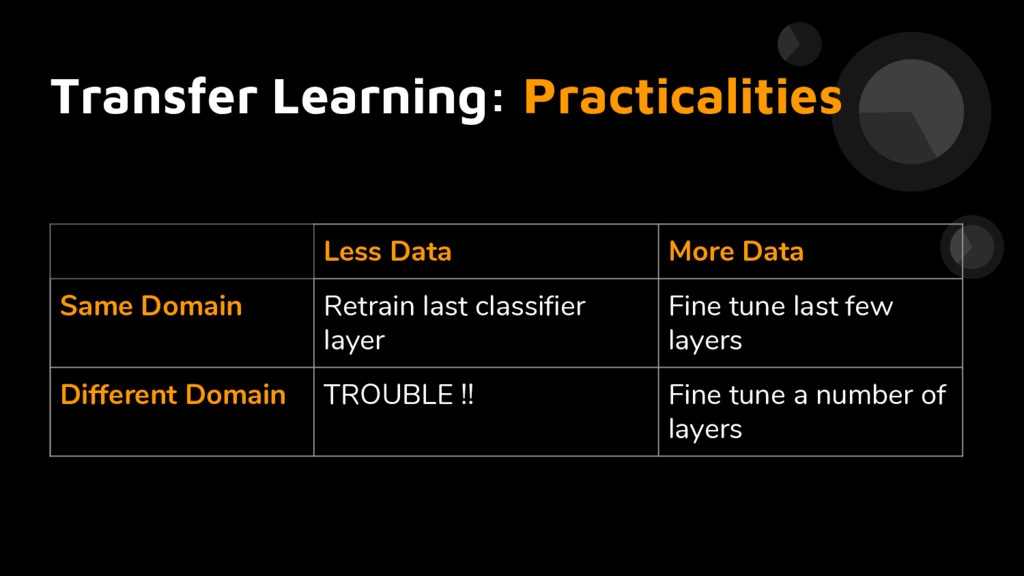
Fine tune last few layers Different Domain TROUBLE !! Fine tune a number of layers Pre-trained models: Initial results We started here! Using pre-trained models - achieved 88% accuracy. < 10 min train time
for rapid prototyping of ideas Some pointers on making the choice: - Tensorflow does have eager execution and fold - but PyTorch is more Pythonic and quite popular with researchers - Horovod is quite good for distributed training on tensorflow - MXNet has distributed training at its core - but no widespread adoption yet
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}