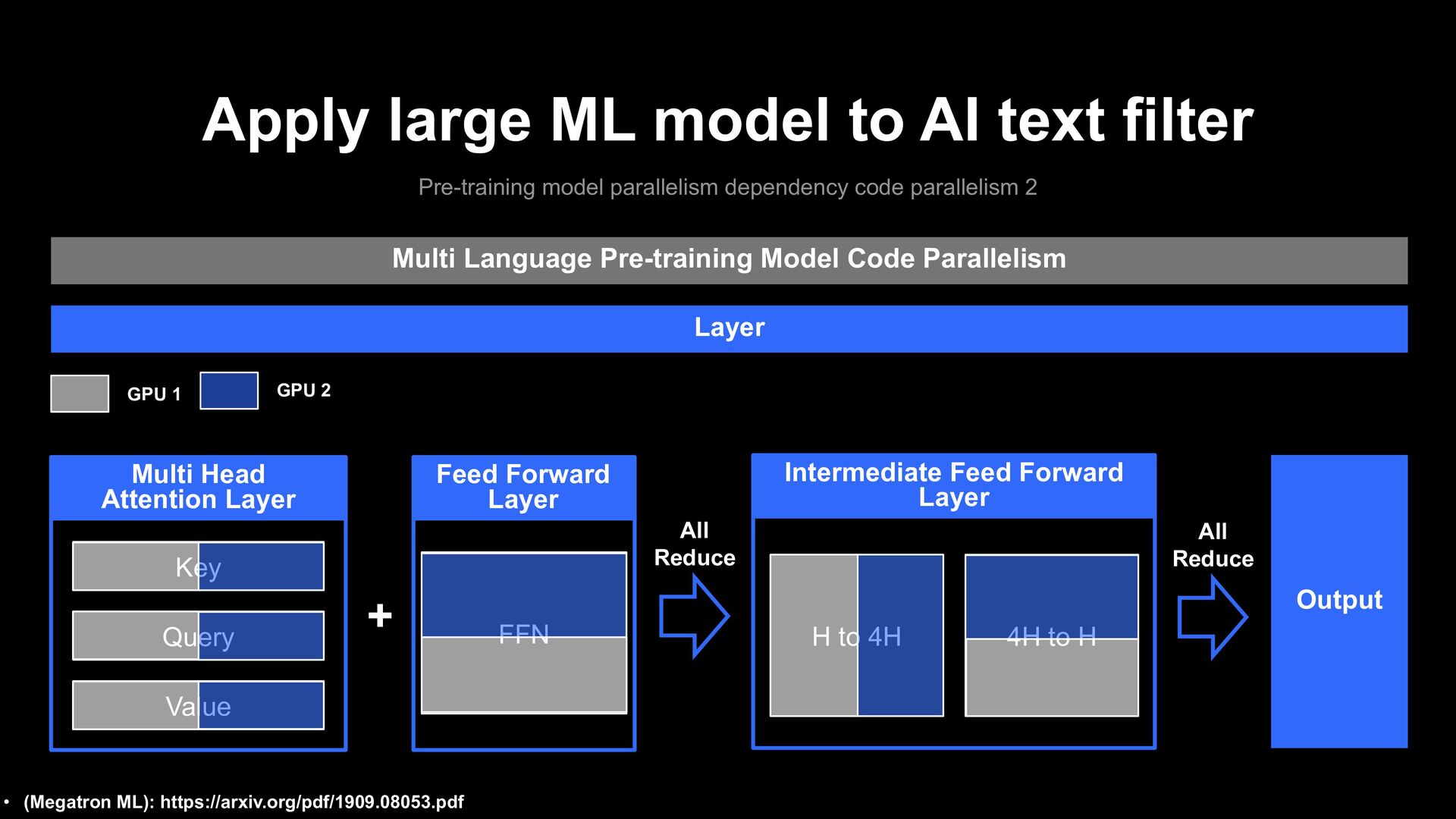
parallelism dependency code parallelism 2 Multi Language Pre-training Model Code Parallelism Layer GPU 1 GPU 2 Key Query Multi Head Attention Layer Value + Intermediate Feed Forward Layer All Reduce Output All Reduce • (Megatron ML): https://arxiv.org/pdf/1909.08053.pdf H to 4H 4H to H FFN Feed Forward Layer
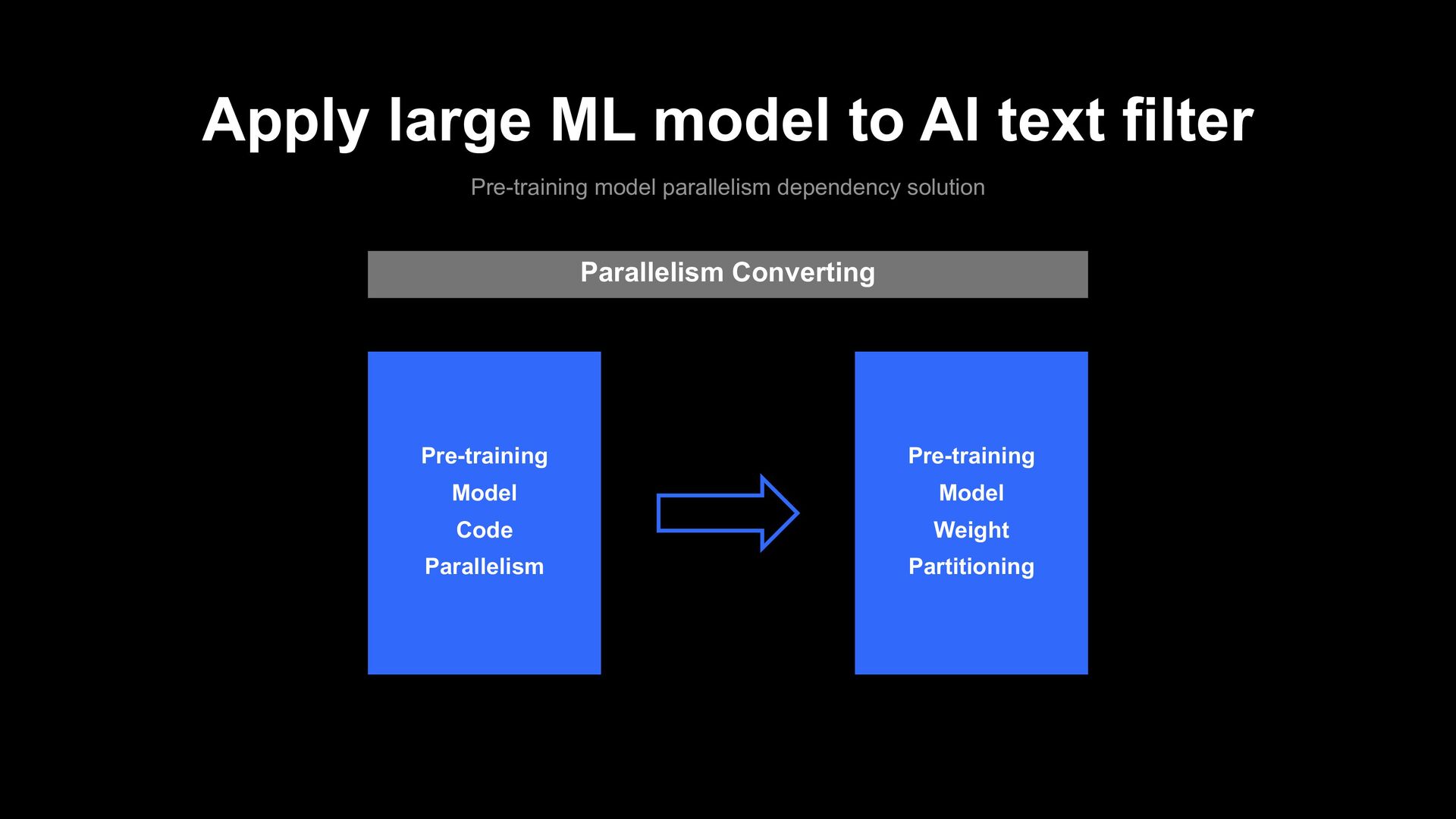
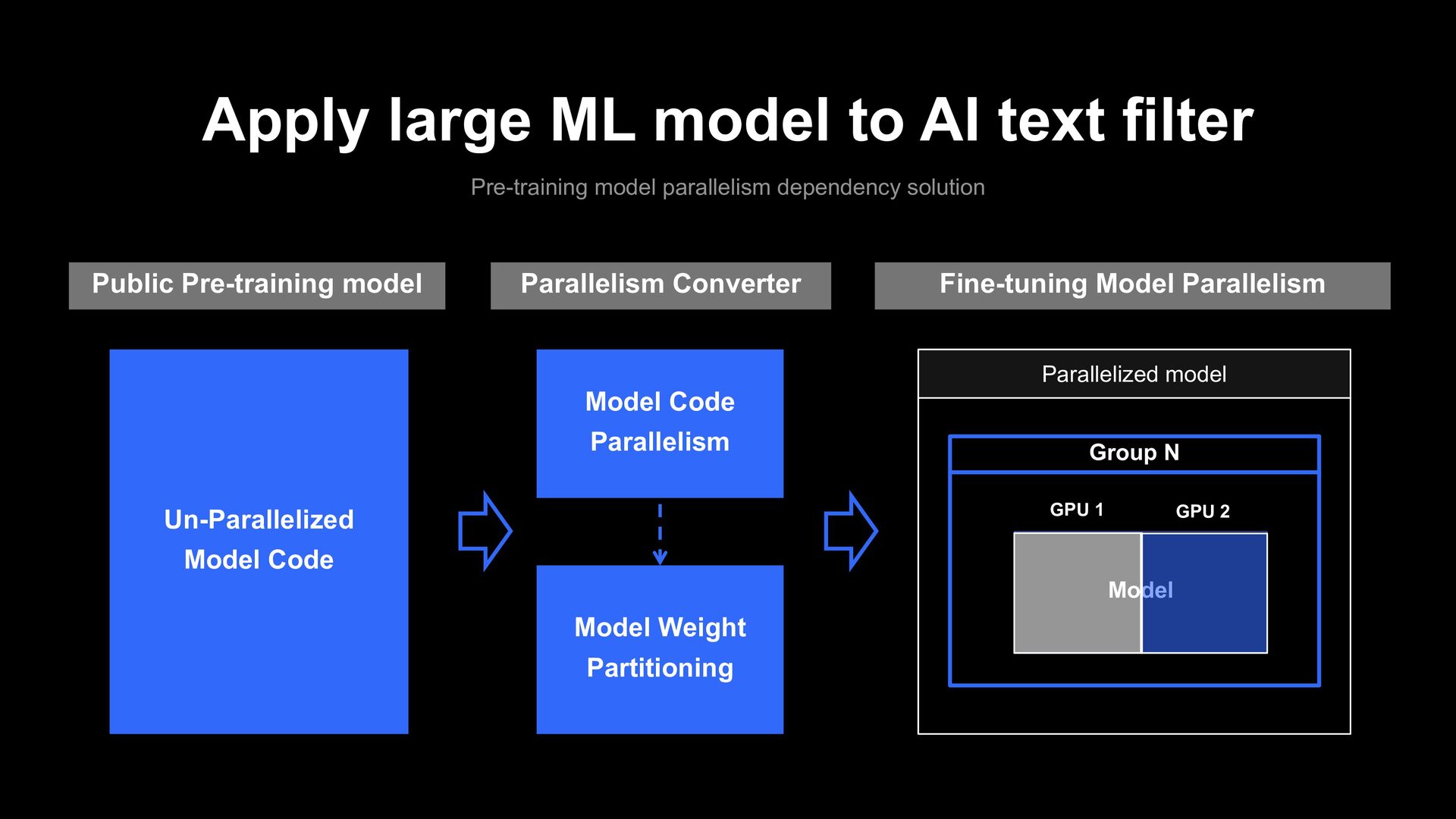
parallelism dependency solution Public Pre-training model Un-Parallelized Model Code Fine-tuning Model Parallelism Parallelized model Group N Model GPU 1 GPU 2 Parallelism Converter Model Code Parallelism Model Weight Partitioning
parallelism dependency solution analysis Disadvantage Advantage Unstable Converge Model Performance Down Parallelism Dependency Free More Research Model Size Up
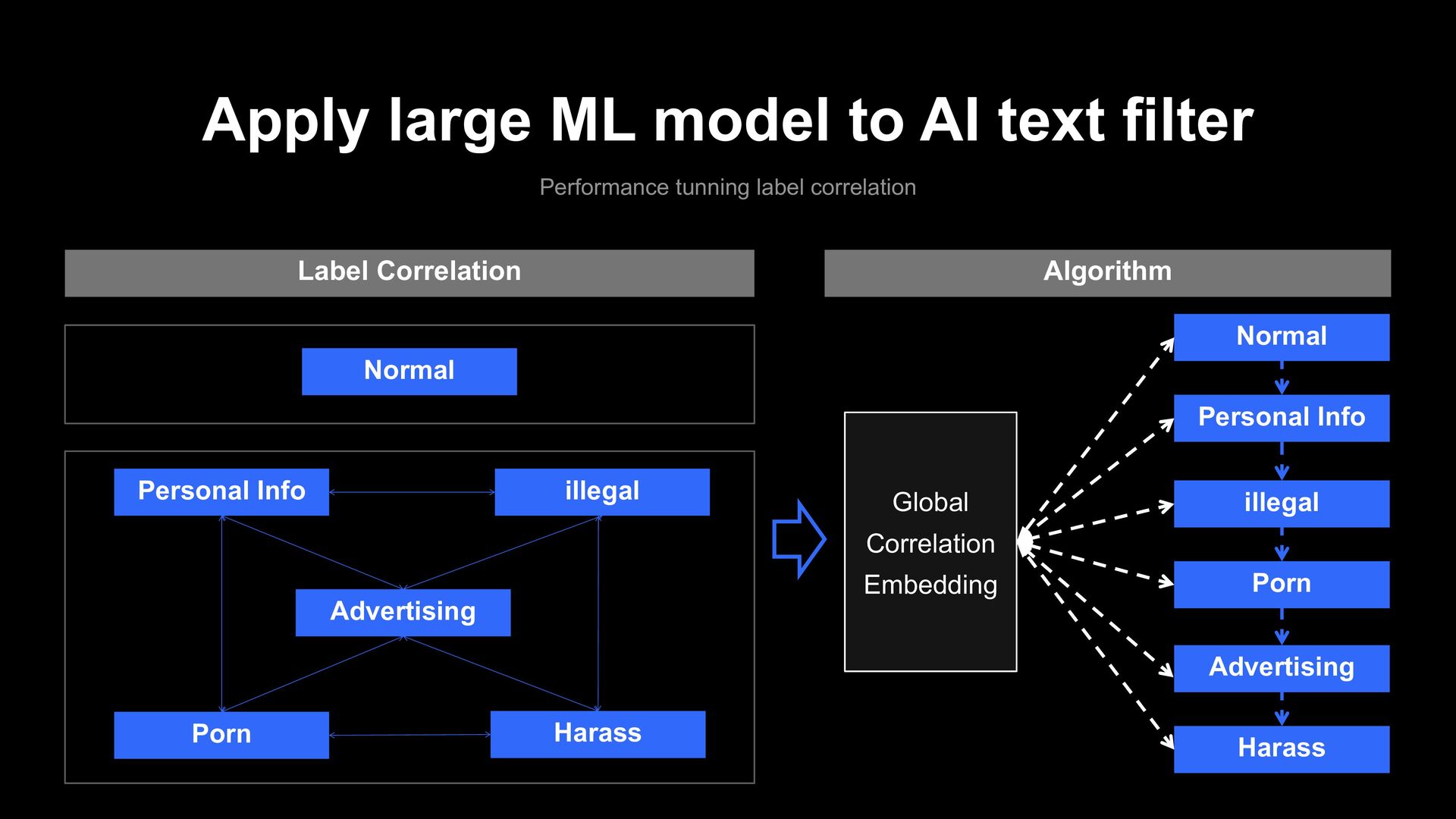
label correlation Label Correlation Normal Advertising Personal Info Porn illegal Harass Algorithm Normal Advertising Personal Info Porn illegal Harass Global Correlation Embedding
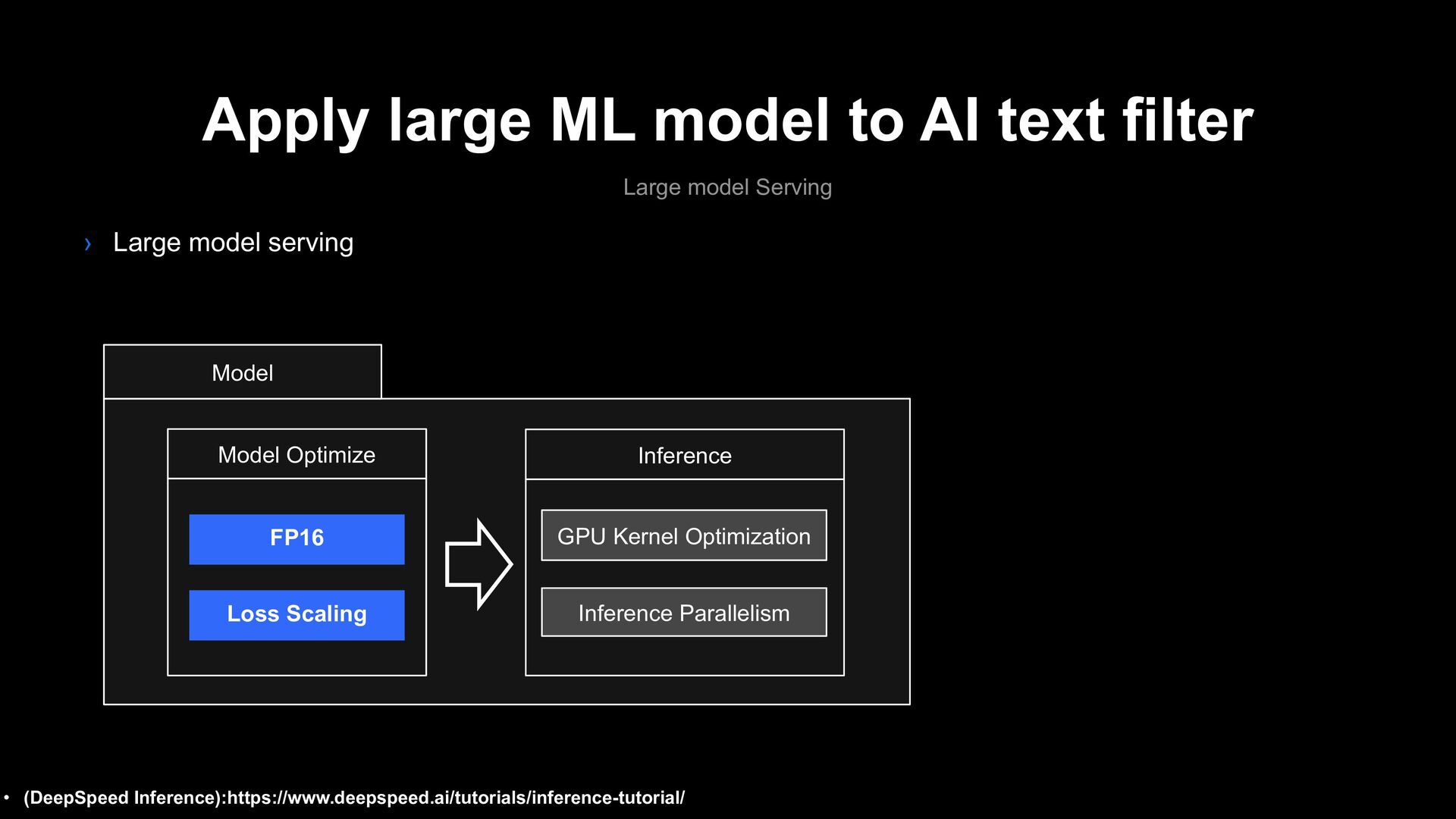
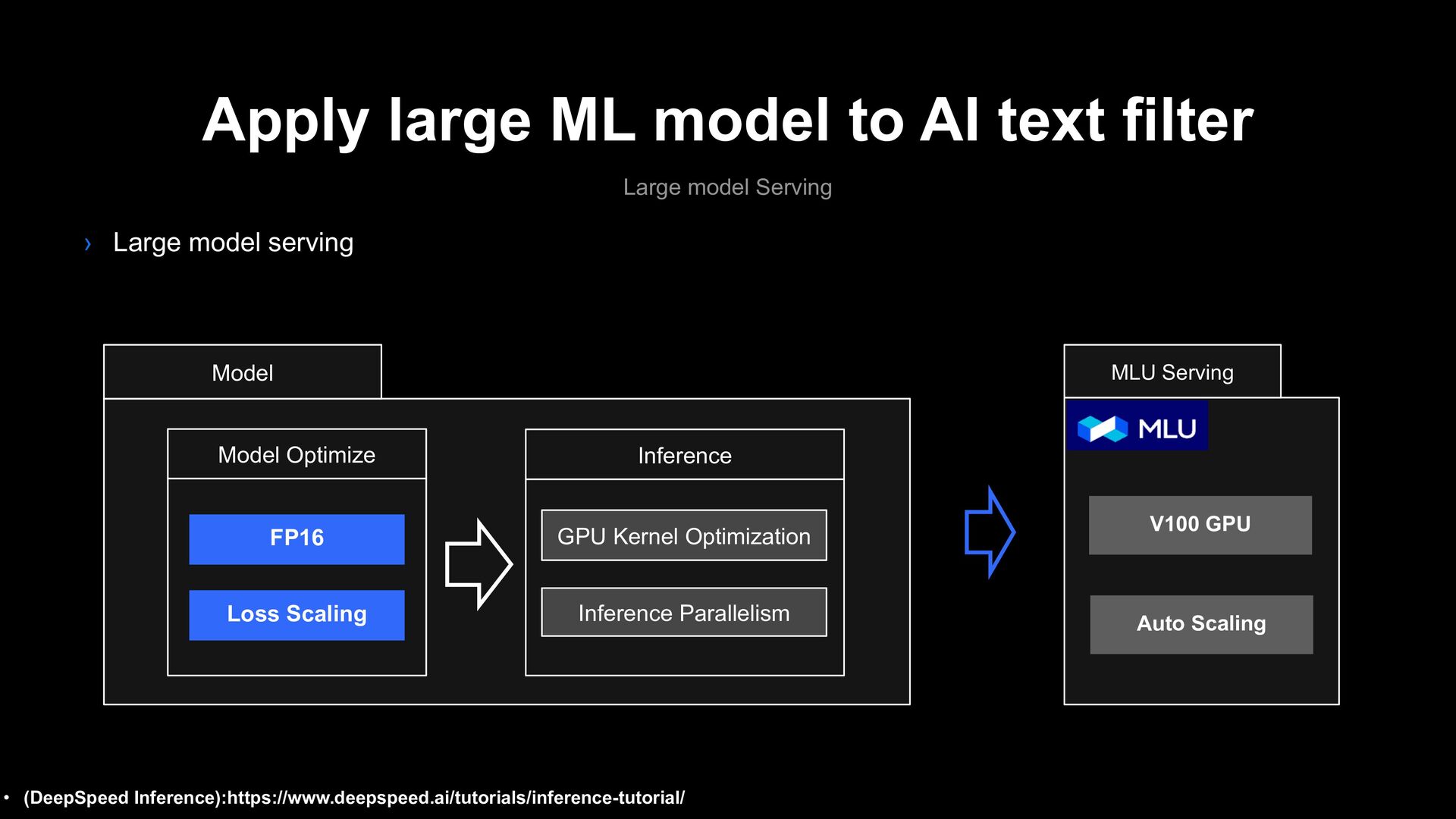
Serving › Large model serving • (DeepSpeed Inference):https://www.deepspeed.ai/tutorials/inference-tutorial/ Model GPU Kernel Optimization Inference Parallelism Inference Model Optimize FP16 Loss Scaling
Serving › Large model serving • (DeepSpeed Inference):https://www.deepspeed.ai/tutorials/inference-tutorial/ V100 GPU Auto Scaling MLU Serving Model GPU Kernel Optimization Inference Parallelism Inference Model Optimize FP16 Loss Scaling
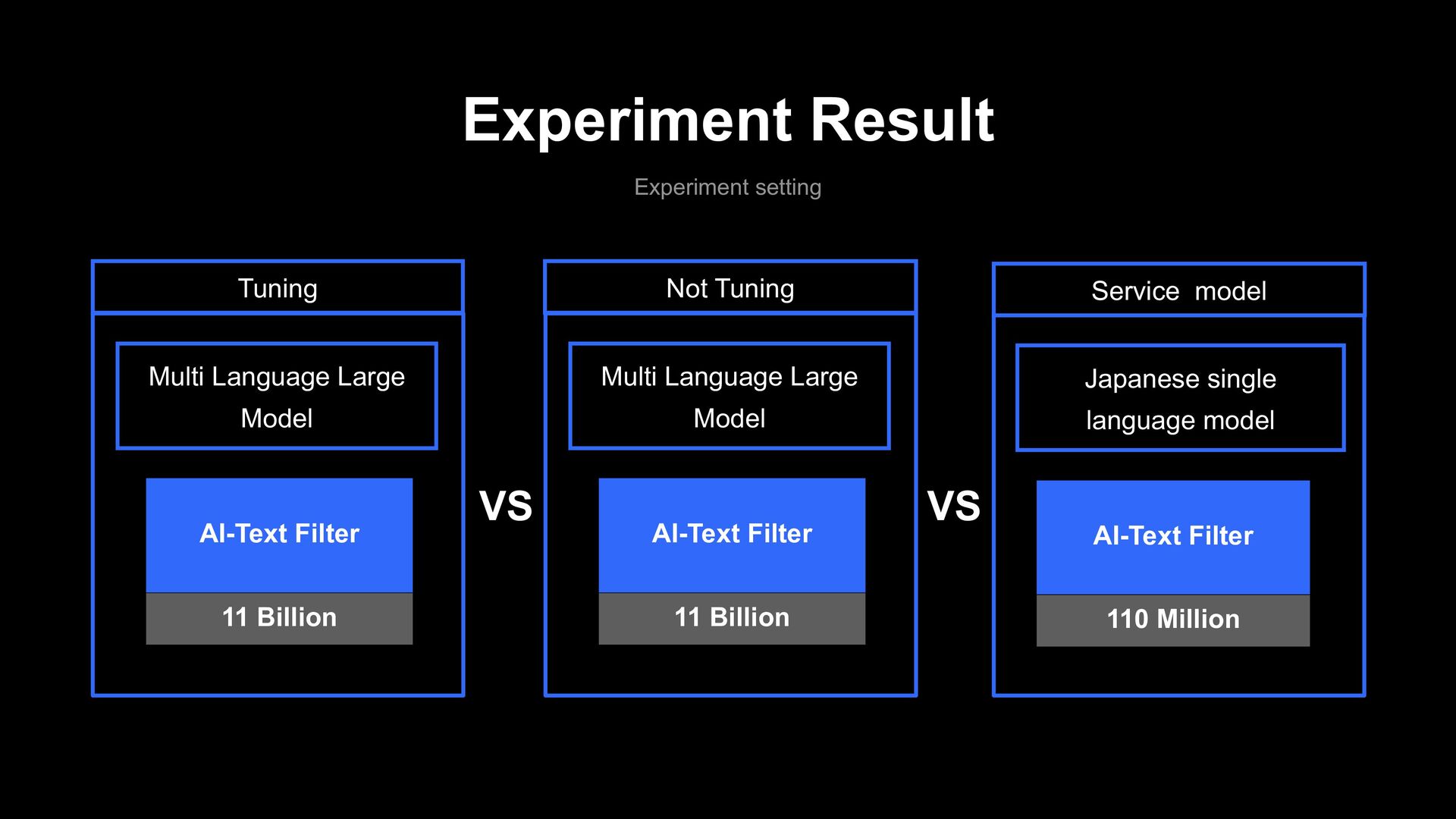
model 110 Million Service model AI-Text Filter Multi Language Large Model 11 Billion Tuning VS AI-Text Filter Multi Language Large Model 11 Billion Not Tuning
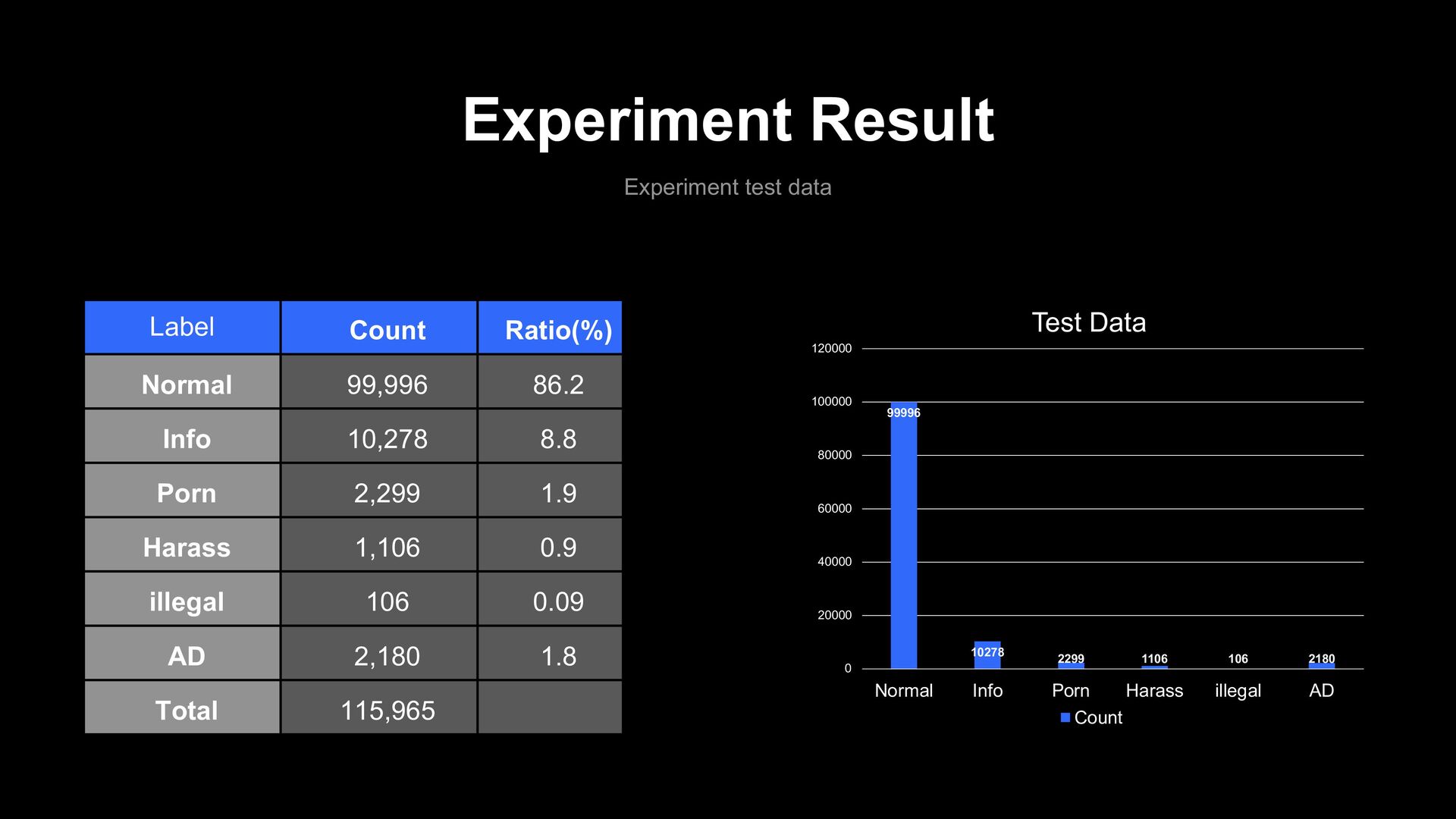
86.2 Info 10,278 8.8 Porn 2,299 1.9 Harass 1,106 0.9 illegal 106 0.09 AD 2,180 1.8 Total 115,965 99996 10278 2299 1106 106 2180 0 20000 40000 60000 80000 100000 120000 Normal Info Porn Harass illegal AD Test Data Count
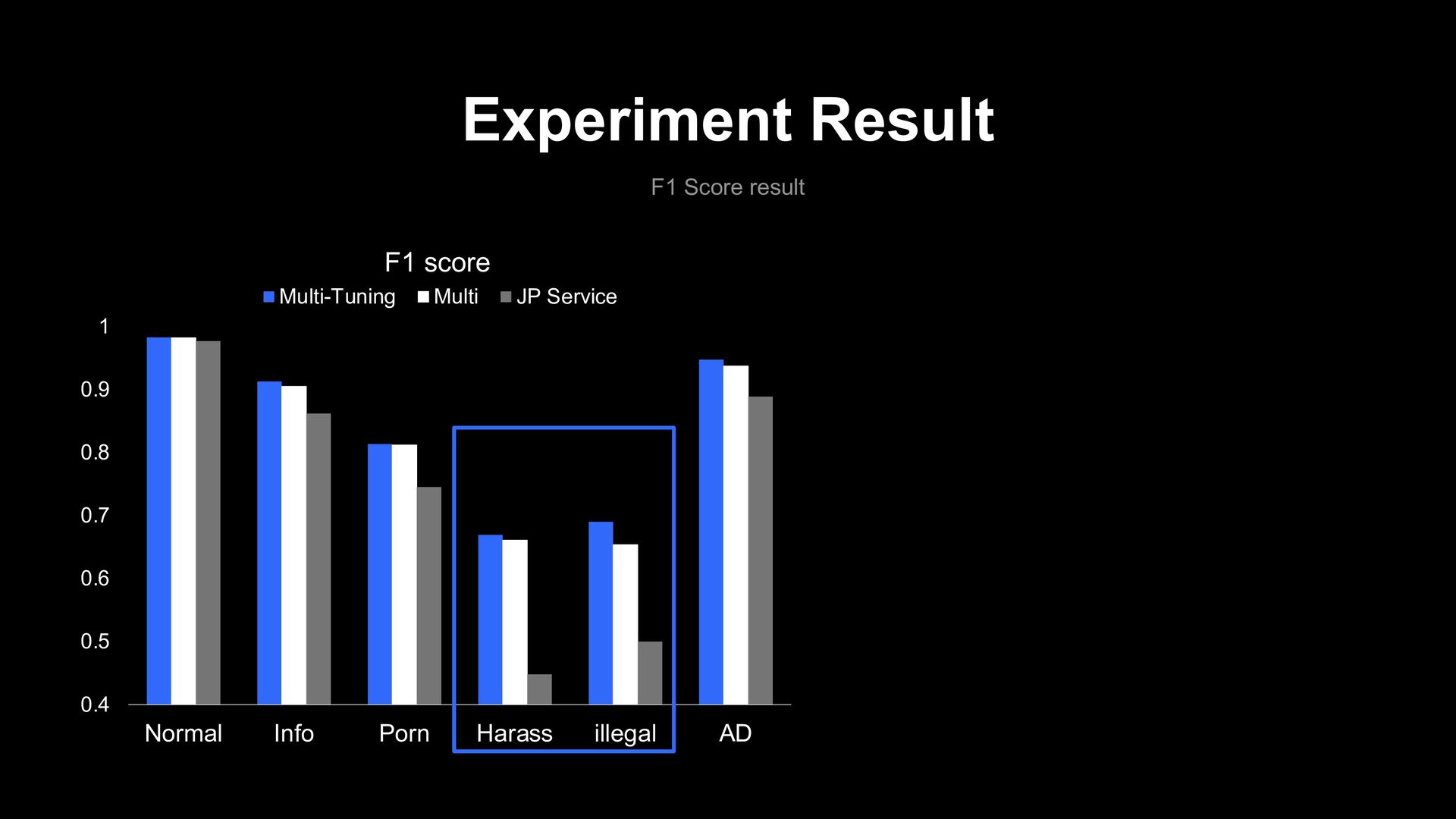
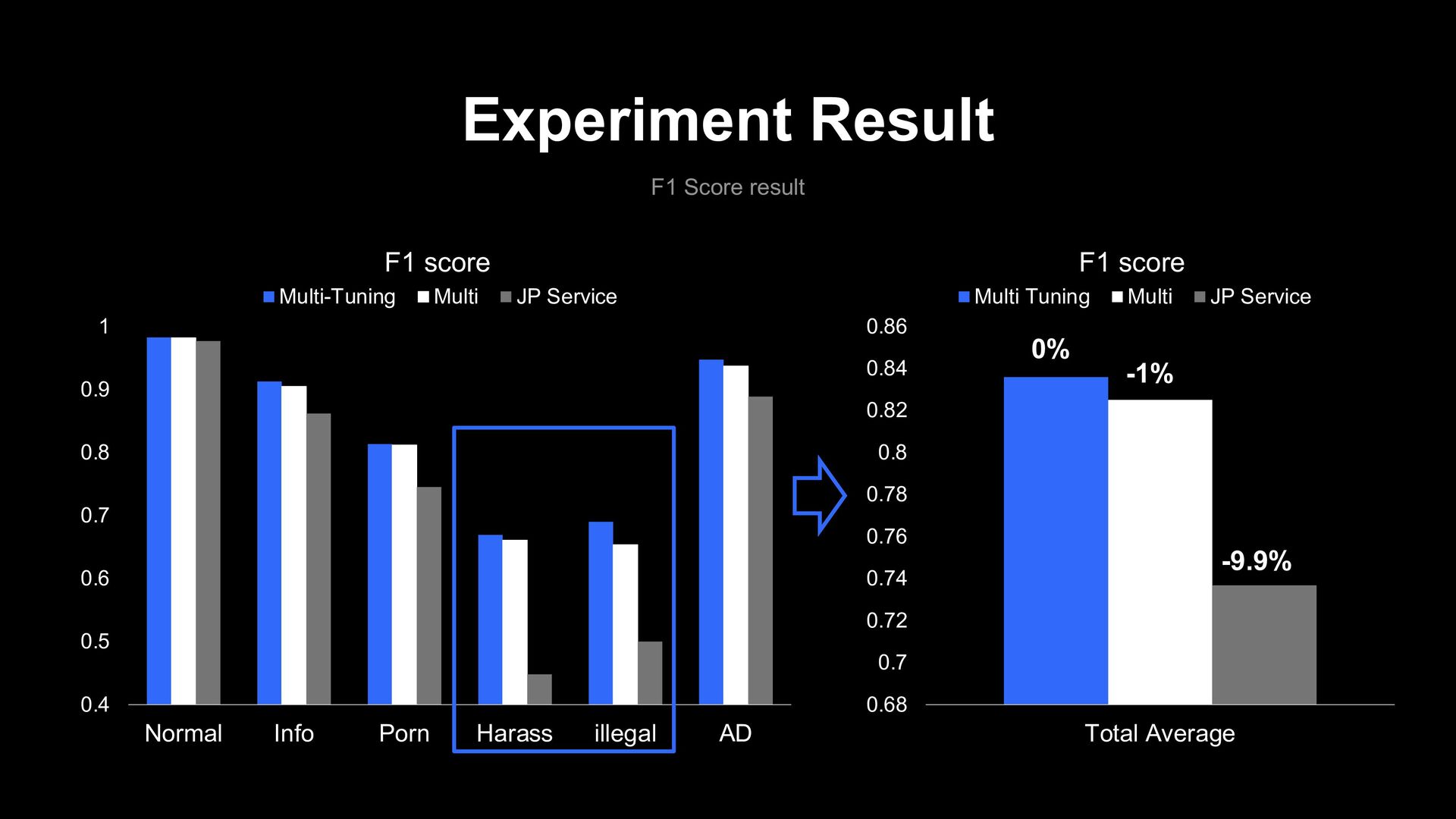
0.9 1 Normal Info Porn Harass illegal AD F1 score Multi-Tuning Multi JP Service 0.68 0.7 0.72 0.74 0.76 0.78 0.8 0.82 0.84 0.86 Total Average F1 score Multi Tuning Multi JP Service -1% -9.9% 0%
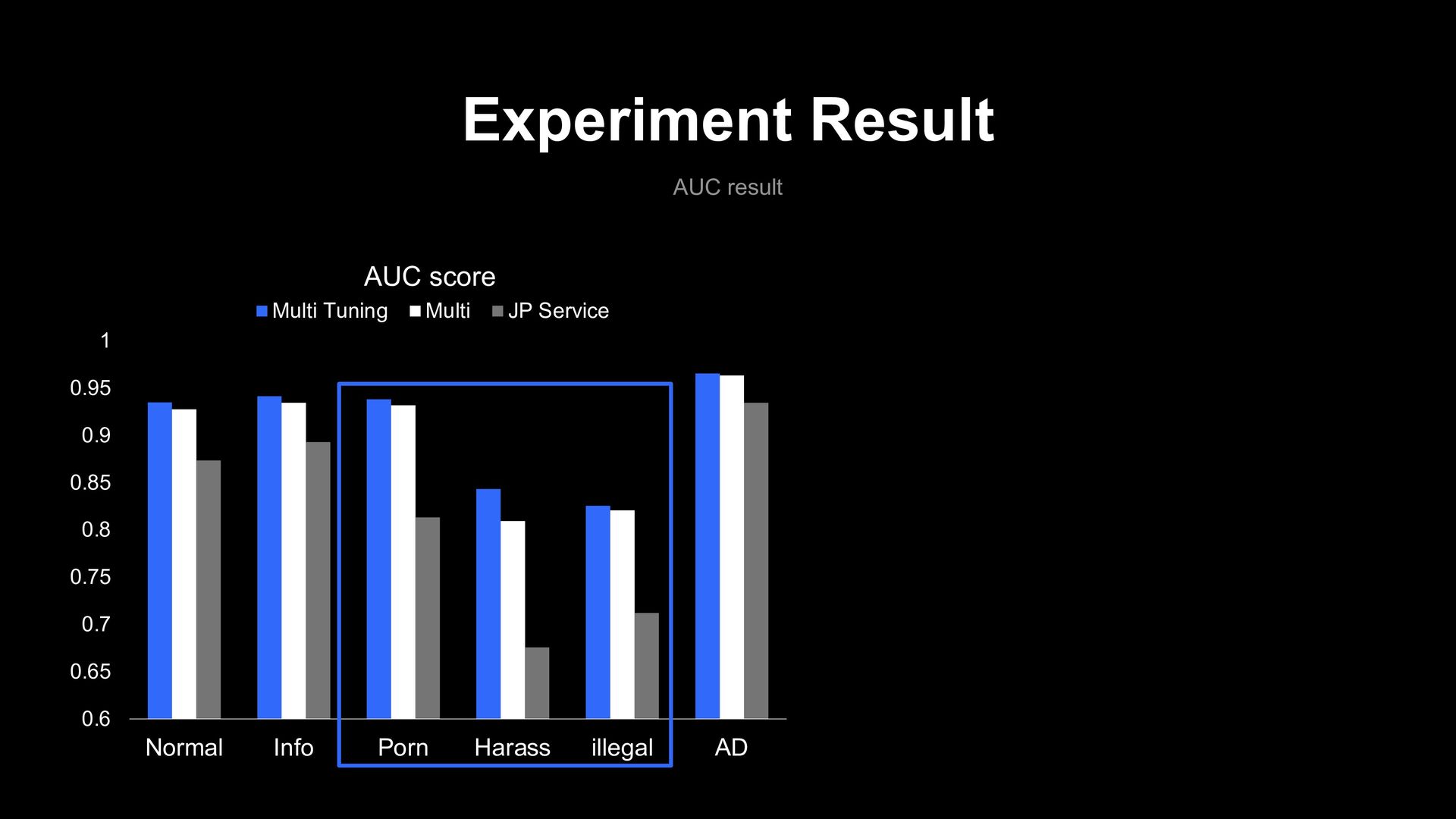
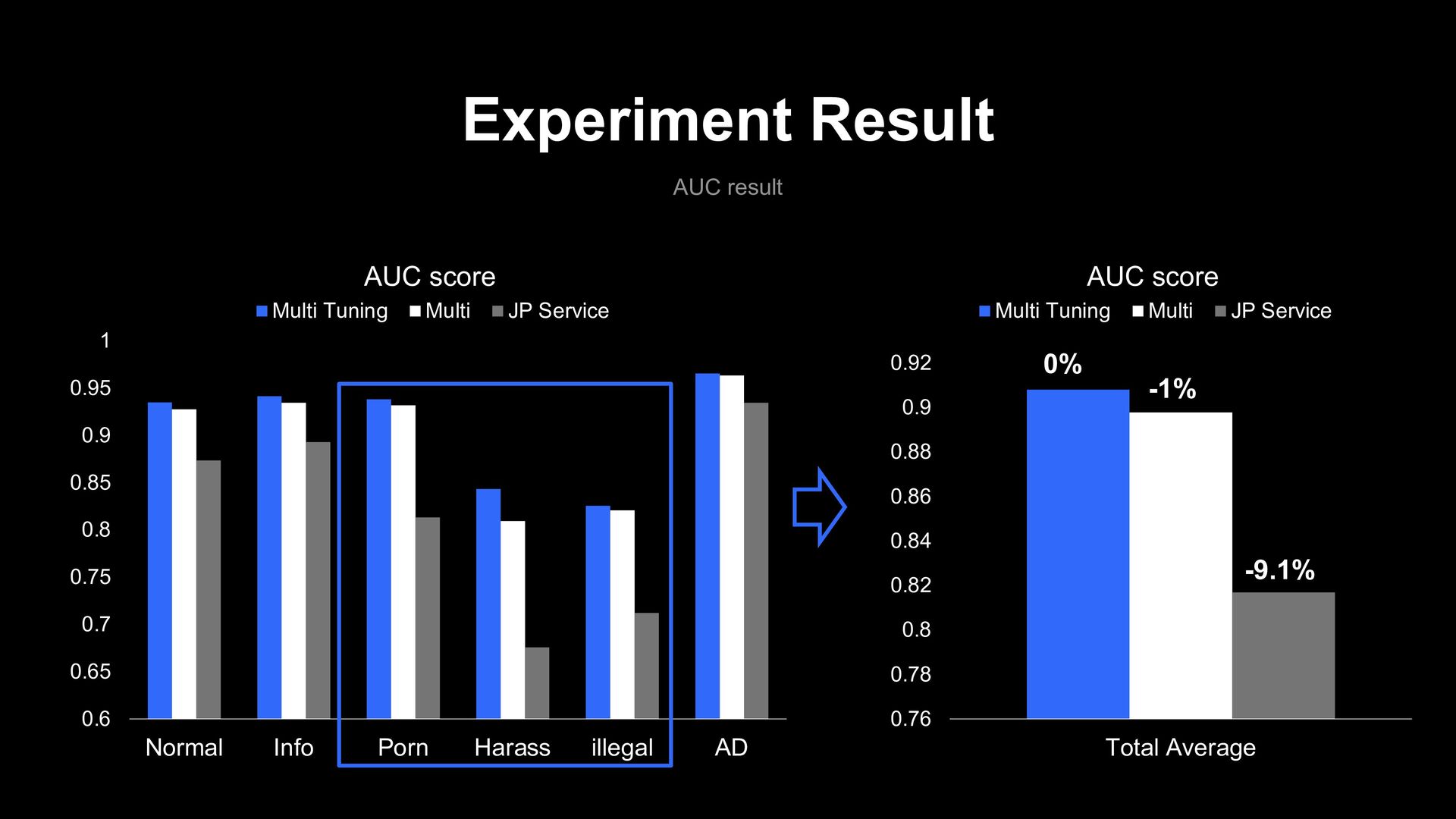
0.9 0.95 1 Normal Info Porn Harass illegal AD AUC score Multi Tuning Multi JP Service 0.76 0.78 0.8 0.82 0.84 0.86 0.88 0.9 0.92 Total Average AUC score Multi Tuning Multi JP Service -1% -9.1% 0%
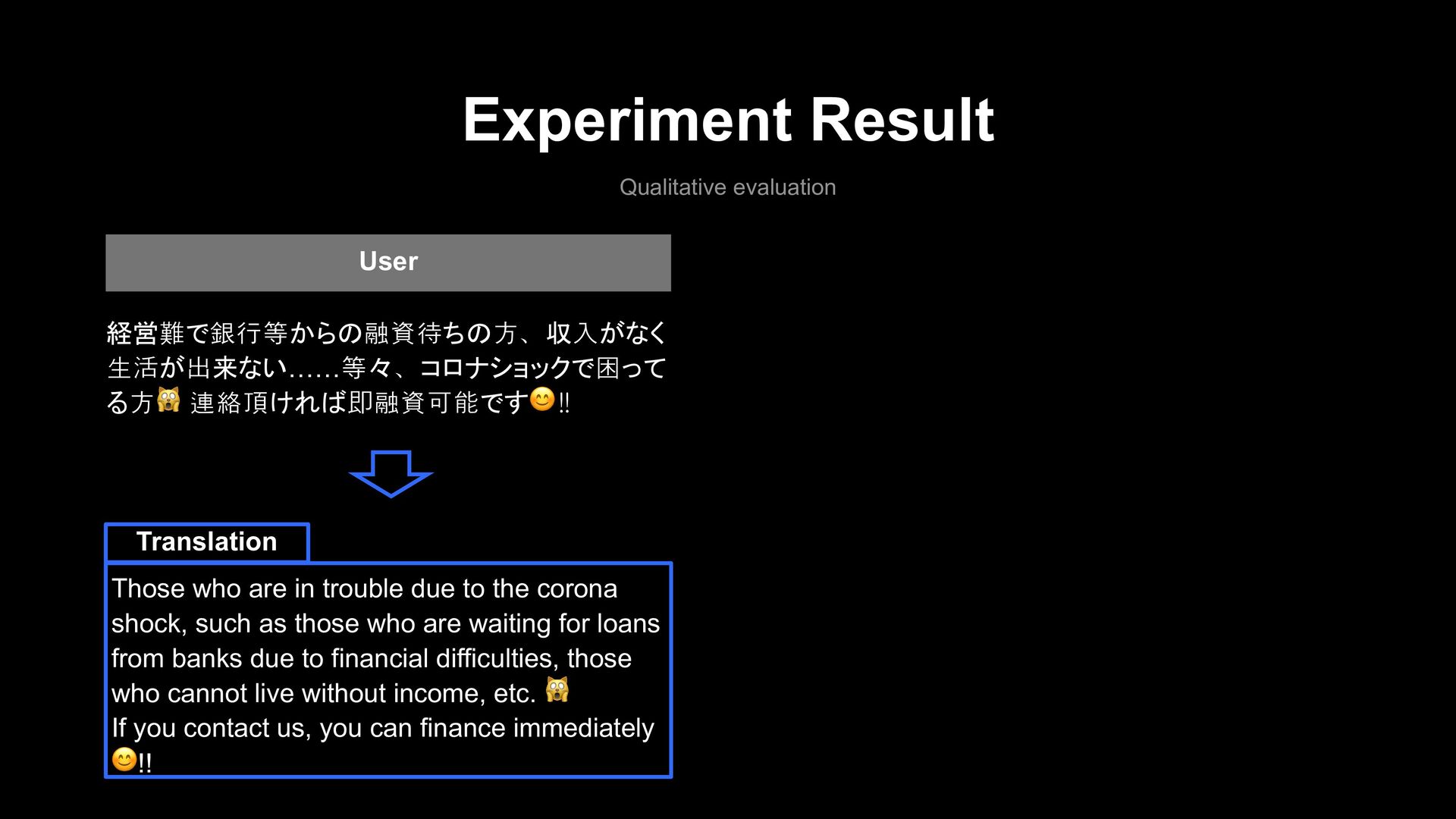
are in trouble due to the corona shock, such as those who are waiting for loans from banks due to financial difficulties, those who cannot live without income, etc. 🙀 If you contact us, you can finance immediately 😊!! Translation User
are in trouble due to the corona shock, such as those who are waiting for loans from banks due to financial difficulties, those who cannot live without income, etc. 🙀 If you contact us, you can finance immediately 😊!! Translation User JP Service Model illegal 12%
are in trouble due to the corona shock, such as those who are waiting for loans from banks due to financial difficulties, those who cannot live without income, etc. 🙀 If you contact us, you can finance immediately 😊!! Translation User Multi Language Large Model - Tuning JP Service Model VS illegal 99% illegal 12%
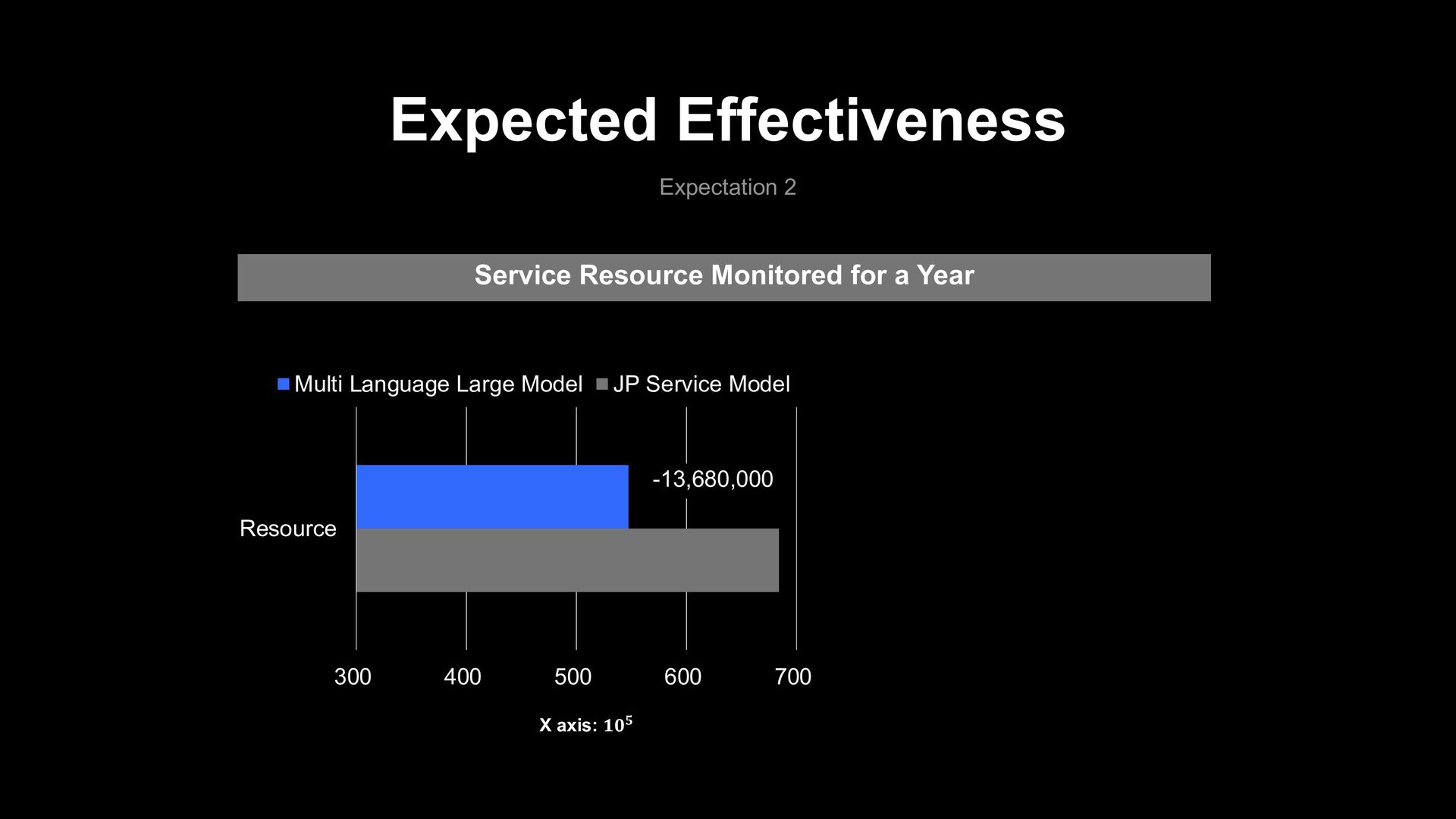
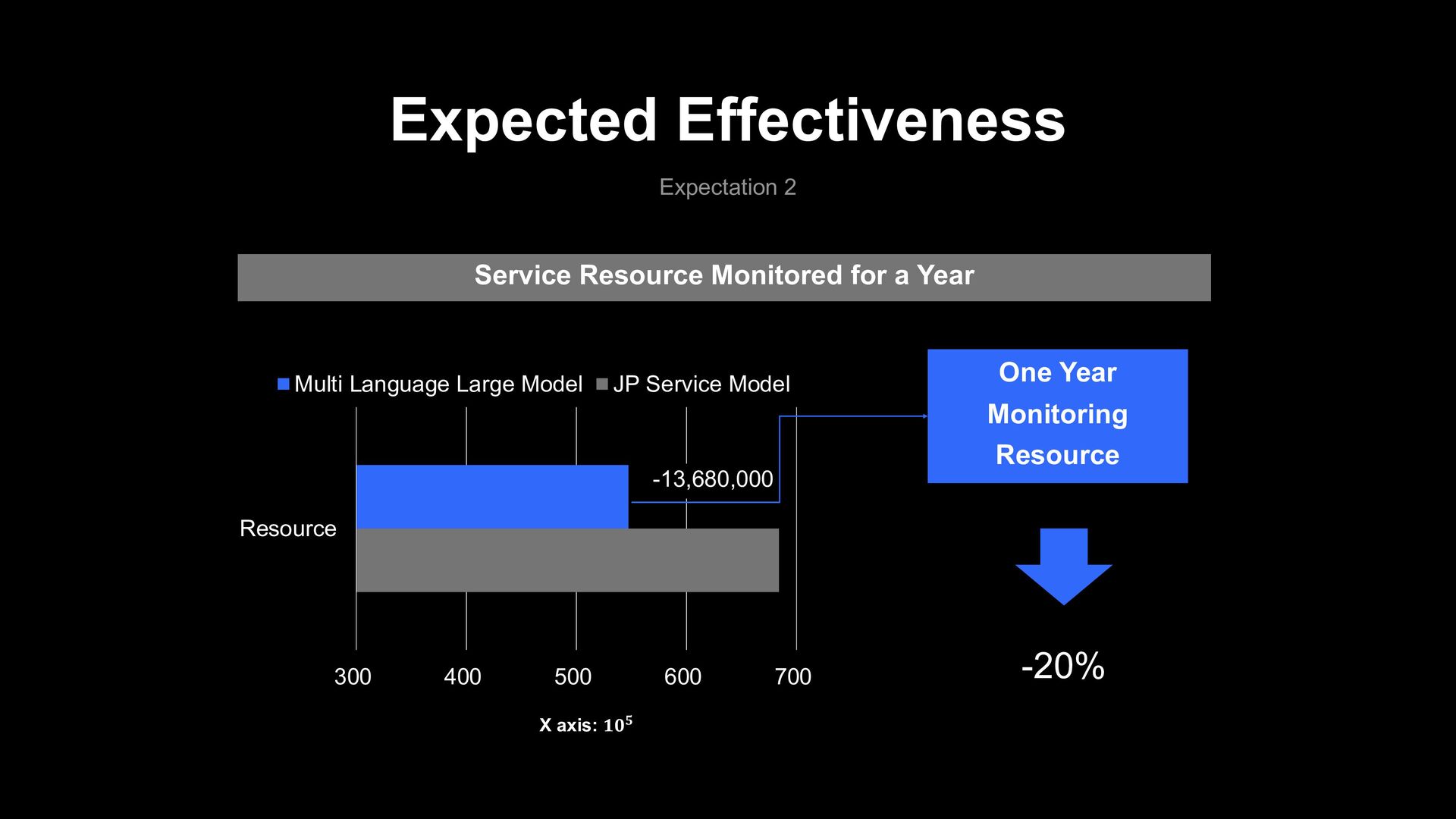
LMP system › 0.3% Monitoring rate down based current AI text filter service model Total 380,000,000 every month JP Service Model 5,700,000 Monitoring Data 1.5% Expected Effectiveness
LMP system › 0.3% Monitoring rate down based current AI text filter service model Total 380,000,000 every month JP Service Model Multi Language Large Model 5,700,000 Monitoring Data 1.5% 1.2% 4,560,000 Monitoring Data − Expected Effectiveness
LMP system › 0.3% Monitoring rate down based current AI text filter service model Total 380,000,000 every month JP Service Model Multi Language Large Model Monthly Monitoring Resource 1.5% 1.2% 4,560,000 Monitoring Data − Expected Effectiveness 1,140,000 Reduction 5,700,000 Monitoring Data
to understand and put in practice › Fun to study as much as it was difficult › Large model effectiveness › Need more collaboration with other teams › Future work › Large model hyper-parameter tuning
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}