Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Language Model Based Grammatical Error Correcti...
Search
youichiro
July 25, 2018
Technology
190
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Language Model Based Grammatical Error Correction without Annotated Training Data
長岡技術科学大学
自然言語処理研究室
文献紹介(2018-07-25)
youichiro
July 25, 2018
More Decks by youichiro
See All by youichiro
日本語文法誤り訂正における誤り傾向を考慮した擬似誤り生成
youichiro
0
1.6k
分類モデルを用いた日本語学習者の格助詞誤り訂正
youichiro
0
140
Multi-Agent Dual Learning
youichiro
1
200
Automated Essay Scoring with Discourse-Aware Neural Models
youichiro
0
150
Context is Key- Grammatical Error Detection with Contextual Word Representations
youichiro
1
170
勉強勉強会
youichiro
0
110
Confusionset-guided Pointer Networks for Chinese Spelling Check
youichiro
0
220
A Neural Grammatical Error Correction System Built On Better Pre-training and Sequential Transfer Learning
youichiro
0
200
An Empirical Study of Incorporating Pseudo Data into Grammatical Error Correction
youichiro
0
230
Other Decks in Technology
See All in Technology
AI、CDK と協働する Full TypeScript アプリケーション開発 / Full TypeScript Application with AI and CDK
geekplus_tech
2
480
AIとハーネスで育てるトランスコンパイラ / 20260722 Yasushi Katayama
shift_evolve
PRO
3
780
変更し続けられるシステムをどう保つか — AI時代のSSoTという設計原則
kawauso
1
1.1k
生成AI×AWS CDK×AWS FISで"振り返れる"ミニGameDayをつくろう
yoshimi0227
2
530
AIが当たり前の組織で エンジニアはどう育つか
nishihira
1
970
現場との対話から始める “作る前に問い直す”業務改善
mochico50
1
220
AI時代の開発生産性は、個人技からチーム設計へ
moongift
PRO
4
2.5k
副作用のある Lambda でも Lambda Power Tuning は使えるのか / lambda-power-tuning-side-effects
koukihosaka
1
140
文字起こし基盤の信頼性
abnoumaru
0
120
AICoEでAIネイティブ組織への進化
yukiogawa
0
210
アップデートで何が変わった?デモで学んで使いこなすIBM Bob2.0
muehara
0
230
設計レビューとAIハーネスで向き合う AIが生み出した新しいボトルネックの対処法 / Design Reviews and AI Harnesses Against New Bottlenecks Created by AI
nstock
4
430
Featured
See All Featured
Crafting Experiences
bethany
1
230
Agile Leadership in an Agile Organization
kimpetersen
PRO
0
190
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
Art, The Web, and Tiny UX
lynnandtonic
304
22k
Information Architects: The Missing Link in Design Systems
soysaucechin
0
1k
The untapped power of vector embeddings
frankvandijk
2
1.8k
How to optimise 3,500 product descriptions for ecommerce in one day using ChatGPT
katarinadahlin
PRO
1
3.7k
Lightning Talk: Beautiful Slides for Beginners
inesmontani
PRO
2
610
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
220
Paper Plane
katiecoart
PRO
2
52k
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
Future Trends and Review - Lecture 12 - Web Technologies (1019888BNR)
signer
PRO
0
3.6k
Transcript
Language Model Based Grammatical Error Correction without Annotated Training Data
Christopher Bryant and Ted Briscoe Proceedings of the Thirteenth Workshop on Innovative Use of NLP for Building Educational Applications, pages 247–253, 2018 ⽂献紹介(2018-07-25) ⻑岡技術科学⼤学 ⾃然⾔語処理研究室 ⼩川 耀⼀朗 1
Abstract l ⾔語モデルを⽤いた⽂法誤り訂正アプローチ l シンプルかつ少量のアノテーションデータしか⽤いない⾔ 語モデルアプローチが、⼤量のアノテーションデータで訓 練されたモデルと競争できる性能を⽰した 2
Introduction l CoNNL-2014 shared taskではTop3のチーム全てがSMTあ るいはclassifier-baseのシステムを⽤いた l これ以降、SMTやSMTとclassifierの混同、NMTのアプロー チにフォーカスした研究が進んでいる l
⾔語モデルを⽤いた⼿法に関する研究は⼤きく停滞した Ø GECにおける⾔語モデルアプローチを再調査する 3
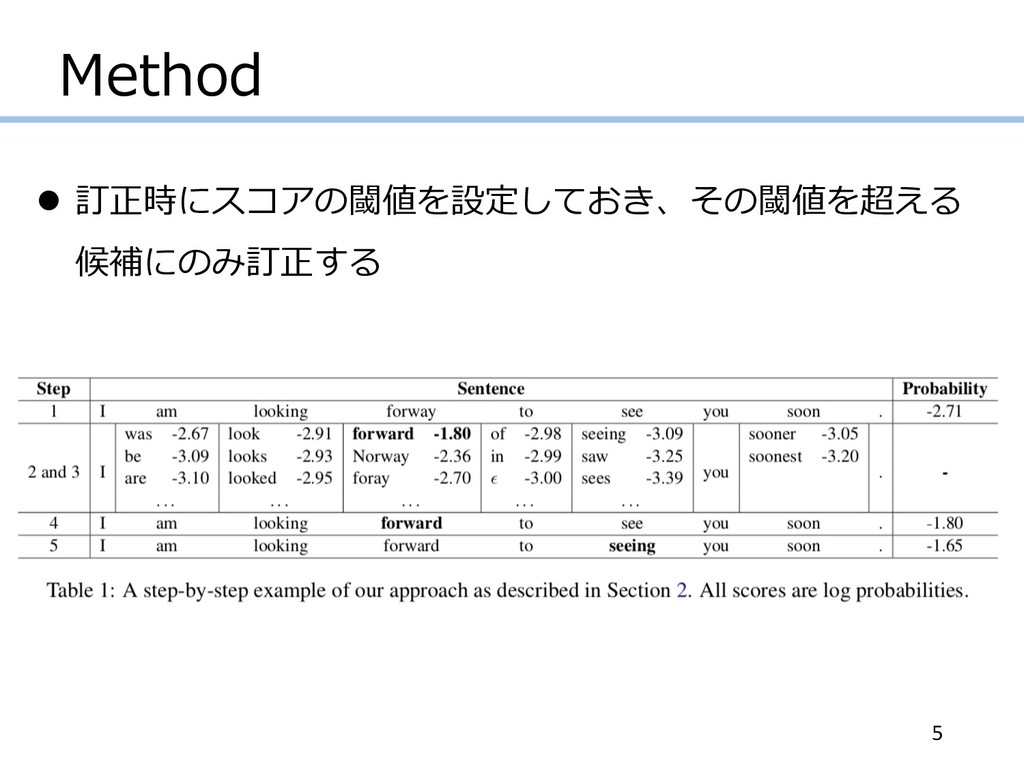
Method l ⾔語モデル確率の低い⽂は、⾔語モデル確率の⾼い⽂よ りも⽂法誤りを含んでいるであろうというアイデア 1. ⼊⼒⽂の⾔語モデルスコアを計算する 2. ⽂中の各単語において、訂正候補セットを作る 3. 各単語における各訂正候補で置換した⽂を⽣成し、
再び⽂のスコアを計算する 4. 訂正候補の中から、スコアが閾値よりもが⾼くなる 1⽂を選ぶ 5. ステップ1~4を繰り返す 4
Method l 訂正時にスコアの閾値を設定しておき、その閾値を超える 候補にのみ訂正する 5
Method 訂正候補セット l 以下の英語のエラータイプを対象とする non-words, morphology, article and prepositions l
Non-words(⾮単語) ex) [freind → friend] CyHunspell*1を使⽤し、訂正候補を⽣成する *1 https://pypi.org/project/CyHunspell/ 6
Method 訂正候補セット l Morphology(語形) - noun number: [cat → cats]
- verb tense: [eat → ate] - adjective form: [big → bigger] など Automatically Generated Inflection Database(AGID)*2から、訂正 候補を⽣成する l Articles and Prepositions(冠詞と前置詞) article: {φ, a, an, the} preposition: {φ, about, at, by, for, from, in, of, on, to, with} *2 http://wordlist.aspell.net/other/ 7
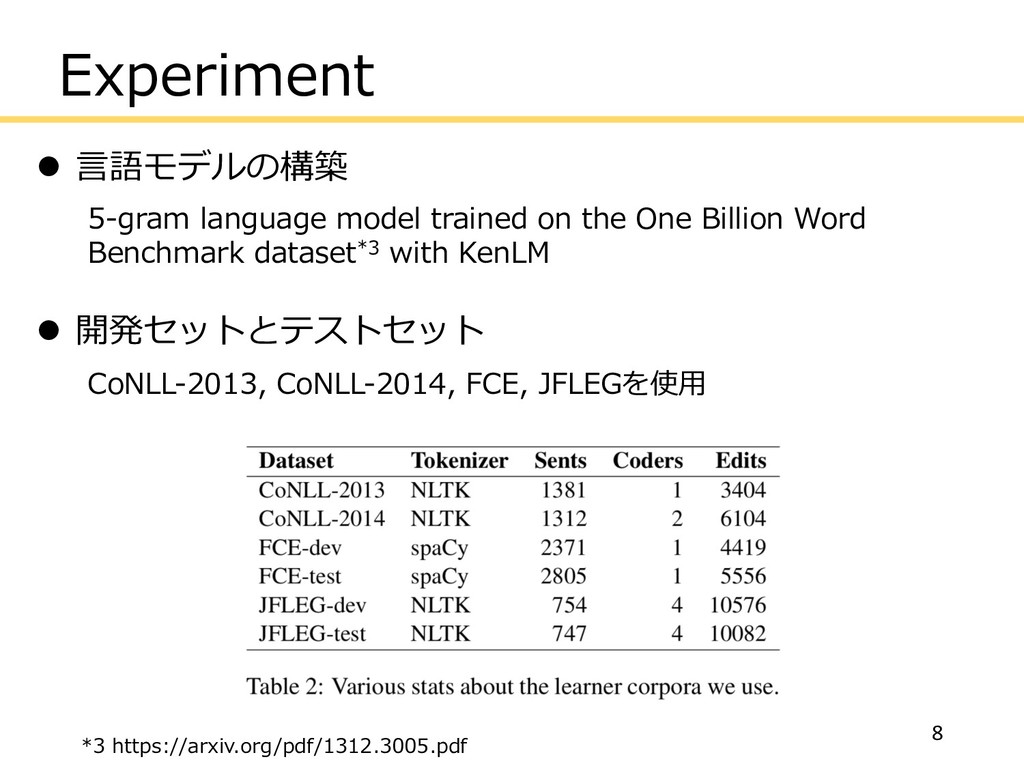
Experiment l ⾔語モデルの構築 5-gram language model trained on the One
Billion Word Benchmark dataset*3 with KenLM l 開発セットとテストセット CoNLL-2013, CoNLL-2014, FCE, JFLEGを使⽤ 8 *3 https://arxiv.org/pdf/1312.3005.pdf
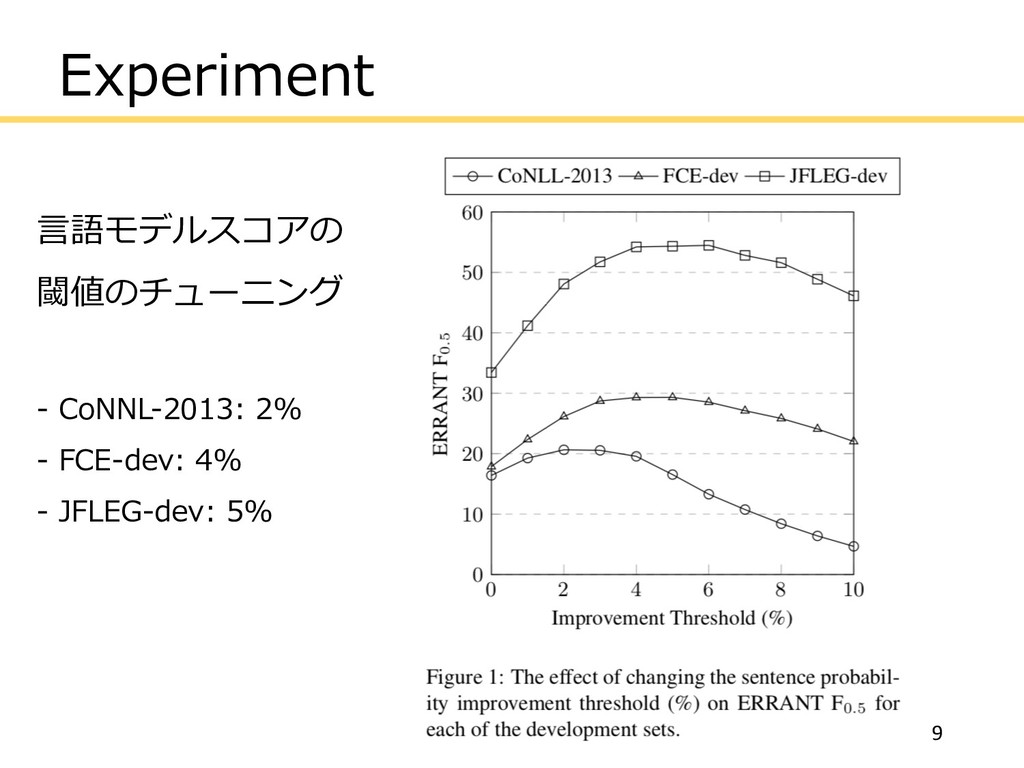
Experiment ⾔語モデルスコアの 閾値のチューニング - CoNNL-2013: 2% - FCE-dev: 4% -
JFLEG-dev: 5% 9
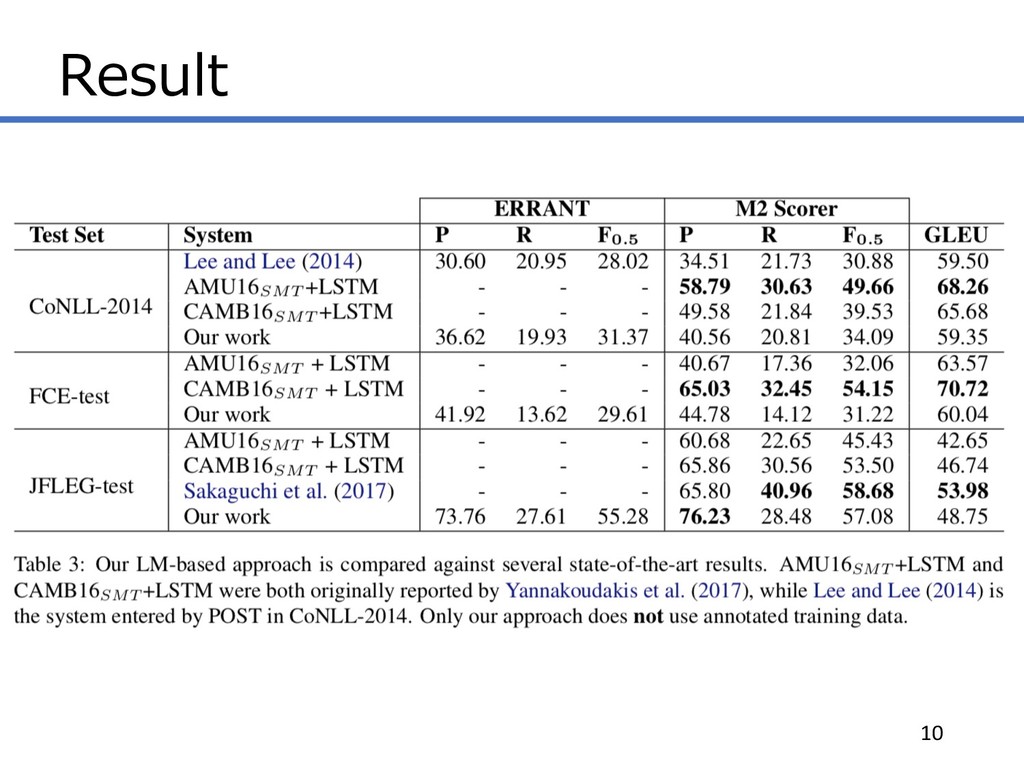
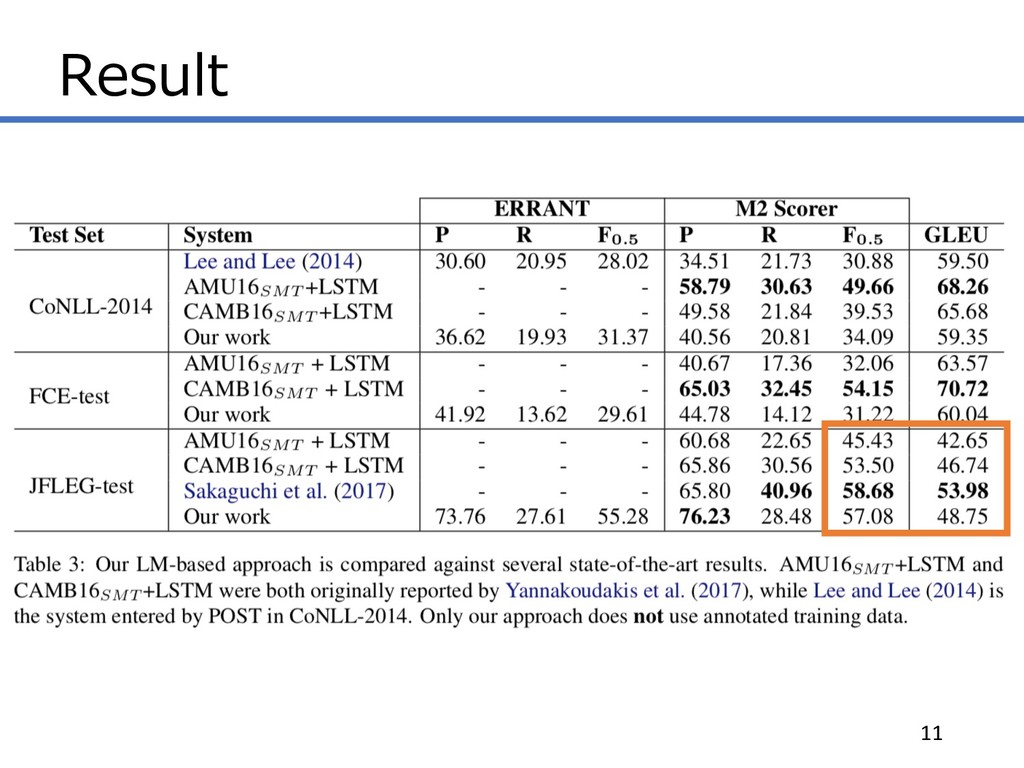
Result 10
Result 11
Conclusion 12 l ⽂法誤り訂正のためのシンプルで少量のアノテーションデータしか使わ ない⾔語モデルアプローチを提案し、⼤量のアノテーションデータを必 要とする機械翻訳アプローチと競争できることを⽰した l このシステムは特定のエラータイプしか訂正できない制限があるため、 missing words(単語の不⾜)など他のエラータイプも訂正可能にするが
課題に挙げられる
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Method 訂正候補セット l Morphology(語形) - noun number: [cat → cats]](https://files.speakerdeck.com/presentations/fe987ead40694db2a9c6cd8cfd9061a4/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}