one should I use? Which method has been shown to consistently work well on a variety of problems? What are the implicit statistical assumptions of feature selection criteria based on mutual information? How will the classifier be affected by the feature selection method? If classifier C1 performed better with JMI than MIM will C2 perform better with JMI than MIM (given similar structure in the data)? Ditzler, Polikar & Rosen (Drexel University) GENSIPS (2012), Washington, D.C. May 3, 2013 2 / 15
and stimulus Consider a data set collected from healthy patients’ and unhealthy patients’ guts. The goal is to determine which organisms carry information that can differentiate between the healthy and unhealthy populations. From a biological perspective, the selection of organisms allows the biologist the opportunity to examine why a set of species is responsible for differentiating healthy and unhealthy patients. From a machine learning perspective, this is a problem of feature selection. There may be additional factors that influence the results, but may not be in the feature set. Ditzler, Polikar & Rosen (Drexel University) GENSIPS (2012), Washington, D.C. May 3, 2013 3 / 15
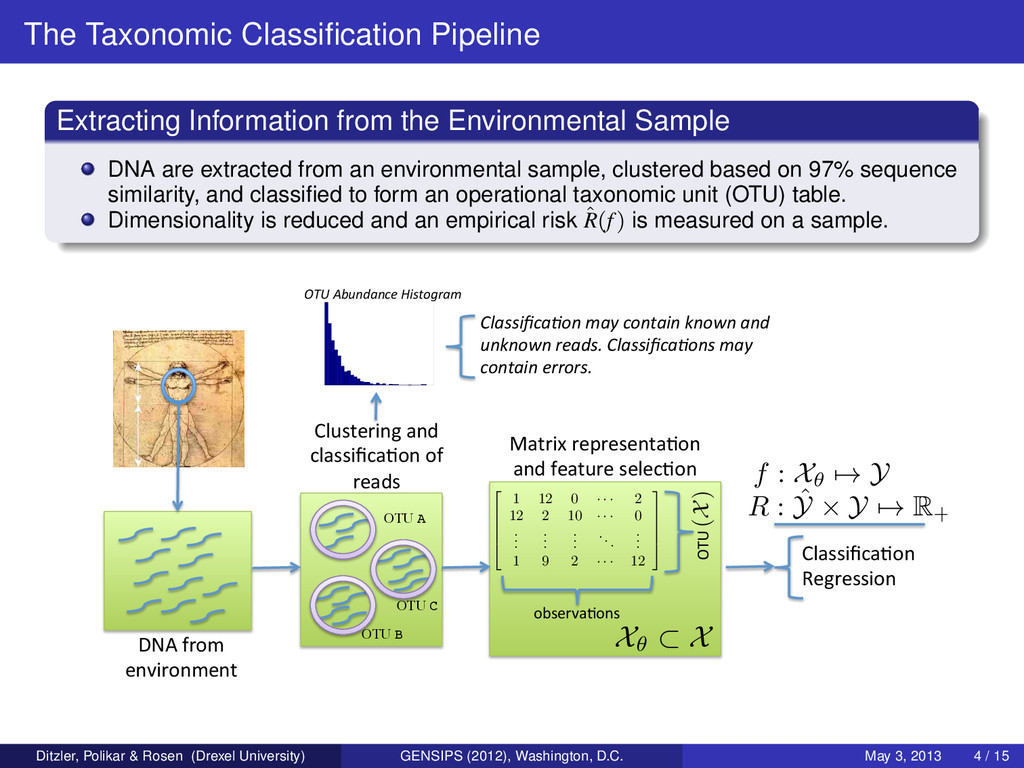
DNA are extracted from an environmental sample, clustered based on 97% sequence similarity, and classified to form an operational taxonomic unit (OTU) table. Dimensionality is reduced and an empirical risk ˆ R(f) is measured on a sample. DNA from environment Clustering and classifica7on of reads OTU A! OTU C! OTU B! 2 6 6 6 4 1 12 0 · · · 2 12 2 10 · · · 0 . . . . . . . . . ... . . . 1 9 2 · · · 12 3 7 7 7 5 observa7ons OTU Matrix representa7on and feature selec7on Classifica7on Regression OTU Abundance Histogram f : X✓ 7! Y R : ˆ Y ⇥ Y 7! R + Classifica8on may contain known and unknown reads. Classifica8ons may contain errors. X✓ ⇢ X (X) Ditzler, Polikar & Rosen (Drexel University) GENSIPS (2012), Washington, D.C. May 3, 2013 4 / 15
Selection Feature selection techniques can be classifier-dependent (wrapper methods), and classifier-independent (filter methods). We focus on filter methods to eliminate dependance on the selected classifier. Information Theoretic Methods The relevance index for an information theoretic filter method are mutual information (I(X; Y)) and conditional mutual information (I(X1; X2|Y)). MI: the amount of uncertainty in X which is removed by knowing Y CMI: as the information shared between X1 and X2 after the value of a third variable, Y, is observed Information theoretic filters use a weighted combination of MI and CMI to add new features into Xθ Ditzler, Polikar & Rosen (Drexel University) GENSIPS (2012), Washington, D.C. May 3, 2013 5 / 15
conditional likelihood maximization Brown et al. (2012) determine the general form of the objective function of a conditional likelihood maximization problem is given by, JCMI = I(Xk; Y) − β j∈S I(Xj; Xk) + γ j∈S I(Xj; Xk|Y) for β, γ ∈ [0, 1]. The inclusion of correlated features can be useful as determined in the CMI objective function. Many different value of β and γ give rise the the objective functions for MIFS, MIM, mRMR, etc. Table: Feature selection methods used for metagenomic classification Criterion Full Name CIFE Conditional Infomax Feature Extraction CMIM Conditional Mutual Info Maximization JMI Joint Mutual Information MIFS Mutual Information Feature Selection MIM Mutual Information Maximization MRMR Max-Relevance Min-Redundancy Ditzler, Polikar & Rosen (Drexel University) GENSIPS (2012), Washington, D.C. May 3, 2013 6 / 15
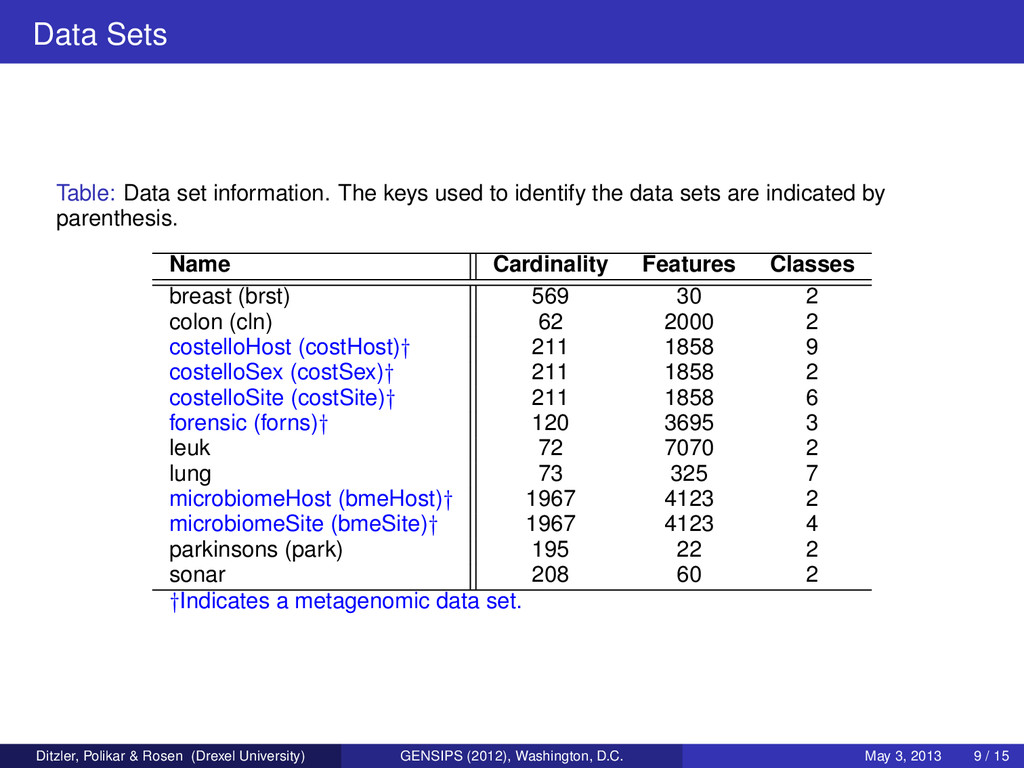
from three individuals fingertips and various keys on their computer keyboard (3500+ features) Objective is to identify which individual a sample belongs to Microbiome Data Data are collected from two individuals over 15 months from four different body sites (4100+ features) Outcome space Y is varied between site and host. Costello Body Site Data Data are collected from multiple individuals over several months (1800+ features) Outcome space Y is varied between site, host, and sex of the host. See references within for the sources of the data. Ditzler, Polikar & Rosen (Drexel University) GENSIPS (2012), Washington, D.C. May 3, 2013 7 / 15
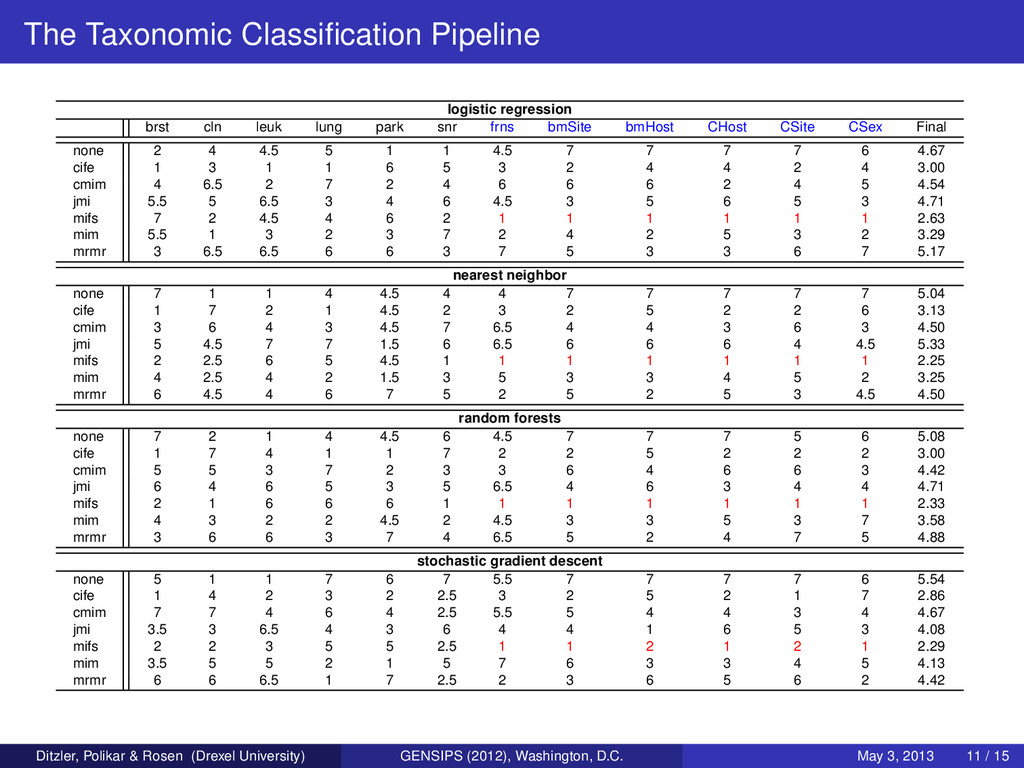
Testing the information theoretic feature selection methods with one classifier may be insufficient to begin to draw conclusions for the following reasons: One cannot expect a single classifier to always yield optimal performance (if you have one let me know!) We want to observe if a feature selection method performs well consistently, and this includes performing consistently well with different classifiers The numerical value of the accuracy is not as important to us as which feature selection method is performing better than the others on a data set Classifiers under test Logistic Regression k-NN: 3-nearest neighbor classifier Random forests: ensemble classifier using 50 decision trees training using Brieman’s random forest algorithm Stochastic Gradient Descent: linear classifier trained using a modified Huber loss function. Ditzler, Polikar & Rosen (Drexel University) GENSIPS (2012), Washington, D.C. May 3, 2013 8 / 15
over the results from 10-fold cross validation and ranked according to their loss low rank → small loss large rank → large loss fractional ranks are used in situations of ties Comparing Multiple Methods Across N Data Sets Friedman’s test is applied to the ranks to determine if the average ranks of the k algorithms are equal χ2 F = 12N k(k + 1) k j=1 R2 j − k(k + 1)2 4 , FF = (N − 1)χ2 F N(k − 1) − χ2 F where FF is distributed according to a F-distribution with k − 1 and (k − 1)(N − 1) degrees of freedom. Nemenyi test along with the Bonferroni-Dunn correction procedure can determine if algorithm A is performing better than algorithm B with statistical significance. Ditzler, Polikar & Rosen (Drexel University) GENSIPS (2012), Washington, D.C. May 3, 2013 10 / 15
on many data sets. Observed across several of the classifiers tested in this study MIFS works particularly well on the metagenomic data sets Friedman test rejects the null hypothesis and some pairwise comparisons are significant The impact of feature extraction as a pre-processing step to feature selection We generate similar accuracy tables for ISOMAP, KPCoA, and PCA. For each of the data sets and classifiers we rank the pre-processing methods rather than the feature selection methods Using the raw features in the feature selection routine consistently provided the best classification accuracy among the four methods tested Processing LR NN RFC SGD Final Isomap 3.33 (4) 3.17 (4) 3.61 (4) 3.10 (4) 4.00 KPCoA 2.24 (2) 2.22 (2) 1.90 (2) 2.44 (3) 2.25 None 1.88 (1) 1.97 (1) 1.51 (1) 2.12 (1) 1.00 PCA 2.57 (3) 2.63 (3) 2.98 (3) 2.34 (2) 2.75 Ditzler, Polikar & Rosen (Drexel University) GENSIPS (2012), Washington, D.C. May 3, 2013 12 / 15
for metagenomic data sets. We evaluated a number of information theoretic feature selection methods and data pre-processing methods on several benchmark metagenomic data sets. We found from the empirical results that: using the raw features (i.e., no pre-processing) with feature selection improved the accuracy of the classifiers out of all the pre-processing methods tested feature selection – all of which are derived from information-theoretic measures – improved the classification accuracy over no feature selection at all MIFS appear to be quite robust for the metagenomic data sets, and all metagenomic data set used in this work is derived from taxonomic Ditzler, Polikar & Rosen (Drexel University) GENSIPS (2012), Washington, D.C. May 3, 2013 13 / 15
focuses on features derived from operational taxonomies, but other features exist. Recent work in functional based features and feature selection is enabling insights into identifying differences between patients with and without IBD. Statistical Hypothesis Testing for Feature Relevancy Filters & wrappers for feature selection return k features, but how can we intuitively select k from a finite sample of size n? What if k is too small/large? Can we recover the appropriate level of k? Ditzler, Polikar & Rosen (Drexel University) GENSIPS (2012), Washington, D.C. May 3, 2013 14 / 15
National Science Foundation [#0845827], [#1120622], and DOE Award [#SC004335]. Robi Polikar is supported by the National Science Foundation [ECCS-0926159]. Ditzler, Polikar & Rosen (Drexel University) GENSIPS (2012), Washington, D.C. May 3, 2013 15 / 15
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}