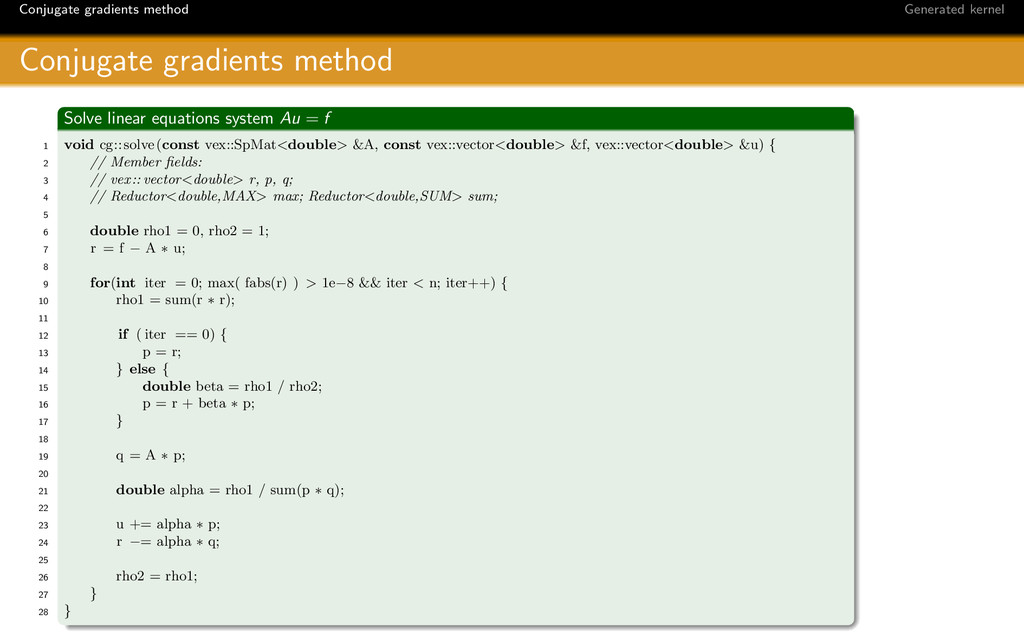
VexCL: a Vector Expression Template Library for OpenCL
OpenCL is the first open, royalty-free standard for cross-platform, parallel programming of modern processors found in personal computers, servers, and handheld/embedded devices. The weakest side of OpenCL is lack of tools and libraries around it and the amount of boilerplate code needed to develop OpenCL applications. The VexCL library tries to solve the latter issue. VexCL is vector expression template library for OpenCL and has been created for ease of C++ based OpenCL development. Multi-device (and multi-platform) computations are supported. This talk is an introduction to the VexCL interface.
Given at Meeting C++, Dusseldorf/Neuss, 10.11.2012
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
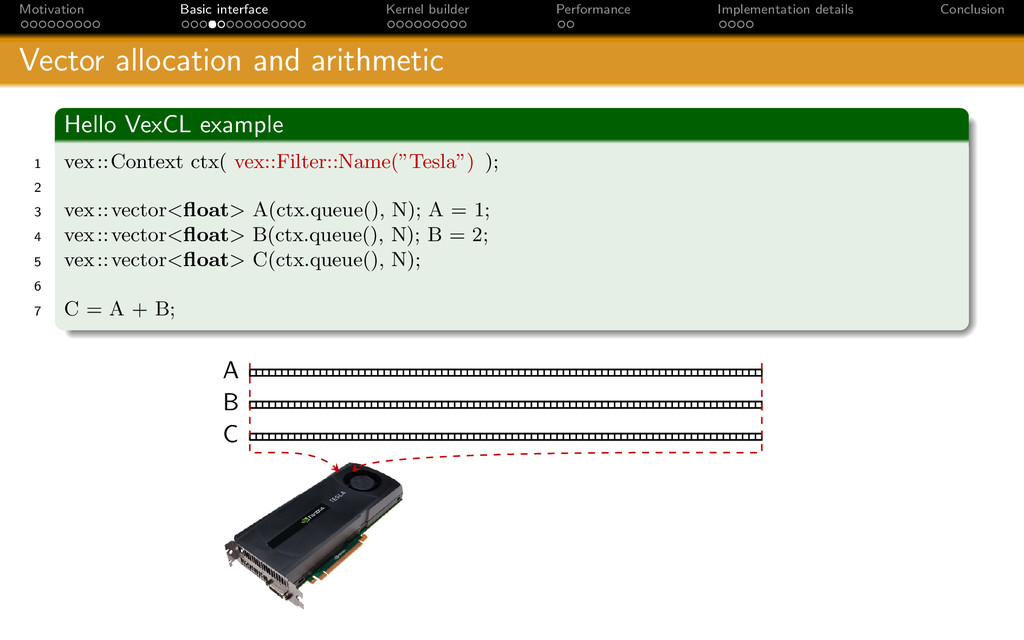{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
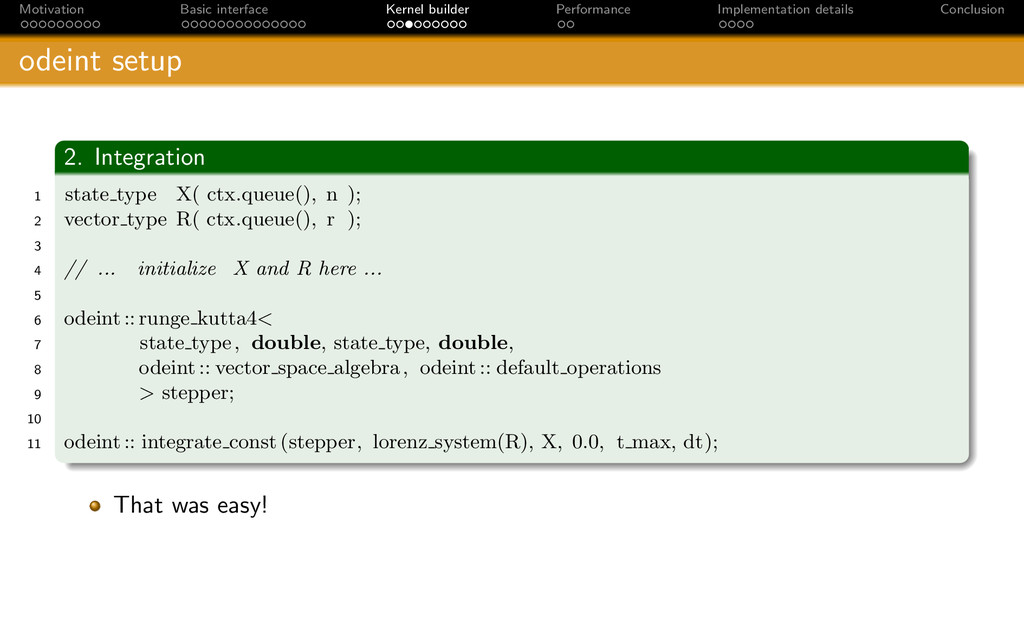{kind=link}
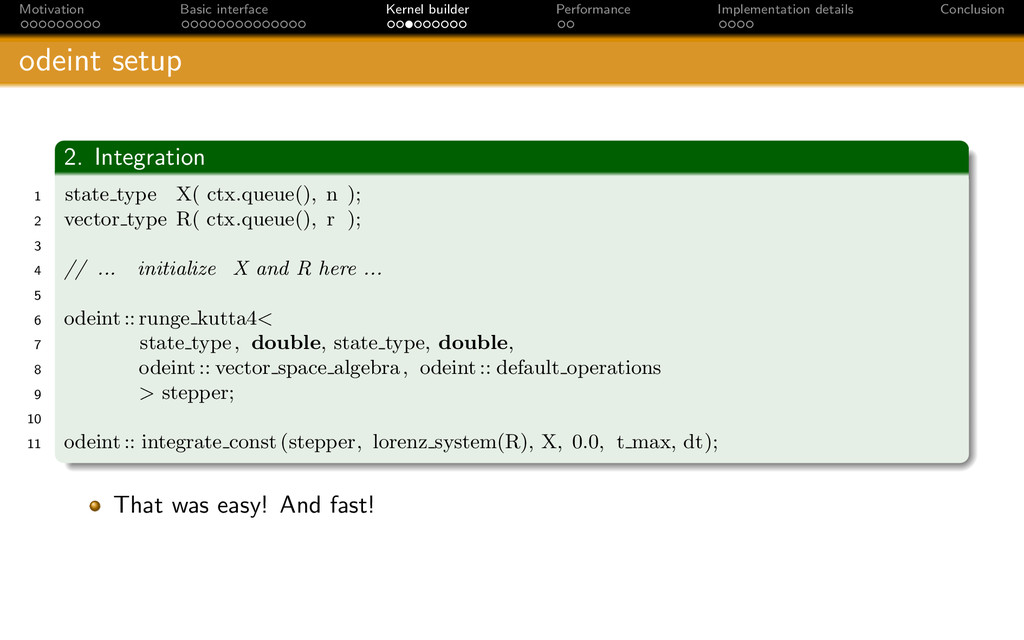{kind=link}
{kind=link}
{kind=link}
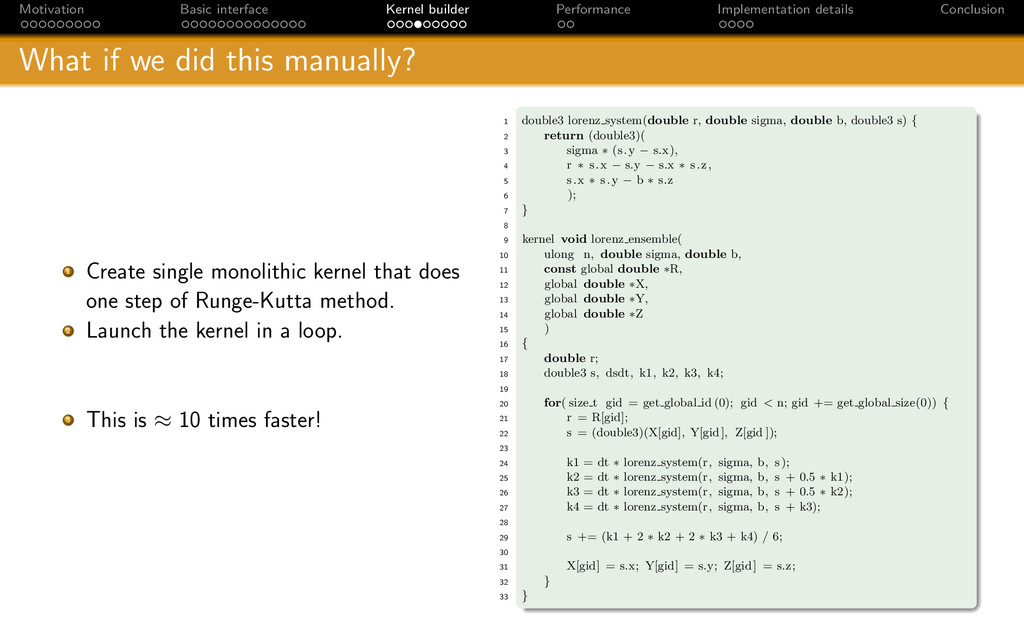{kind=link}
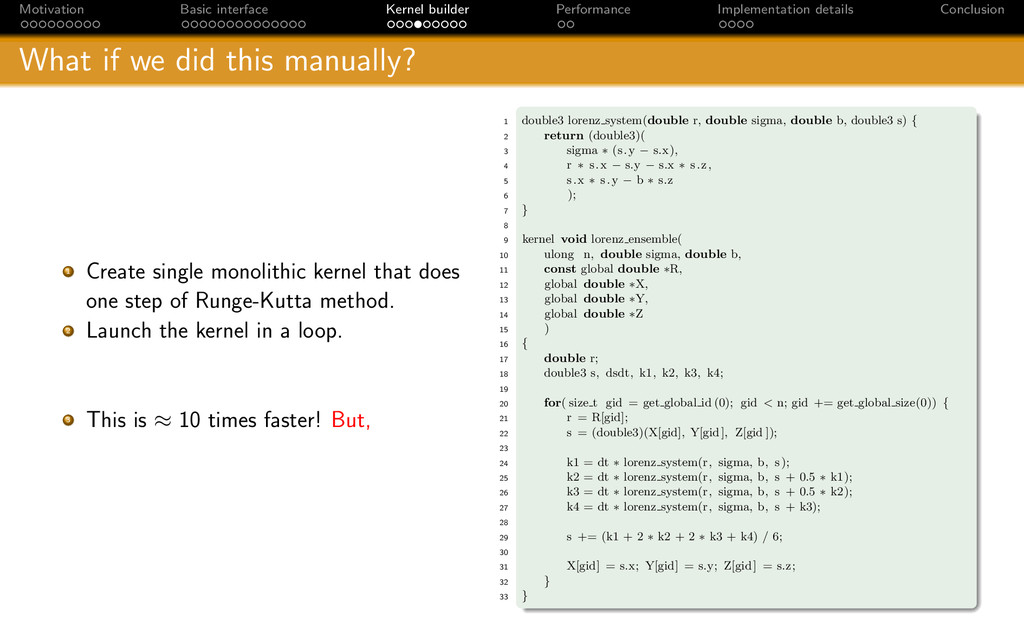{kind=link}
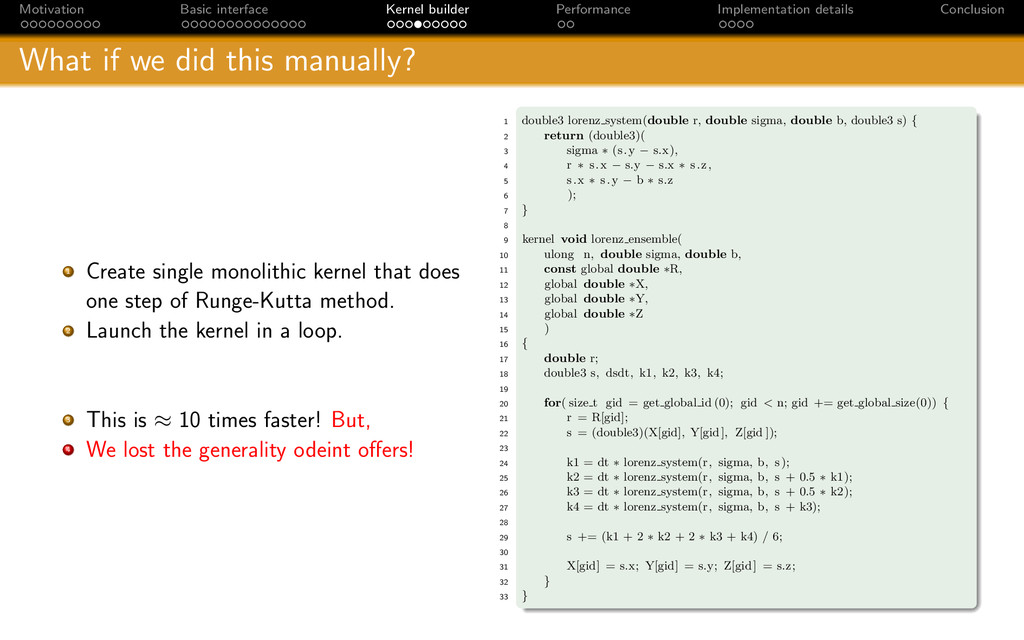{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
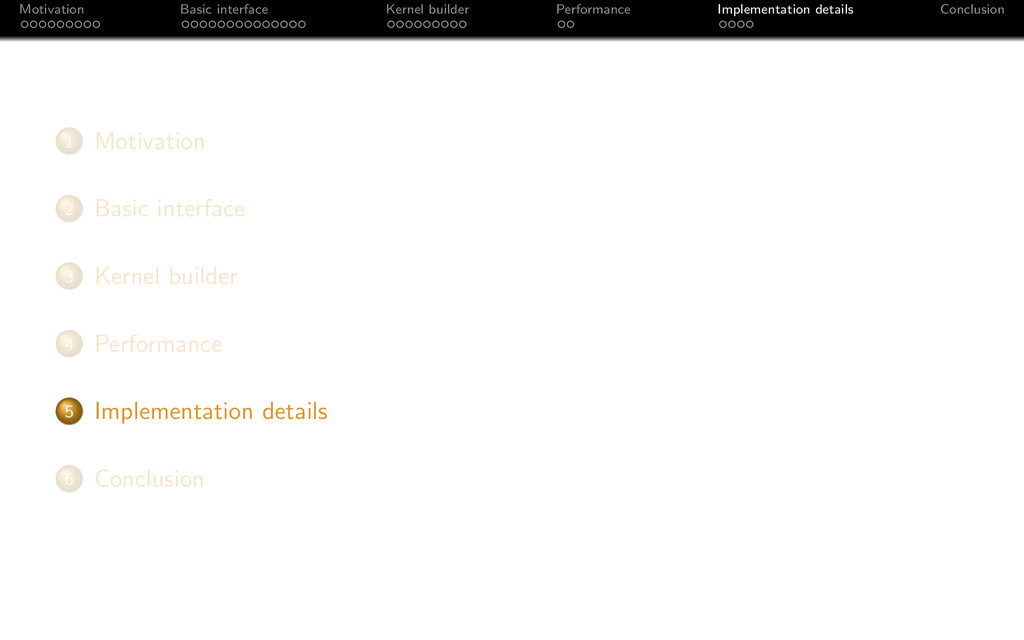{kind=link}
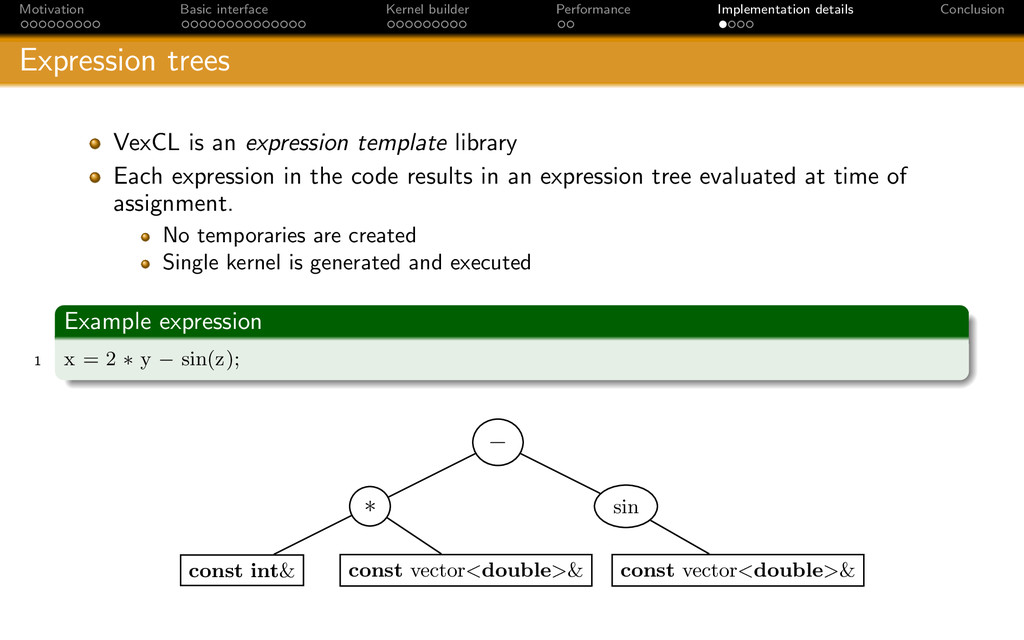{kind=link}
{kind=link}
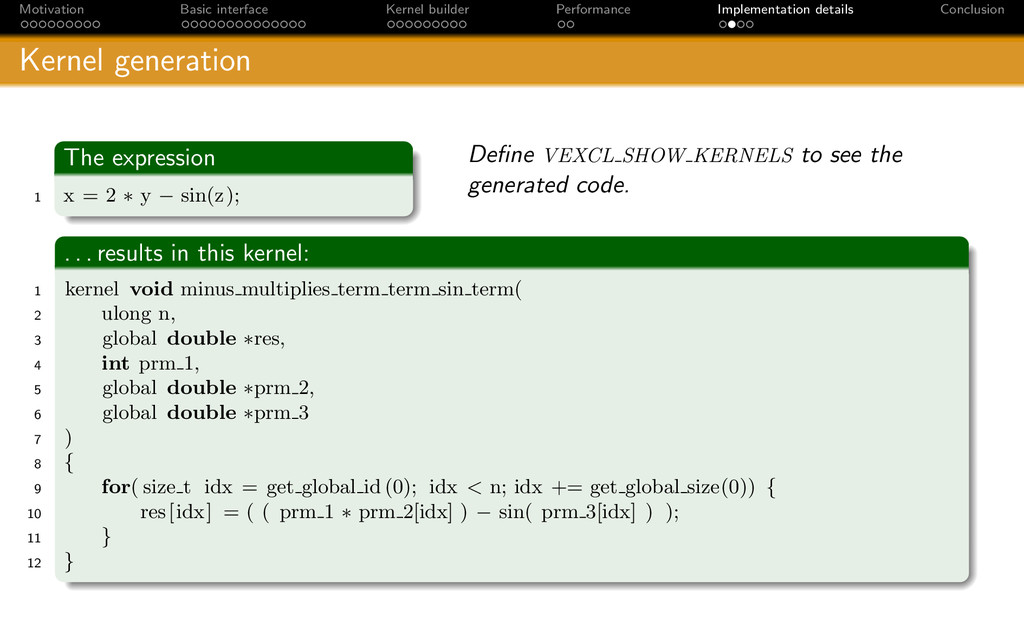{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}