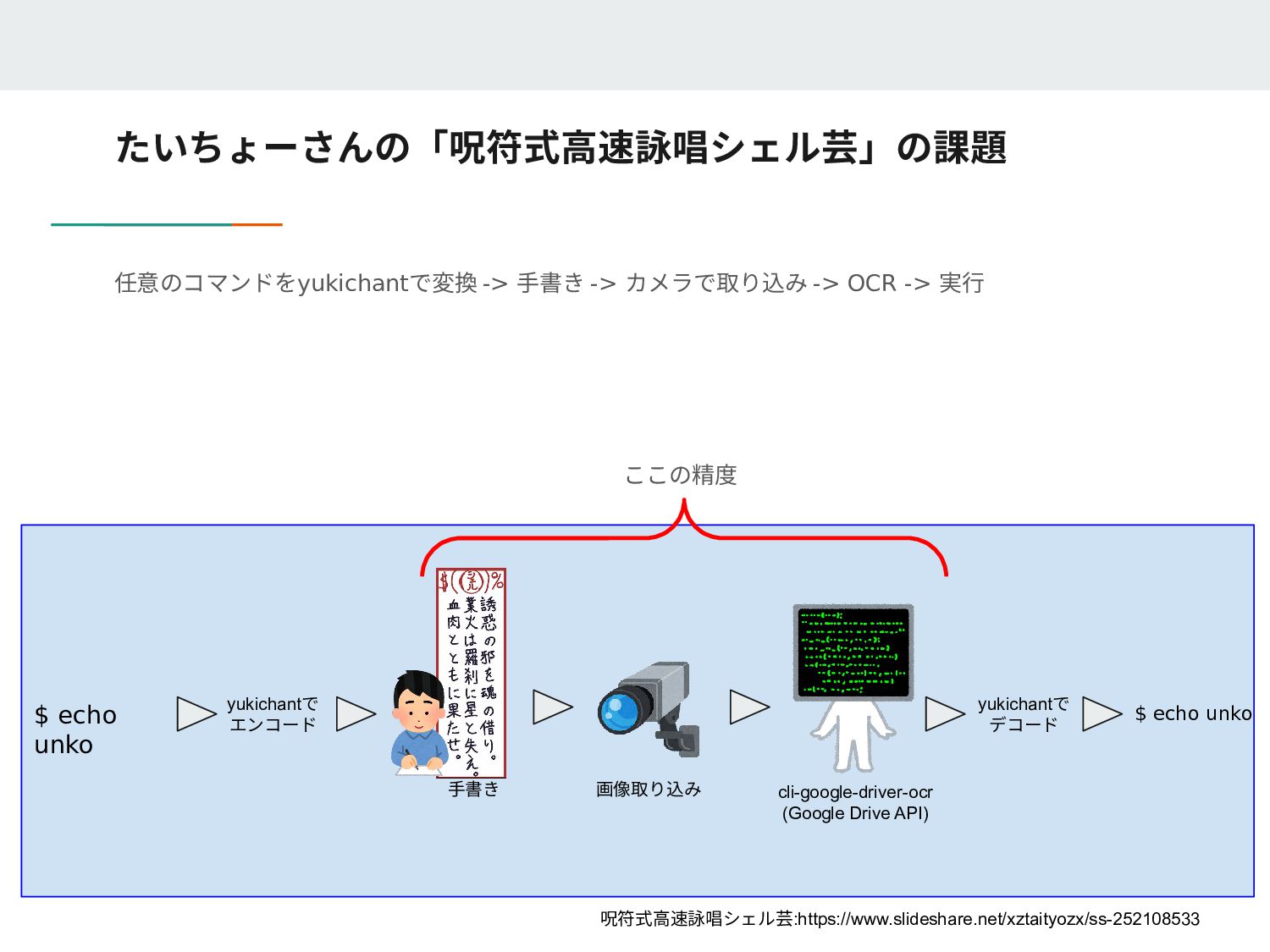
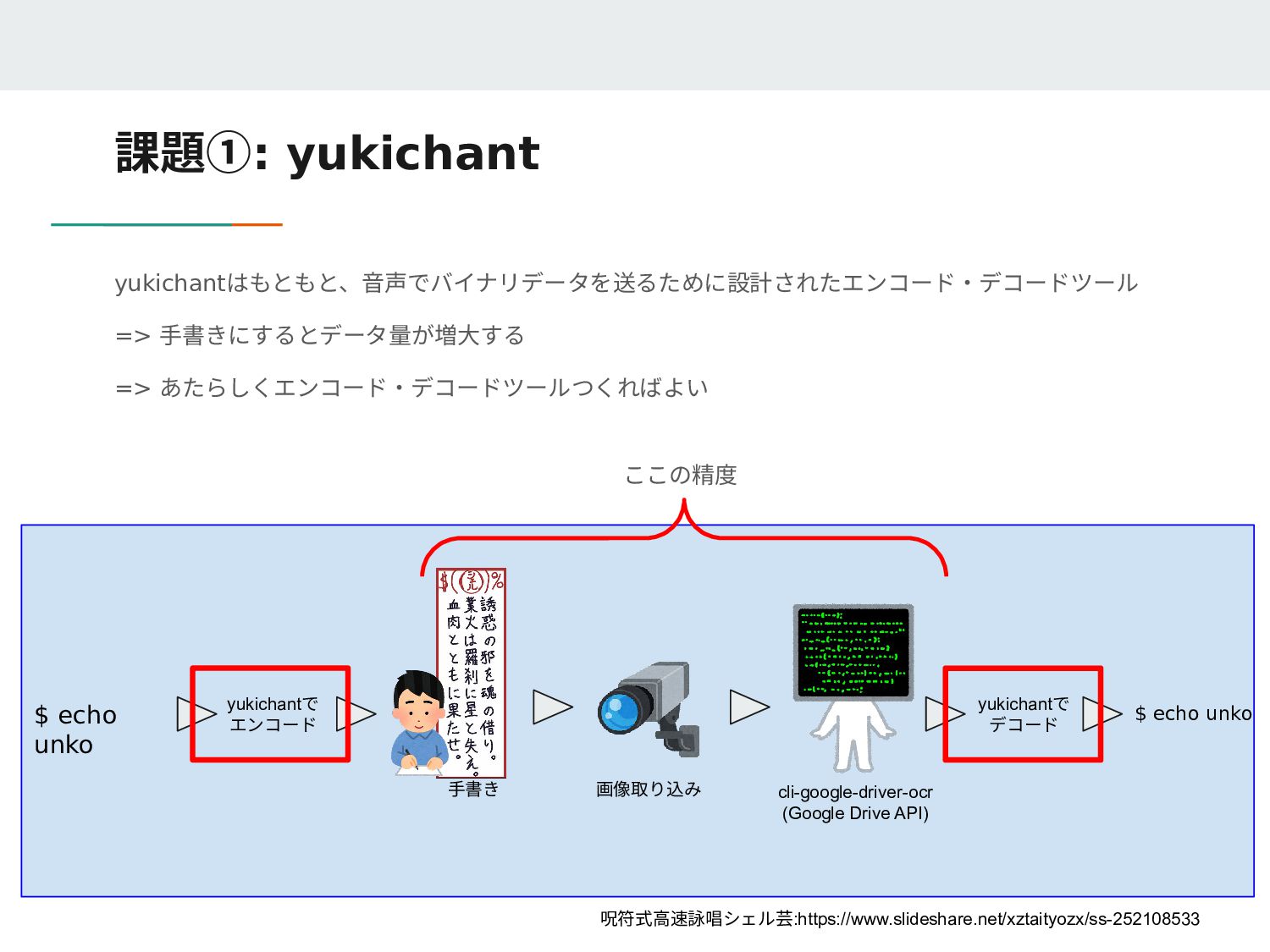
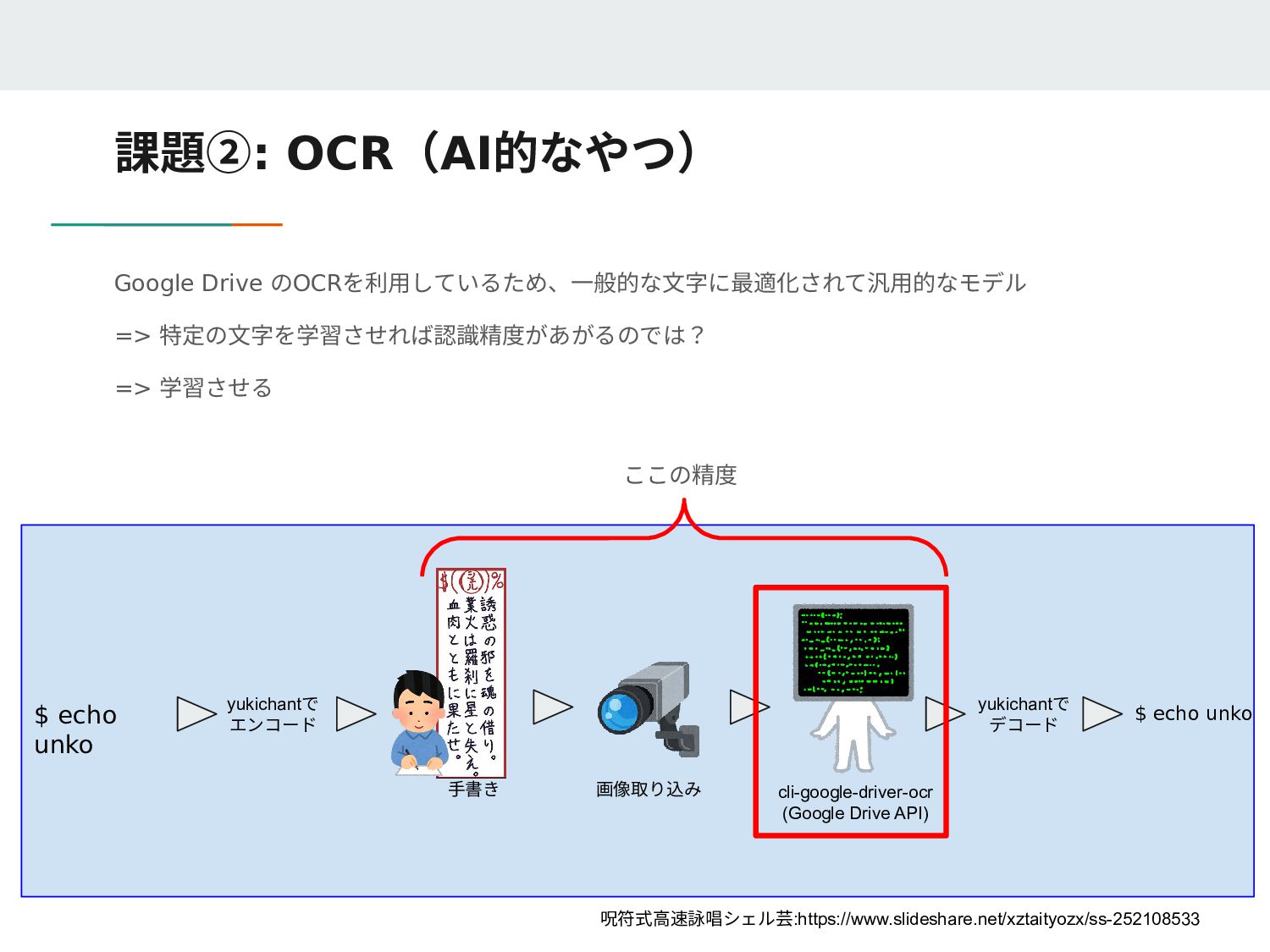
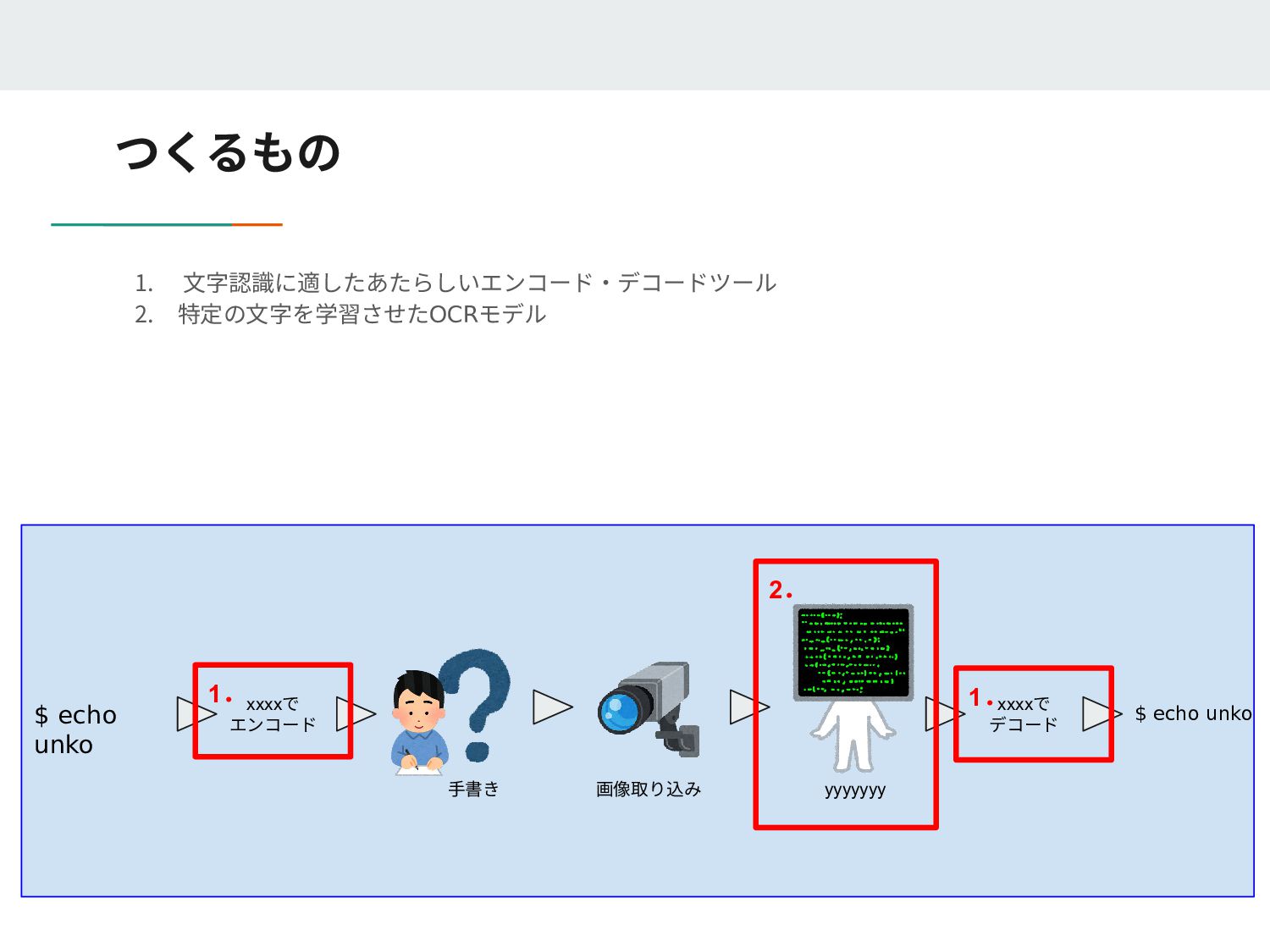
Loaded 1/1 lines (1-1) of document data/rune-ground-truth/140071.lstmf Loaded 1/1 lines (1-1) of document data/rune-ground-truth/53234.lstmf Loaded 1/1 lines (1-1) of document data/rune-ground-truth/162477.lstmf 2 Percent improvement time=1086, best error was 2 @ 2481 At iteration 3567/16300/16300, Mean rms=0.06%, delta=0%, char train=0%, word train=0%, skip ratio=0%, New best char error = 0 wrote best model:data/rune/checkpoints/rune0_3567.checkpoint wrote checkpoint. Finished! Error rate = 0 Loaded file data/rune/checkpoints/rune_checkpoint, unpacking... 20万データ作成したけど16000暗いのデータでエラー率が0になり学習が終了 (ローカルミニマム(局所解)になってしまった?)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![学習データを作る ## ルーン文字毎に画像を分割する $ identify 1.png|awk -F '[ x]' '{print](https://files.speakerdeck.com/presentations/d2b1537af5424692bfa02df4668f41a5/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}