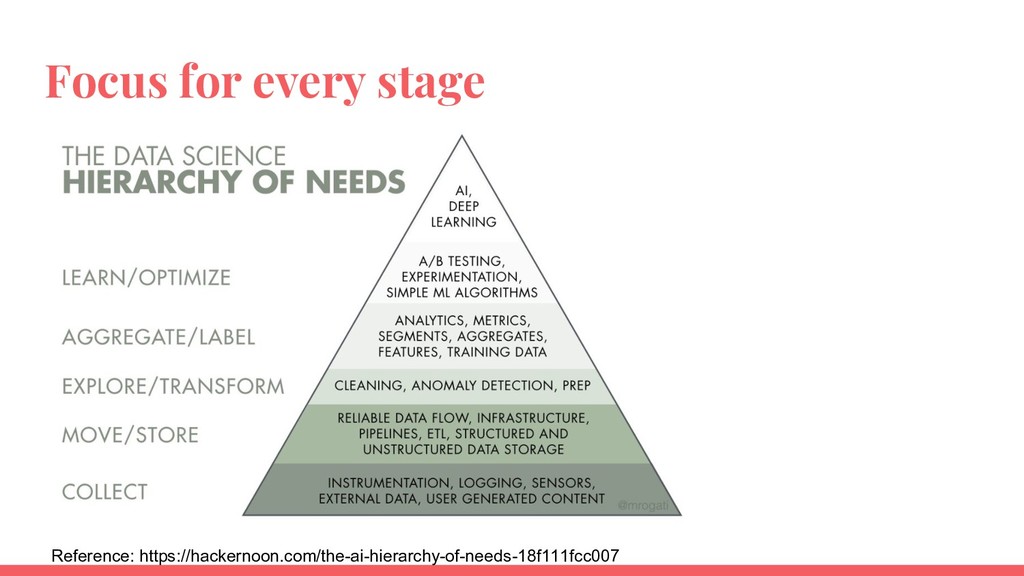
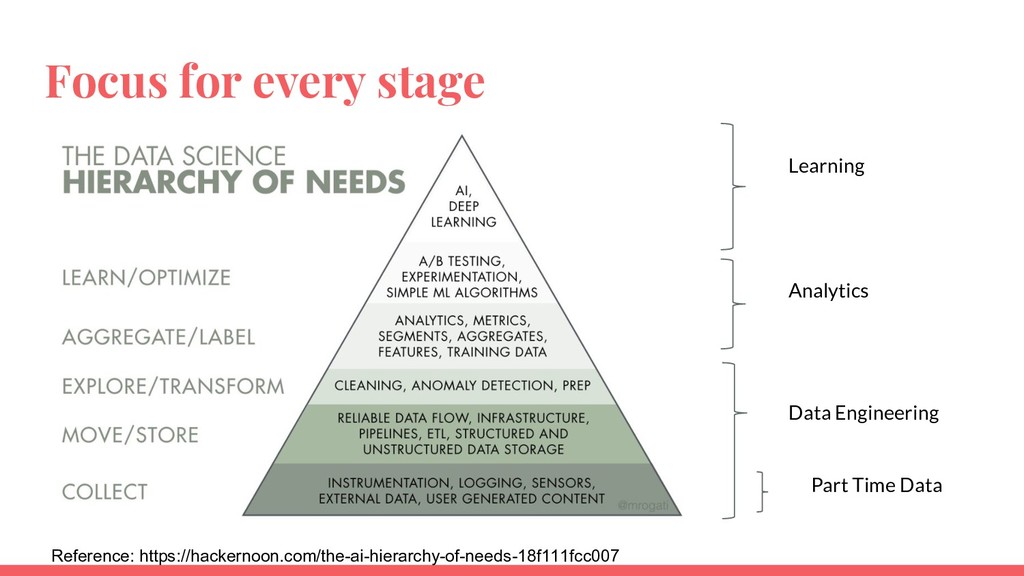
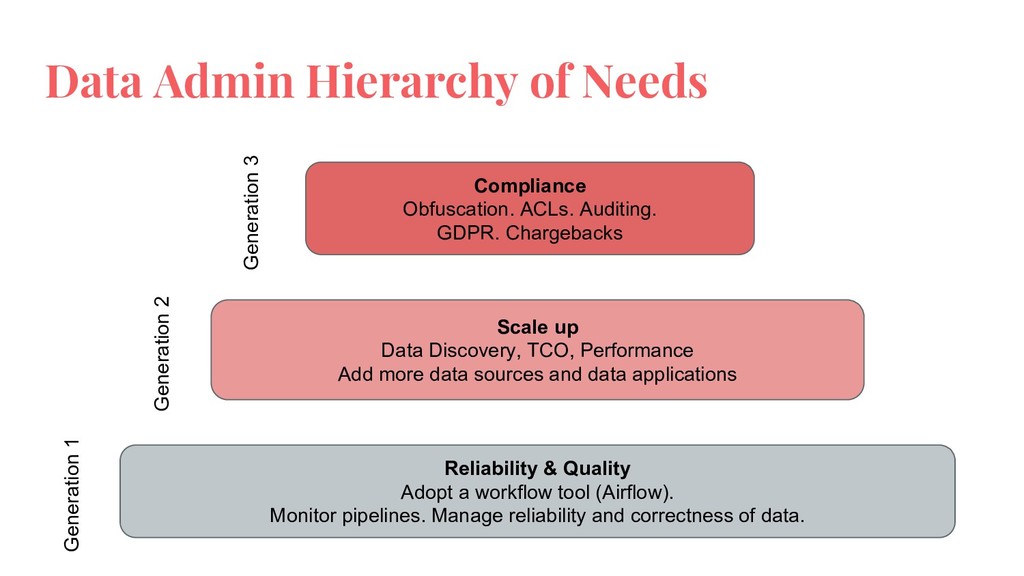
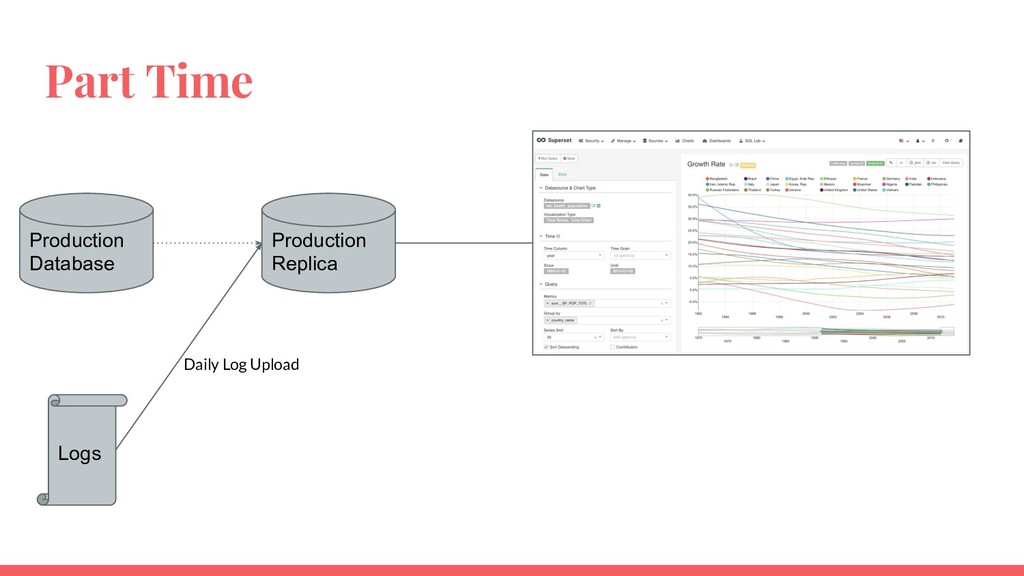
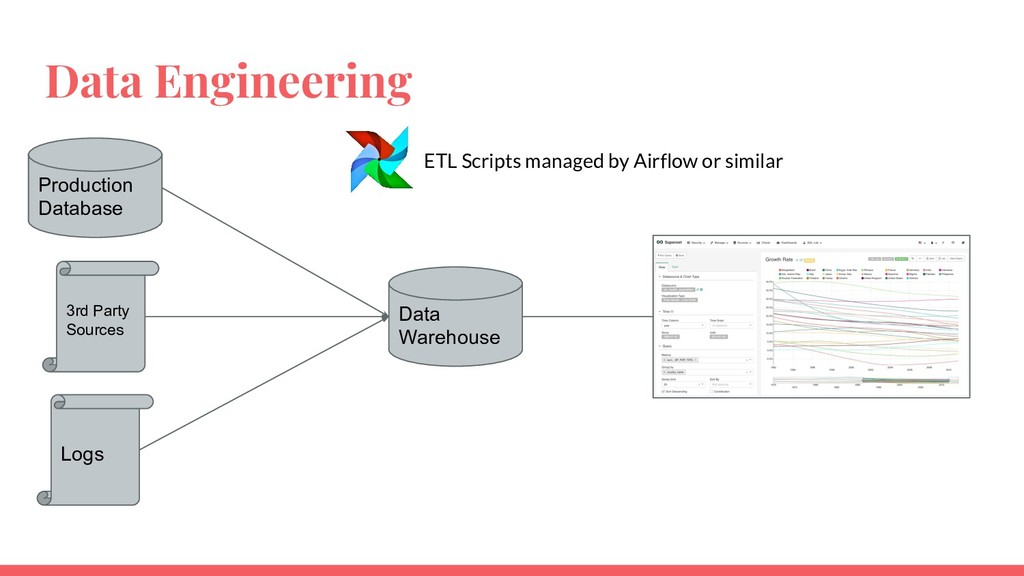
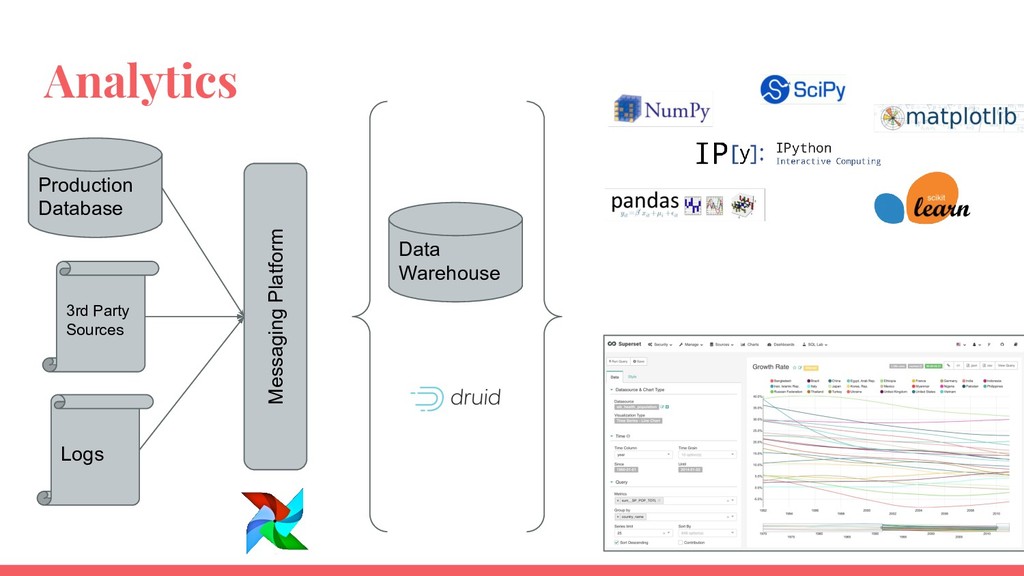
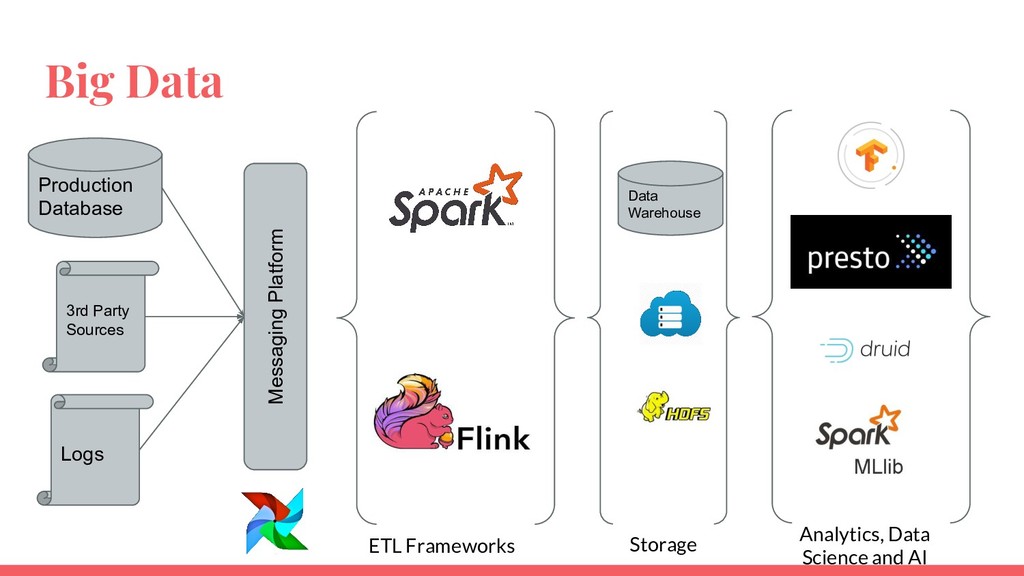
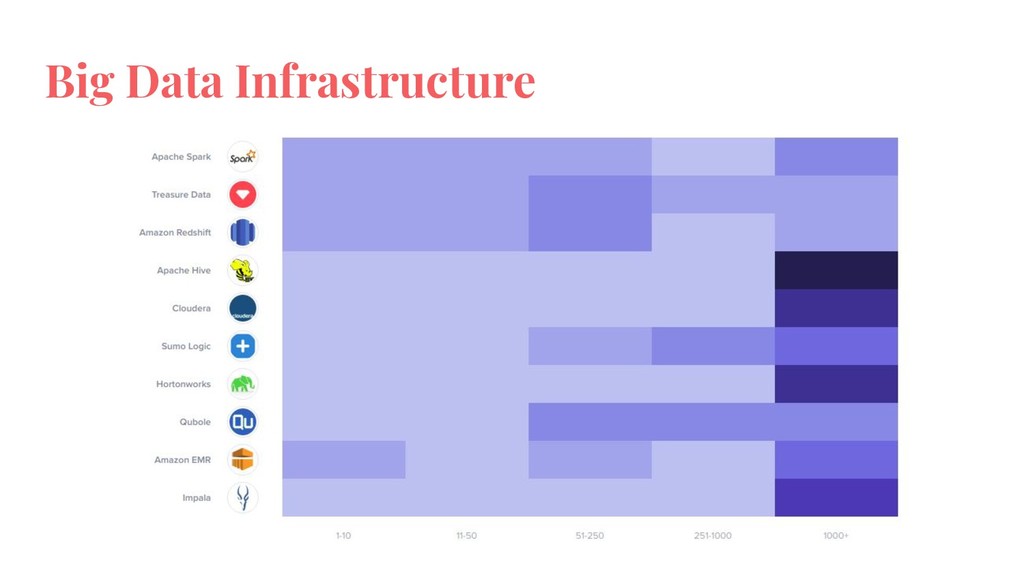
Requirements of a data platform depends on data volume and use cases. An effective data platform for a startup, mid-sized company and a large enterprise is different from each other. This talk will introduce a framework to understand the requirements of a data platform. Then the talk will explore successful architectures segmented by start ups, mid-size companies and large enterprises.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}