file-system cache-friendly Cons – only works for static ranks – not if the sort order depends on the query – requires the index to be sorted – doesn’t work for tasks that require visiting every doc: – total number of matches – faceting Early termination
/ Unicorn – https://www.facebook.com/publications/219621248185635 Many more... Doesn’t need to be the exact sort order – heuristics when score is only a function of the static rank Static ranks
inserting docs between existing docs! – segments are immutable Offline sorting to the rescue: – index as usual – sort into a new index – search! Pros/cons – super fast to search, the whole index is fully sorted – but only works for static content Offline sorting
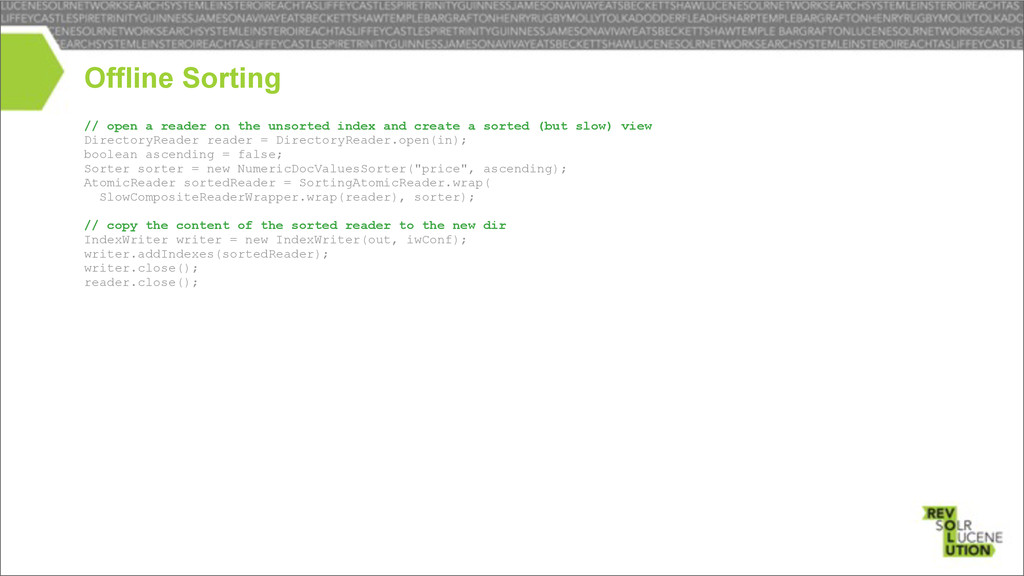
and create a sorted (but slow) view DirectoryReader reader = DirectoryReader.open(in); boolean ascending = false; Sorter sorter = new NumericDocValuesSorter("price", ascending); AtomicReader sortedReader = SortingAtomicReader.wrap( SlowCompositeReaderWrapper.wrap(reader), sorter); // copy the content of the sorted reader to the new dir IndexWriter writer = new IndexWriter(out, iwConf); writer.addIndexes(sortedReader); writer.close(); reader.close();
segments – collection could still be early-terminated on a per-segment basis But segments are immutable – must be sorted before starting writing them Online sorting?
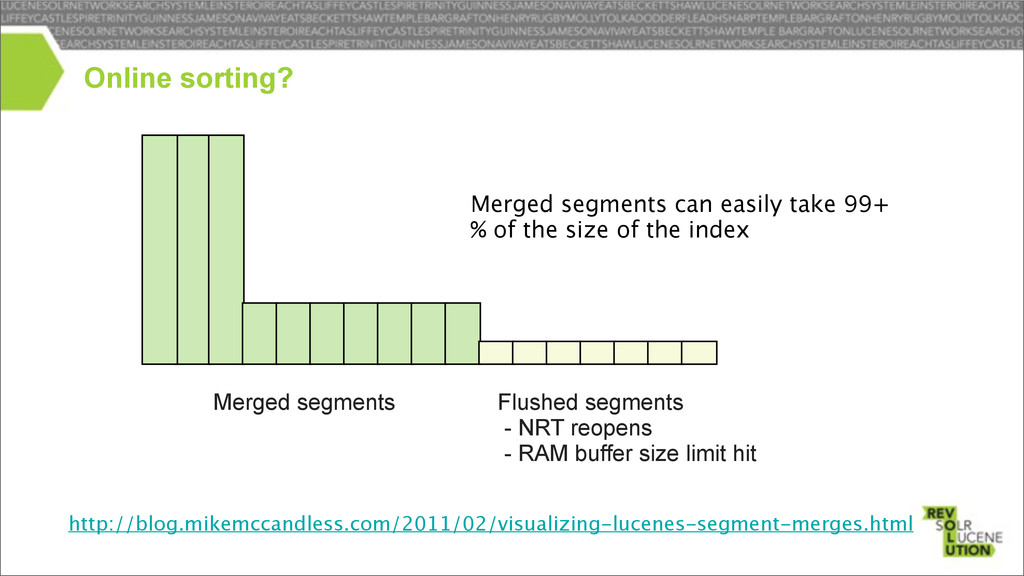
can’t be sorted – Lucene writes stored fields to disk on the fly – could be buffered but this would require a lot of memory merged segments can be sorted – create a sorted view over the segments to merge – pass this view to SegmentMerger instead of the original segments not a bad trade-off – flushed segments are usually small & fast to collect Online sorting?
size limit hit Merged segments http://blog.mikemccandless.com/2011/02/visualizing-lucenes-segment-merges.html Merged segments can easily take 99+ % of the size of the index
finds the segments to merge MergePolicy origMP = iwConf.getMergePolicy(); // SortingMergePolicy wraps the segments with a sorted view boolean ascending = false; Sorter sorter = new NumericDocValuesSorter("price", ascending); MergePolicy sortingMP = new SortingMergePolicy(origMP, sorter); // setup IndexWriter to use SortingMergePolicy iwConf.setMergePolicy(sortingMP); IndexWriter writer = new IndexWriter(dir, iwConf); // index as usual
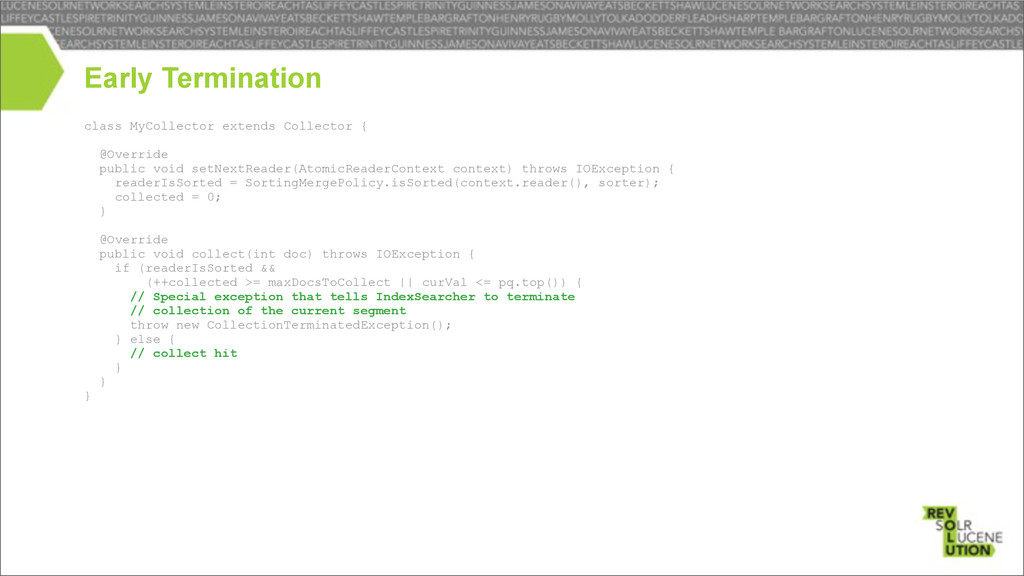
– early terminate after N matches have been collected – no priority queue needed! Online sorting – no early termination on flushed segments – early termination on merged segments – if N matches have been collected – or if current match is less than the top of the PQ Early termination
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}