Slides em HTML5: http://fgmacedo.github.io/talks/pybr9_raspador
Palestra apresentada na PythonBrasil[9], em Brasília.
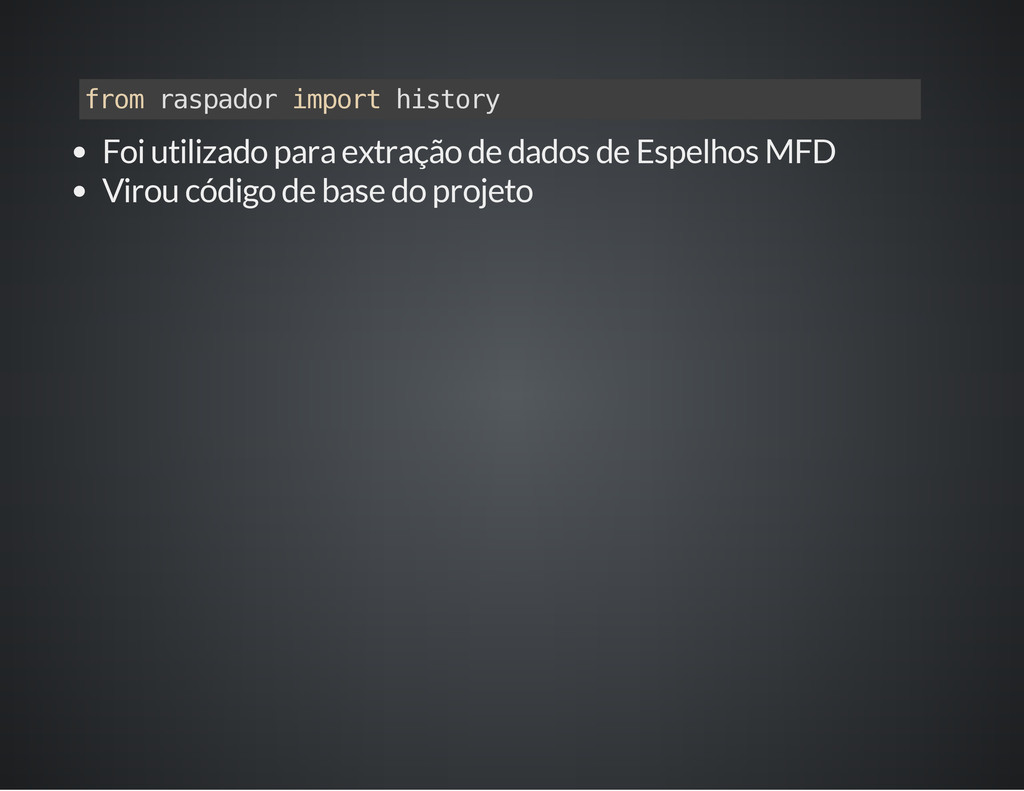
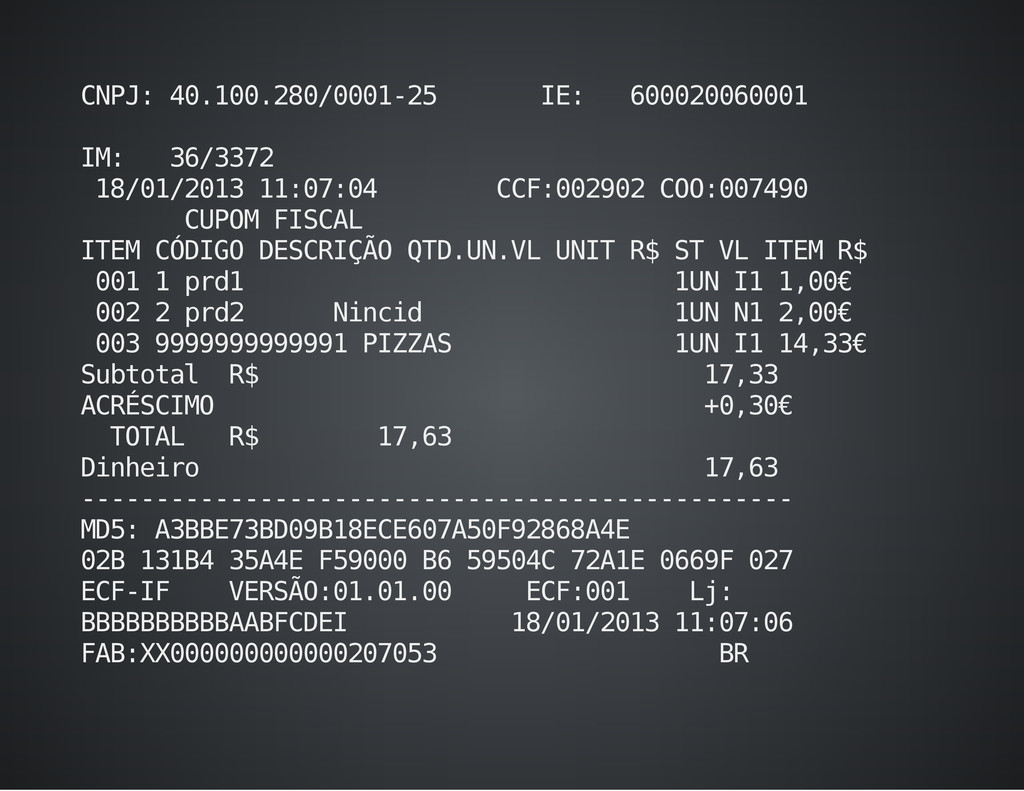
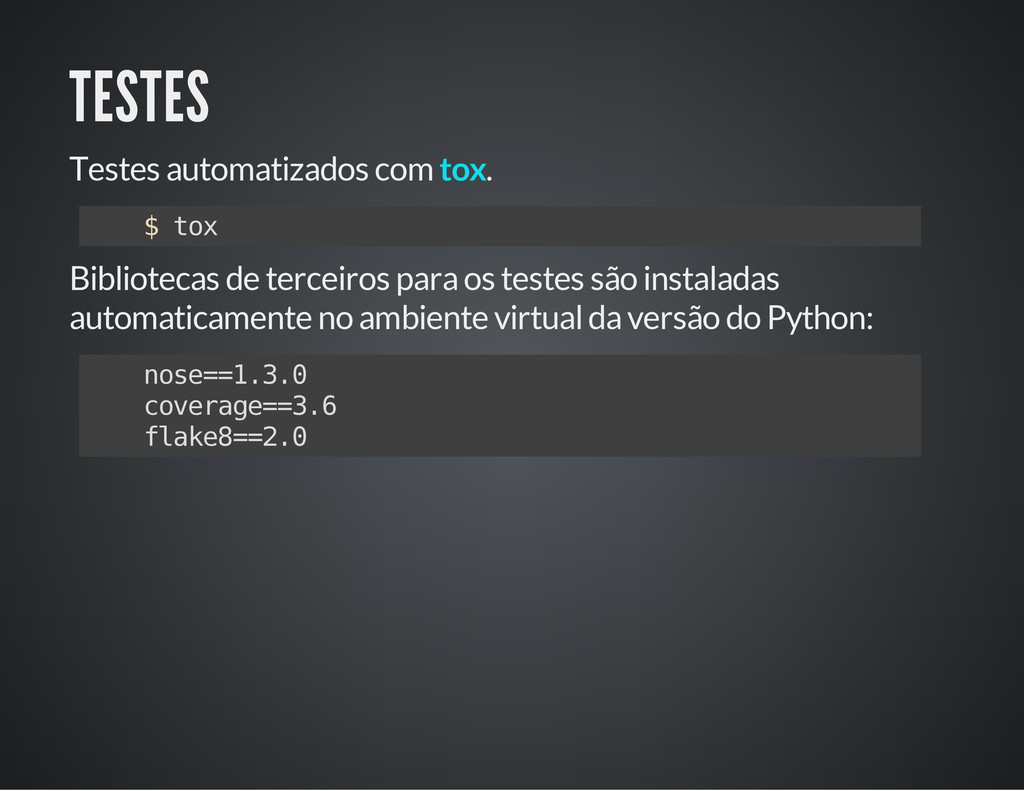
Com aproximadamente 500 linhas de código (+testes), o raspador é uma mini-biblioteca para extração de dados em fontes semi-estruturadas. Está em produção utilizado como fundamento para extração de dados em Espelhos MFD de impressoras fiscais.
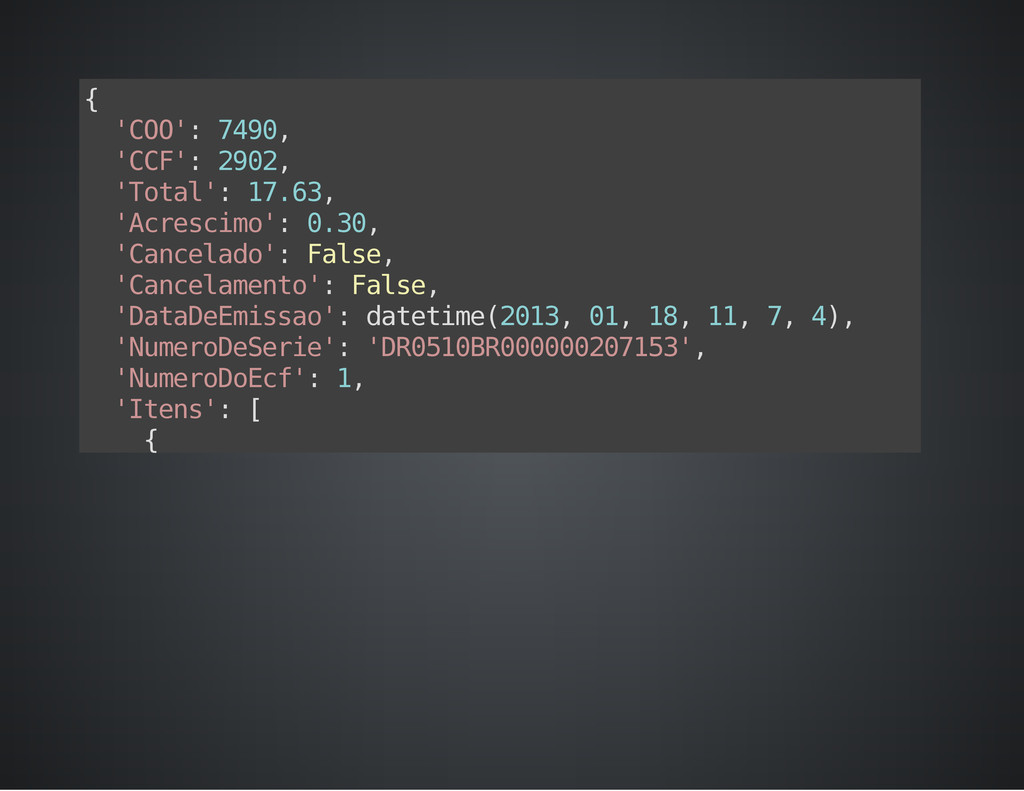
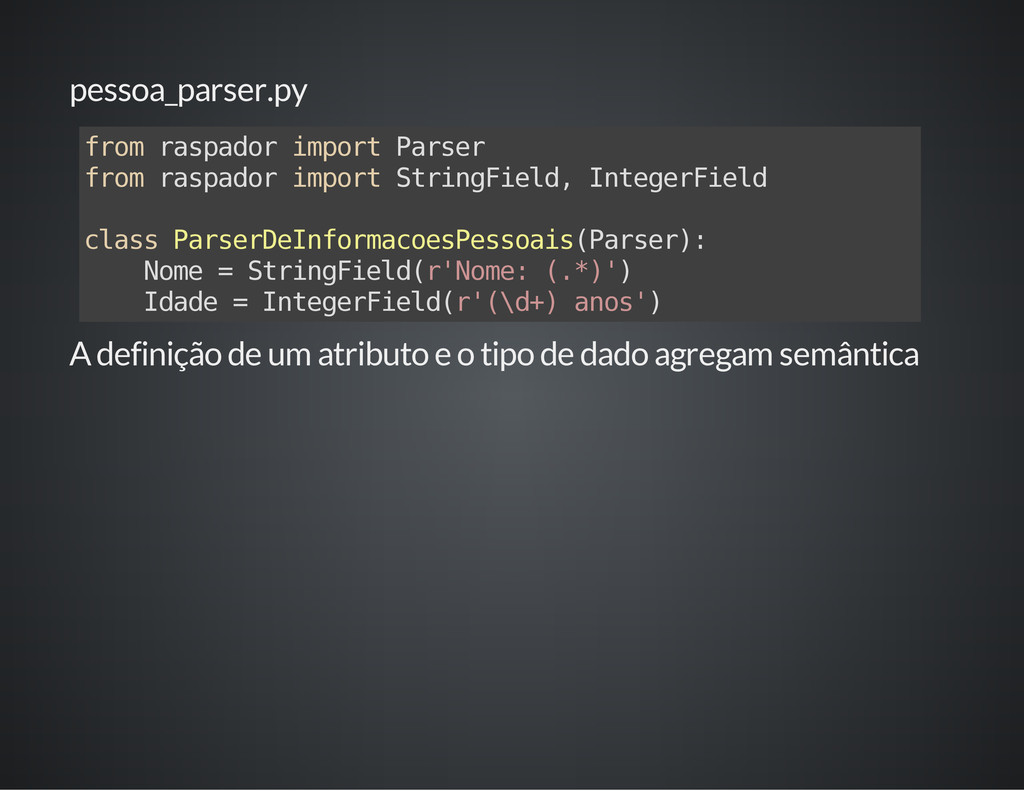
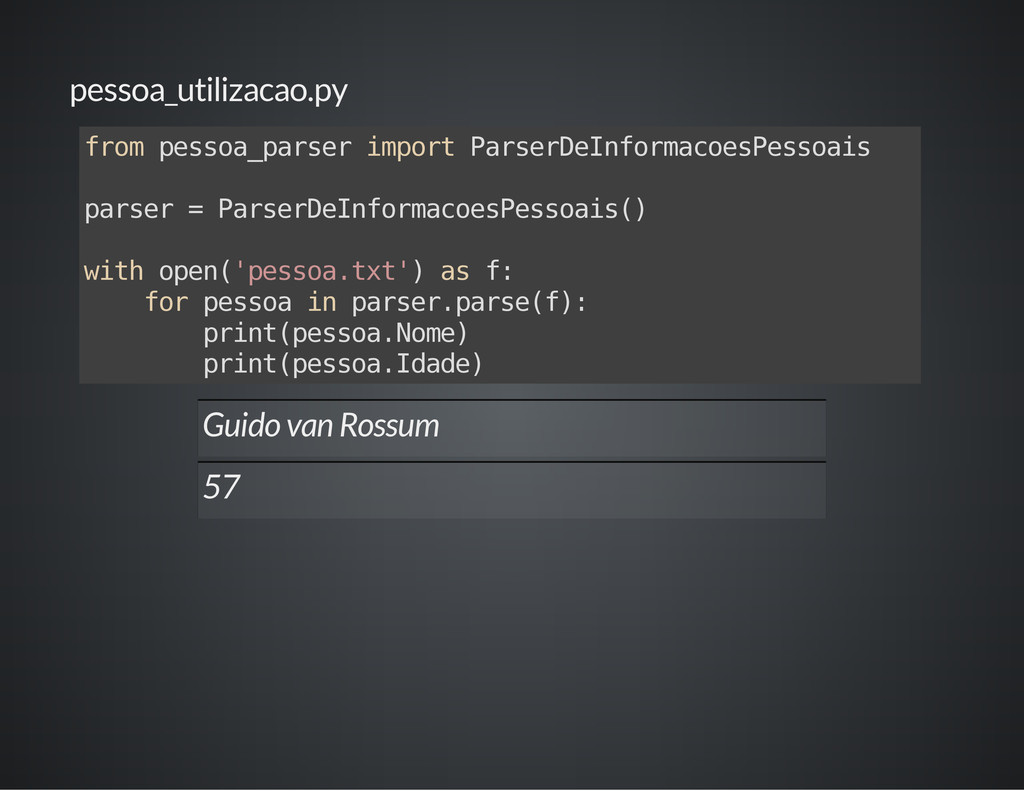
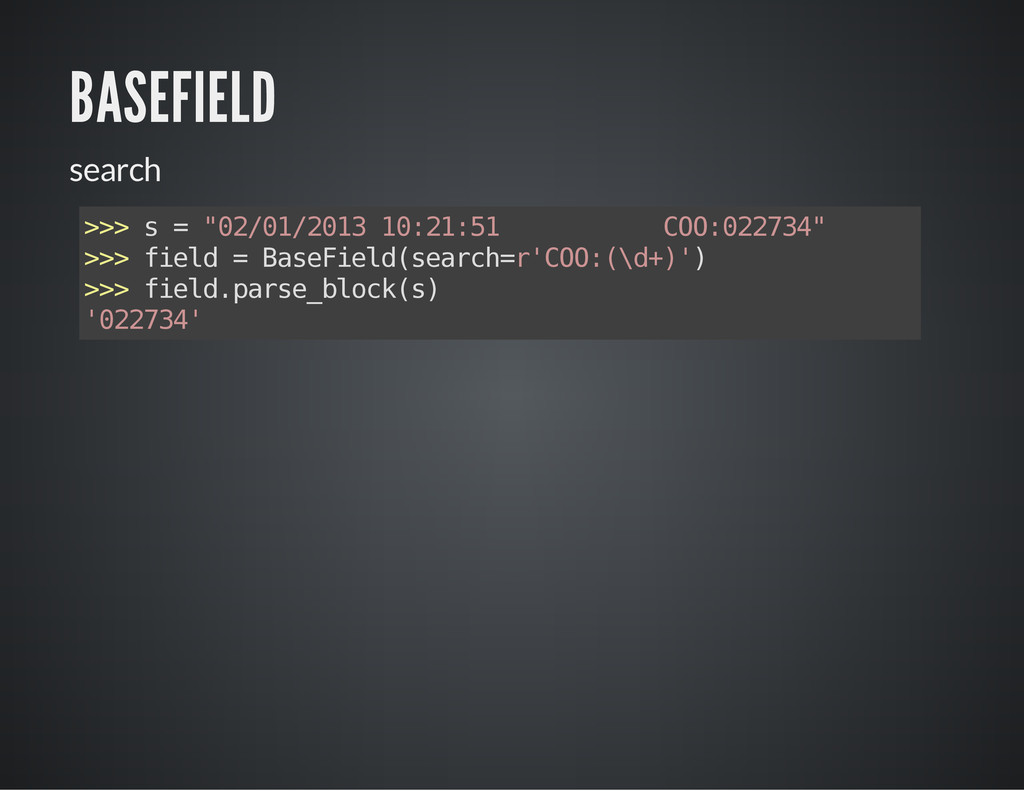
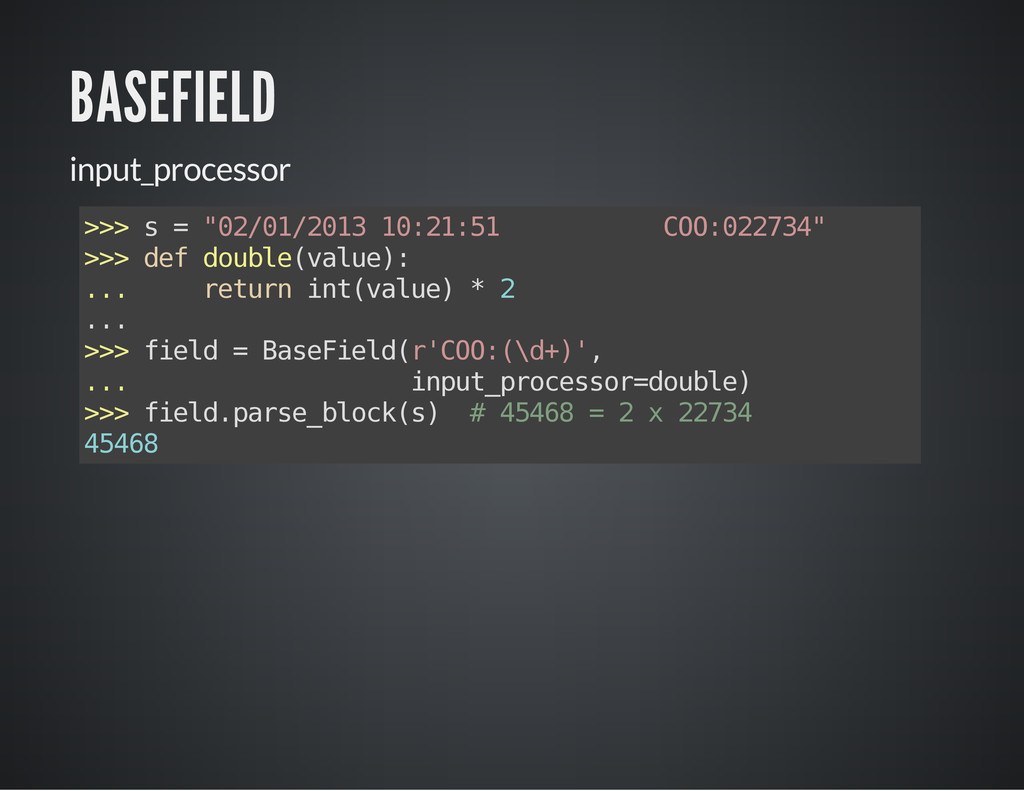
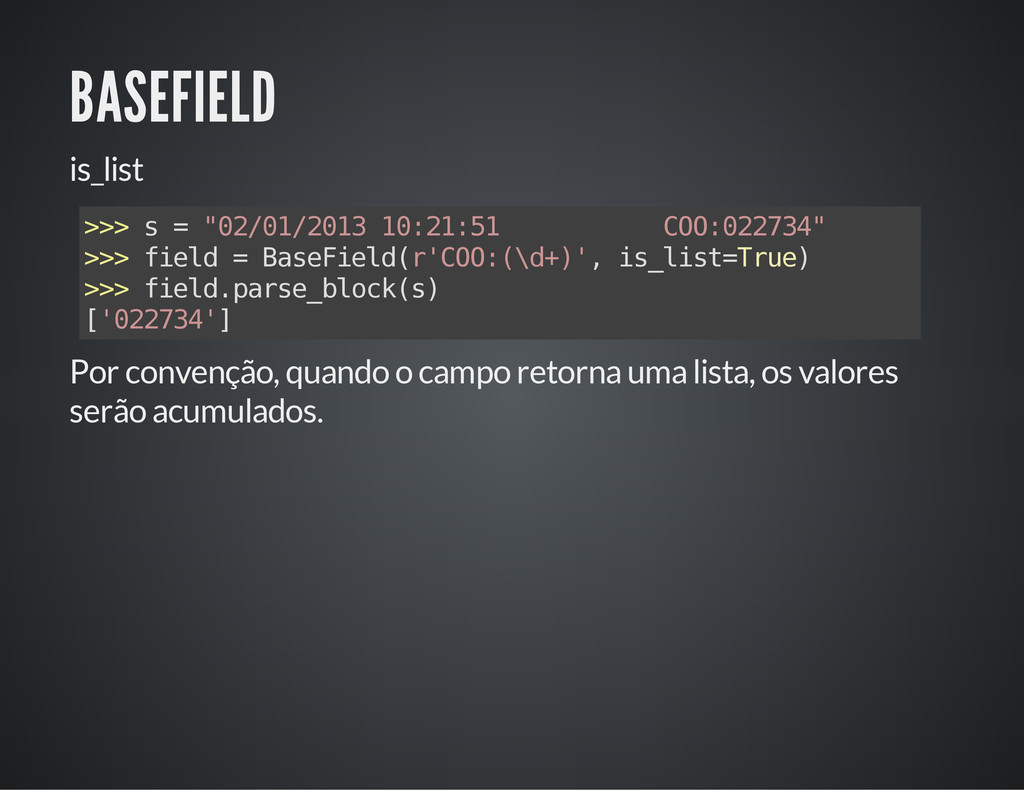
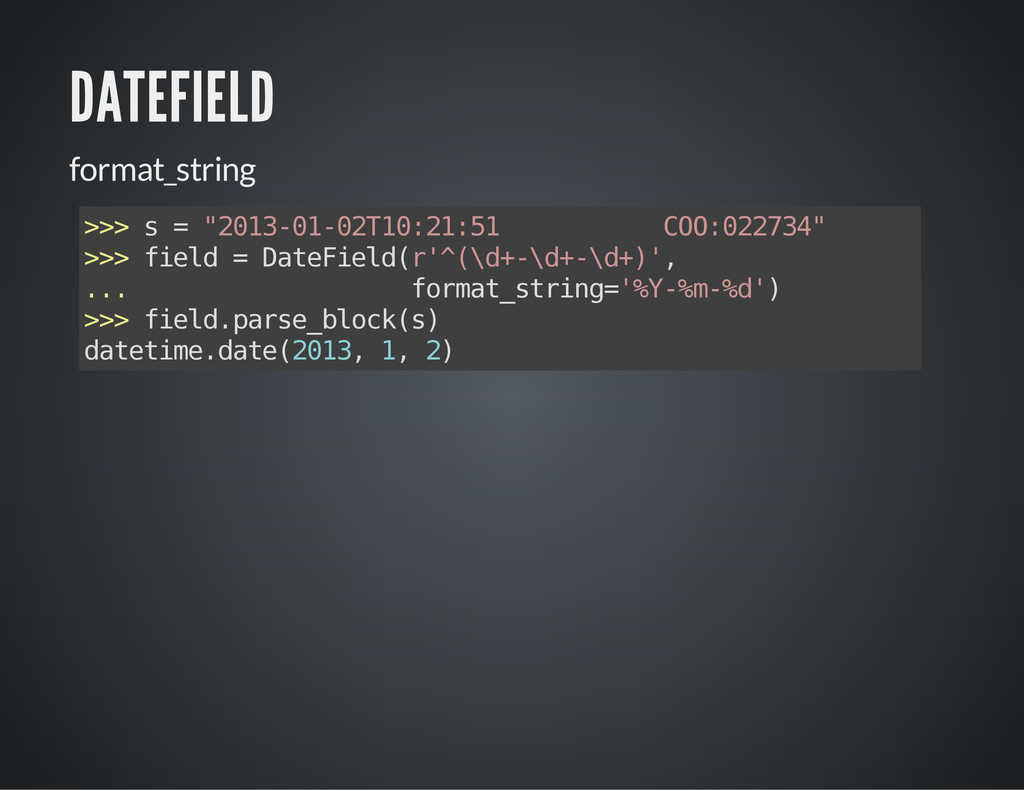
A definição dos extratores é feita através de classes como modelos, de forma semelhante ao ORM do Django. Cada extrator procura por um padrão especificado por expressão regular, e a conversão para tipos primitidos é feita automaticamente a partir dos grupos capturados.
O analisador é implementado como um gerador, onde cada item encontrado pode ser consumido antes do final da análise, caracterizando uma pipeline.
A análise é foward-only, o que o torna extremamente rápido, e deste modo qualquer iterador que retorne uma string pode ser analisado, incluindo streams infinitos.
Com uma base sólida e enxuta, é fácil construir seus próprios extratores.
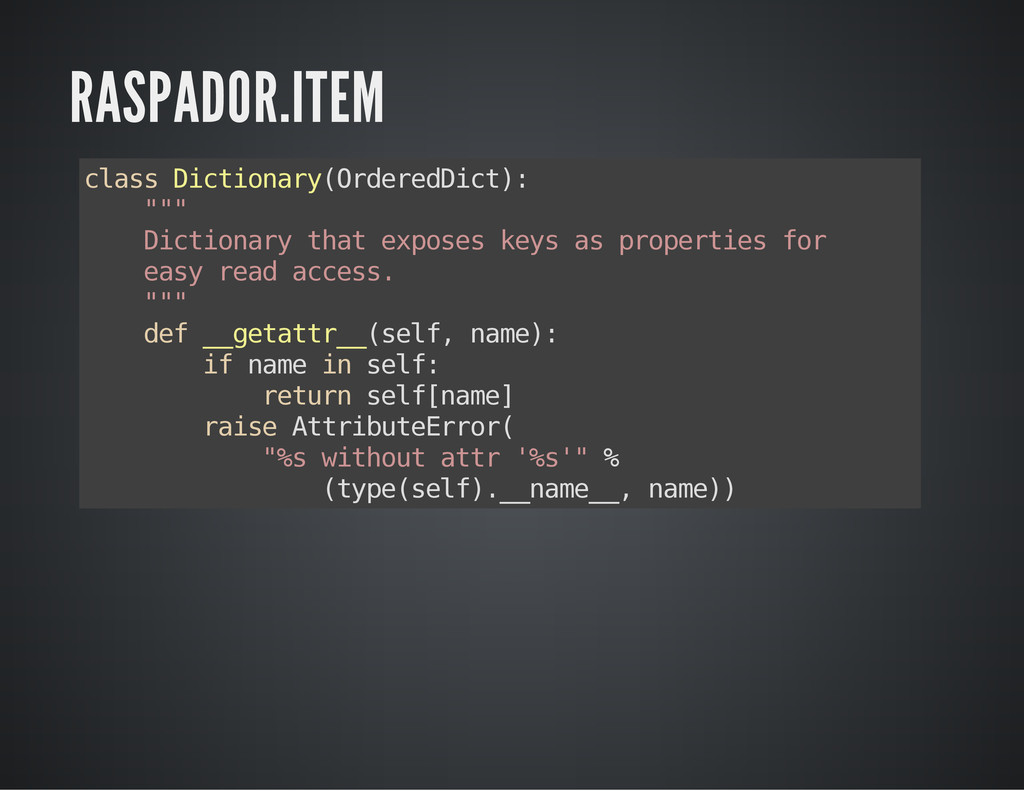
Além da utilidade da ferramenta, o raspador é um exemplo prático e simples da utilização de conceitos e recursos como iteradores, geradores, meta-programação e property-descriptors.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![O que faz? r e s = [ ] f](https://files.speakerdeck.com/presentations/c81af9a00f6701316eae12aa00a81214/slide_10.jpg){kind=link}
{kind=link}
![I n [ ] : # O q u e](https://files.speakerdeck.com/presentations/c81af9a00f6701316eae12aa00a81214/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![OBRIGADO! Fernando Macedo (Slides) @fgmacedo fgmacedo.com [email protected] http://code.fgmacedo.com/talks](https://files.speakerdeck.com/presentations/c81af9a00f6701316eae12aa00a81214/slide_31.jpg){kind=link}