• SRE learns about the service • Dramatically speeds up ‘newbie to expert’ process • ՃతʹproductΛͤ͞Δ • Exposes details that otherwise would be difficult (or painful) to learn of • ൿͷλϨԽͷഉআ • Creates a shared backlog of improvements • ՝ͷڞ༗
a judgment of past choices • Focus on ‘How’ questions not ‘Why’ questions • Why’s can be seen as judgmental • Every participant must understand this • Managing emotions is critical to a safe discussion environment
a judgment of past choices • Focus on ‘How’ questions not ‘Why’ questions • Why’s can be seen as judgmental • Every participant must understand this • Managing emotions is critical to a safe discussion environment
matter. • 2. Failure is expensive, so it must be prevented. • 3. Capacity planning can make or break you. • 4. Sometimes your destiny is still outside your control. Operational Materialism ӡ༻࣭ओٛʁ
any time, for any reason. • 2. Trying to prevent this server failure is an endless source of suffering for SREs and DBAs alike. • Trying to prevent server failure leads only to suffering • 3. Accepting the impermanence of our servers, we should design systems that are failure-resilient, not failure-resistant. • Cloud-based servers can fail at any time, for any reason. • Automated replacement • Configuration management tools • 4. We can break the cycle of suffering and create a better experience for end users, internal customers, and colleagues Operational Buddhism ͷΑ͏ͳ੩͔ͳ৺ͰݟकΓଓ͚Δʁw
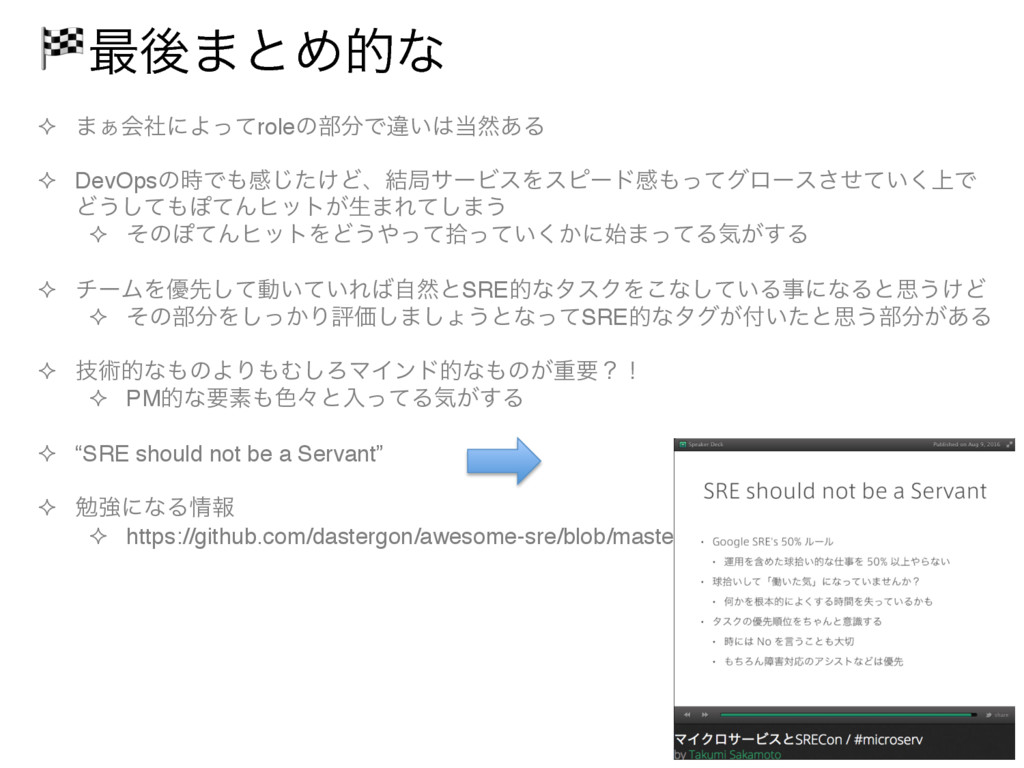
² ͦͷ෦Λ͔ͬ͠ΓධՁ͠·͠ΐ͏ͱͳͬͯSREతͳλά͕͍ͨͱࢥ͏෦͕͋Δ ² ٕज़తͳͷΑΓΉ͠ΖϚΠϯυతͳͷ͕ॏཁʁʂ ² PMతͳཁૉ৭ʑͱೖͬͯΔؾ͕͢Δ ² “SRE should not be a Servant” ² ษڧʹͳΔใ ² https://github.com/dastergon/awesome-sre/blob/master/README.md
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}