An overview of the CONTROL project and Online QP. Versions of this talk given at MIT (1/03), Polytechnic (11/02), Harvard (10/02), OGI/PSU (1999), Internet Archive (1999). Distinguished lecture at University of Virginia, 1999.
situation: online query processing n HCI motivations n Example applications n Example Algorithms n Reordering and Ripple Joins Implications for “hot topics” n Big data, small pipes: P2P, Sensor nets n Continuous Queries over data streams
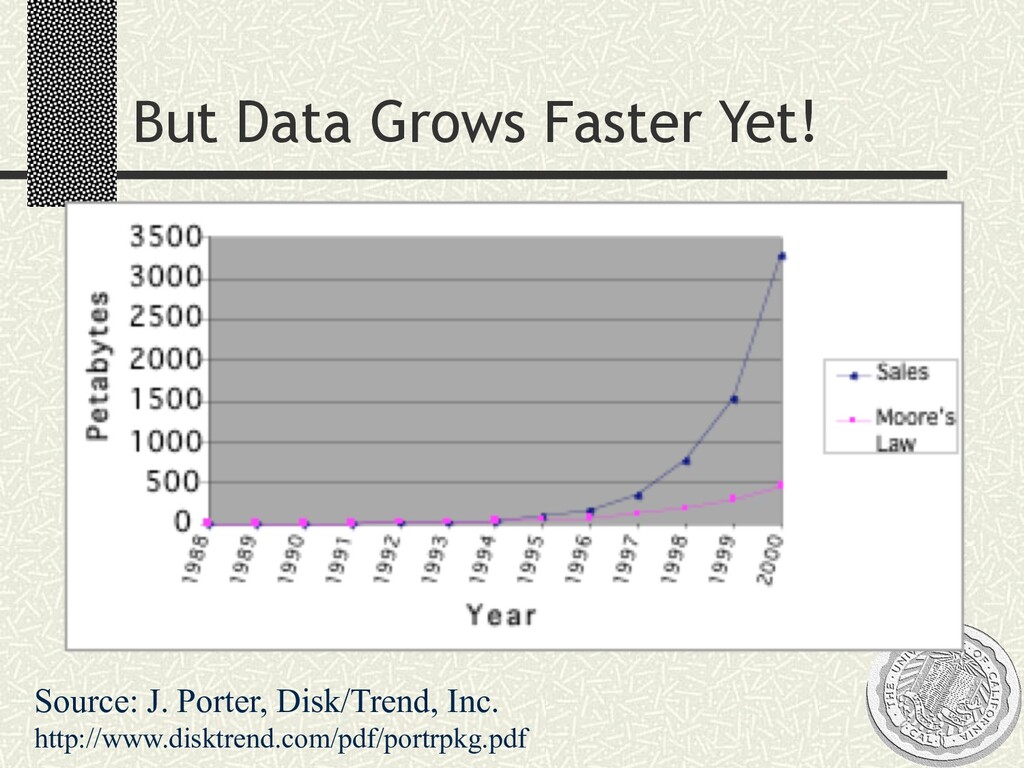
doubling every 9 months Translate: n Time to process all your data doubles every 18 months n MOORE’S LAW INVERTED! Big challenge (opportunity?) for SW systems research n Feel free to discount the analysis above significantly n Even so, traditional “scalability” research won’t help n “Ideal” linear scaleup is NOT NEARLY ENOUGH! n HW will not take us there.
TB Data Warehouse n ClickStream n One service generates >100GB of log per day n Web n Internet Archive WayBack Machine: >100 TB n Replicated OS/Apps, MP3s, etc. Tomorrow: n Sensor feeds galore n Big data, small pipes: Sensor nets, P2P n Continuous queries over data streams
situation: online query processing n HCI motivations n Example applications n Example Algorithms n Reordering and Ripple Joins Implications for “hot topics” n P2P query systems n Sensor nets n Stream Query Processing
A losing proposition as data volume grows HCI solution: interactive tools don’t do big jobs n E.g., spreadsheet programs (64Krow limit) Systems solution: big jobs aren’t interactive n No user feedback or control in big DBMS queries n “back to the 60’s” n Long processing times n Fundamental mismatch with preferred modes of HCI Best solutions to date precompute n E.g. “OLAP” n Don’t handle ad hoc queries or data sets well
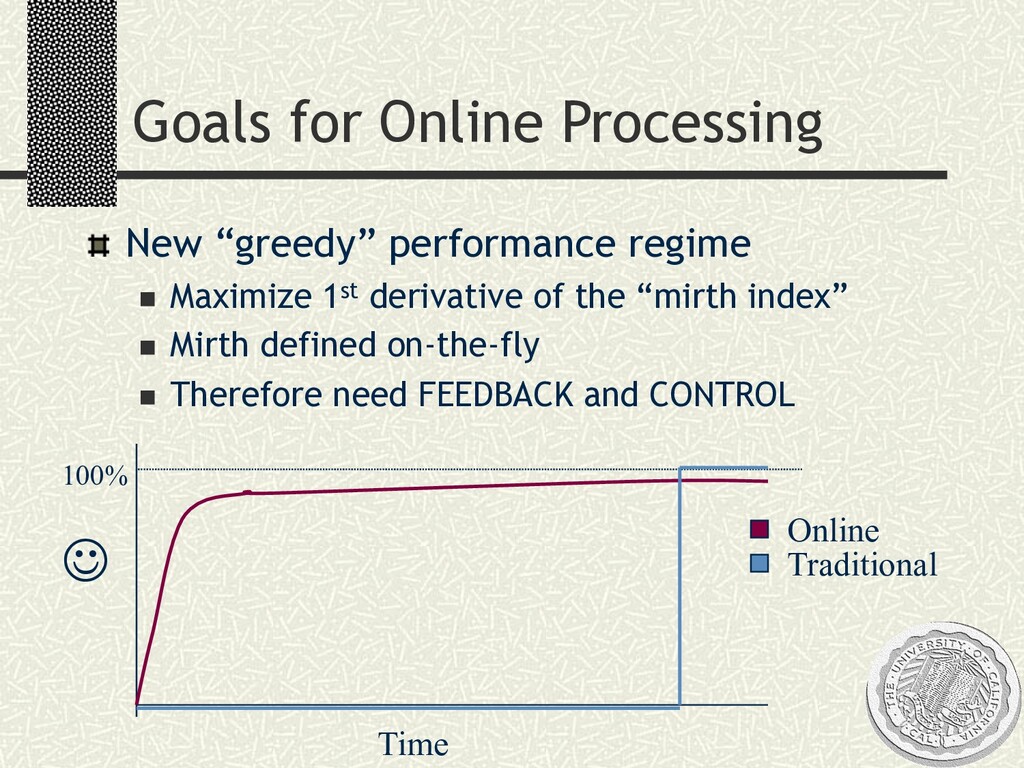
all men's miseries, the bitterest is this: to know so much and have control over nothing” -- Herodotus Requirements for CONTROL systems n Early answers n Refinement over time n Interaction and ad-hoc control “Crystal Ball” vs. Black Box n vs. “Lucite Watch”
SQL n Postgres, Informix, IBM DB2 n Potter’s Wheel n Scalable Spreadsheet for Online Data Cleaning n Interactive anomaly detection & transformation n CARMA online association rule mining n 2 Online Data Viz prototypes n CLOUDS & Phoebus Seeded current Telegraph project n Adaptive dataflow for querying networked sources
situation: online query processing n HCI motivations n Example applications n Example Algorithms n Reordering and Ripple Joins Implications for “hot topics” n P2P query systems n Sensor nets n Stream Query Processing
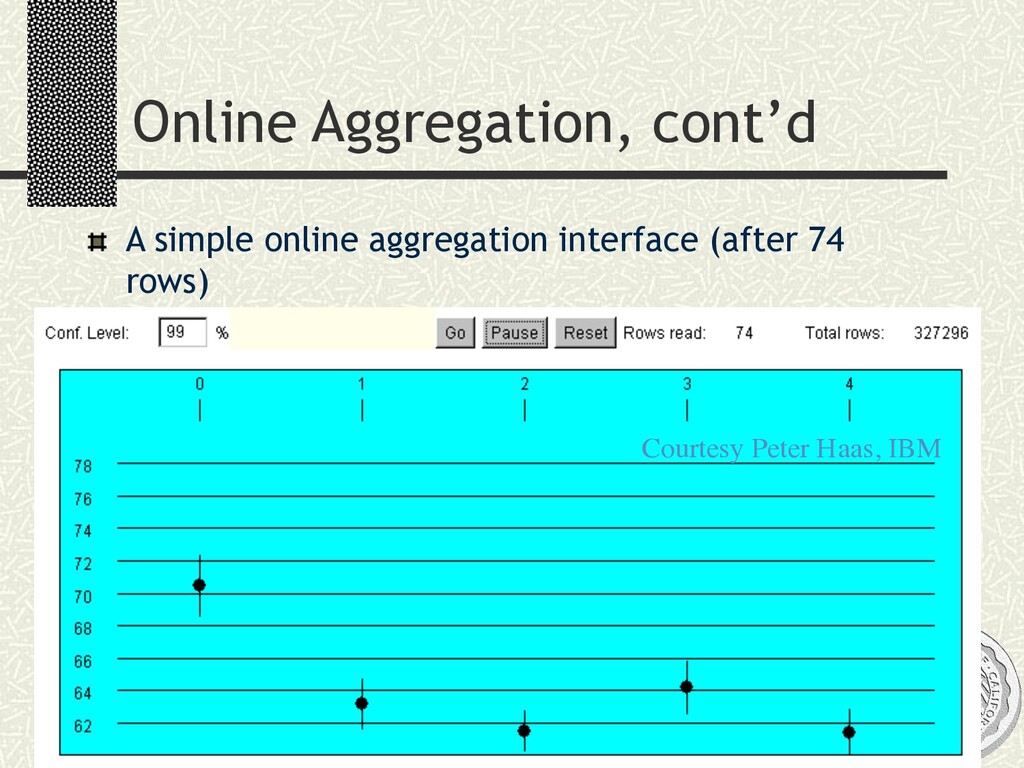
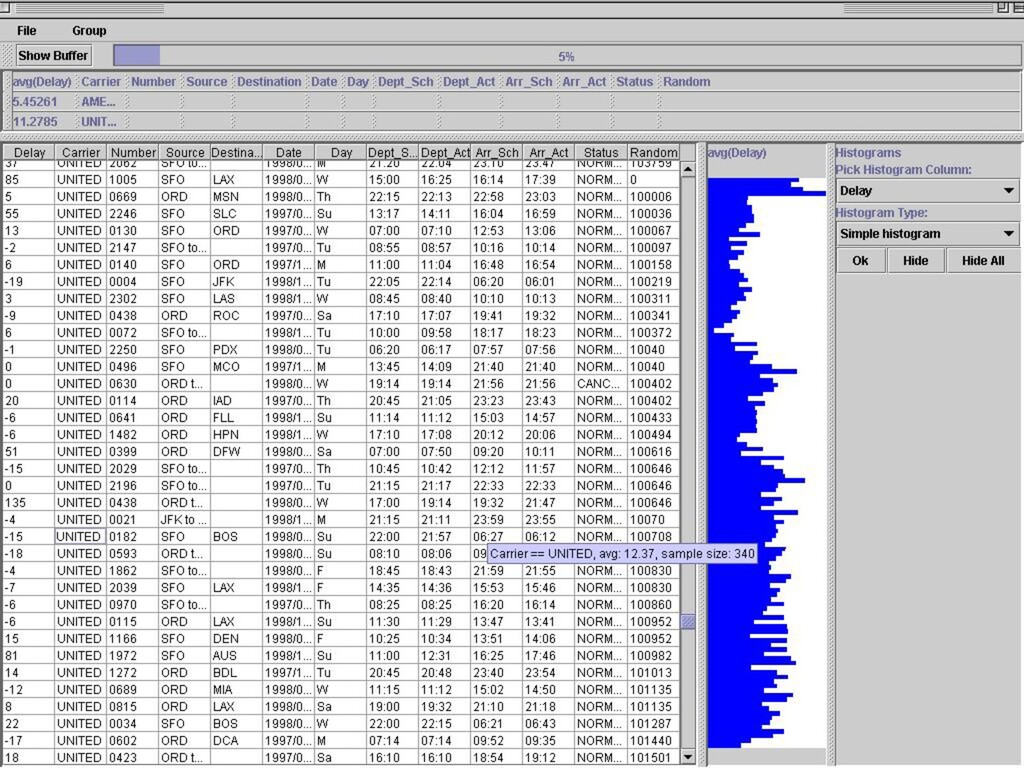
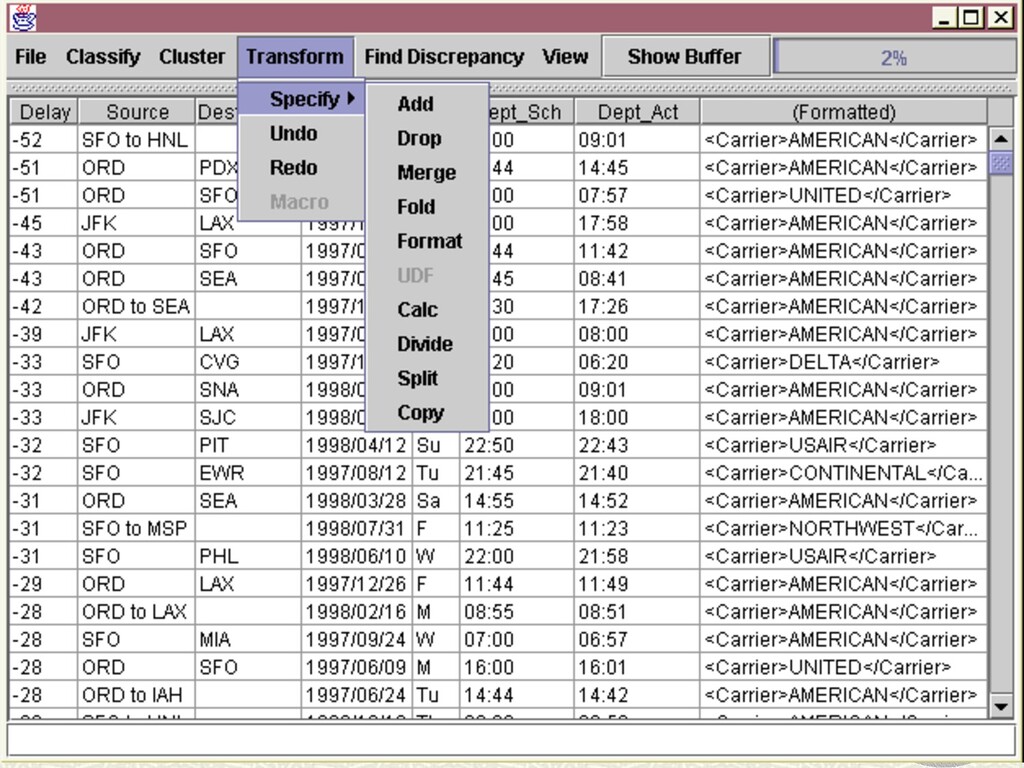
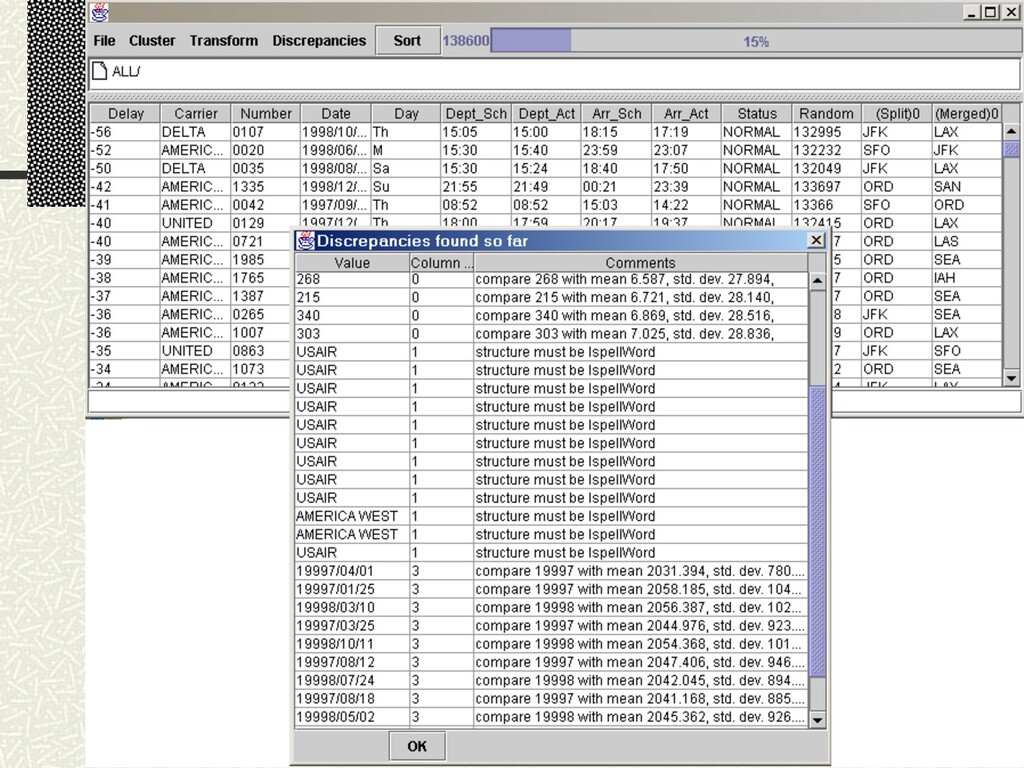
n A fraction of data is materialized in GUI widget at any time n Scrolling = preference for delivering quantiles to widget Interactive data cleaning n Direct-manipulation interface via visual algebra n Transformation by example Online structure and discrepancy detection n MDL meets ADTs n Minimum Description Length [Rissinen] for modeling data n Based on a grammar of user-defined Abstract Data Types n Simple API for programmers to register new ADTs
situation: online query processing n HCI motivations n Example applications n Example Algorithms n Reordering and Ripple Joins Implications for “hot topics” n P2P query systems n Sensor nets n Stream Query Processing
At any time, the input to the query is a sample n Input grows over time Can pre-sort tables randomly n And start scans from random positions n Best I/O behavior n Can re-randomize incrementally in the background n Note: can do this as a “secondary index” Techniques for random sampling in DBs well studied n Both from files and from indexes n Some tricks here (e.g. acceptance-rejection sampling)
SQL: SELECT * WHERE RAND() <= 0.01 n Similar capability in SAS Bernoulli Sampling with pre-specified rate n Informix, Oracle 8i, (DB2) n Ex: SELECT * FROM T1 SAMPLE ROW(10%), T2 n Ex: SELECT * FROM T1 SAMPLE BLOCK(10%), T2 Not for novices n Need to pre-specify precision n no feedback/control n recall the “multiresolution” patterns from example n No estimators provided in current systems
Spreadsheet scrollbars n Pipeline quasi-sort Mechanisms: n Juggle [Raman2/Hellerstein, VLDB ‘99] n General purpose: works with streaming data, etc. n Index stride [Hellerstein/Haas/Wang, SIGMOD ‘97] n Needs index, high I/O cost, but good for outliers n Mix adaptively! [Raman/Hellerstein, ICDE ‘03]
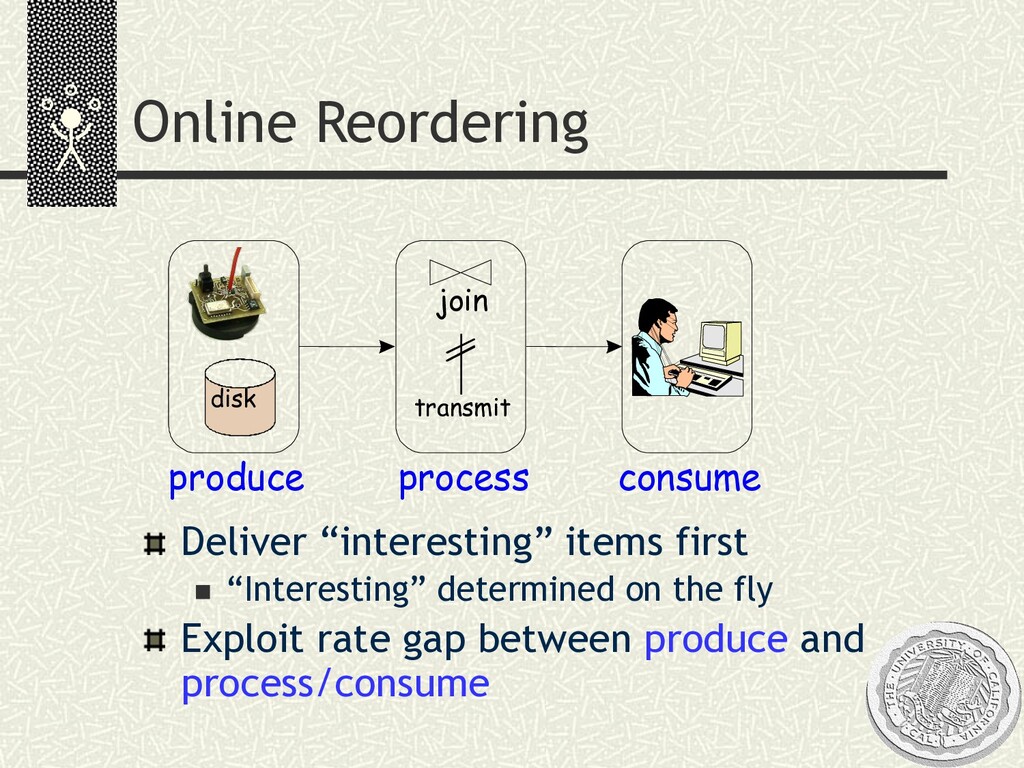
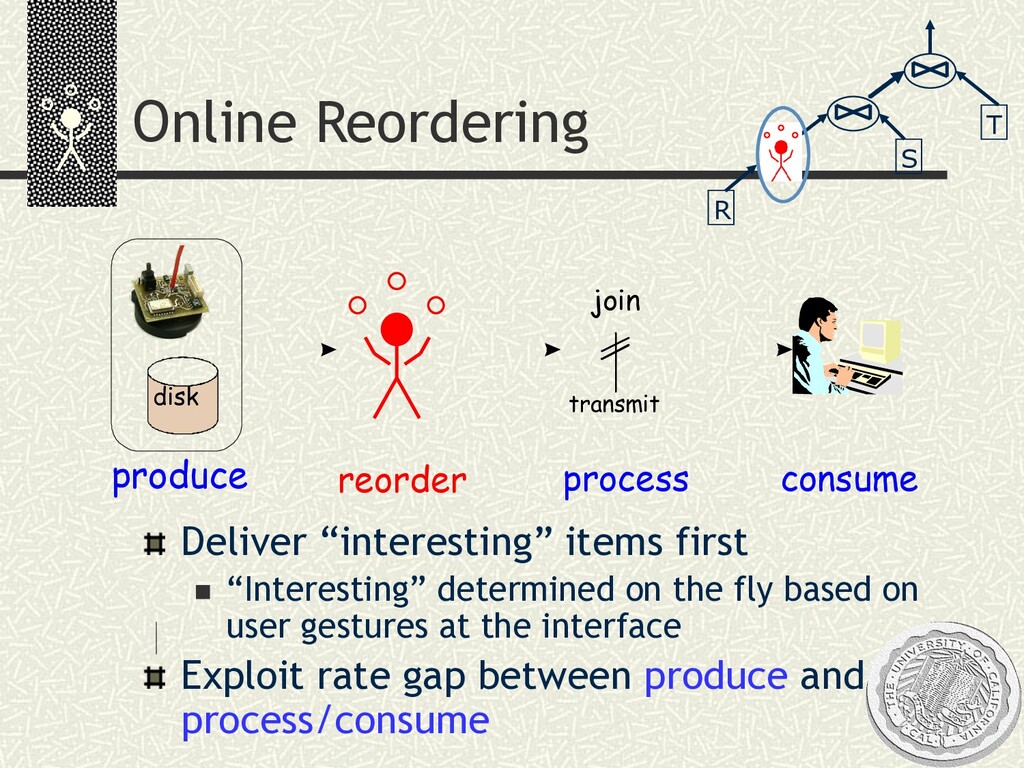
the fly based on user gestures at the interface Exploit rate gap between produce and process/consume S T R reorder process consume join transmit produce disk
tP1 …tPn Quality of Feedback for a prefix tP1 tP2 …tPk QoF(UP(tP1 ), UP(tP2 ), … UP(tPk )), UP = user preference n determined by application Goodness of reordering: dQoF/dt Delivery Priority (DP): n At any given time, try to deliver tuple that improves QoF most time QoF J
acts as weight on confidence interval n QOF = -Si UPi / (ni )1/2 n ni = number of tuples processed from group i n DPi = UPi / (ni )3/2 Metric: explicit proportional rates (NW QoS) n QOF = -Si (ni — nUPi )2 n where n = Si ni n DPi = nUPj — nj Explicit ranking (scrollbar) n QOF = -Si UPi n DPi = UPi
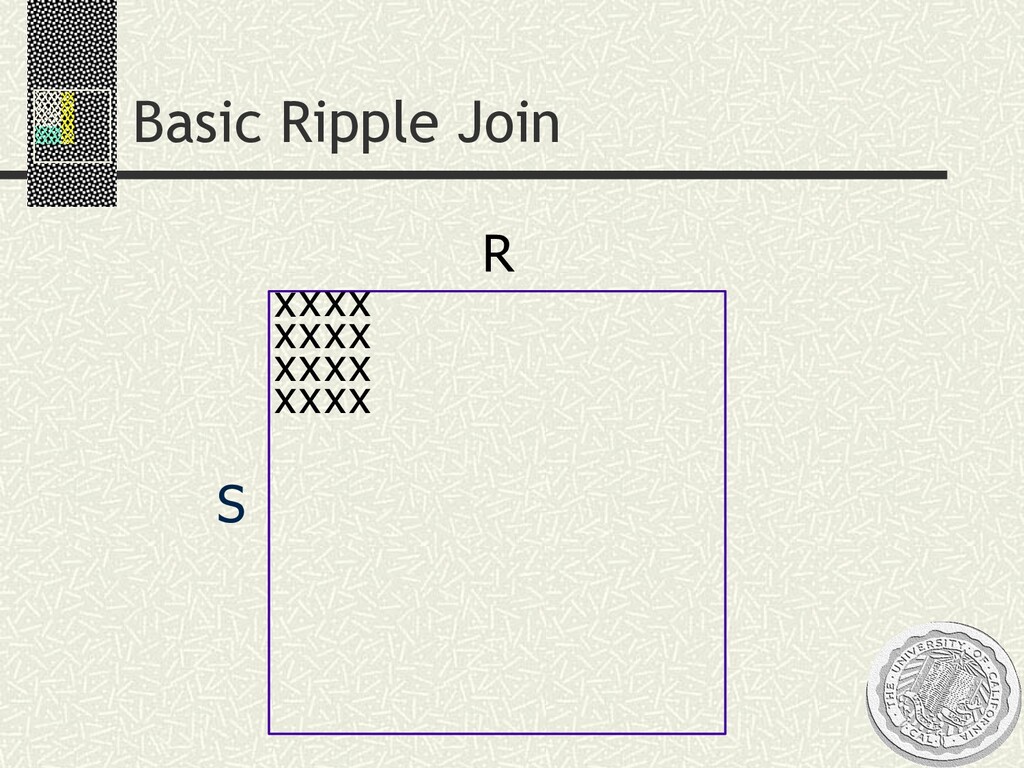
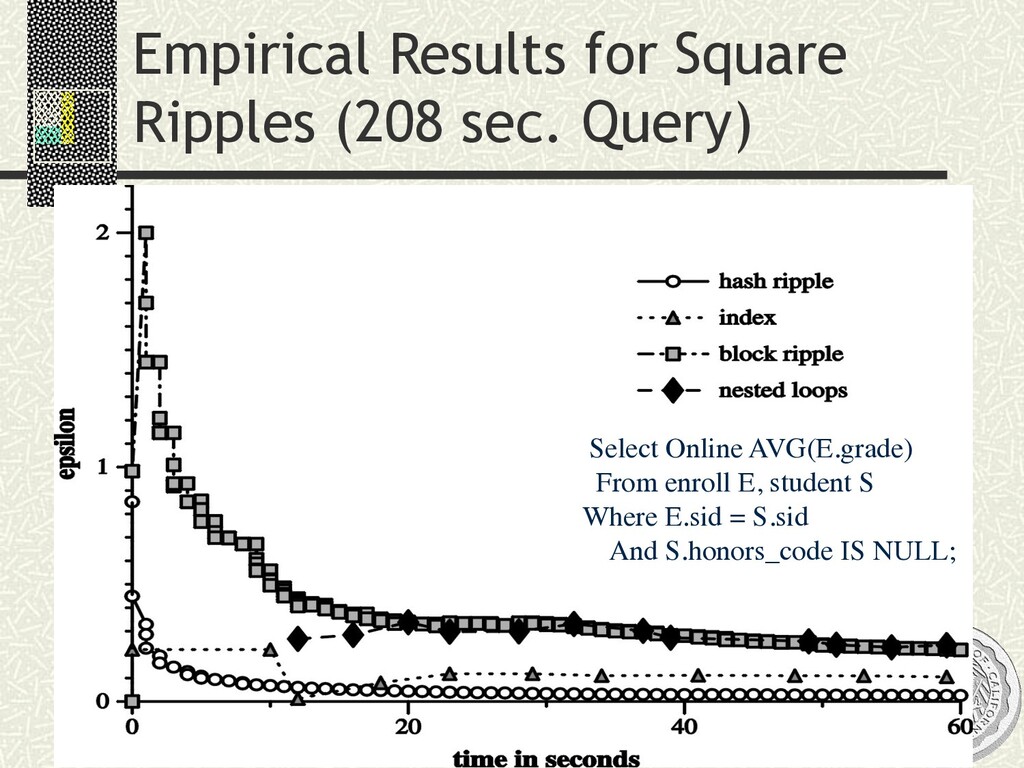
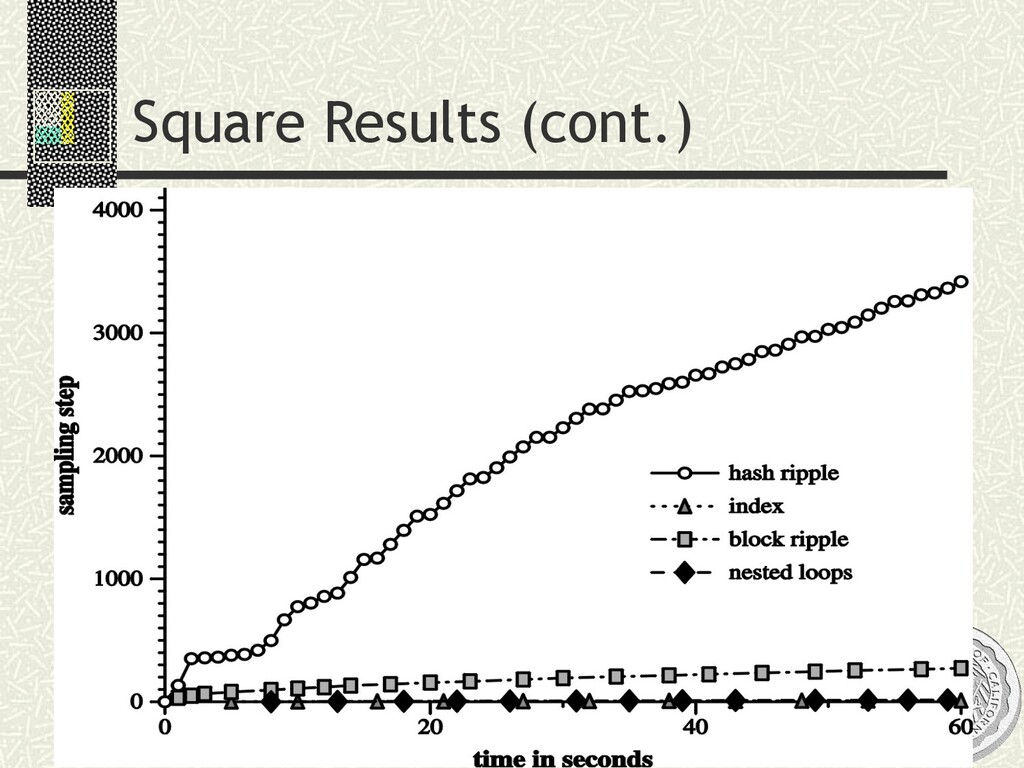
input n Statistically robust: estimates/CIs as you go SELECT AVG(R.a * S.b) FROM R, S WHERE R.c = S.c xxxx xxxx xxxx xxxx xxxx xxxx xx xx xx xx xx xx Ripple Joins [Haas/Hellerstein, SIGMOD ’99]
input n Statistically robust: estimates/CIs as you go SELECT AVG(R.a * S.b) FROM R, S WHERE R.c = S.c Solution space n Simple idea: sample a join xxxx xxxx xxxx xxxx xxxx xxxx xx xx xx xx xx xx Ripple Joins [Haas/Hellerstein, SIGMOD ’99] S R x x x x x x x x x x x x x x x x
input n Statistically robust: estimates/CIs as you go SELECT AVG(R.a * S.b) FROM R, S WHERE R.c = S.c Solution space n Simple idea: sample a join n Better: join samples xxxx xxxx xxxx xxxx xxxx xxxx xx xx xx xx xx xx Ripple Joins [Haas/Hellerstein, SIGMOD ’99] S R xxxx xxxx xx xxxxxx xx xx xx xx xxxxxxxx S R x x x x x x x x x x x x x x x x
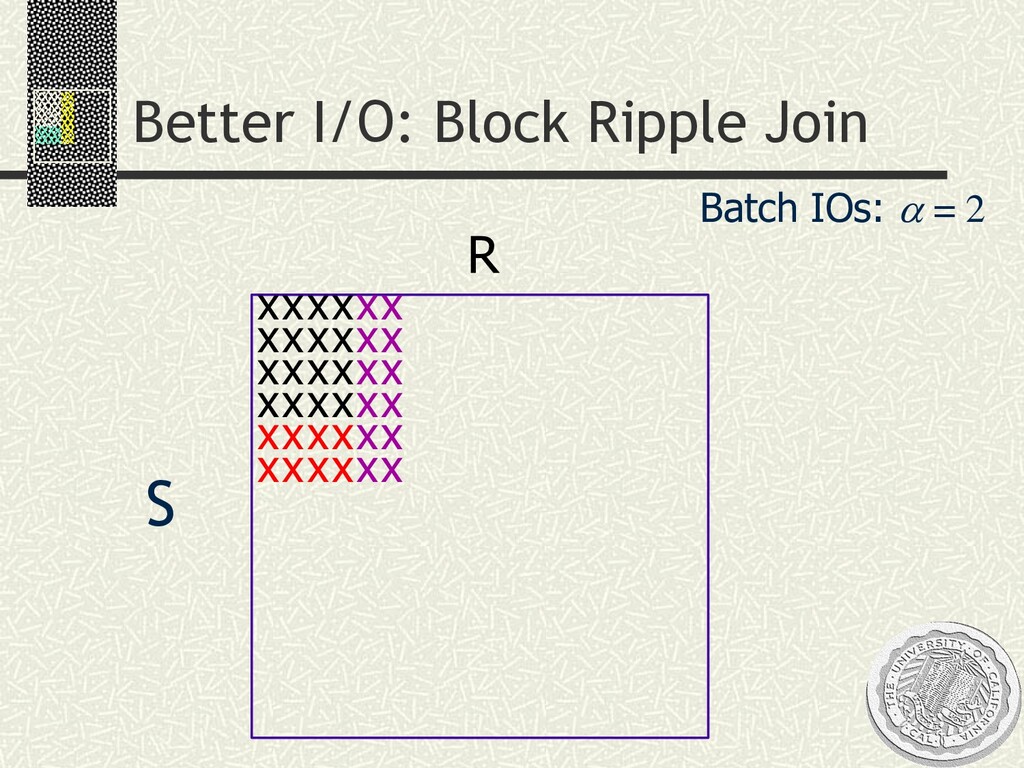
input n Statistically robust: estimates/CIs as you go SELECT AVG(R.a * S.b) FROM R, S WHERE R.c = S.c Solution space n Simple idea: sample a join n Better: join samples Ripple Joins n Family of algorithms for joining increasing samples n Optimized to shrink confidence intervals ASAP n Q: Which input to sample faster? “Aspect ratio” of ripples? n A: Adapt to estimator’s “variance contribution” from different inputs xxxx xxxx xxxx xxxx xxxx xxxx xx xx xx xx xx xx Ripple Joins [Haas/Hellerstein, SIGMOD ’99] S R xxxx xxxx xx xxxxxx xx xx xx xx xxxxxxxx S R x x x x x x x x x x x x x x x x
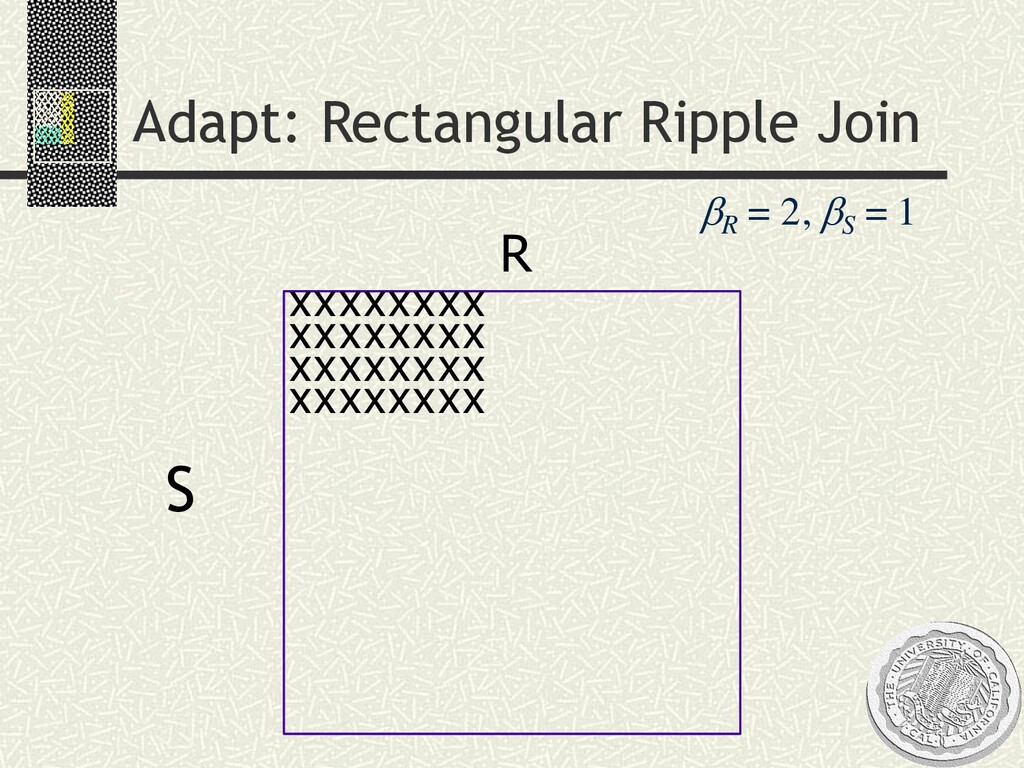
Block: minimizes I/O in alternating nested loops n Hash: symmetric hash tables to avoid scans n Index: basic index join Adaptive aspect ratio n User sets “frame rate” of animation at GUI n System goal: minibatch optimizations n minimize CI width subject to “frame-rate” time constraint n CI’s computable at corners, so a new frame each corner n Challenge: choose the next minibatch corner n Sample from higher variance-contributing relation faster n System solves linear programming problem to do this (approximately) xxxx xxxx xxxx xxxx xxxx xxxx xx xx xx xx xx xx
n Make it work in a re-entrant iterator model n RippleJoin.get_next() ? n Multi-join queries n “Corner” cases -- e.g. EOT on one input of k n Statistical matters n Estimators and CIs for joins of samples n Not textbook statistics! n The adaptivity issue: choosing the next corner n Based on cost (I/O model for algorithm) and benefit (CI formula) n Approximate a non-linear integer programming problem
“outer” roles switch back and forth n Note asymmetry in inner loops: “mitres” the box for (ever) { for (i = 1 to max -1) // S fixed, loop on R if (predicate(R[i], S[max])) output(R[i], S[max]); for (i = 1 to max) // R fixed, loop on S if (predicate(R[max], S[i])) output(R[max], S[i]); } x x x x x x x x x x x x x x x x x x x x x x x x x
iterators n get_next() must re-enter and generate next result tuple n state for square, 2-table ripple join: n cursors on both inputs (as in nested loops join) n target -- where’s the next “corner” n currel -- which relation is currently looping x x x x x x x x x x x x x x x x x x x x x x
“wrapping” 1 layer on each side n must pad side i with bi layers correctly Multiple joins = pipeline of binary joins n But can’t be done naively n “Wrapping” hypercubes not rectangles n Given subtree of size i, factor in b’s and a n Subtree’s hyperplane is: b1 b2 …bi ai tuples n Boundary conditions n Overload control messages: n EOT may mean end of sampling step, not end of table n Need to signal aggregator of arrival at corner (EOT on all tables) n Also, EOTable on a relation may change “mitre-ing” rules! S T R
after n sampling steps: n Unbiased, consistent n A scaled average -- hence amenable to CLT S (r,s) Î Rn x Sn expressionp(r,s) |Rn| |Sn| |R| |S| Running Estimators xxxx xxxx xxxx xxxx xxxx xxxx xx xx xx xx xx xx
steps: 1 << n << |R| n Based on Central Limit Theorem for averages of i.i.d. observations Complications for multiple tables n Estimator for AVG is a ratio of averages n expressionp (r, s) and expressionp (r, s’) are correlated! Solution: n CLT for (ratios of) cross-product averages n Based on theory of “convergence in distribution” n Courtesy Peter Haas, IBM n Also “conservative” CIs that can be used for very small n n Based on Hoeffding inequality n And deterministic CIs for the endgame xxxx xxxx xxxx xxxx xxxx xxxx xx xx xx xx xx xx
n zp is the area under the standard normal curve 0 ± p n n is the number of tuples so far n n d(k) is agg-fn dependent, computed on tuples of input n dn (k) a consistent estimator by applying d(k) to samples so far n a the block size, a constant n bi the number of blocks to fetch from relation i Tradeoff between update rate/CI shrinkage n Bigger b’s = smaller CIs, slower animation CI width = 2 r zp n1/2 r2 = S k = 1 K d(k) abk Large-Sample Confidence Intervals xxxx xxxx xxxx xxxx xxxx xxxx xx xx xx xx xx xx
= b1 b2 …bk aK-1nK + o(nK) Cost of hash ripple after n steps: n c = (b1 + b2 + … + bk )n Non-linear integer programming problem: minimize r2(b1 , b2 , …, bk , a) such that 1. c (b1 , b2 , …, bk , a) £ constant [animation speed] 2. 1 £ bk £ |Rk |/ a for 1 £ k £ K 3. b1 , b2 , …, bk integer = S k = 1 K d(k) abk Aspect Ratio Selection xxxx xxxx xxxx xxxx xxxx xxxx xx xx xx xx xx xx
b2 = … = bK = 1 2. Execute m sampling steps (m >= 1) 3. Update each d(k) estimate 4. Solve optimization problem to get new b’s 5. Sweep out new rectangle 6. Go to 2 Approximate optimization algorithm for b’s n First ignore all constraints, minimize r2 n Then scale up all so smallest bi ≥ 1 (constraint 2) n Scale down by ever-larger bi ’s until animation goal met (constraint 1) n Round down to integers (constraint 3) xxxx xxxx xxxx xxxx xxxx xxxx xx xx xx xx xx xx 1. c (b1 , b2 , …, bk , a) £ c 2. 1 £ bk £ |Rk |/ a 3. b1 , b2 , …, bk integer
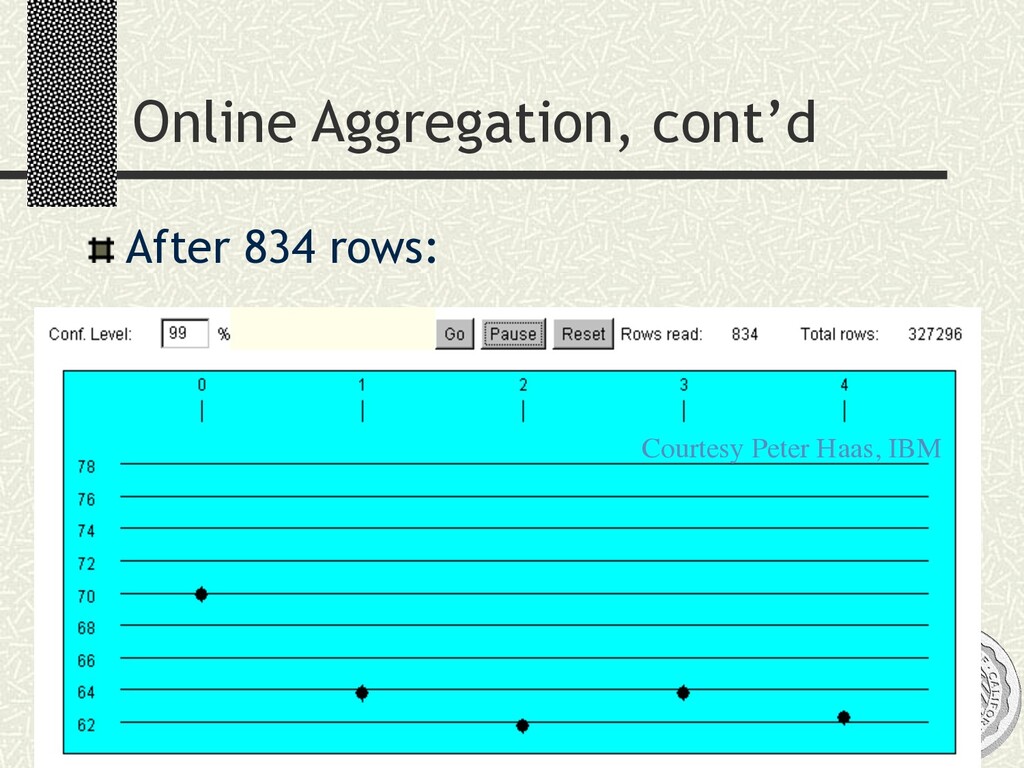
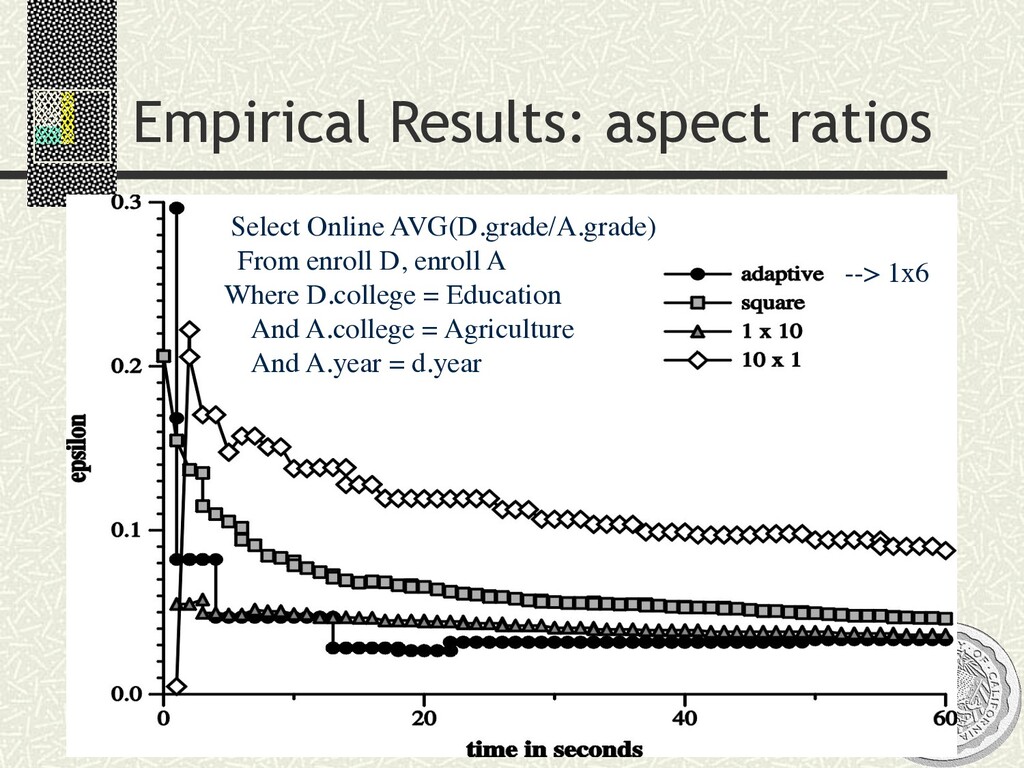
xx xx xx xx xx xx Select Online AVG(D.grade/A.grade) From enroll D, enroll A Where D.college = Education And A.college = Agriculture And A.year = d.year --> 1x6
work n Subqueries in Singapore [Tan, et al, VLDB 99] n Scaling at Wisconsin/IBM [Luo, et al, SIGMOD 02] n Parallel and out-of-core variants n Query optimization issues n Motivated eddies [SIGMOD 99] and the rest of the Telegraph project [CIDR 03] A number of API and other systems issues n Informix implementation [DMKD 2000] xxxx xxxx xxxx xxxx xxxx xxxx xx xx xx xx xx xx
situation: online query processing n HCI motivations n Example applications n Example Algorithms n Reordering and Ripple Joins Implications for “hot topics” n P2P query systems n Sensor nets n Stream Query Processing
nets (e.g. TinyDB) n Querying in P2P networks (e.g. PIER) Continuous queries over data streams n E.g. TelegraphCQ, Aurora, STREAM, NiagaraCQ Natural settings for these ideas!
Sets n E.g. disks, traces in P2P setting n E.g. the physical world in sensornets Constraint: Small pipes n P2P != cluster [IPTPS03] n Sensor nets have extremely limited comm per battery Will have long-running dataflow programs! So… n Need to provide streaming, approximate answers n Need to prioritize delivery a la juggle n Need to decide adaptively on how to sample physical world n “Acquisitional Query Processing” in TinyDB related to both Ripple Join and Juggle n Need to consider human factors while the query runs
Berkeley’s TelegraphCQ, OGI/Wisconsin’s NiagaraCQ, MIT/Brown/Brandeis’ Aurora, Stanford’s STREAM Again, natural setting for these ideas n Need pipelining operators for STREAMS n Interest in approximate answers during bursts n And prioritized delivery n Need to consider human factors! n DB community focused on the next query language n Also need to focus on interactivity! n Initiation of a Continuous Query is only half the battle
User needs drive systems design n For long-running, data-intensive apps especially Systems and statistics intertwine n Adaptive systems All 3 go together naturally n User desires and behavior: 2 more things to model, predict n “Performance” metrics need to reflect key user needs “What unlike things must meet and mate…” -- Art, Herman Melville
Association Rules n Ng, et al’s CAP, SIGMOD ’98 n Hidber’s CARMA, SIGMOD ‘99 Implications for deductive DB semantics n Monotone aggregation in LDL++, Zaniolo and Wang Online agg with subqueries n Tan, et al. VLDB ’99 Dynamic Pipeline Scheduling n Urhan/Franklin VLDB ’01 Pipelining Hash Joins n Su/Raschid, Wilschut/Apers, Tukwila, Xjoin n Relation to semi-naive evaluation Anytime Algorithms n Zilberstein, Russell, et al.
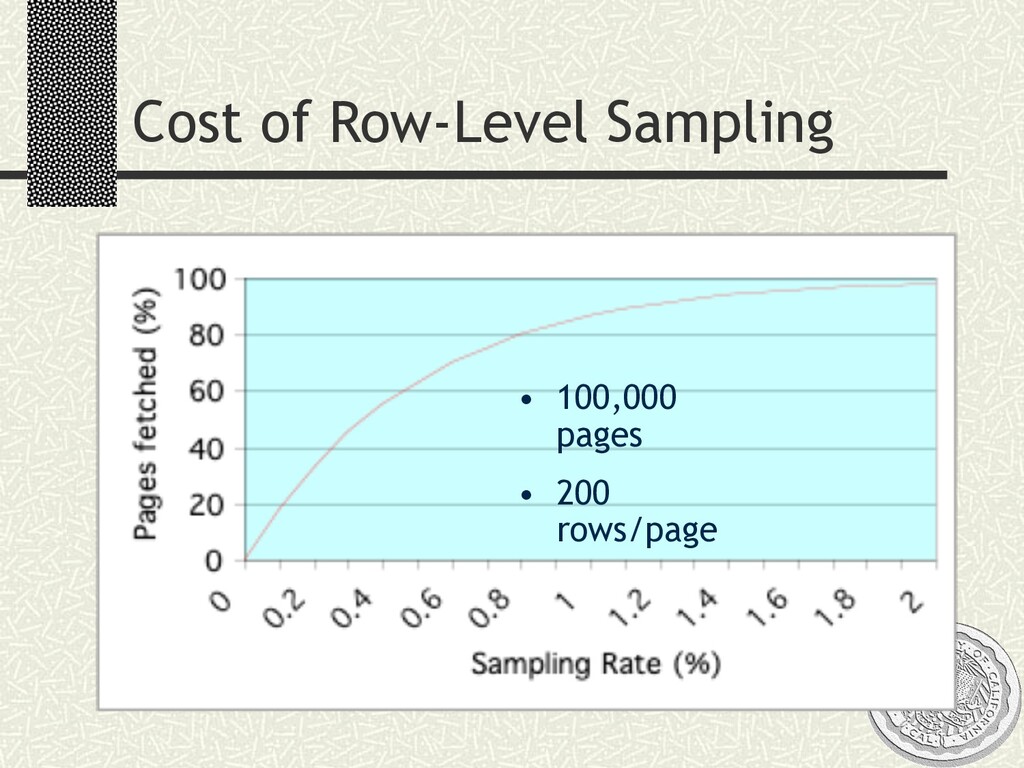
high I/O cost n Block-level (page-level): high variability from clustering Type of sample n Often simple random sample (SRS) n Especially for on-the-fly n With/without replacement usually not critical Data structure from which to sample n Files or relational tables n Indexes (B+ trees, etc)
= scan n Is file initially in random order? n Statistical tests needed: e.g., Runs test, Smirnov test n In DB systems: cluster via RAND function n Must “freshen” ordering (online reorg) On-the-fly sampling n Via index on “random” column n Else get random page, then row within page n Ex: extent-map sampling n Problem: variable number of records on page
ni /nMAX Commonly used in other settings n E.g. sampling from joins n E.g. sampling from indexes r r r r r r r r r r r r r r r r r r r r r r r r r r r r r r r r r r r r r r r r r Original pages Modified pages
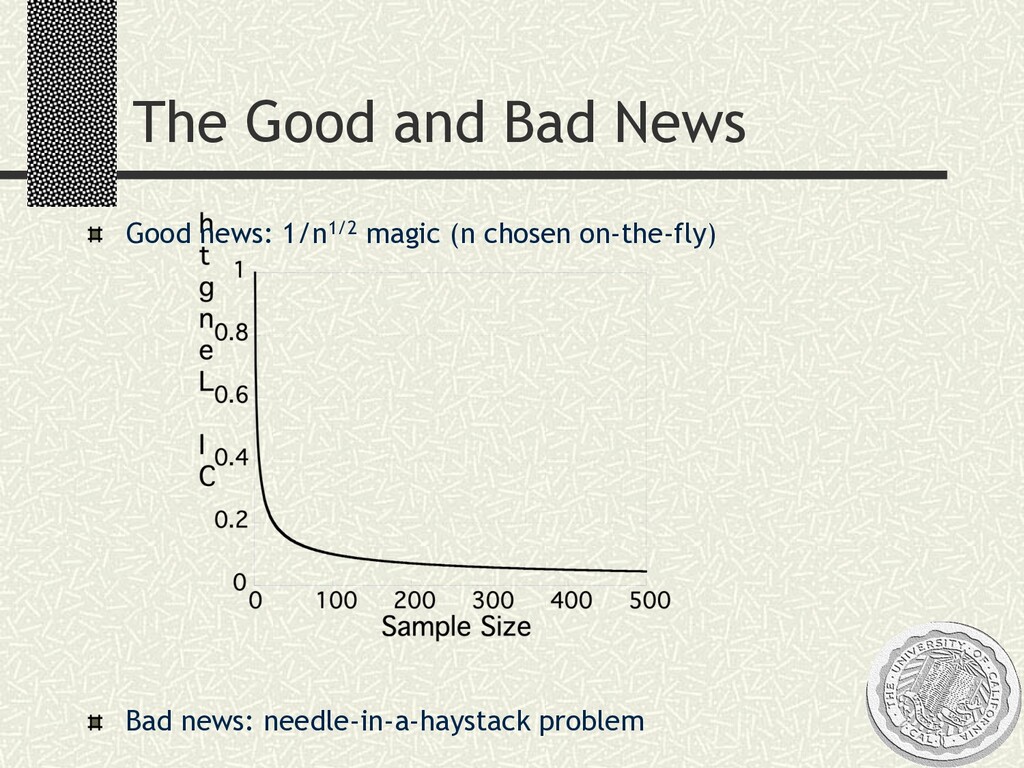
a precision parameter єn such that running aggregate Yn is within ± єn of the final answer µ with probability approximately equal to p. [Yn- єn ,Yn+ єn ] contains µ with probability approximately equal to p
retrieved records: n Conservative confidence intervals based on Hoeffding’s inequality or recent extention of this inequality, for all n>=1 n Large-sample confidence intervals based on central limit theorems (CLT’s), for n both small and large enough n Deterministic confidence intervals contain µ with probability 1, only for very large n
£ i £ m): the value of exp when applied to tuple i Li: the random index of the ith tuple retrieved from R a and b are a priori bounds a £ v(i) £ b for 1 £ i £ m Conservative confidence interval equations:
limit theorems (CLT’s) , Yn approaches a normal distribution with a mean (µ) and a variance s2/n as n, the sample size, increases. s2 can be replaced by the estimator Tn,2 (v)
we want to optimize bk ’s – the aspect- ratio parameters minimize such that b1 b2 b3 ...bK aK-1£c (decided by animation speed) 1 £ bk £ mk / a for 1 £ k £ K b1 ,b2 ,b3 ,...bK interger
HOLAP Semantic hierarchies n APPROXIMATE (Vrbsky, et al.) n Query Relaxation, e.g. CoBase n Multiresolution Data Models (Silberschatz/Reed/Fussell) More general materialized views n See Gupta/Mumick’s text
flavors n Extended to enumeration queries recently n Multi-dimensional histograms Parametric estimation n Wavelets and Fractals n Discrete cosine transform n Regression n Curve fitting and splines n Singular-Value Decomposition (aka LSI, PCA) Indexes: hierarchical histograms n Ranking and pseudo-ranking n Aoki’s use of GiSTs as estimators for ADTs Data Mining n Clustering, classification, other multidimensional models
Chaudhuri et al.: join samples n Statistical inferences complicated over “recycled” samples? Barbará’s quasi-cubes AQUA “join synopses” on universal relation Maintenance issues n AQUA’s backing samples Can use fancier/more efficient sampling techniques n Stratified sampling or AQUA’s “congressional” samples Haas and Swami AFV statistics n Combine precomputed “outliers” with on-the-fly samples
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
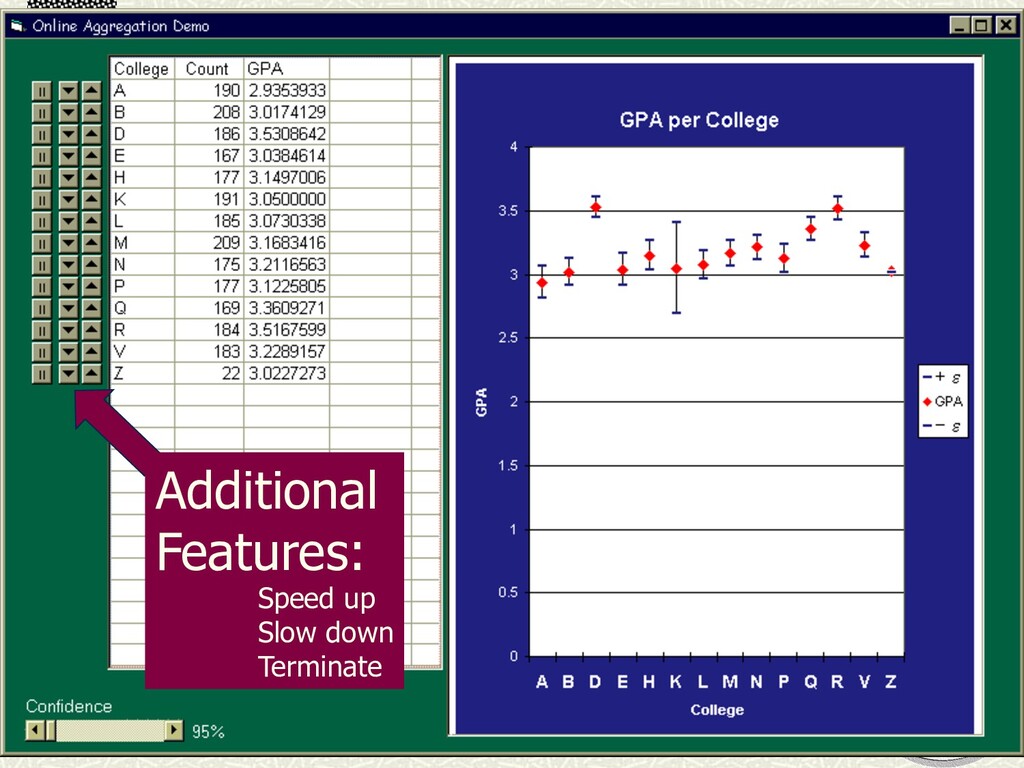
![Online Browsing & Editing Potter’s Wheel [VLDB 2001] Scalable spreadsheet](https://files.speakerdeck.com/presentations/fc6ffdaddac04dca82a58c16c13fc152/slide_18.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}