in the field of computer science that often uses statistical techniques to give computers the ability to “learn” (i.e., progressively improve performance on a specific task) with data, without being explicitly programmed. My interpretation: … a number of algorithms, which can be used to automatize and optimize mundane tasks, make predictions and find deviations in big data. These algorithms can “learn” and make their own “decisions”.
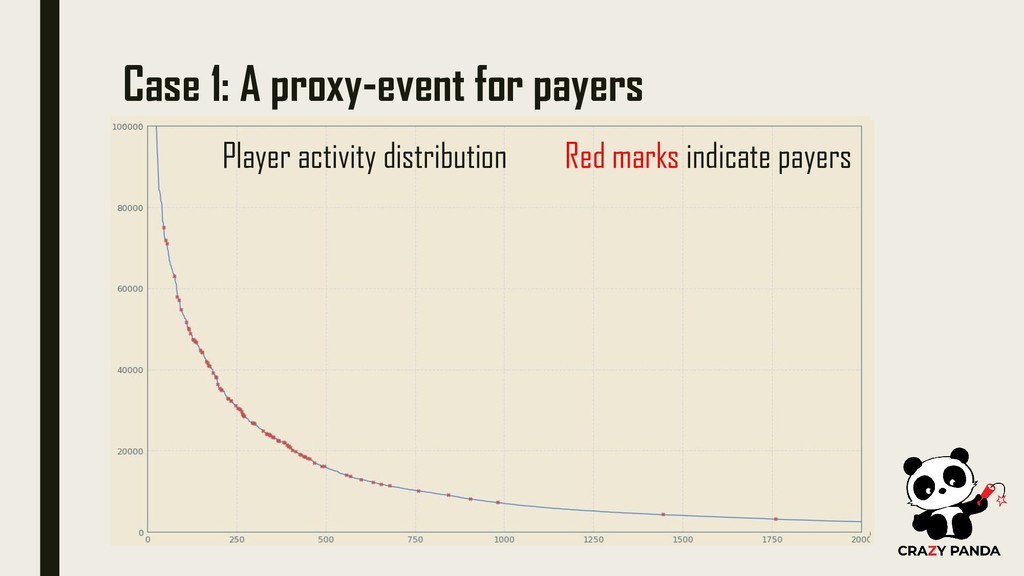
Event optimization for Advertising Networks: • Reducing amount of time taking for event to appear • Increasing number of events • Maintaining high value for these events • Estimating traffic value early • Possible fraud detection Goal: To detect users likely to be payers as early as possible
was actually correct? What proportion of actual positives was identified correctly? 1. Precision vs Recall 2. Be prepared to manage missing Data Hints:
events on Day 1 after registration from 1% to 11% • Substantial reduction of the optimization window for advertising campaigns (from 7 days to 1 day) • Lower budget needed for channel value estimation Results and achievements
a user is as early as possible Can be useful for: • LTV prediction • Estimating traffic value early on • Possible fraud detection • Increasing number of events for early optimization
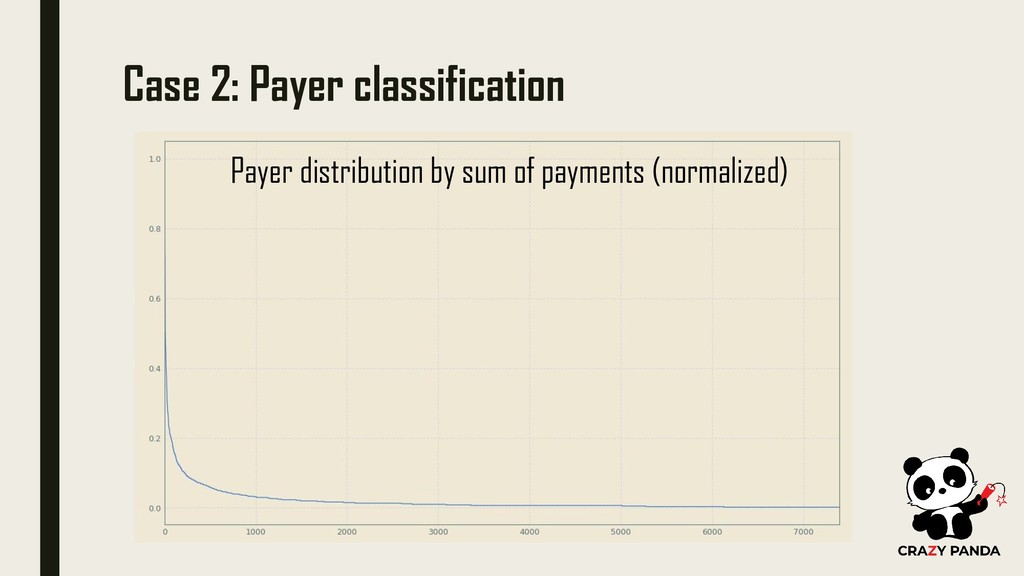
have discovered so much use of this, which this margin is too narrow to contain Goal: Estimate LTV as early as possible and increase its accuracy with each day of life for that cohort
we already know how to classify them early. 2. If we know how many different payers currently make up the cohort, we can use historical distribution or even make another machine learning model to predict how many more and what type of payers will be converted. 3. If we don’t have enough Data to fuel LTV prediction for 100 days, we can always go for 30 days and then use the classic mathematical model to extrapolate effect (for example)
Start with easy objectives • Measure your errors, some can, in fact, be positive • Test your models not only on typical, but also on abnormal data • Know your limits (mostly having enough data)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Questions Ivan Kozyev [email protected] Telegram: @IvanKozyev](https://files.speakerdeck.com/presentations/782db59466584068b08f669864909fd3/slide_16.jpg){kind=link}