Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
20年以上オンプレサーバで稼働し続けたSNSサービス「GREE」のクラウド移行をやりきったぞ!...
Search
gree_tech
PRO
October 17, 2025
Technology
590
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
20年以上オンプレサーバで稼働し続けたSNSサービス「GREE」のクラウド移行をやりきったぞ!そしてコンテナ化!
GREE Tech Conference 2025で発表された資料です。
https://techcon.gree.jp/2025/session/TrackB-3
gree_tech
PRO
October 17, 2025
More Decks by gree_tech
See All by gree_tech
我々はどう生きるか
gree_tech
PRO
0
2
変わるもの、変わらないもの :OSSアーキテクチャで実現する持続可能なシステム
gree_tech
PRO
0
5.1k
マネジメントに役立つ Google Cloud
gree_tech
PRO
0
72
今この時代に技術とどう向き合うべきか
gree_tech
PRO
3
2.8k
生成AIを開発組織にインストールするために: REALITYにおけるガバナンス・技術・文化へのアプローチ
gree_tech
PRO
0
470
安く・手軽に・現場発 既存資産を生かすSlack×AI検索Botの作り方
gree_tech
PRO
0
470
生成AIを安心して活用するために──「情報セキュリティガイドライン」策定とポイント
gree_tech
PRO
1
2.4k
あうもんと学ぶGenAIOps
gree_tech
PRO
0
590
MVP開発における生成AIの活用と導入事例
gree_tech
PRO
0
620
Other Decks in Technology
See All in Technology
QAと開発の両側から進める AI活用 -QAプロセスAI支援ツールキットと Inner Loop / Outer Loopの取り組み-
legalontechnologies
PRO
2
350
AWS環境のセキュリティ不安を解消した企業事例 ~よくある課題と対策を一挙公開~
asanoharuki
0
230
1台から試せる!Edge IoTを使った位置情報の活用設計【SORACOM Discovery 2026】
soracom
PRO
0
100
データ活用研修 問いの発見と仮説構築【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
640
『モンスターストライク』 の運営に伴走する! データ民主化への 解析グループの3つのアプローチ
mixi_engineers
PRO
0
170
基調講演:人とAIをつなぐIoTの今と未来 ー 「フィジカル」と「デジタル」が出会うその先へ【SORACOM Discovery 2026】
soracom
PRO
0
350
「待ち時間」の消滅と「自我消耗」の加速:生成AI時代のエンジニアを救うメンタル・リソース管理
poropinai1966
0
310
CloudWatchから始めるAWS監視
butadora
0
280
人依存からAIネイティブの体制へ:バックエンド開発の裏側【SORACOM Discovery 2026】
soracom
PRO
0
120
Amazon Bedrock Managed Knowledge Base Dive Deep
ren8k
0
190
全社でのソフトウェアサプライチェーン攻撃対策をやってみた with Takumi Guard
z63d
0
320
AIQAのナレッジ構築について
qatonchan
1
120
Featured
See All Featured
How To Speak Unicorn (iThemes Webinar)
marktimemedia
1
520
Technical Leadership for Architectural Decision Making
baasie
3
450
Building Better People: How to give real-time feedback that sticks.
wjessup
370
20k
Making Projects Easy
brettharned
120
6.7k
Marketing Yourself as an Engineer | Alaka | Gurzu
gurzu
0
260
Rails Girls Zürich Keynote
gr2m
96
14k
JAMstack: Web Apps at Ludicrous Speed - All Things Open 2022
reverentgeek
1
510
世界の人気アプリ100個を分析して見えたペイウォール設計の心得
akihiro_kokubo
PRO
72
41k
Why Mistakes Are the Best Teachers: Turning Failure into a Pathway for Growth
auna
0
190
How to Create Impact in a Changing Tech Landscape [PerfNow 2023]
tammyeverts
55
3.4k
Mobile First: as difficult as doing things right
swwweet
225
10k
Building Experiences: Design Systems, User Experience, and Full Site Editing
marktimemedia
0
560
Transcript
20年以上オンプレサーバで稼働し続けた SNSサービス「GREE」のクラウド移行を やりきったぞ!そしてコンテナ化! 株式会社グリー エンジニア 後藤 浩行 エンジニア 大迫 裕樹
後藤 浩行 2013年にグリーに新卒入社。エンジニアとして、オ ンプレ環境のIaC導入、GREEサービスのクラウド 移行プロジェクトに従事したのち、ゲーム新規タイト ルのクラウドエンジニアリングを牽引 株式会社グリー リードエンジニア 2
『GREEってオンプレで動いてるんですよね』 よく聞かれます 3
1万台以上のサーバ群 クラウド移行やりきりました!!! 大変だった!! 4
目次・アジェンダ • GREEのサービスのインフラ構成 • クラウド移行 ◦ ゲームプロダクトのクラウド移行 ◦ Platform機能のクラウド移行 •
クラウド最適化 5
GREEのサービスのインフラ構成 6
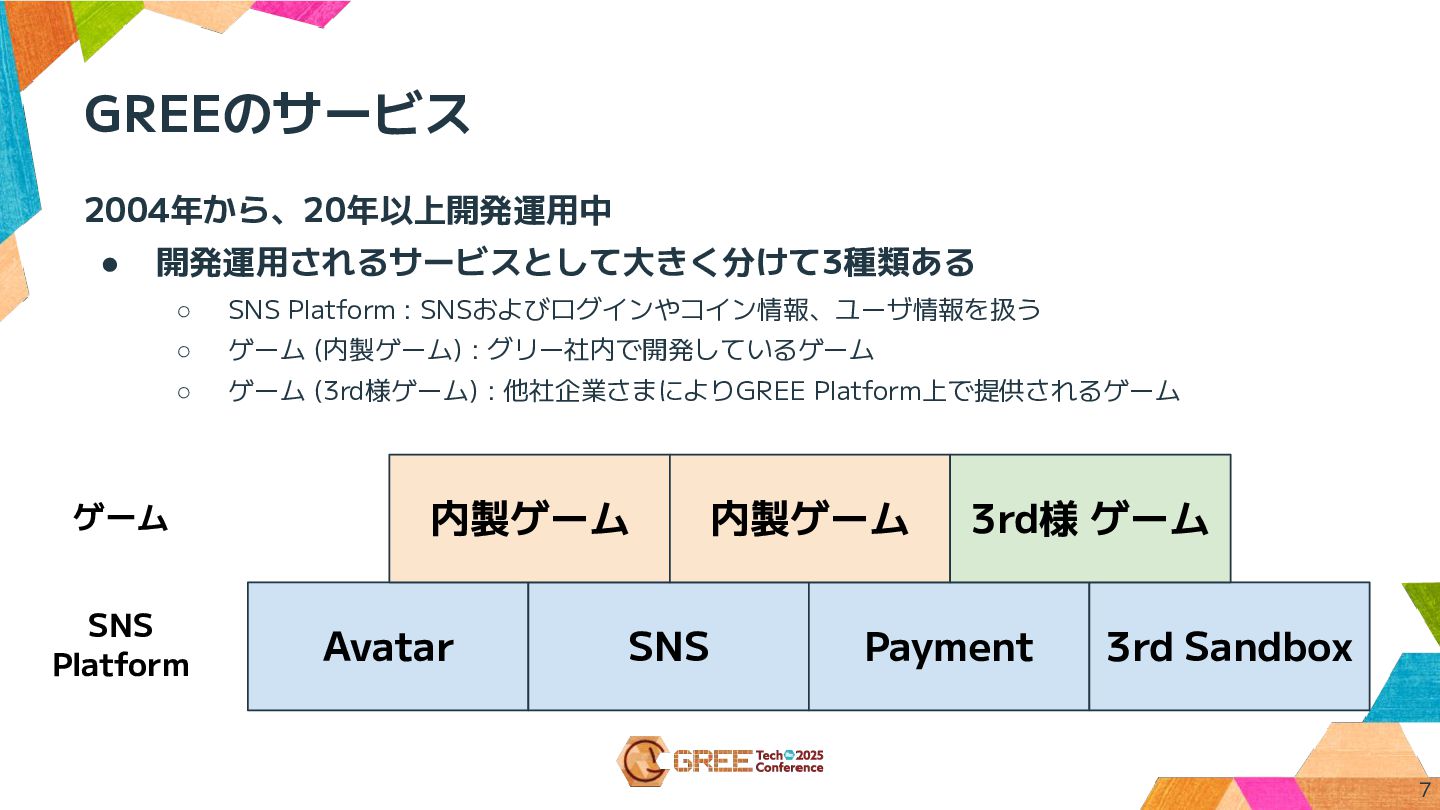
GREEのサービス 7 Avatar SNS Payment 3rd Sandbox 内製ゲーム 内製ゲーム 3rd様
ゲーム SNS Platform ゲーム 2004年から、20年以上開発運用中 • 開発運用されるサービスとして大きく分けて3種類ある ◦ SNS Platform : SNSおよびログインやコイン情報、ユーザ情報を扱う ◦ ゲーム (内製ゲーム) : グリー社内で開発しているゲーム ◦ ゲーム (3rd様ゲーム) : 他社企業さまによりGREE Platform上で提供されるゲーム
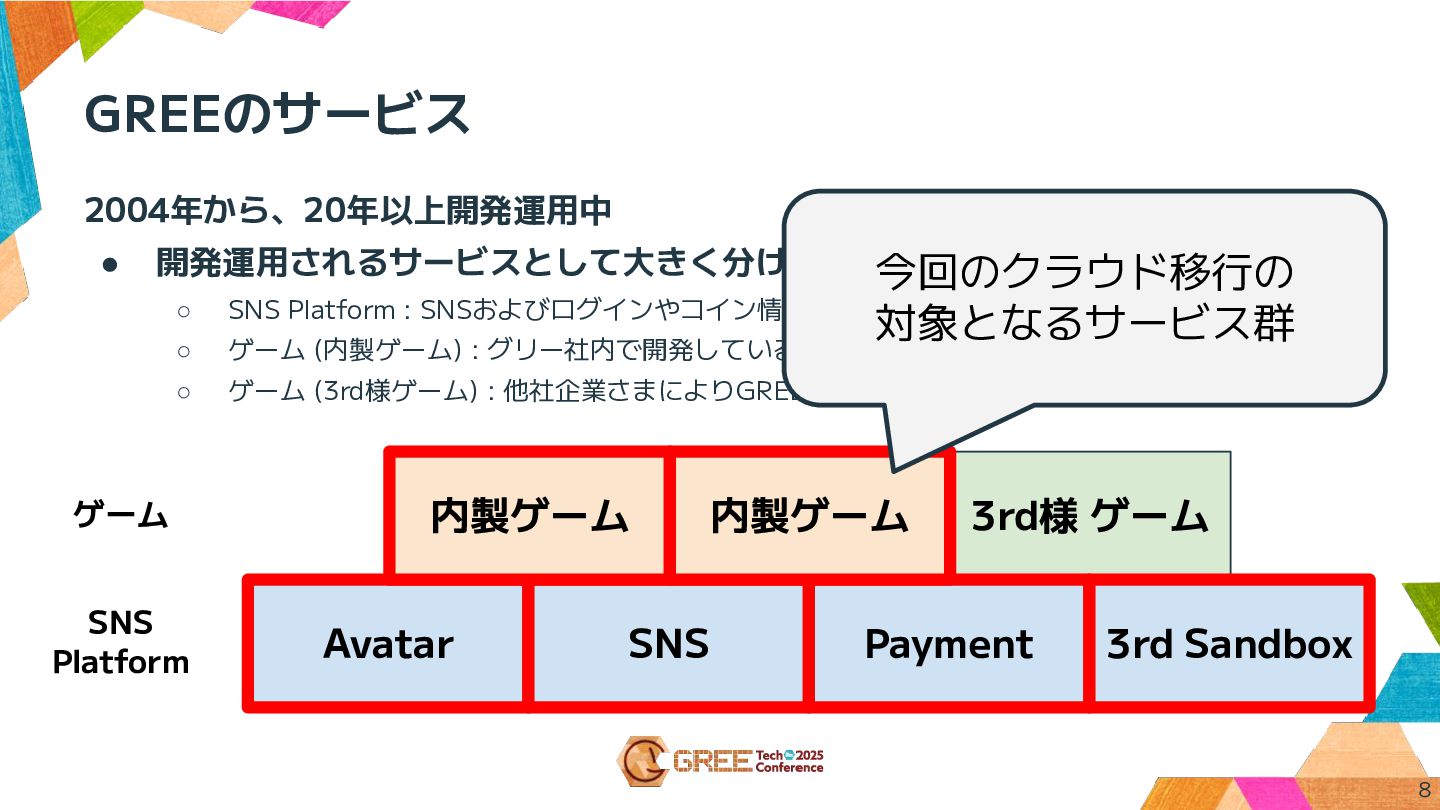
3rd様 ゲーム GREEのサービス 8 Avatar SNS Payment 3rd Sandbox 内製ゲーム
内製ゲーム SNS Platform ゲーム 2004年から、20年以上開発運用中 • 開発運用されるサービスとして大きく分けて3種類ある ◦ SNS Platform : SNSおよびログインやコイン情報、ユーザ情報を扱う ◦ ゲーム (内製ゲーム) : グリー社内で開発しているゲーム ◦ ゲーム (3rd様ゲーム) : 他社企業さまによりGREE Platform上で提供されるゲーム 今回のクラウド移行の 対象となるサービス群
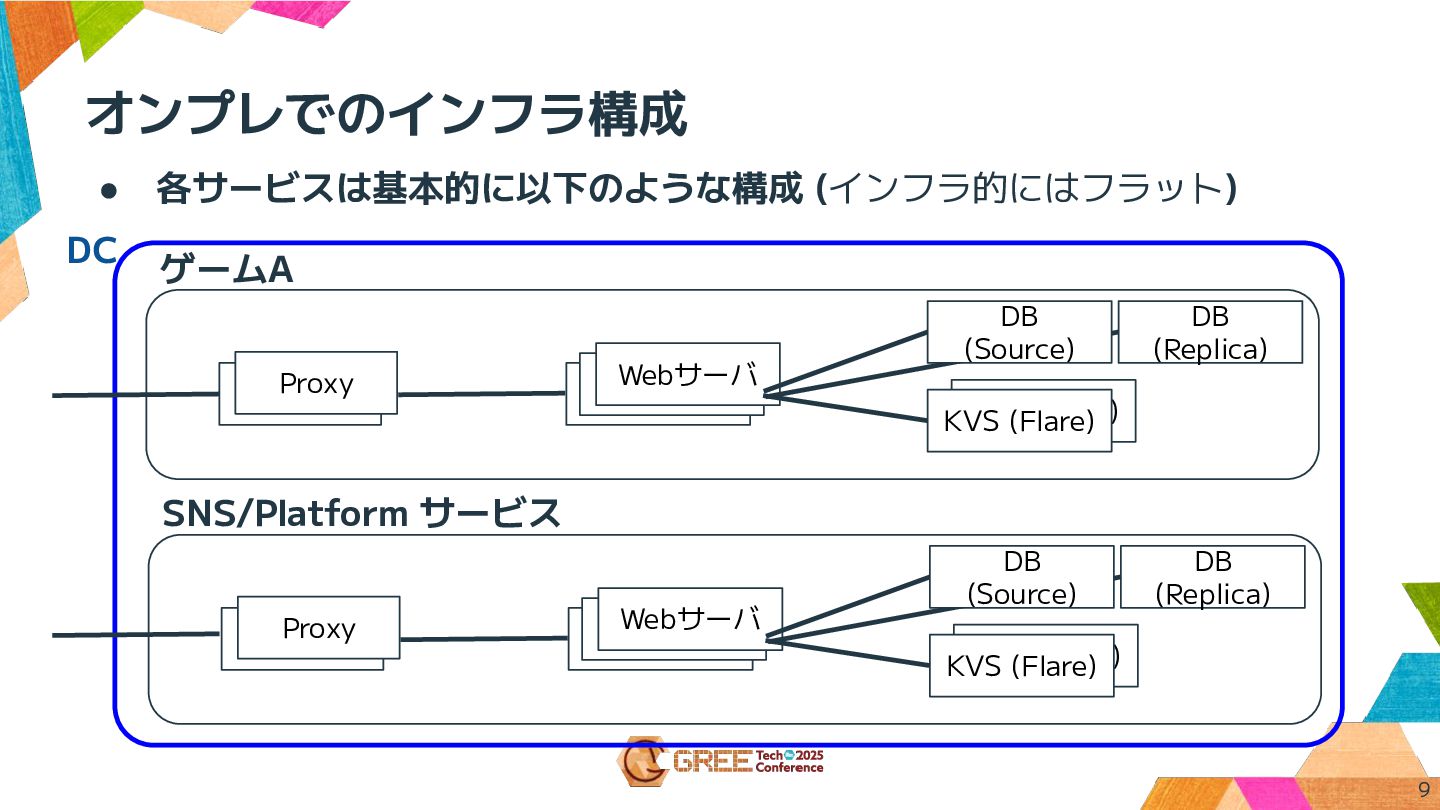
オンプレでのインフラ構成 9 • 各サービスは基本的に以下のような構成 (インフラ的にはフラット) ゲームA Proxy Webサーバ DB (Replica)
KVS (Flare) KVS (Flare) Webサーバ Webサーバ Proxy DB (Source) SNS/Platform サービス Proxy Webサーバ DB (Replica) KVS (Flare) KVS (Flare) Webサーバ Webサーバ Proxy DB (Source) DC
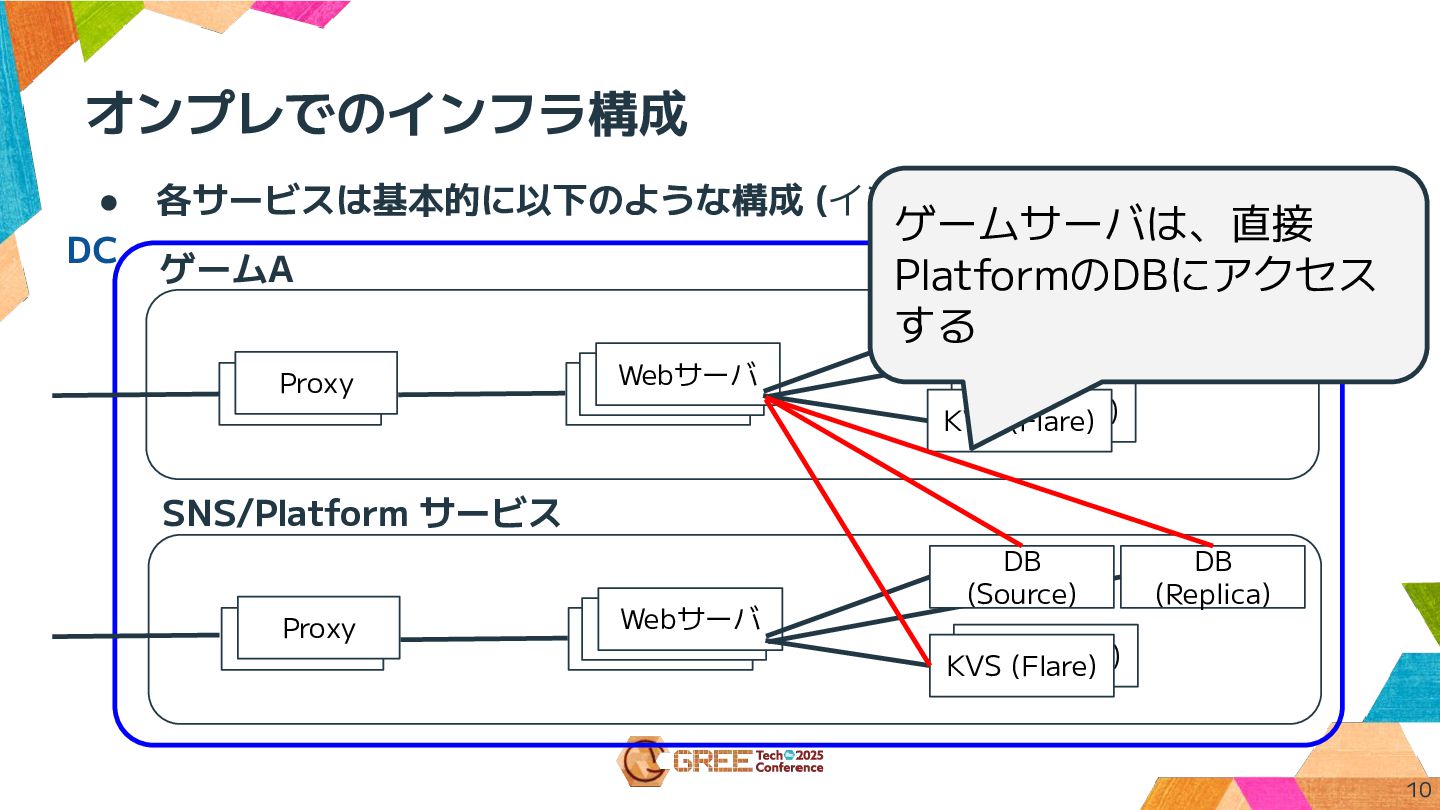
オンプレでのインフラ構成 10 • 各サービスは基本的に以下のような構成 (インフラ的にはフラット) ゲームA Proxy Webサーバ DB (Primary)
KVS (Flare) KVS (Flare) Webサーバ Webサーバ Proxy DB (Source) SNS/Platform サービス Proxy Webサーバ DB (Replica) KVS (Flare) KVS (Flare) Webサーバ Webサーバ Proxy DB (Source) ゲームサーバは、直接 PlatformのDBにアクセス する DC
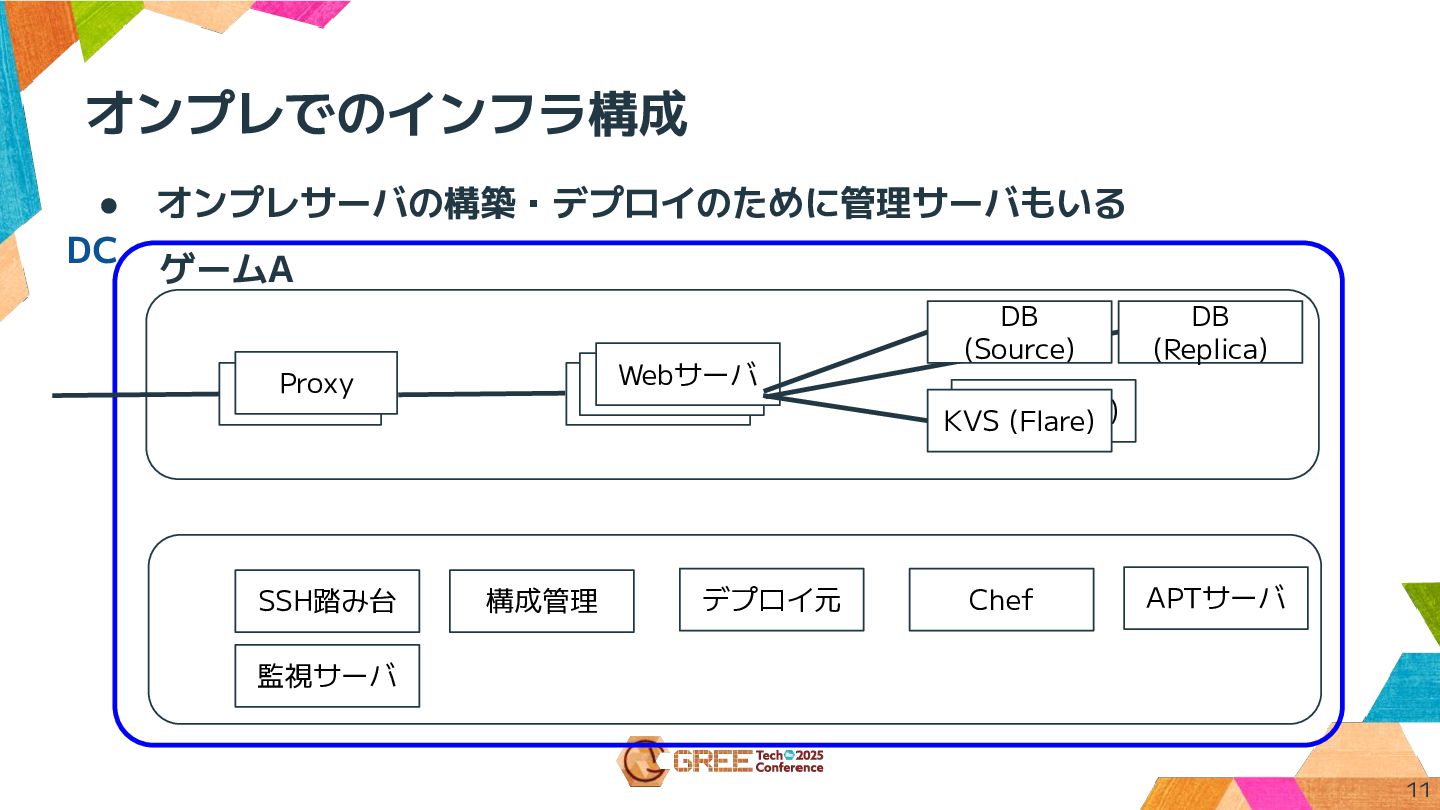
オンプレでのインフラ構成 11 • オンプレサーバの構築・デプロイのために管理サーバもいる ゲームA Proxy Webサーバ DB (Replica) KVS
(Flare) KVS (Flare) Webサーバ Webサーバ Proxy DB (Source) SSH踏み台 構成管理 Chef APTサーバ デプロイ元 監視サーバ DC
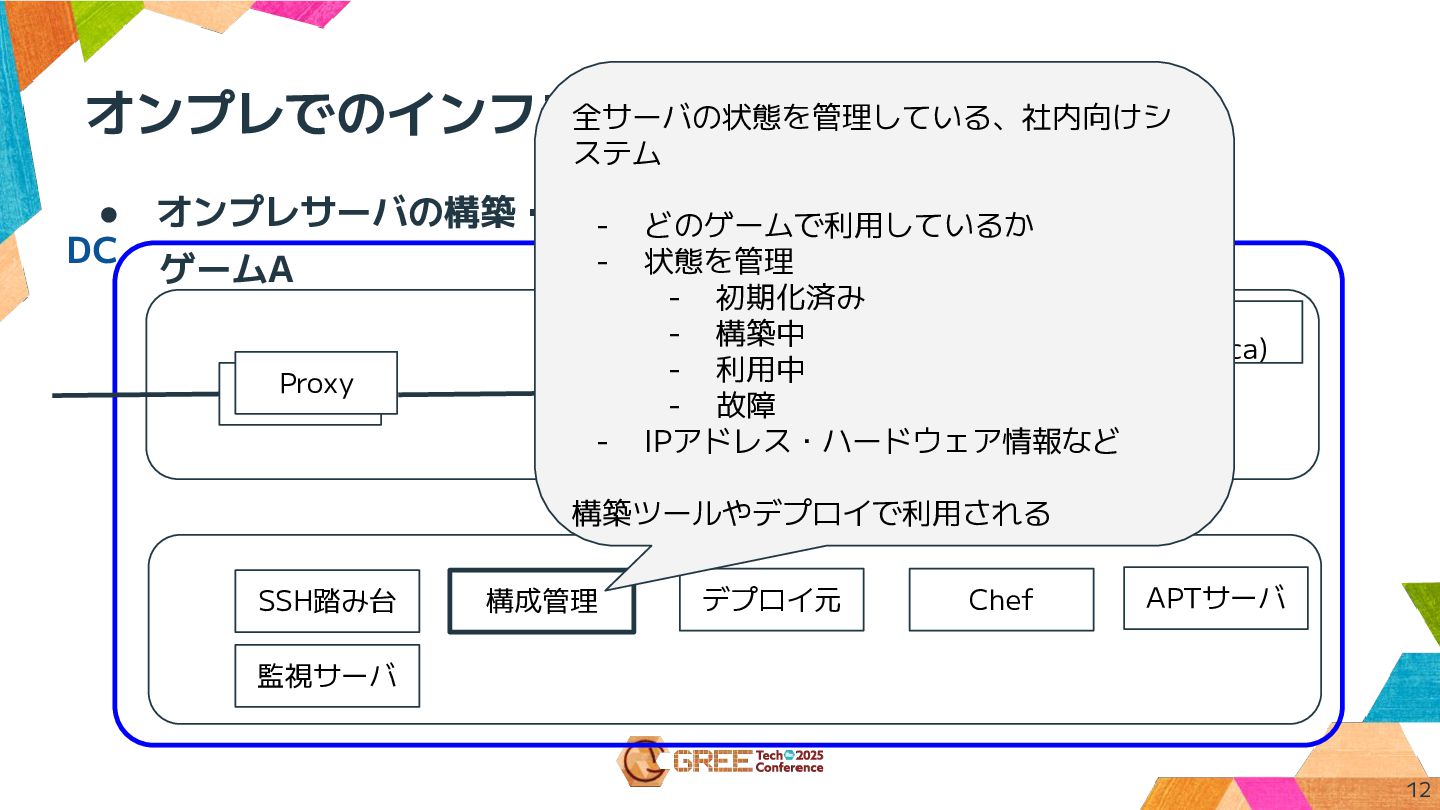
オンプレでのインフラ構成 12 • オンプレサーバの構築・デプロイのために管理サーバもいる ゲームA Proxy Webサーバ DB (Replica) KVS
(Flare) KVS (Flare) Webサーバ Webサーバ Proxy DB (Source) SSH踏み台 構成管理 Chef APTサーバ デプロイ元 全サーバの状態を管理している、社内向けシ ステム - どのゲームで利用しているか - 状態を管理 - 初期化済み - 構築中 - 利用中 - 故障 - IPアドレス・ハードウェア情報など 構築ツールやデプロイで利用される 監視サーバ DC
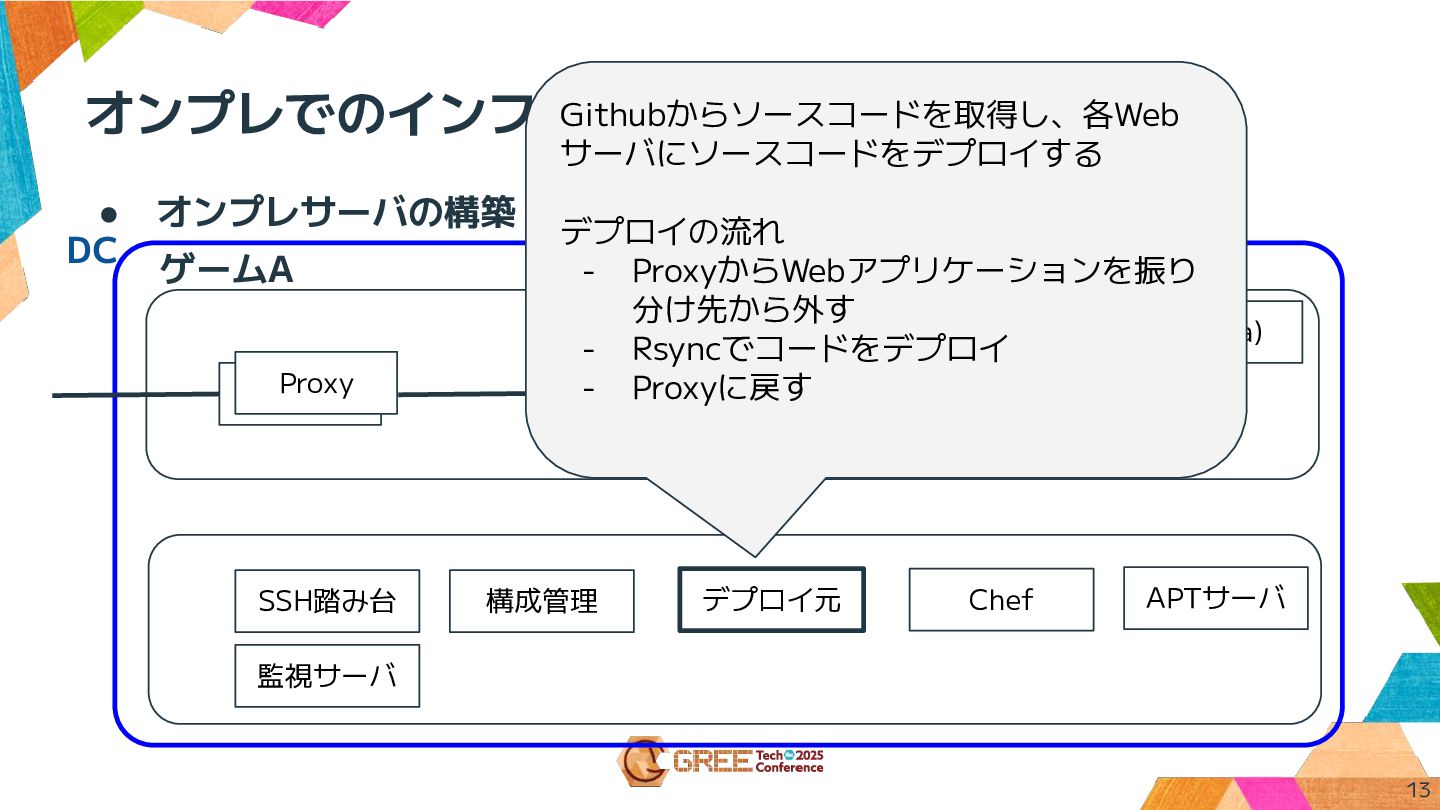
オンプレでのインフラ構成 13 • オンプレサーバの構築・デプロイのために管理サーバもいる ゲームA Proxy Webサーバ Replica) KVS (Flare)
KVS (Flare) Webサーバ Webサーバ Proxy DB (Source) SSH踏み台 構成管理 Chef APTサーバ デプロイ元 Githubからソースコードを取得し、各Web サーバにソースコードをデプロイする デプロイの流れ - ProxyからWebアプリケーションを振り 分け先から外す - Rsyncでコードをデプロイ - Proxyに戻す 監視サーバ DC
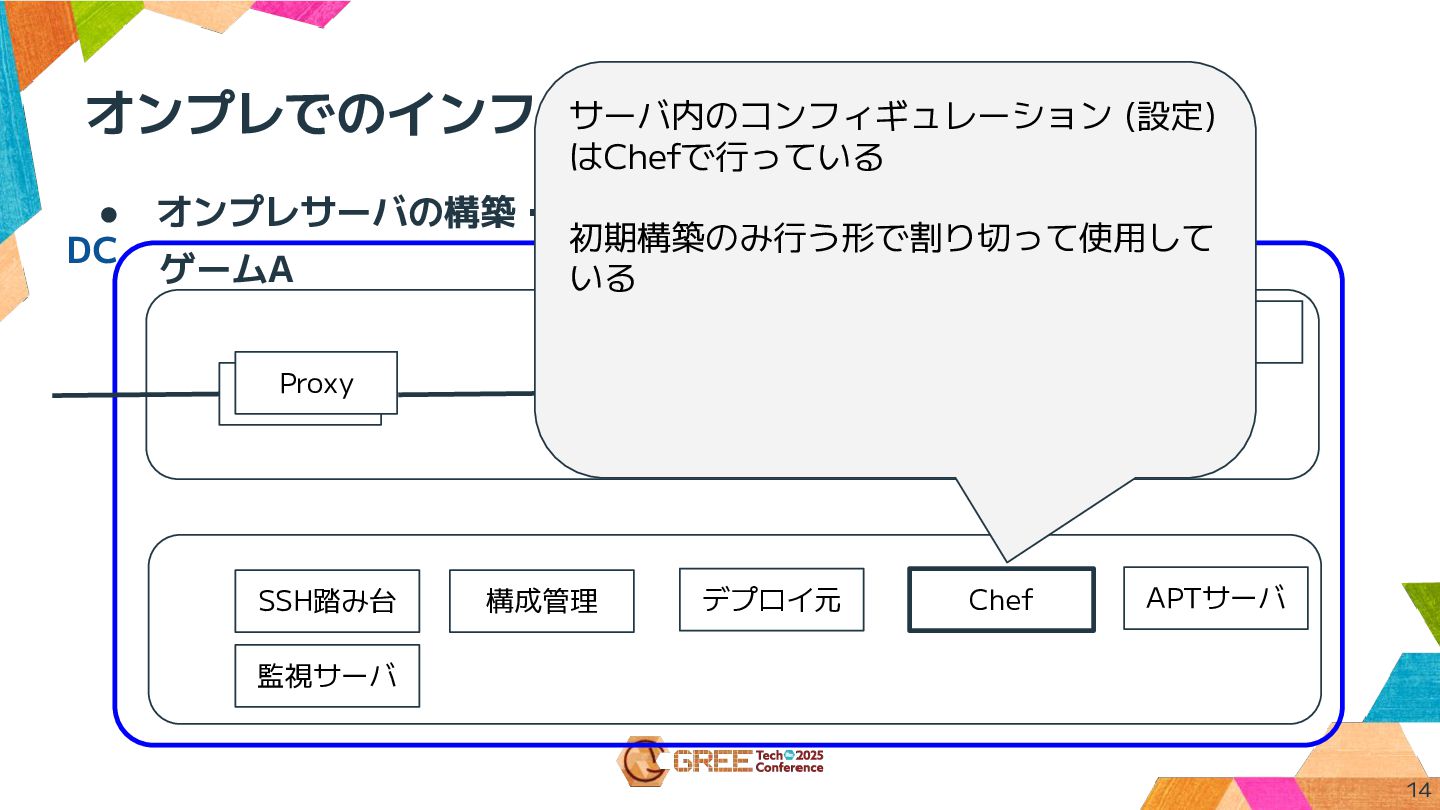
オンプレでのインフラ構成 14 • オンプレサーバの構築・デプロイのために管理サーバもいる ゲームA Proxy Webサーバ (Replica ) KVS
(Flare) KVS (Flare) Webサーバ Webサーバ Proxy DB (Source) SSH踏み台 構成管理 Chef APTサーバ デプロイ元 サーバ内のコンフィギュレーション (設定) はChefで行っている 初期構築のみ行う形で割り切って使用して いる 監視サーバ DC
クラウド移行 15
クラウド移行タイムライン 16 • ~2014 データセンタ(オンプレ)でGREEサービス群を運用 • 消滅都市(2014リリース)においてクラウドを採用するなど知見が蓄積され、 GREEサービスでも部分的にクラウドの移行を開始(GPUインスタンス) • 2016年頃ゲームサーバ
(9サービス)の移設 • 2019年頃よりPlatformサービス のサーバ移設を開始 • 2025年 クラウド移行完了
ゲームサーバ移行 (2016年~) 17
クラウド移行方針 18 • 移行を優先し、VMインスタンス(Web, DB)で移行する ◦ サーバの構築はChefでAMIイメージを作成する形 • オンプレとダイレクトコネクトで接続する ◦
変わらず、PlatformのDBとの通信 ◦ オンプレ側の構成管理サーバを引き続き利用する ◦ デプロイ(Rsync)はオンプレから行う • クラウド切り替え手順 ◦ 事前に移行先を構築しておく ◦ (DBなどはオンプレ=>クラウドでレプリケーションしておく) ◦ サービスをメンテナンスモードに入れ、DNSでLBの参照をクラウドに変更
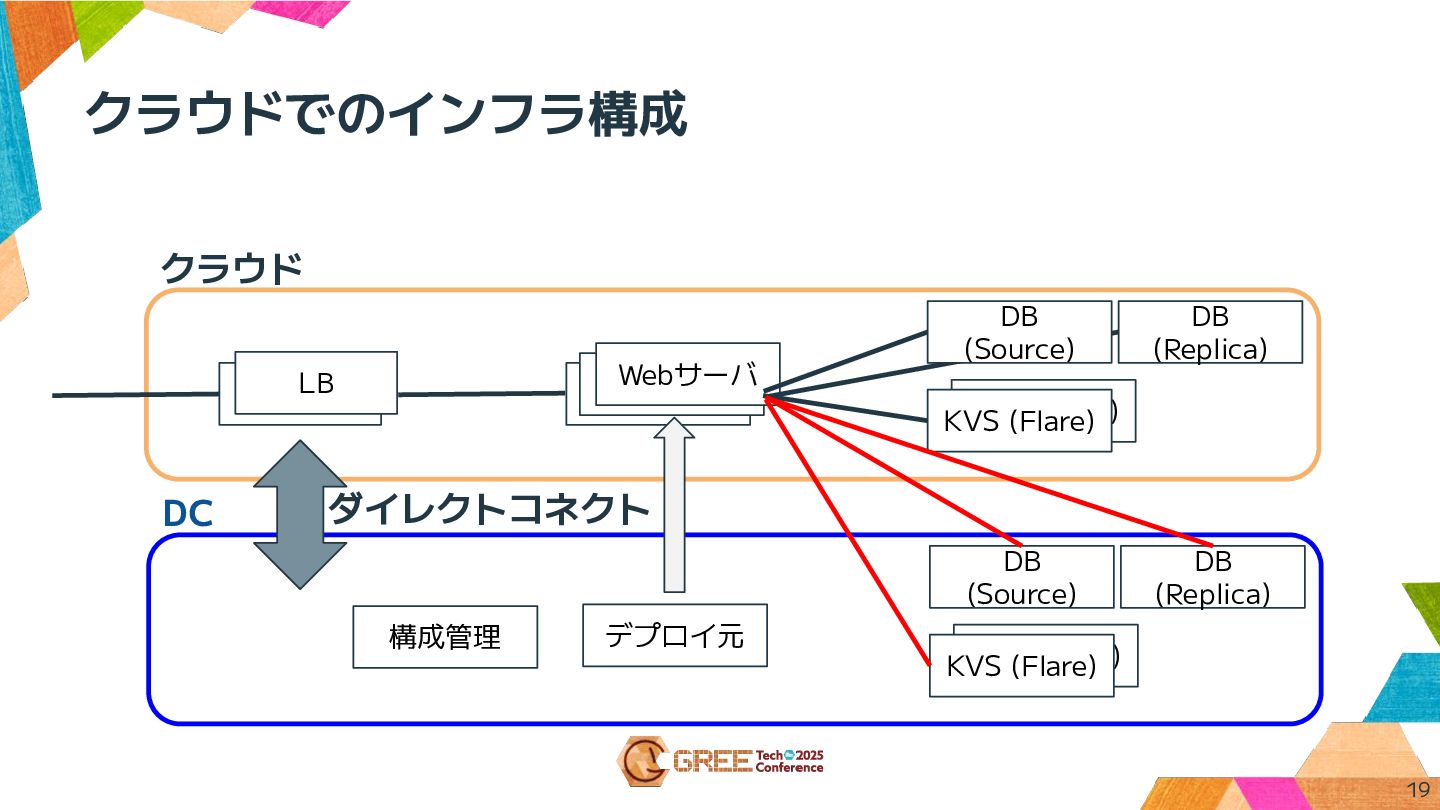
クラウドでのインフラ構成 19 クラウド Proxy Webサーバ DB (Replica) KVS (Flare) KVS
(Flare) Webサーバ Webサーバ LB DB (Source) DB (Replica) KVS (Flare) KVS (Flare) DB (Source) DC ダイレクトコネクト 構成管理 デプロイ元
クラウド移行で起こったこと 20 • DBインスタンスの高負荷 オンプレはSSD, Fusion-IOもあったため、Disk I/O性能が足りず適切にスケー ルアップ • ネットワーク遅延、寸断(1s以下)
オンプレ側前提の監視条件だと敏感すぎた。継続時間を考慮しつつ一部緩和 • デプロイ時間が長くなる • その他アプリケーション起因の問題
クラウド移行後の最適化でやったこと 21 • マネージドDBの活用 ◦ 文字コードとか、ストレージエンジンとかを調整 • Webサーバのスケジュールベースのスケールの導入 ◦ オンプレ側の構成管理サーバに依存しているため、情報更新・デプロイ・Proxyのフリ理
由変更などをすべて自動化する仕組みを内製 • ダイレクトコネクト メンテナンス対応自動化 • ゼロトラスト的踏み台サーバ
Platform サーバ移行 (2019年~) 22
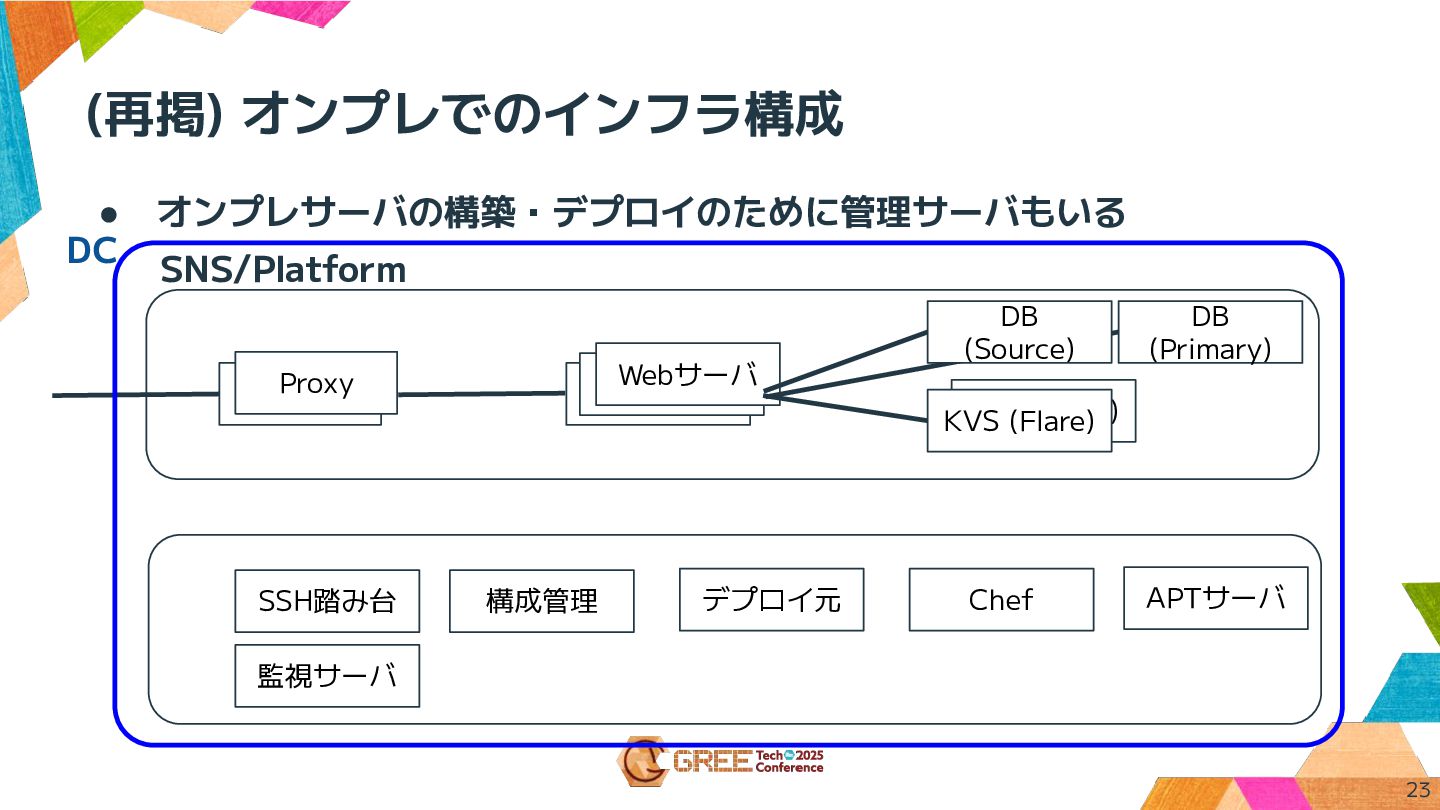
(再掲) オンプレでのインフラ構成 23 • オンプレサーバの構築・デプロイのために管理サーバもいる SNS/Platform Proxy Webサーバ DB (Primary)
KVS (Flare) KVS (Flare) Webサーバ Webサーバ Proxy DB (Source) SSH踏み台 構成管理 Chef APTサーバ デプロイ元 監視サーバ DC
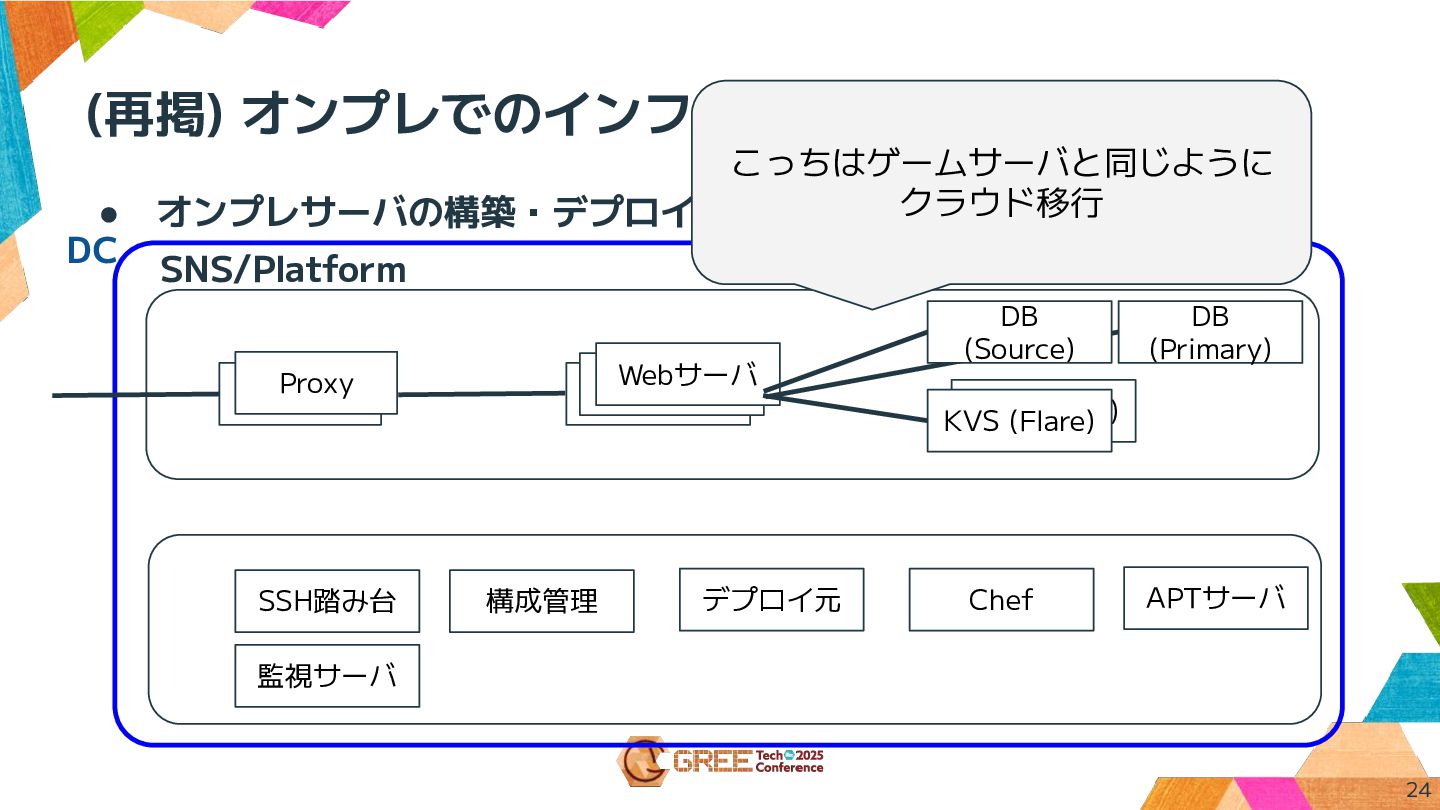
(再掲) オンプレでのインフラ構成 24 • オンプレサーバの構築・デプロイのために管理サーバもいる SNS/Platform Proxy Webサーバ DB (Primary)
KVS (Flare) KVS (Flare) Webサーバ Webサーバ Proxy DB (Source) SSH踏み台 構成管理 Chef APTサーバ デプロイ元 監視サーバ こっちはゲームサーバと同じように クラウド移行 DC
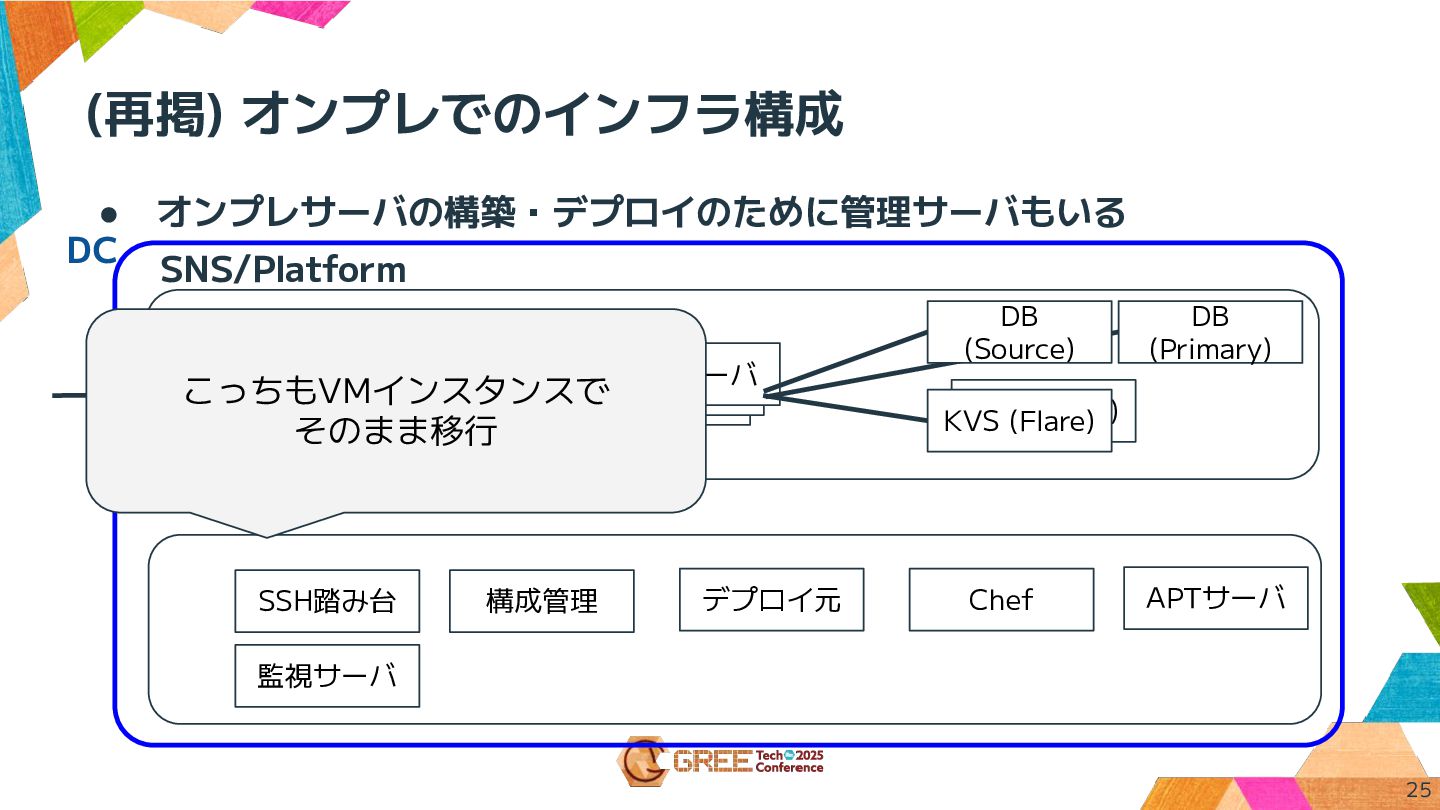
(再掲) オンプレでのインフラ構成 25 • オンプレサーバの構築・デプロイのために管理サーバもいる SNS/Platform Proxy Webサーバ DB (Primary)
KVS (Flare) KVS (Flare) Webサーバ Webサーバ Proxy DB (Source) SSH踏み台 構成管理 Chef APTサーバ デプロイ元 監視サーバ こっちもVMインスタンスで そのまま移行 DC
他にもあるサーバ群 26 • メールサーバ • 画像ストレージサーバ/キャッシュサーバ • DB故障自動対応 • NTPサーバ
• 監視サーバ • LDAPサーバ • Jenkinsサーバ • Internal DNS サーバ • 古い画像入稿サーバ
全体を振り返って 27
全体を振り返って 28 • 勢いが大事!! ◦ 移行手法を決めて、サービス単位ごとに切り替えていく ◦ 構成を標準化し、手分けして推し進める • 妥協したこと
◦ 今までオンプレで作ってきた仕組みをインスタンスで移行する ◦ 密結合してる部分はそのまま移行 • とはいえ、クラウドに行って故障機対応やスケールはしやすくなって運用 負荷は激減!!
全体を振り返って 29 • 勢いが大事!! ◦ 移行手法を決めて、サービス単位ごとに切り替えていく ◦ 構成を標準化し、手分けして推し進める • 妥協したこと
◦ 今までオンプレで作ってきた仕組みをインスタンスで移行する ◦ 密結合してる部分はそのまま移行 • とはいえ、クラウドに行って故障機対応やスケールはしやすくなって運用 負荷は激減!! その他泥臭いあれこれは ブース コーナー にて!!!
大迫 裕樹 2019年にグリー株式会社(現:グリーホールディン グス株式会社)へ新卒入社。 k8sやモニタリング領域 を中心に、クラウドインフラの設計・構築・運用に従 事。近年は GREE サービスのインフラ環境リアーキ テクトに携わる。
株式会社グリー リードエンジニア 30
クラウド最適化 31
クラウド移行後の課題 webサーバの運用負荷・サーバ費用 • VM運用の複雑性 ◦ 内製システム (デプロイ・サーバ管理) との連携 ◦ AMI
のメンテナンス (cookbook, CI) → 認知負荷上昇・属人化 • 負荷ベーススケーリング利用不可のためコスト増 ◦ 内製のデプロイシステムへの強い依存・オートスケールとの相性 → 過剰プロビジョニング • 内製リリースシステムの運用保守 ◦ 巨大なモノリスを内部サービス毎にリリース制御するために必須 ◦ 保守コスト・属人化 32
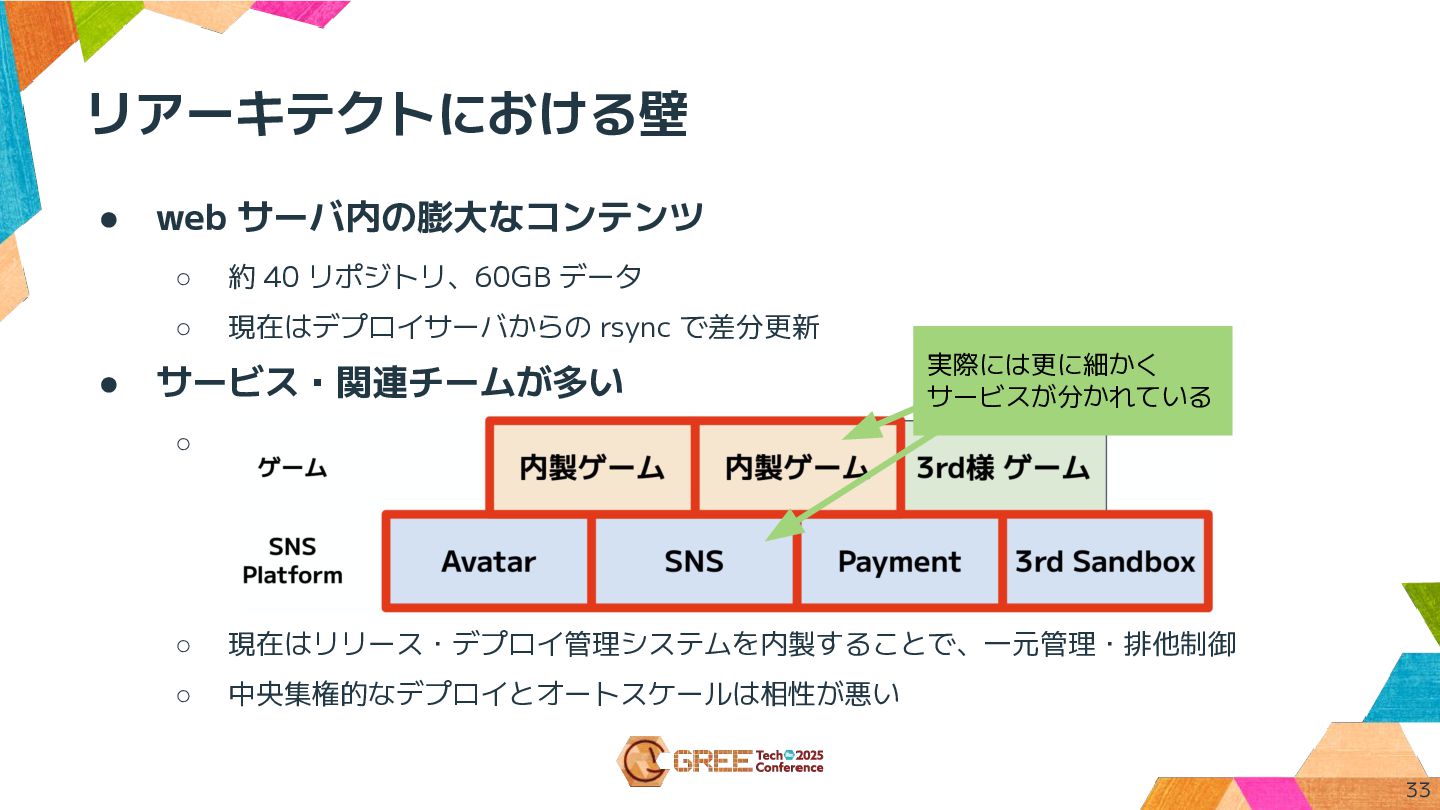
• web サーバ内の膨大なコンテンツ ◦ 約 40 リポジトリ、60GB データ ◦ 現在はデプロイサーバからの
rsync で差分更新 • サービス・関連チームが多い ◦ ◦ ◦ ◦ ◦ 現在はリリース・デプロイ管理システムを内製することで、一元管理・排他制御 ◦ 中央集権的なデプロイとオートスケールは相性が悪い リアーキテクトにおける壁 33 実際には更に細かく サービスが分かれている
リアーキテクトで必要となる要件 • ビルド時間・デプロイ時間が十分に短いこと • 個別にリリース・ロールバックが制御できること • 各サーバで使用するリポジトリを選択できること • 現行運用と両立すること (段階的移行・運用変更は最小に)
• アプリケーション側の変更を必要としないこと (インフラレイヤで完結) → 既存の仕組みの改良で全条件を満たすのは困難 → 現代の技術スタックを活用してゼロベースで再設計 34
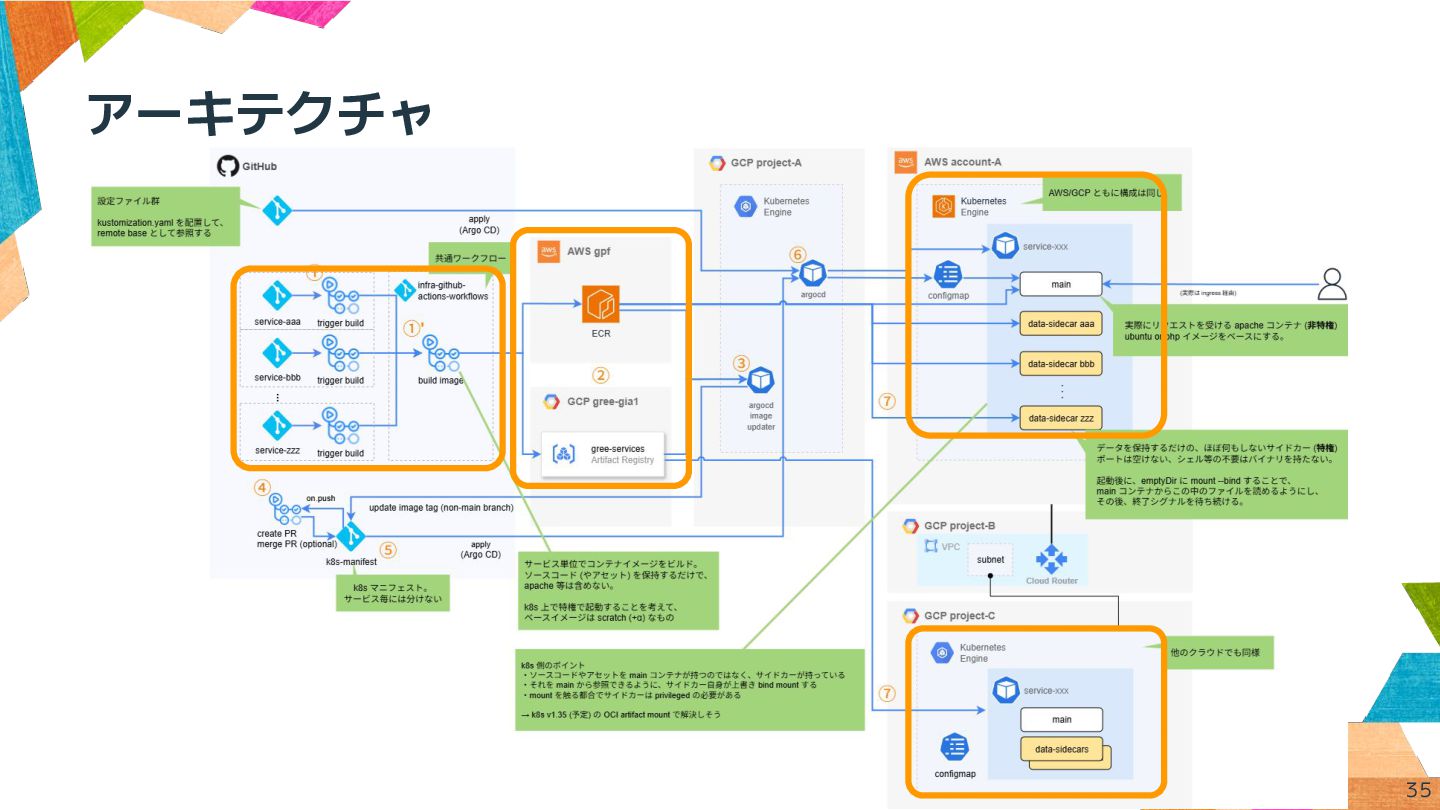
アーキテクチャ 35
アーキテクチャ (コンテナイメージ設計) • コンテナイメージの分割 (リポジトリ単位) ◦ ビルド時間短縮 ◦ 一部をロールバックしても新規ビルド不要 ◦
カナリアリリースの制御が容易 ▪ 複数チームによる複数リリースが発生するケースに配慮 • パッケージング方式としてのコンテナ (OCI artifact) ◦ データの保持のみを目的とする ◦ コンテナや k8s エコシステムの恩恵 (リトライ制御、キャッシュ etc.) • レイヤ操作による単一イメージ化も検討 → 多チーム横断の細粒度リリース用パイプラインの構築・運用は困難 36
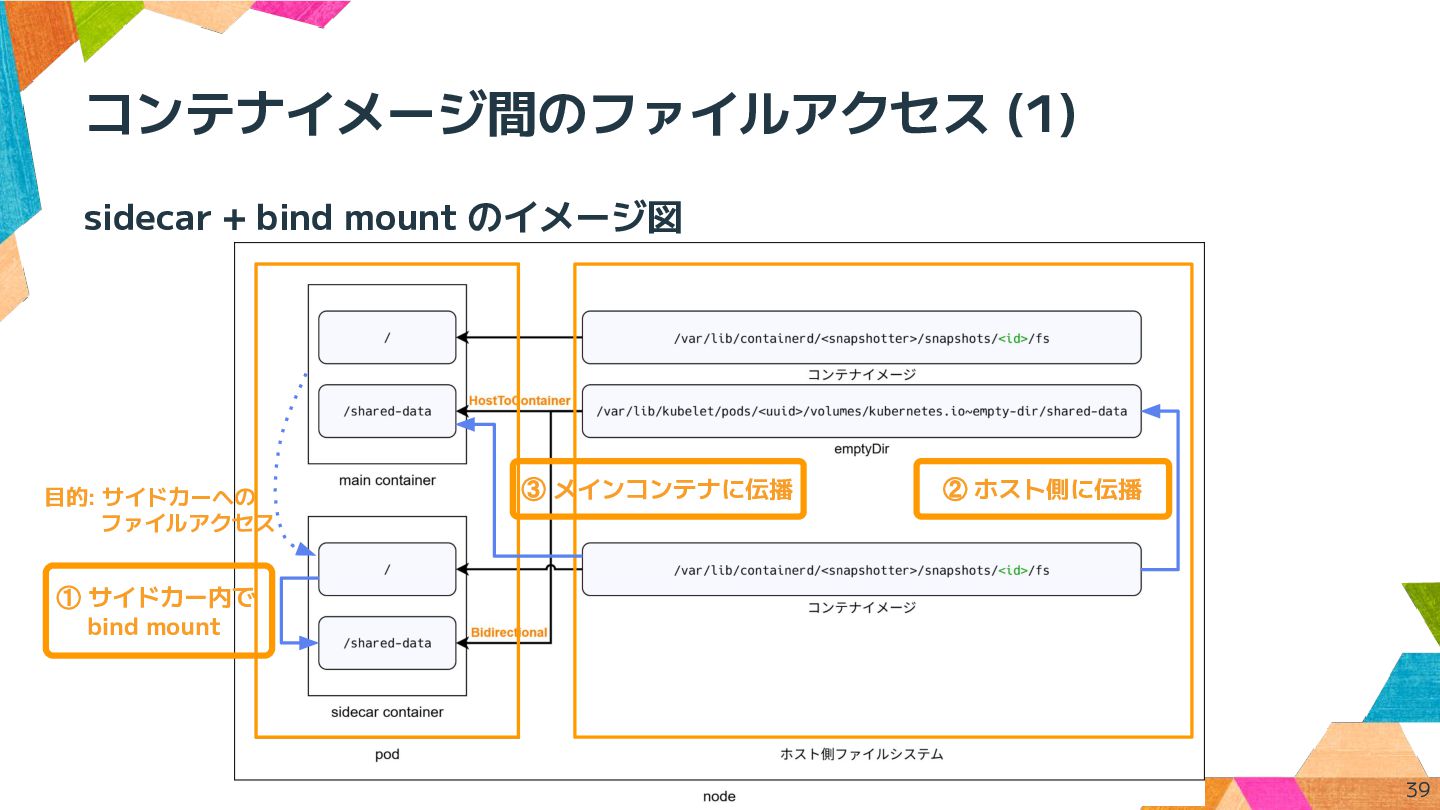
コンテナイメージ間のファイルアクセス (1) sidecar + bind mount (mount propagation) • Linux
の shared subtree という仕組みを利用 ◦ マウントポイント配下へのマウントイベントをマウント元に伝播 • k8s では mountPropagation として設定 ◦ サイドカー: emptyDir を Bidirectional でマウント 配下にサイドカー内のディレクトリを bind mount ◦ メインコンテナ: emptyDir を HostToContainer でマウント • Bidirectionl でマウントするには対象コンテナに特権が必要 ◦ サイドカーは scratch ベースのイメージ ◦ static ビルドした mount/umount/mountpoint、制御用の実行ファイルのみ (シェル無し) 37 FUSE や CSI ドライバで 使われている仕組み
コンテナイメージ間のファイルアクセス (1) sidecar + bind mount のマニフェストイメージ 38 initContainers: -
# ... restartPolicy: Always image: example.com/bindmount # mount --bind /data /shared-data を実行 args: - /data:/shared-data startupProbe: exec: command: [mountpoint, /shared-data] volumeMounts: - name: shared-data mountPath: /shared-data mountPropagation: Bidirectional # ... containers: - # ... volumeMounts: - name: shared-data mountPath: /shared-data mountPropagation: HostToContainer # ... volumes: - name: shared-data emptyDir: {}
コンテナイメージ間のファイルアクセス (1) sidecar + bind mount のイメージ図 39 目的: サイドカーへの
ファイルアクセス ① サイドカー内で bind mount ② ホスト側に伝播 ③ メインコンテナに伝播
コンテナイメージ間のファイルアクセス (2) Image Volume (KEP-4639) • OCI image/artifact を volume
としてマウント • β にはなったものの、多くのマネージド k8s でまだ利用できない ◦ feature gate がデフォルトで disabled • v1.35 での GA に期待 40 GREE サービスに限らず、 社内で利用中のデータサイドカーを 置き換えていきたい
リアーキテクト後のスケール時間・コスト試算 • スケールアウト時間 ◦ 20~25分 (+ キュー待ち時間) → 5分前後 ◦
該当サーバには不要な一部のリポジトリを除去した構成 ◦ イメージ pull 高速化のソリューション導入でさらに高速化可能 ▪ クラスタ内キャッシュ、ストリーミング、P2P配布 etc. • サーバ費用 ◦ シミュレーション上で 50% 以上削減 ▪ HPA target CPU 33% ▪ 前週の 30 分後 (10050 分前) の負荷を参考に事前スケール ◦ スケールが十分速ければ、spot インスタンス導入でさらなる削減も 41
リアーキテクトまとめ • web サーバの運用負荷とサーバ費用 ◦ 運用の複雑性やオートスケール未対応に起因 • CI/CD パイプライン上でモノリスを分割し、 個別のコンテナイメージを作成
◦ ビルド時間短縮・細粒度リリース制御 • k8s 側で統合して単一の web サーバとして動作 ◦ bind mount + mount propagation でコンテナ間ファイルアクセス ◦ アプリケーション側の対応不要 → 高速かつ柔軟、コンテナや k8s の恩恵を最大限受けることができる 42
ご清聴ありがとうございました 43
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}