□ 登壇者
芝田 将
□ 発表について
サイバーエージェントには、機械学習を活用したプロダクトが多数存在します。
しかし、機械学習システムの開発や運用は、機械学習の知識とシステム開発・運用の知識の両方が求められるなど技術的に難しい点も多く存在します。
機械学習のコミュニティにおいてもMLOpsという単語とともにその方法論や設計プラクティスが議論・共有されてきました。
サイバーエージェントにおいてもMLOpsに関する様々な取り組みが行われています。
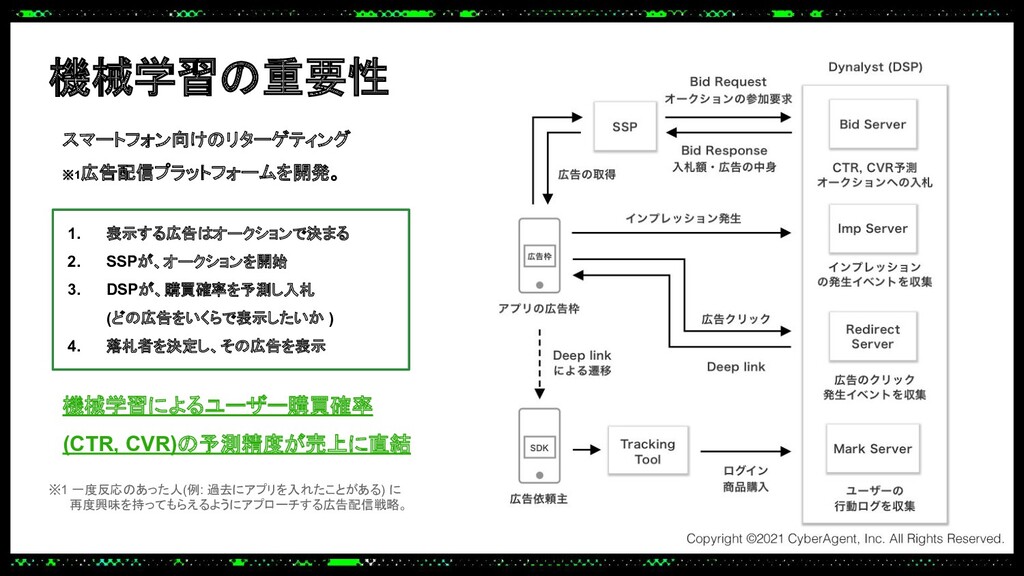
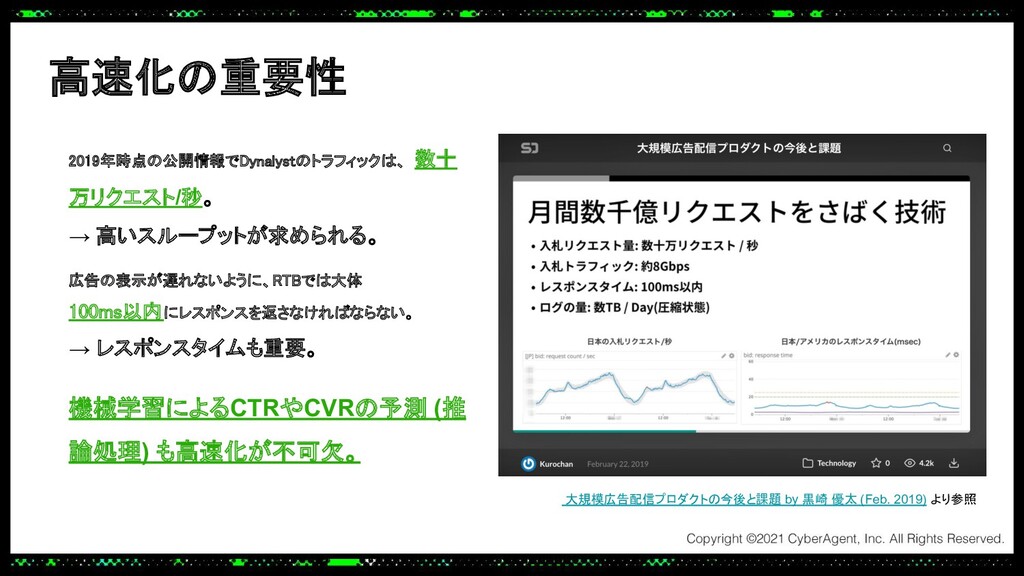
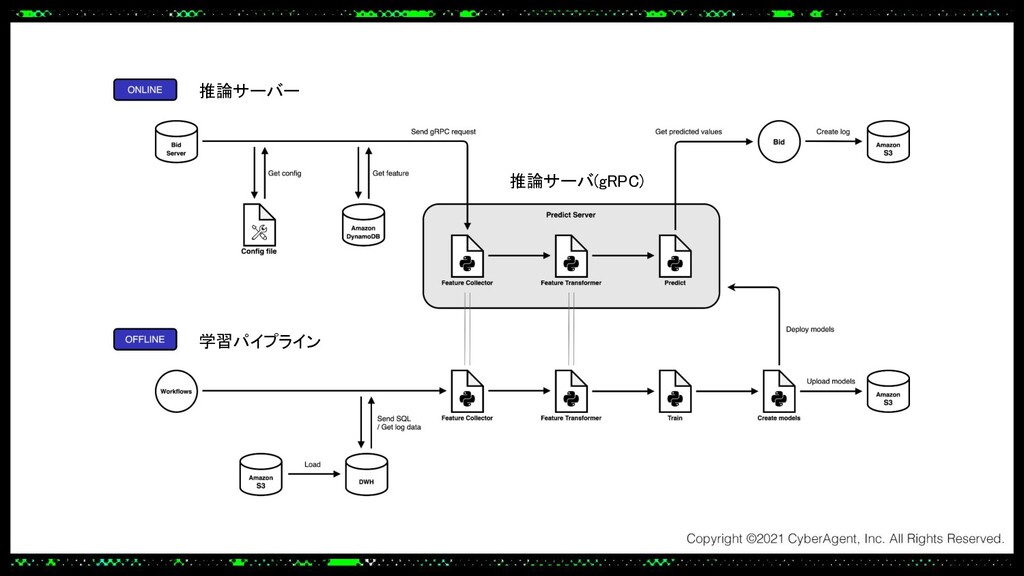
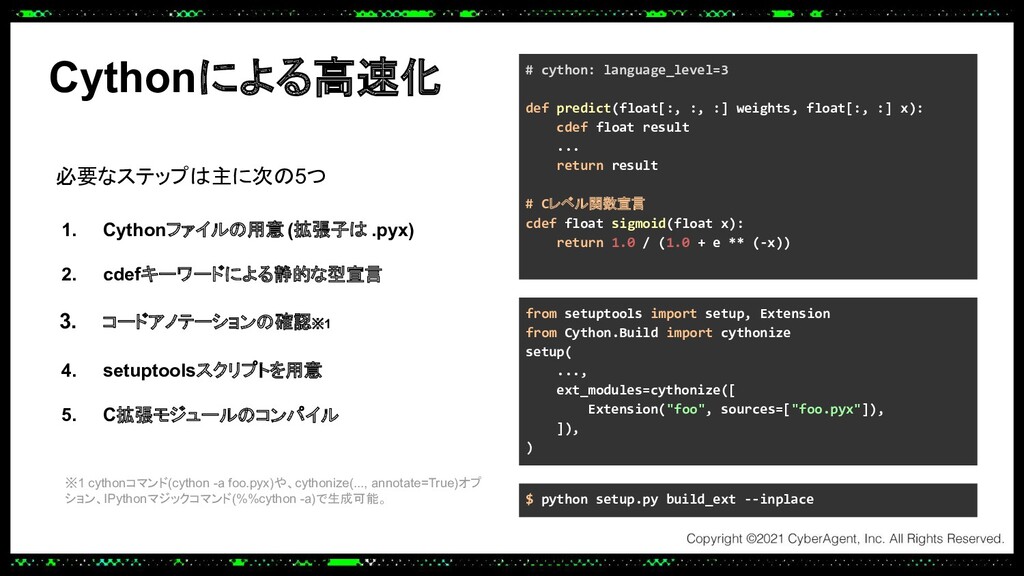
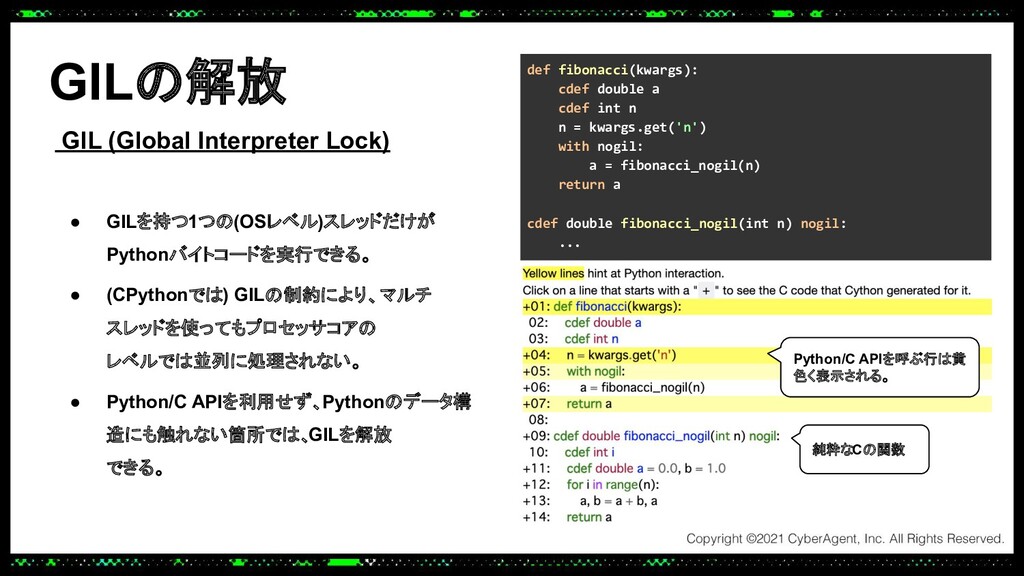
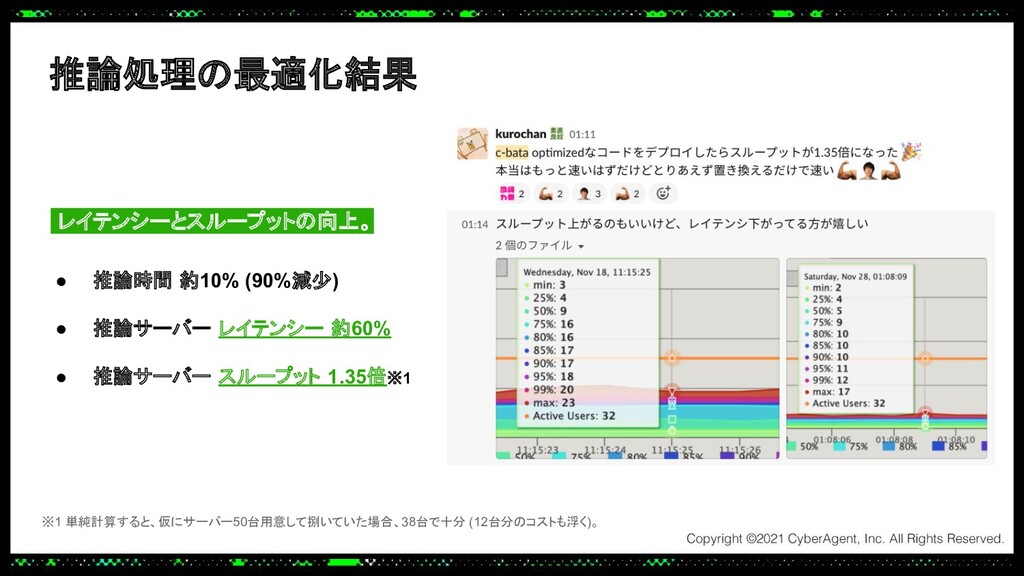
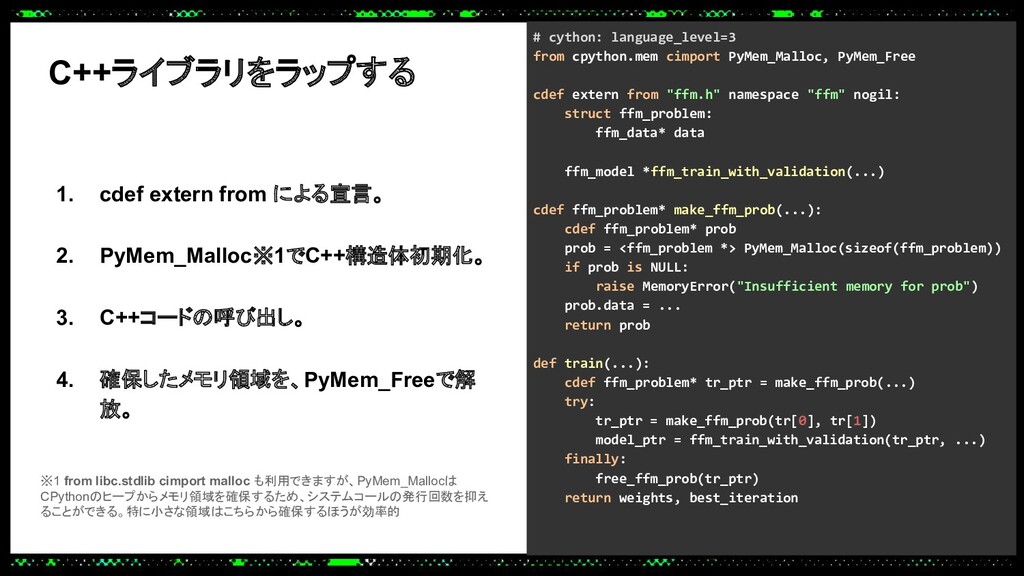
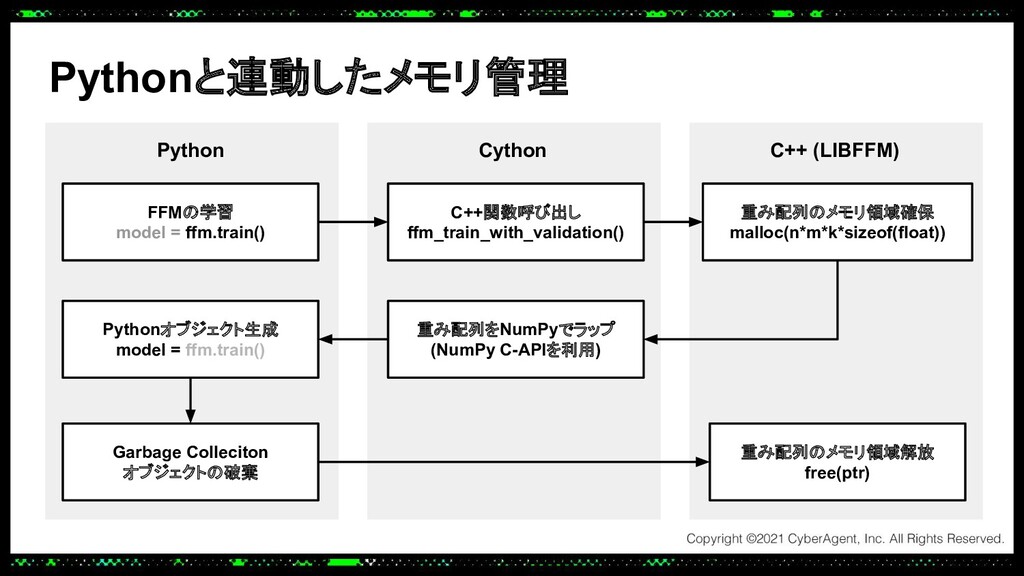
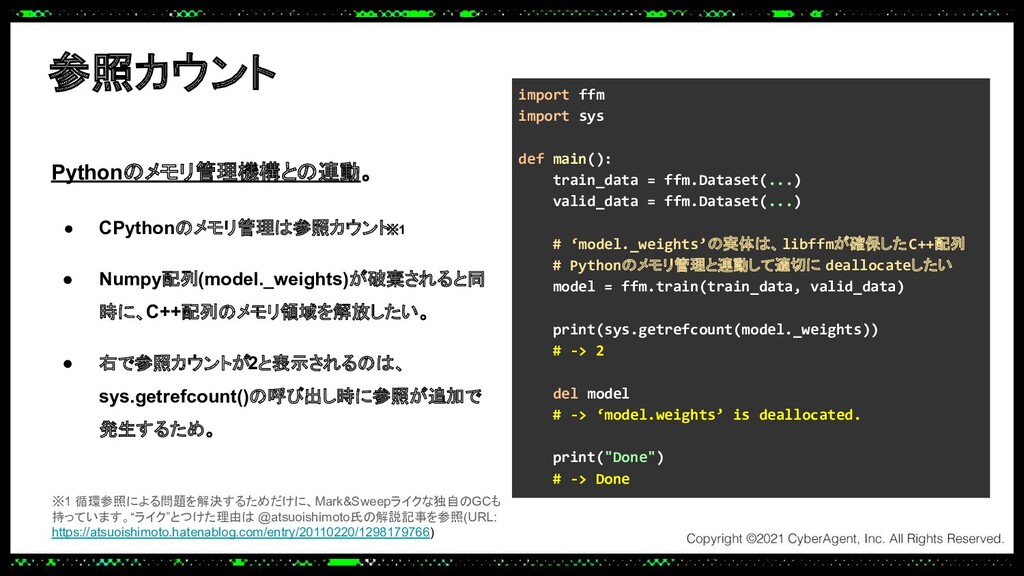
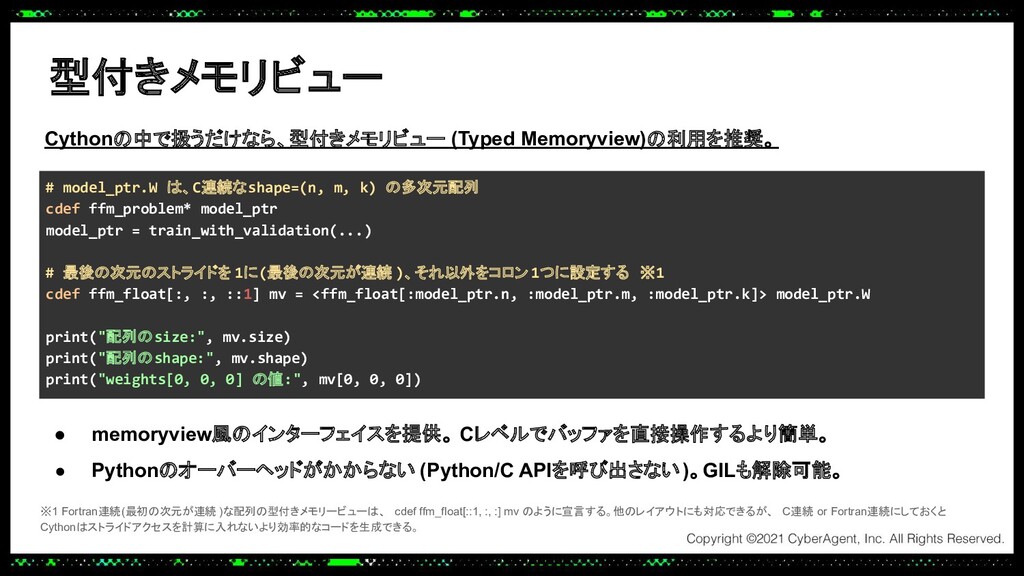
あるプロダクトでは大規模なトラフィックにも耐えられる推論サーバーをPythonで実装する必要があり、Cythonを使って機械学習モデルの推論処理を高速化し、低レイテンシーかつ高スループットを実現しました。
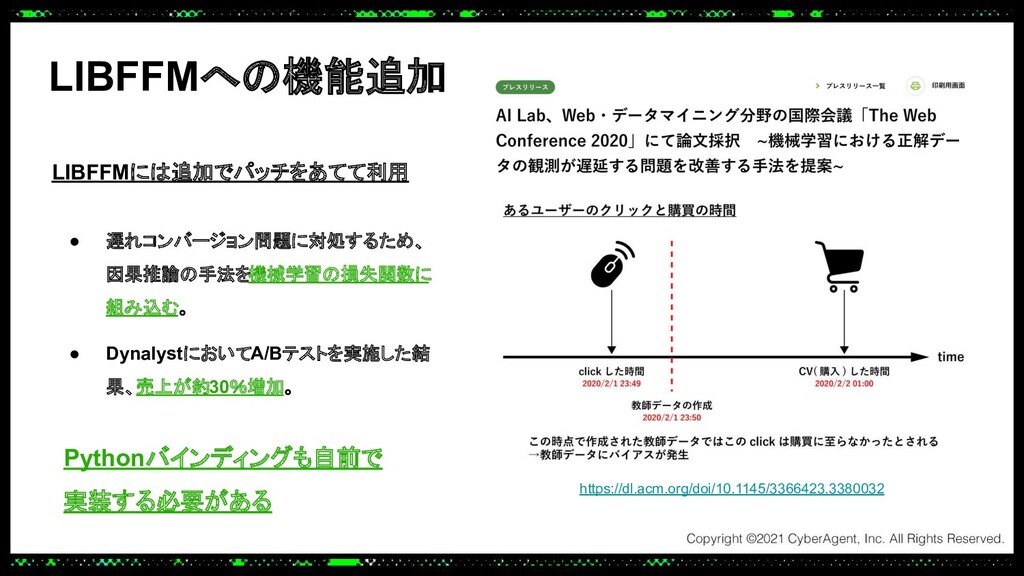
またあるプロダクトでは、継続的に最適なハイパーパラメータの探索を行う上で、より効率的に探索を行うためOptunaとMLflowを用いたハイパーパラメータ最適化の転移学習を実装しました。
本発表を通してこういった社内の事例を共有します。
□ CA BASE NEXT (CyberAgent Developer Conference by Next Generations) とは
20代のエンジニア・クリエイターが中心となって創り上げるサイバーエージェントの技術カンファレンスです。
当日はセッション・LT・パネルディスカッション・インタビューセッションを含む約50のコンテンツをYouTube Liveを通じて配信します。
イベントページ
□ 採用情報
サイバーエージェントに少しでも興味を持っていただきましたら、お気軽にマイページ登録やエントリーをおねがいします!
◆新卒エンジニア採用
エントリー・マイページ登録はこちら
採用関連情報のまとめはこちら
◆新卒クリエイター採用
エントリー・マイページ登録はこちら
◆中途採用
採用情報はこちら
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}