We've got unit tests, functional tests, and integration tests — but where are our tests for production? How we define (and check for!) "correct behavior" for a Rails app running in the wild?
In this workshop, we'll start by creating an end-to-end check together (like an integration test on prod!) on a fun, interactive demo app. Then, we'll go one level deeper by adding custom instrumentation. (There will be prizes and at least one shiny light involved.)
You'll leave with a deeper understanding of how to ask questions of your app and how to think about ensuring "correctness" in production.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
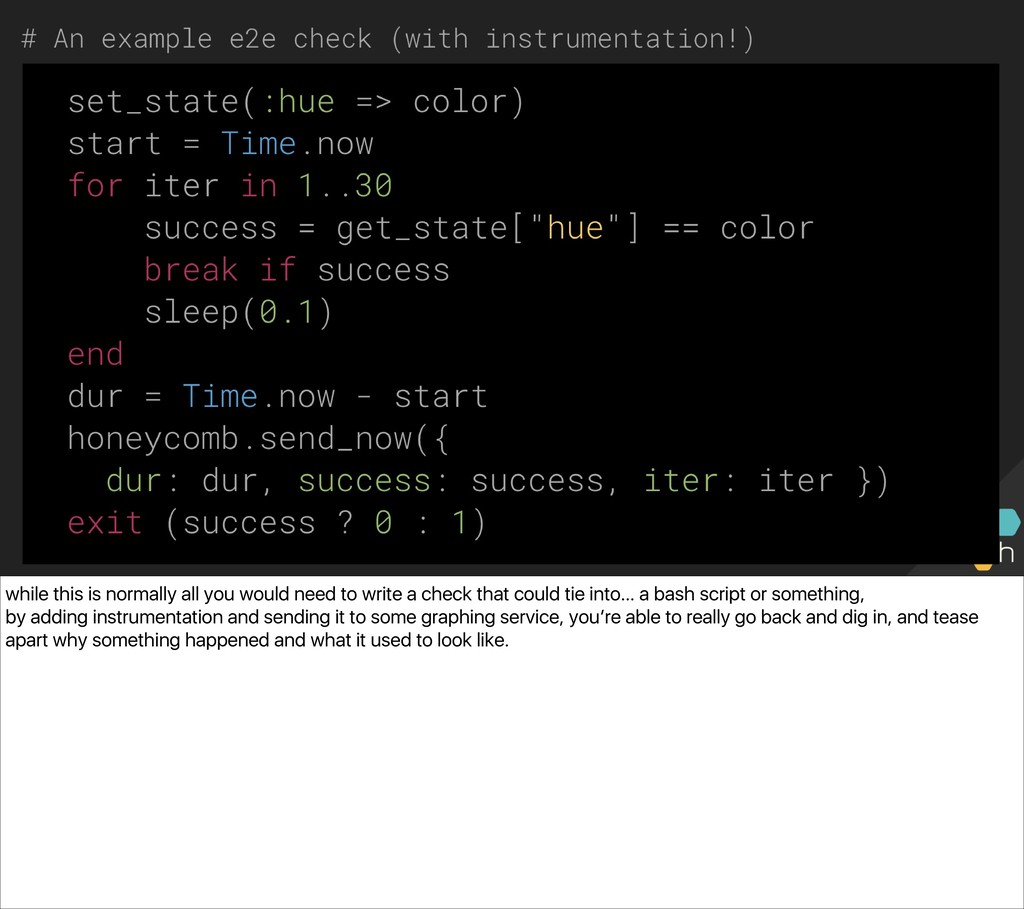{kind=link}
{kind=link}
{kind=link}
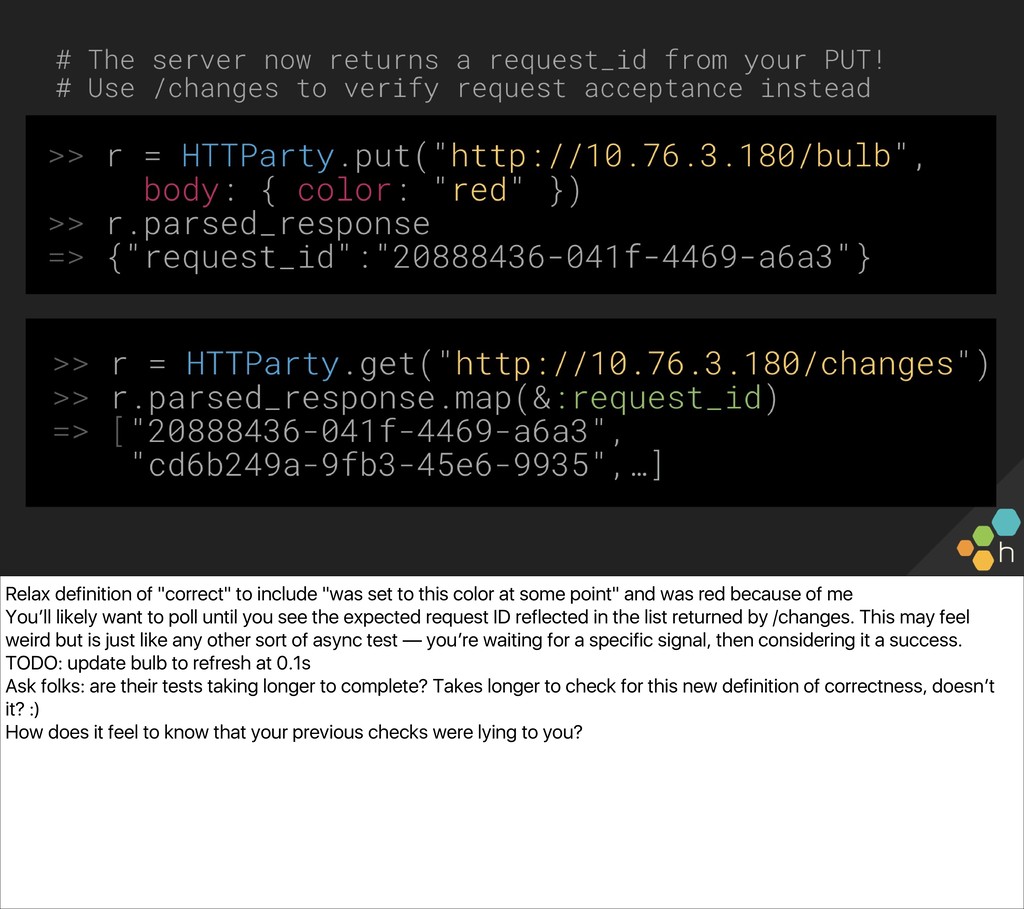{kind=link}
{kind=link}
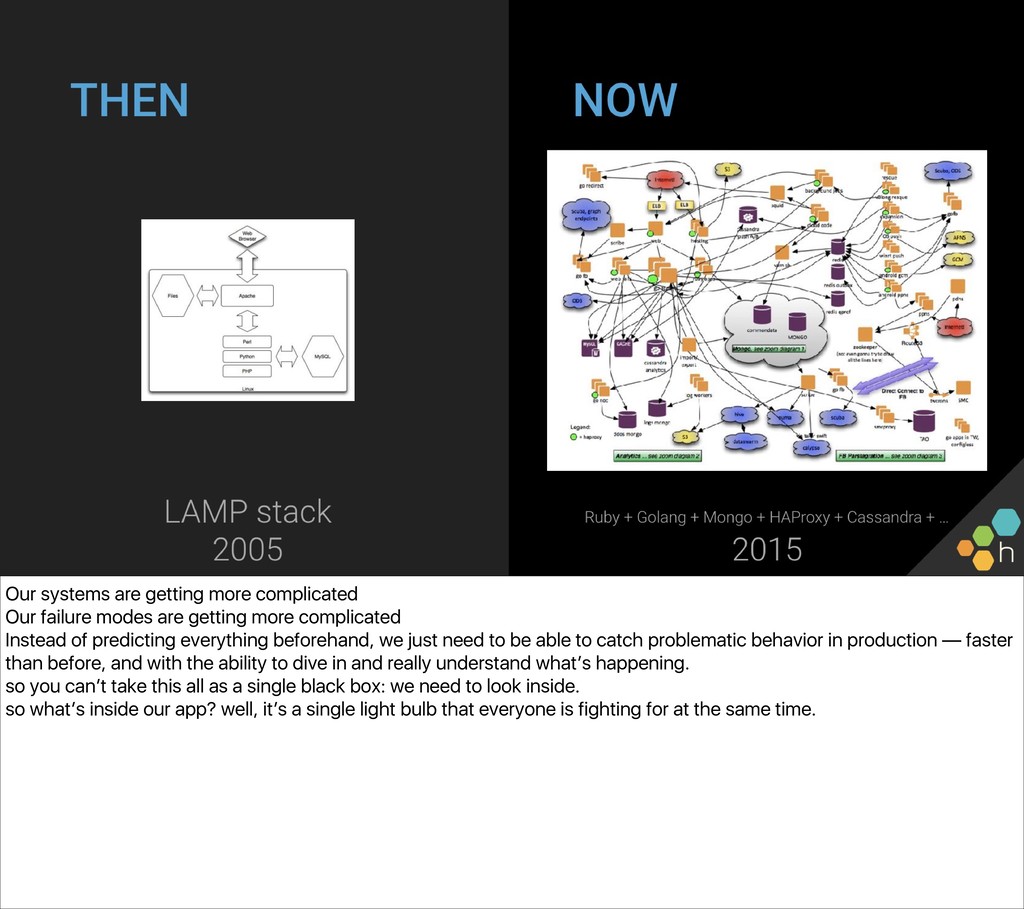{kind=link}
{kind=link}
{kind=link}
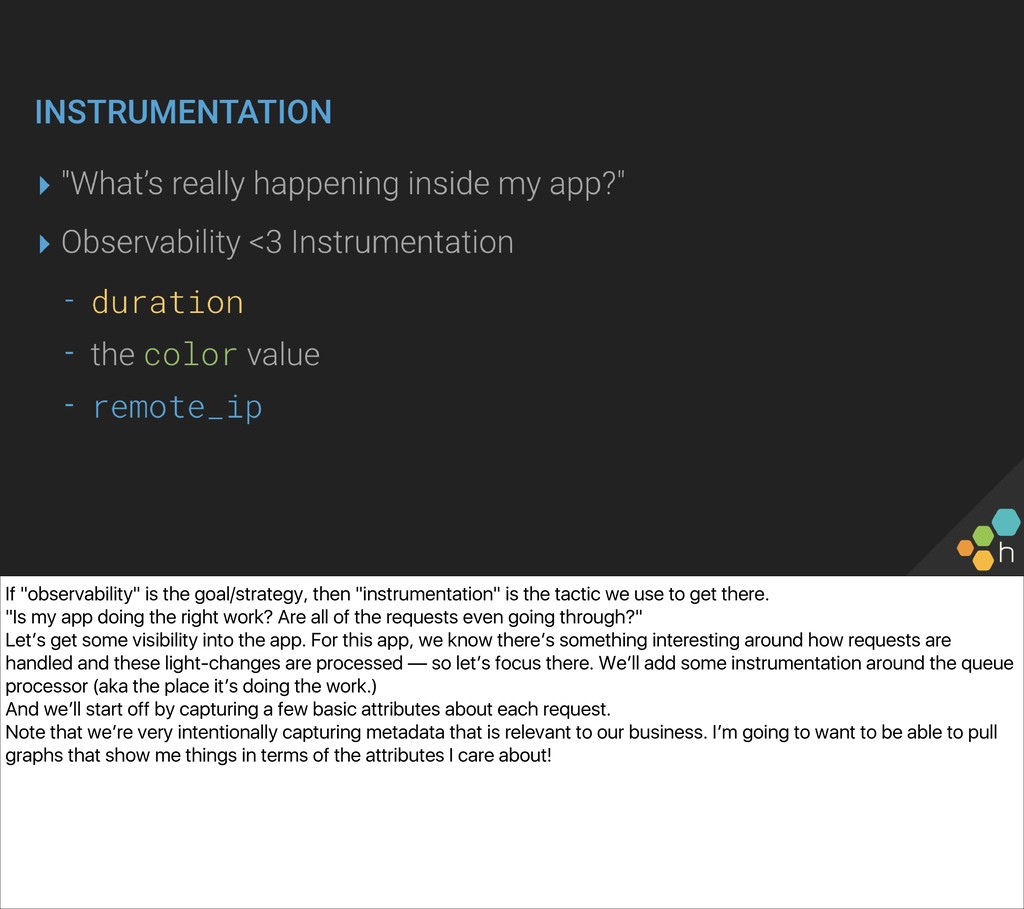{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}