by Dustin Wright, Sarah Masud, Jared Moore, Srishti Yadav, Maria Antoniak, Peter Ebert Christensen, Chan Young Park, Isabelle Augenstein PyCon DE, 2026
Model (LLM) or AI Chat System to describe a concept, eg “Democracy” • You have examined your 10th prompt variant. • Lost track of unique information captured by multiple prompt variants. • Thinking “what would Google say?”.
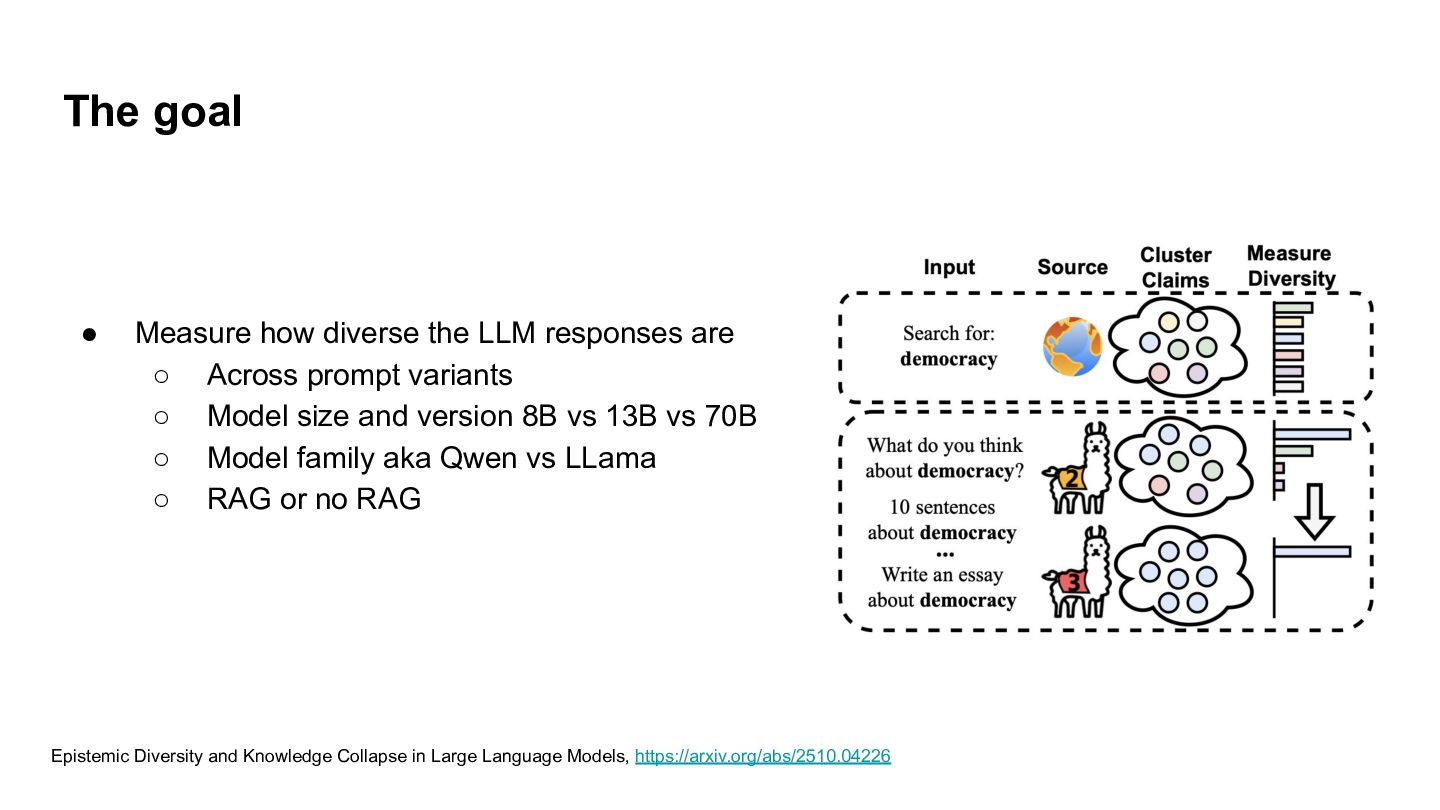
◦ Across prompt variants ◦ Model size and version 8B vs 13B vs 70B ◦ Model family aka Qwen vs LLama ◦ RAG or no RAG Epistemic Diversity and Knowledge Collapse in Large Language Models, https://arxiv.org/abs/2510.04226
a list of information about a topic say “democracy”. • A simple approach: count the items in the list. ◦ ✅ More items → more diversity? • Loophole? ◦ 🤔 What about synonms/similar sentences that can conflate the results?
a list of information about a topic say “democracy”. • Better approach: cluster the sentences. • ✅ More clusters → more unique types of information → more diversity? • Loophole? ◦ 🤔 What about long tail, a model produces many singleton clusters aka noisy clusters.
a list of information about a topic say “democracy”. • Better approach: cluster the sentences. • ✅ More clusters → more unique types of information → more diversity? • Can all the sentences/claims in this cluster answer a specific question about that topic and no more. Epistemic Diversity and Knowledge Collapse in Large Language Models, https://arxiv.org/abs/2510.04226
a list of information about a topic say “democracy”. • Better approach: cluster the sentences. • Loophole? ◦ 🤔 What about long tail, a model produces many singleton clusters aka noisy clusters. • ❌ Naively counting number of items or number of clusters is not a good measure.
a list of information about a topic say “democracy”. • Even better approach: Measure entropy of cluster sizes instead. • ✅ Uneven cluster sizes (low diversity) → balanced cluster sizes (higher diversity) Number of clusters obtained for model m when prompted for topic t. Size of the cluster i.e number of claims in ith cluster/ total number of claims for model m when prompted for topic t.
a list of information about a topic say “democracy”. • Even better approach: Measure Hill-Shannon entropy of cluster sizes instead. • ✅ Exponent of log → We are back to linear scale now!
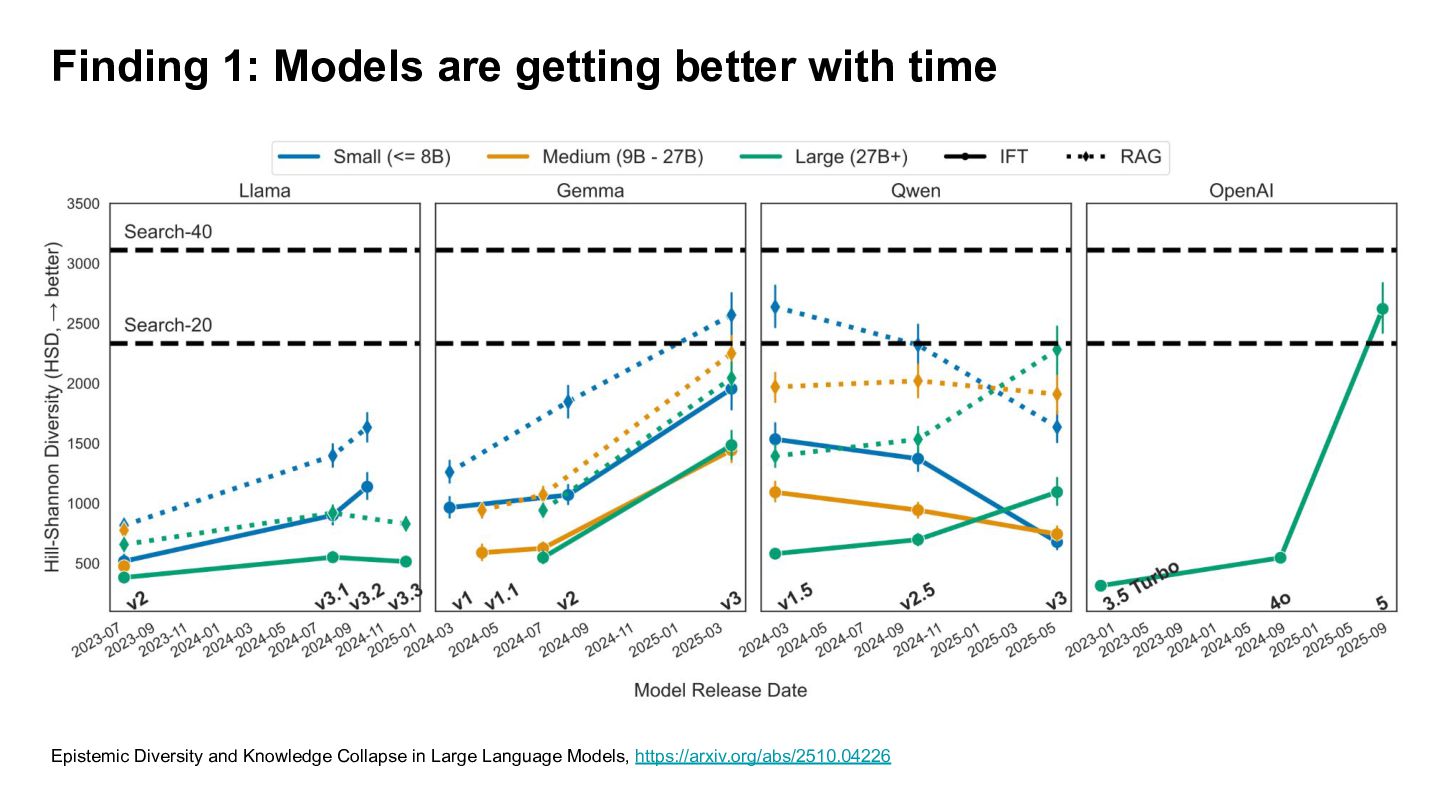
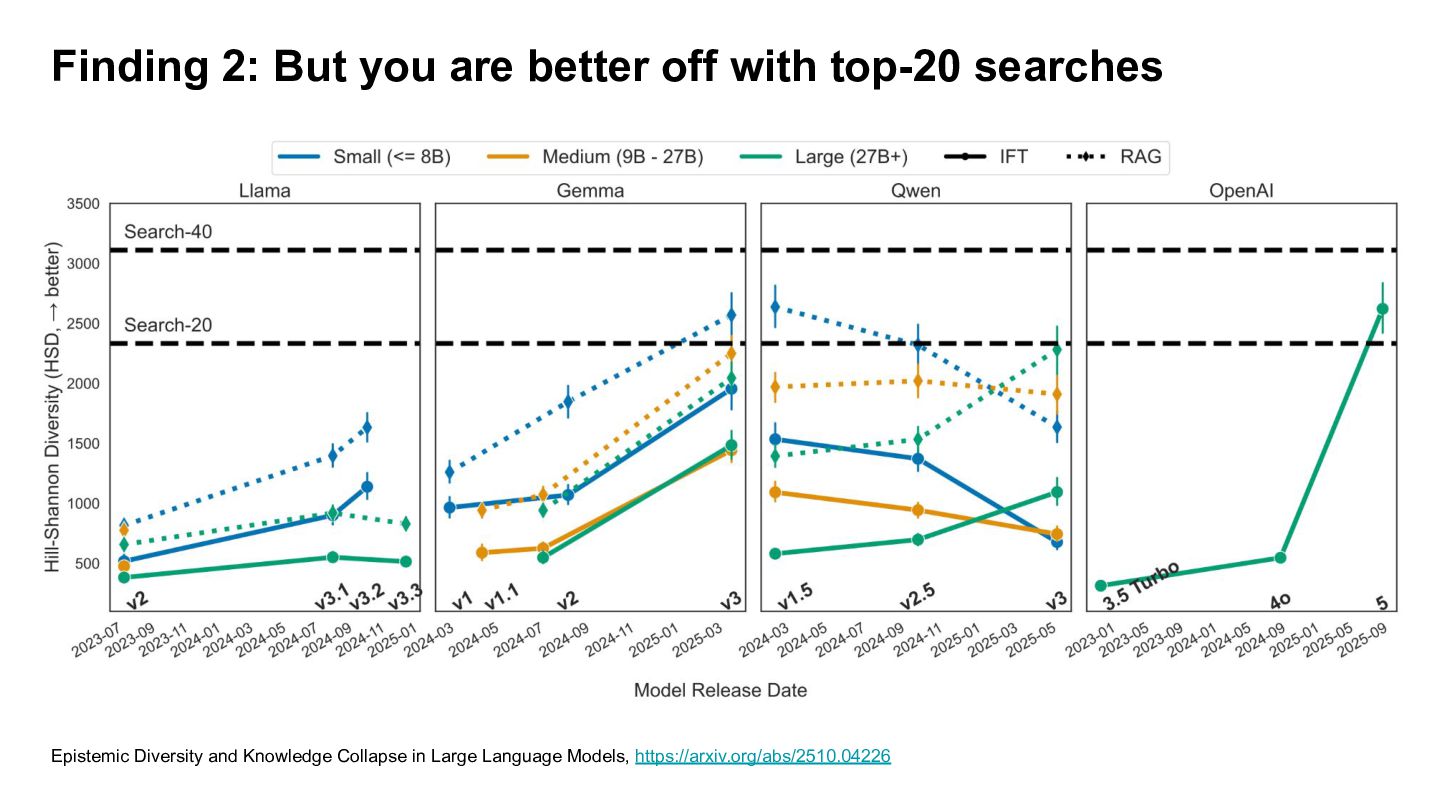
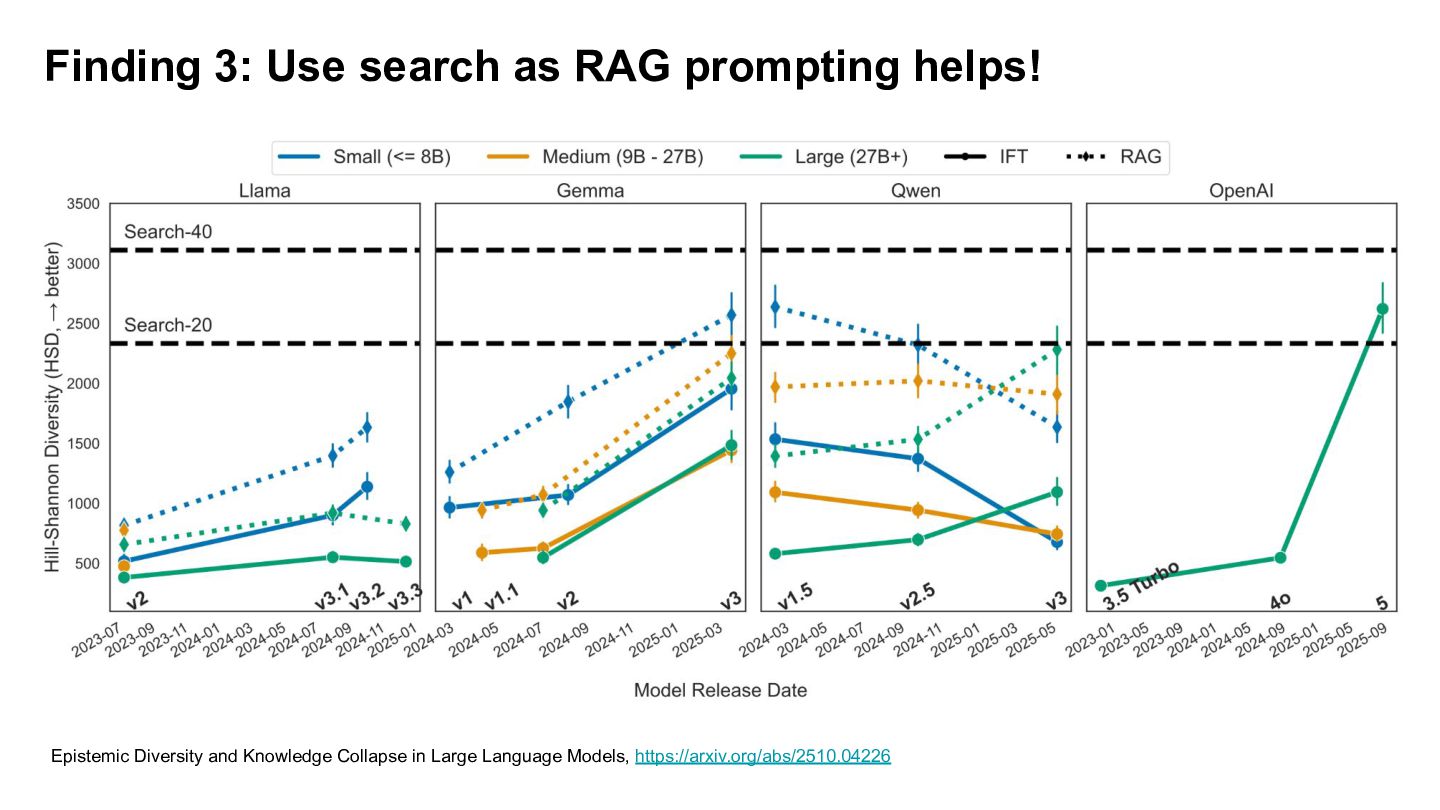
• Use top-40, top-20 Google-USA search result as baseline. • Use 27 LLMs of varing size, family and release dates. • Prompt each LLM with 200 input variation of writing/information seeking. • RAG vs non-RAG • Cluster for each system and obtain it's diversity score. Epistemic Diversity and Knowledge Collapse in Large Language Models, https://arxiv.org/abs/2510.04226
agree → Don’t trust a single model → Compare outputs across multiple LLMs. • Open‑weight models tend to agree more with each other. → Better for consistency. • Search ≠ LLMs → use it to spot what LLMs might miss. Epistemic Diversity and Knowledge Collapse in Large Language Models, https://arxiv.org/abs/2510.04226 Similarity = 1- Divergence
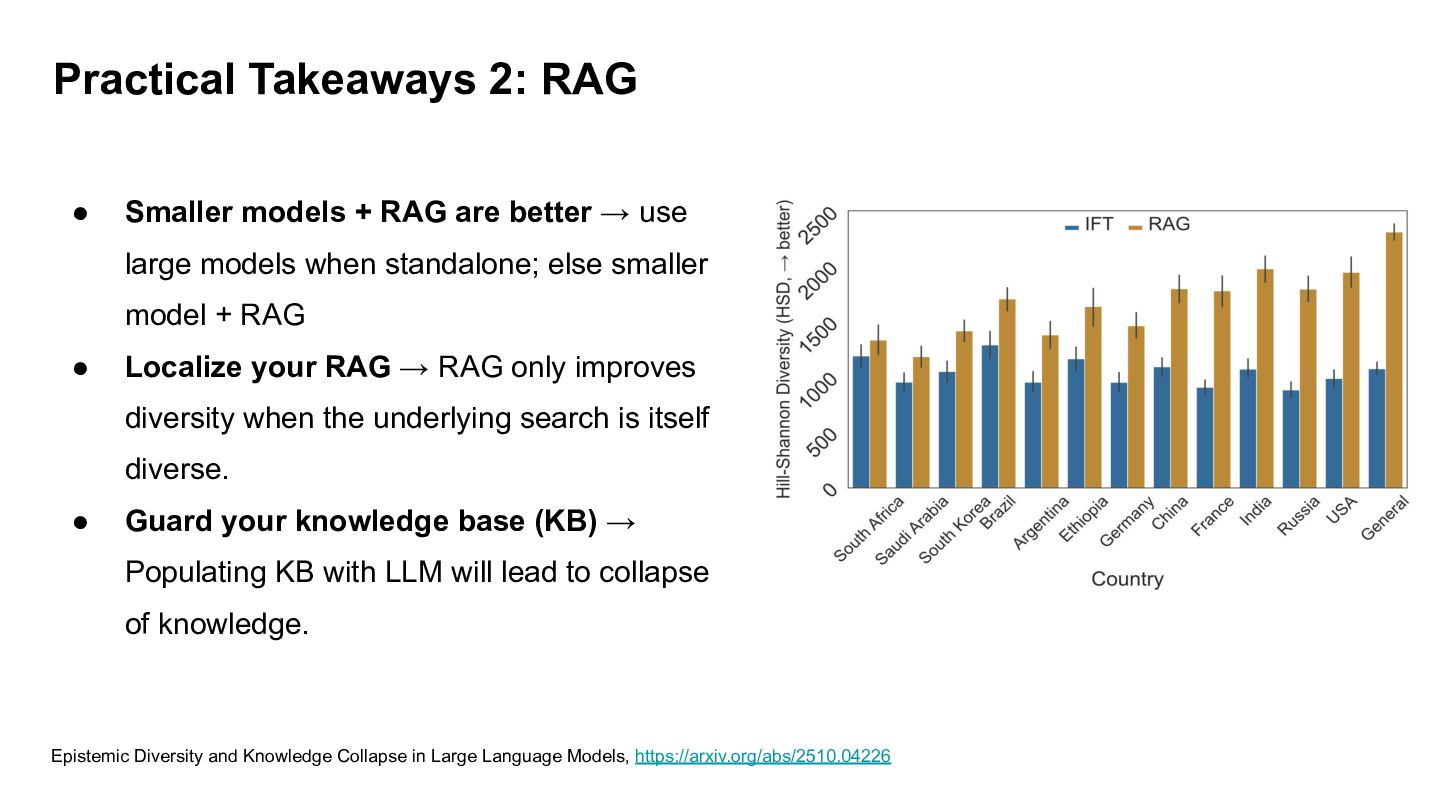
better → use large models when standalone; else smaller model + RAG • Localize your RAG → RAG only improves diversity when the underlying search is itself diverse. • Guard your knowledge base (KB) → Populating KB with LLM will lead to collapse of knowledge. Epistemic Diversity and Knowledge Collapse in Large Language Models, https://arxiv.org/abs/2510.04226
on our research by Dustin Wright, Sarah Masud, Jared Moore, Srishti Yadav, Maria Antoniak, Peter Ebert Christensen, Chan Young Park, Isabelle Augenstein PyCon DE, 2026
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}