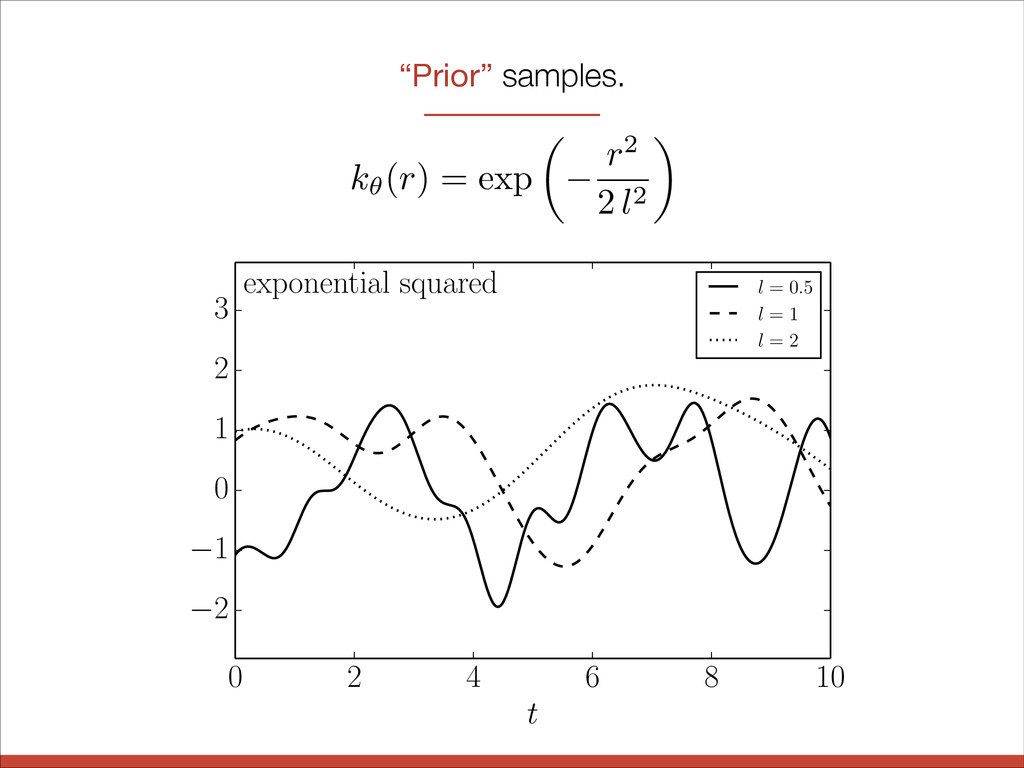
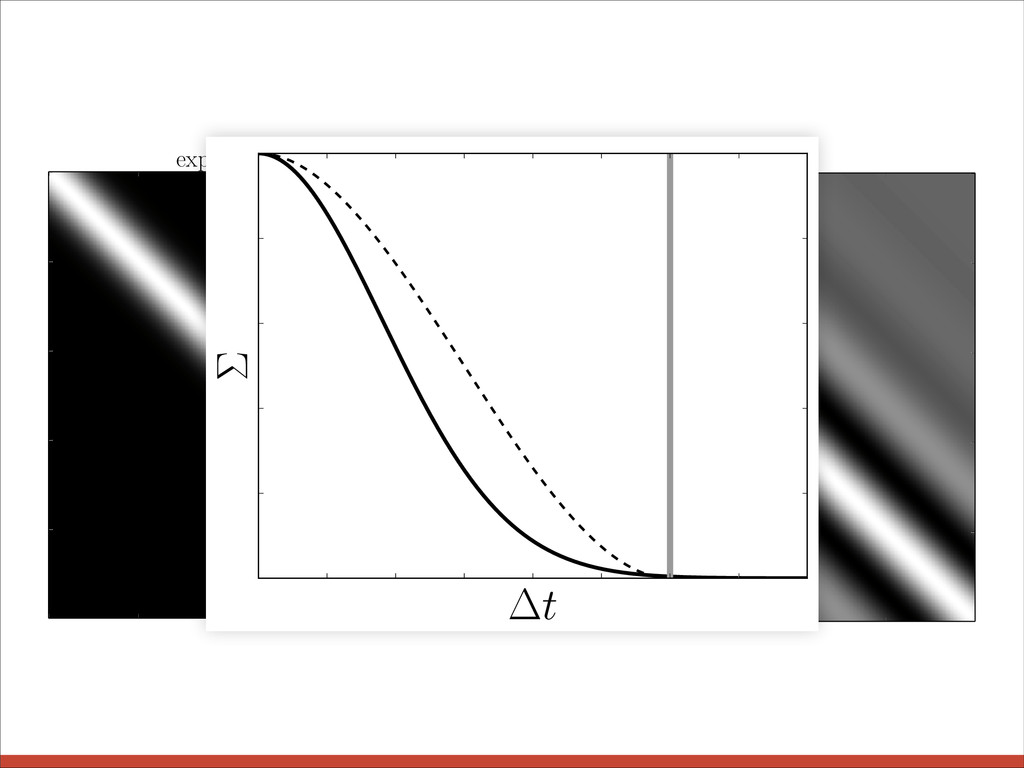
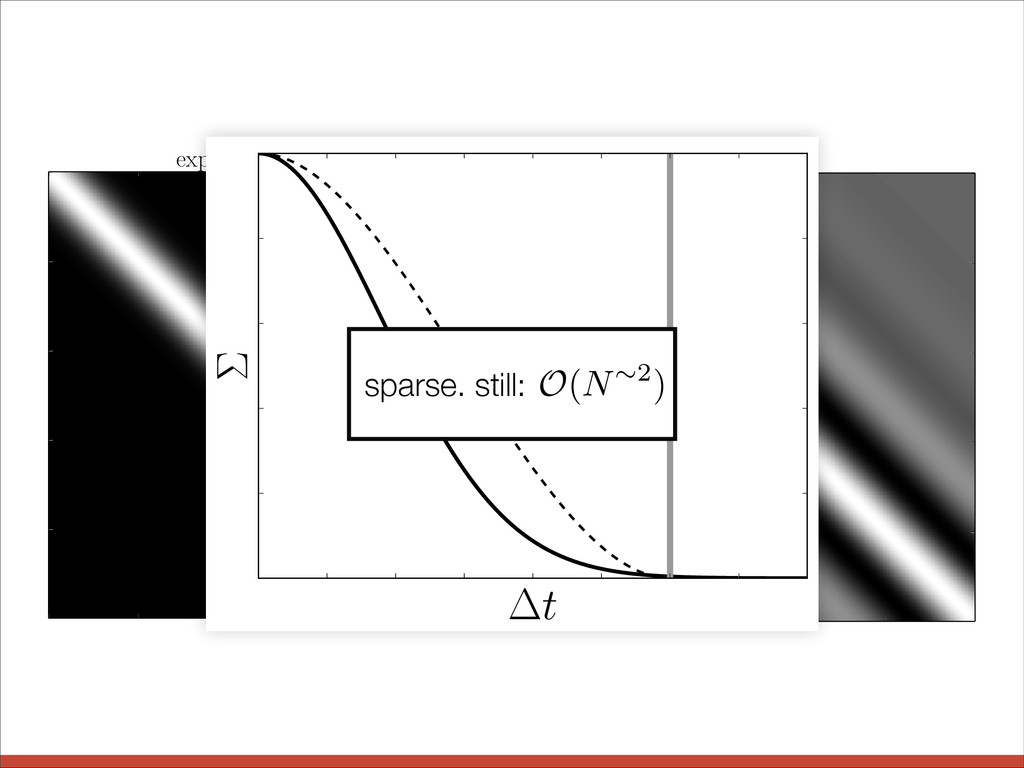
l = 0.5 l = 1 l = 2 3 quasi-periodic l = 2, P = 3 l = 3, P = 3 l = 3, P = 1 2 1 0 1 0 2 4 6 8 10 t 2 1 0 1 2 3 quasi-periodic l = 2, P = 3 l = 3, P = 3 l = 3, P = 1 k✓( r ) = exp ✓ r2 2 l2 ◆
l = 0.5 l = 1 l = 2 3 quasi-periodic l = 2, P = 3 l = 3, P = 3 l = 3, P = 1 2 1 0 1 0 2 4 6 8 10 t 2 1 0 1 2 3 quasi-periodic l = 2, P = 3 l = 3, P = 3 l = 3, P = 1 k✓( r ) = exp ✓ r2 2 l2 ◆ exponential squared
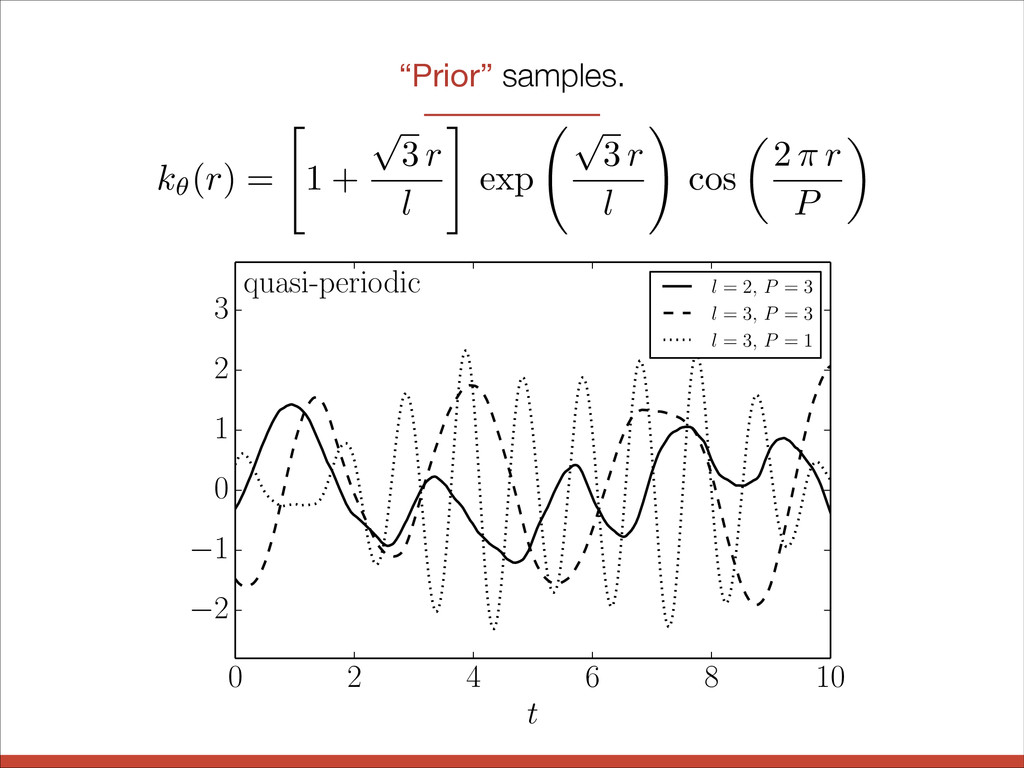
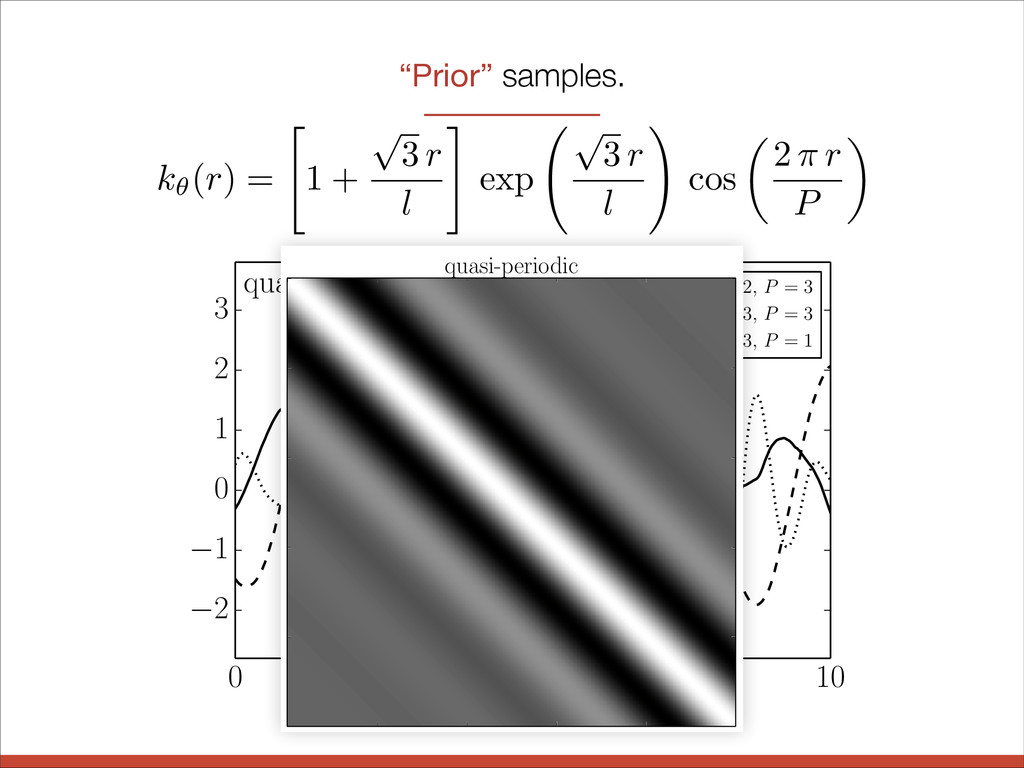
l # exp p 3 r l ! cos ✓ 2 ⇡ r P ◆ “Prior” samples. 2 1 0 1 0 2 4 6 8 10 t 2 1 0 1 2 3 quasi-periodic l = 2, P = 3 l = 3, P = 3 l = 3, P = 1 quasi-periodic
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
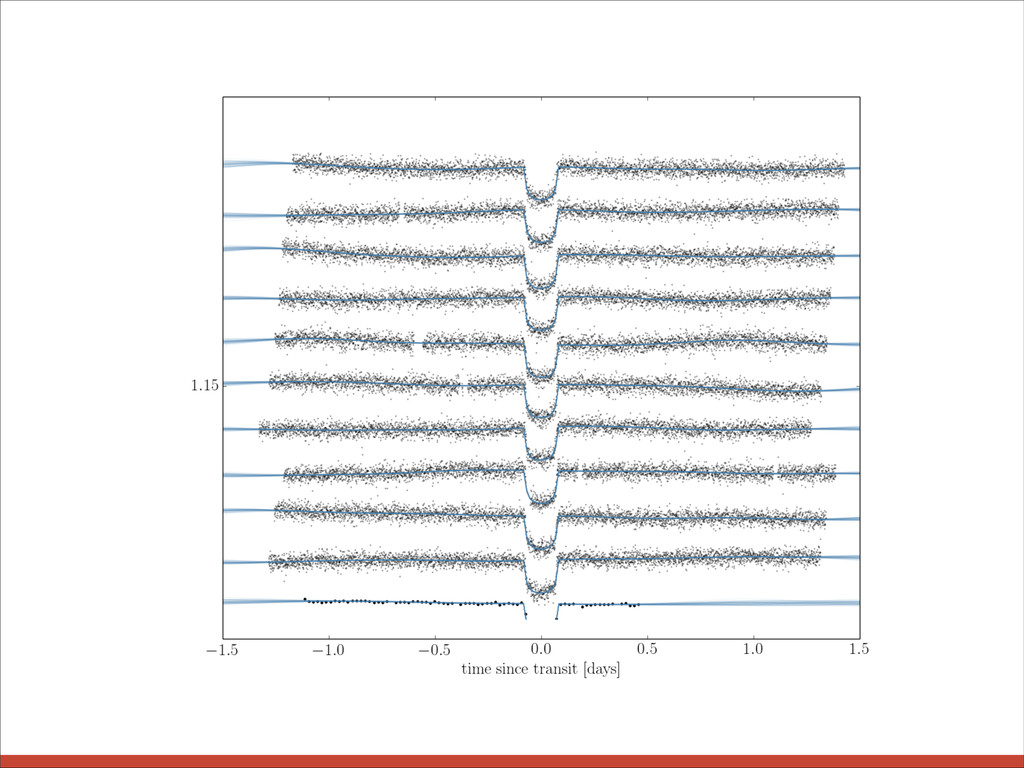
![635 640 645 650 655 660 time [KBJD] 0.004 0.003](https://files.speakerdeck.com/presentations/44f553008b4e013186e21e80f4899475/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
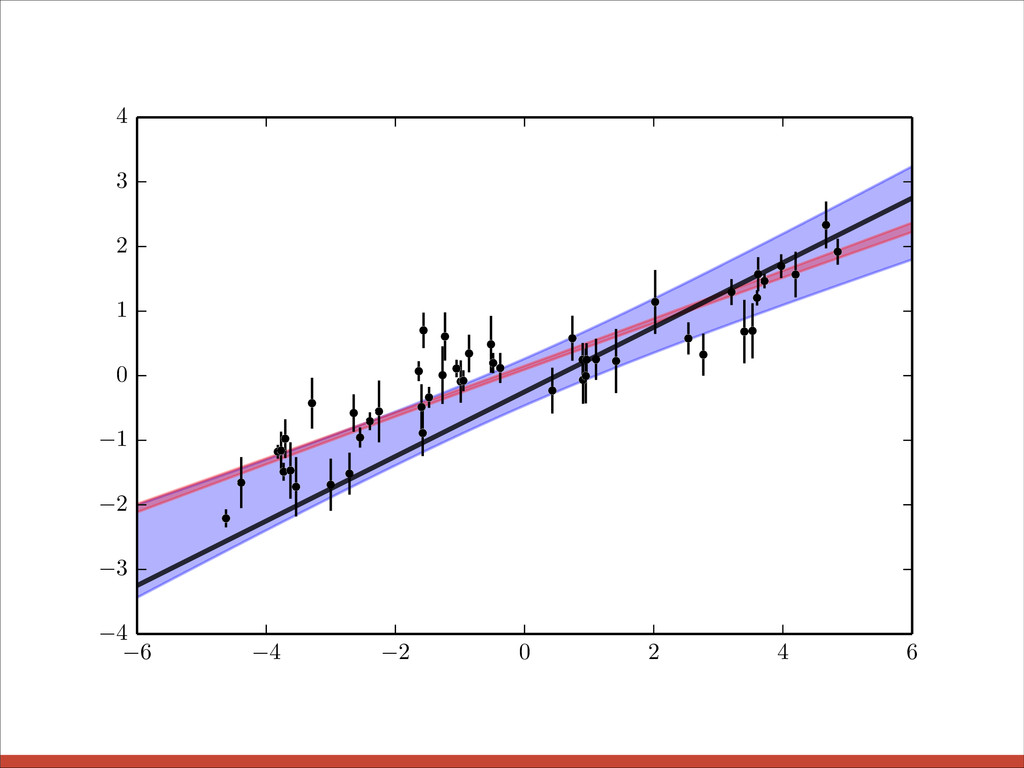{kind=link}
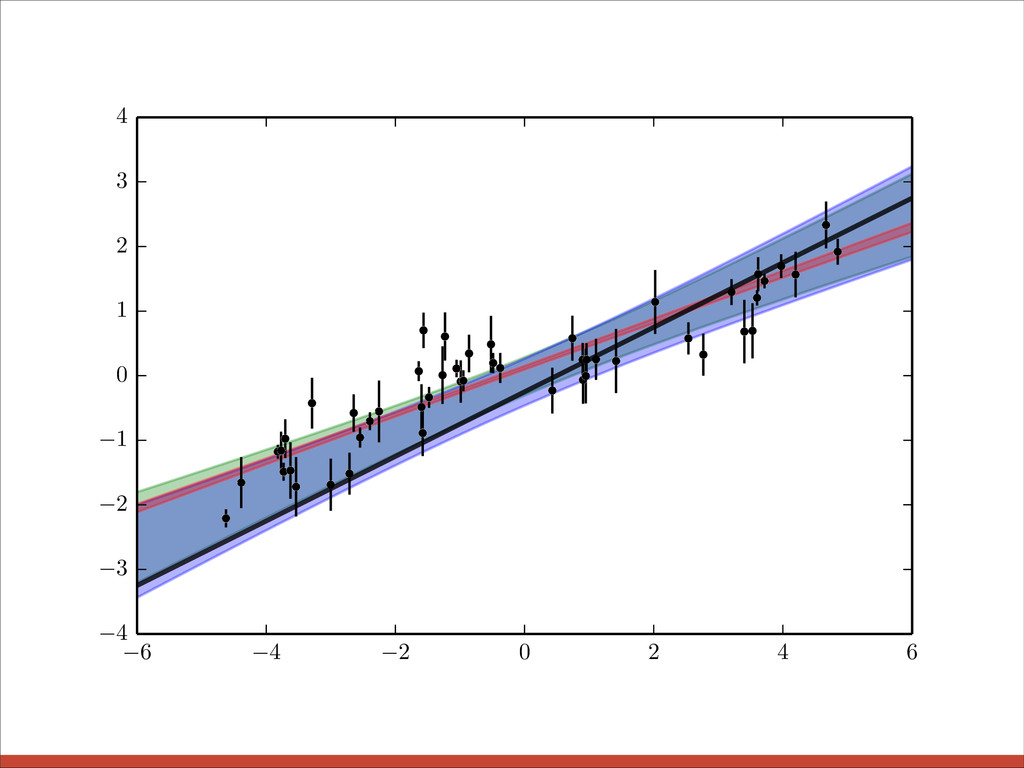{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
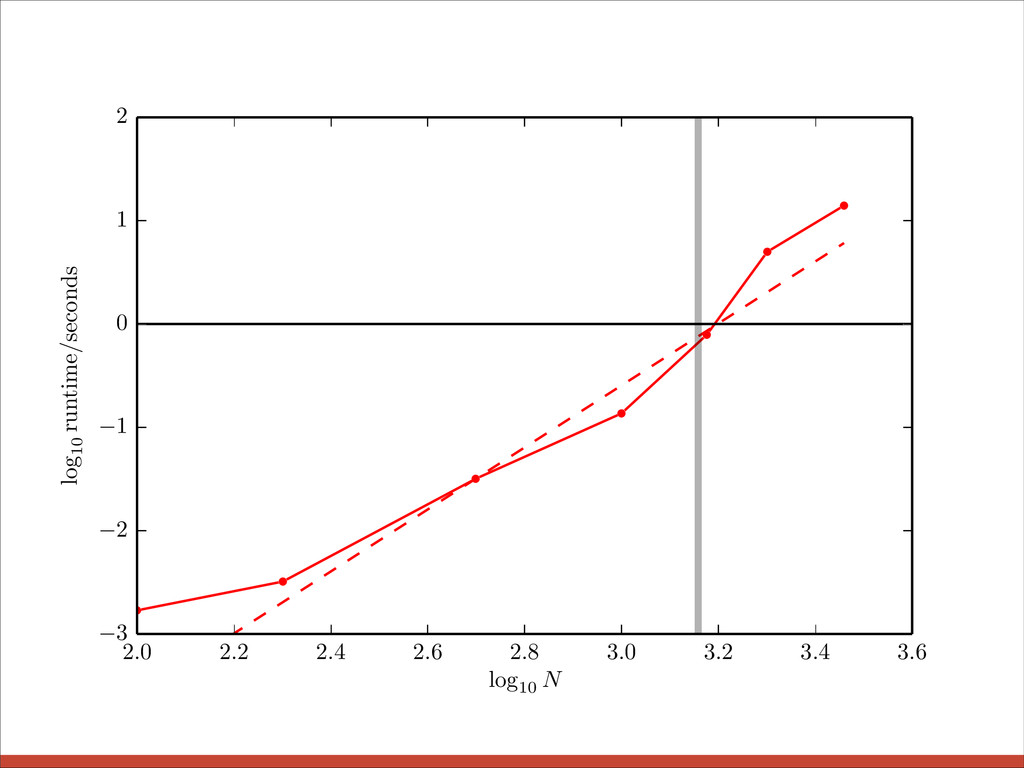{kind=link}
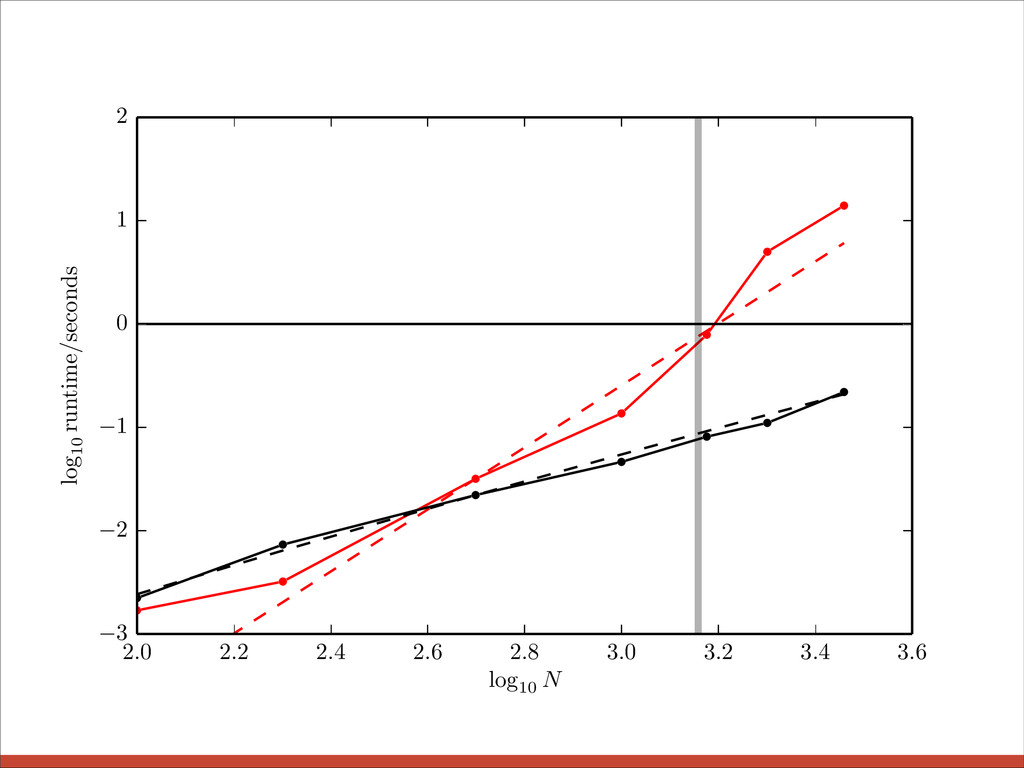{kind=link}
{kind=link}
{kind=link}
{kind=link}
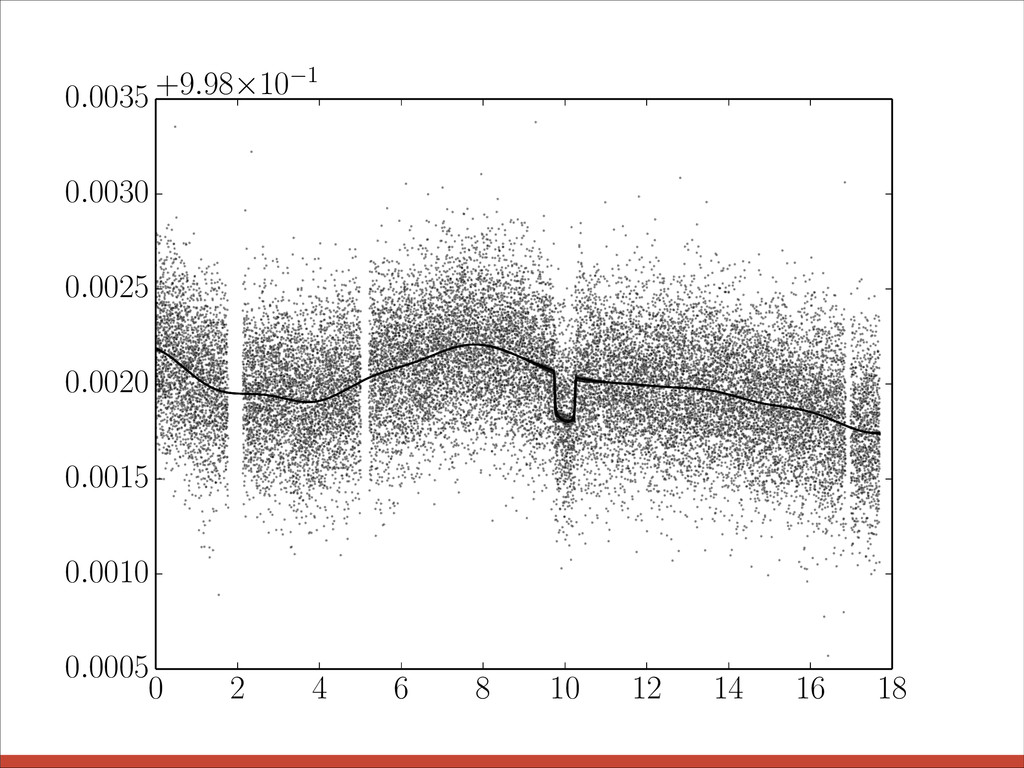{kind=link}
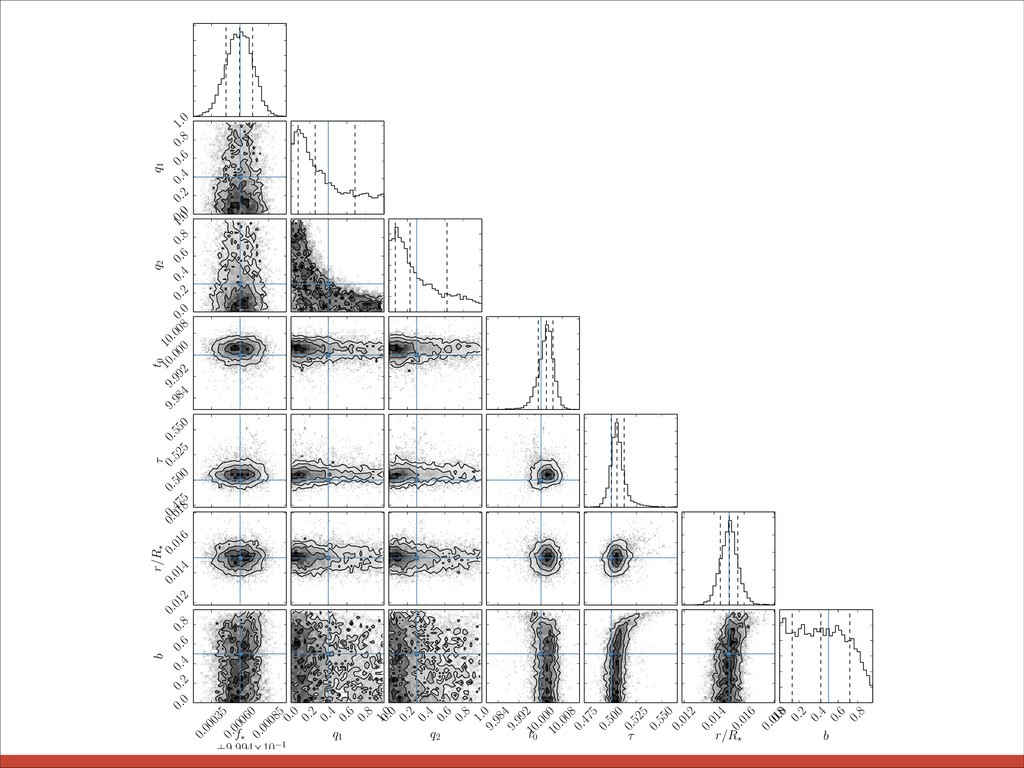{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}