analysis, environmental monitoring, surveillance, customer behavior, urban dynamics, social science and media studies running example: when did buses pass by this intersection today? increasingly cheap to acquire this data… ...how to process it?
nonlinear functions capture representations » Preferred for image analytics, often better than humans » High-quality models widely available (e.g., open source on GitHub) Enables new kinds of downstream analytics (e.g., use with DBMS)
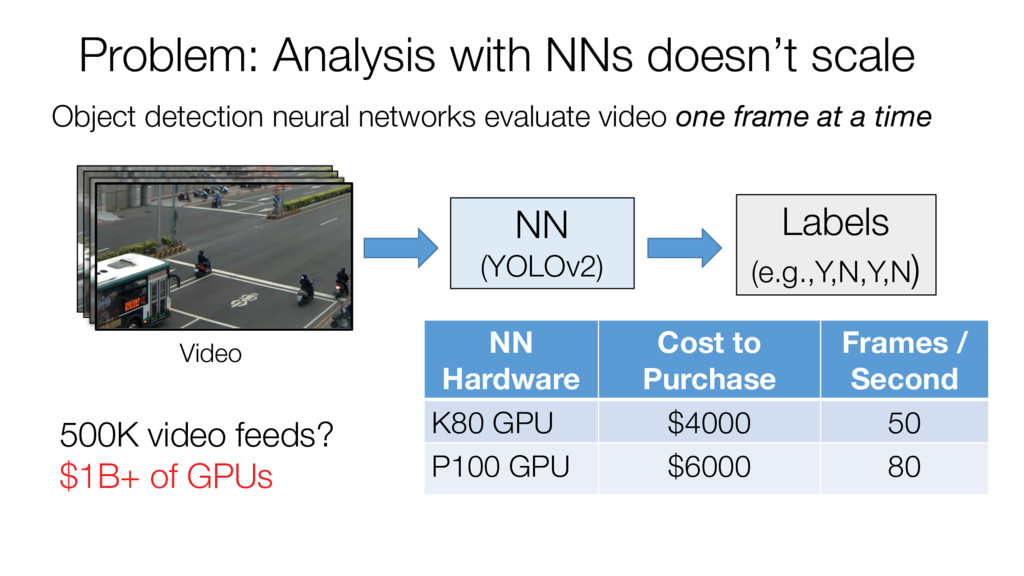
time NN (YOLOv2) Problem: Analysis with NNs doesn’t scale NN Hardware Cost to Purchase Frames / Second K80 GPU $4000 50 P100 GPU $6000 80 Video Labels (e.g.,Y,N,Y,N) 500K video feeds? $1B+ of GPUs
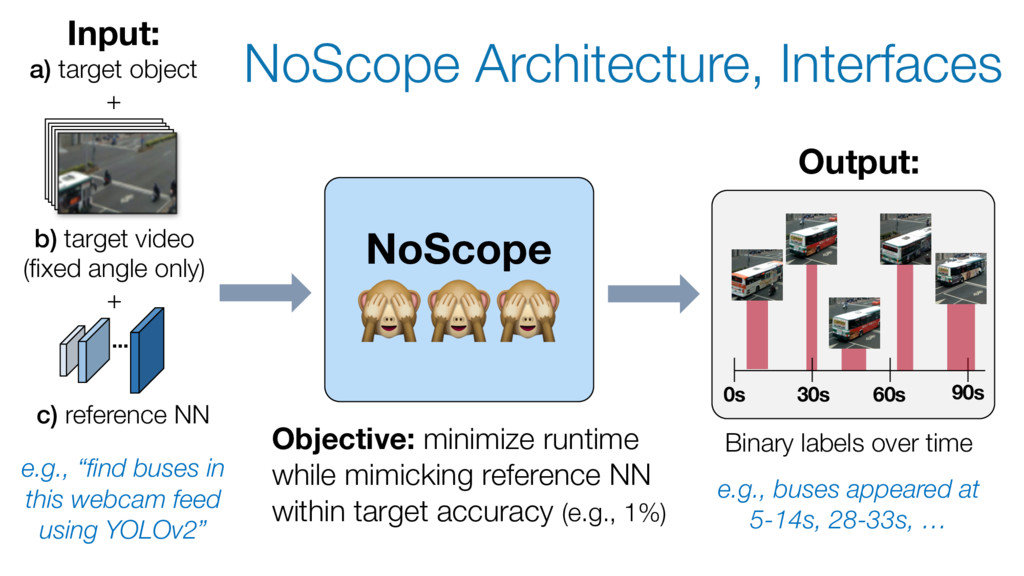
video (fixed angle only) + c) reference NN e.g., “find buses in this webcam feed using YOLOv2” ... NoScope Output: 0s 30s 60s 90s Binary labels over time e.g., buses appeared at 5-14s, 28-33s, … Objective: minimize runtime while mimicking reference NN within target accuracy (e.g., 1%)
in arbitrary scenes and from arbitrary angles images from training set for YOLOv2 Query: “When did buses pass by this intersection?” Opportunity 1: Query-specific locality If we only want to detect buses in a given video, we’re overpaying
reference NN to train a smaller, specialized NN The specialized NN: Only works for a given video feed and object Is much, much smaller than the reference NN
per layer 4096 neurons in FC layer 4 convolutional layers 32-128 filters per layer 32 neurons in FC layer 35 billion FLOPS 3 million FLOPS 10,000x fewer FLOPS NoScope specialized model YOLOv2
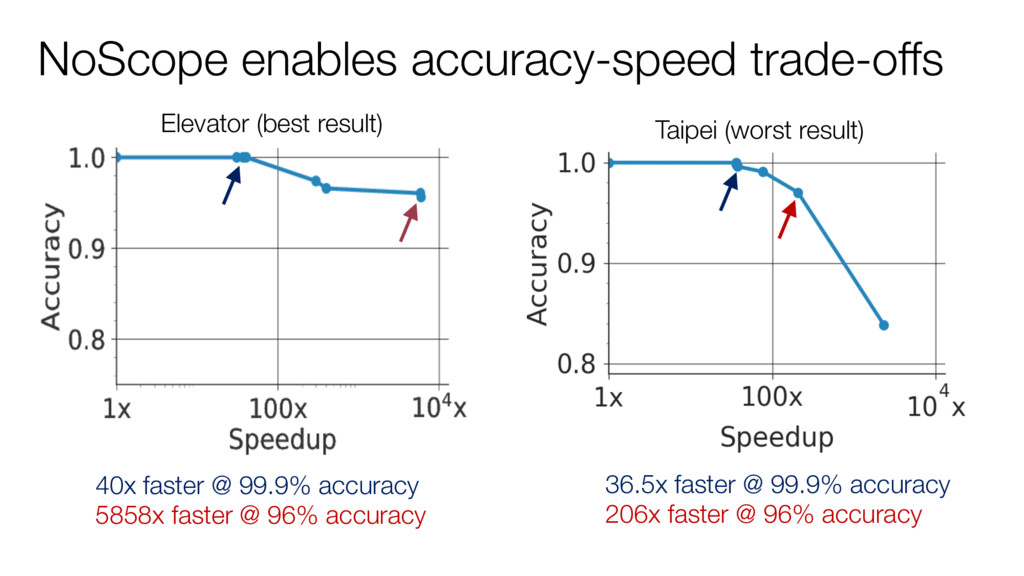
Goal: smaller model for same task as reference model Result: typically 2-10x faster execution Specialization: perform “lossy” compression of reference model A specialized model does not generalize to other videos… …but is accurate on target video, up to 300x faster
hours to obtain video-specific training data 2. Train specialized NN over video-specific training data 3. Enable specialized NN, only call big NN when unsure In paper: NoScope automatically searches for the smallest NN
for detecting scene changes NoScope: simple regression model over subtracted frames - = Frame 1 Frame 0 Difference Difference detection runs at 100k+ fps on CPU Surprising: detecting differences is faster than even specialized NNs
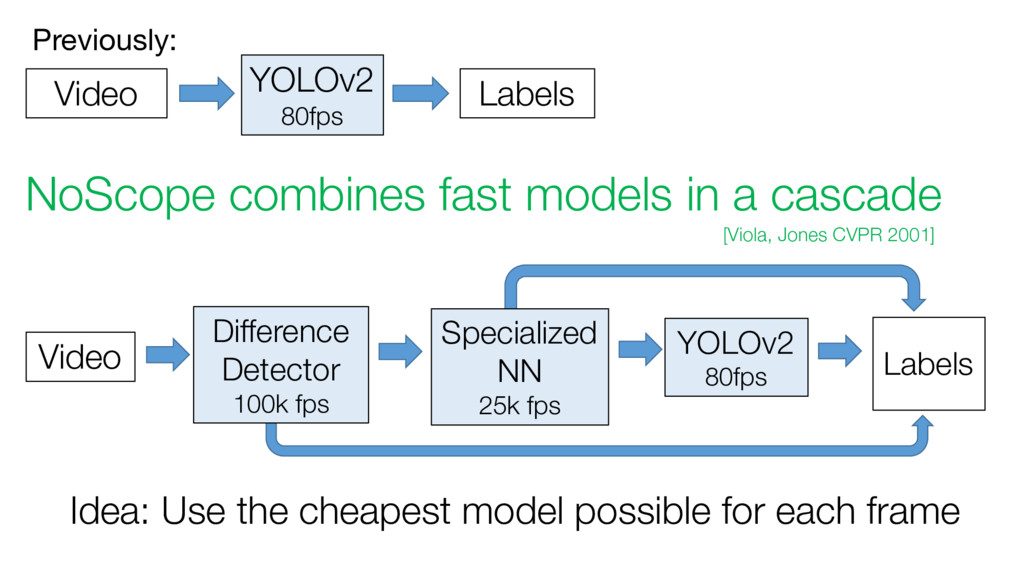
Video Previously: [Viola, Jones CVPR 2001] YOLOv2 80fps Labels Specialized NN 25k fps Difference Detector 100k fps Idea: Use the cheapest model possible for each frame Video
NoScope performs: Model search: e.g., how many layers in specialized NN? Cascade search: e.g., how to set the cascade thresholds? Data-dependent process: high-quality choices vary across queries and videos (see paper)
of video for training data (~75 minutes) 2. Model search specialized NN, difference detector (15 minutes) 3. Perform cascade firing threshold search (2 minutes) 4. Activate cascade to process rest of video
bus/no bus) Ongoing research on also locating objects (e.g., bus location) Targets fixed-angle cameras (e.g., surveillance cameras) Ongoing research on moving cameras Does not automatically handle model drift Requires representative training set (e.g., morning, afternoon) Batch-oriented processing Poor on-GPU support for control flow in cascades
32 CPU cores + specialized/target NNs runs on P100 GPU; omit MPEG decode time Seven video streams from real-world, fixed-angle surveillance cameras; 8-12 hours of video per stream (evaluation set) Taipei: bus Amsterdam: car Store: person Jackson Hole: car
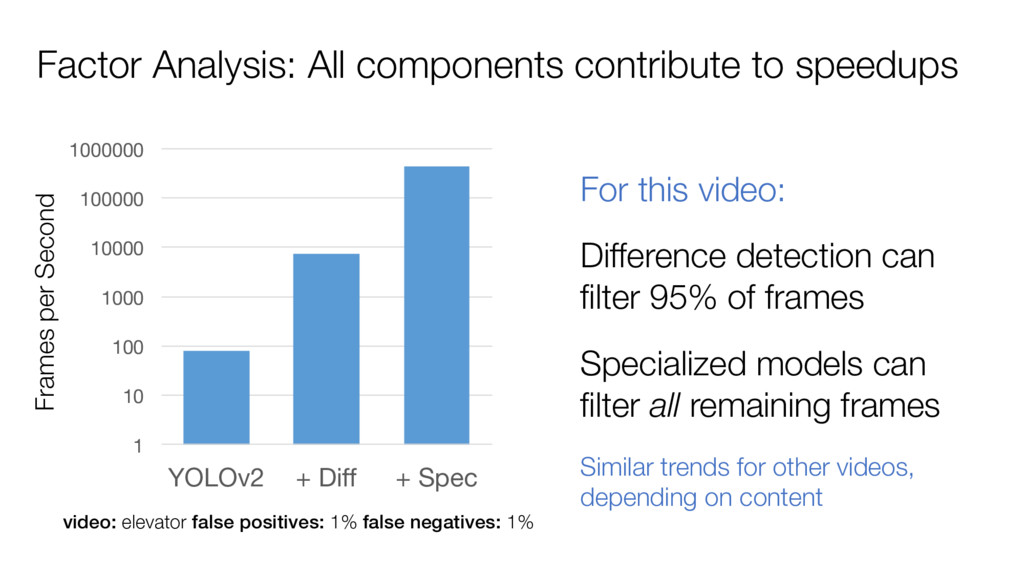
filter 95% of frames Specialized models can filter all remaining frames 1 10 100 1000 10000 100000 1000000 YOLOv2 + Diff + Spec Frames per Second video: elevator false positives: 1% false negatives: 1% For this video: Similar trends for other videos, depending on content
each optimization » Demonstration of optimizer selection procedure » Efficient firing threshold search for optimizer » Additional details on limitations and extensions » Additional related work for computer vision, NNs, RDBMS
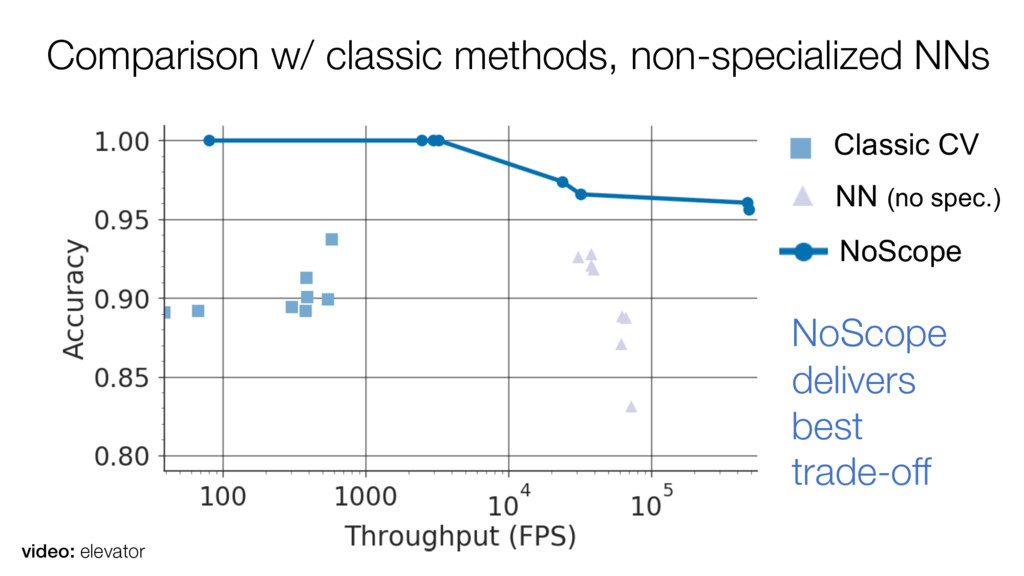
but are very slow to execute (50-80fps on GPU) NoScope accelerates NN-based video queries by: 1. Specializing networks to exploit query-specific locality 2. Training difference detectors to exploit temporal locality 3. Cost-based optimization for video-specific cascades Promising results (10-1000x speedups) for many queries https://github.com/stanford-futuredata/noscope
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Specialization != Model Compression Model compression/distillation [NIPS14, ICLR16]: lossless models](https://files.speakerdeck.com/presentations/784a4f6500b74fcc806306edac82d549/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}