Speaker : Erwan David, CTO chez DEXSTR
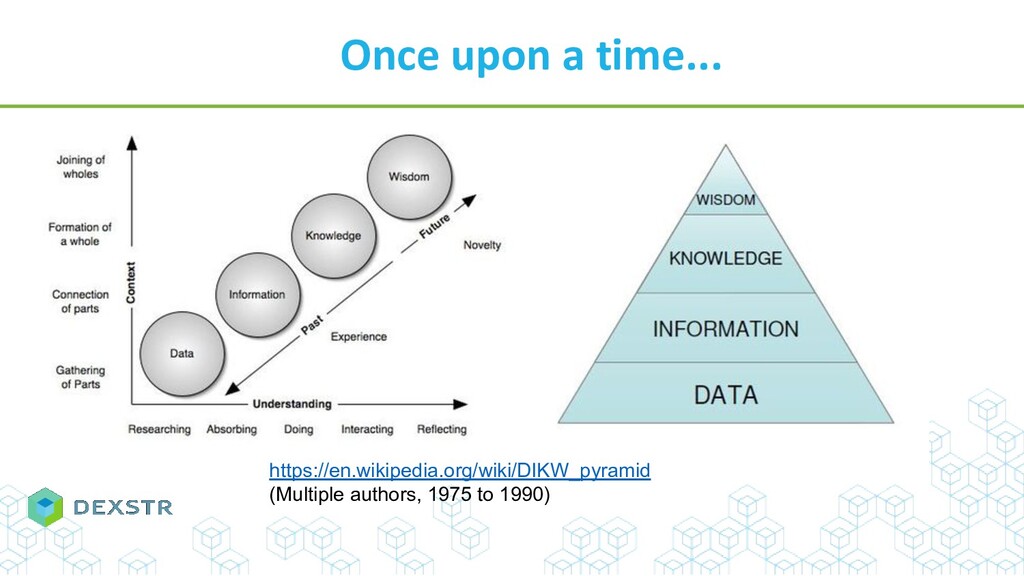
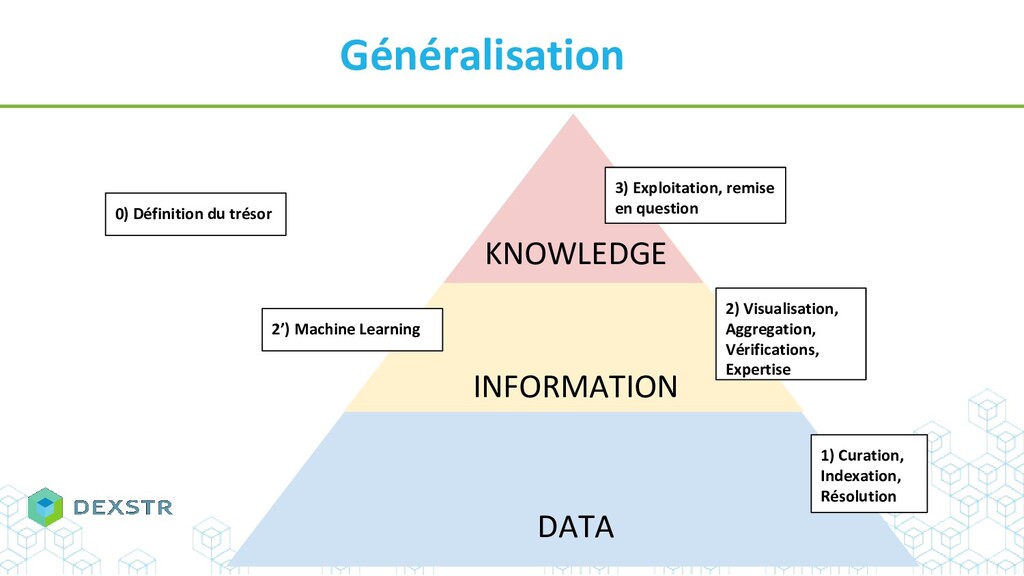
Abstract :De la BI au Big data, nous autres informaticiens nous targuons de transformer la donnée en informations et même en connaissance.
Mais qu'en est il vraiment ? Comment extraire, stocker et rendre utilisable des connaissances ?
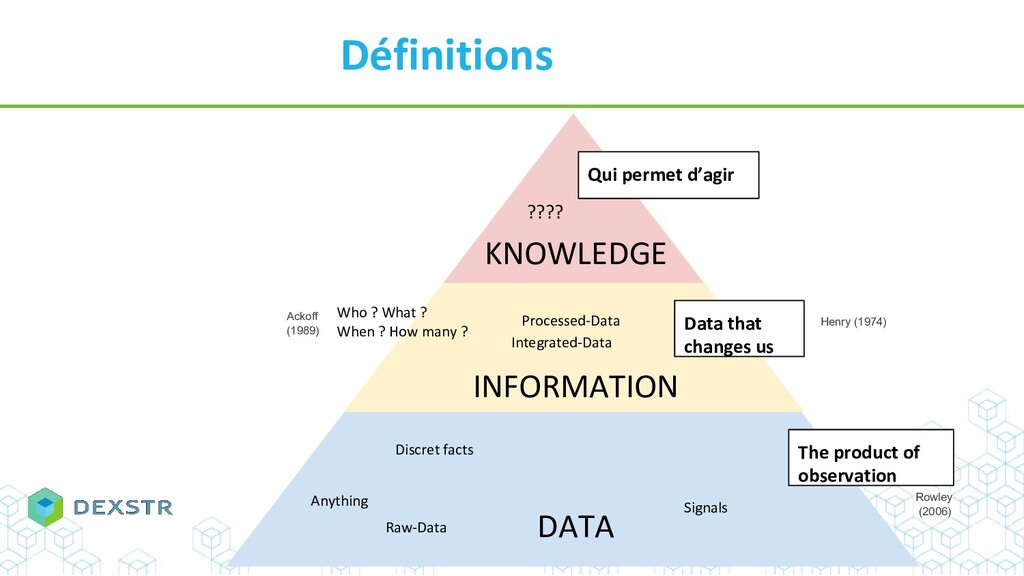
Et puis c'est quoi de la connaissance ? Une (co) relation entre entités ? Une ligne dans une base de données ? Une publi ? Une ontologie ?
A l'heure où les avancées scientifiques ne peuvent se faire qu’en ayant connaissance des faits antérieurs, comment rendre accessible et utilisables le savoir existant ?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}