Pendant cette époque de hype autour du machine learning, ce sont les applications de l'apprentissage supervisé qui semblent avoir toute l'attention du public.
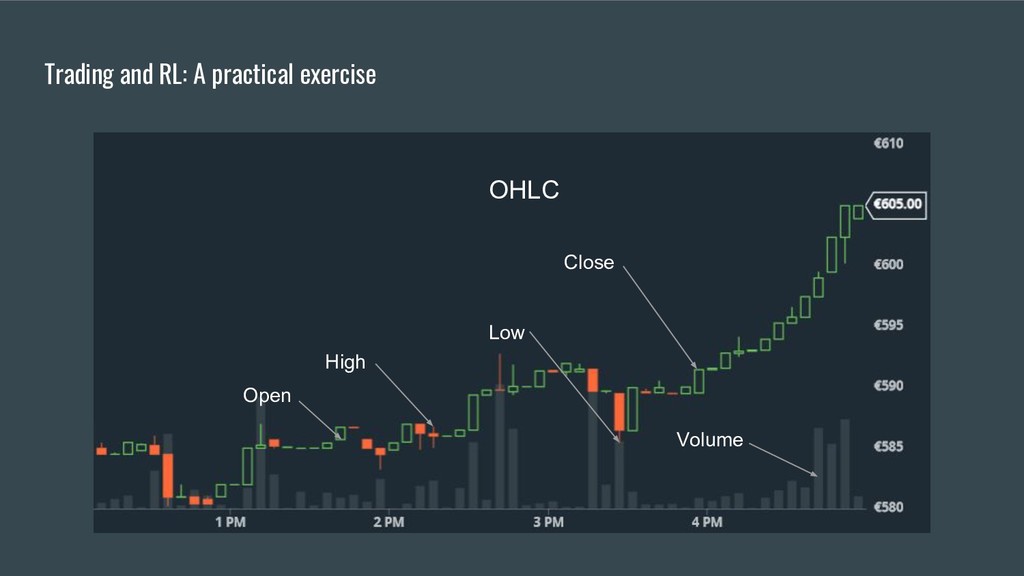
Présentation du RL ainsi que quelques applications. L'une sera la création d'un bot pour trading automatique que nous explorerons un peu plus à fond en s'appuyant sur un projet développé depuis le début de l'année. Ce projet open source se sert d'environnements OpenAI custom afin de fournir les outils nécessaires et surtout standardisés à tous ceux qui voudront créer leur propre bot!
Plus d'infos sur ce projet : https://github.com/GuilhermeGSousa/ml-stock-prediction
Cette présentation portera ainsi sur les sujets suivants :
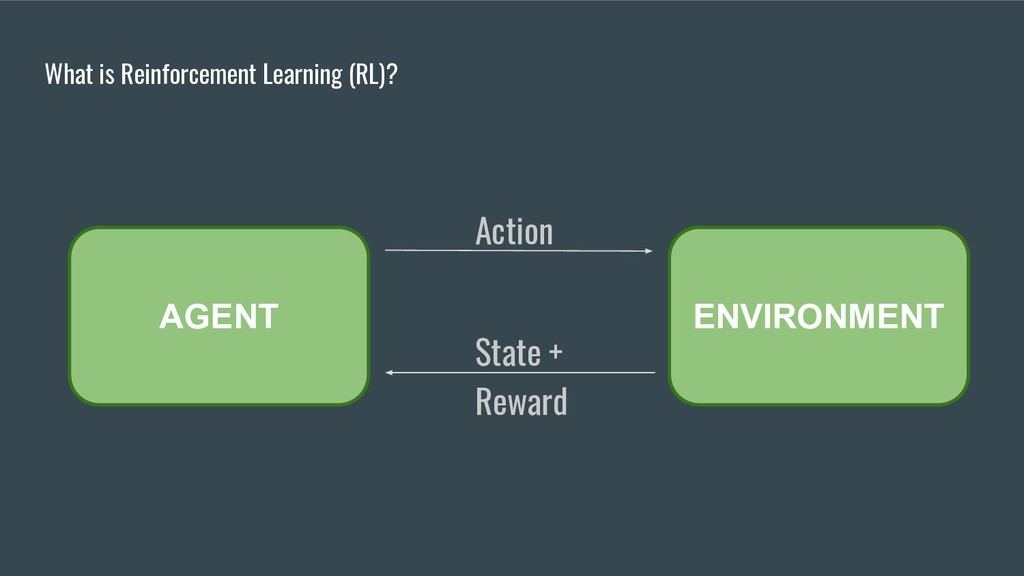
• Qu’est-ce l’apprentissage par renforcement et quelles sont ses applications.
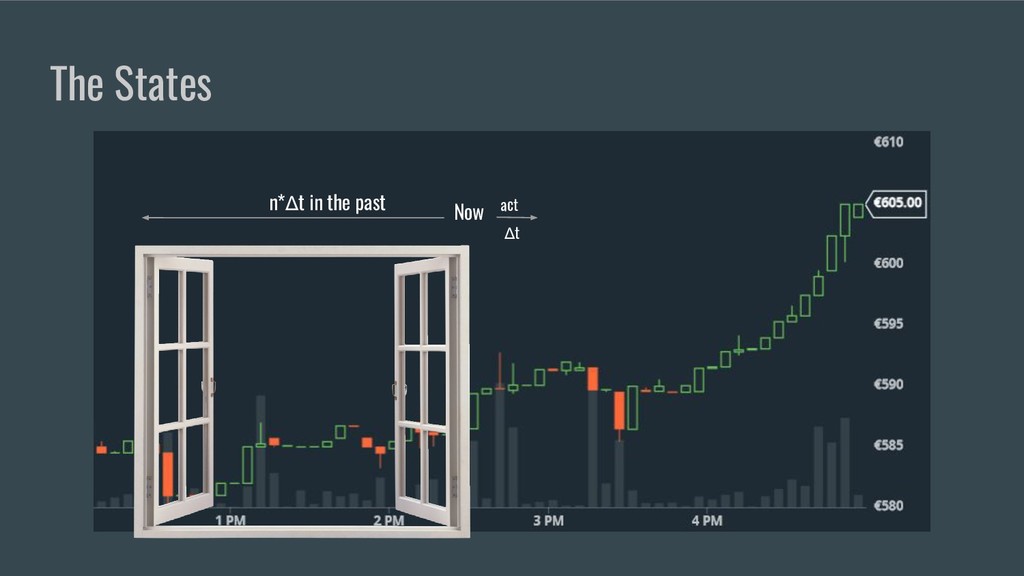
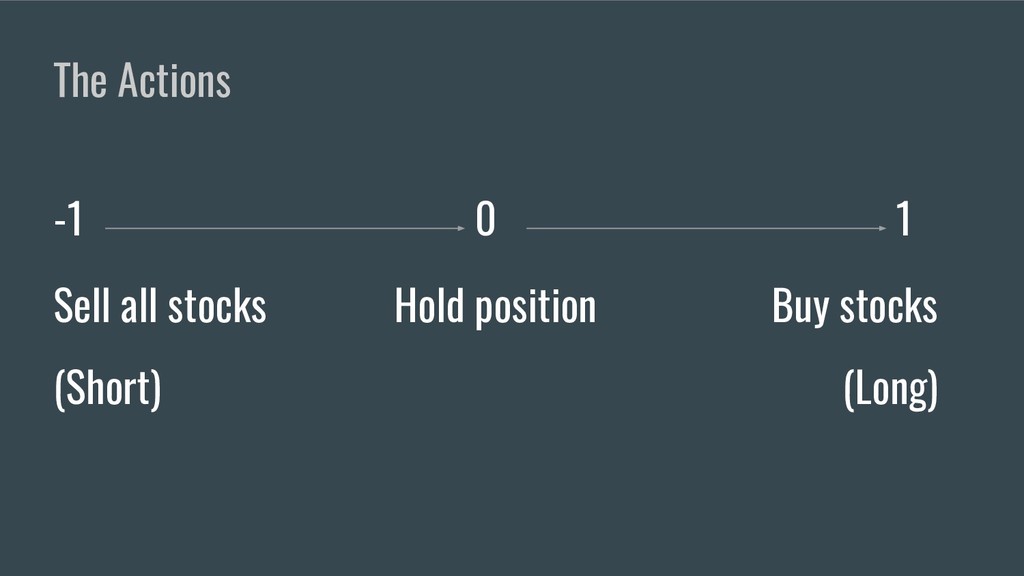
• Comment énoncer un problème d’apprentissage par renforcement.
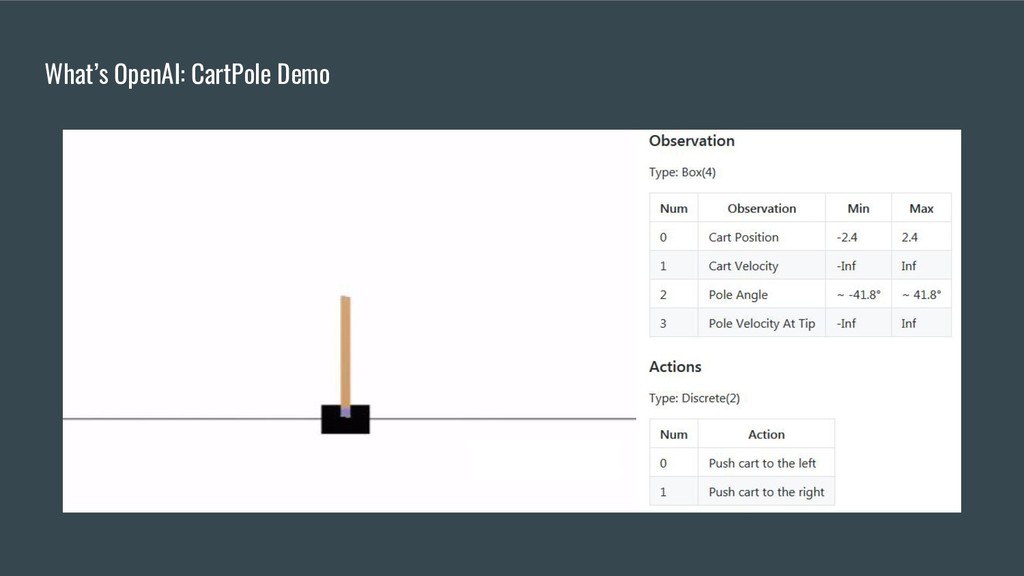
OpenAI Gym et ses environnements.
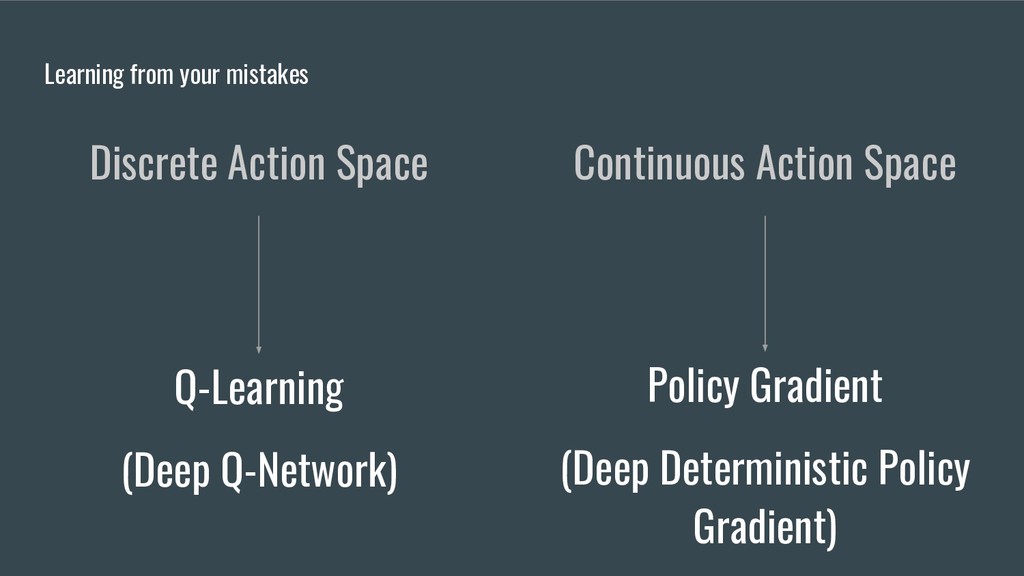
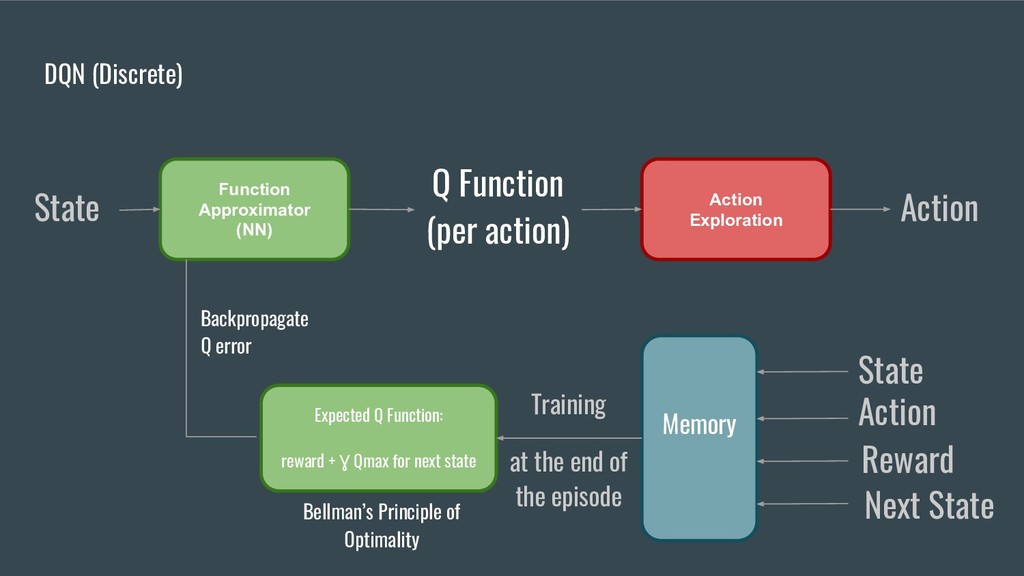
• Présenter quelques algorithmes utilisés dans le domaine du Reinforcement Learning (RL) (Q-learning et Policy Gradient).
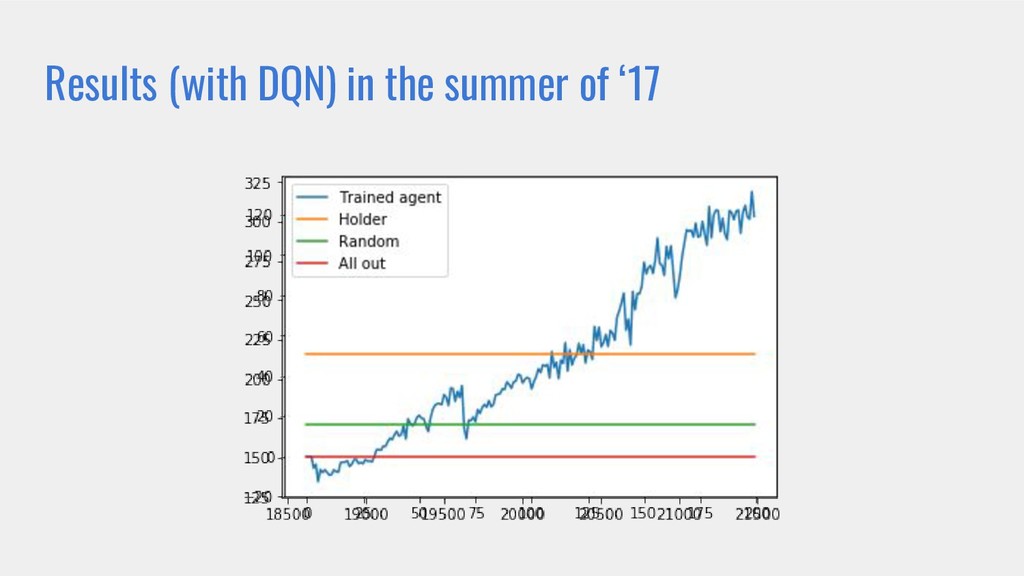
• En se basant sur les points précédents, démontrer comment créer et entrainer un bot capable de faire du trading en utilisant des environnements OpenAI customisés.
Bio:
- Guilherme Sousa - dev software @ Thales Avionics / Sous-traitant SII
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}