Using Automatic Word Alignment and Measures of Distributional Similarity Lonneke van der Plas & Jorg Tiedemann Alfa-Informatica University of Groningen Proceedings of the COLING/ACL 2006 Main Conference Poster Sessions, pages 866-873, Sydney, July 2006.
related words. – Not able to distinguish between synonym and other types of semantically related words. • This paper present a method based on automatic word alignment of parallel corpora • Results shows higher precision and recall scores than the monolingual syntax-based approach.
speak of synonyms. • they define context in multilingual setting. – Translate a word into other languages – Assume that word share translation context are semantically related – Measure using distributional similarity • They use both monolingual syntax-based and multilingual alignment-based
to acquire semantically similar words • Similar words are used in similar contexts. The contexts a given word are used as the feature in the vector called context vectors • Van der Plas and Boma (2002) present similar experiment for Ductch by Pointwise Mutual Information and Dice
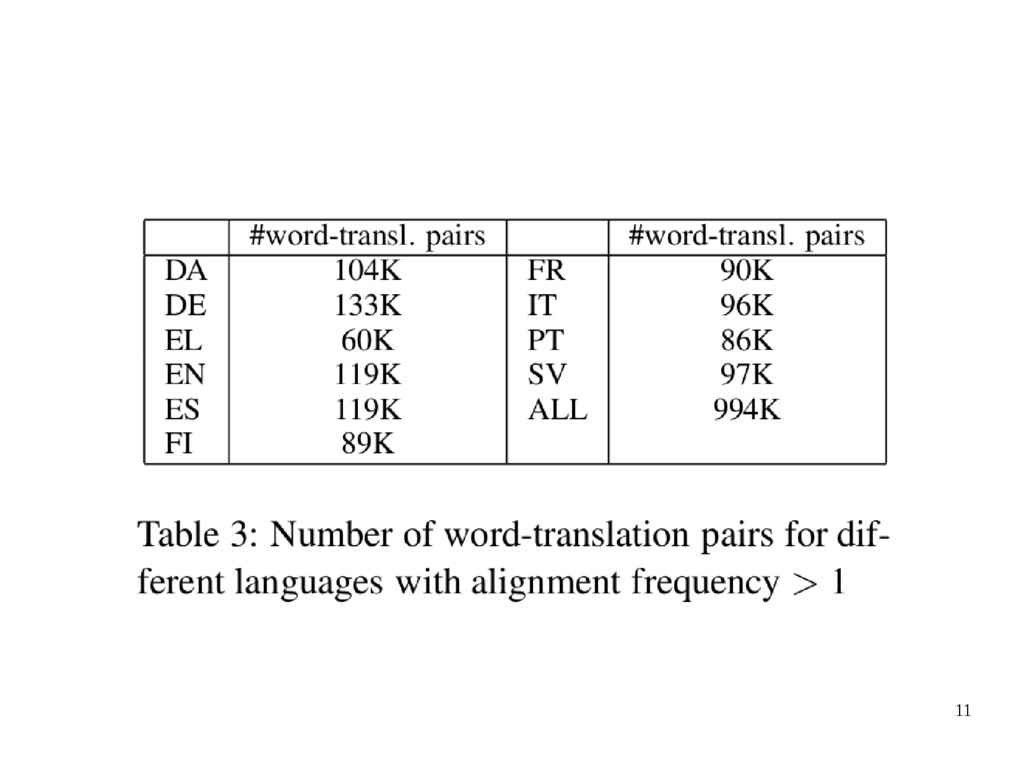
– Facilite eluation based on comparing their results to existing synonym databases • They applied GIZA++ and intersection heuristics • From word aligned corpora they extracted word type links, pairs of source and target words with their alignment frequency.
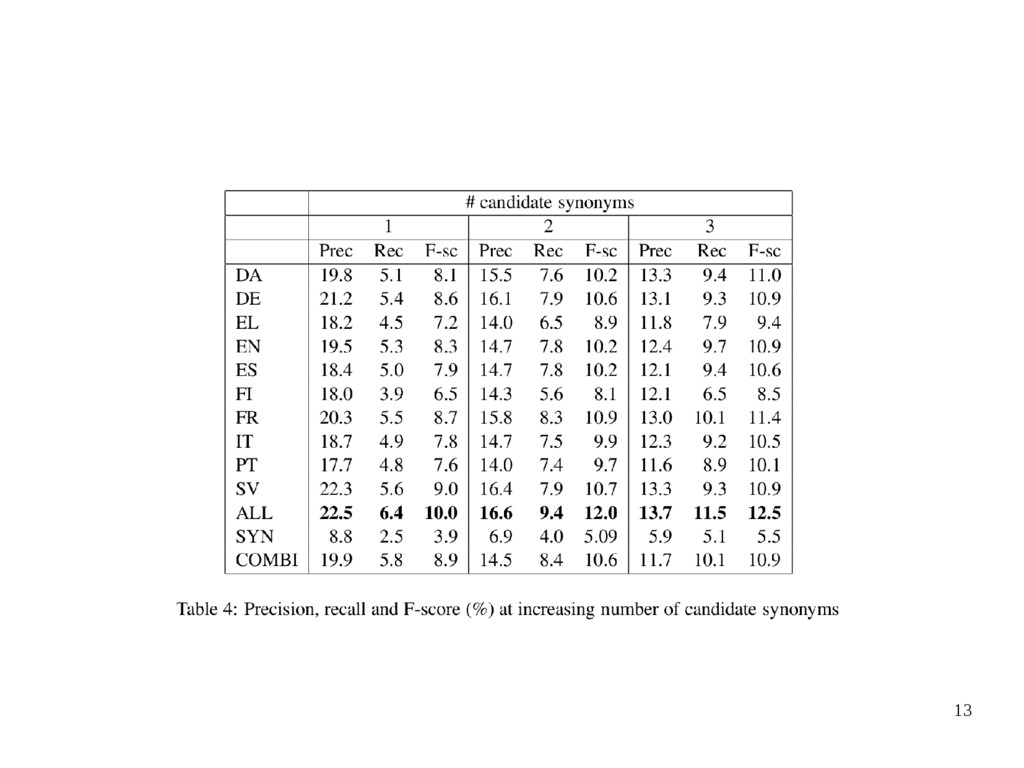
Dutch EuroWordnet (EWN, Vossen(1998)) – Extract all synsets in EWN 1000 words with a frequency above 4 • Precision is the percentage of candidate synonyms are truly synonyms • Recall is the percentage of the synonyms according to EWN
– Feature vectors are constructed from syntactically parsed monolingual corpora. – Used data: Dutch CLEE QA corpus which consists of 78 million words of Dutch – Use several grammatical relations: subject, object, adjective, coordination, apposition, prepositional complement
– Context vectors are built from the alignments found in a parallel corpus. – Used data: Use Europarl corpus (Koehn, 2003) includes 11 languages parallel. Dutch includes 29 million tokens in about 1.2 million sentences
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}