Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Modeling Naive Psychology of Characters in Simp...
Search
Yuto Kamiwaki
January 29, 2019
Research
1
220
Modeling Naive Psychology of Characters in Simple Commonsense Stories
2019/01/30 文献紹介の発表内容
Yuto Kamiwaki
January 29, 2019
Tweet
Share
More Decks by Yuto Kamiwaki
See All by Yuto Kamiwaki
Emo2Vec: Learning Generalized Emotion Representation by Multi-task Training
yuto_kamiwaki
0
120
Using millions of emoji occurrences to learn any-domain representations for detecting sentiment, emotion and sarcasm
yuto_kamiwaki
0
110
Epita at SemEval-2018 Task 1: Sentiment Analysis Using Transfer Learning Approach
yuto_kamiwaki
0
140
Tensor Fusion Network for Multimodal Sentiment Analysis
yuto_kamiwaki
0
270
Sentiment Analysis: It’s Complicated!
yuto_kamiwaki
0
86
ADAPT at IJCNLP-2017 Task 4: A Multinomial Naive Bayes Classification Approach for Customer Feedback Analysis task
yuto_kamiwaki
0
180
EmoWordNet: Automatic Expansion of Emotion Lexicon Using English WordNet
yuto_kamiwaki
0
110
ATTENTION-BASED LSTM FOR PSYCHOLOGICAL STRESS DETECTION FROM SPOKEN LANGUAGE USING DISTANT SUPERVISION
yuto_kamiwaki
0
160
BB_twtr at SemEval-2017 Task 4: Twitter Sentiment Analysis with CNNs and LSTMs
yuto_kamiwaki
0
250
Other Decks in Research
See All in Research
POI: Proof of Identity
katsyoshi
0
140
[チュートリアル] 電波マップ構築入門 :研究動向と課題設定の勘所
k_sato
0
260
Agentic AI フレームワーク戦略白書 (2025年度版)
mickey_kubo
1
120
生成的情報検索時代におけるAI利用と認知バイアス
trycycle
PRO
0
300
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
230
Ankylosing Spondylitis
ankh2054
0
120
それ、チームの改善になってますか?ー「チームとは?」から始めた組織の実験ー
hirakawa51
0
670
生成AI による論文執筆サポート・ワークショップ 論文執筆・推敲編 / Generative AI-Assisted Paper Writing Support Workshop: Drafting and Revision Edition
ks91
PRO
0
120
Proposal of an Information Delivery Method for Electronic Paper Signage Using Human Mobility as the Communication Medium / ICCE-Asia 2025
yumulab
0
170
SREはサイバネティクスの夢をみるか? / Do SREs Dream of Cybernetics?
yuukit
3
390
When Learned Data Structures Meet Computer Vision
matsui_528
1
2.9k
[IBIS 2025] 深層基盤モデルのための強化学習 驚きから理論にもとづく納得へ
akifumi_wachi
19
9.6k
Featured
See All Featured
Designing for Timeless Needs
cassininazir
0
130
JAMstack: Web Apps at Ludicrous Speed - All Things Open 2022
reverentgeek
1
350
HDC tutorial
michielstock
1
400
Rebuilding a faster, lazier Slack
samanthasiow
85
9.4k
The Cult of Friendly URLs
andyhume
79
6.8k
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.2k
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
54k
技術選定の審美眼(2025年版) / Understanding the Spiral of Technologies 2025 edition
twada
PRO
117
110k
Ecommerce SEO: The Keys for Success Now & Beyond - #SERPConf2024
aleyda
1
1.8k
The browser strikes back
jonoalderson
0
420
個人開発の失敗を避けるイケてる考え方 / tips for indie hackers
panda_program
122
21k
Transcript
Modeling Naive Psychology of Characters in Simple Commonsense Stories Nagaoka
University of Technology Yuto Kamiwaki Literature Review
Literature • Modeling Naive Psychology of Characters in Simple Commonsense
Stories • Hannah Rashkin , Antoine Bosselut , Maarten Sap , Kevin Knight and Yejin Choi • Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Long Papers) 2
Abstract • 機械が物語を理解するのは,容易ではない. ◦ 行間を読む,人の精神状態 • 動機と感情的反応に関して登場人物の精神状態を特定し, 物語中の心理変化を説明する新しいアノテーションフレーム ワークを提案. 3
Introduction • 物語の中の出来事と登場人物の精神状態との間の因果関 係についての推論が必要.(たとえ,それらの関係が明確に 述べられていなくても) • Mostafazadeh et al.,2017で示されているように,本推論は 統計学とニューラルマシンにとって非常に困難(人間にとって
は些細なこと) 4
Introduction • 登場人物の精神状態に関して,短編小説を密にラベル付け するための新しいアノテーション形式を構築した Mostafazadeh et al.,2016→(この文献はコーパス構築につ いての内容) ◦ 文献url
: http://www.aclweb.org/anthology/N16-1098 5
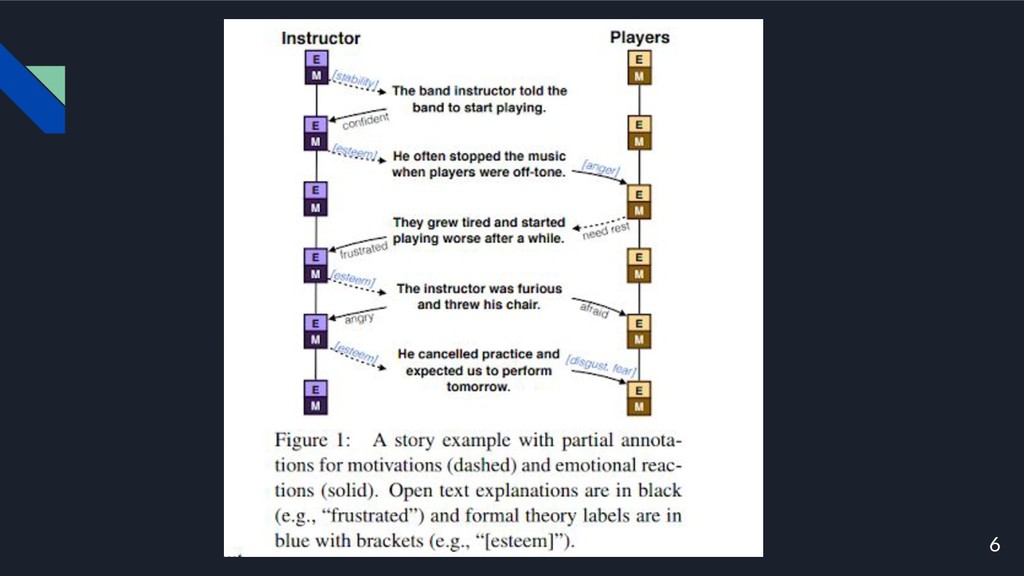
6
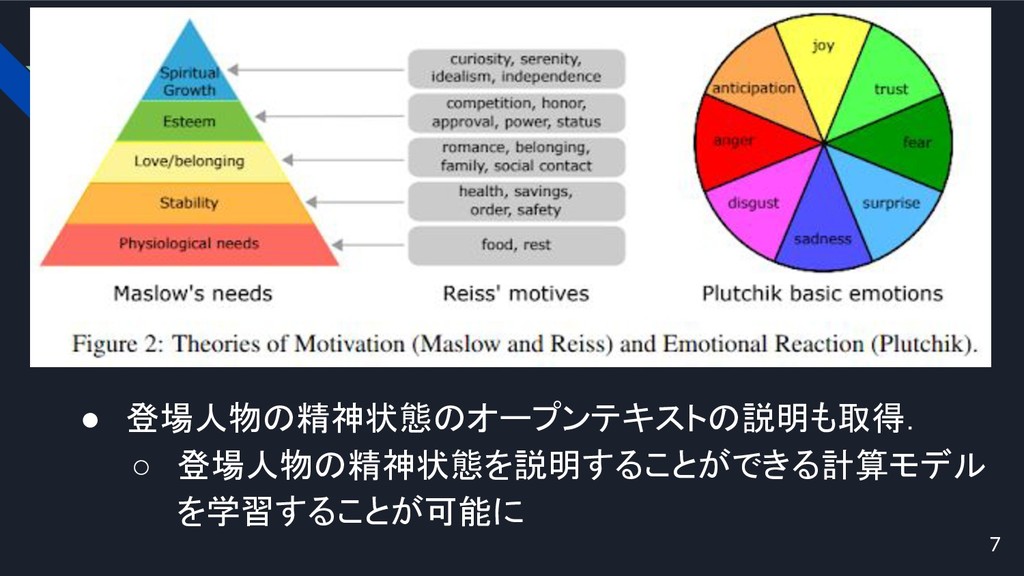
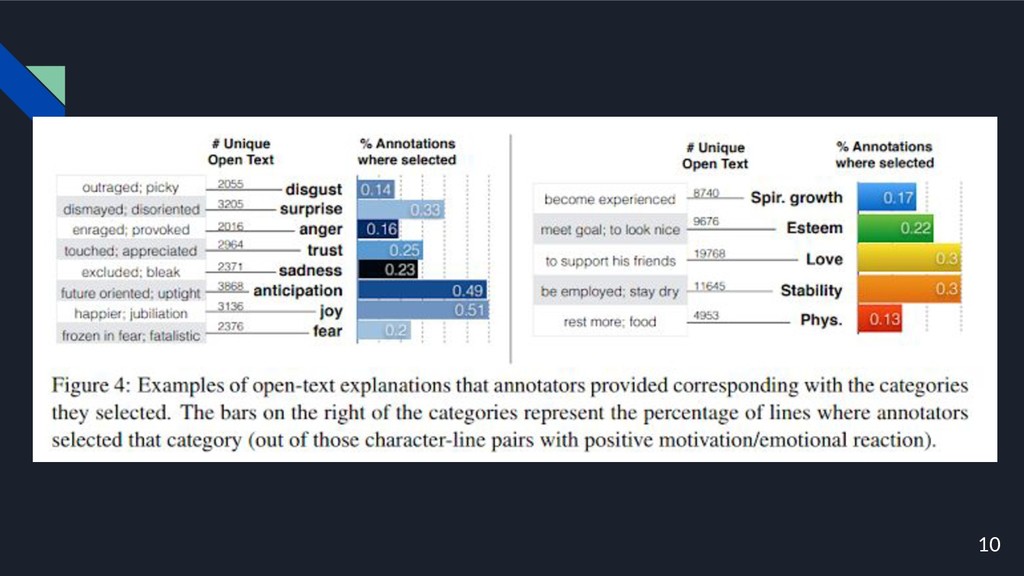
• 登場人物の精神状態のオープンテキストの説明も取得. ◦ 登場人物の精神状態を説明することができる計算モデル を学習することが可能に 7
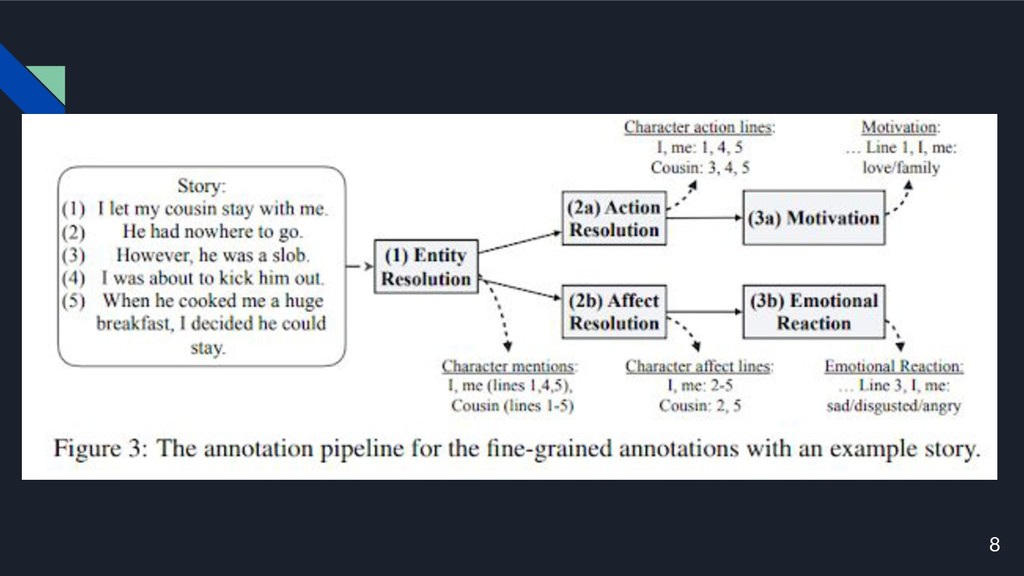
8
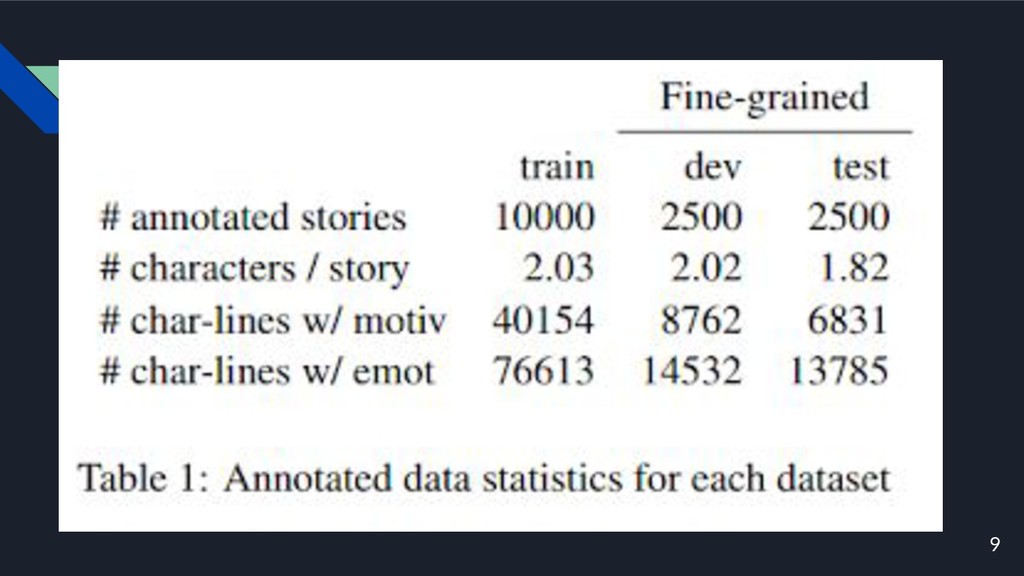
9
10
11
12
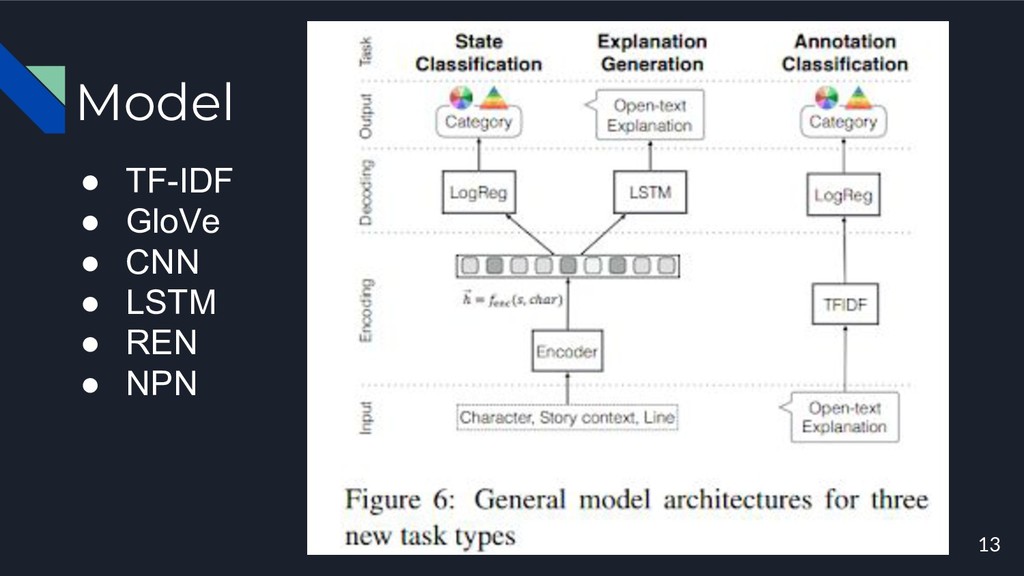
Model • TF-IDF • GloVe • CNN • LSTM •
REN • NPN 13
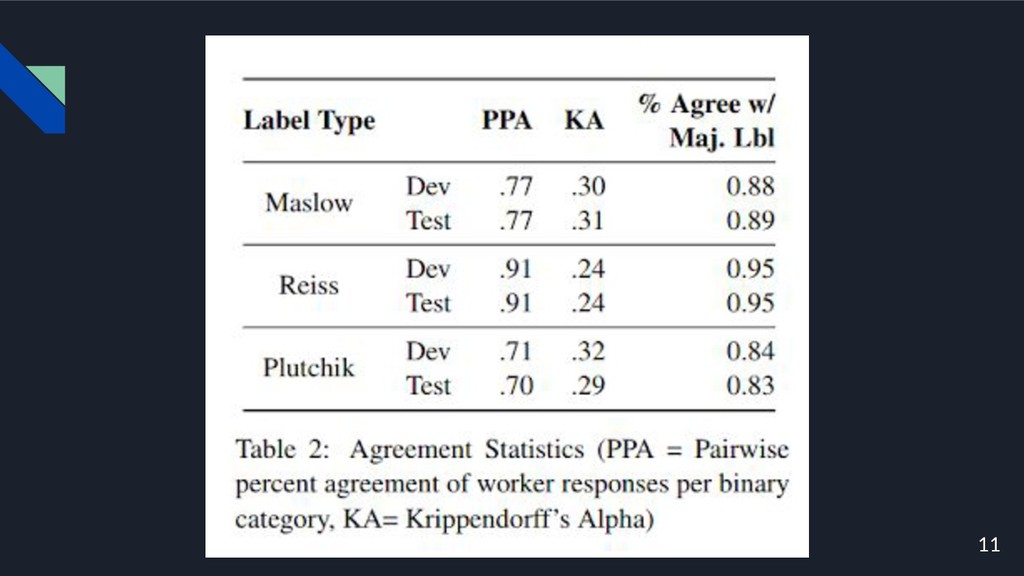
14
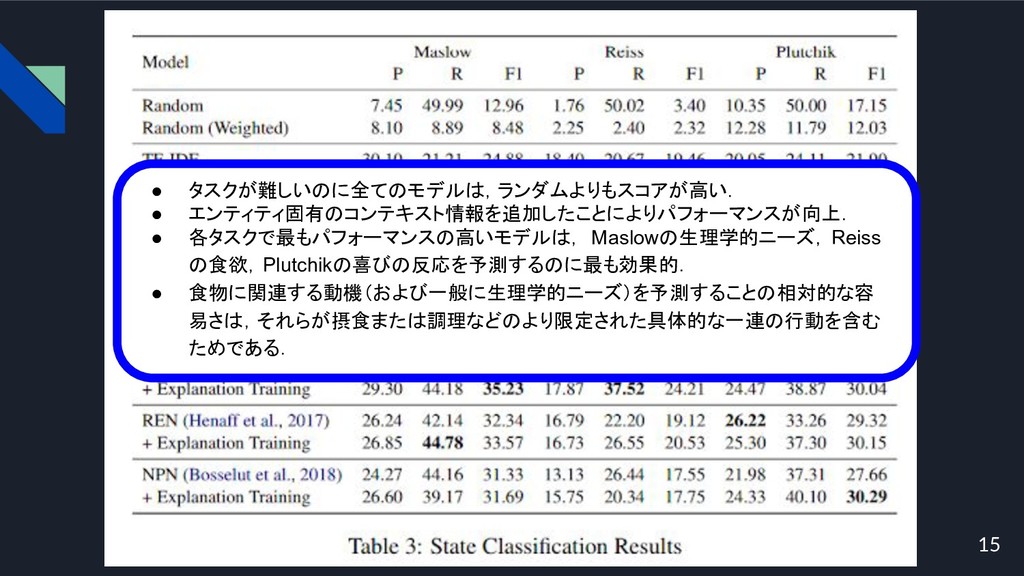
15 • タスクが難しいのに全てのモデルは,ランダムよりもスコアが高い. • エンティティ固有のコンテキスト情報を追加したことによりパフォーマンスが向上. • 各タスクで最もパフォーマンスの高いモデルは, Maslowの生理学的ニーズ, Reiss の食欲,Plutchikの喜びの反応を予測するのに最も効果的.
• 食物に関連する動機(および一般に生理学的ニーズ)を予測することの相対的な容 易さは,それらが摂食または調理などのより限定された具体的な一連の行動を含む ためである.
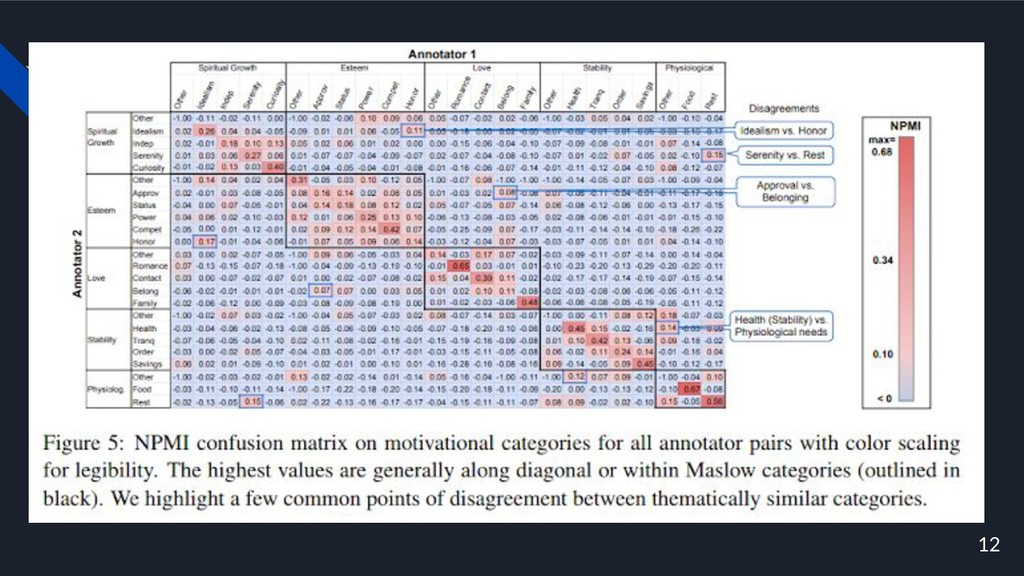
16
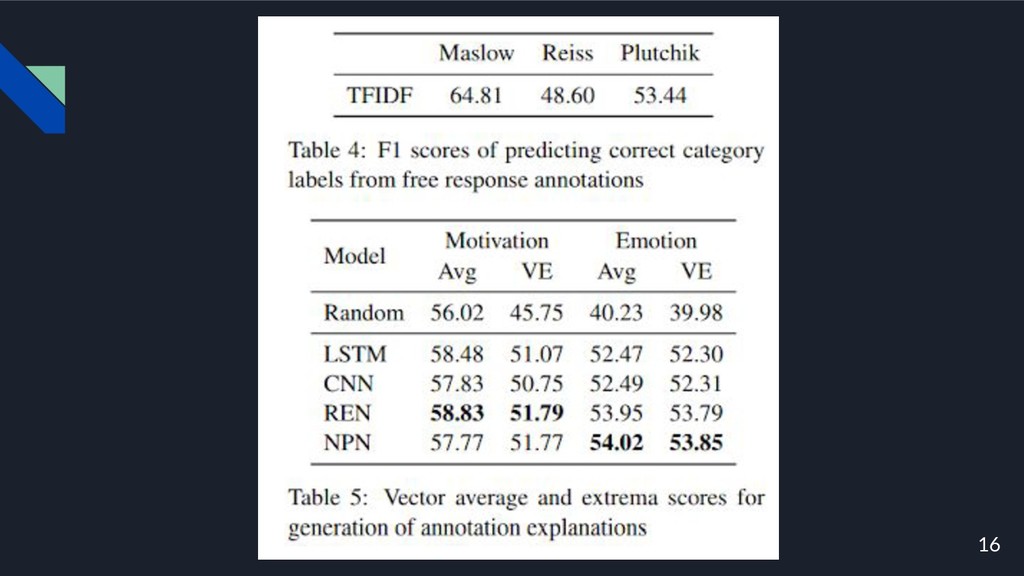
17 • 単純なモデルがオープンテキスト応答をカテゴリにマッピングすることを学習できて いる. • 自由回答アノテーションの分類モデルを事前学習することが,カテゴリ予測のパ フォーマンス向上に役立つ可能性があるという私たちの仮説を支持している.
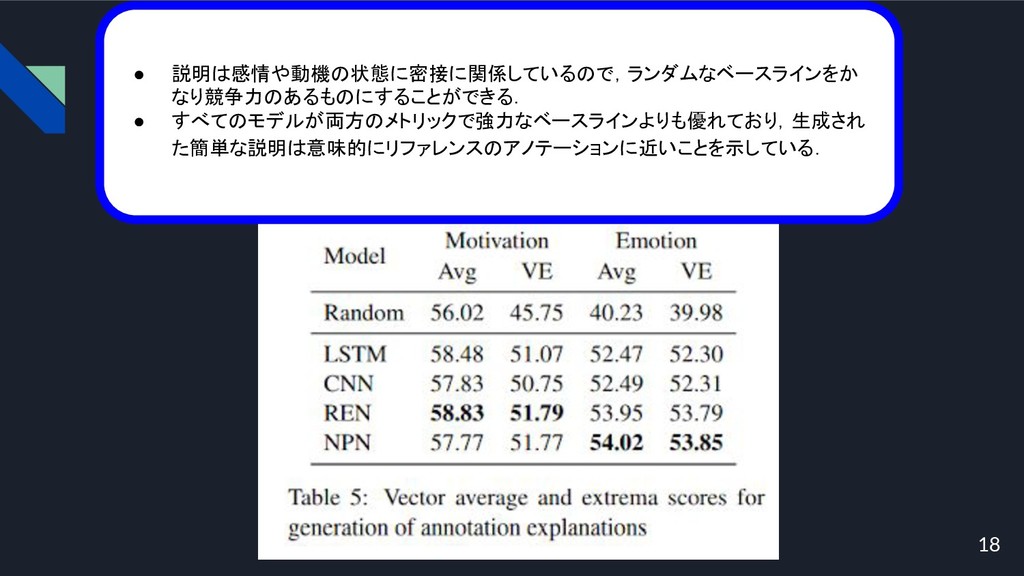
18 • 説明は感情や動機の状態に密接に関係しているので,ランダムなベースラインをか なり競争力のあるものにすることができる. • すべてのモデルが両方のメトリックで強力なベースラインよりも優れており,生成され た簡単な説明は意味的にリファレンスのアノテーションに近いことを示している.
Conclusion • 短い物語における登場人物の精神状態の情報で訓練し,評 価するためのリソースとして大規模データセットを構築した. • データセットには、登場人物の動機と感情的な反応に対する 30万以上の低レベルの注釈が含まれている. • 重要なのは、登場人物固有のコンテキストをモデリングし,フ リーレスポンスデータを事前トレーニングすることでラベリン
グパフォーマンスが向上することである. 19
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}