Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
⾔言語資源と付き合う
Search
Yuya Unno
June 07, 2012
Technology
21
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
⾔言語資源と付き合う
Yuya Unno
June 07, 2012
More Decks by Yuya Unno
See All by Yuya Unno
深層学習で切り拓くパーソナルロボットの未来 @東京大学 先端技術セミナー 工学最前線
unnonouno
0
29
深層学習時代の自然言語処理ビジネス @DLLAB 言語・音声ナイト
unnonouno
0
53
ベンチャー企業で言葉を扱うロボットの研究開発をする @東京大学 電子情報学特論I
unnonouno
0
50
PFNにおけるセミナー活動 @NLP2018 言語処理研究者・技術者の育成と未来への連携WS
unnonouno
0
20
進化するChainer @JSAI2017
unnonouno
0
30
予測型戦略を知るための機械学習チュートリアル @BigData Conference 2017 Spring
unnonouno
0
29
深層学習フレームワーク Chainerとその進化
unnonouno
0
31
深層学習による機械とのコミュニケーション @DeNA TechCon 2017
unnonouno
0
43
最先端NLP勉強会 “Learning Language Games through Interaction” @第8回最先端NLP勉強会
unnonouno
0
25
Other Decks in Technology
See All in Technology
Genie Ontologyは銀の弾丸かを考える / Is Genie Ontology a Silver Bullet?
nttcom
0
260
“それは自分の仕事じゃない"を 越えて行け
yuukiyo
0
240
大量データに対しても、生成AIを用いてリーズナブルにデータ加工をしたい!Databricksのai_queryについて調べてみた
kamoshika
1
130
Amazon EVS で VCF 9.0 / 9.1 のサポート開始まとめ
mtoyoda
0
290
Keeping applications secure by evolving OAuth 2.0 and OpenID Connect
ahus1
PRO
1
160
Kaggleで成長するために意識したこと
prgckwb
2
330
SRE依存からの脱却 運用を開 発チームへ移す、 フルサイ クル開 発体制の実践
joooee0000
0
2.7k
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
Foxgloveについて 実際にExtensionを開発して公開するまでの話 / About Foxglove: The Story of Developing and Releasing an Extension
ry0_ka
0
220
End-to-Endで考える信頼性 — LINEアプリにおける クライアント開発×SRE連携の実践
maruloop
4
4.2k
CDKで書くECSのベストプラクティス、 改めて考え直す2026 #cdkconf2026
makies
0
120
Control Planeで育てるBtoB SaaSの認証基盤 - SRE NEXT 2026
pokohide
1
2.3k
Featured
See All Featured
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.5k
KATA
mclloyd
PRO
35
15k
How Fast Is Fast Enough? [PerfNow 2025]
tammyeverts
3
650
Max Prin - Stacking Signals: How International SEO Comes Together (And Falls Apart)
techseoconnect
PRO
0
200
What Being in a Rock Band Can Teach Us About Real World SEO
427marketing
0
1k
Imperfection Machines: The Place of Print at Facebook
scottboms
270
14k
Fireside Chat
paigeccino
42
4k
Building the Perfect Custom Keyboard
takai
2
810
Mobile First: as difficult as doing things right
swwweet
225
10k
AI: The stuff that nobody shows you
jnunemaker
PRO
8
830
Marketing to machines
jonoalderson
1
5.6k
Building Flexible Design Systems
yeseniaperezcruz
330
40k
Transcript
⾔言語資源と付き合う 2012/06/07 @ PFIセミナー 株式会社Preferred Infrastructure 海野 裕也
⾃自⼰己紹介 l 海野 裕也 l @unnonouno l unno/no/uno l 研究開発部⾨門 l
Jubatusチームリーダー l 専⾨門 l ⾃自然⾔言語処理理 l 統語解析、⽂文圧縮、同義語抽出+クエリ拡張、⼊入⼒力力⽀支援 l テキストマイニング l ⾔言語横断テキストマイニング、曖昧パターンマッチ 2
今⽇日はゆるふわです 3
今⽇日のゴール l ⾔言語処理理における⾔言語資源の重要性を認識識する l ⾔言語資源に絡む⽤用語を知る l ⾔言語資源に関連する研究の紹介 l これから⾔言語資源とどう付き合うべきか 4
アジェンダ 1. ⾔言語処理理と⾔言語資源 2. ⾔言語資源とは何か 3. ⾔言語資源の作成 4. ⾔言語資源と付き合う 5
⾔言語処理理と⾔言語資源 6
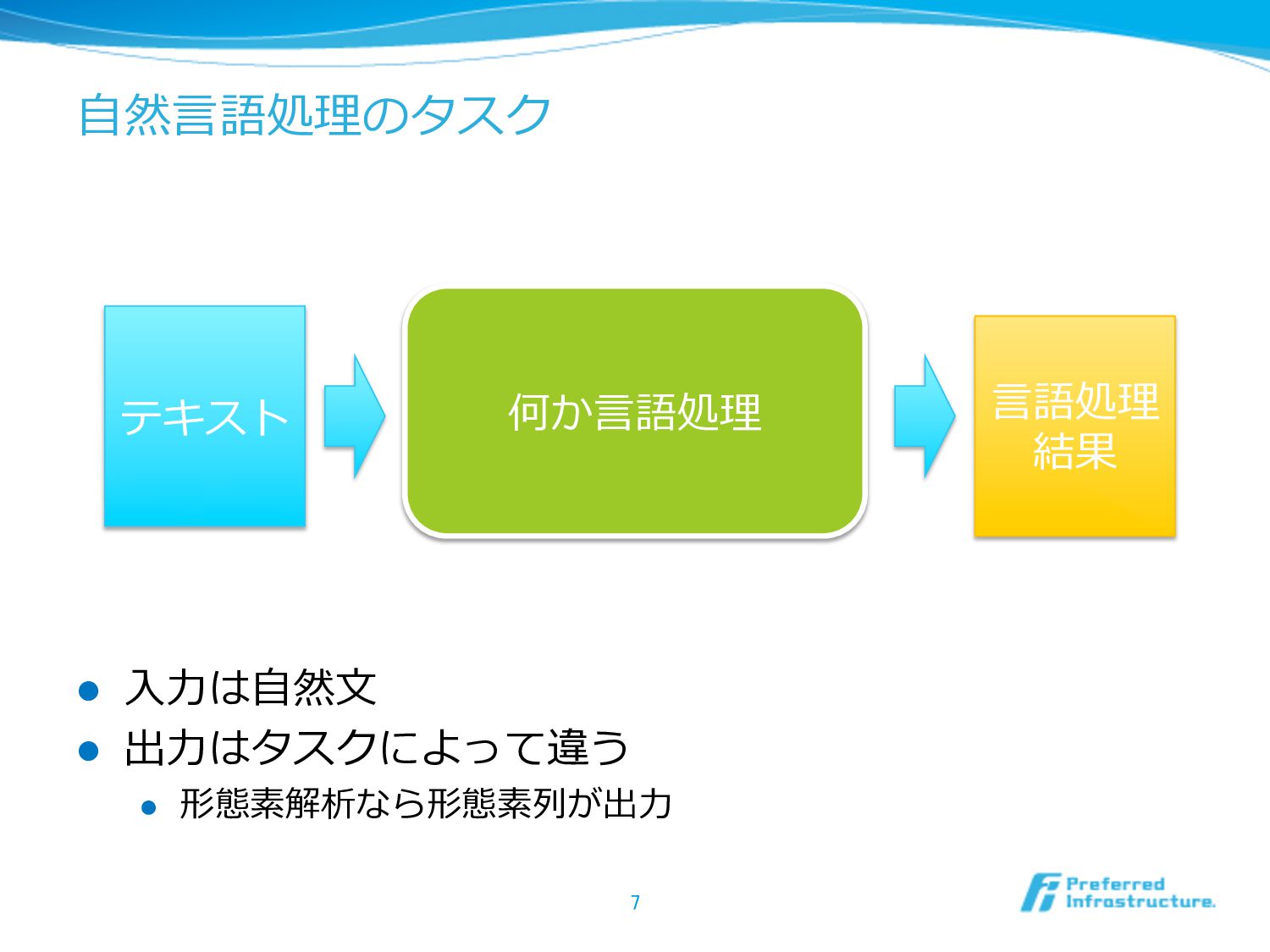
⾃自然⾔言語処理理のタスク l ⼊入⼒力力は⾃自然⽂文 l 出⼒力力はタスクによって違う l 形態素解析なら形態素列列が出⼒力力 7 何か⾔言語処理理 テキスト
⾔言語処理理 結果
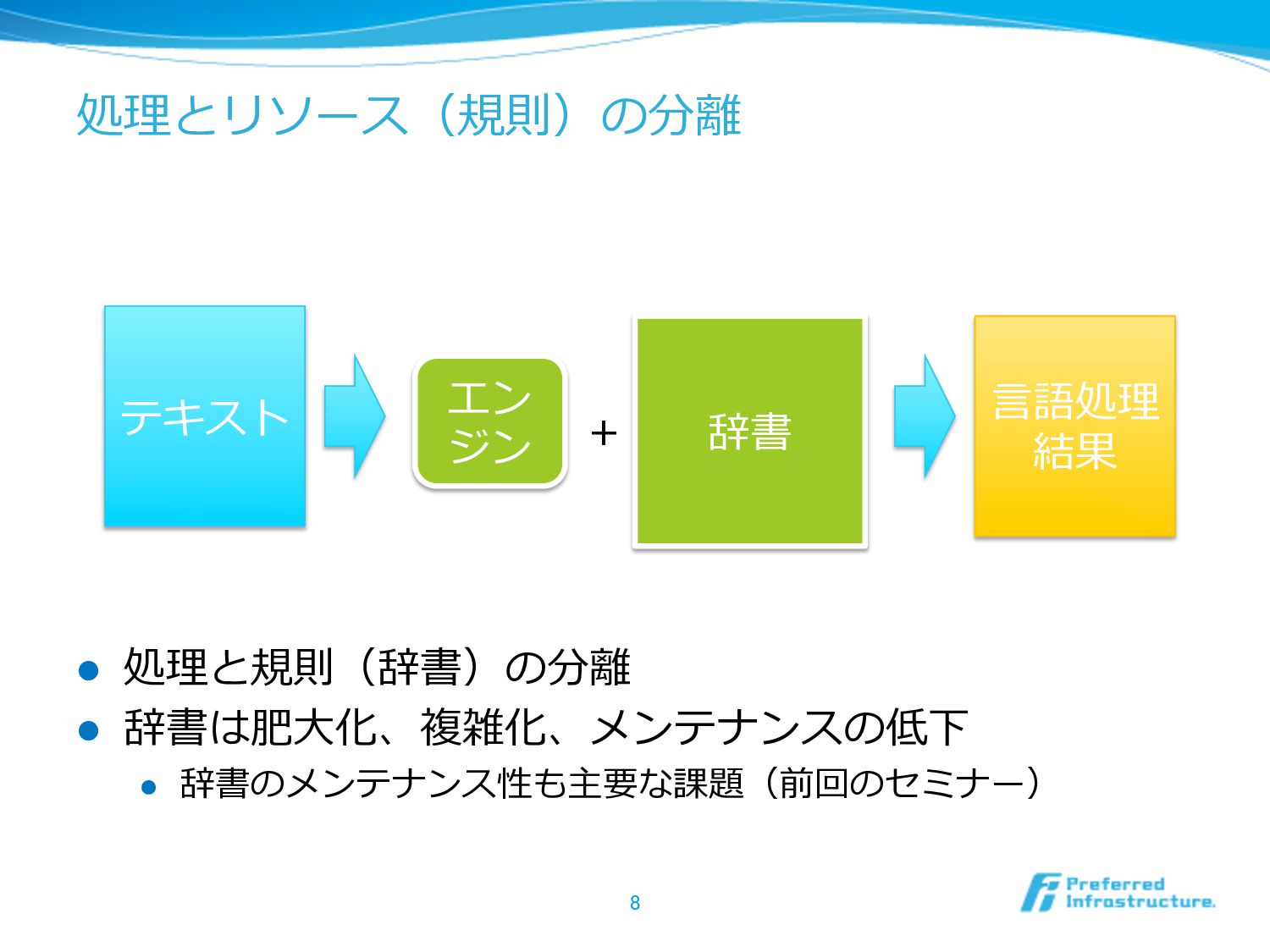
処理理とリソース(規則)の分離離 l 処理理と規則(辞書)の分離離 l 辞書は肥⼤大化、複雑化、メンテナンスの低下 l 辞書のメンテナンス性も主要な課題(前回のセミナー) 8 エン ジン
テキスト ⾔言語処理理 結果 辞書 +
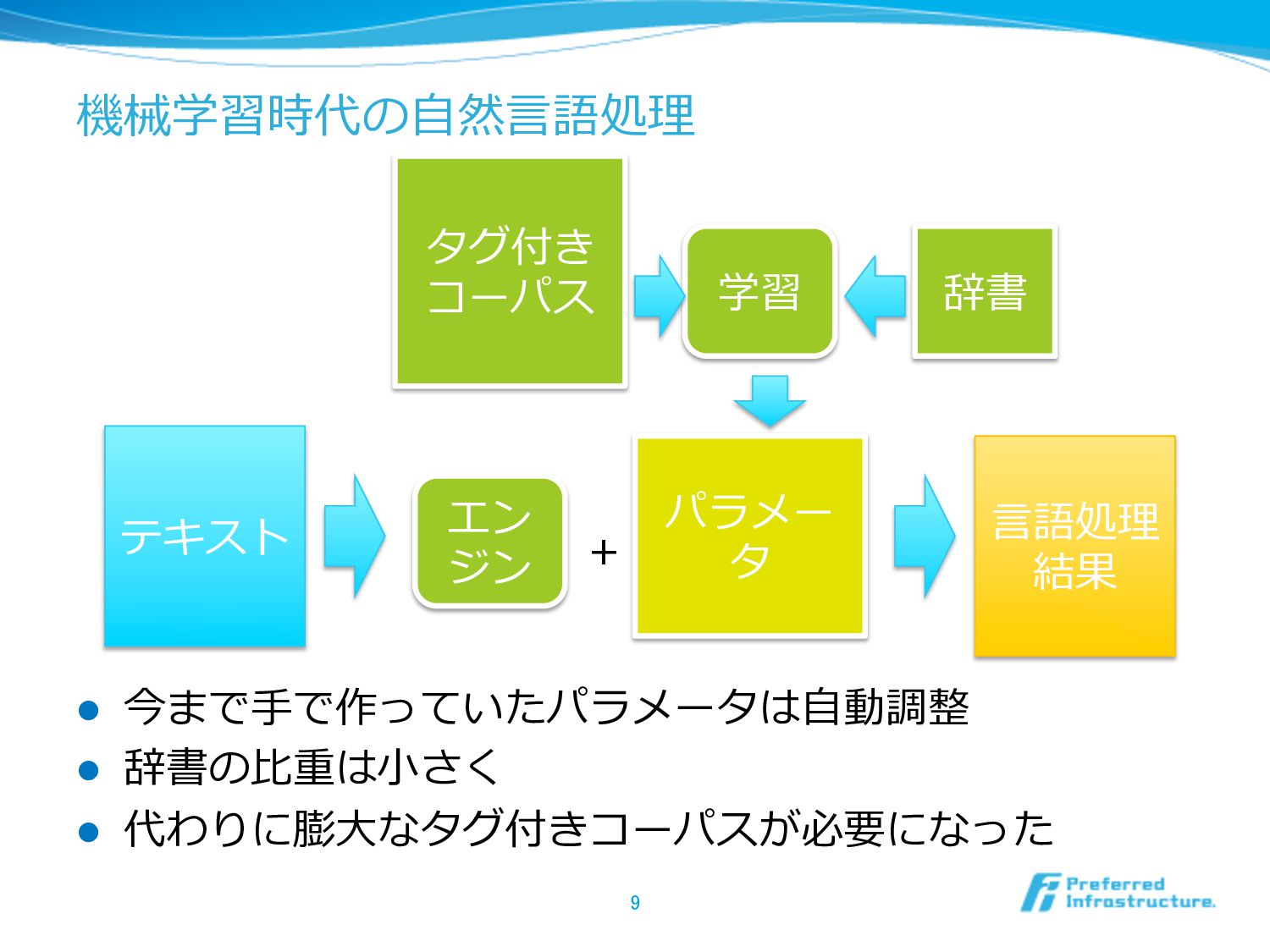
機械学習時代の⾃自然⾔言語処理理 l 今まで⼿手で作っていたパラメータは⾃自動調整 l 辞書の⽐比重は⼩小さく l 代わりに膨⼤大なタグ付きコーパスが必要になった 9 エン ジン
テキスト ⾔言語処理理 結果 パラメー タ + タグ付き コーパス 学習 辞書
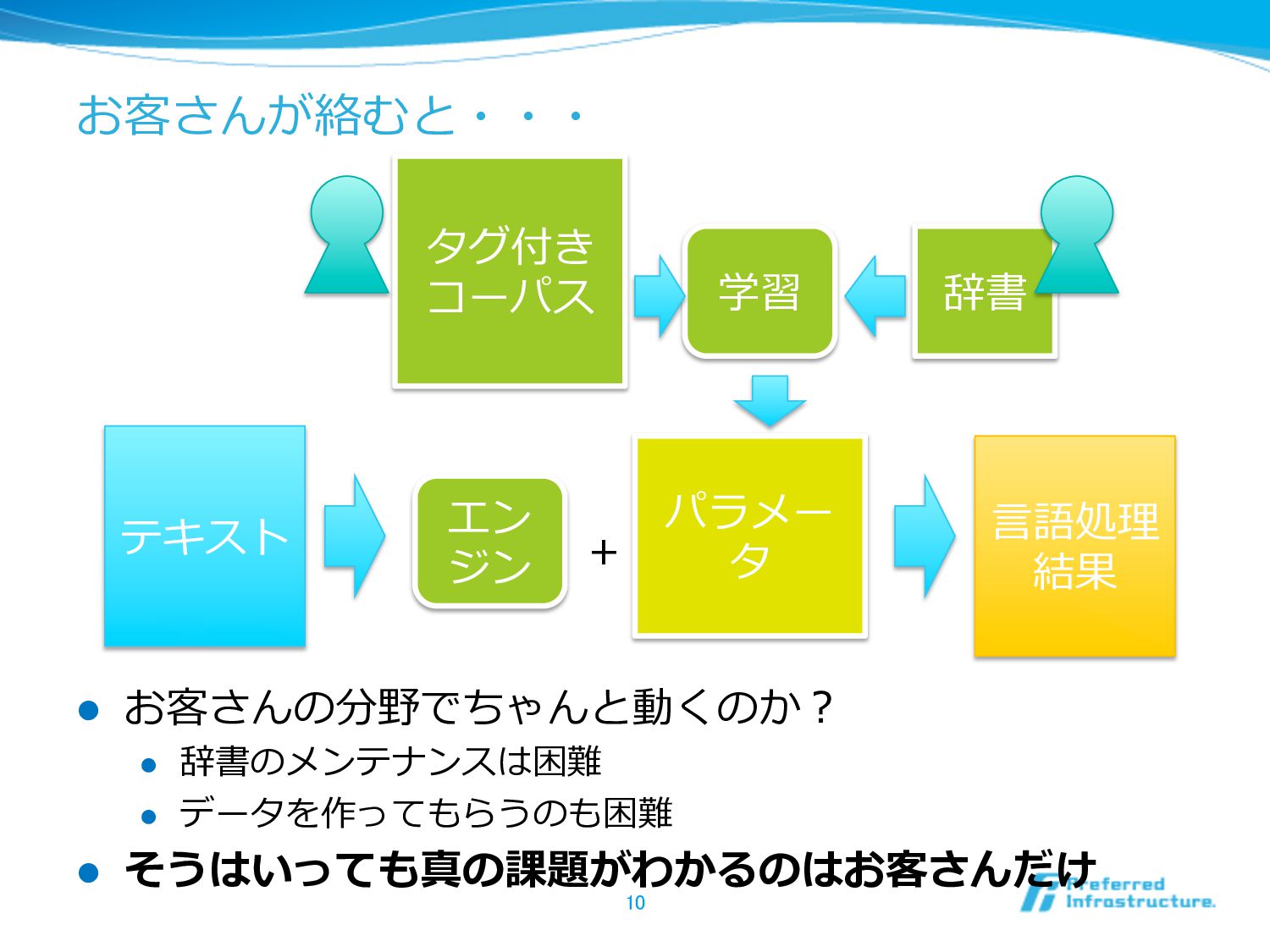
お客さんが絡むと・・・ l お客さんの分野でちゃんと動くのか? l 辞書のメンテナンスは困難 l データを作ってもらうのも困難 l そうはいっても真の課題がわかるのはお客さんだけ 10
エン ジン テキスト ⾔言語処理理 結果 パラメー タ + タグ付き コーパス 学習 辞書
課題は増えていく l 辞書のメンテナンス l 「辞書に追加したのに⾒見見つけてくれないよ!」 l 「変な単語が出てきちゃうよ!」 l コーパス作成 l
「データは何件作ればいいの?」 l 「データ作るの⼤大変なんだけど」 11 技術で解決したい!
⼿手法よりもデータが重要 l タスクの複雑さは⼿手法よりもデータに依存 l データに依存して難易易度度が変わる l 形態素解析しやすい⽂文書、しにくい⽂文書、しやすい⾔言語、しに くい⾔言語 l 精度度を担っているのはほとんどが⾔言語資源
l 良良い規則を作る l 良良い辞書を作る l 良良い正解データを作る 12
⾔言語資源とは何か 13
⾔言語資源とは何か ⼤大雑把には2種類に⼤大別される l コーパス l 辞書 14 言語資源(げんごしげん)とは、自然言語を研究するさい に用いられる資源のこと。 辞書やコーパス、シソーラス、
インフォーマントなどがこれにあたる。 (Wikipedia)
「コーパス」とは? l 基本的には実際に使われた⽂文をたくさん集めたデータ l ⾃自然⾔言語処理理以外でも使われる l コーパス⾔言語学 l 構造化した情報が付与されてない場合もある 15
コーパス(corpus)とは、言語学において、自然言語 処理の研究に用いるため、自然言語の文章を構造化 し大規模に集積したもの。構造化では言語的な情報 (品詞、統語構造など)が付与される。コンピュータ利 用が進み、電子化データとなった。 (Wikipedia)
アノテーション(注釈)とは? l テキストデータに対して付与された正解情報 l 固有表現抽出なら正解タグ l 単語分割なら分割ラベル l 統語解析なら句句構造や依存構造 l
正解付与する⼈人のことをアノテーターと呼ぶ 16 ChaKi
注釈の整合性とタスクの難易易度度 l ⼈人間が注釈をつけても曖昧なことがある l 例例:係り受け解析の⼈人間同⼠士の⼀一致率率率は90%くらい l 数値上これ以上の精度度はそもそも不不可能 l AさんがOKと⾔言っても、BさんはNOと⾔言う l
⼀一致率率率がそもそも70%くらいにしかならないタスクもあ る 17
「κはいくつですか?」 l Inter-annotator agreement l アノテーター間でどれくらい同意が取れるか l ⼀一般的にはκ統計量量を⽤用いる l Pr(a):
評価が⼀一致する確率率率 l Pr(e): 独⽴立立だと仮定した場合に⼀一致する確率率率 18
注釈付きコーパスあれこれ l ツリーバンク l 統語構造のアノテーションがついたコーパス l 統語構造は⽊木構造で表現されることが多いため、こう呼ばれる l 対訳コーパス l
翻訳関係にある⽂文対を集めたコーパス 19
「辞書」とは? l 特定の⾔言語単位に対する⾔言語情報資源 l 例例:⾳音素、形態素、単語、意味役割… l データによって情報の粒粒度度は様々 l 単なる単語集合 l
品詞情報 l 各種情報 l いわゆる「辞典」のことではない l お客様先で使うときは注意 l NLPの⽂文脈だと機械が利利⽤用するためのリソースの意味 20
辞書あれこれ l 単語辞書 l 何かしらの「単語」の⼀一覧 l その他の情報(品詞、読み、活⽤用など)が付与されることもあ る l シソーラス
l 類語や上位語・下位語関係など、語と語の意味の粒粒度度の関係が 付与された辞書 l 紙に書かれたシソーラスもあります l 訳語辞書 l 訳語関係にある単語対の⼀一覧 21
コーパスと辞書の違いは? l コーパスは「⽂文書の事例例」ベース、辞書は「単語や複合 語などの⾔言語単位」ベース l ・・・と書いてみたが、たぶん割りと曖昧 22
メジャーな⾔言語資源を幾つか・・・ l コーパス l 京都⼤大学テキストコーパス l 現代⽇日本語書き⾔言葉葉均衡コーパス l EDRコーパス l
ATR⾳音素バランス503⽂文 l Penn Treebank l 辞書 l IPA辞書 l ⽇日本語語彙体系 l EDR辞書 l WordNet 23
京都⼤大学テキストコーパス l 京⼤大⿊黒橋研究室 l 毎⽇日新聞1995年年データに対して、⼈人⼿手でタグ付け l 形態素解析、係り受け解析、照応解析などの情報 24 * 0
26D 村山 むらやま * 名詞 人名 * * 富市 とみいち * 名詞 人名 * * 首相 しゅしょう * 名詞 普通名詞 * * は は * 助詞 副助詞 * * * 1 2D 年頭 ねんとう * 名詞 普通名詞 * * に に * 助詞 格助詞 * * * 2 6D あたり あたり あたる 動詞 * 子音動詞ラ行 基本連用形
現代⽇日本語書き⾔言葉葉均衡コーパス (BCCWJ) l 国⽴立立国語研究所 l 世の中に流流通する様々な分野の⽂文書から、均等にサンプ リングしたようなコーパスを⽬目指している 25 <corpus lang="japanese">
<article articleID="OC14_03054m" genre="OC"> <sentence> <mor pos="名詞-普通名詞-一般" rd="チエ">知恵</mor> <mor pos="名詞-普通名詞-一般" rd="ブクロ">袋</mor> <mor pos="助詞-格助詞" rd="ニ">に</mor> <mor pos="動詞-非自立可能" rd="シ" bfm="スル">し</mor> <mor pos="助動詞" rd="タ" bfm="タ">た</mor> <mor pos="名詞-普通名詞-サ変可能" rd="シツモン">質問</mor> <mor pos="助詞-格助詞" rd="デ">で</mor>
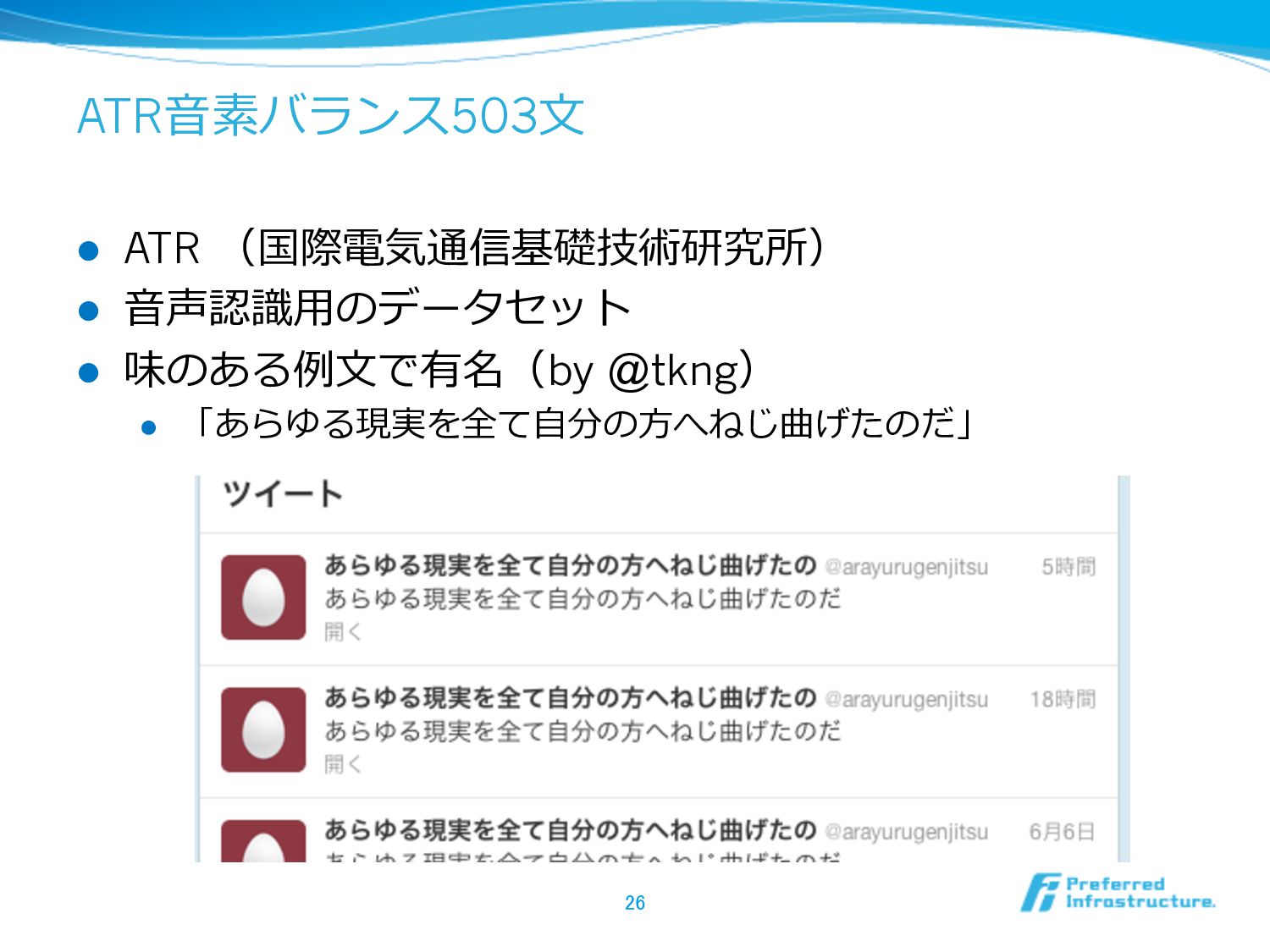
ATR⾳音素バランス503⽂文 l ATR (国際電気通信基礎技術研究所) l ⾳音声認識識⽤用のデータセット l 味のある例例⽂文で有名(by @tkng) l
「あらゆる現実を全て⾃自分の⽅方へねじ曲げたのだ」 26
Penn Treebank l ペンシルバニア⼤大学 l Wall Street JournalやBrown Corpusに品詞と統語構造 をタグ付け
l 最も有名なタグ付きコーパスの1つ 27 ( (S (NP-SBJ (NP (NNP Pierre) (NNP Vinken) ) (, ,) (ADJP (NP (CD 61) (NNS years) ) (JJ old) ) (, ,) ) (VP (MD will) …
Google N-gram コーパス l Google l ウェブ上でクロールしたデータに単語1~7グラムの中で、 頻度度の⾼高いものとその頻度度をまとめたデータ 28 の
呼び声 王宮 の お触れ × 2 30 の 呼び声 王宮 の お触れ × 3 51 の 呼び声 砂塵 の 大 竜巻 × 28 の 呼び声 破 界 伝 ( 5 43 の 呼び声 神 の 宣告 × 3 25 の 呼び声 第 壱 章 チェーン ・ 20 の 呼び声 罠 【 永続 】 自分 22 の 呼び声 聖なる バリア - ミラーフォース - 194
タグ付きコーパスの探し⽅方 l 紹介しているページ l NAIST松本研のページ l ⾔言語資源を管理理しているサイト l Linguistic Data
Consortium (LDC) l ⾔言語資源協会 (GSK) l 個別に⼊入⼿手 l 個⼈人が作成している場合がある 29
⾔言語資源の作成 30
⾔言語資源を作るのは⼤大変! l 統制のとれた⾔言語資源を作るのは⼤大変 l 統括マネージャー+アノテーター複数⼈人 l 同⼀一データに対して2⼈人以上のアノテーション l 定例例ミーティング、問題の洗い出し l
⼀一般的に年年単位のプロジェクトになる l 膨⼤大な⼈人件費 31 しかし,大規模コーパスは通常,膨大な試行錯誤の累積 として成立している。当初に定めた仕様にしたがって実装 を進めるなかで多くの問題が発見され,それらに対処す る過程で,仕様が精密化されてゆくが,ときとして仕様に 矛盾が発見されることもあり,その結果,過去の作業に遡 及した修正作業を行わなければならない事態なども発生 する。 「日本語話し言葉コーパスの構築法」より
コーパス作成の例例 l GENIA corpus l @東⼤大辻井研 l 分⼦子⽣生物学論論⽂文中に記載される、タンパク質の反応に関する情 報抽出のアノテーションつきコーパス l
BCCWJ l @国⽴立立国語研究所 l 8つのグループ、5年年間(2006~2010年年) l EDRコーパス l @NICT l 1辞書、1ライセンス120万円 32
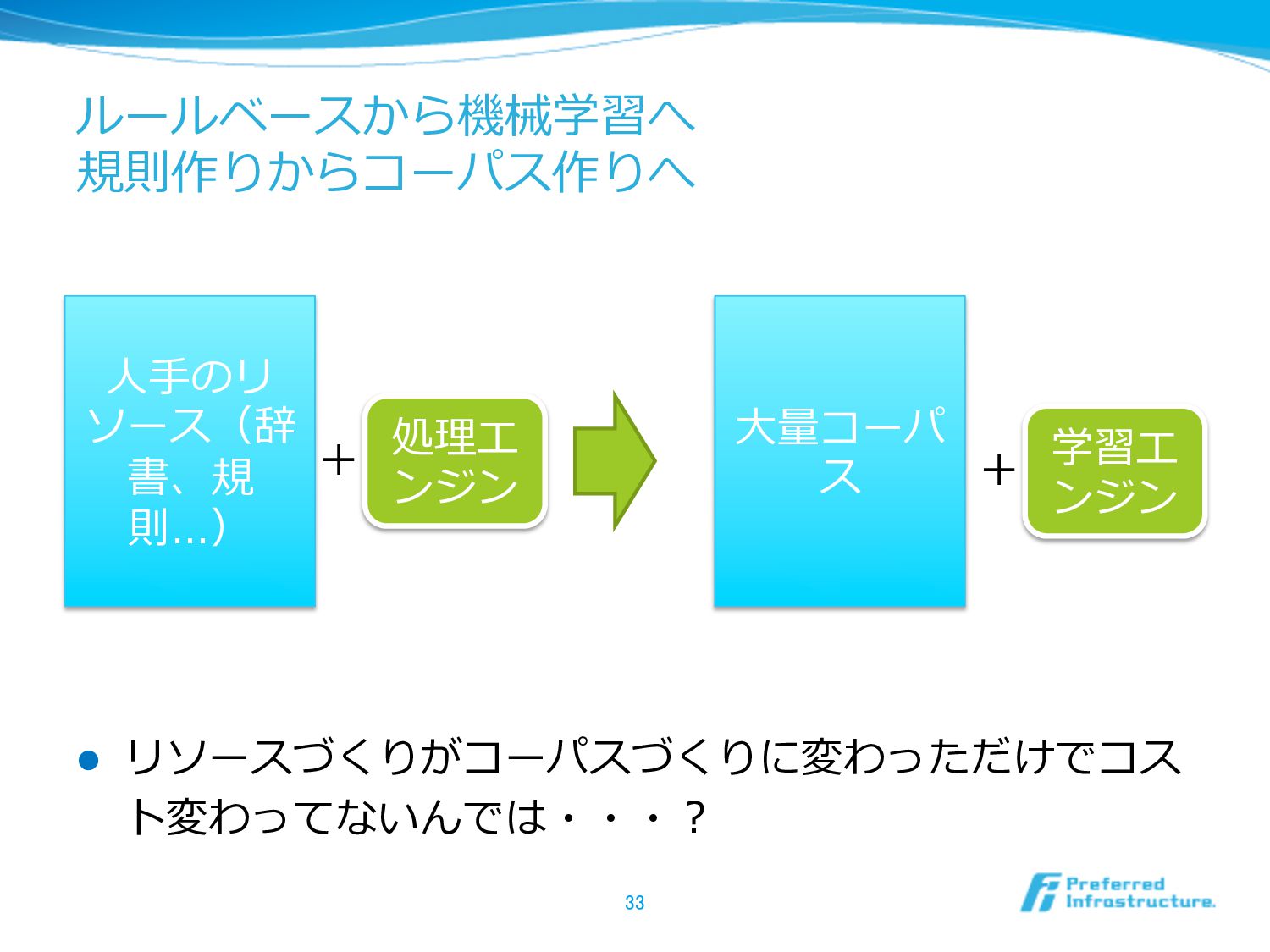
ルールベースから機械学習へ 規則作りからコーパス作りへ l リソースづくりがコーパスづくりに変わっただけでコス ト変わってないんでは・・・? 33 ⼈人⼿手のリ ソース(辞 書、規 則…)
処理理エ ンジン ⼤大量量コーパ ス 学習エ ンジン + +
コーパスと⾃自然⾔言語処理理・機械学習関連での研究 より効率率率よく性能を上げることが研究テーマになる 1. タグ無しコーパスの積極的な利利⽤用 l 半教師有り学習 l 転移学習 2. コーパス作成の効率率率化
l 能動学習 3. ⾮非専⾨門家の利利⽤用 l Learning from Crowds 4. コーパス作成環境の整備 34
1. タグ無しコーパスの利利⽤用 l 半教師有り学習 l ラベル付きデータ(タグ付きコーパス)と⼤大量量のラベルなし データ(⽣生コーパス)から学習 l ラベル付きデータのみの時よりも効率率率が良良い l
転移学習 l 学習データと適応先のデータで分野が異異なるという問題設定 l 学習データのみを使うよりも、適応先ドメインのタグ無しデー タを使ったほうが効率率率が良良い 35
2. コーパス作成の効率率率化 l 能動学習 l 最も効率率率良良く学習できる正解ラベル(アノテーション)から順 番につけていく l 単純にランダムな順序で学習するよりも効率率率が良良い l
⼤大岩さんのPFIセミナーを参照 36
3. ⾮非専⾨門家の利利⽤用 l Learning From Crowds l ノイズがある、アノテーターに能⼒力力差があるという前提での機 械学習の⽅方法論論 l
Amazon Mechanical Turkを利利⽤用した研究などが近年年盛ん 37
4. コーパス作成環境の整備 l アノテーション⾃自体の研究 l アノテーションのツール l 実際にコーパスを作ったときの報告 l テキストアノテーションワークショップ
l http://nlp.nii.ac.jp/tawc/ l アノテーションの設計、⽅方法論論、⽀支援等に関する会議 l 2012/8/6, 7 @NII 38
⾔言語資源とどう付き合うか 39
ある⽇日ルールが適⽤用できなくなる瞬間 l 「NMB à ミネベア」だと思ってたら、ある⽇日から NMB48が・・・ l 「スイカ à ⻄西⽠瓜」だと思ってたら、ある⽇日からSuica
が・・・ l 機械学習 or ルールベースとは独⽴立立の問題 l モデルが適⽤用できなくなる l ルールが適⽤用できなくなる 40
同じ問題は機械学習でも起こりうる l 未知の領領域のデータに対してどう振る舞うのか? 41
分類基準が変えたら何が起こるのか? l 誤分類が改善される l 新しいルールの追加 l ルールの修正 l 再学習を⾛走らせる l
今までうまく動いていたデータは? l 影響がないとは思えない l それは充分に検証しましたか? l そんなこといってもイタチごっこじゃないか l そうですね l だから何もしなくていいとは思えない 42
疑⼼心暗⻤⿁鬼 l いつか破綻するかもしれない l 実はもう破綻しているのかもしれない l ⾒見見つかる間違い、増える問い合わせ l 説明できないロジック・・・ 43
全てを疑ったとき、信じられるのは⽤用例例だけ l ⽤用例例に対する判断は変わらない l 「NMBのキーボードを買った」がNMB48になることはない l 「スイカ割りをした」がSuicaになることはない l 信じられるものだけを信じる l
⽤用例例は単体テストのようなもの l ロジック(ルール)だけあってテスト(事例例)のないプログラ ムを信⽤用できますか? l テストで全てを⾔言えるわけではないが、何もないより説得⼒力力が ある 44 用例のよさは,それが実際に人間によって使われた表現で あるという意味で,健全でかつ安定した情報であるという点 にあるだろう. (自然言語処理, 岩波より)
お客さんが報告できるのは⽤用例例だけ l どの例例をどう間違えたか l 「NMB48がたくさん引っかかるんだけど!」 l 内部がどうなっているかはわからない l 内部の詳細なロジックを理理解して使ってもらうのは厳しい l
どの例例をどう間違えたかならわかるはず(多分) 45
基準が変わることとは別 問題⾃自体が変わった場合とは別、問題は切切り分ける l 本当に変わった l 「ホークス à ダイエー」から「ホークス à ソフトバンク」
l 粒粒度度が変わった l 「iPhone à 携帯電話」から「iPhone à スマートフォン」 l 気分が変わった l ⾟辛い・・・ l Inter-annotator agreement 46
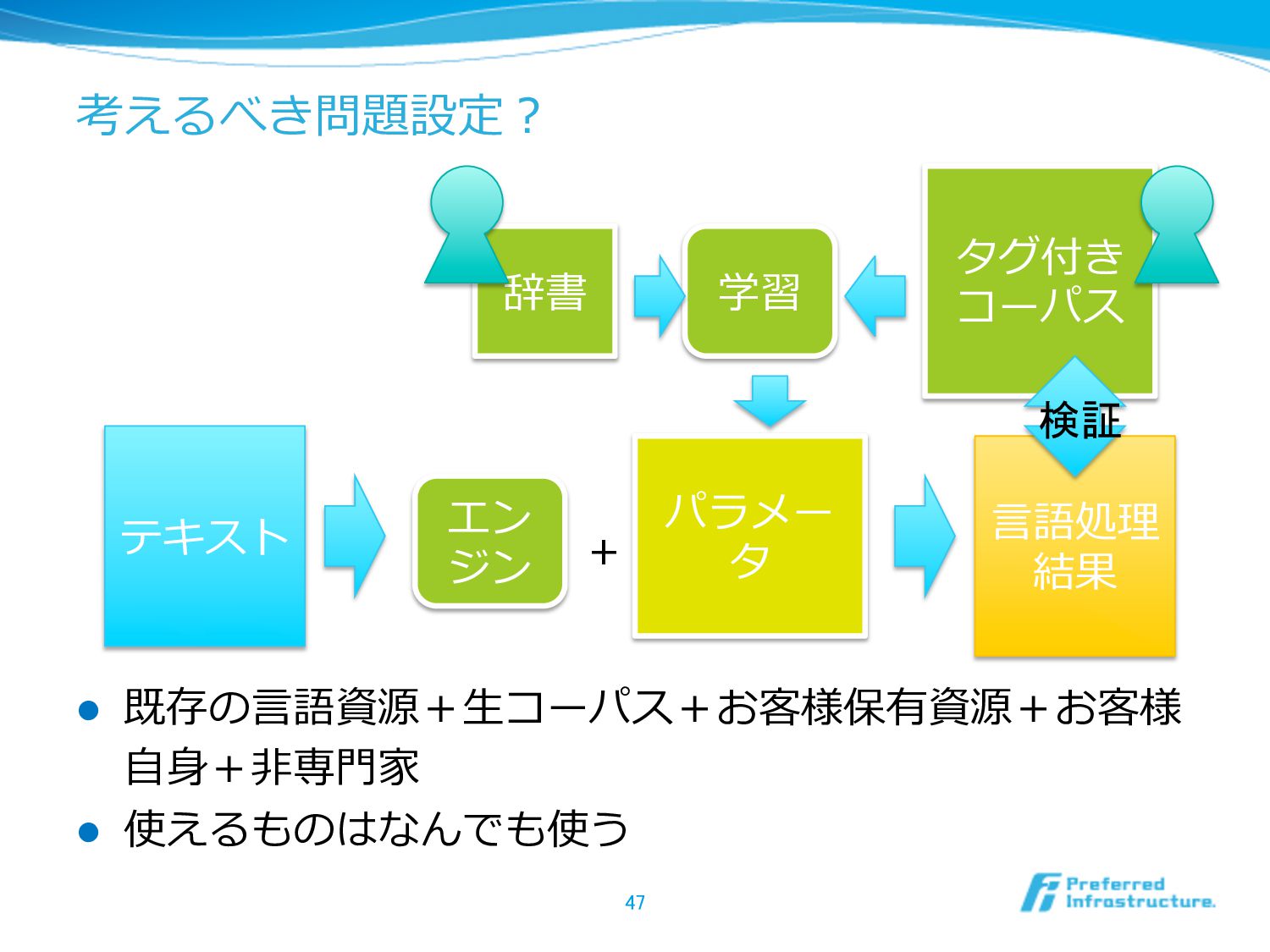
考えるべき問題設定? l 既存の⾔言語資源+⽣生コーパス+お客様保有資源+お客様 ⾃自⾝身+⾮非専⾨門家 l 使えるものはなんでも使う 47 エン ジン テキスト
⾔言語処理理 結果 パラメー タ + タグ付き コーパス 学習 辞書 検証
まとめ l ⾔言語処理理の振る舞いを決めるうえで⾔言語資源は重要 l ⼤大別するとコーパスと辞書がある l ⾔言語資源を作るのは⼤大変 l 数億という単位でお⾦金金がかかっている・・・ l
⽤用例例をベースとして考える l 規則はいつか破綻する可能性がある l ⽤用例例をためる、管理理する、全体の仕組みを考える 48
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}