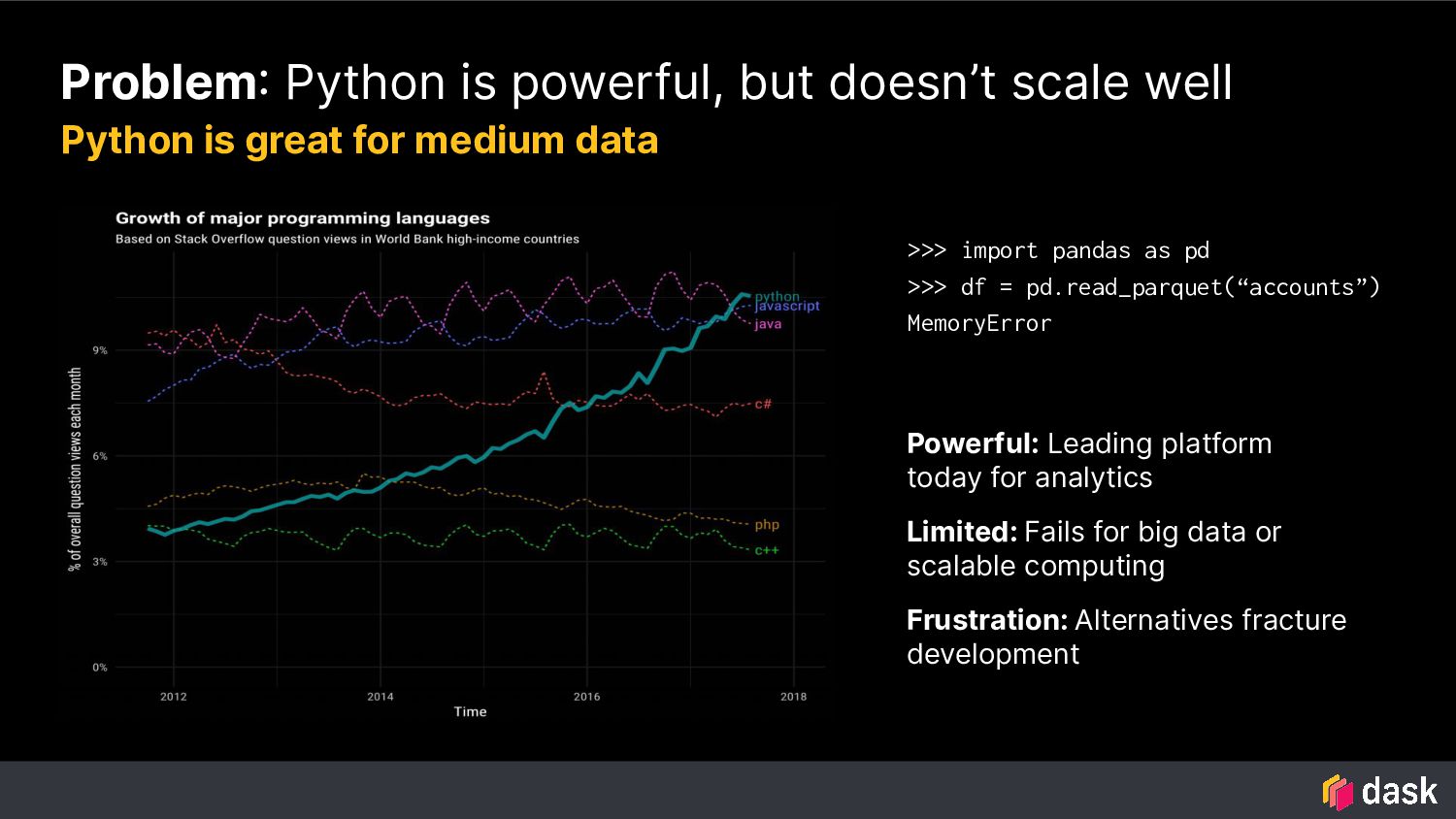
data or scalable computing Frustration: Alternatives fracture development Problem: Python is powerful, but doesn’t scale well Python is great for medium data >>> import pandas as pd >>> df = pd.read_parquet(“accounts”) MemoryError
ambitious project that tried to redefine computation, storage, compression, and data science APIs for Python, led originally by Travis Oliphant and Peter Wang, the co-founders of Anaconda. However, Blaze’s approach of being an ecosystem-in-a-package meant that it was harder for new users to easily adopt. As a result, we started to intentionally develop new components of Blaze outside the project … [and dask was designed to be] the simplest way to do parallel NumPy operations” Matthew Rocklin Dask Creator Source https://coiled.io/blog/history-dask/
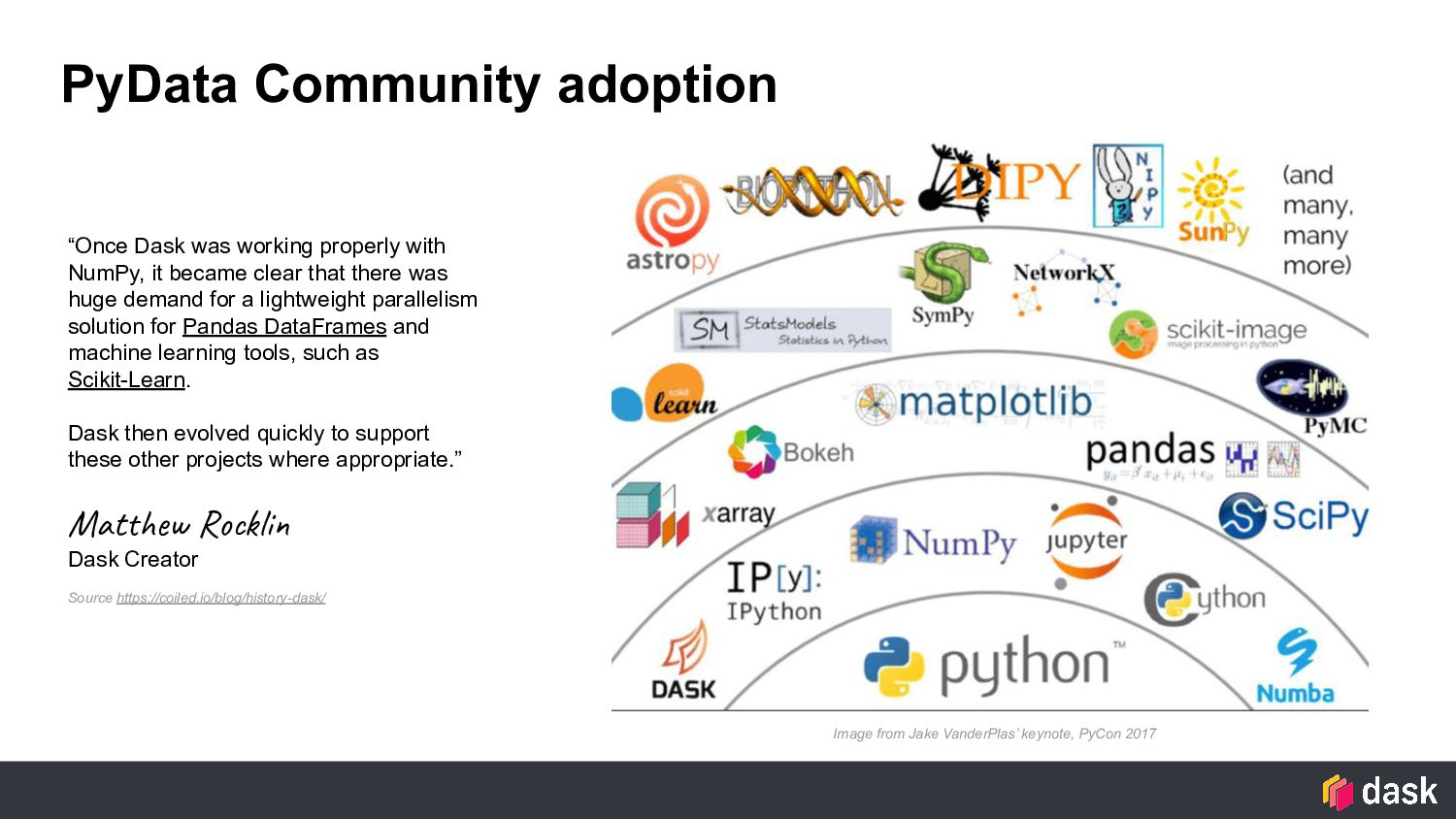
it became clear that there was huge demand for a lightweight parallelism solution for Pandas DataFrames and machine learning tools, such as Scikit-Learn. Dask then evolved quickly to support these other projects where appropriate.” Matthew Rocklin Dask Creator Source https://coiled.io/blog/history-dask/ Image from Jake VanderPlas’ keynote, PyCon 2017
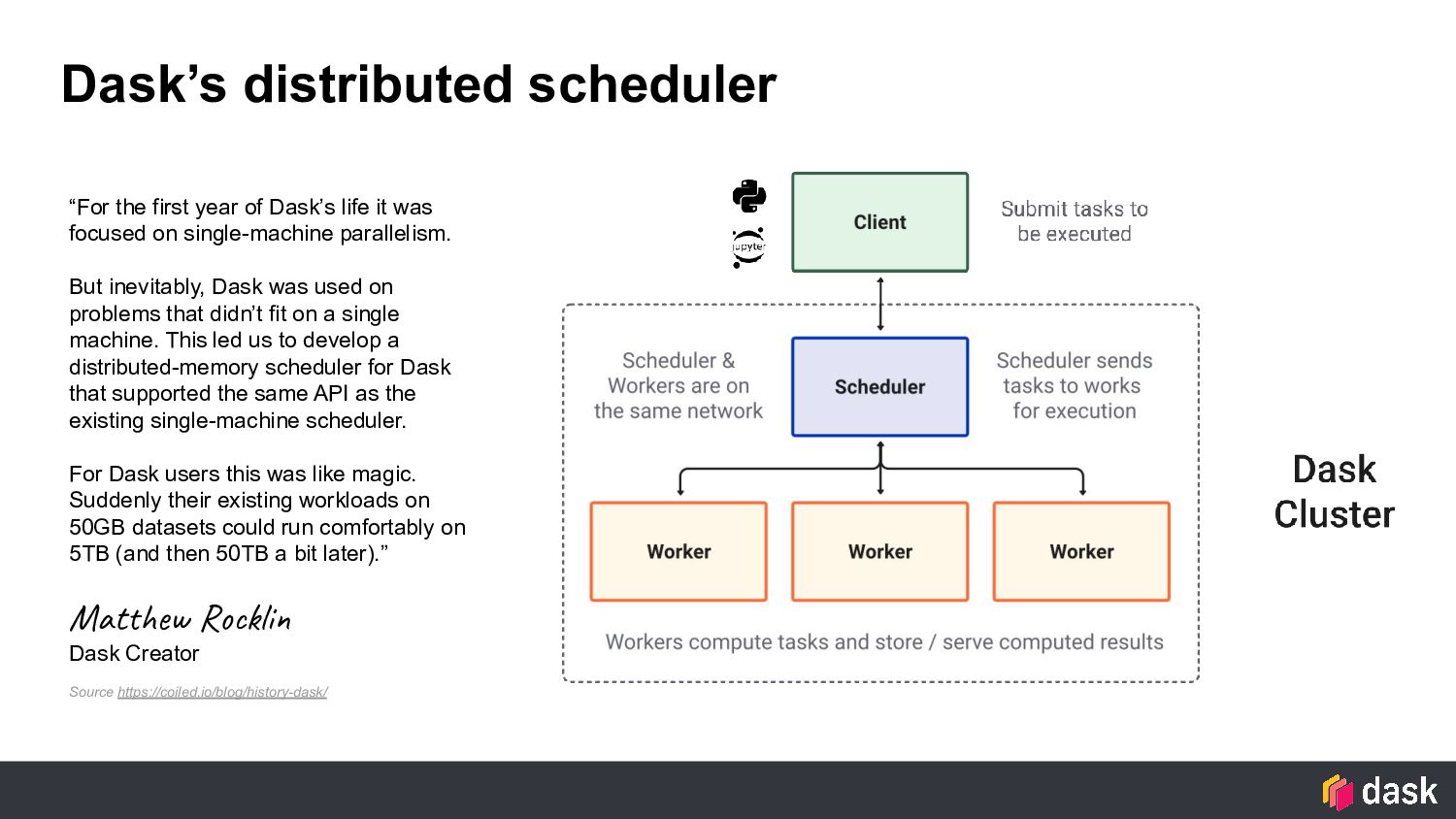
it was focused on single-machine parallelism. But inevitably, Dask was used on problems that didn’t fit on a single machine. This led us to develop a distributed-memory scheduler for Dask that supported the same API as the existing single-machine scheduler. For Dask users this was like magic. Suddenly their existing workloads on 50GB datasets could run comfortably on 5TB (and then 50TB a bit later).” Matthew Rocklin Dask Creator Source https://coiled.io/blog/history-dask/
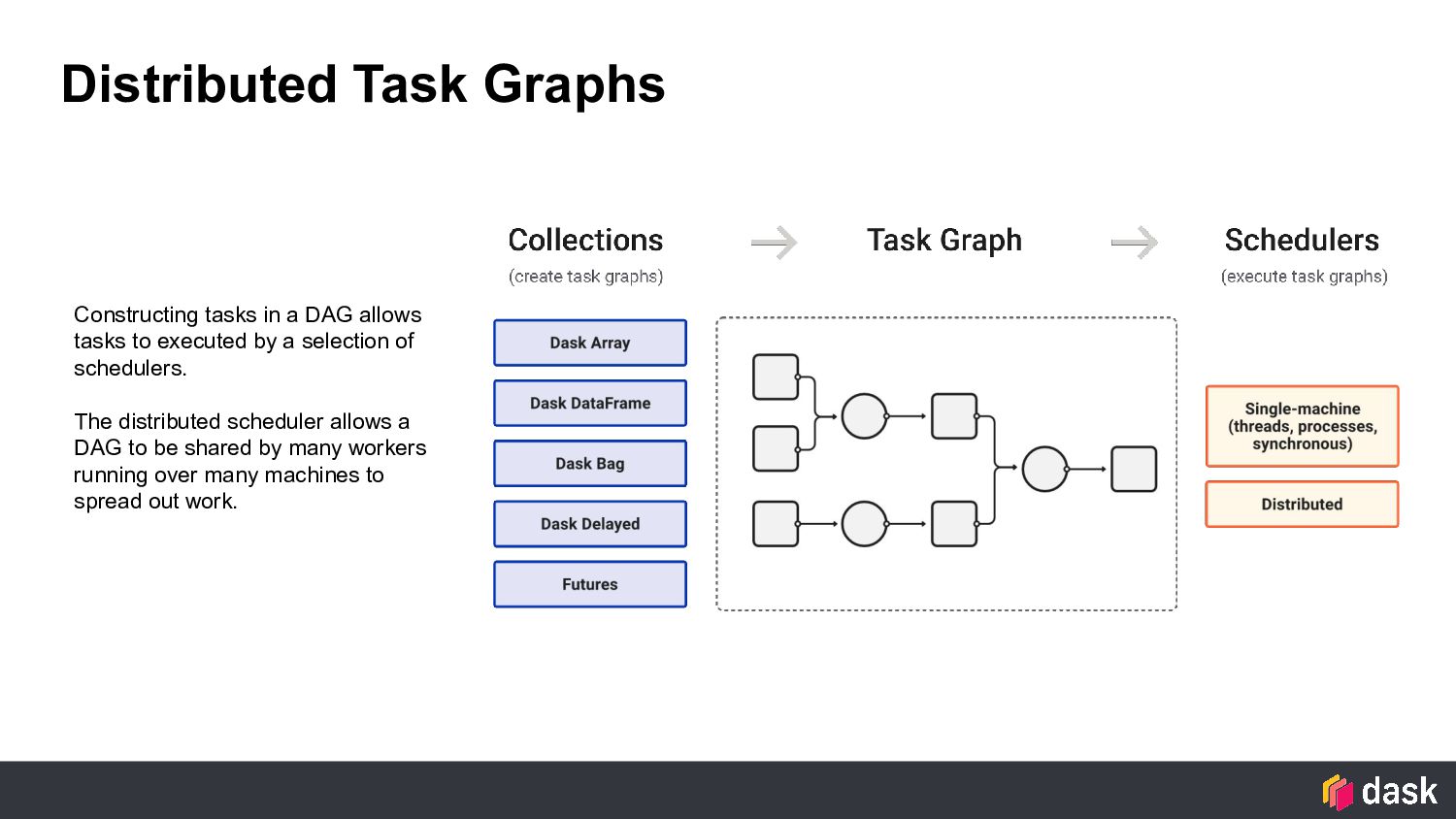
to executed by a selection of schedulers. The distributed scheduler allows a DAG to be shared by many workers running over many machines to spread out work.
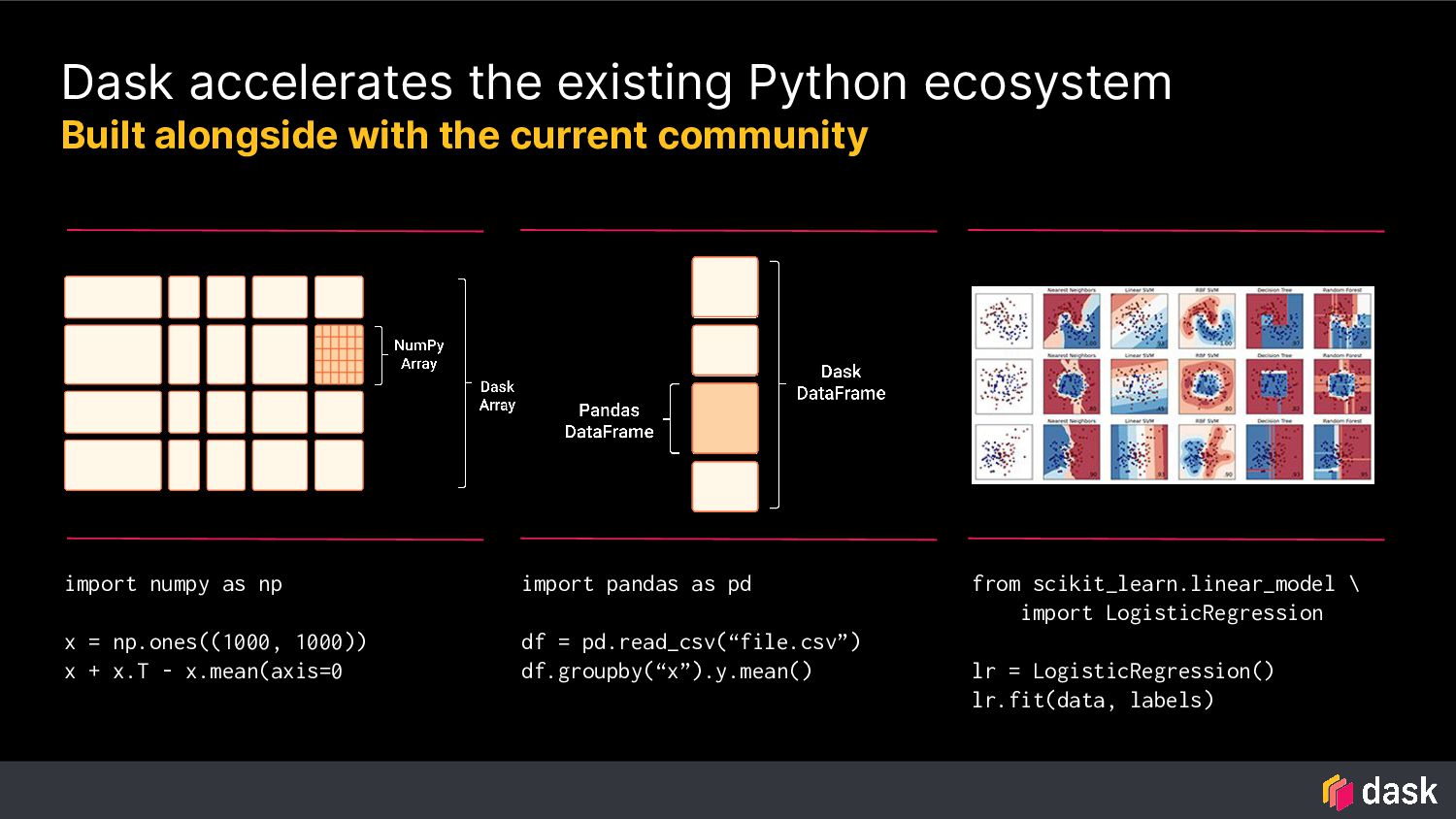
current community import numpy as np x = np.ones((1000, 1000)) x + x.T - x.mean(axis=0 import pandas as pd df = pd.read_csv(“file.csv”) df.groupby(“x”).y.mean() from scikit_learn.linear_model \ import LogisticRegression lr = LogisticRegression() lr.fit(data, labels) Numpy Pandas Scikit-Learn
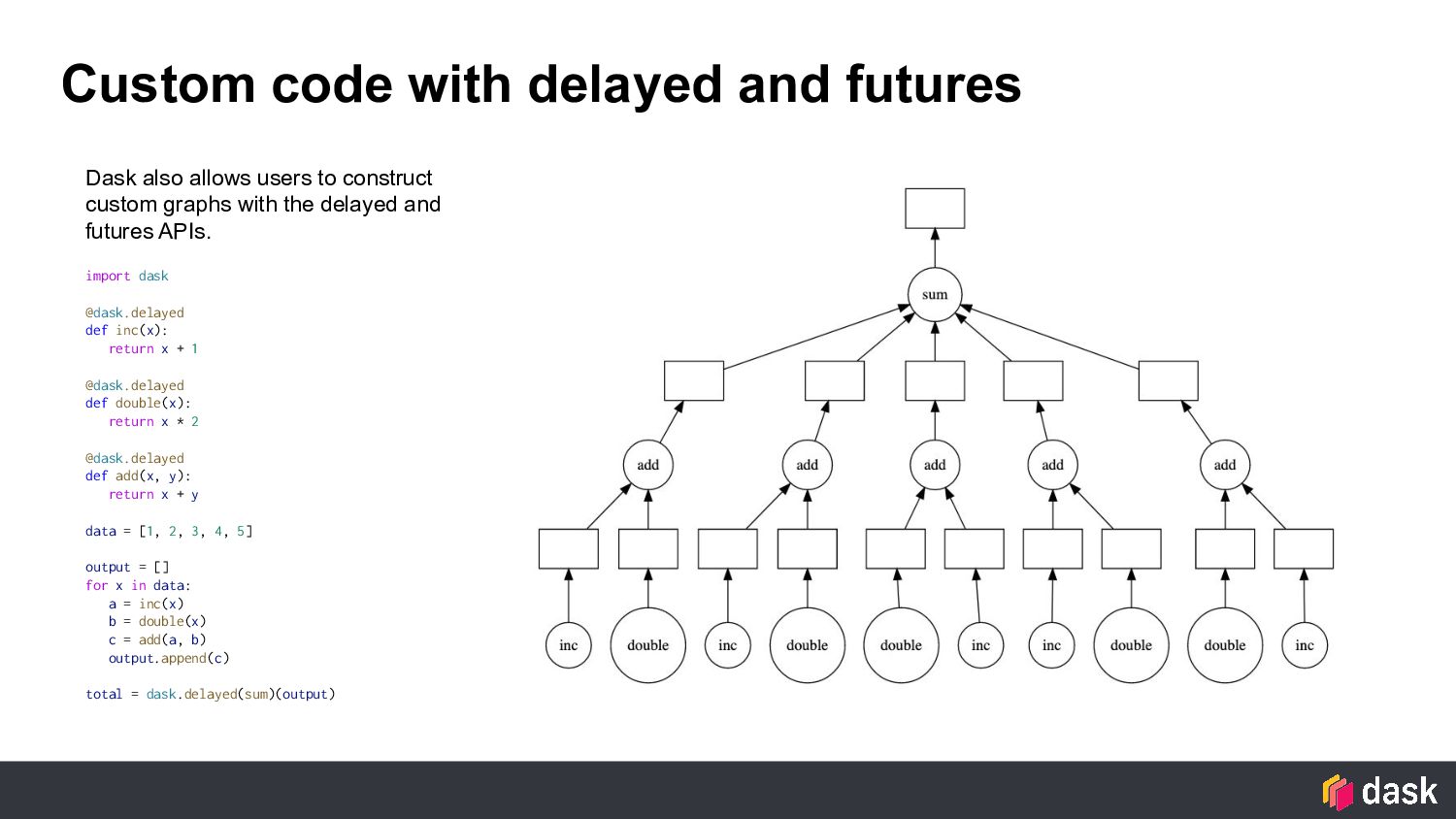
inc(x): return x + 1 @dask.delayed def double(x): return x * 2 @dask.delayed def add(x, y): return x + y data = [1, 2, 3, 4, 5] output = [] for x in data: a = inc(x) b = double(x) c = add(a, b) output.append(c) total = dask.delayed(sum)(output) Dask also allows users to construct custom graphs with the delayed and futures APIs.
= PBSCluster() cluster = LSFCluster() cluster = SLURMCluster() … df = dd.read_parquet(...) cluster = YarnCluster() df = dd.read_parquet(...) Dask deploys on all major resource managers Cloud HPC Hadoop/Spark Cloud, HPC, or Yarn, it’s all the same to Dask
install dask-kubernetes # Launch a cluster >>> from dask_kubernetes.experimental \ import KubeCluster >>> cluster = KubeCluster(name="demo") # List the DaskCluster custom resource that was created for us under the hood $ kubectl get daskclusters NAME AGE demo-cluster 6m3s
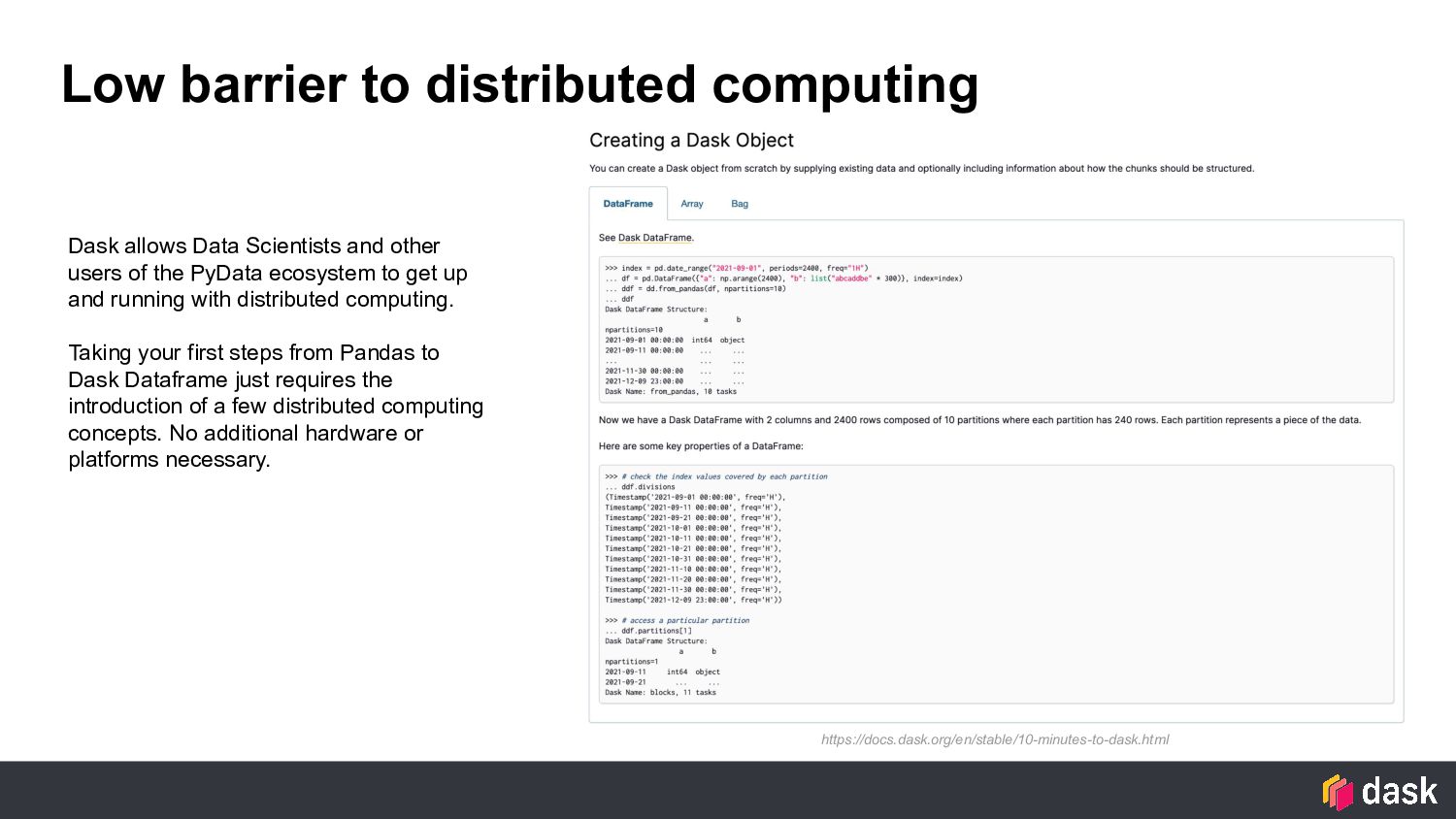
and other users of the PyData ecosystem to get up and running with distributed computing. Taking your first steps from Pandas to Dask Dataframe just requires the introduction of a few distributed computing concepts. No additional hardware or platforms necessary.
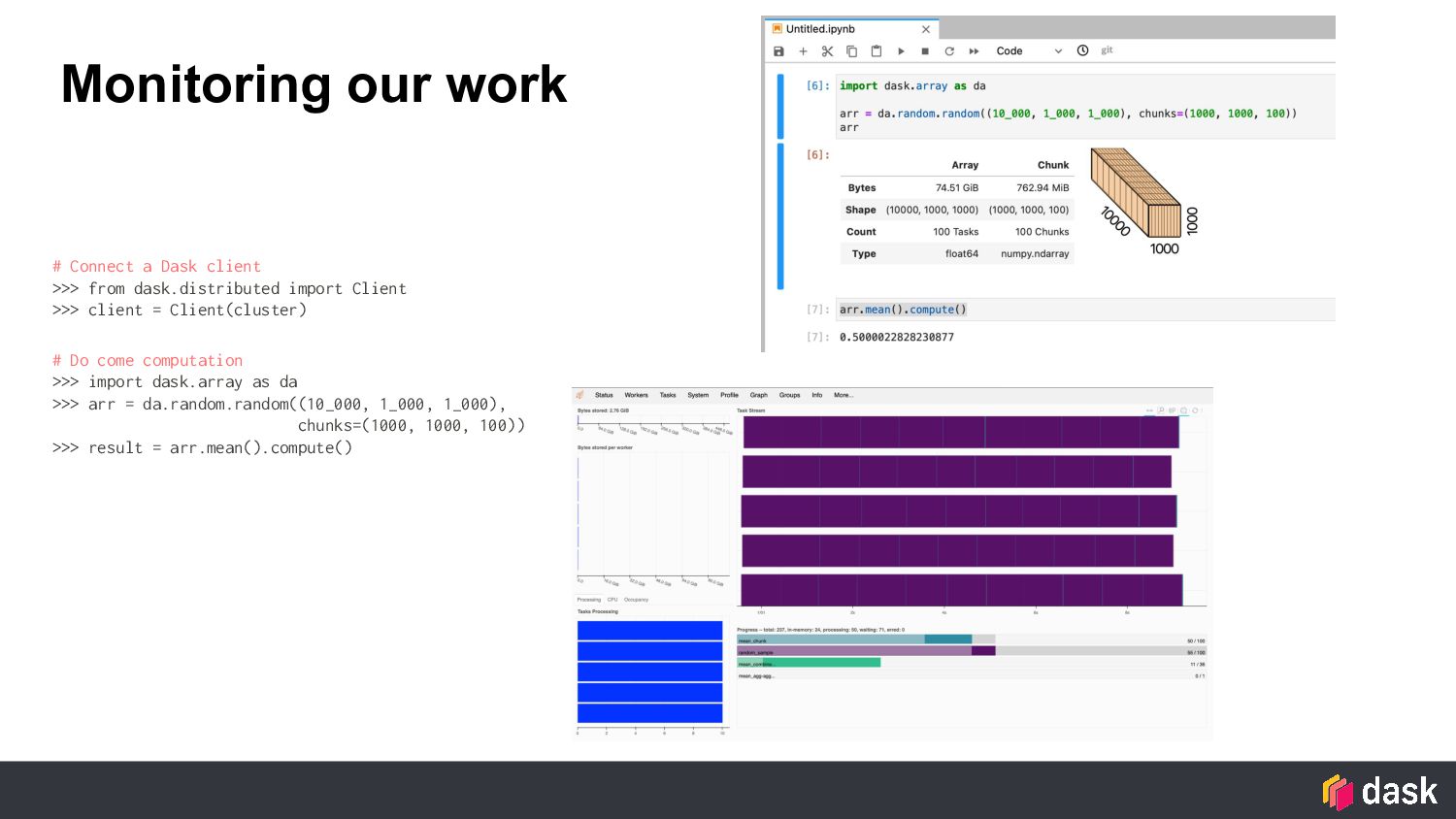
cluster is performing. You can view it in a browser or directly within Jupyter Lab to see how your graphs are executing. You can also use the built in profiler to understand where the slow parts of your code are.
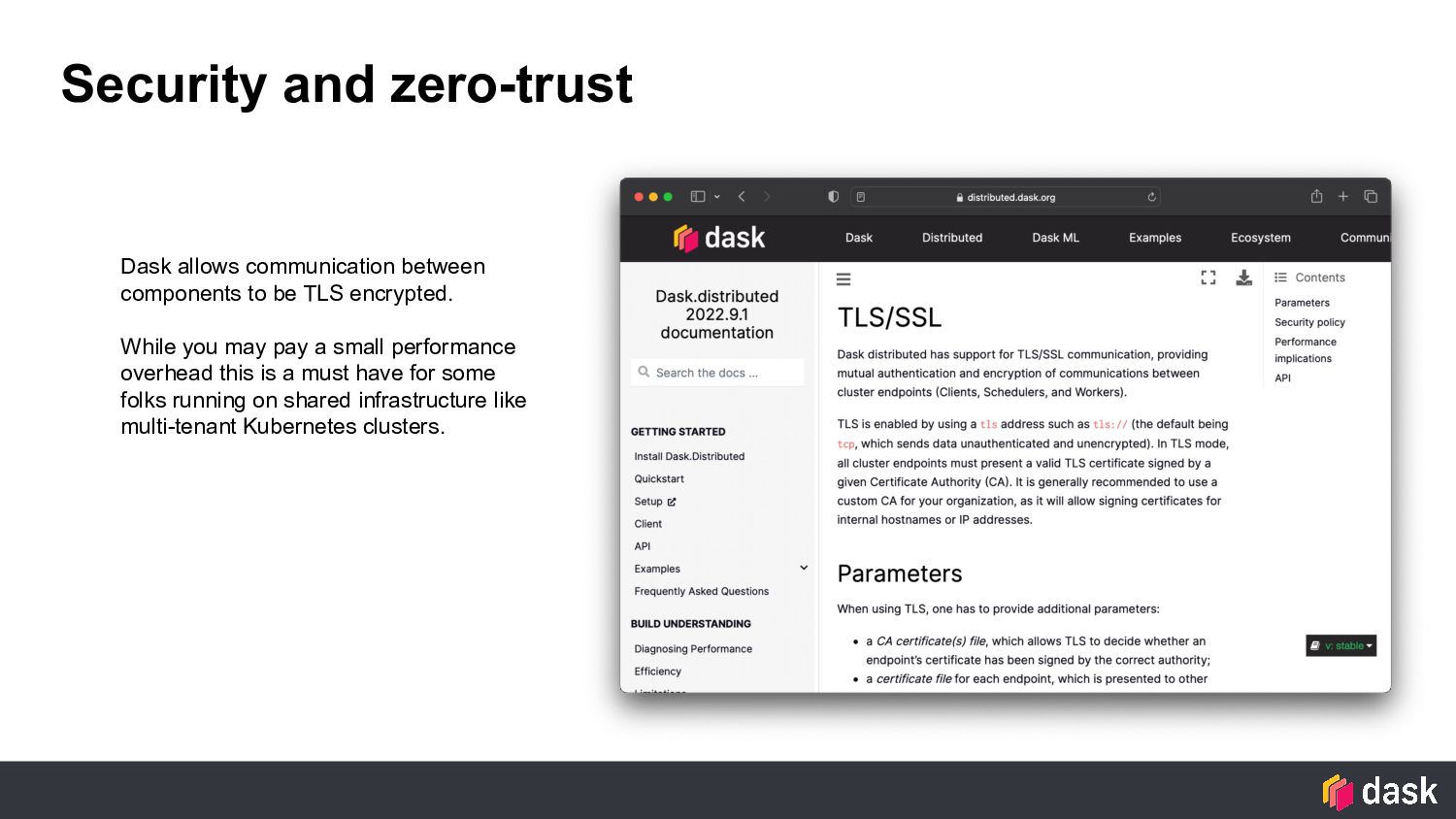
TLS encrypted. While you may pay a small performance overhead this is a must have for some folks running on shared infrastructure like multi-tenant Kubernetes clusters.
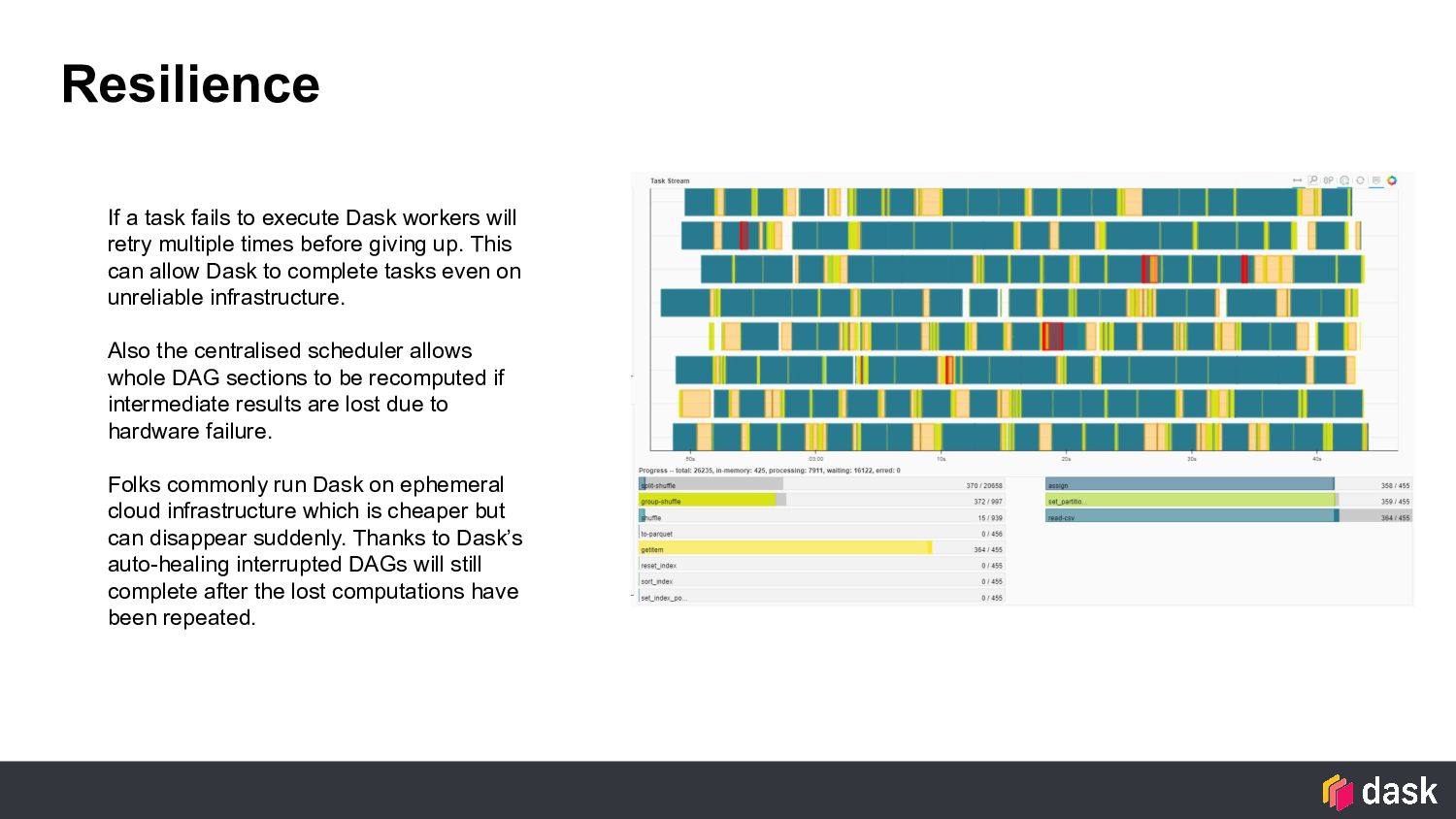
retry multiple times before giving up. This can allow Dask to complete tasks even on unreliable infrastructure. Also the centralised scheduler allows whole DAG sections to be recomputed if intermediate results are lost due to hardware failure. Folks commonly run Dask on ephemeral cloud infrastructure which is cheaper but can disappear suddenly. Thanks to Dask’s auto-healing interrupted DAGs will still complete after the lost computations have been repeated.
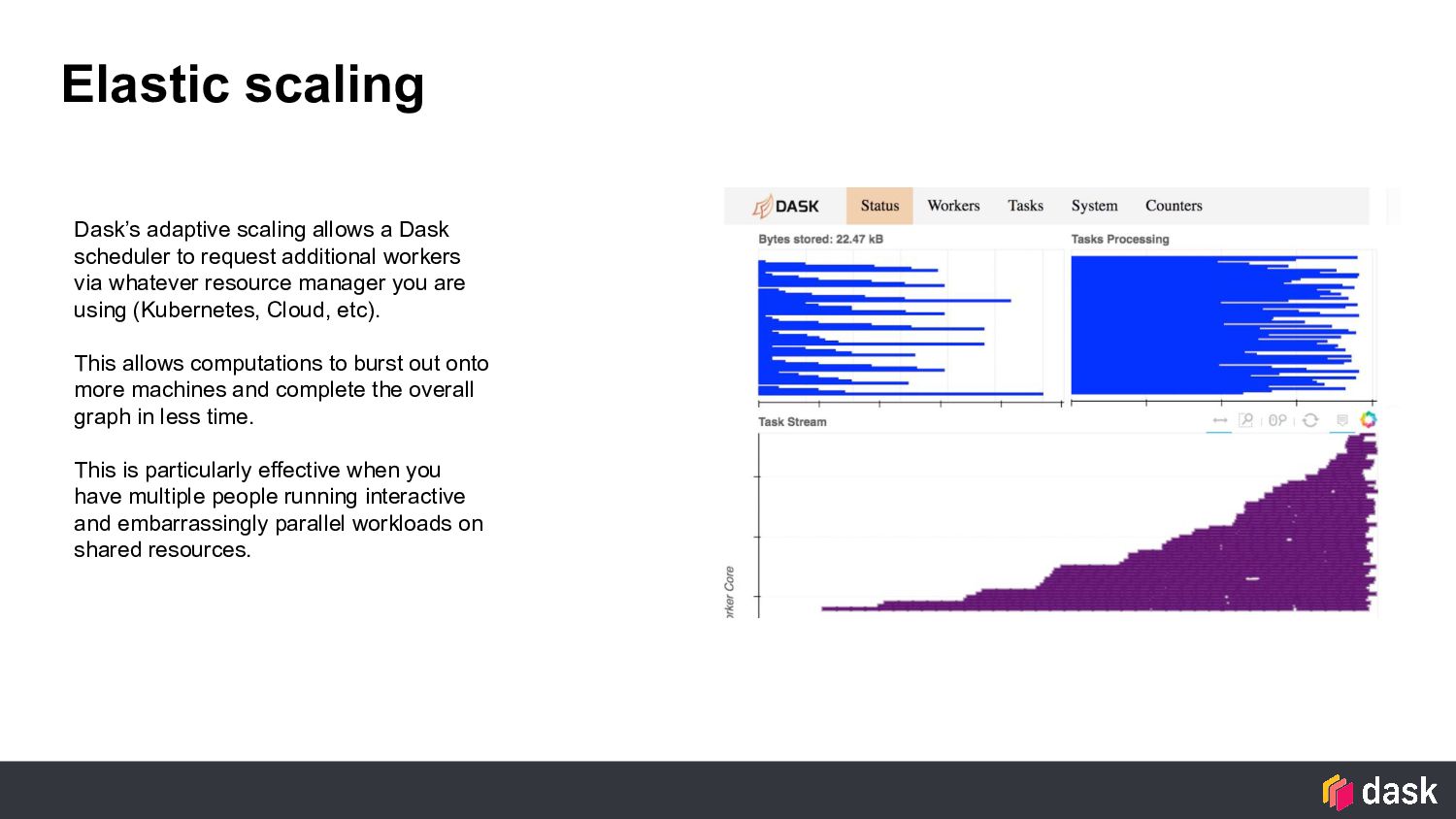
request additional workers via whatever resource manager you are using (Kubernetes, Cloud, etc). This allows computations to burst out onto more machines and complete the overall graph in less time. This is particularly effective when you have multiple people running interactive and embarrassingly parallel workloads on shared resources.
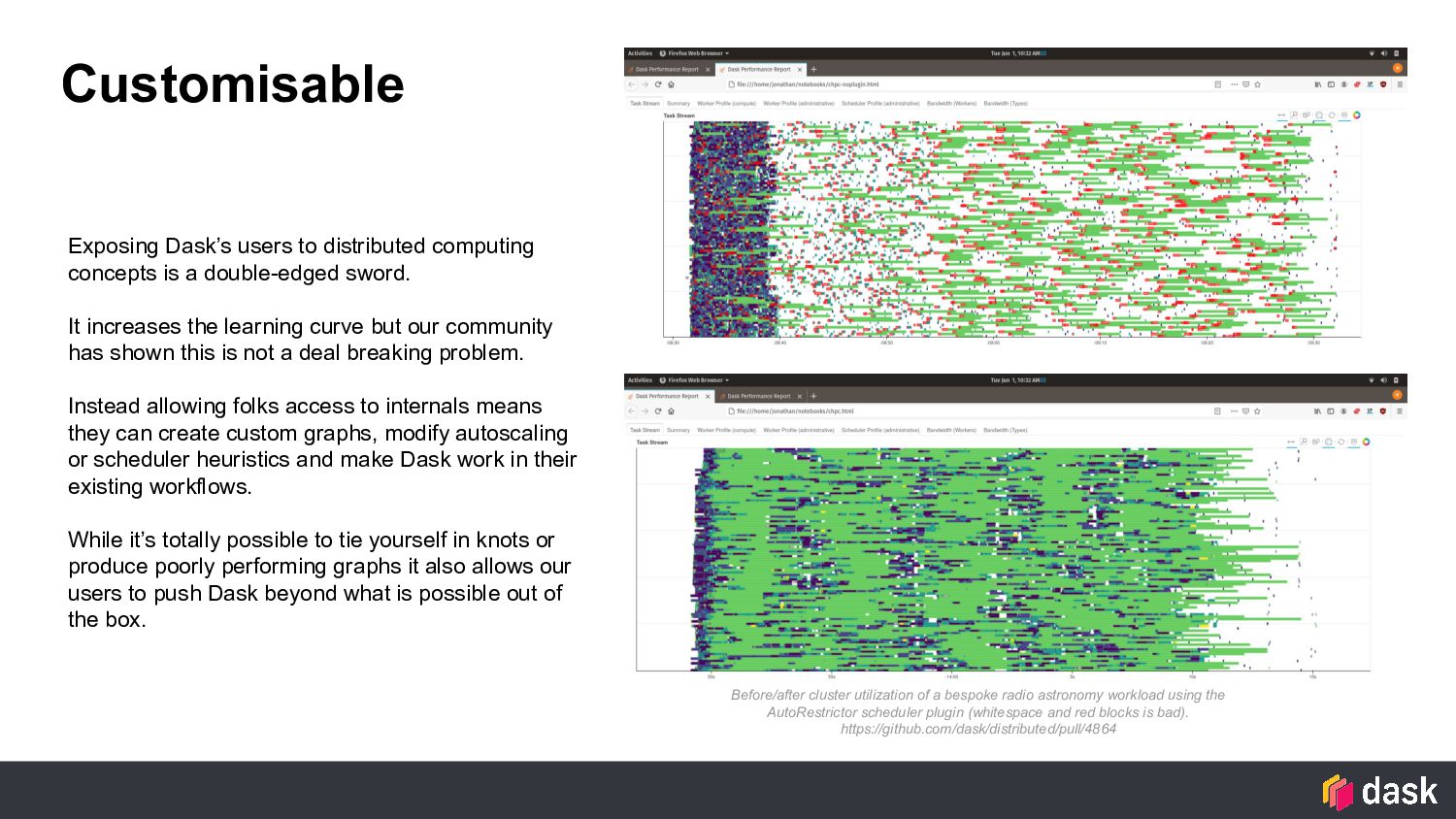
double-edged sword. It increases the learning curve but our community has shown this is not a deal breaking problem. Instead allowing folks access to internals means they can create custom graphs, modify autoscaling or scheduler heuristics and make Dask work in their existing workflows. While it’s totally possible to tie yourself in knots or produce poorly performing graphs it also allows our users to push Dask beyond what is possible out of the box. Before/after cluster utilization of a bespoke radio astronomy workload using the AutoRestrictor scheduler plugin (whitespace and red blocks is bad). https://github.com/dask/distributed/pull/4864
on parallel performance Familiar APIs and data models Dask looks and feels like well known libraries in the PyData ecosystem Co-developed with the ecosystem Built by NumPy, Pandas, and Scikit-Learn devs Dask complements the existing ecosystem Dask is designed for experts and novices alike
Pandas, Scikit-Learn, Jupyter, and more Run by people you know, built by people you trust Safe: BSD-3 Licensed, fiscally sponsored by NumFOCUS, community governed Discussed: Dask is the most common parallel framework at PyData/SciPy/PyCon conferences today. Used: 10k weekly visitors to documentation 28
financial and credit data to build cloud-based machine learning models • Datasets range in scale from 1 GB - 100 TB • CSV and Parquet datasets 100s - 1000s of columns • Data Cleaning, Feature Selection, Engineering, Training, Validation, and Governance • Dask DataFrames used to train with dask-ml and dask-xgboost • 10x speed up in computational performance with Dask • Faster development and improved accuracy for credit risk models • Deployments on AWS can be optimized to reduce overall computing costs or faster development iterations Data cleaning, Feature engineering, and Machine learning
observed climate and imaging data 1 GB - 100 TB HPC and Cloud HDF5/NetCDF/Zarr storage Interactive computing with notebooks Includes collaborators NASA, NOAA, USGS, UK-Met, CSIRO, and various industries Learn more about Pangeo in this talk Sea level altitude variability over 30 years Columbia/NCAR leverage Dask Array to understand our planet
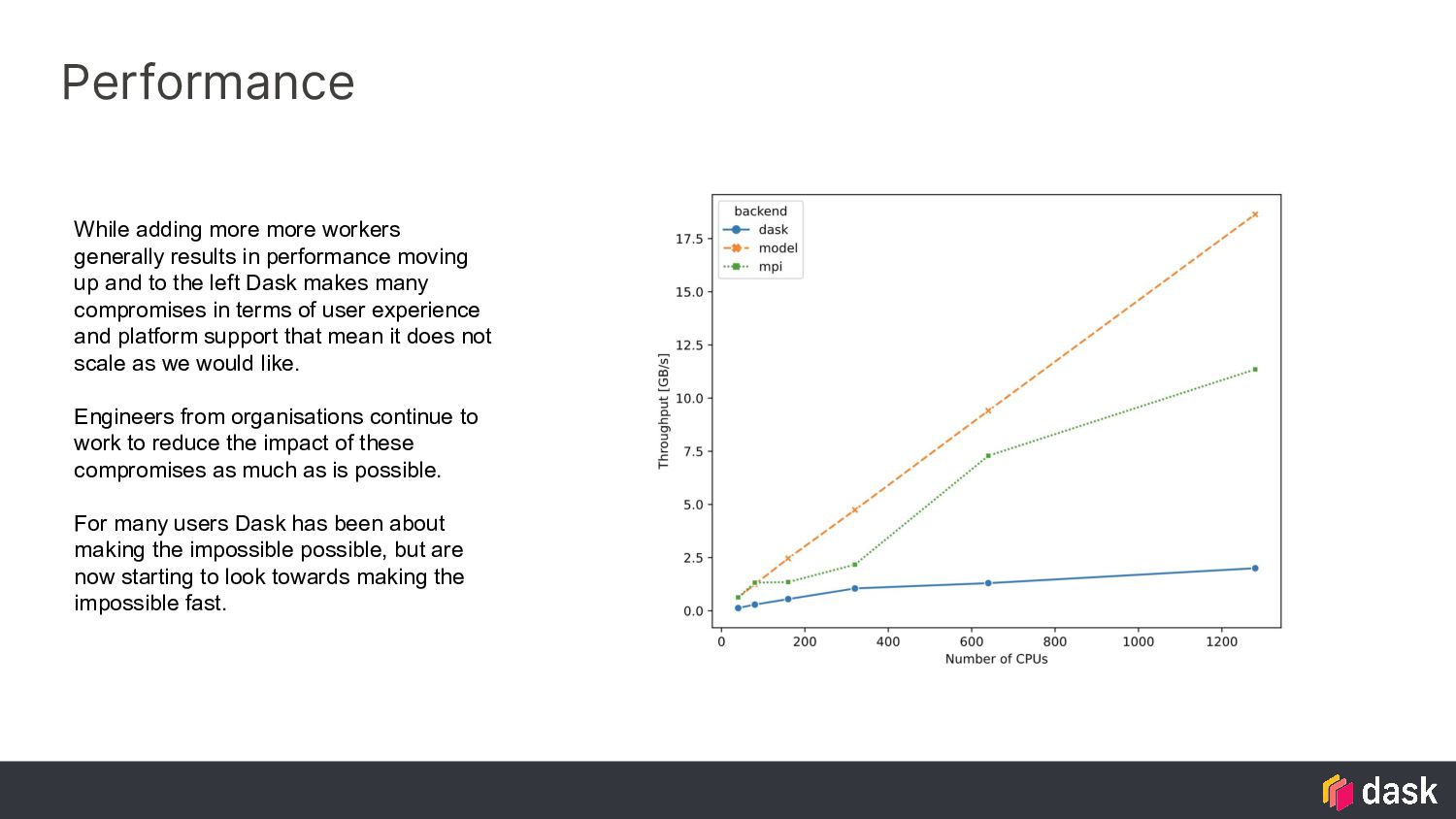
moving up and to the left Dask makes many compromises in terms of user experience and platform support that mean it does not scale as we would like. Engineers from organisations continue to work to reduce the impact of these compromises as much as is possible. For many users Dask has been about making the impossible possible, but are now starting to look towards making the impossible fast.
requires users to have knowledge of how to deploy it and to manage their clusters. There are many tools in Dask that automate this and allow less experienced users to run large clusters on the cloud and beyond. A key next step is making these deployment mechanisms more robust, flexible and usable. Whether that is improving the tools themselves or creating new tools that give more context and information to users about their clusters.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}