2000 • Exchange Student in Malaysia • 2002-2009 • CLARAONLINE, INC. • ICT Hosting Company, nowadays called Cloud system supplier • 2009-2015 • Institute of Innovation Research, HITOTSUBASHI UNIVERSITY • 2015-2017 • Science for RE-Designing Science, Technology and Innovation Policy Center, National Graduate Institute for Policy Studies (GRIPS) / NISTEP / Hitotsubashi UNIVERSITY/MANAGEMENT INNOVATION CENTER • 2018-2019 • EHESS Paris – CEAFJP/Michelin Research Fellow • OECD Expert Advisory Group: Digital Science and Innovation Policy and Governance (DSIP) and STI Policy Monitoring and Analysis (REITER) project • 2019- • TDB Center for Advanced Empirical Research on Enterprise and Economy, Faculty of Economics, Hitotsubashi University
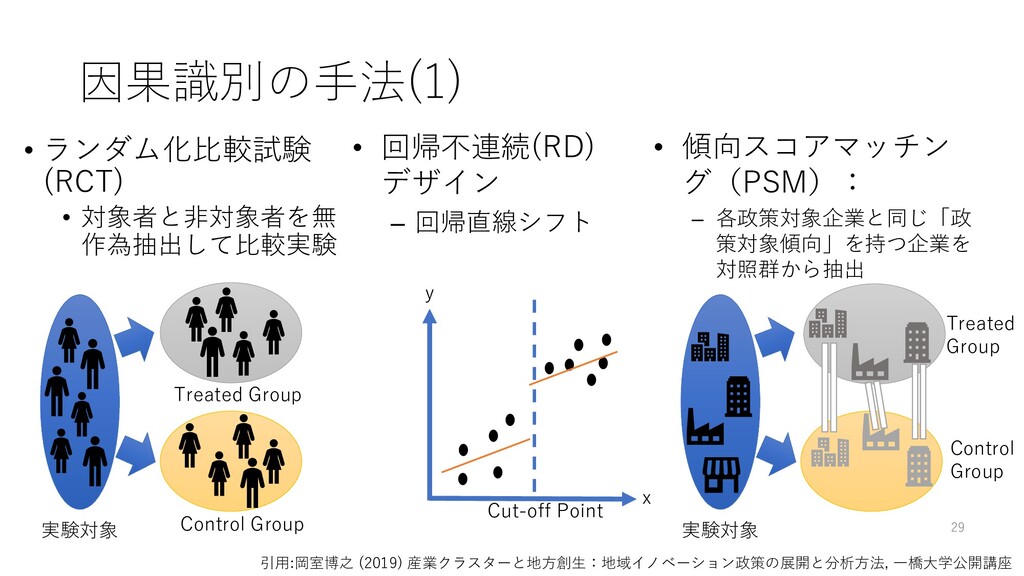
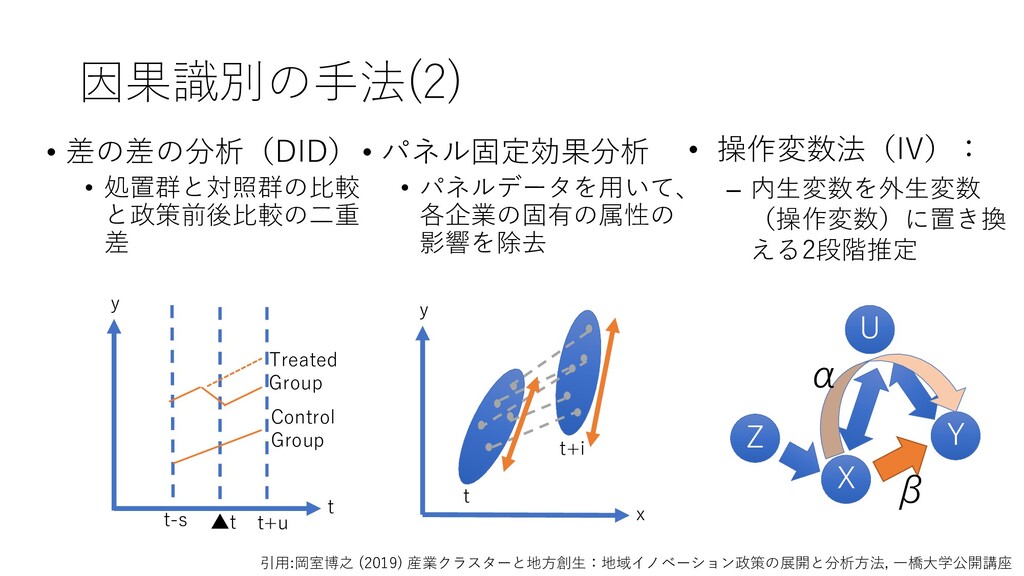
Group Treated Group t+u t-s ▲t • パネル固定効果分析 • パネルデータを用いて、 各企業の固有の属性の 影響を除去 y x t+i t • 操作変数法(IV): – 内生変数を外生変数 (操作変数)に置き換 える2段階推定 Z X Y U β α 引用:岡室博之 (2019) 産業クラスターと地方創生:地域イノベーション政策の展開と分析方法, 一橋大学公開講座
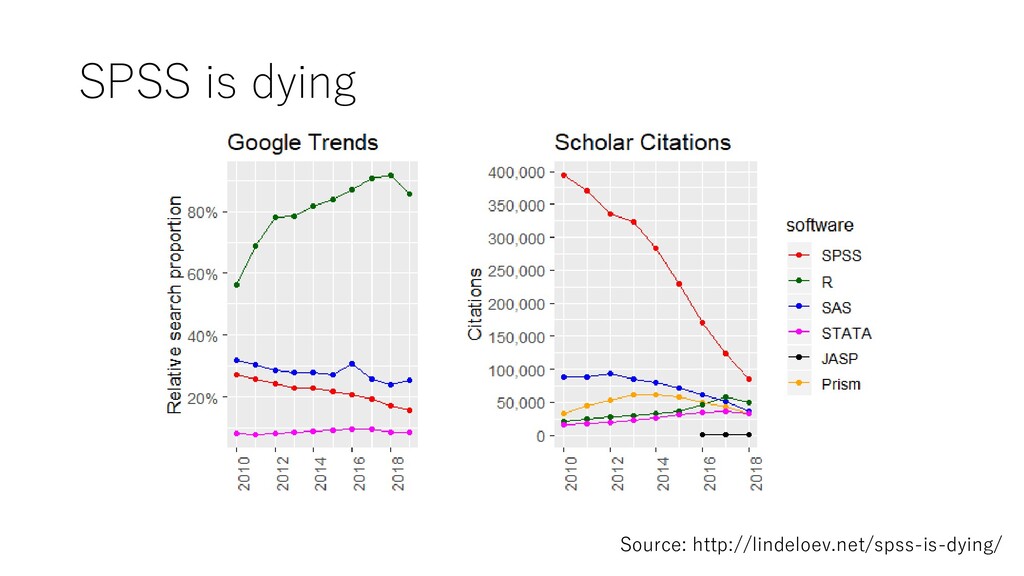
SPSS in yearly citations by 2020. The implications are clear: • If you use SPSS in your business or research, move to R now rather than later. • Do not ask for SPSS competences in job postings. You will scare away the good candidates. • We are doing students a disservice by teaching SPSS. Switch to JASP for simple one-off analyses and R for complex or repeated analyses. Rstudio Desktop is a highly recommended interface to R.” Source: http://lindeloev.net/spss-is-dying/
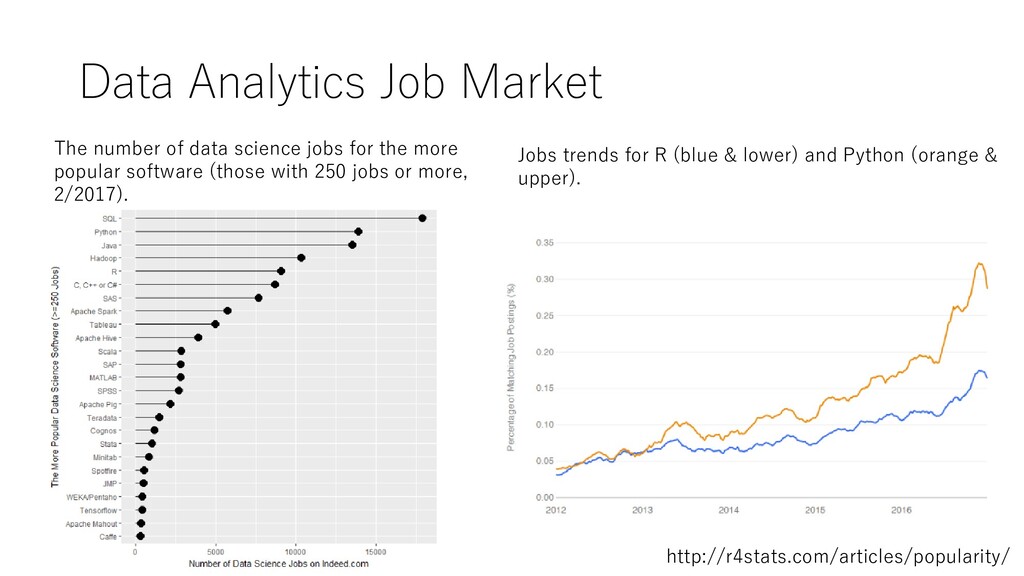
for the more popular software (those with 250 jobs or more, 2/2017). Jobs trends for R (blue & lower) and Python (orange & upper). http://r4stats.com/articles/popularity/
{kind=link}
![今日の内容 • 13:00-13:15 • プレ講義 [録画なし] • 13:15-13:35 • 1.1](https://files.speakerdeck.com/presentations/d858c0eb3df141d0ac5311190d70c97d/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Source: OECD (2017[3]), Core Skills for Public Sector Innovation, https://www.oecd.org/media/oecdorg/satellite](https://files.speakerdeck.com/presentations/d858c0eb3df141d0ac5311190d70c97d/slide_32.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![春学期講義スケジュール(1) • 1. 5/8 [今日] • イントロダクション (ビッグデータと社会科学), 分析環境の構築とプログラミング言語入門/統計分析ソフトの比 較](https://files.speakerdeck.com/presentations/d858c0eb3df141d0ac5311190d70c97d/slide_45.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Jupyter Notebook のインストール(1) • 1. https://anaconda.com にアクセスし 右上の [Download] を](https://files.speakerdeck.com/presentations/d858c0eb3df141d0ac5311190d70c97d/slide_82.jpg){kind=link}
![Anaconda Distribution のインストール(1) • 利用しているオペレーティングシステム (Windows/Mac/Linux)に基づき, Python3.7 バージョンの [Download] をクリック](https://files.speakerdeck.com/presentations/d858c0eb3df141d0ac5311190d70c97d/slide_83.jpg){kind=link}
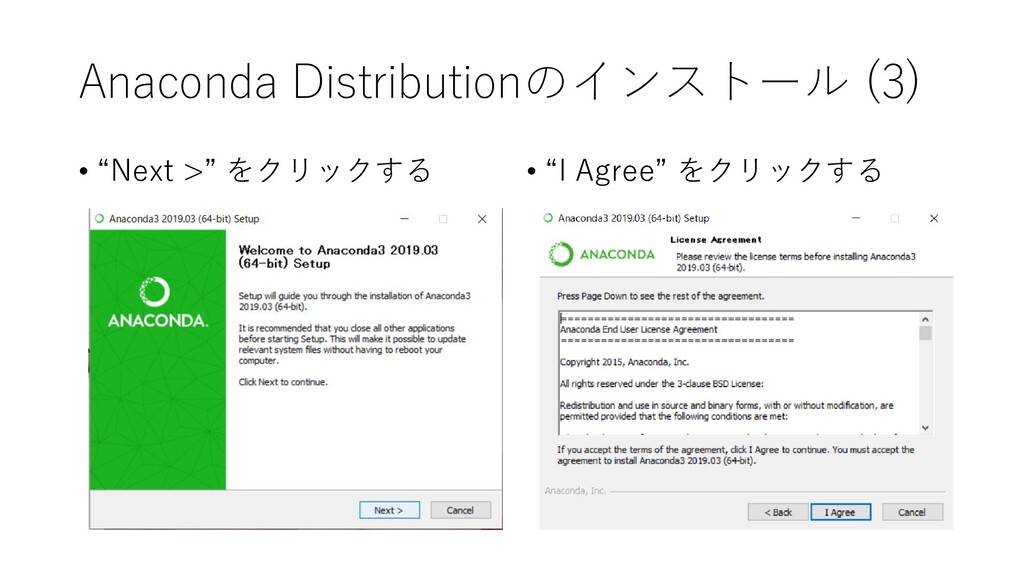{kind=link}
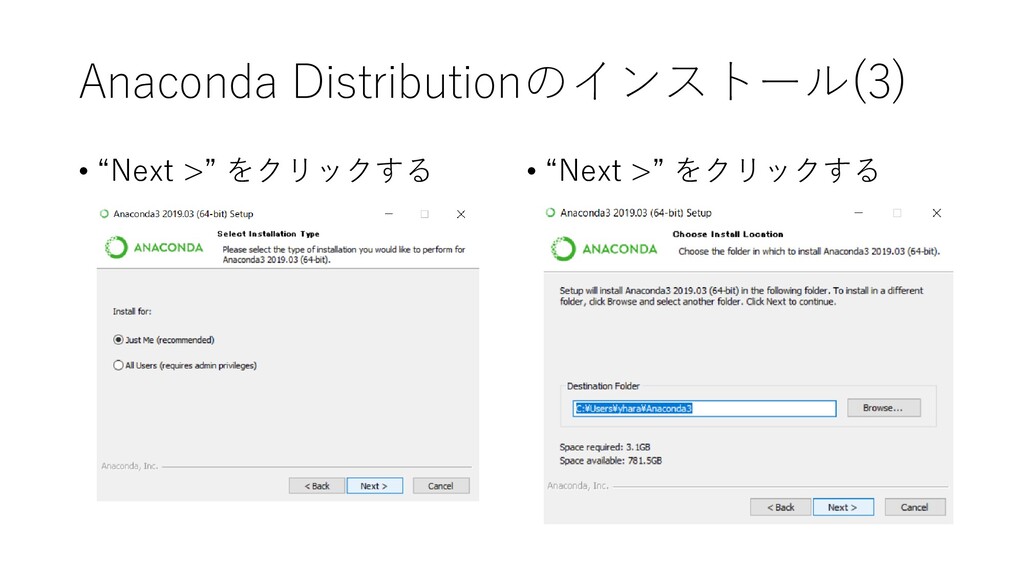{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![3-2. 新しいnotebook を作成する • [ファイル]-[python3 の新しいノートブック] を選択する](https://files.speakerdeck.com/presentations/d858c0eb3df141d0ac5311190d70c97d/slide_94.jpg){kind=link}
{kind=link}
{kind=link}
![THANKS [email protected]](https://files.speakerdeck.com/presentations/d858c0eb3df141d0ac5311190d70c97d/slide_97.jpg){kind=link}