леса Введение Прогнозирование является важной составной частью науки о пространственных данных. Прогнозирование можно использовать для оценки будущих значений (например, прогнозирование качества воздуха на завтра для указанного местоположения), информации на более мелком масштабе (например, с использованием данных о явке избирателей на уровне округа для прогнозирования явки с учетом переписи населения) или заполнения отсутствующих значений в наборе данных. ArcGIS предоставляет различные инструменты прогнозирования, которые направлены на выполнение такого рода анализов. В этом упражнении используется инструмент Forest-Based Classification And Regression программного обеспечения ArcGIS Pro, который использует адаптацию метода Random Forest, разработанного Leo Breiman (Лео Брейманом). Сильная сторона метода случайного леса состоит в том, что он улавливает общие черты слабых предикторов (деревья) и объединяет их для создания мощного предиктора (леса). Для этого инструмент создает множество деревьев решений, называемых ансамблем или лесом, которые затем используются для прогнозирования. С этой целью каждое сформированное дерево генерирует свой собственный прогноз, результат которого используется в настоящем примере в качестве части схемы т.н. голосования, для получения окончательного прогноза в результате статистического анализа прогнозов всех участвующих в голосовании деревьев. Инструмент Forest-Based Classification And Regression, относящийся к категории машинного обучения с учителем, позволяет использовать существующие данные для обучения моделей, которые могут быть использованы для проведения прогнозного анализа. В этом примере этот инструмент используется для обучения и проведения модельной прогнозной оценки, изменения переменных и параметров для повышения производительности модели. Сценарий выполнения упражнения В этом упражнении создаются модели, прогнозирующие явку избирателей. Эти модели используют независимые переменные, такие как доход и возраст избирателей, для получения прогнозной оценки зависимой переменной, которой является явки избирателей. Получения модельного прогноза состоит из нескольких этапов, включающих подготовку и визуализацию данных, а также модельный прогнозный и анализ его результатов. Созданная модель может быть использована для прогноза явки избирателей, начиная с уровня округа (county). На основании этих прогнозов может быть организована агитационная кампания типа «Выходи на
день выборов и проголосовать. В тоже самое время результаты моделирования могут быть использованы для идентификации мест, где ожидается низкая явка избирателей, и таким образом могут быть использованы для формирования целей и задач предвыборной кампании. Шаг 1. Загрузка входных данных упражнения На этом этапе вы загрузите файлы данных упражнений. Откройте новую вкладку или окно веб-браузера. Извлеките файлы в папку на локальном компьютере, сохранив файлы в необходимом месте. Шаг 2: Открытие проект ArcGIS Pro Запустите ArcGIS Pro. При необходимости войдите в систему, используя имя пользователя и пароль учетной записи ArcGIS. В нижнем левом углу стартовой страницы ArcGIS Pro щелкните Open Another Project (Открыть другой проект). Примечание: Если вы настроили ArcGIS Pro для запуска без шаблона проекта или с проектом по умолчанию, вы не увидите стартовую страницу. На вкладке «Project» (Проект) нажмите «Open» (Открыть), а затем - «Open Another Project» (Открыть другой проект). В диалоговом окне «Open Project» (Открыть проект) перейдите к папке «Прогноз», которую вы сохранили на своем компьютере. Щелкните Prediction.aprx, чтобы выбрать его, а затем щелкните OK. Вкладка карты прогнозов открывается с серой базовой картой, поверх которой расположен слой карты, представляющим результаты президентских
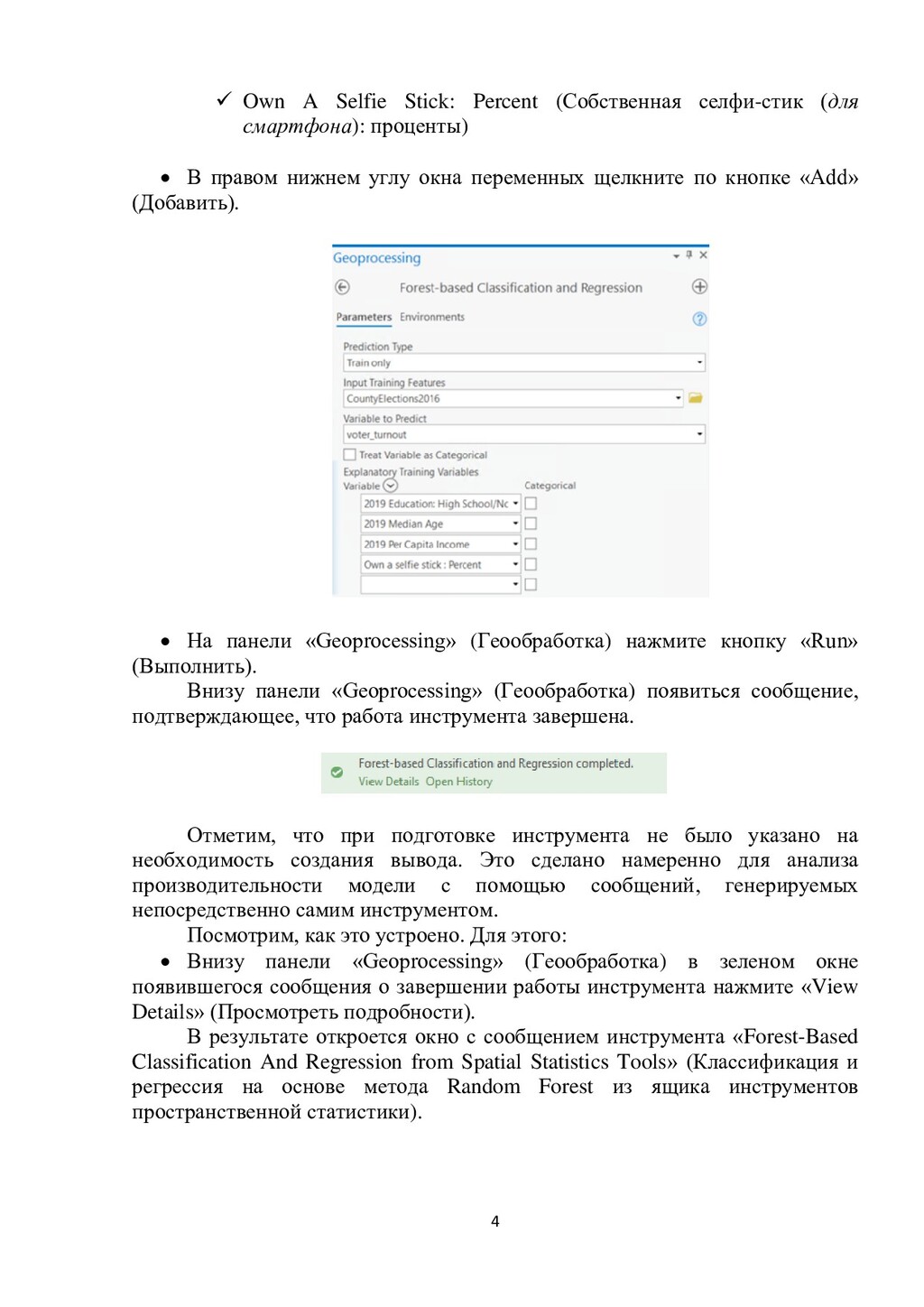
этом округа с показателем явки избирателей ниже среднего отмечены фиолетовым цветом, а округа с показателем явки избирателей выше среднего - зеленым. Шаг 3. Создание модели прогноза Ранее во время работы по инженерии данных президентских выборов 2016 года в США было проведено их обогащение дополнительными демографическими переменными. В упражнении по визуализации данных было проведено исследование связи дополнительных демографических переменных с данными явки избирателей. При этом была проведена идентификация переменных, имеющих сильную связь с данными явки избирателей. Ниже идентифицированные переменные, полученные в предыдущем упражнении, используются для создания первой модели прогноза. Для продолжения: На вкладке «Analysis» (Анализ) в группе «Geoprocessing» (Геообработка) нажмите «Tools» (Инструменты). На панели «Geoprocessing» (Геообработка) найдите инструмент «Forest- Based Classification And Regression» (классификации и регрессии на основе метода Random Forest) from Spatial Statistics Tools (инструменты пространственной статистики) и щелкните по нему. Примечание. Обратите внимание на использование ящика инструментов «Spatial Statistics tool» (Пространственная статистика), а не GeoAnalytics Desktop. В результате реализации указанных действий на панели «Geoprocessing» (Геообработка) откроется вкладка инструмента «Forest-Based Classification And Regression» (Классификация и регрессия на основе метода Random Forest). Для продолжения: На панели «Geoprocessing» (Геообработка) установите или подтвердите принятие значений следующих параметров: Prediction Type: Train Only (Тип прогноза: только обучение). Input Training Features: CountyElections2016 (Функции обучения вводу: CountyElections2016). Variable To Predict: Voter_Turnout (Прогнозируемая переменная: Voter_Turnout). В разделе «Explanatory Training Variables» (Объясняющие обучающие переменные), вслед за полем «Variable» (Переменная) нажмите кнопку «Add Many» (Добавить много), имеющей форму (v). В окне переменных установите флажки для следующих переменных: 2019 Education: High School/No Diploma: Percent (Образование 2019: средняя школа/без диплома: процент) 2019 Median Age (Средний возраст 2019 г.) 2019 Per Capita Income (Доход на душу населения в 2019 г.)
смартфона): проценты) В правом нижнем углу окна переменных щелкните по кнопке «Add» (Добавить). На панели «Geoprocessing» (Геообработка) нажмите кнопку «Run» (Выполнить). Внизу панели «Geoprocessing» (Геообработка) появиться сообщение, подтверждающее, что работа инструмента завершена. Отметим, что при подготовке инструмента не было указано на необходимость создания вывода. Это сделано намеренно для анализа производительности модели с помощью сообщений, генерируемых непосредственно самим инструментом. Посмотрим, как это устроено. Для этого: Внизу панели «Geoprocessing» (Геообработка) в зеленом окне появившегося сообщения о завершении работы инструмента нажмите «View Details» (Просмотреть подробности). В результате откроется окно с сообщением инструмента «Forest-Based Classification And Regression from Spatial Statistics Tools» (Классификация и регрессия на основе метода Random Forest из ящика инструментов пространственной статистики).
для запуска инструмента, продолжительности его работы, а также диагностику производительности модели. Для этого: Прокрутите вниз и разверните раздел «Messages» (Сообщения). В разделе «Messages» (Сообщения) прокрутите вниз и найдите раздел «Training Data: Regression Diagnostics» (Данные обучения: диагностика регрессии). Примечание. При каждом запуске инструмента Forest-Based Classification And Regression from Spatial Statistics Tools» (Классификация и регрессия на основе метода Random Forest из ящика инструментов пространственной статистики), возможно получение результатов, отличных от ранее полученных. Это связано с преднамеренным случайным формированием новой обучающей выборки, встроенной в алгоритм для предупреждения переобучение модели. По умолчанию инструмент Forest-Based Classification And Regression from Spatial Statistics Tools» (Классификация и регрессия на основе на основе метода Random Forest из ящика инструментов пространственной статистики) формирует специальный подмнабор для проверки результатов моделирования в объеме 10% от объема всех используемых для обучения данных. В
на поднаборе, который не содержит заранее удаленный поднабор. После завершения обучения инструмент Forest-Based Classification And Regression from Spatial Statistics Tools» (Классификация и регрессия на основе метода Random Forest из ящика инструментов пространственной статистики) возвращает значение R-квадрат, которое является оценкой качества обучения модели, рассчитываемого по данным зарезервированного для этой цели поднабора. В том случае если качество обучения модели оценивается на основе непосредственно поднабора обучающих данных, а не поднабора данных проверки, то при этом обычно получают завышенные оценки качества обучения в результате так называемого переобучения. Таким образом, значение для проверки качества обучения R-квадрат, рассчитанное по заранее зарезервированному поднабору, является лучшим индикатором качества обучения модели, нежели значение R-квадрата, рассчитанное по тому же поднабору, которое было использовано непосредственно для аналогичного обучения. В обсуждаемом примере в результате проверки полученной модели по проверочному поднабору инструмент вернул значение R-квадрата, равное 0,519. Это указывает на то, что полученная модель предсказывает значение явки избирателей с использованием проверочного поднабора данных с точностью порядка 52%. Далее проводится демонстрация дополнительных расчетов по оценке значимости каждой независимой переменной при формировании требуемого прогноза. Для этого: Закройте окно сообщения инструмент «Forest-Based Classification And Regression from Spatial Statistics Tools» (классификации и регрессии на основе метода Random Forest из ящика инструментов пространственной статистики). На панели «Contents» (Содержание) отключите слой CountyElections2016. Инструмент геообработки «Forest-Based Classification And Regression from Spatial Statistics Tools» (классификации и регрессии на основе метода Random Forest из ящика инструментов пространственной статистики) будет далее снова использован, но уже с другими переменными и параметрами обработки. Для получения новых результатов необходимо внимательно ознакомиться с соответствующими инструкциями для правильного задания параметров этого инструмента так, чтобы они соответствовали приведенным инструкциям.
избирателей для каждого округа США. При этом таблица значимости переменных и связанная столбчатая диаграмма были добавлены на панель «Contents» (Содержание) и могут быть использованы для исследования значимости отдельных переменных, использованных в этом модельном прогнозе. На панели «Contents» (Содержание) откройте диаграмму «Summary Of Variable Importance» (Сводка важности переменных) и выберите «Open» (открыть). Подсказка: в разделе «Charts» (Диаграммы) щелкните правой кнопкой мыши «Summary Of Variable Importance and choose» (Сводка важности переменных) и выберите «Open» (Открыть). Отметим, что выраженные в процентах переменные The 2019 Per Capita Income доход на душу населения за 2019 год, а также 2019 Education: High School/No Diploma (уровень образования на 2019 год - средняя школа/без диплома) имеют наибольшие значения. Это означает, что эти переменные были наиболее полезными для прогнозирования явки избирателей. Выше уже упоминалось, что для предотвращения переобучение модели каждый новый запуск инструмент геообработки «Forest-Based Classification And Regression from Spatial Statistics Tools» (классификации и регрессии на основе метода Random Forest из ящика инструментов пространственной статистики) приводит к получению несколько отличных результатов от предыдущих, из-за введенной в алгоритм процедуры случайности формирования поднаборов. Для понимания и учета этой случайности необходимо использовать параметр, позволяющий создавать несколько моделей за один запуск. Это позволит исследовать характеристики качества формирования прогнозной модели. ЗАДАНИЕ – Проведите такой запуск и проанализируйте полученные результаты.
Of Variable Importance» (Сводка переменных по важности), полученную на предыдущем шаге. Внизу панели «Chart Properties» (Свойства диаграммы) щелкните вкладку «Geoprocessing» (Геообработка) для возврата на эту панель. В нижней части панели «Geoprocessing» (Геообработка) разверните «Validation Options» (Параметры проверки). В поле «Number Of Runs For Validation» (Число прогонов для проверки) введите 10, а затем щелкните на сером пространстве инструмента для распознавания проведенных изменений параметров. В результате панель «Geoprocessing» (Геообработка) обновится, и появится опция Output Validation Table (Выходная таблица проверки). Этот параметр появляется только в том случае, если указанное количество прогонов для проверки больше 2, что позволяет для созданной модели получить таблицу, а также гистограмму распределения значений R-квадрата. Для этого: В выходной таблице проверки введите Out_Validation_Table (подробности смотрите выше). В позиции «Output Validation Table» (Таблица проверки вывода) установите флажок в поле «Calculate Uncertainty» (Рассчитать неопределенности). Примечание. Если вы не видите флажок «Calculate Uncertainty box» (Рассчитать неопределенность), прокрутите панель геообработки вниз. Запустите инструмент геообработки «Forest-Based Classification And Regression from Spatial Statistics Tools» (Классификация и регрессия на основе метода Random Forest из ящика инструментов пространственной статистики). Внизу панели «Геообработка» нажмите «View Details» (Просмотреть подробности).
«Messages» (Сообщения), а затем перейдите к разделу «Validation Data: Regression Diagnostics section» (Данные проверки: диагностика регрессии). Отмечаем, что примененный инструмент провел обучение с использованием 10-ти запусков моделей, для каждого из которых случайным образом были сформированы поднаборы данных для обучения и проверки. Наиболее репрезентативное значение R-квадрата для 10 прогонов составило 0,527, что соответствует примерно 53% точности прогноза по данным проверки. Для анализа распределение значений R-квадрата, полученных за 10 прогонов необходимо использовать полученную гистограмму. Для этого: Закройте окно сообщений инструмента. На панели «Contents» (Содержание) откройте диаграмму «Validation R2» (Проверка R2). Полученная гистограмма отображает изменчивость оценки качества модели путем визуализации распределения значений R ~ квадрат, полученных за 10-ть прогонов. Среднее значение R-квадрата для 10 прогонов этой модели составляет 0,52. На панели «Содержание» откройте диаграмму «Distribution Of Variable Importance» (Распределение значимости переменных).
усами», отображено распределение значимости по 10-ти прогонам модели. Сравнение диаграмм значимостей двух показателей - Per Capita Income (дохода на душу населения в 2019 г.) и уровня образования Education: High School/No Diploma в 2019 г. (средняя школа/без диплома) частично совпадают поскольку в ряде прогонов Созданной модели более важным оказывался Per Capita Income (дохода на душу населения в 2019 г.), а в других - уровень образования Education: High School/No Diploma в 2019 г. (средняя школа/без диплома). В итоге приходим к выводу, что обе переменные представляют собой сильных кандидатов в качестве предикторов созданной прогнозной модели. Далее: На панели «Contents» (Содержание) в разделе Out_Trained_Features щелкните правой кнопкой мыши «Prediction Interval» (Интервал прогнозирования) и выберите «Open» (Открыть). Полученная диаграмма интервалов прогнозирования отображает уровень неопределенности для любого заданного значения прогноза. С помощью анализа диапазона полученных значений прогнозирования, возвращаемого отдельными деревьями в лесу, генерируются интервалы
значение. При этом, очевидно, что новые значения прогнозирования, созданные с использованием тех же независимых переменных, попадут в полученный диапазон с вероятностью 90%. Полученная диаграмма позволяет проводить оценку способности созданной модели прогнозировать искомые значения явки избирателей. Например, если бы рассчитанные доверительные интервалы явки избирателей были бы существенно шире для низких значений, то по всей видимости можно будет предполагать, что модель не так устойчива для прогнозирования в этом случае, в сравнении с прогнозированием высокой явки избирателей. В данном случае поскольку интервалы прогнозирования достаточно согласованы то это указывает на достаточно стабильное качество модели во всем исследованном диапазон. На данном этапе в созданной модели в качестве независимых переменных были использованы атрибуты из существующего набора геоданных. На следующем этапе будут использованы новые переменные, что позволит оценить их значимость для модельного прогноза. Далее: Закройте окно Charts (диаграммы) и активируйте панель «Geoprocessing» (Геообработка).
задачи по улучшению качества модельных предсказаний прогнозирования явки избирателей необходимо провести исследование значимости дополнительных переменных, отражающих влияние влияния городских агломераций, окружающих сельские территории. На этом шаге упражнения предлагается провести проверку гипотезы о влиянии расстояний от городов до территорий округов, расположенных в т.н. сельской местности. Эта гипотеза сформулирована на основе анализа организации образа жизненного пространства, широко распространенного в США, когда деятельная часть населения, живущая га территории, относимой к сельской местности, работает в расположенных поблизости городах. Для проверки этой гипотезы удобно использовать метрики расстояний от исследуемых округов, где проводится голосование, городов, расположенных на их периферии. Для решения поставленной задачи по параметризации связи между местоположением городов и округов голосования необходимо рассчитать расстояния для каждого отдельного округом до расположенными в близи него городов. После формирования соответствующей таблицы необходимо будет провести новые расчеты с уже имеющимися переменными предсказания, а также новыми добавленными переменными, характеризующими расстояния от территорий округов до местоположений городов. Эти расчеты необходимо выполнить с помощью того же инструмента, что и ранее - «Forest-Based Classification And Regression from Spatial Statistics Tools» (классификации и регрессии на основе метода Random Forest из ящика инструментов пространственной статистики). Для этого: На панели «Содержание» выключите слой Out_Trained_Features. Включите и разверните групповой слой DistanceVariables, а затем включите следующие слои: Cities10 Cities9 Cities8 Cities7 Cities6
населения в соответствующие классы. При этом в класс Cities10 включены города с наибольшим населением, а в класс Cities5, соответственно, включены города с наименьшим населением. Далее: Отключите групповой слой DistanceVariables и все слои Cities. Щелкните Cities10, чтобы выбрать его (но не устанавливайте флажок), затем нажмите Shift и щелкните Cities5. В итоге выбраны шесть переменных расстояния от городов с разной численностью населения до округов проведения голосования. Далее: Перетащите выбранные слои на панель «Геообработка» под «Explanatory Training Distance Features» (Объекты расстояний для предсказательного обучения). Щелкните по кнопке Run (Выполнить).
Out_Trained_Features и выберите «Attribute Table» (Таблица атрибутов). В таблице атрибутов «Attribute Table» прокрутите до полей атрибутов Cities. Примечание. В случае если точка, обозначающая город, находится внутри округа, расстояние будет равно нулю. В результате запуска инструмента «Forest-Based Classification And Regression» (классификации и регрессии на основе метода Random Forest) рассчитываются расстояния от каждого округа до ближайшего города всех заданных классов (ближайший город класса 5, ближайший город класса 6 и т. Д.). Рассчитанные расстояния добавляются в слой «Out_Trained_Features» в качестве отдельных полей атрибутов. Далее: Закройте таблицу атрибутов «Attribute Table». В нижней части панели «Геообработка» нажмите «View Details» (Просмотреть подробности) В окне сообщений используемого инструмента разверните «Messages» (Сообщения), а затем прокрутите до раздела Validation Data: Regression Diagnostics (Данные проверки: диагностика регрессии). В результате отмечаем, что значение метрики R-квадрат созданной с помощью улучшенной модели увеличилось до 0,614, что означает, что прогноз реализуется с точностью порядка 61% на основе использования дополнительных данных.
оценке влияния переменных расстояний на качество модели. Далее: Закройте окно сообщений инструмента. На панели «Content» (Содержание) откройте диаграмму «Distribution Of Variable Importance» (Распределение важности переменных). Из приведенной диаграммы следует, что характеристики расстояний до самых маленьких городов (Cities5) и расстояние до самых больших городов (Cities10) являются наиболее важными среди всех других характеристик расстояний. В то же самое время можно отметить, что в целом сами характеристики расстояний оказались не столь значимыми в сравнении с характеристиками, связанными с доходами и уровнем образования.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}