transfer methods and interlingual methods has the following problems: • it is hard (or impossible) to create rules or maintain them as the size of the rules increases. • there are so many exceptions that make difficult to write some phenomena as rules.
is to do that by human. • until the late 1990s all of evaluation is done by human. Evaluation items include: • readability : a degree of expression • informativeness : a degree of contents However, it is expensive and time consuming to conduct evaluations so many times, where we have to do them in research & development phase.
are proposed recently (2002), that compute similarity between the output and the previously-stored answer(s). BLEU (BiLingual Evaluation Understudy) • compares translation output with (one or multiple) reference(s) using a modified form of precision. • reported that it correlates well with human judgement. • it is also criticized as well.
translation – is a new translation method proposed in early 1990s. – replaces words in the source language into the corresponding words in the target language, and – reorder them by using statistics of likelihood. • It is a kind of direct translation method.
of Shannon's noisy channel model. • Idea: a sentence S in the source language goes through a noisy channel, that is observed as a sentence T in the target language. • At this time, the task is to infer S from the observed T. SMT consists of two modules: translation model and language model.
use of computer power. • enables full use of corpus. Disadvantages • lots of computation are required. • performance depends on size of corpus; large amount of parallel corpus is required for better performance. • everything is done by statistics, that makes difficult to improve performance other than increasing corpus.
conducted an experiment to recover word English word order given words in a sentence. • The results show that 63% can be recovered correctly, and 84% can be understood. But what about the other language such as Japanese?
word-to-word correspondences. • In some cases word-to-phrase or phrase-to-phrase correspondences are required instead. • Moreover, none-to-word alignment may be necessary. – 中学生 vs. junior high school student – particle は
better; huge parallel corpus that aligns word- to-word is necessary. • Current model uses n-gram statistics for language model that enables to recover only local information. • Major behaviors get priority, while minor behaviors are difficult to be translated correctly. • Difficult to implement humans wisdom into the engine. Some researchers are skeptical for statistical MT since it has many problems to solve. But it is paid more attentions as time goes.
by Professor Nagao of Kyoto University in 1984. • Imagine how do human translates a sentence? Do we use some rules for translation? Statistics? Anything else? • The basic idea for example-based machine translation is that when we translate a sentence, we get somewhat similar sentences out of the memory (=brain), and modify them to adopt the given sentence.
the similar process as explained in the next slides: • segments an input expression into several short phrases, • looks for similar phrases for each phrases, and • transforms and combines phrases according to the similar phrases.
「下午可能会下雨」 Instances • 明年可能会去北京/来年は北京に行くかもしれません • 下午/午後 • 下雨/雨が降る Even though we don't understand Chinese, we can translate the input sentence by the following procedures; (1) choosing the first instance 「来年は北京に行くかもしれません」 (2) replacing the words in red into the corresponding translation, again by using instances. 「午後は雨が降るかもしれません」
of X' (京都のツアー、講演の日付、...) Y' in X' (京都の会議、...) Y' on X' (電話の会議、...) Y' for X' (ホテルの登録、...) Although there are many translations of "の", it can be translated correctly if we imitate the translation of the input, i.e., "東京の会議". In this case "京都の会議" is chosen as most similar instance and it is translated to "meeting IN Tokyo".
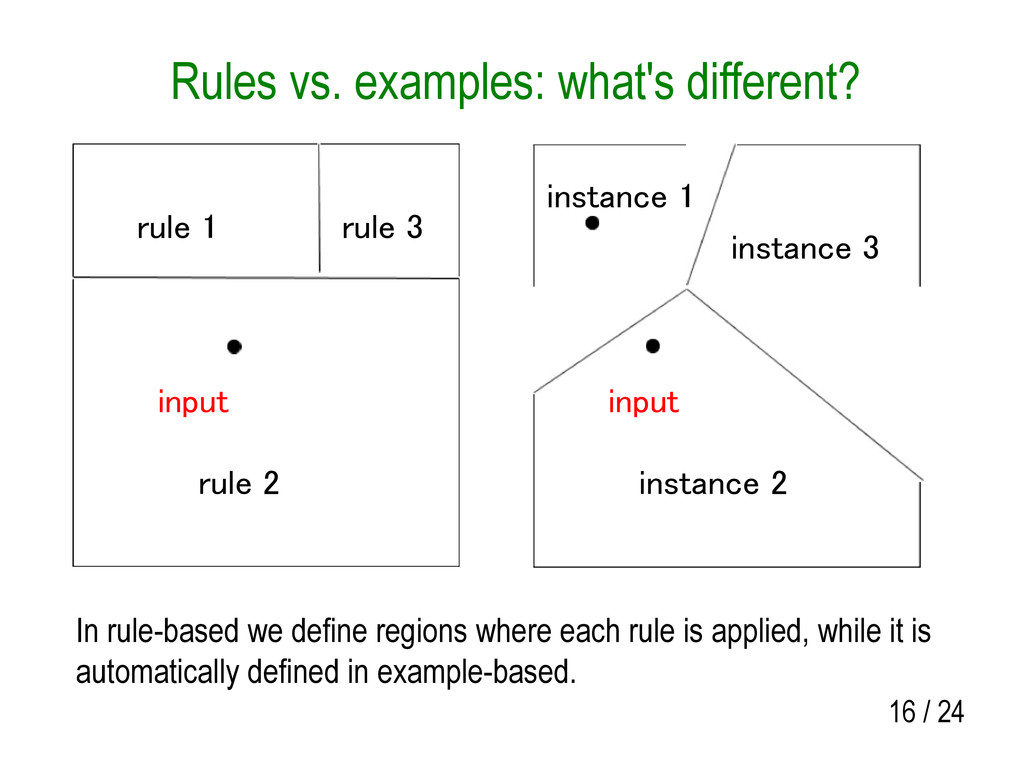
rule 1 rule 3 instance 2 instance 3 instance 1 input input In rule-based we define regions where each rule is applied, while it is automatically defined in example-based.
• Instances: – How many examples should be provided? • thesaurus: – What type of thesaurus is good? – How do you manage if unknown words are given? • essential question: – Can we translate it only by similarity?
and outputs speech in a different language. • Several laboratories in Japan, including NICT, NEC, Panasonic, and university such as NAIST are working for this.
are necessary to achieve speech translation: • speech recognition – speech is given, its description is produced. • machine translation – language is converted into different one. • speech synthesis – the translation is spoken. However, it is not enough if we simply pipeline them.
most difficult task among the three processes in speech translation. • It also requires processing time. Suppose that the speech sound has some noise, determining words in speech recognition basically requires language processing before that. Human considers situation, language knowledge, facial expression, prosody, and so on, to disambiguate speech into words, but current speech recognizers never use such information at all.
for translating spoken language, that tends to be shorter in input, but highly requires context. • Realtime processing is required. No one can wait for 10 seconds at communication situation. • It allows no give up in translation. • It also allows no pre-editing and no post-editing, that is a big difference to automatic document translation.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}