Abstract
Despite our best efforts, tackling hate speech remains an elusive issue for researchers and practitioners alike. What can be considered hateful is subject to context, time, geography, and culture. This poses a challenge in defining standard benchmarks and modelling techniques to combat hate. However, what underpins hate is universally accepted as the intent of dehumanising and biasing against a historically vulnerable group. Unfortunately, determining both intent and power dynamics in an online setting is formidable; further, the influence of the human evaluator's lived experiences creates a gap in the human and computational understanding of hatefulness.
By examining the role of external priming via contextual signals, we aim to bridge this information gap and improve the human-computer alignment for analysing and monitoring hateful content on the Web.
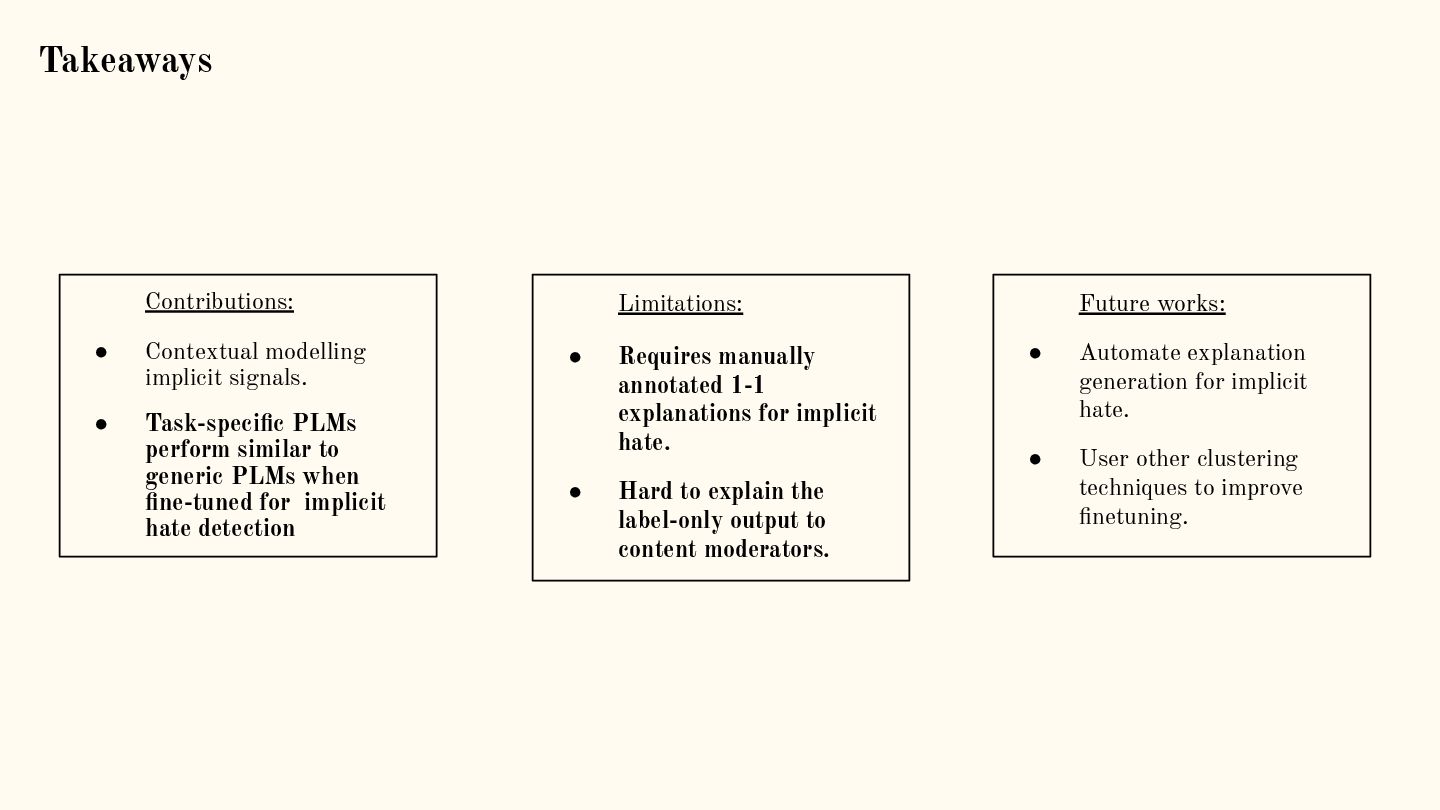
Through a series of five datasets and model pairs, the thesis empirically establishes the efficacy of contextual signals in modelling hate speech-related tasks. The compelling use of contextual signals gets further solidified as our findings apply to any pipeline from feature-engineered logistic regressor to zero-shot prompted large language models. However, we caution against using a one-size-fits-all setup by quantifying the toxic connotations and scalability challenges of certain signals. To this end, the thesis outlines strategies for deployable, human-centric tools for reactive and proactive moderation paradigms, focusing on the multilingual and implicit nature of hate.
{kind=link}
{kind=link}
{kind=link}
![Broad Scope [1]: https://www.un.org/en/hate-speech/understanding-hate-speech/what-is-hate-speech We focus on textual modality with](https://files.speakerdeck.com/presentations/e5606d469e87401680b84d1483689886/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
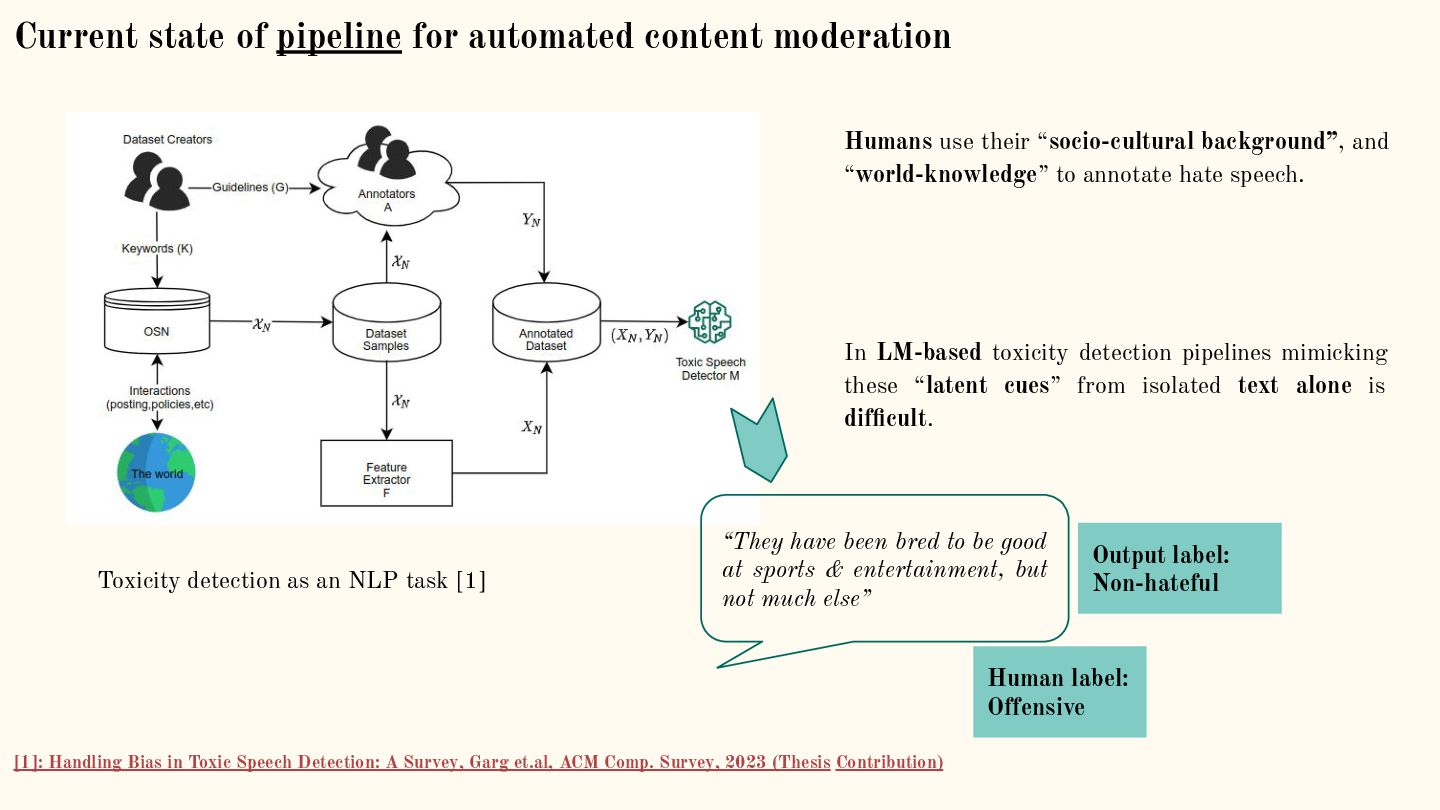{kind=link}
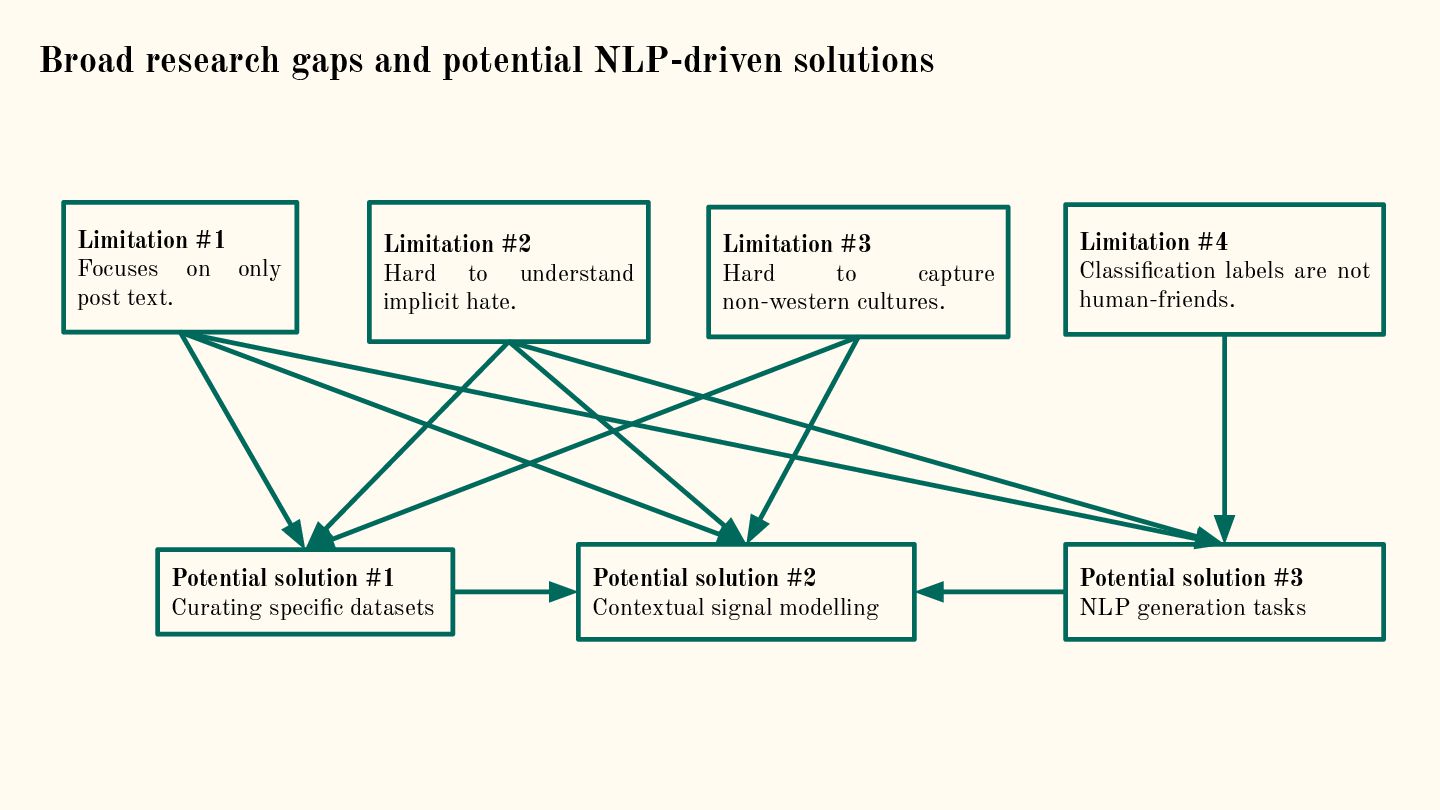{kind=link}
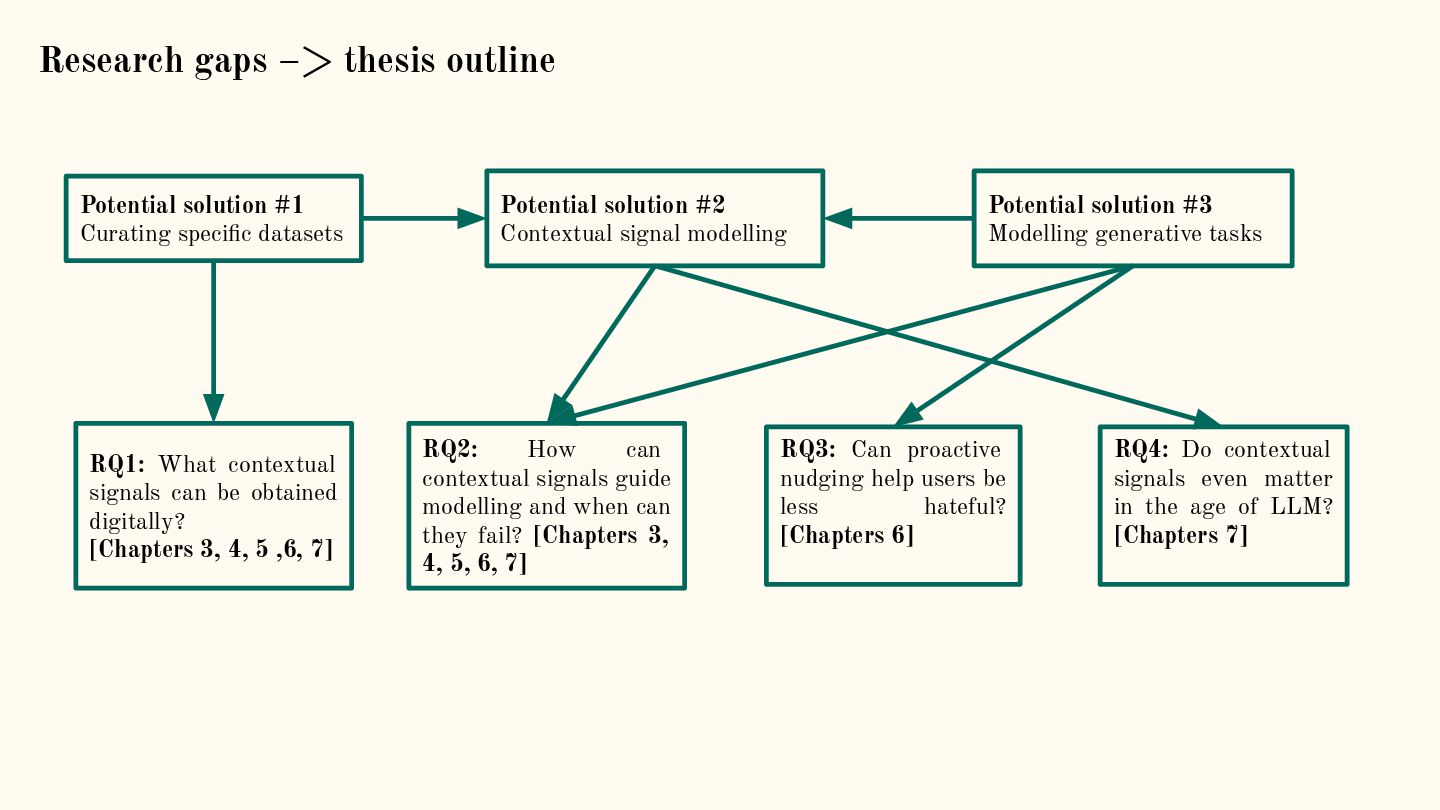{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
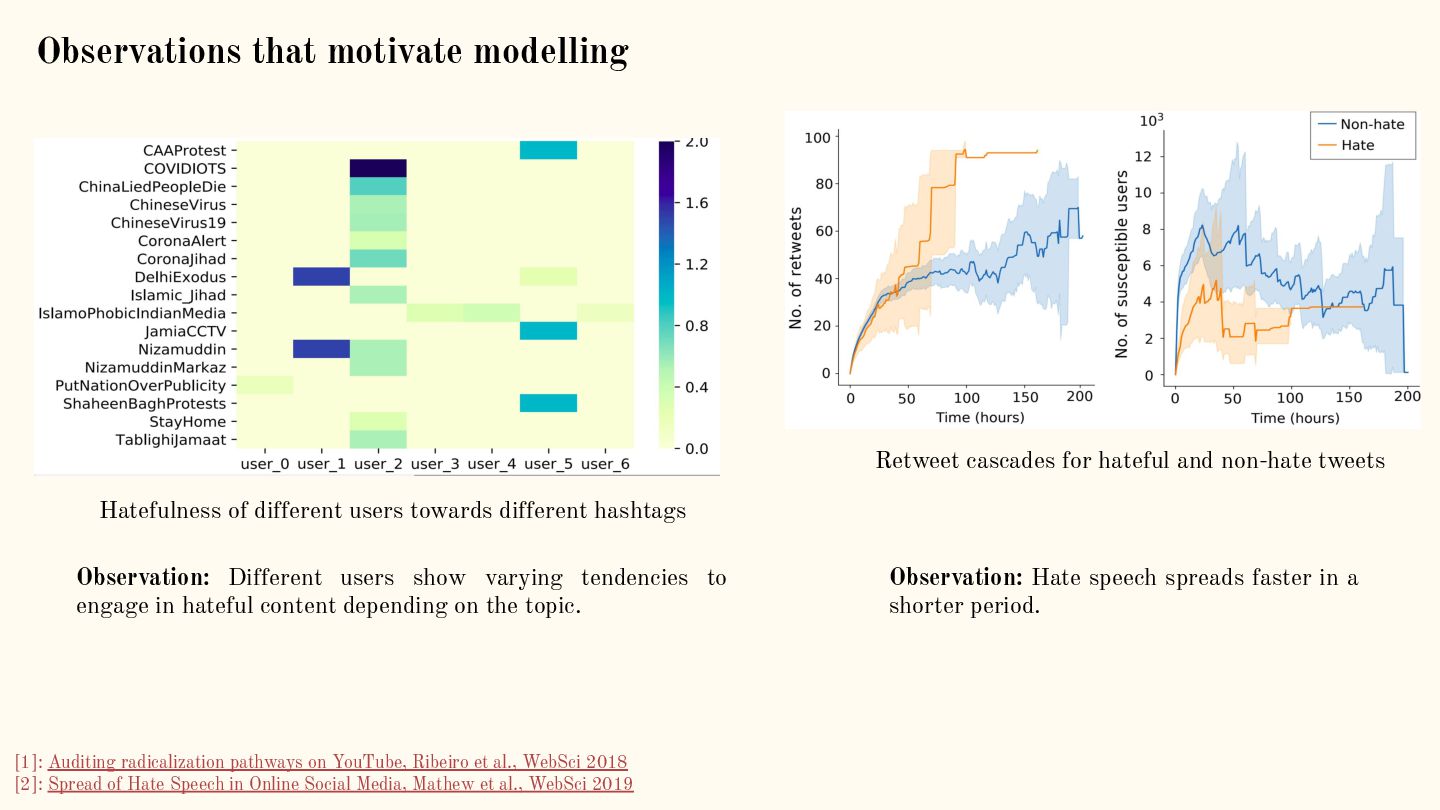{kind=link}
{kind=link}
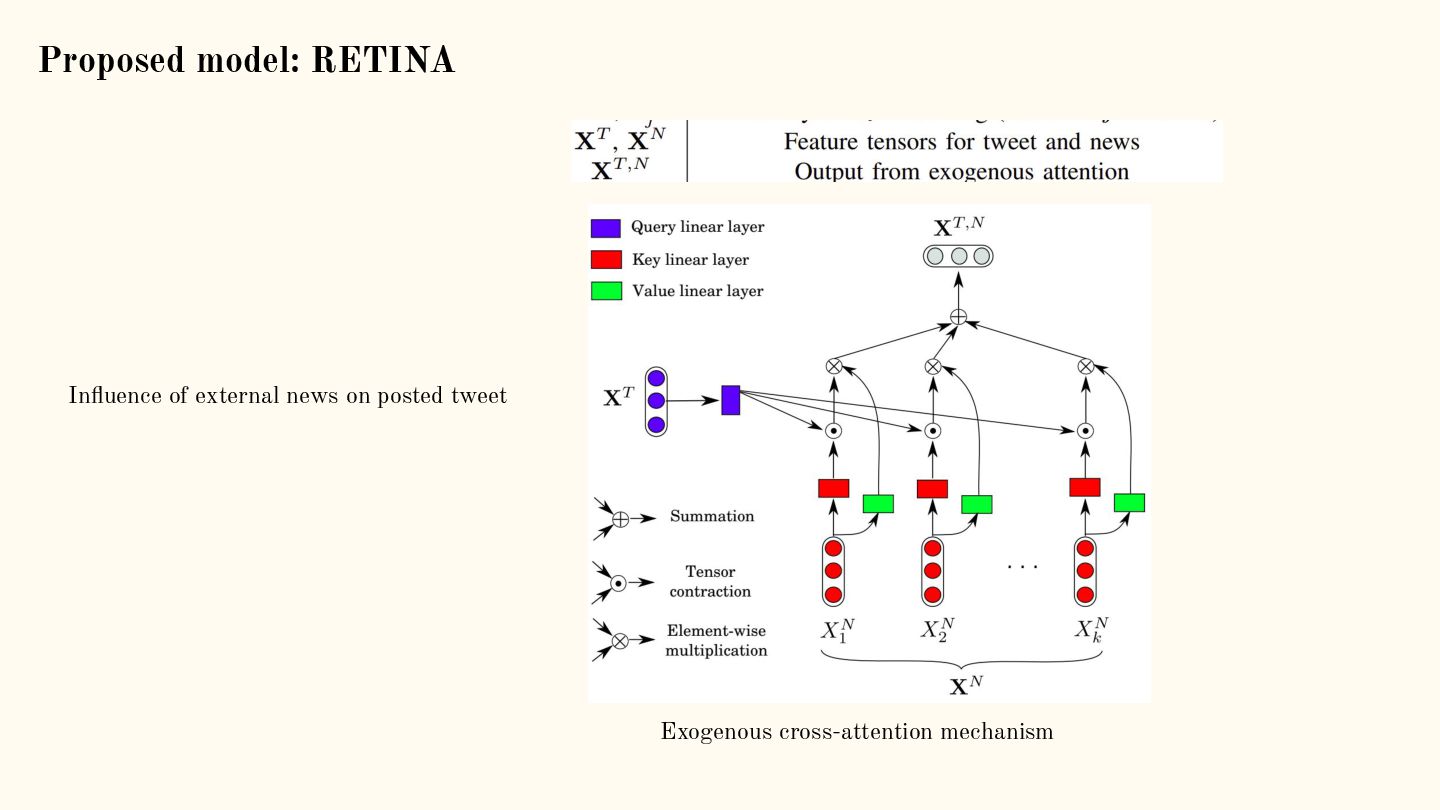{kind=link}
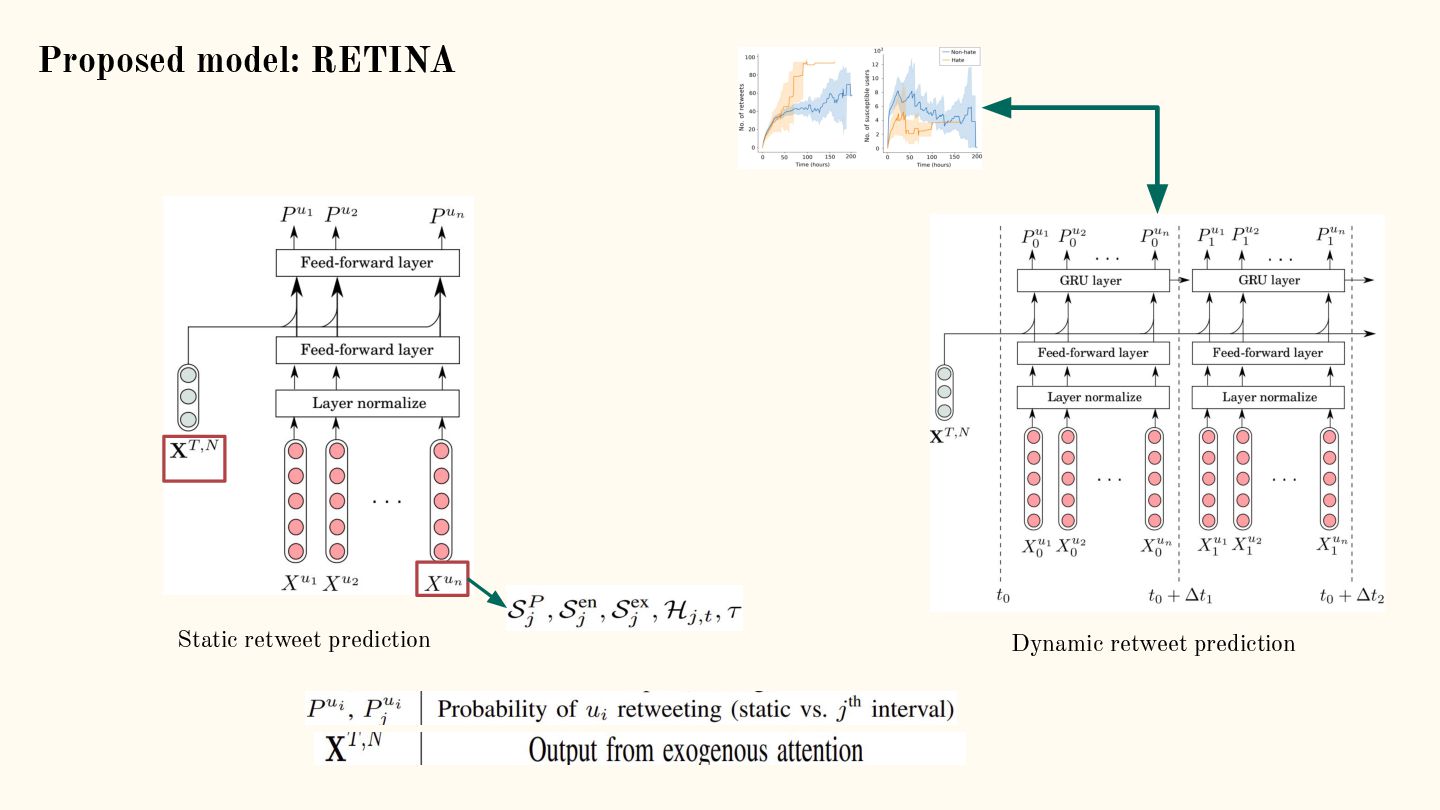{kind=link}
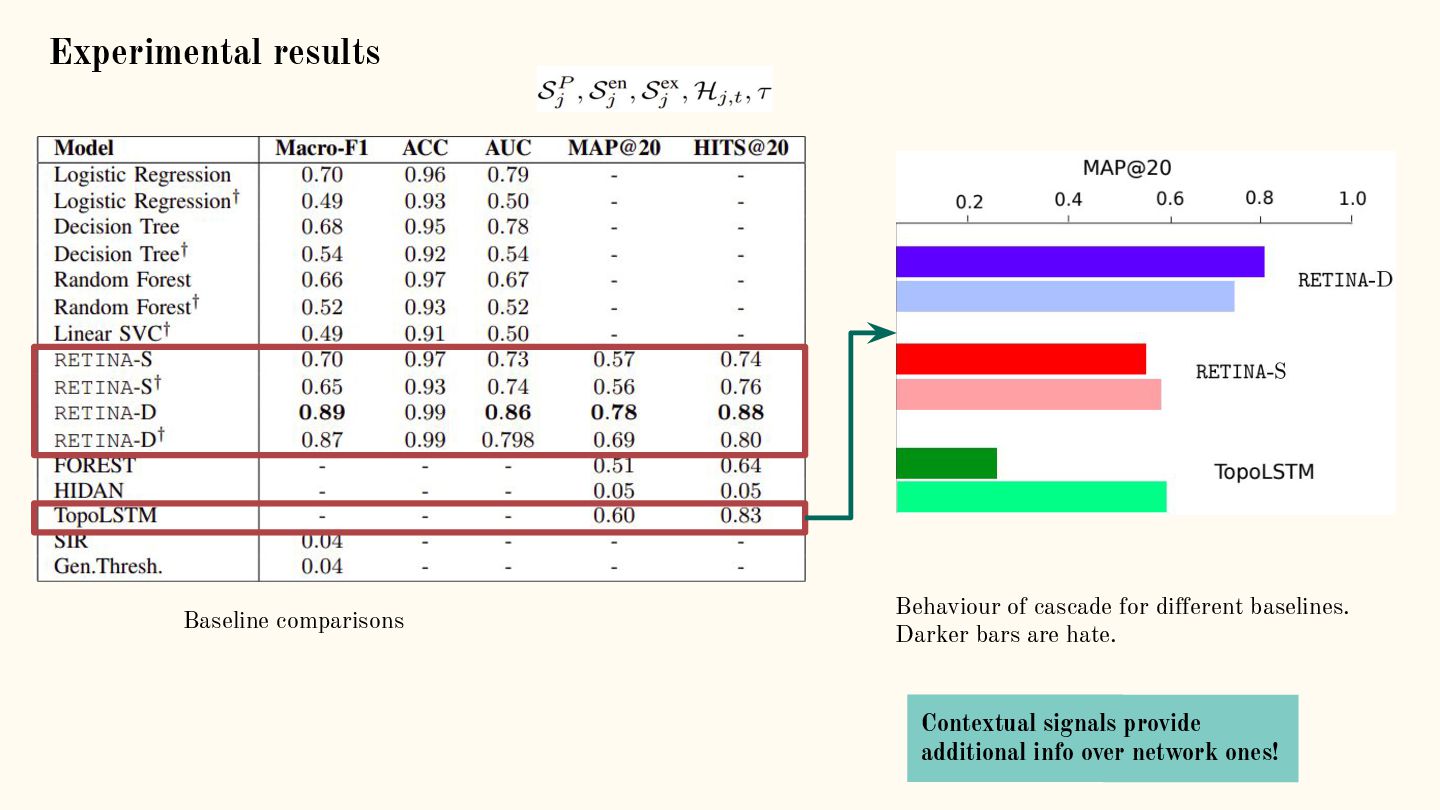{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
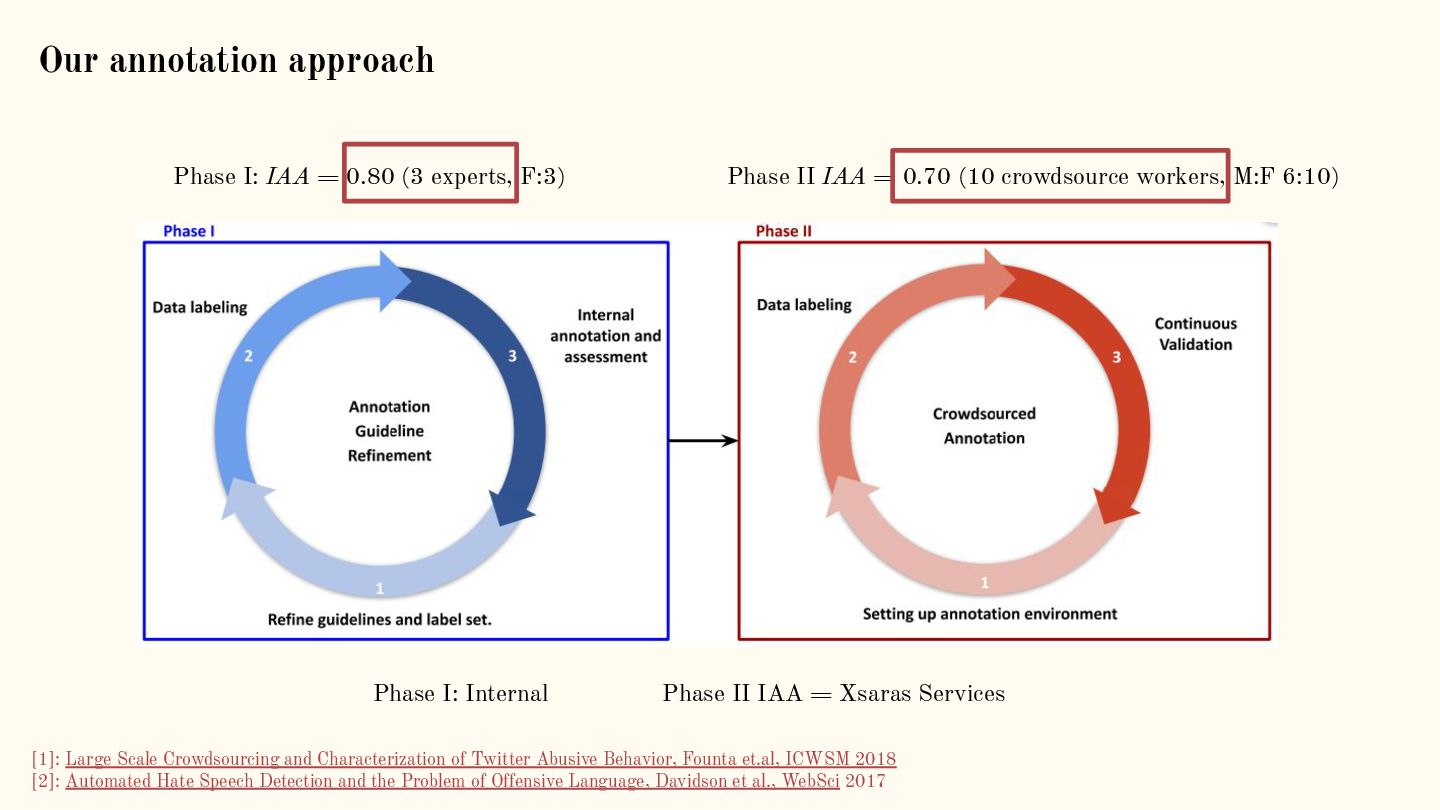{kind=link}
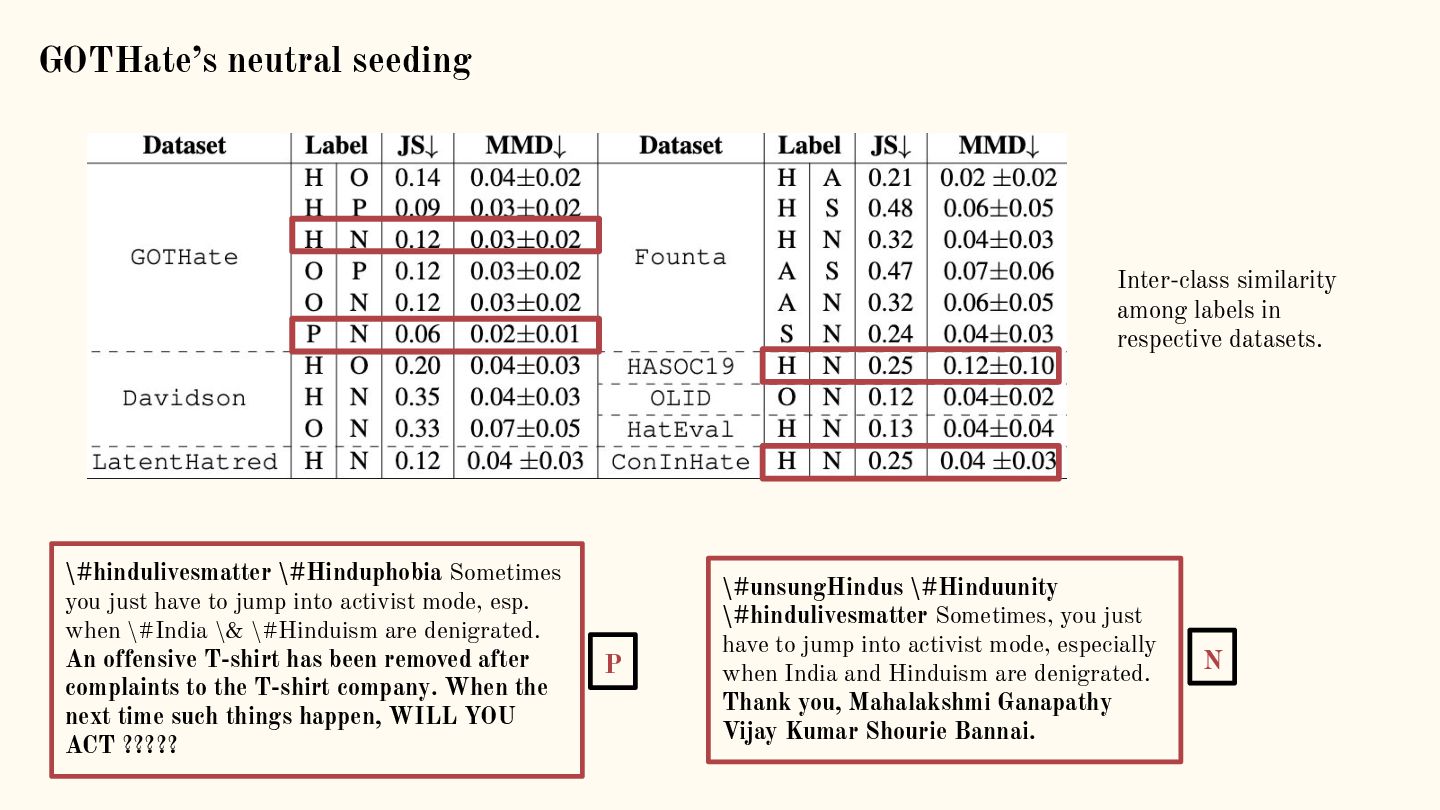{kind=link}
{kind=link}
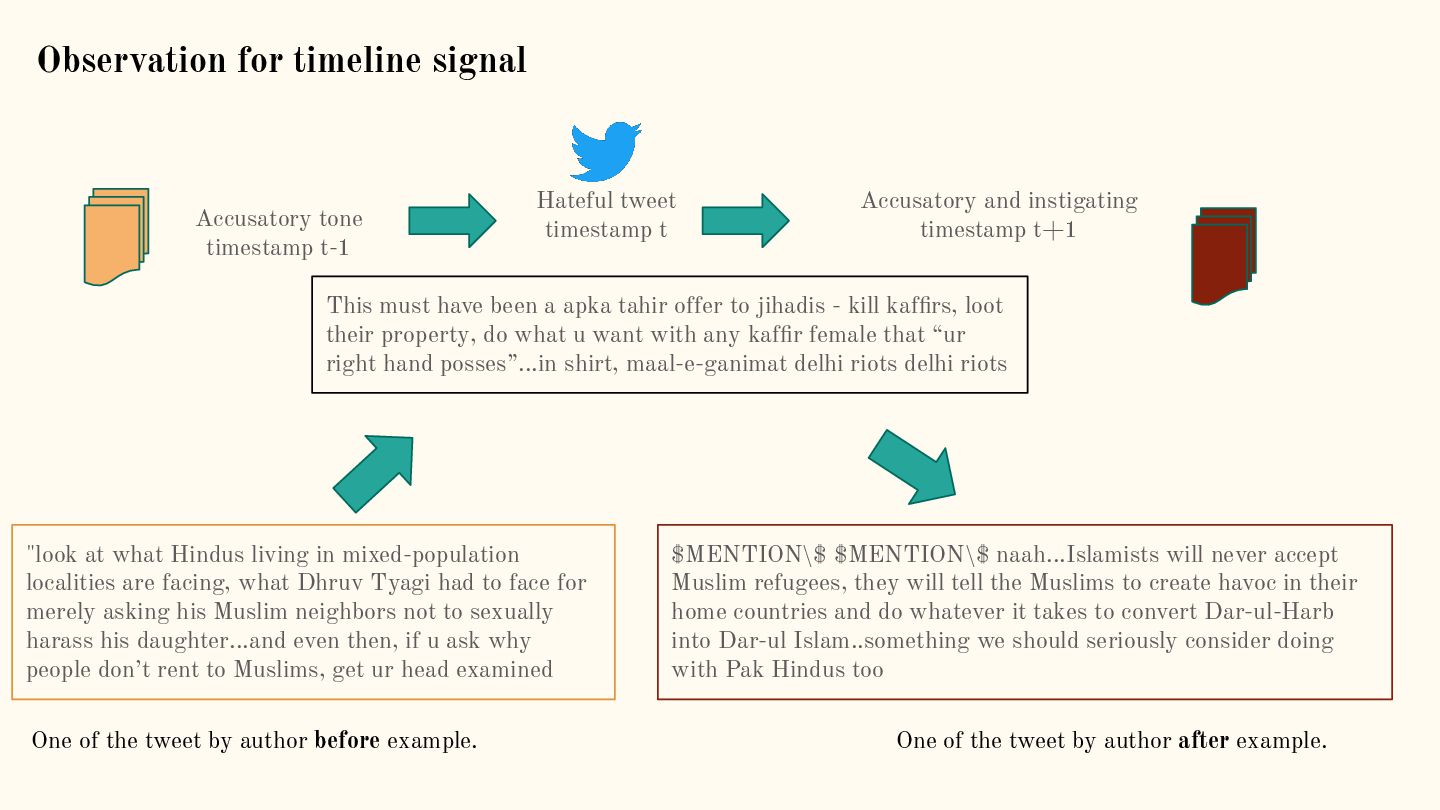{kind=link}
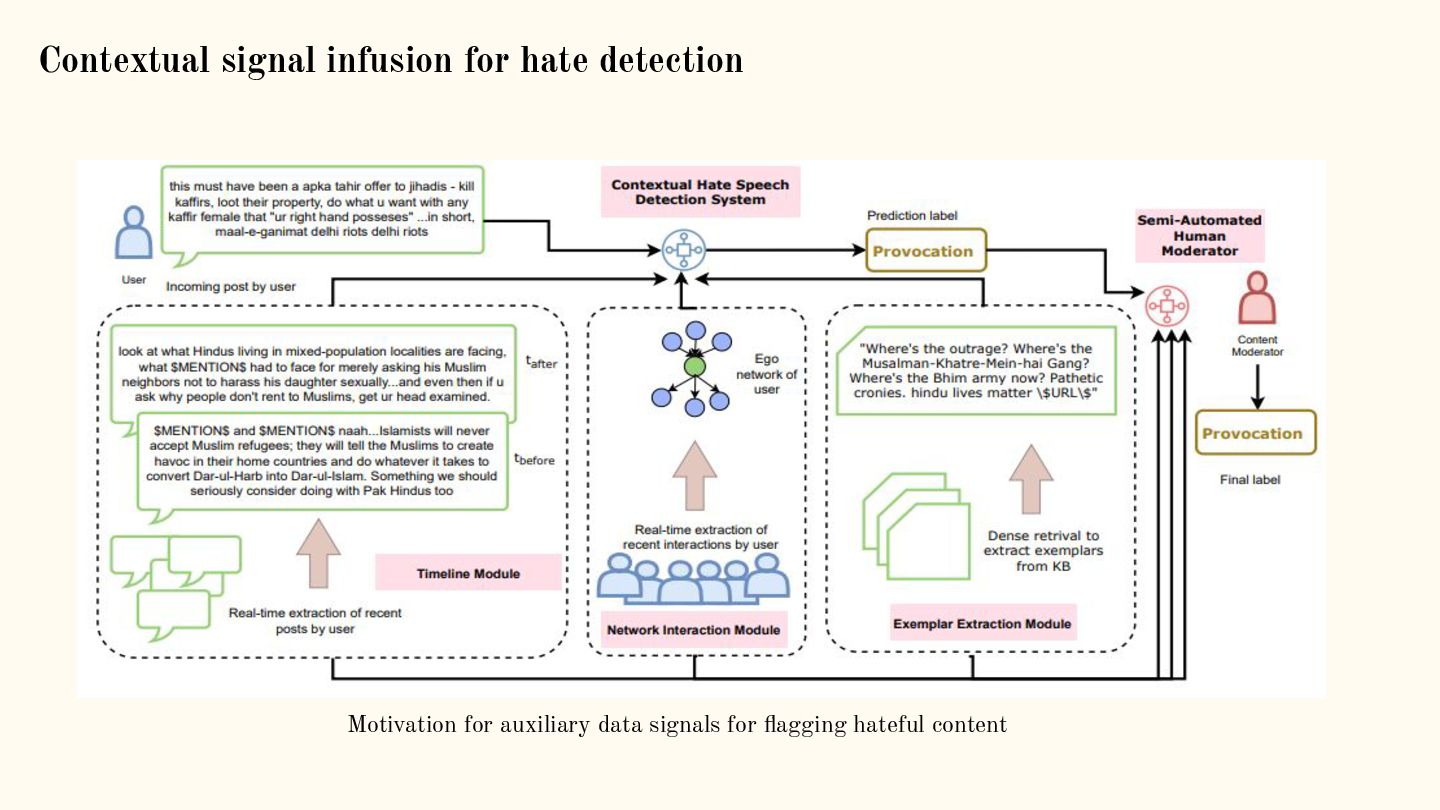{kind=link}
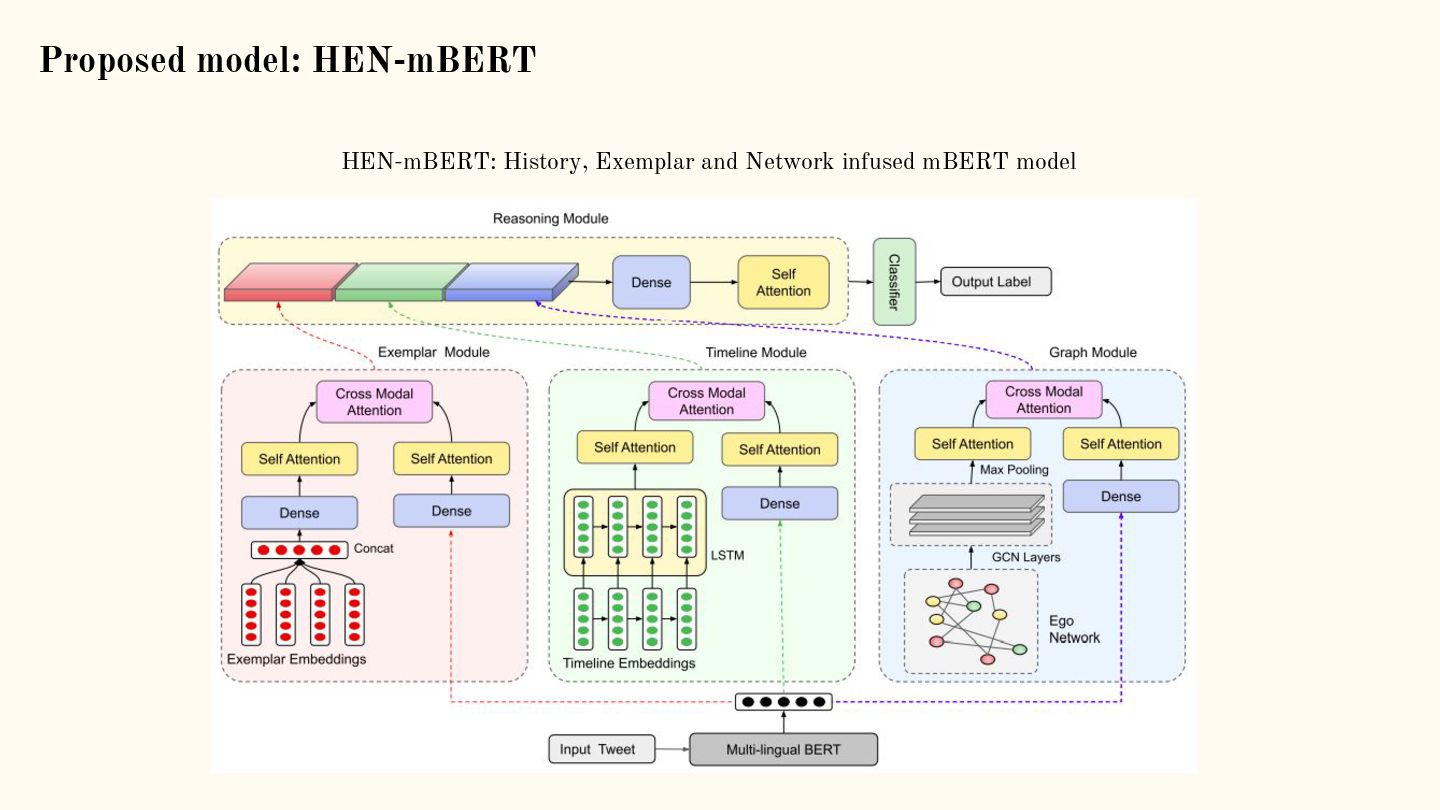{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
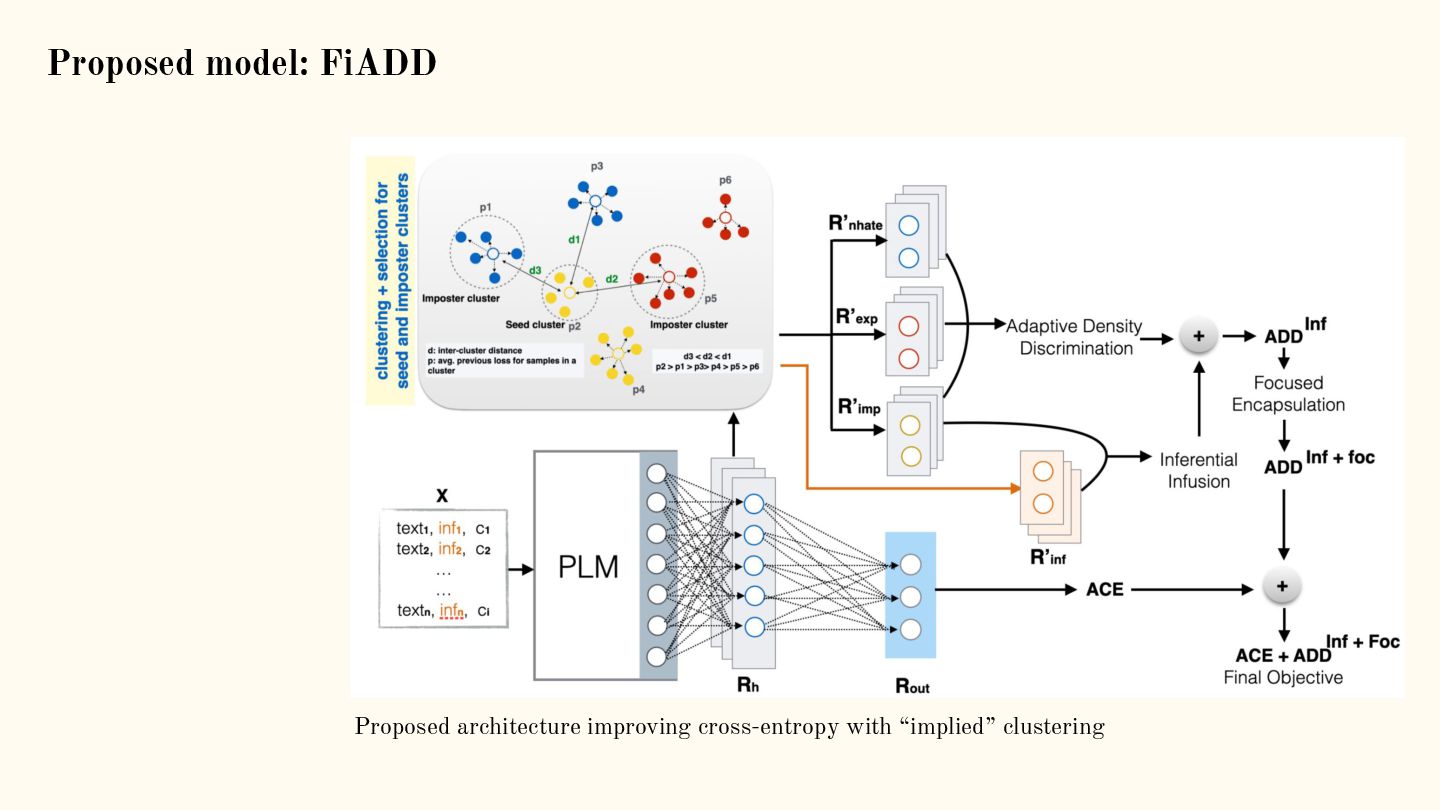
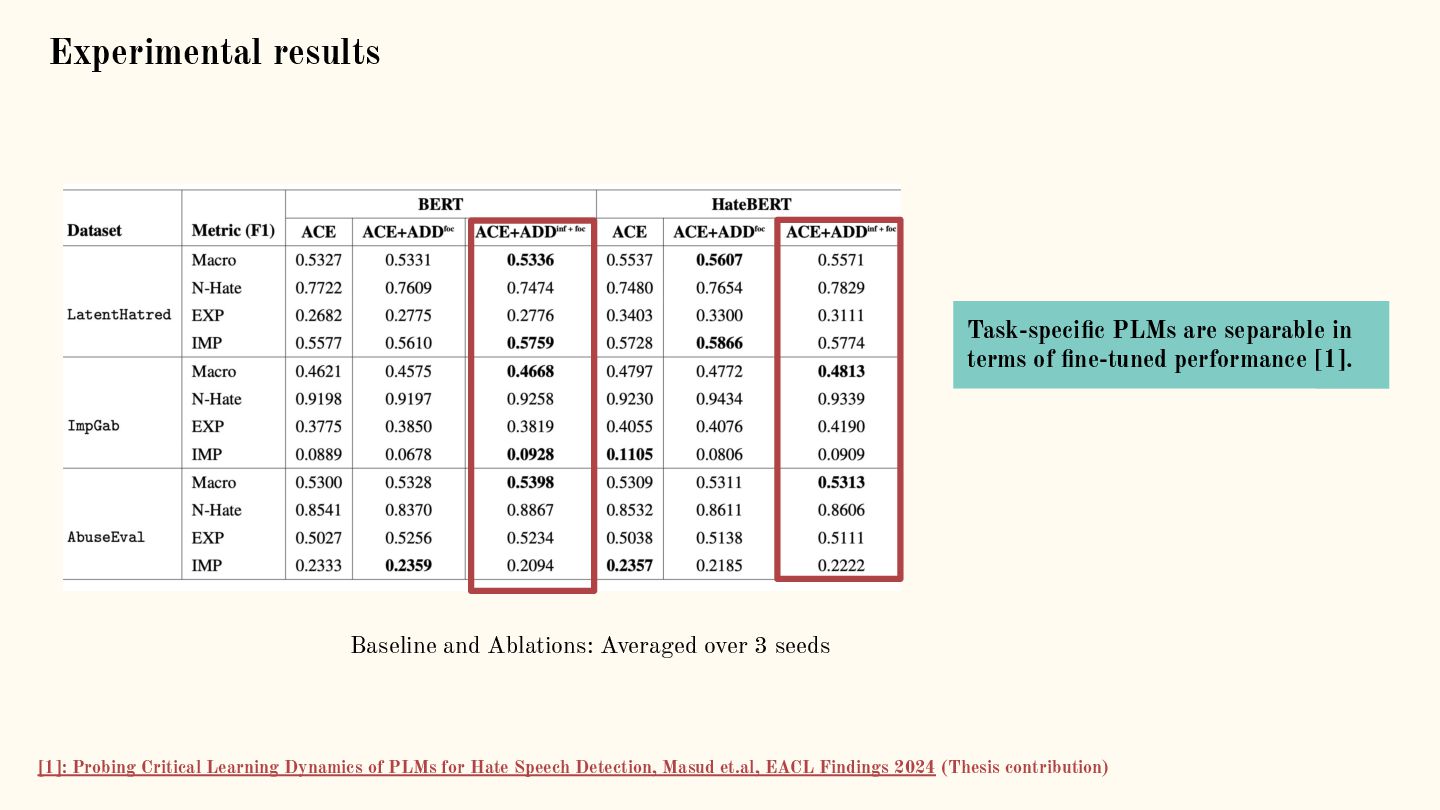
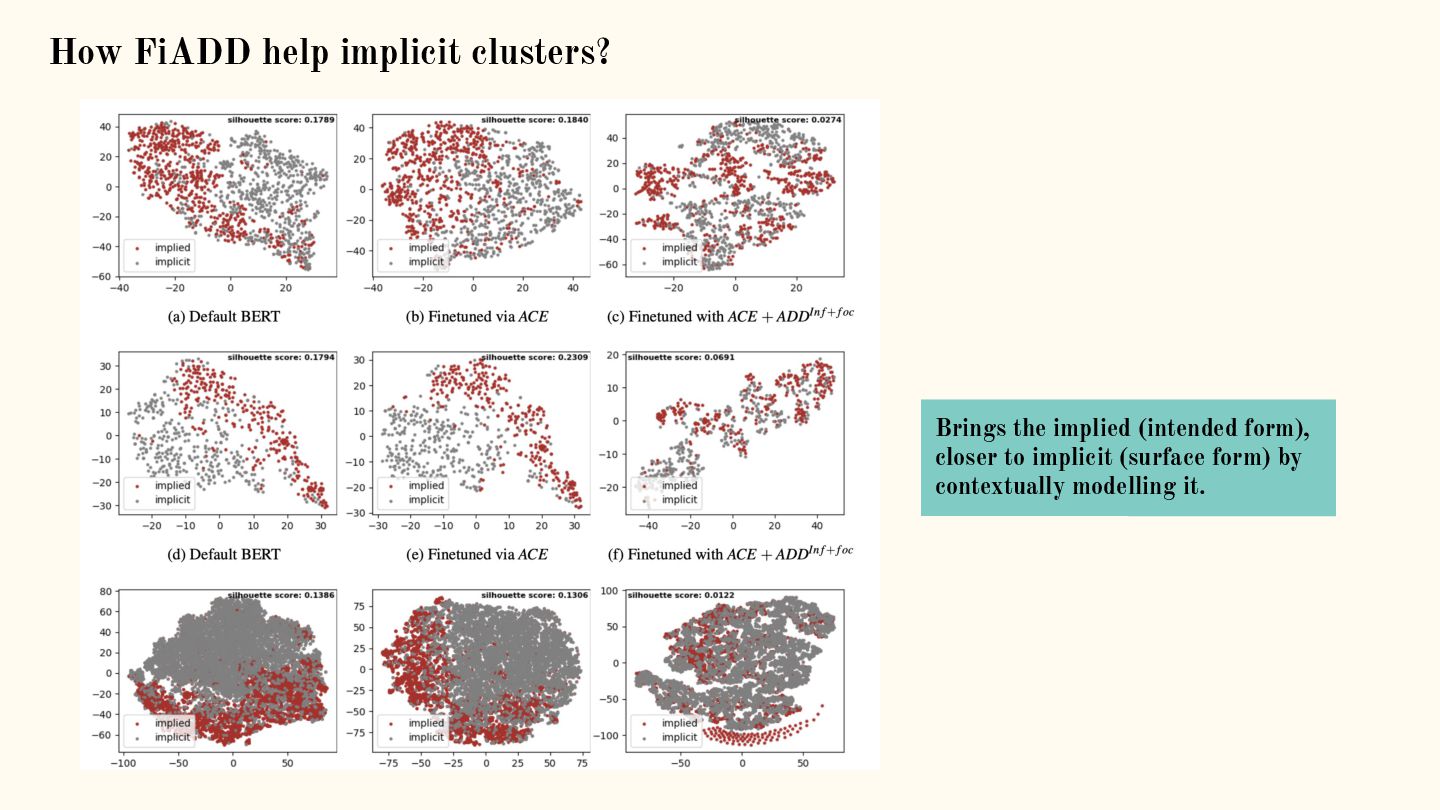
![Adaptive density discrimination (ADD) for implicit hate [1]: Metric Learning](https://files.speakerdeck.com/presentations/e5606d469e87401680b84d1483689886/slide_39.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
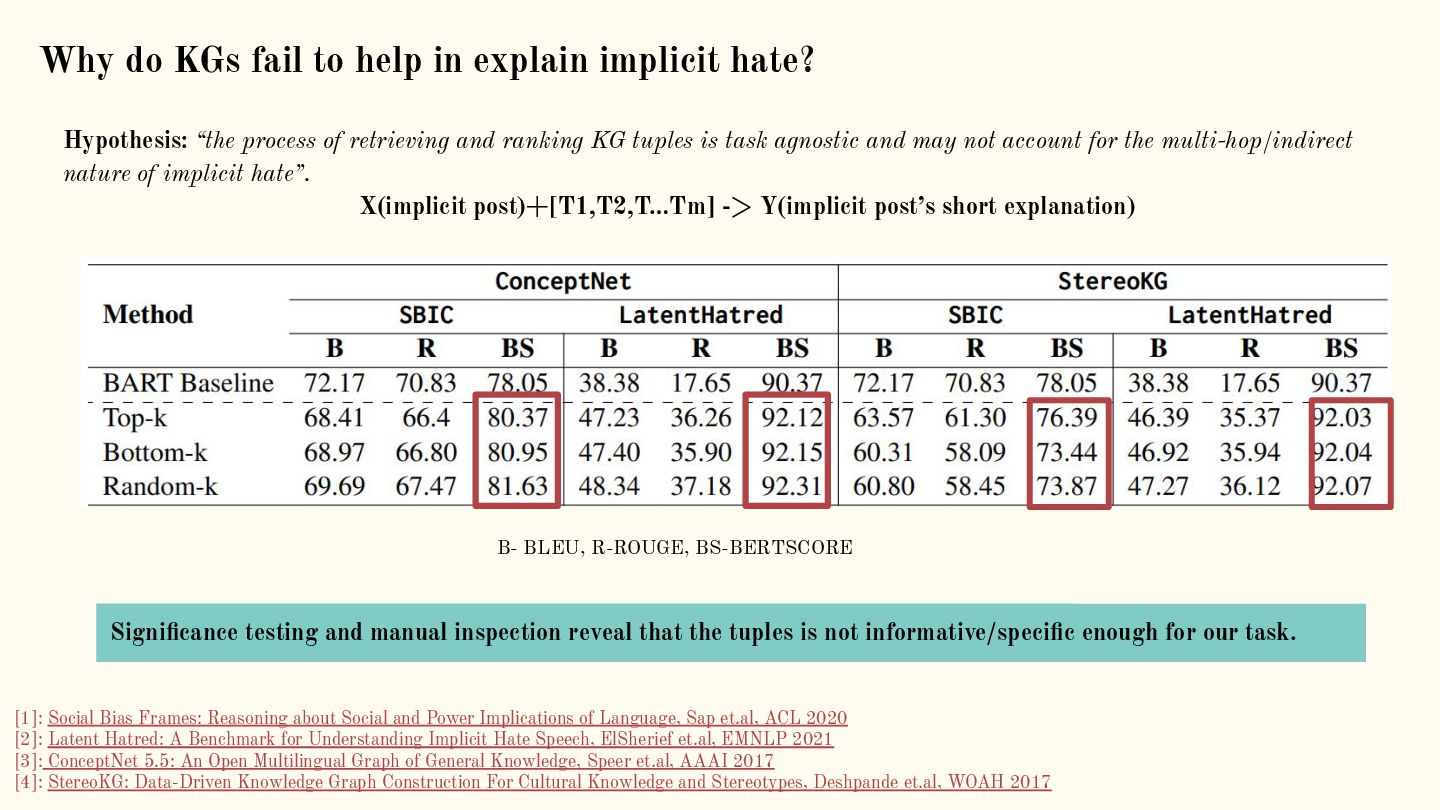{kind=link}
{kind=link}
![Alternate contextual signals for explaining implicit hate [1]: https://www.perspectiveapi.com/research/](https://files.speakerdeck.com/presentations/e5606d469e87401680b84d1483689886/slide_49.jpg){kind=link}
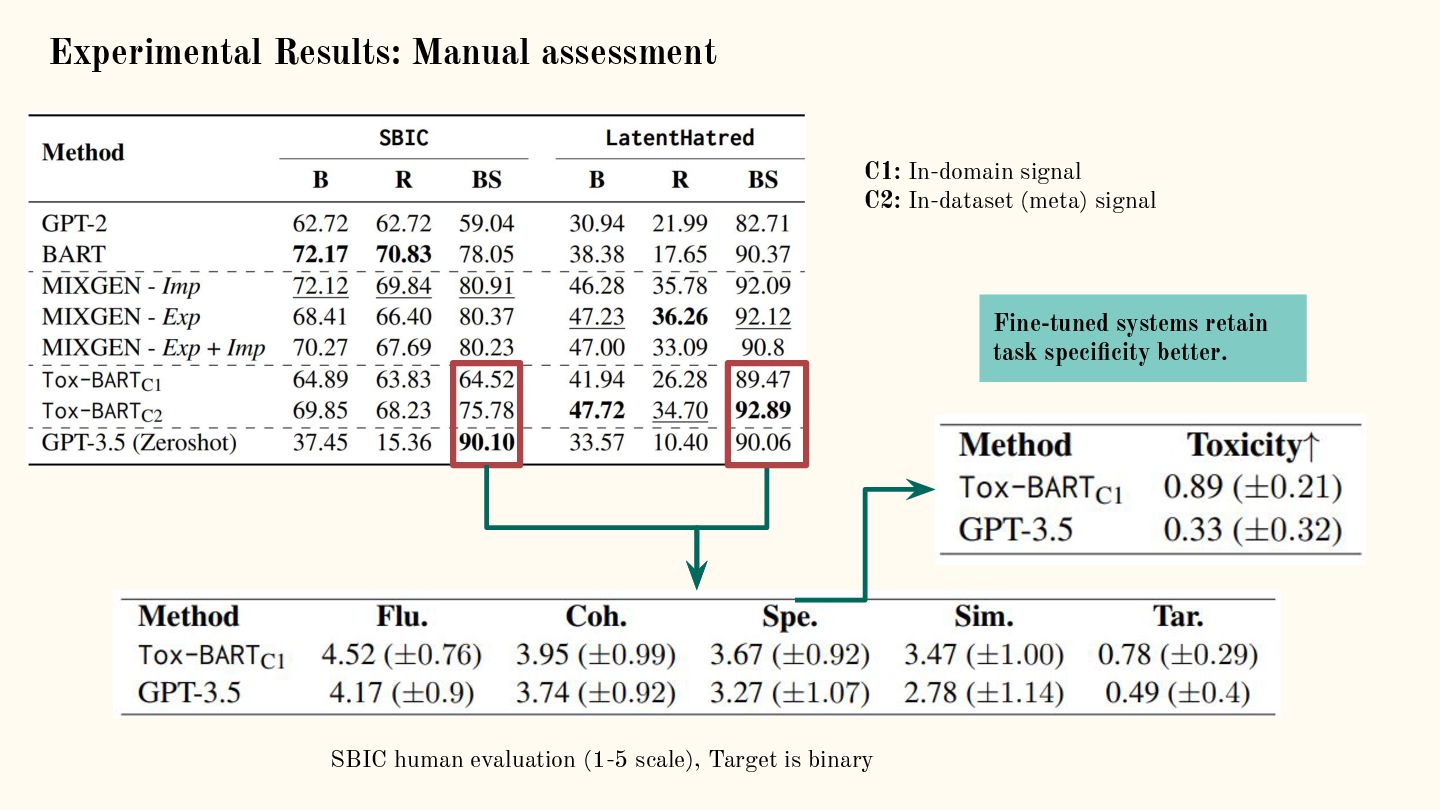{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
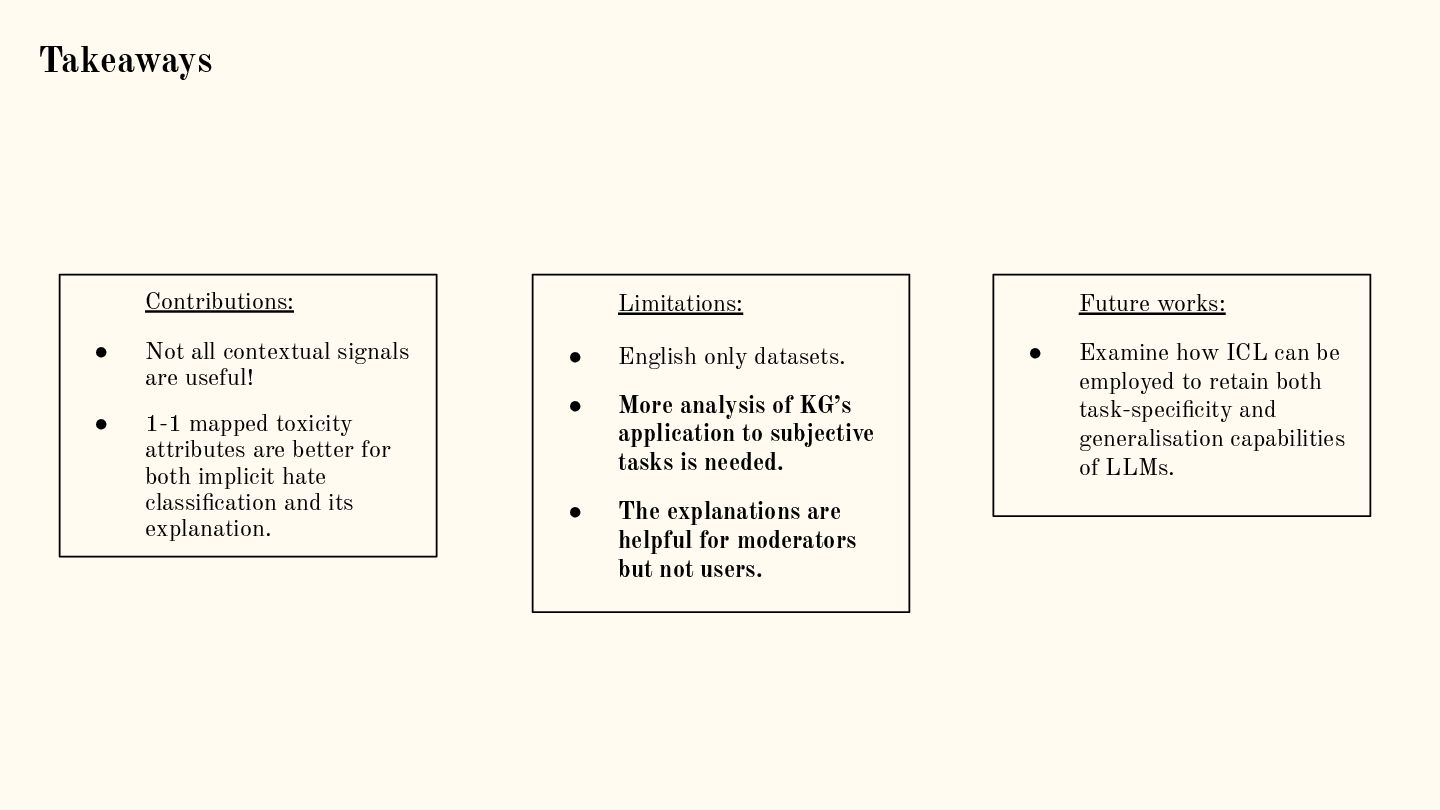
{kind=link}
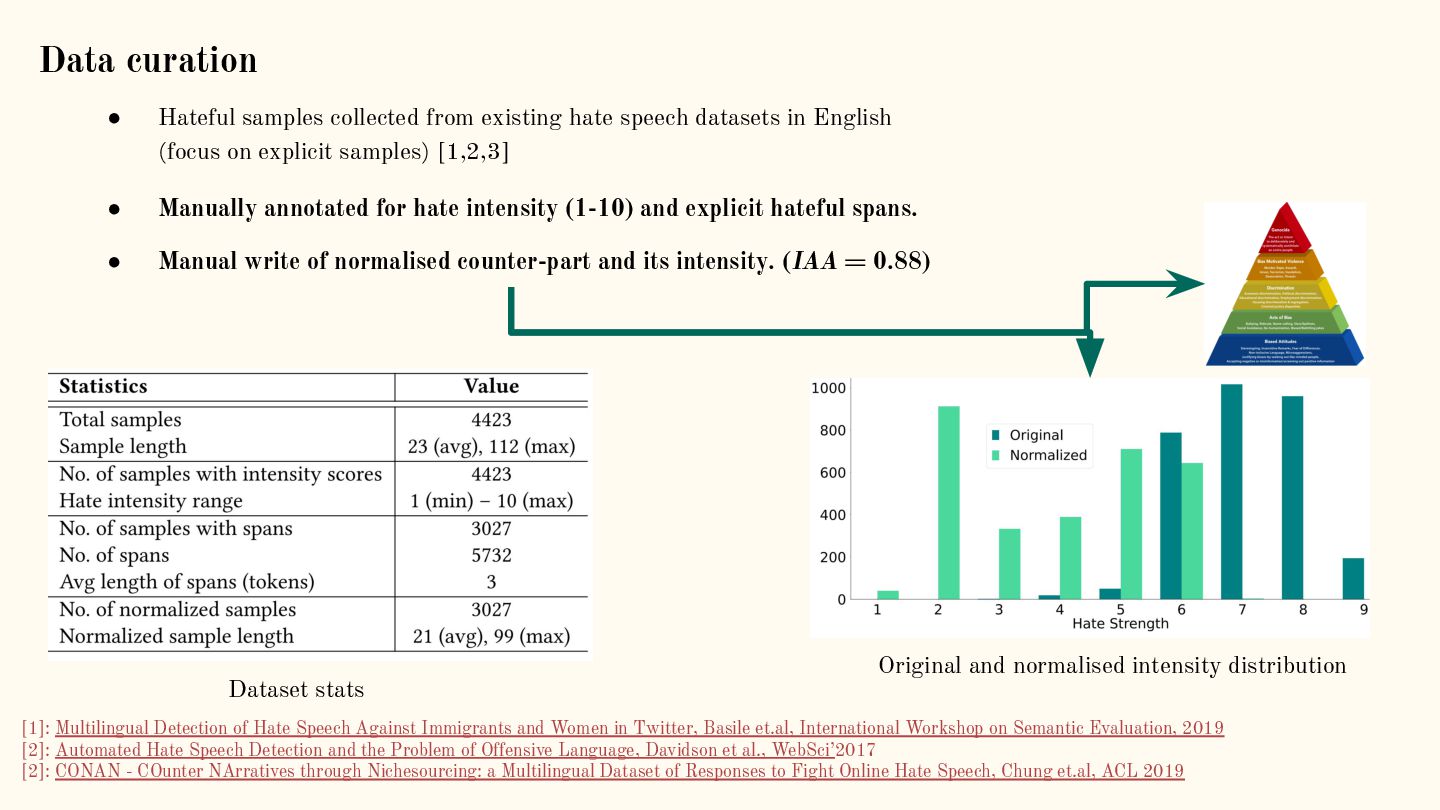{kind=link}
{kind=link}
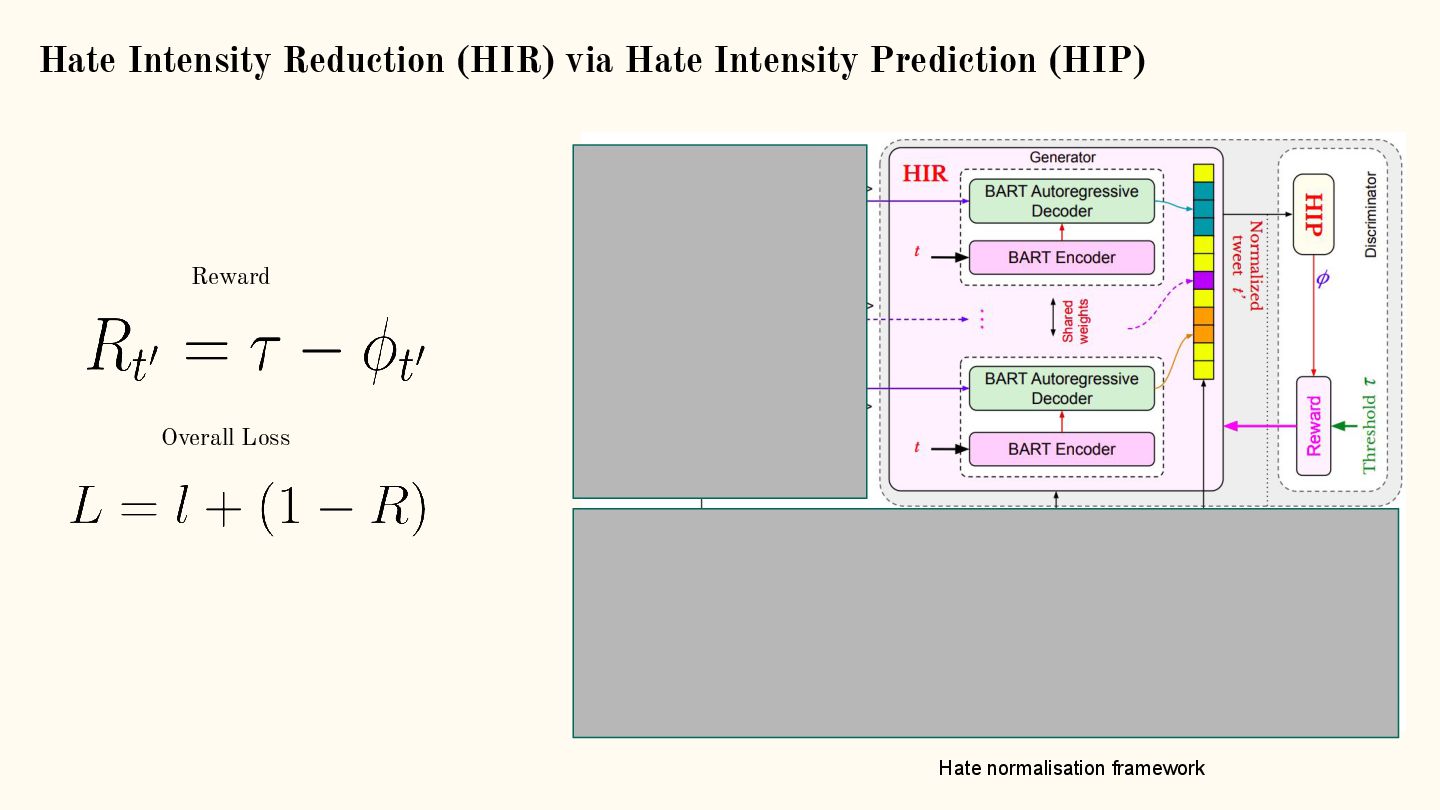{kind=link}
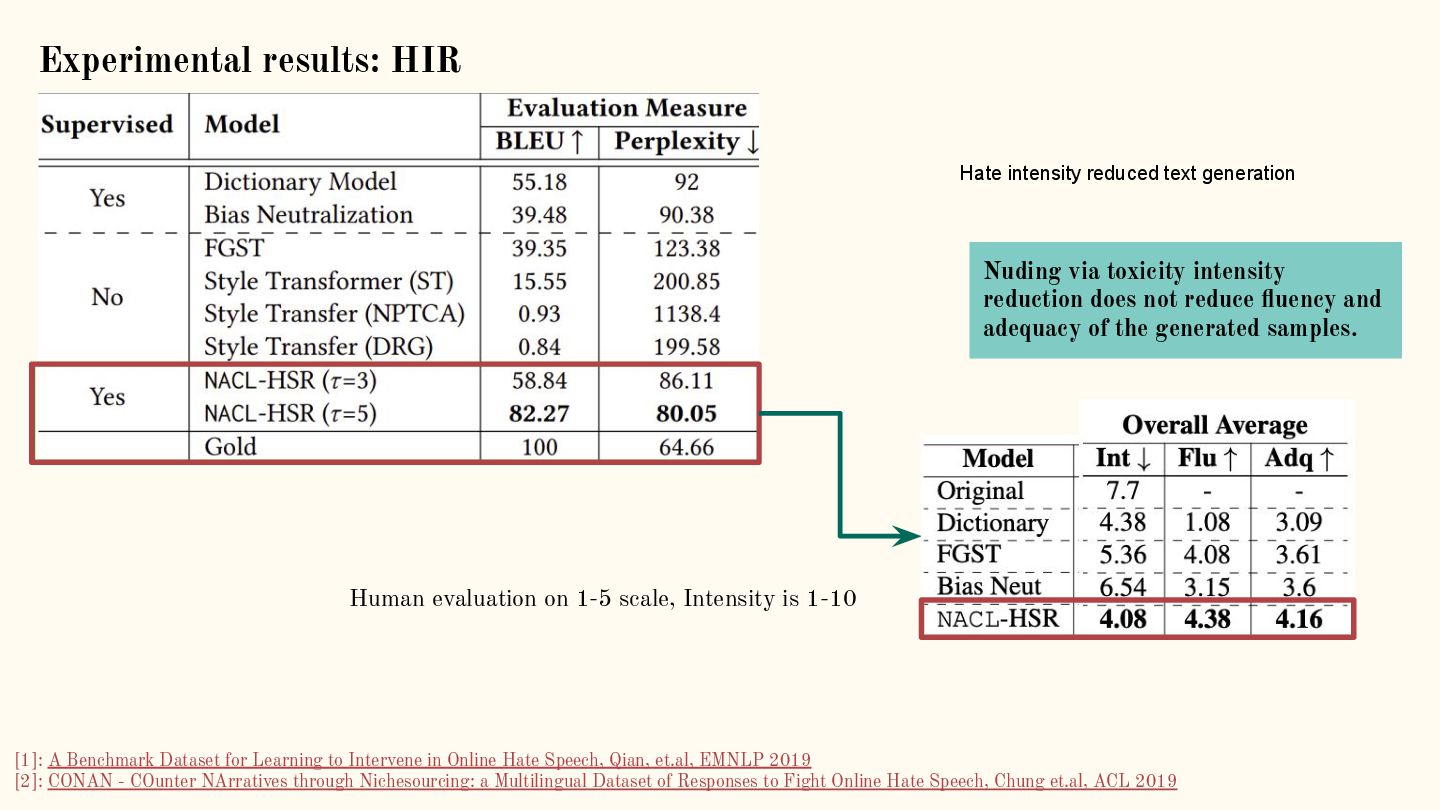{kind=link}
{kind=link}
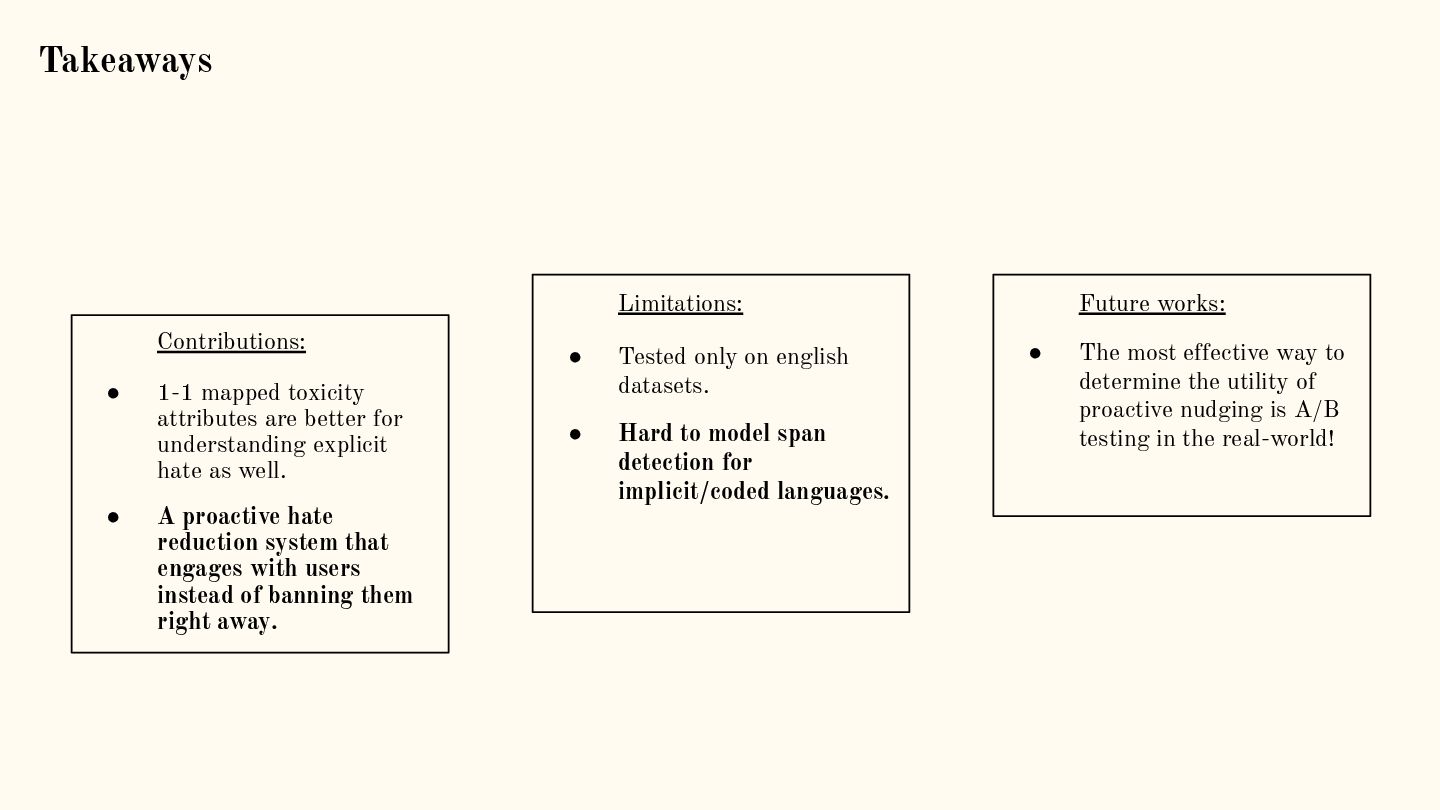{kind=link}
{kind=link}
{kind=link}
![Background [1]: Handling Bias in Toxic Speech Detection: A Survey,](https://files.speakerdeck.com/presentations/e5606d469e87401680b84d1483689886/slide_64.jpg){kind=link}
![Do LLMs pick on geographical cues? [1]: Exploring Cross-Cultural Differences](https://files.speakerdeck.com/presentations/e5606d469e87401680b84d1483689886/slide_65.jpg){kind=link}
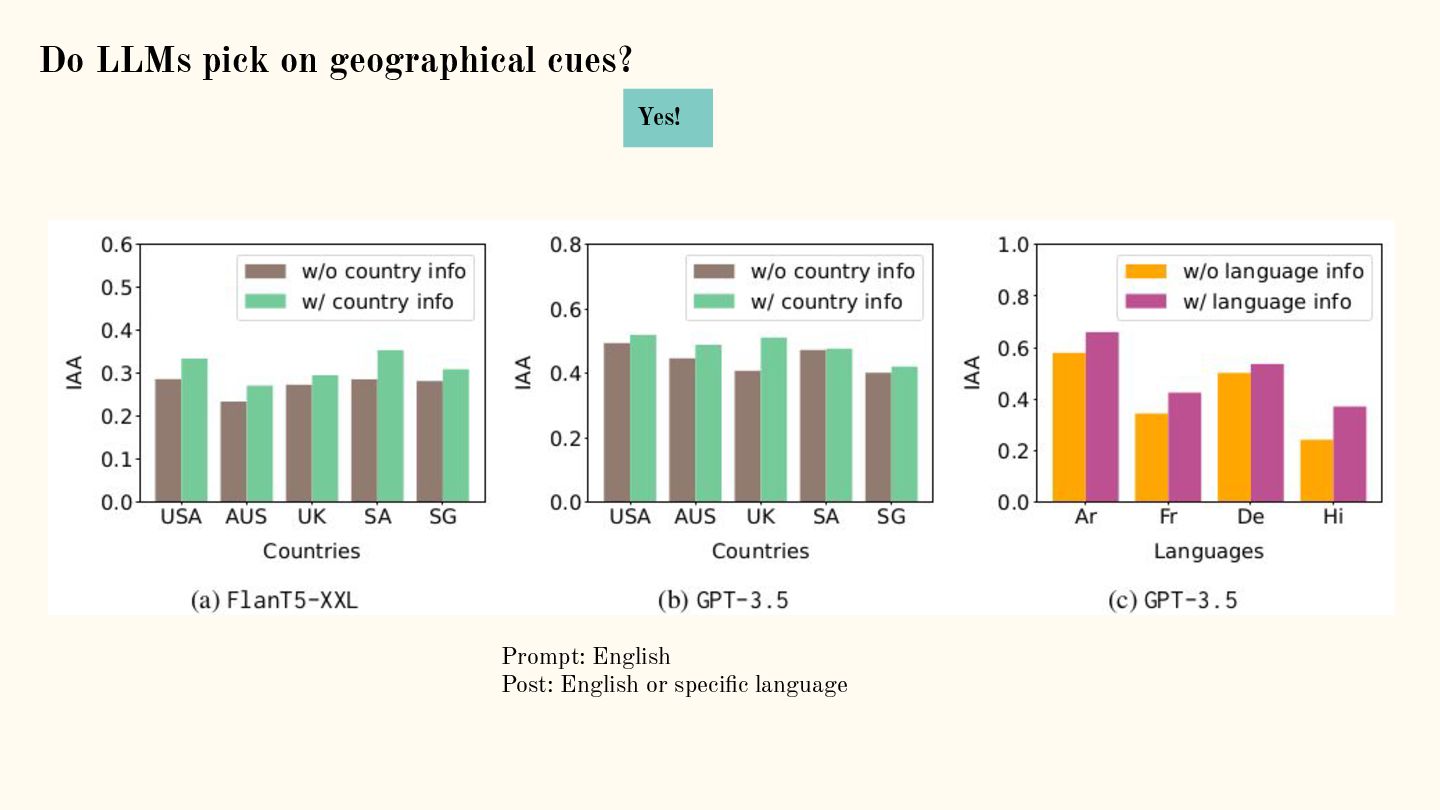{kind=link}
![Can LLMs mimic annotator persona? [1]: Exploring Cross-Cultural Differences in](https://files.speakerdeck.com/presentations/e5606d469e87401680b84d1483689886/slide_67.jpg){kind=link}
![Not really! Can LLMs mimic annotator persona? [1]: Sociodemographic Prompting](https://files.speakerdeck.com/presentations/e5606d469e87401680b84d1483689886/slide_68.jpg){kind=link}
![Are LLMs sensitive to anchoring bias? [1]: HateXplain: A Benchmark](https://files.speakerdeck.com/presentations/e5606d469e87401680b84d1483689886/slide_69.jpg){kind=link}
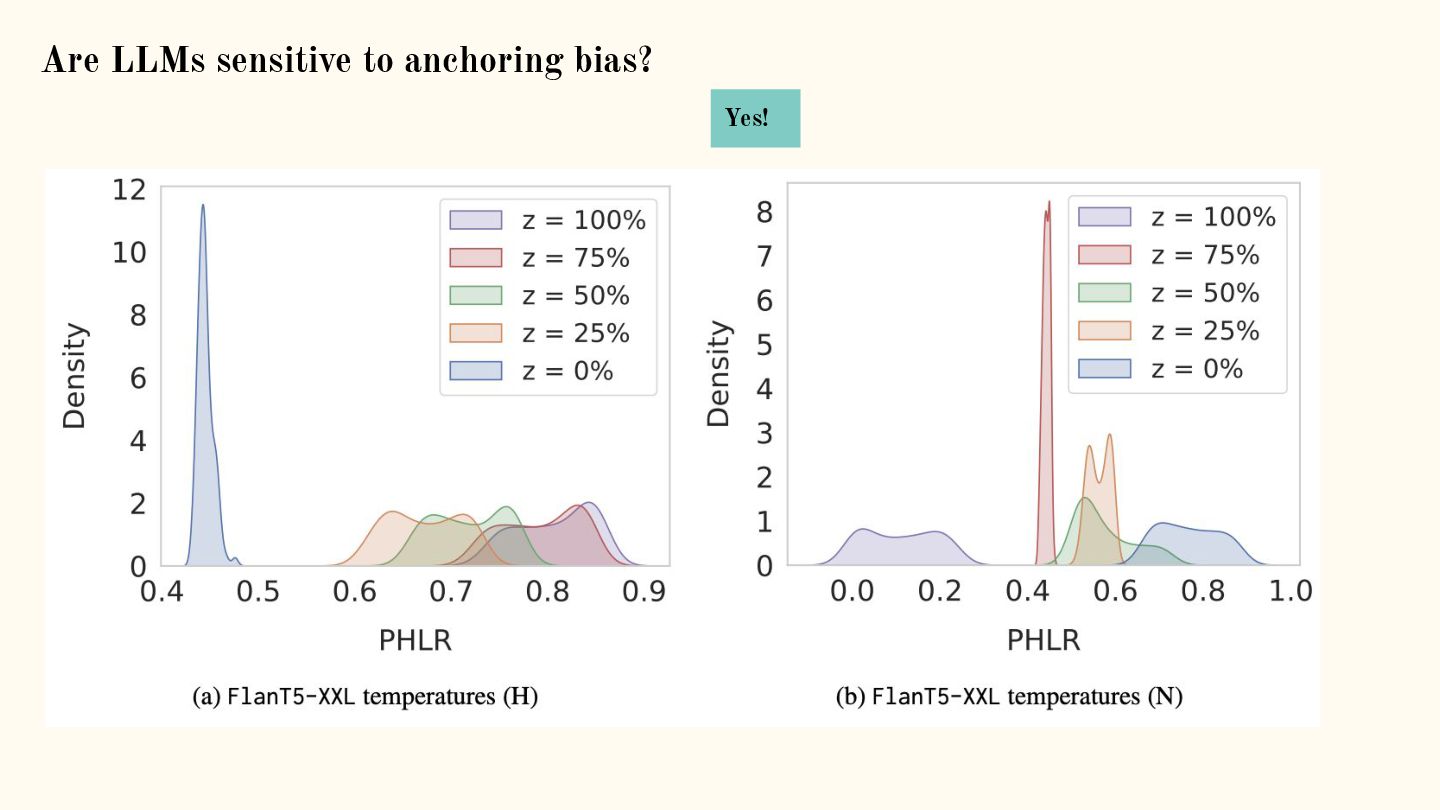{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}