Face à l'explosion du volume d'informations, la data est devenue “Big” et cela ne vous aura pas échappé. Vous avez sans doute entendu que le données se comptent désormais par Zettaoctets, qu’il y a de valeur cachée dans ce tas de données et que pour les analyser il faut faire appel aux technologies Big Data ! Et Hadoop fut !
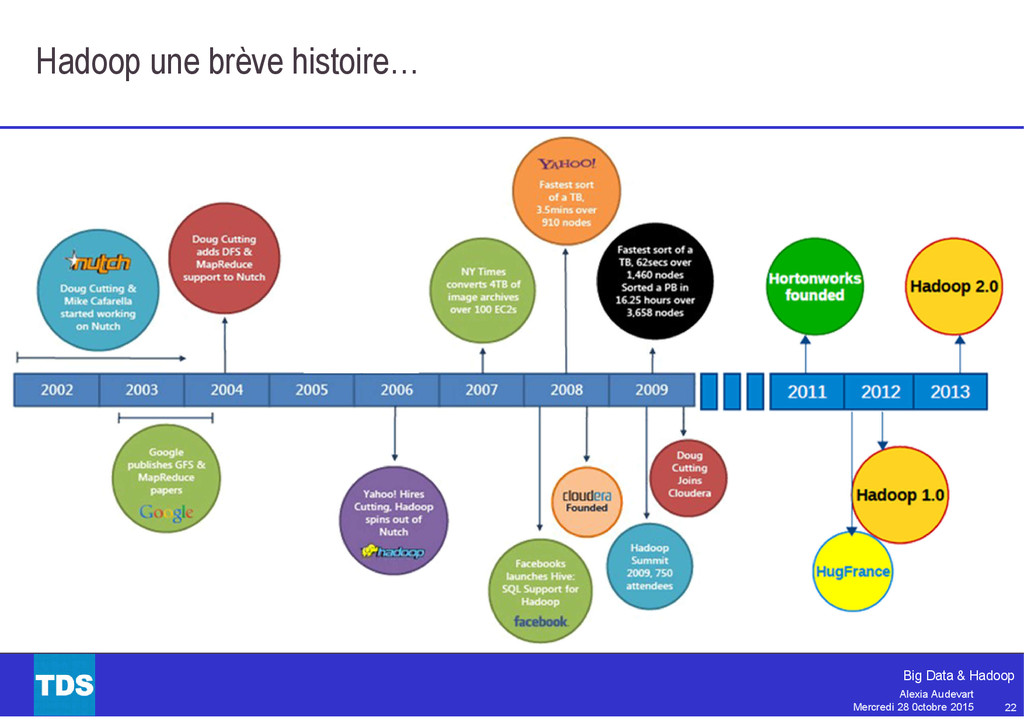
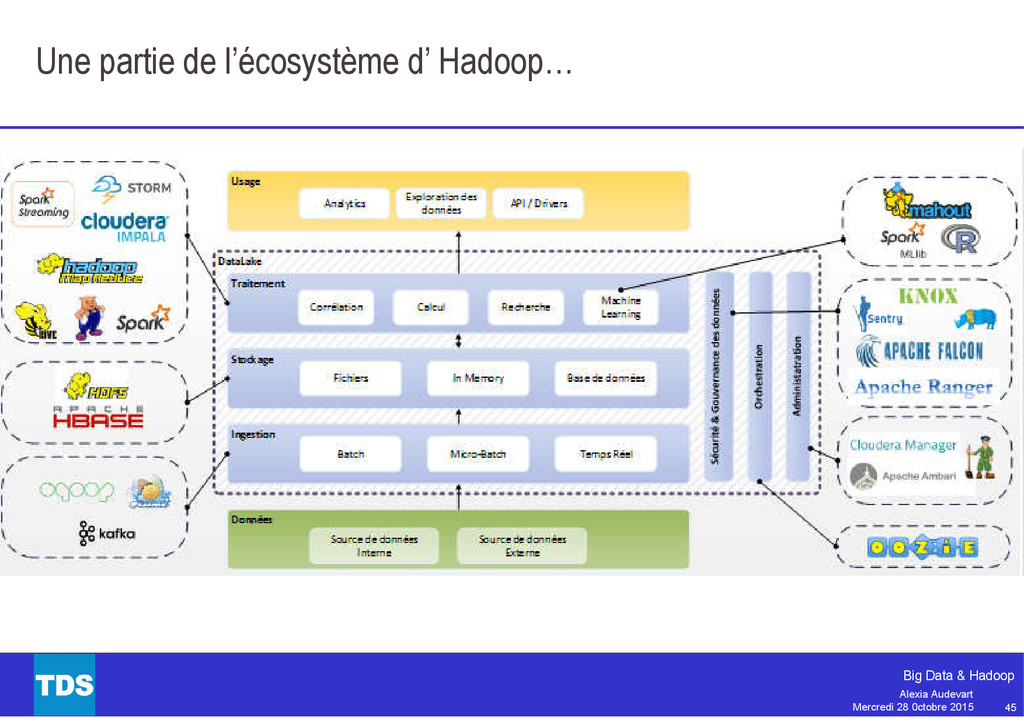
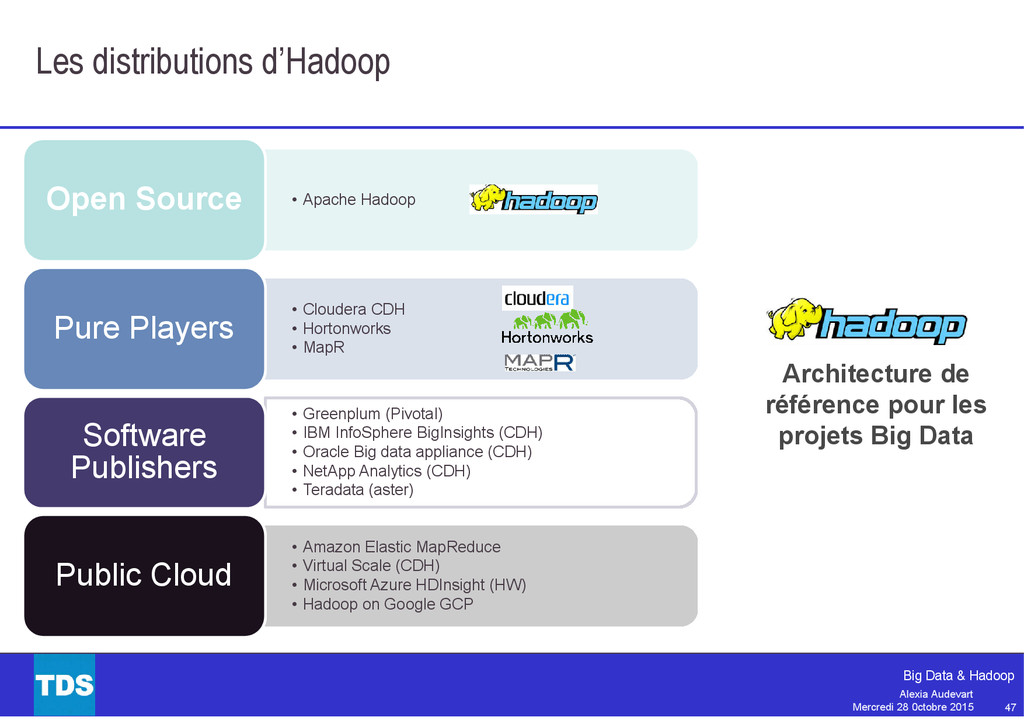
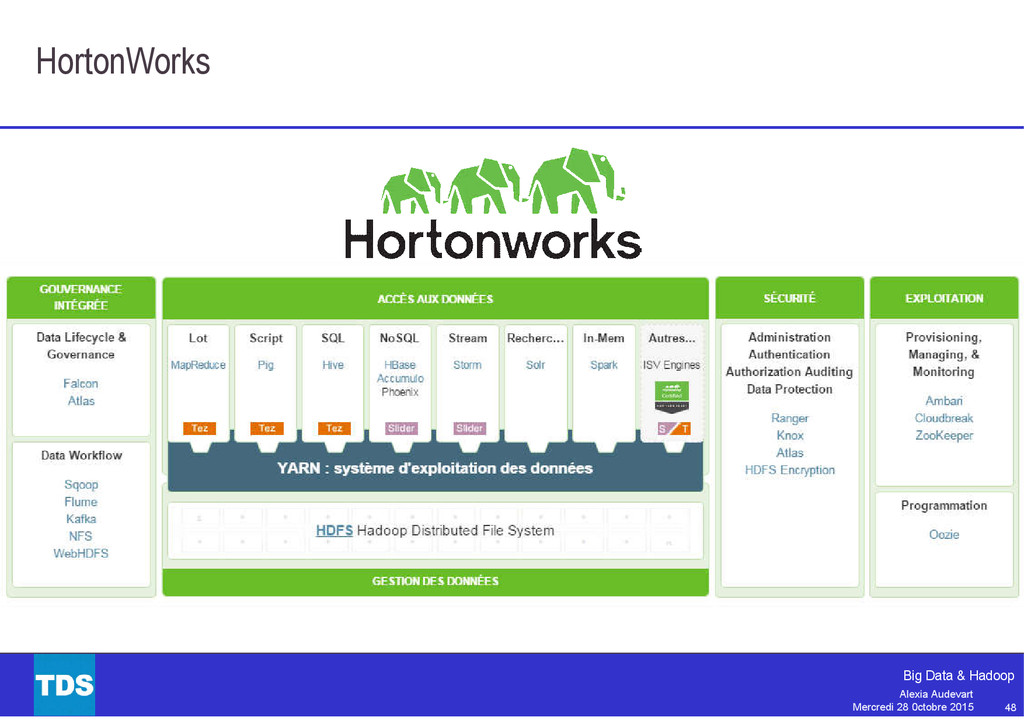
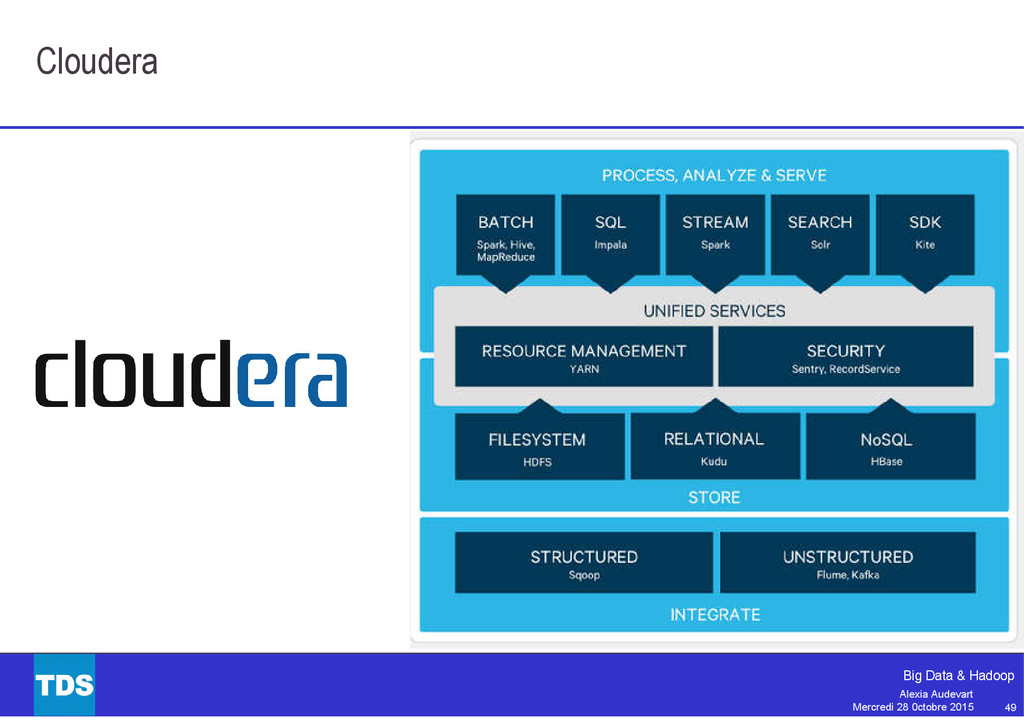
Souvent pris par synonyme de Big Data, Hadoop est aujourd’hui bien plus qu’un simple framework pour le traitement massivement parallèle. L’écosystème Hadoop est aujourd’hui très riche et mature : MapReduce, Pig, Hive, Tez, Spark, Flume et plus encore.
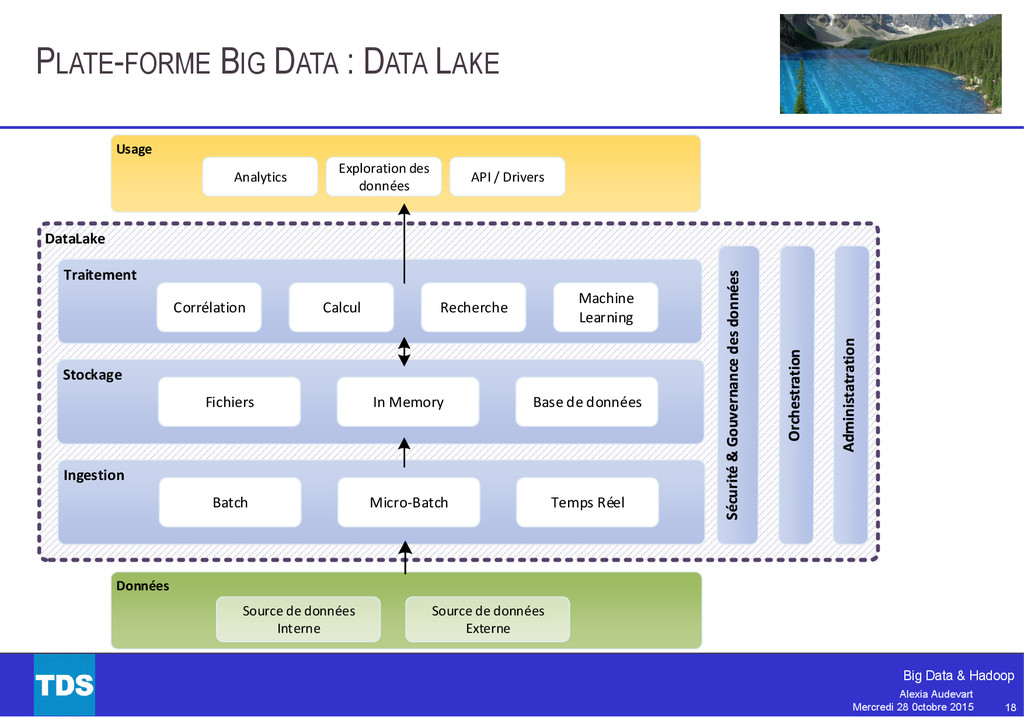
Alexia Audevart, architecte Big Data chez Capgemini, nous propose de voir au-delà du buzzword marketing et découvrir vraiment ce qu’est Big Data et en particulier la plate-forme Big Data Hadoop qui permet de capter, stocker, filtrer, analyser ces grosses volumétries de données.
Présentation Meetup Toulouse Data Science - 28 Octobre 2015
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
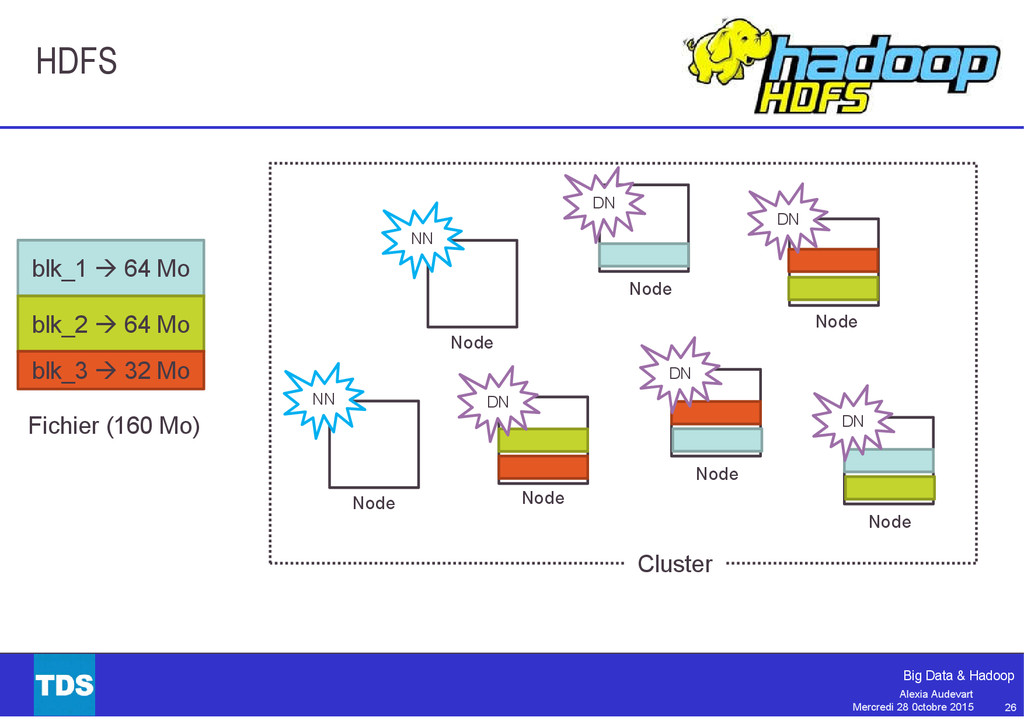{kind=link}
{kind=link}
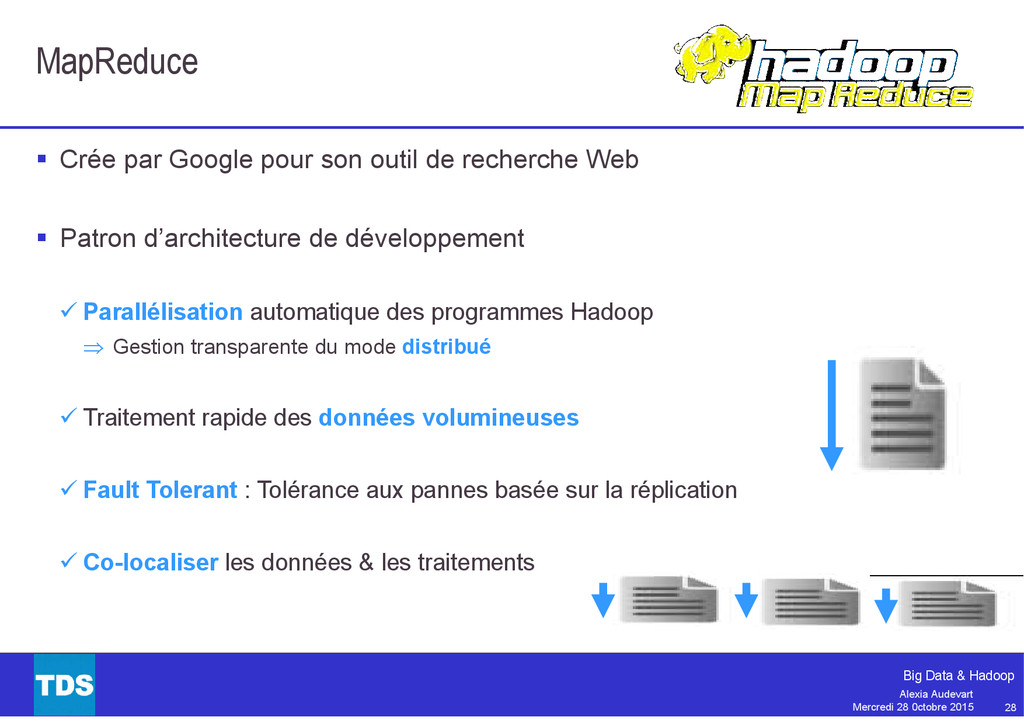{kind=link}
{kind=link}
{kind=link}
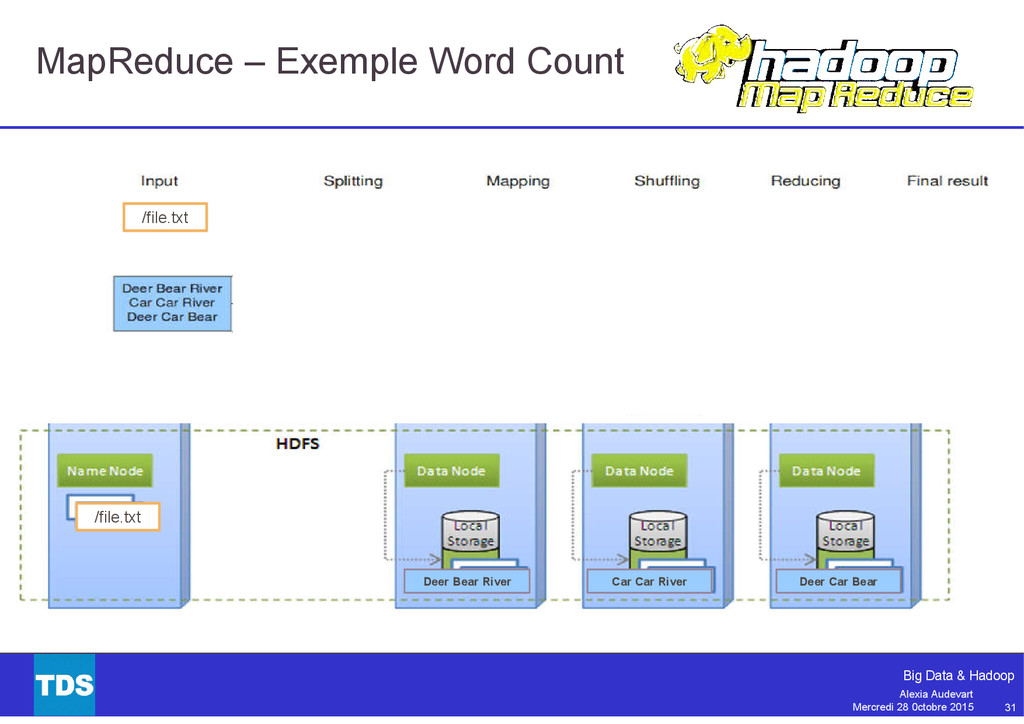{kind=link}
{kind=link}
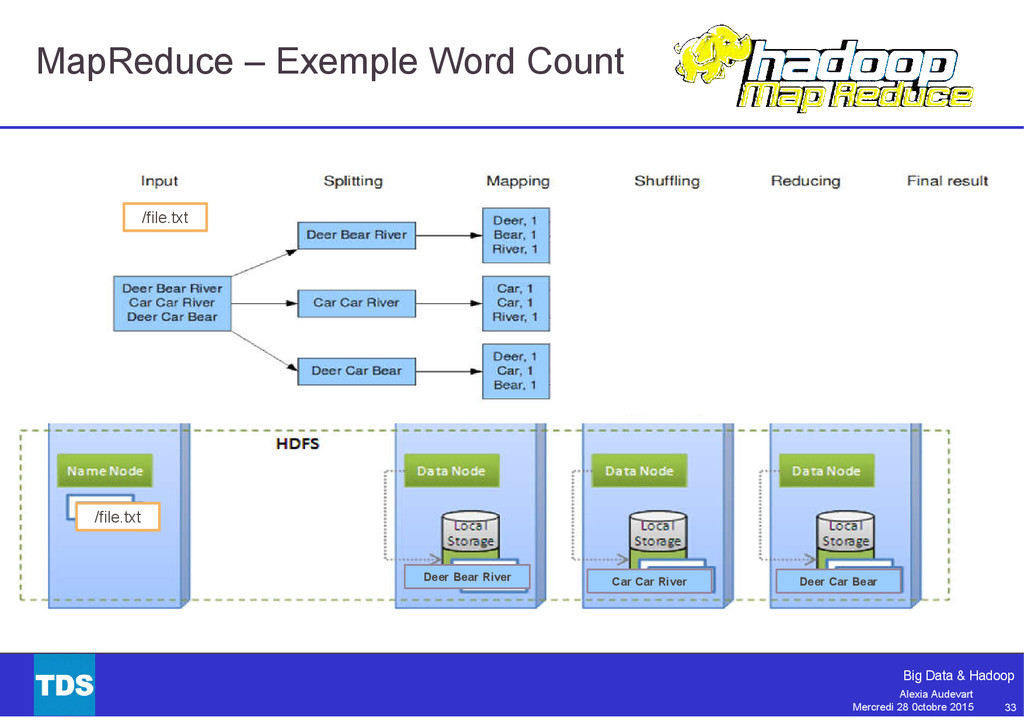{kind=link}
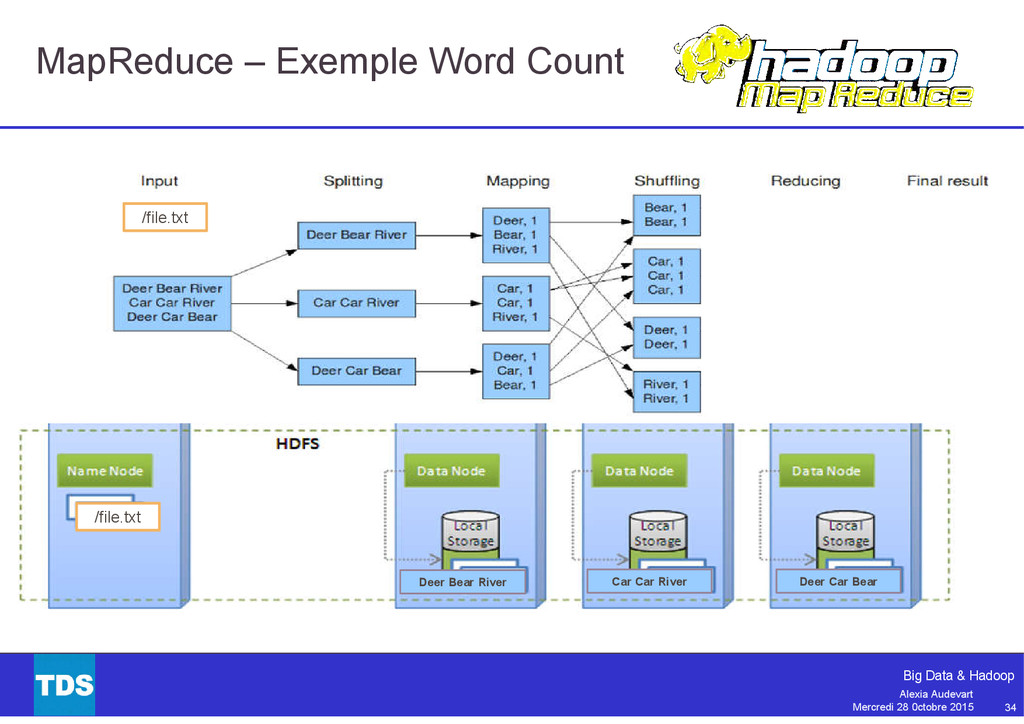{kind=link}
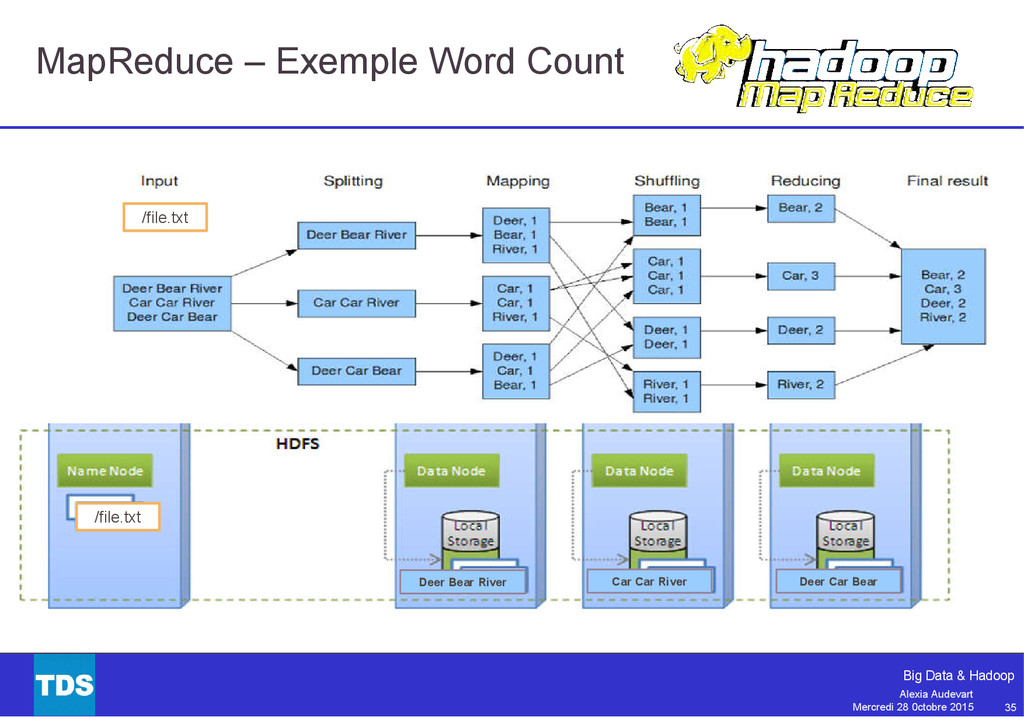{kind=link}
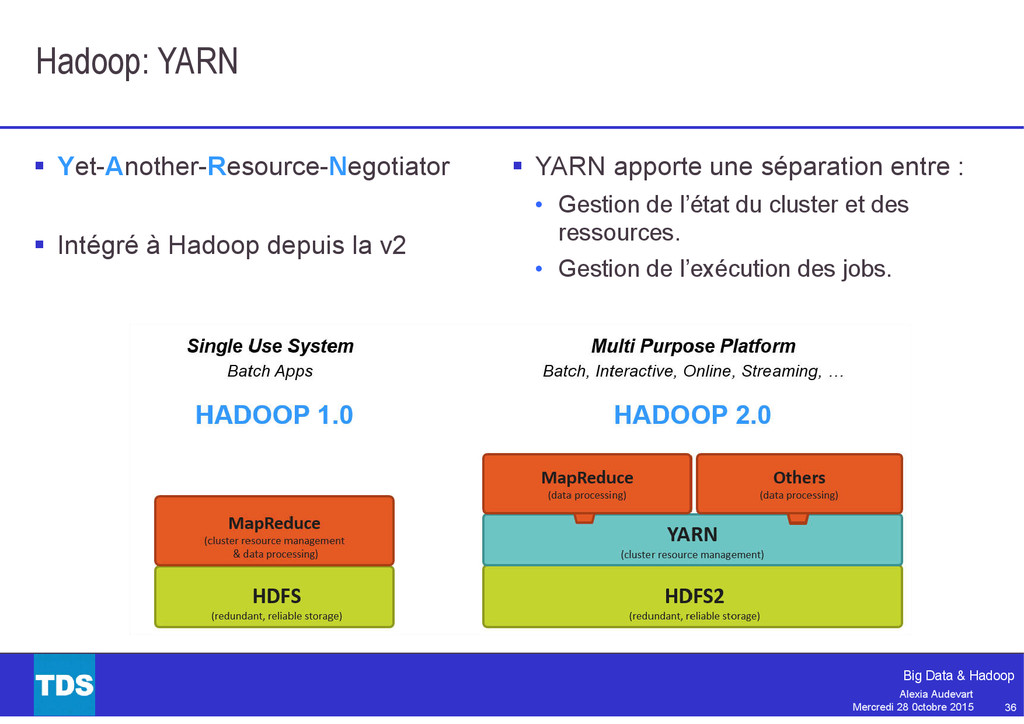{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
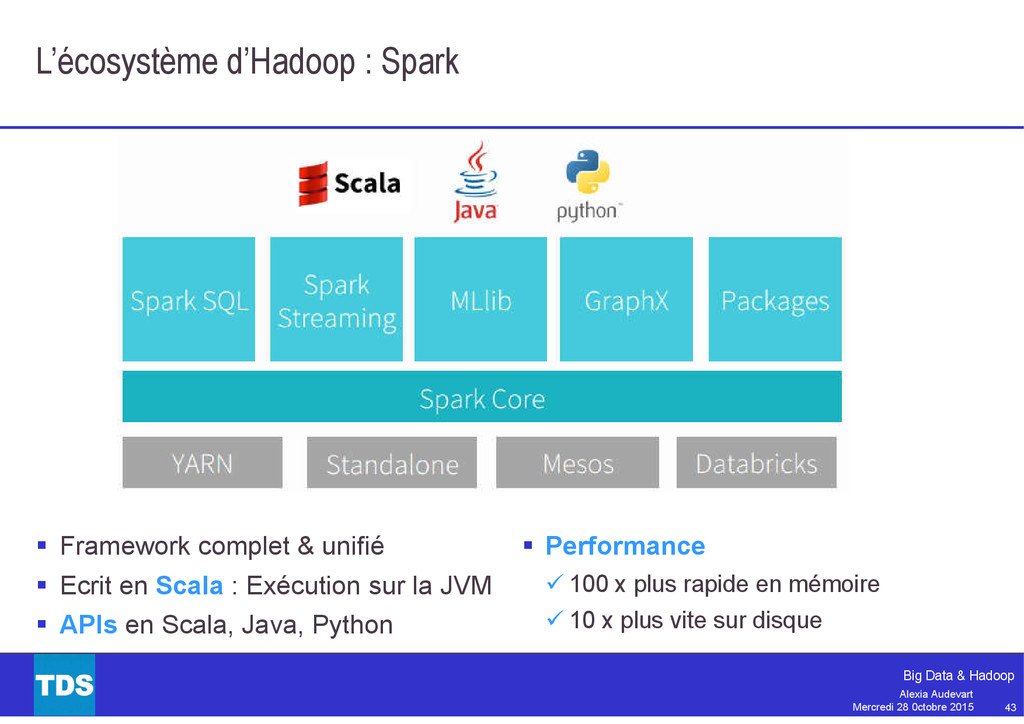{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}