論文の引用数,など n べき分布に従う場合 u 将来,大きな研究成果を上げる課題について, 予め一定確率以上で予測できるのであれば, 選択と集中により,非常に大きな成果が得られる u そうでない場合,一切選択せず,広く薄くあまねく課題に 予算を付与する方が,全体として大きな成果が得られる 2 石を拾うことがあっても玉を捨てない(情報処理学会論文査読ポリシー)
The a die Fa i e E a C fe ac B e Bah e J M eThe a die C e e E i e Mabe f C befe e Fe i M ie G a ai e G e e e Babe C a e Th e P ai e M a a e Ba a ab i Li ie Fa e i B ache i e Fa i e Dah ia Ze hi e Gi e a d M eGi e a d B M eH che J dge Cha a hie B e e Che i die C che ai e Fa che e e Si ice L Gi e a d M eBa i i e M eMag i e P e c A e a W a 2 T ai Ma g e i e Pe e e W a 1 M he I ce M eB g Mag M eP e c Ba e T Chi d1 Chi d2 Na e C e DeL Geb a d Cha e cie C a a e C O dMa Laba e M eDeR I abea Ge ai Sca ff ai e B a e e G ibie J d e e M eVa b i M he P a ch Les Misérables の登場人物共起 ( Node: 77, Edge, 254 ) ランダムNW:例1 ( Node: 77, Edge, 254 ) ランダムNW:例2 ( Node: 77, Edge, 254 ) ※ ランダムNWのコネクション数は正規分布
ランダム選択で, 平均から大きくズレることは少ない n 「標準的な研究者」は考えづらい n 少数サンプリングしてきても, なかなか全体は把握しづらい n ランダム選択だと, 試行のたびに結果が大きくズレる 予測不可能性 な状態であれば,基本戦略はランダム選択 よく分からないなら適当に選ぶしかない(適当に選んだ方がよい)
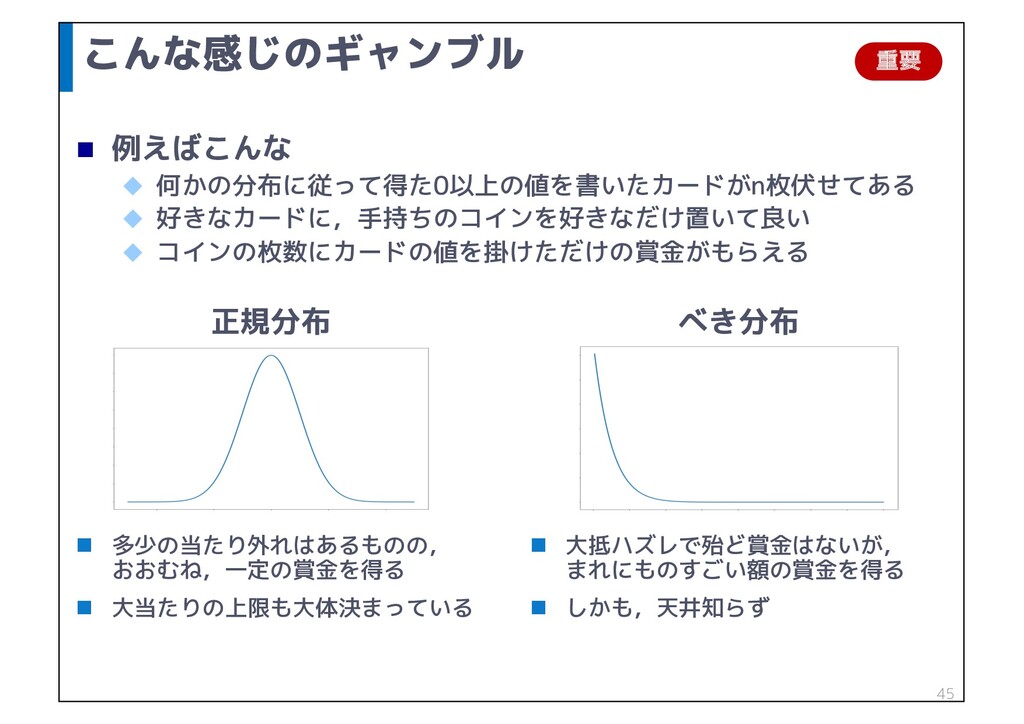
p 1.0 だと,損も得もしない p 1.1 だと,投資額の 1.1倍 の利益 p 0.1 だと,投資額の 0.1倍 の利益 = 0.9倍 の損益 u f(x) は ある価値 x を生み出せる人の人数 p 多くの人は利益をあげることができない p 同じ投資で大きな利益をあげられる人の割合は利益の大きさに 応じて少なくなっていく(が,全くいなくなるわけでもない) 重要
100枚引くと,90枚は1未満の値,9枚は10未満,1枚は10以上の値 p 1000枚引くと,900枚は1未満の値,90枚は10未満,9枚は100未満, 1枚は100以上の値 u …という,べき分布に従ってカードが出てくる u 毎回,手持ちのコインの枚数を上限に好きなだけカードを引いて, ギャンブルを行うことができる 48 コイン&カードの枚数は,どの位が一番儲かるか???
カードは任意の枚数(n枚)引くことができる u プレイヤーはカードと同数のコインをもらえる p 好きなカードに,手持ちのコインを好きなだけ置くことができる u カードをめくって書いてある数字に,コインの枚数を掛けただけ, ポイントがもらえる p ポイントが元のコインの枚数(n)を越えていたら勝ち 93 ※ 正確には以前算出した γ より大きい 重要
u コインの数を上限として,その中でセレクションを行う事で, 全部のカードにコインを置いた場合との比較も可能になります n ランダムにカードを引くのなら,ものすごく良いカードが まとまって出てくる可能性もあるのでは u その通りです.従って複数回試行する必要があります. u 実際,べき分布 では「ものすごく高価値なカード」が出てしまい, 妙なことになるケースもそこそこ発生し得ます 97
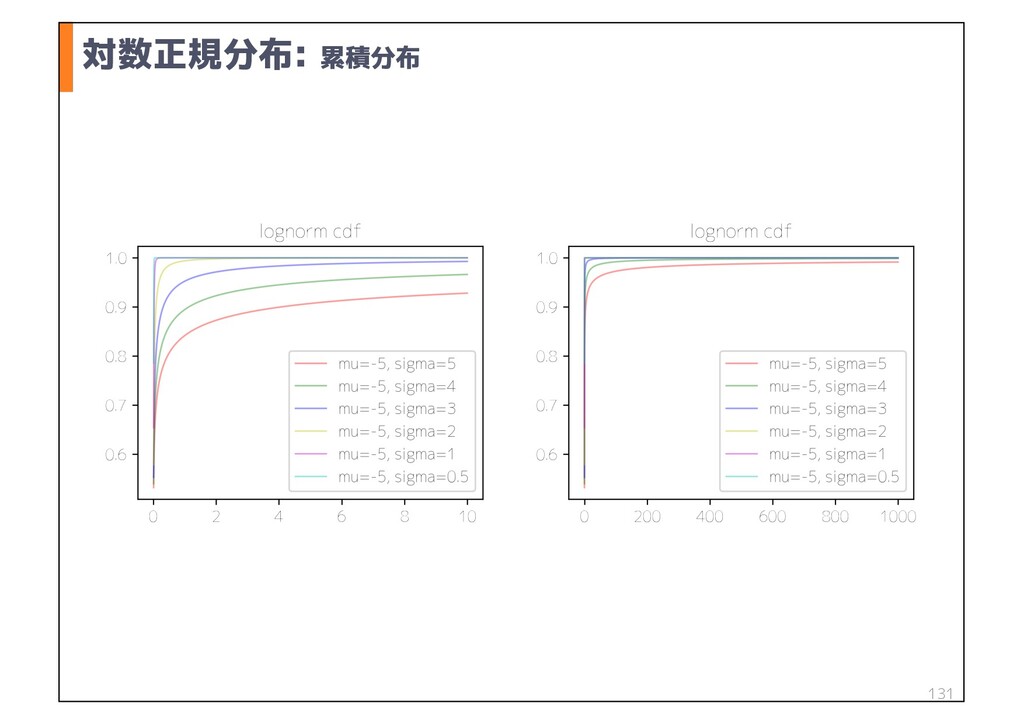
n べき分布 など 任意の確率分布 に基づく乱数生成の方法 u 確率密度分布を直接考えるのは難しい u 確率累積分布であれば,範囲は確実に0-1の範囲に収まる p 累積なので,確率密度関数がどれだけ複雑でも,微分値は負にならない u 0−1の範囲で 一様分布 に基づく乱数生成は容易 u 例えば累積分布が 90% の時の x を求めることができればよい p 一様分布に基づく乱数から,任意の確率密度関数に基づく乱数が出る 98 ※ 正確には疑似乱数 累積分布の逆関数 G(F(X)) を求めれば良い
2値予測の場合,価値1 or 0 で,1のものにランダムに投資 u 数値予測の場合は,具体価値に沿って順に投資 u ランダム投資なら平均的には 予測ミスが打ち消される u 数値予測の場合,読み間違えで 大当たり を逆に逃す可能性向上? 116 あえて粗い予測をする方が,かえって有利 u 明日の14時12分から48分間 雨が降る u 明日か明後日に 雨が降る
という設定 u 研究分野毎に 1 単位 の実際の金額は大きく異なる n 収穫期への注意 u 今回は 投資後,全ての成果の利益を回収できている設定 u 実際には成果が出るまでの期間も様々 p しばらく何の成果も無く一定期間後に大きな成果を挙げるもの p 期間中すこしずつ,広く薄く成果を挙げるもの p すぐに成果を挙げるもの,…など n 予測についての注意 u 予測には様々なバイアスもかかる u 大きな成果を挙げる,ディストラクティブなイノベーションになるほど, 逆に「そんなことはあり得ない・無理だ」と,積極的に捨てる可能性も n 内容面についての注意 u 絞り込み時 の 予測 は確率が絡むので本来は複数回試行が必要(現状は1試行) 122 重要
論文の引用数,など n べき分布に従う場合 u 将来,大きな研究成果を上げる課題について, 予め一定確率以上で予測できるのであれば, 選択と集中により,非常に大きな成果が得られる u そうでない場合,一切選択せず,広く薄くあまねく課題に 予算を付与する方が,全体として大きな成果が得られる 124 石を拾うことがあっても玉を捨てない(情報処理学会論文査読ポリシー)
各マシンに過去,いくら入れていくら儲けたか,記録済み u どのマシンに賭けるか? u 強化学習の古典的問題のひとつ u いろいろな解法や,応用問題がある p 応用問題:途中でマシンの報酬確率が変わる…など n スロットマシンを研究者に置き換えれば,数値解析的に どういう風な資金配分戦略がベターか導ける可能性 125
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![べき分布と期待値 68 n 上記の場合に E[X]=1 より, それ以上であれば期待値は1を超える! ところで は 何であったか?](https://files.speakerdeck.com/presentations/0fe987747e524f67894cd34d919de370/slide_67.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}