Sujet: DEEP LEARNING ON 3D DATA
Speaker: Nicola Luminari, Computer Vision Engineeer chez Delair
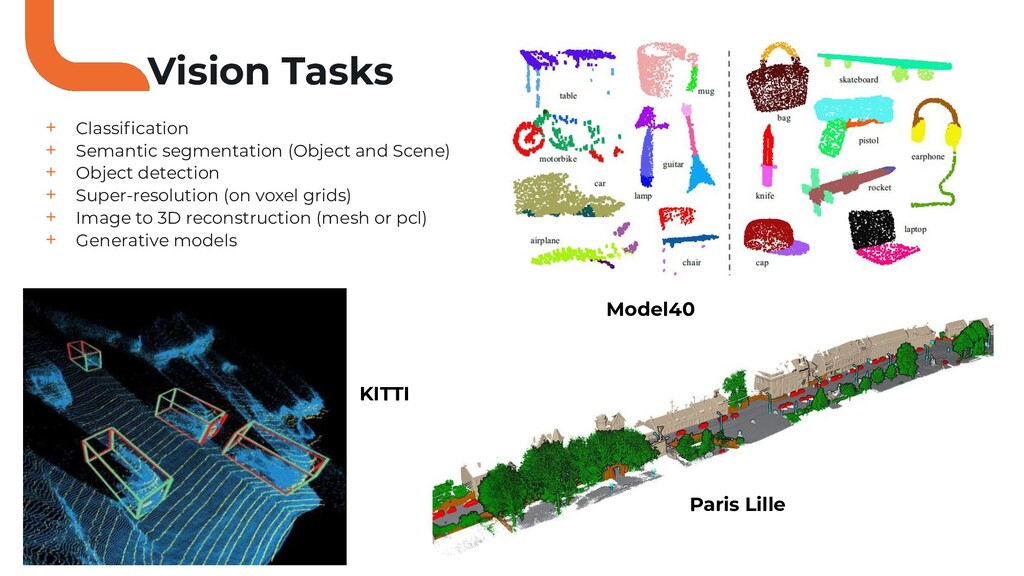
Les cameras et la data basées sur l'image ont forcés le développement de réseaux de neurones conventionnels pour résoudre des tâches de vision par ordinateur (détection d'objet etc..).
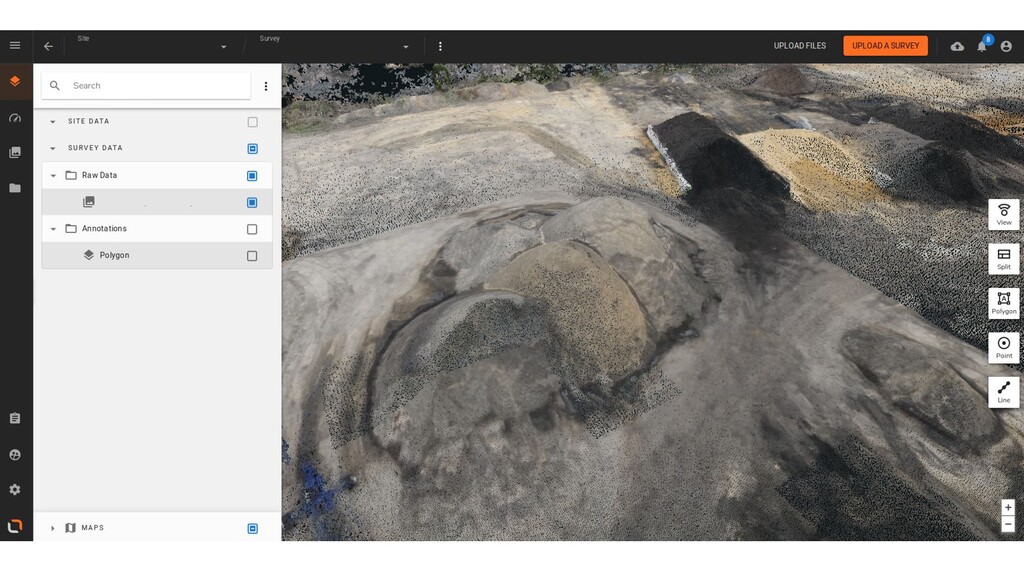
Cependant, aujourd’hui diverses applications comme le mapping par drone et la conduite automatique, utilisent des capteurs différents (comme le LIDAR) qui permettent de produire une représentation 3D de la scène autour du capteur (maillages et/ou nuages de points).
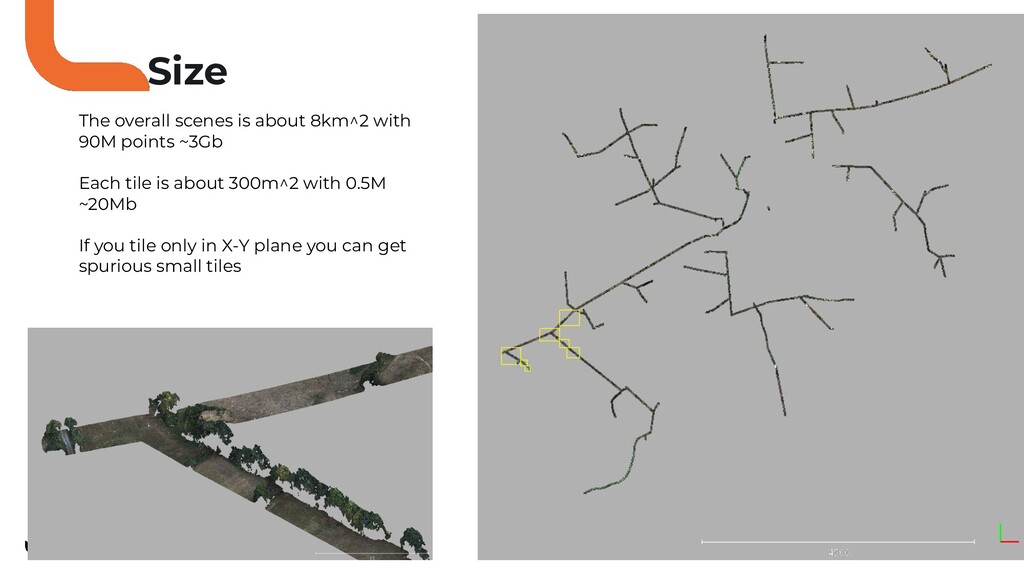
Cette nouvelle typologie de données 3D ne peut pas être traité naïvement avec des réseaux CNN “modernes” à cause de problématique diverses et variés.
De ce fait, de nouvelles CNN spécialisées pour la 3D viennent d'être proposées en littérature.
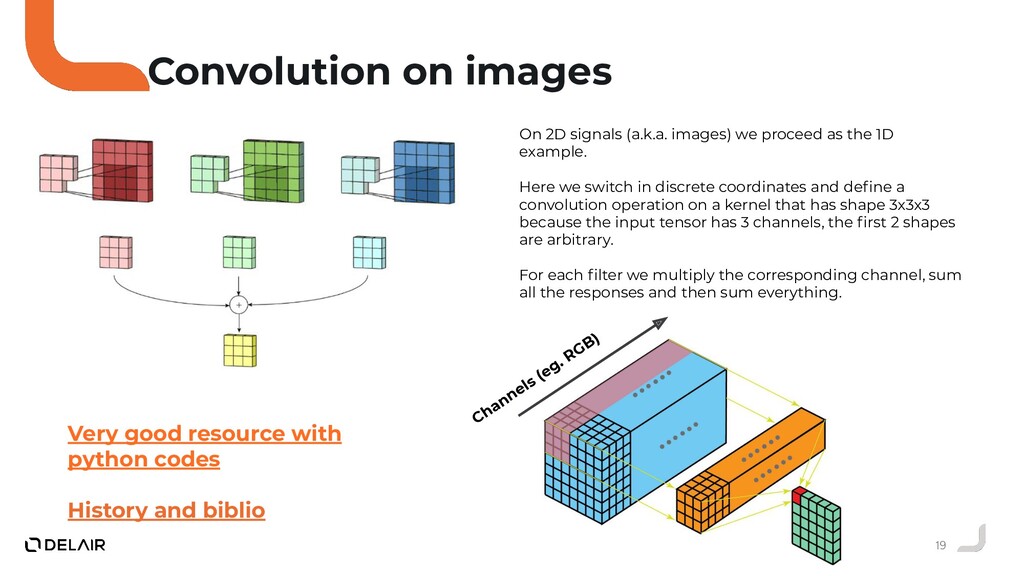
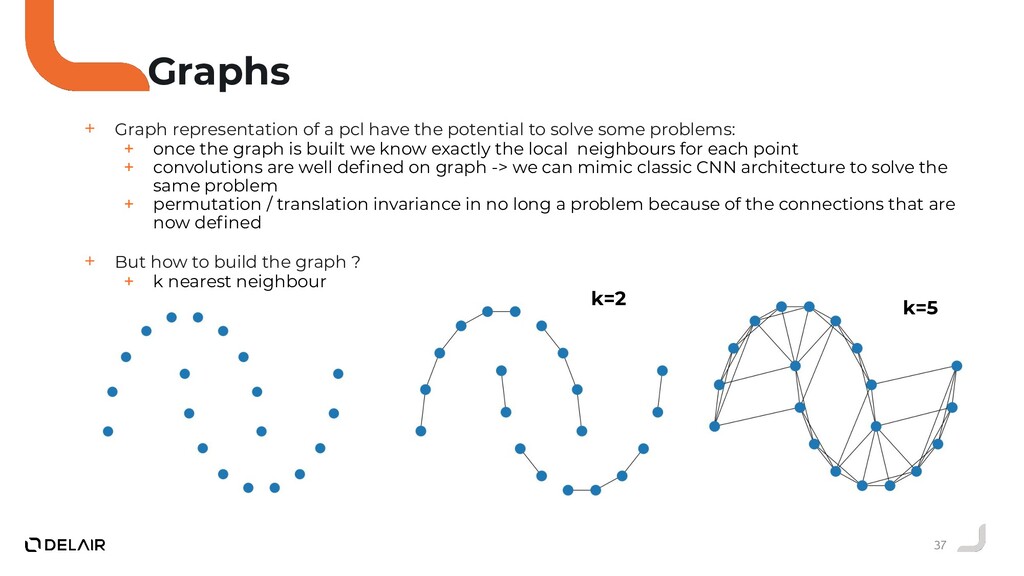
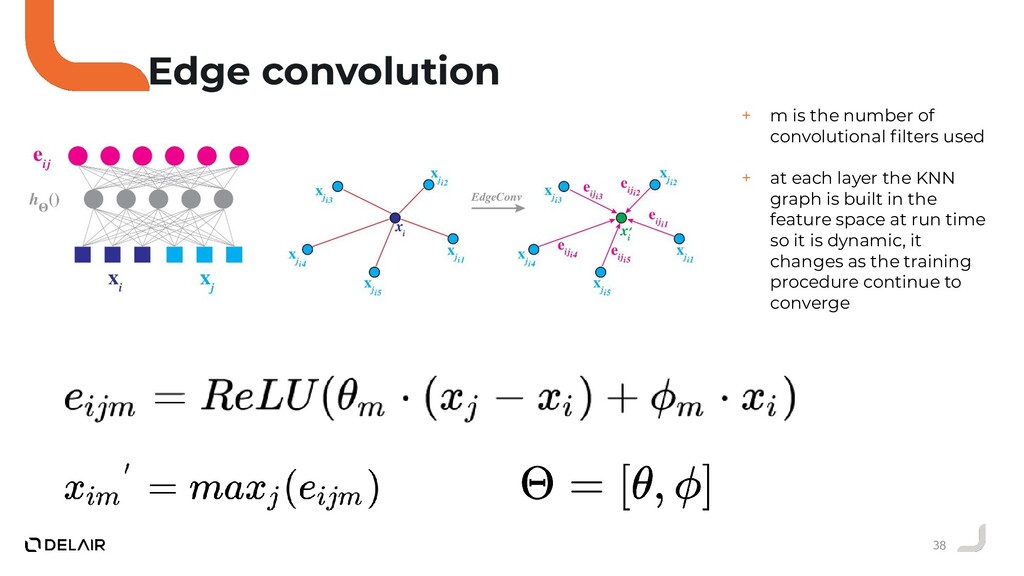
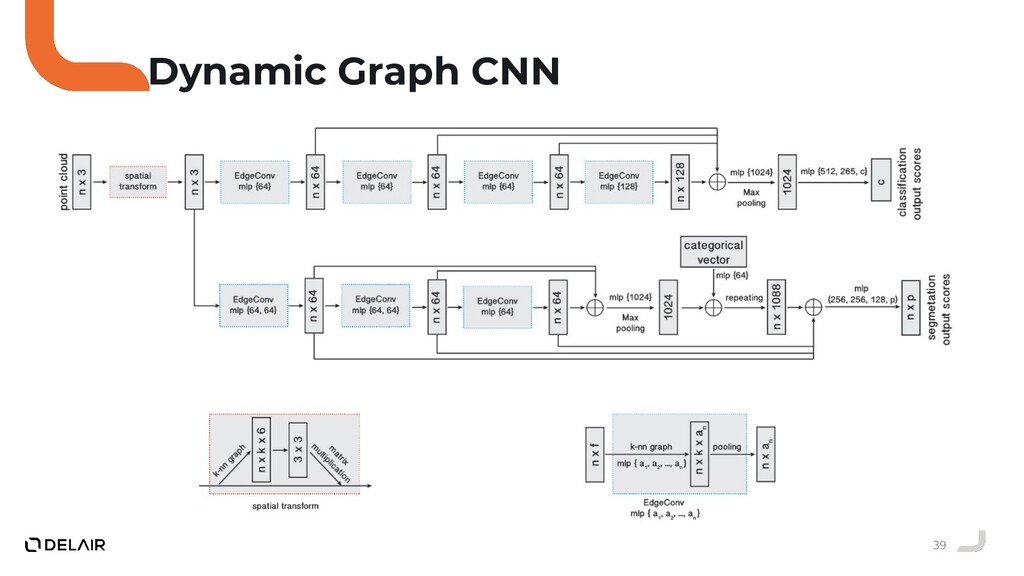
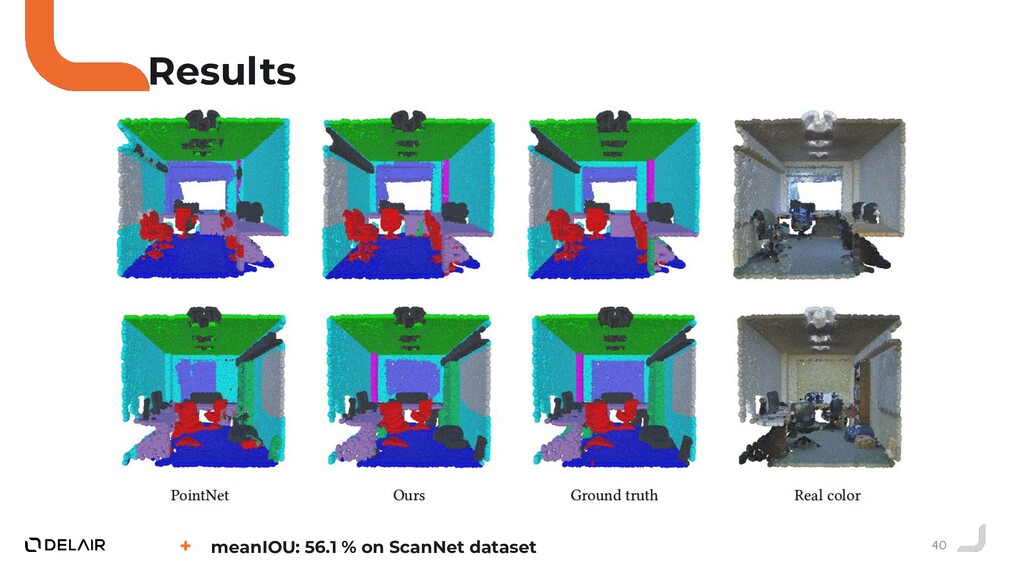
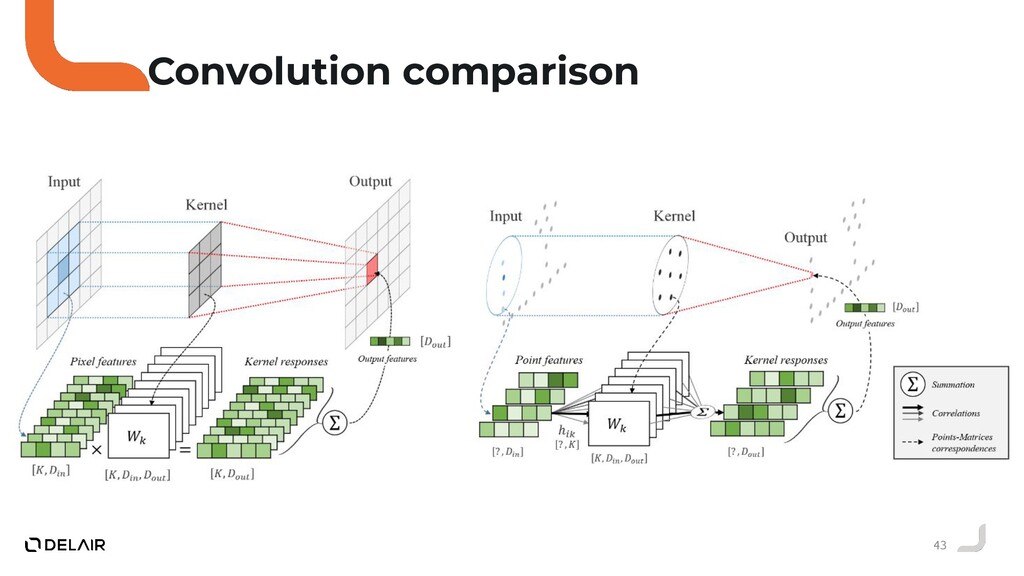
Durant ce talk nous allons voir pourquoi l'opérateur de convolution classique ne peut pas être utilisé directement sur des nuages de points.
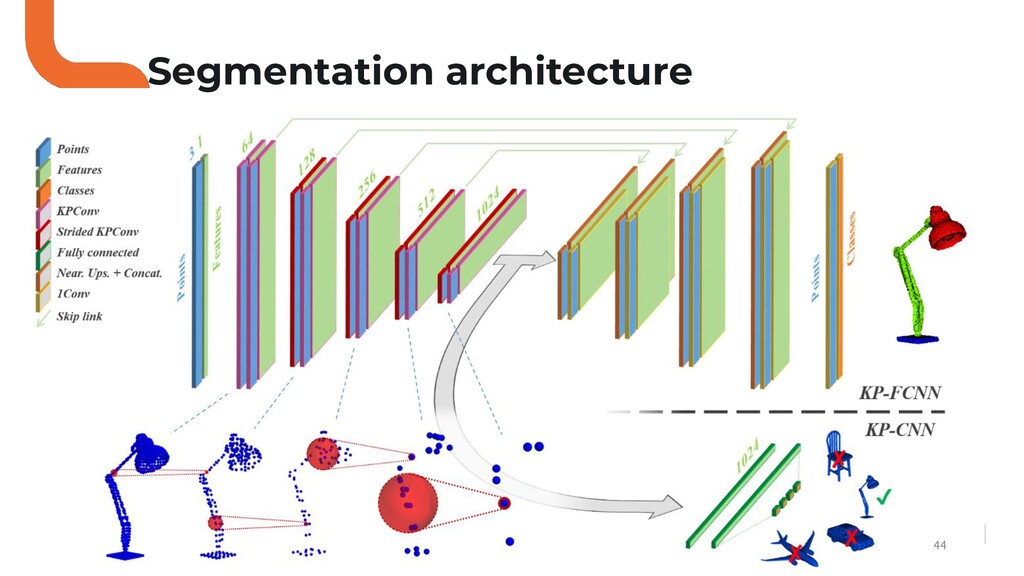
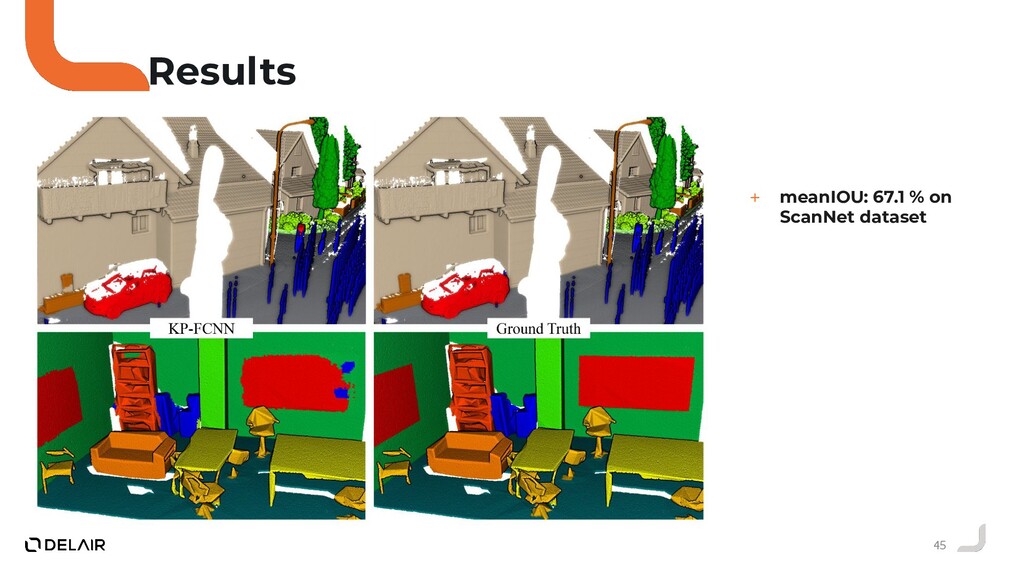
Puis, nous allons faire le tour des solutions proposées par la communauté deep learning sur ce sujet.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![16 Datasets + https://modelnet.cs.princeton.edu/ [Classification 93.6% accuracy] + http://www.cvlibs.net/datasets/kitti/ [3D](https://files.speakerdeck.com/presentations/f5f3554651c24c76bf9f01e5151e7226/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
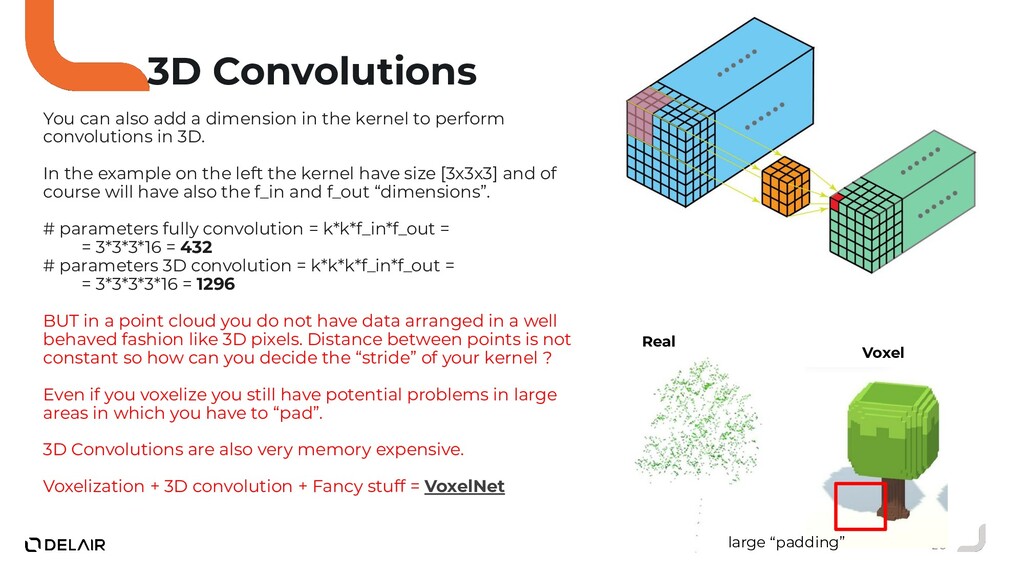{kind=link}
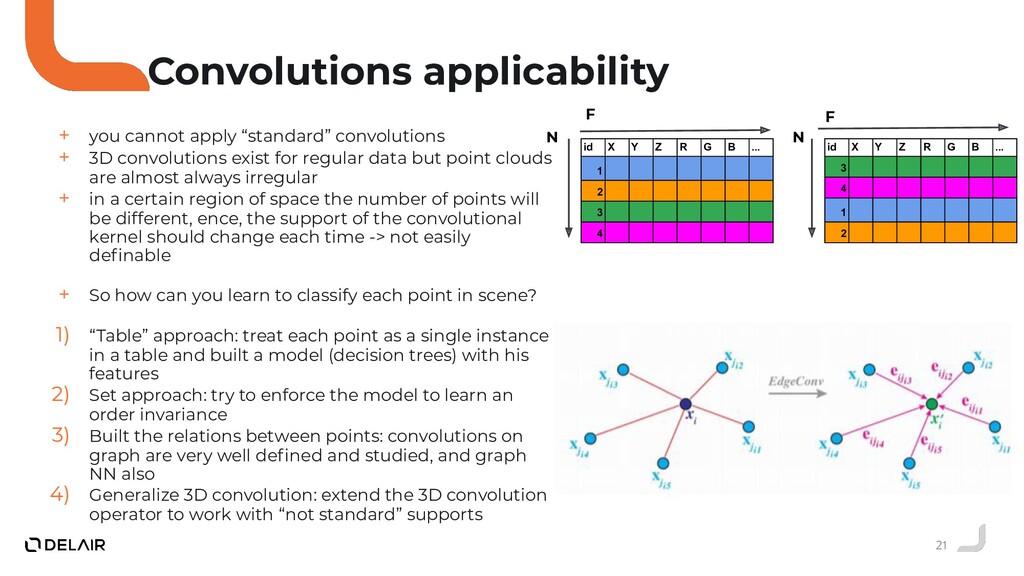{kind=link}
{kind=link}
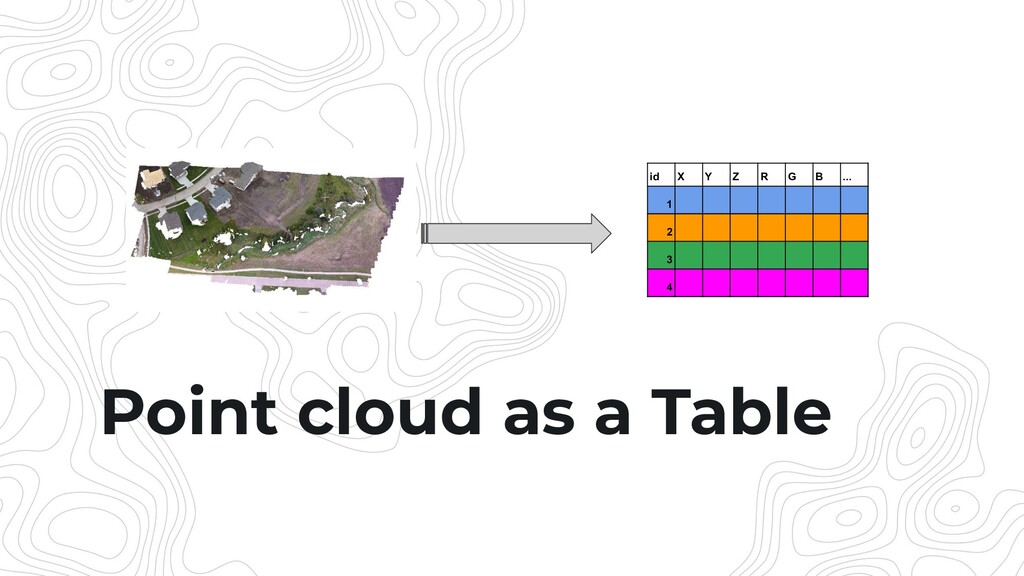{kind=link}
{kind=link}
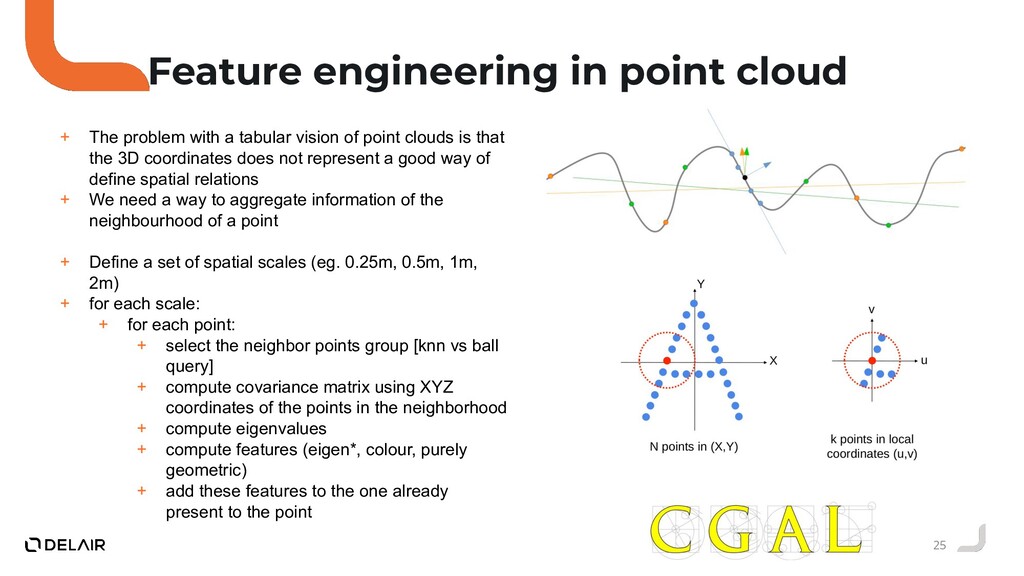{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you. Follow us Contact us [email protected] www.delair.aero](https://files.speakerdeck.com/presentations/f5f3554651c24c76bf9f01e5151e7226/slide_50.jpg){kind=link}
{kind=link}