Shared from the perspective of 4 ultra-endurance athletes, who coincidentally are experts in building resiliency and constant improvements in systems both digital and human, I’ll share some of the most critical aspects of site reliability engineering.
From preparation to pushing known limits to learning and improving, there is much that can be learned about how we approach building resiliency into our systems.
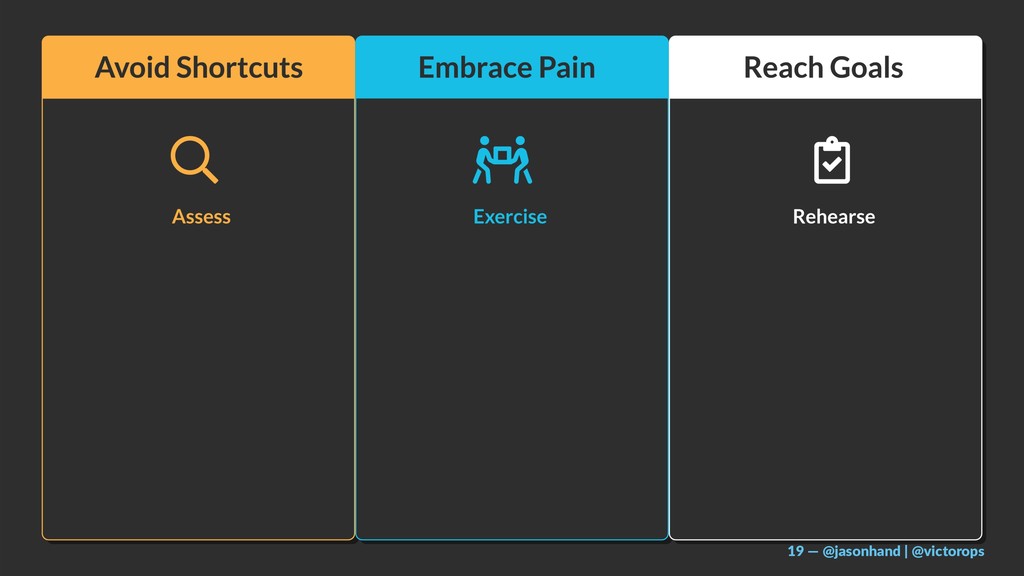
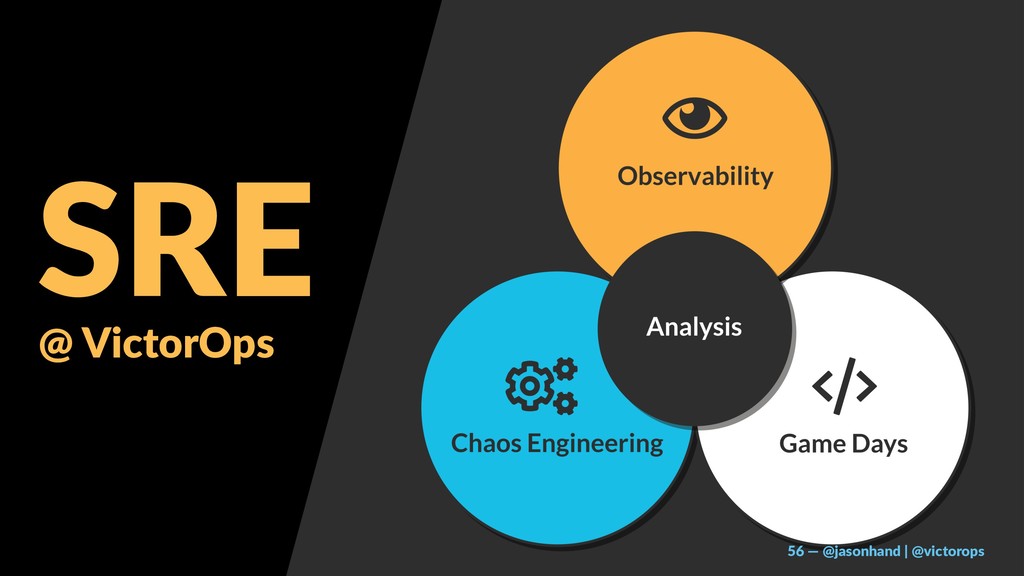
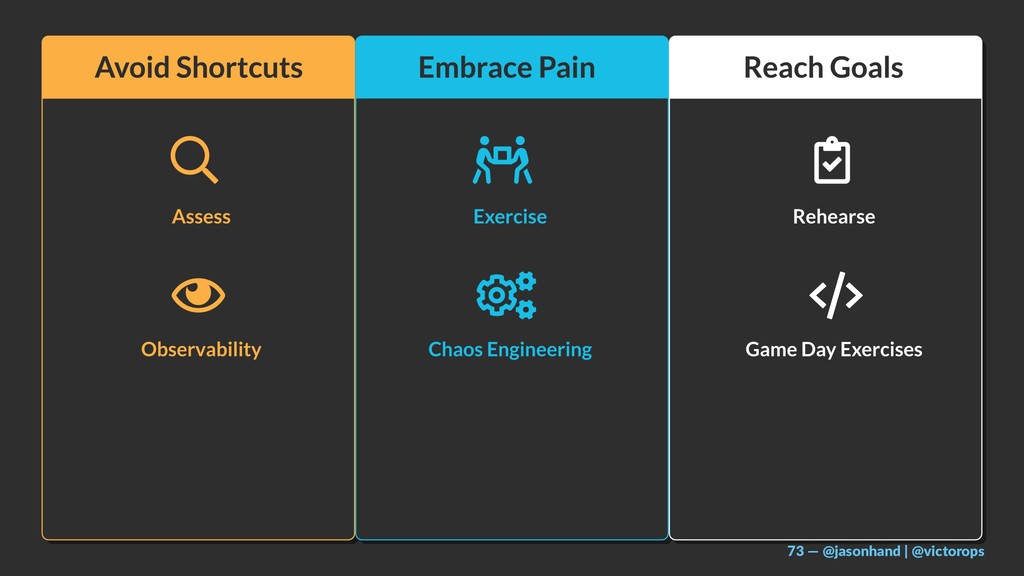
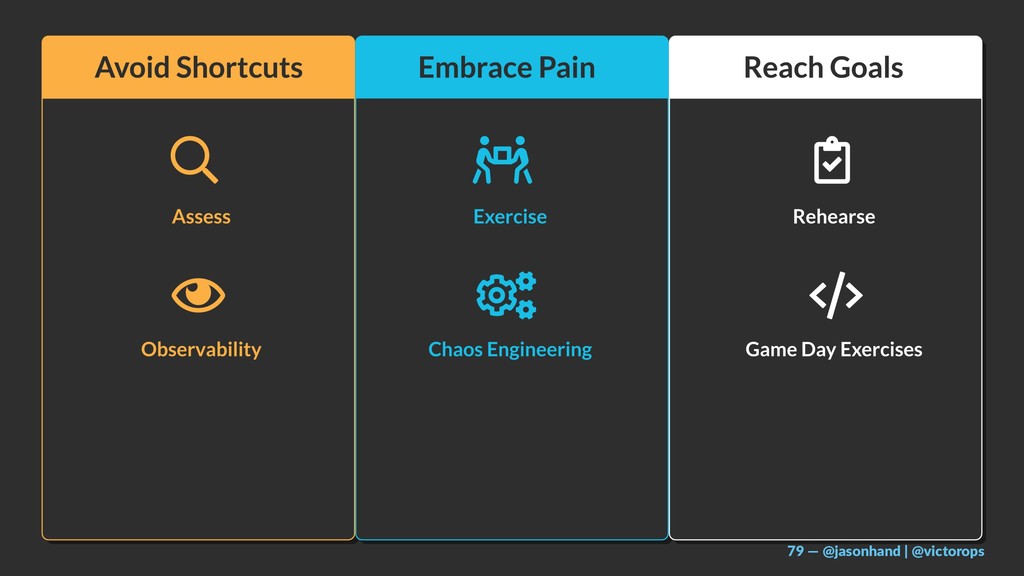
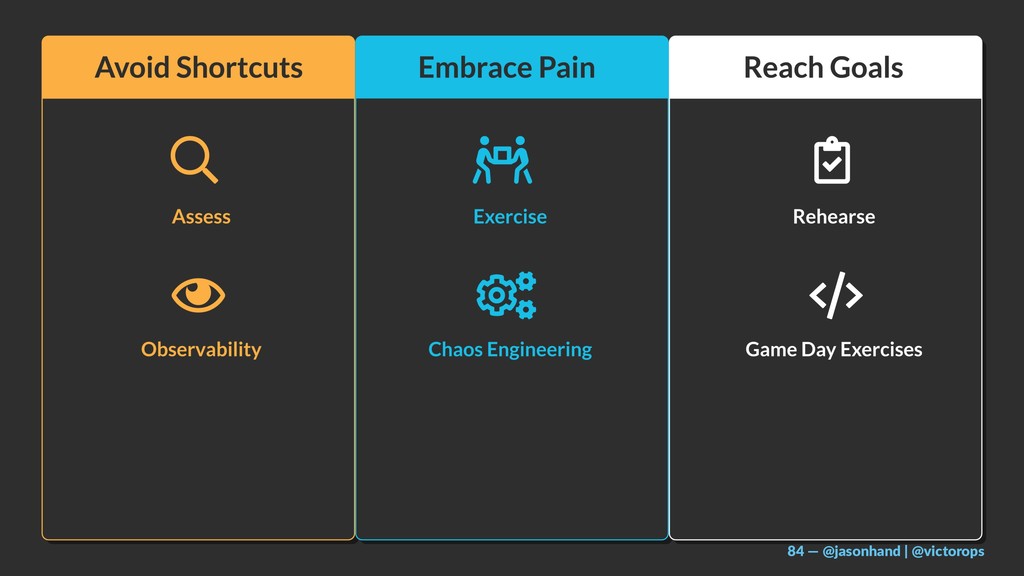
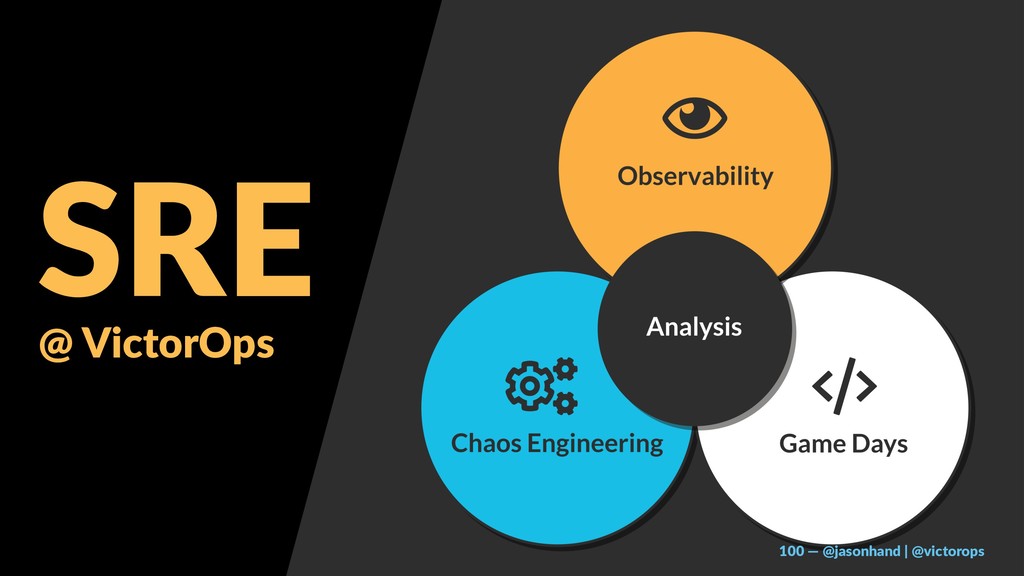
I will share a 3-tiered approach towards site reliability including:
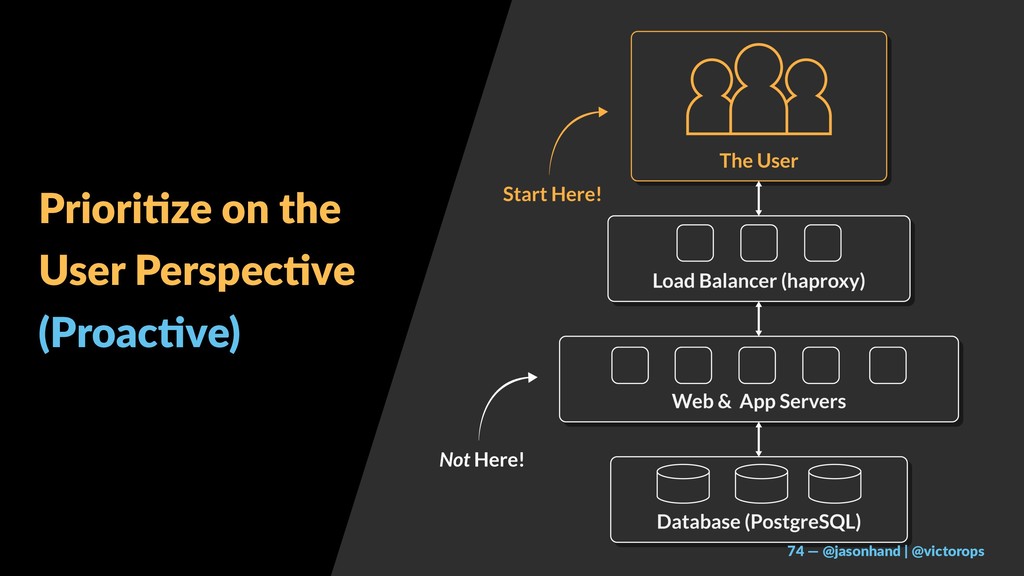
Observability (from the customer’s perspective)
Chaos Engineering (proactively understanding reality and setting expectations)
GameDay & Incident Management (preparation and practice of important roles and procedures)
Audience members will walk away with a better understanding of Observability and where monitoring plays a role in it. They will also be left with actionable ideas to implement very quickly within their own organization to begin their own SRE initiative almost immediately. Fears and confusion surrounding Chaos Engineering and QA testing “in Prod” will be clarified and the value of such efforts will be extremely clear.
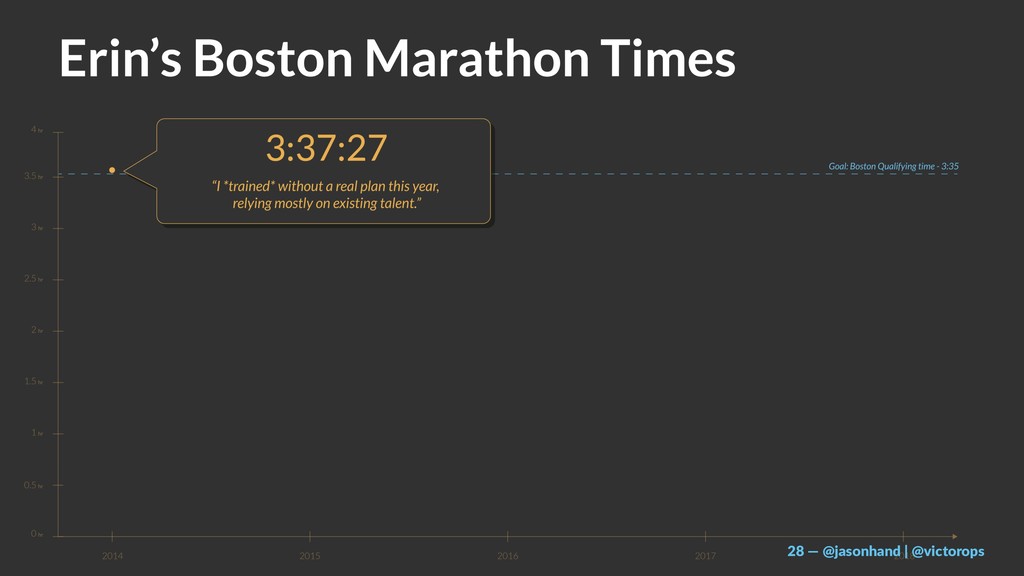
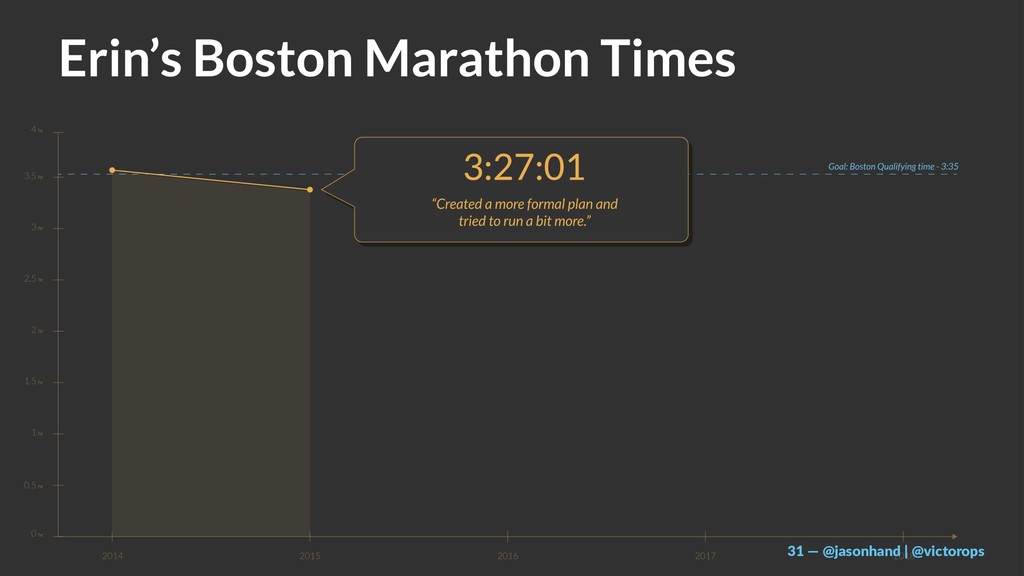
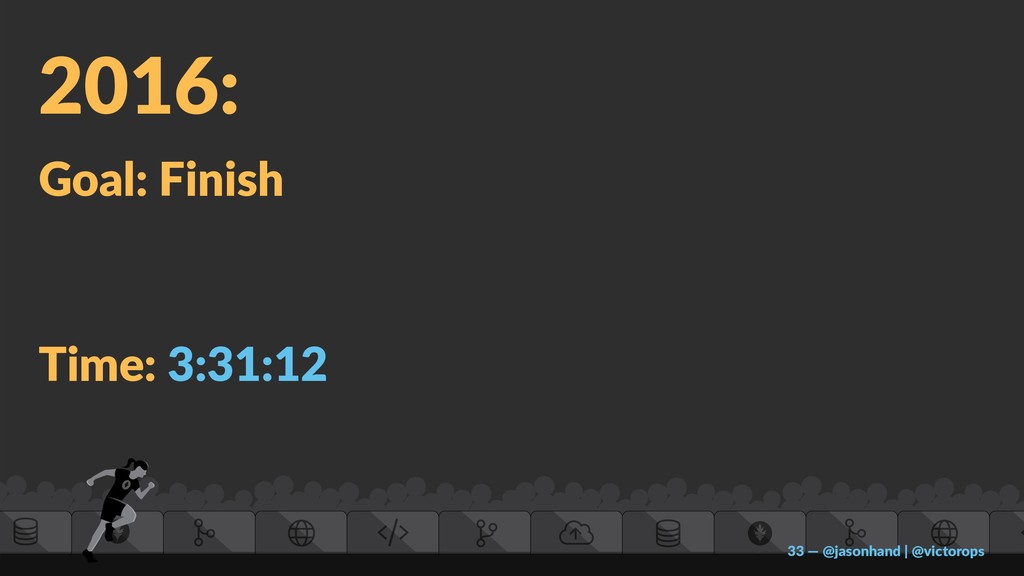
By sharing the stories of 4 athletes and the extreme (100+ mile) races they train for, execute, and learn from… I hope to expose a clear approach to increasing the uptime of systems while continuously delivering products and services our customers value the most.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}