Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
濃縮還元型文要約モデルの検討
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
自然言語処理研究室
July 31, 2006
Research
59
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
濃縮還元型文要約モデルの検討
池田 諭史, 牧野 恵, 山本 和英. 濃縮還元型文要約モデルの検討. 情報処理学会 研究報告, NL174-13 (2006.7)
自然言語処理研究室
July 31, 2006
More Decks by 自然言語処理研究室
See All by 自然言語処理研究室
データサイエンス14_システム.pdf
jnlp
0
420
データサイエンス13_解析.pdf
jnlp
0
530
データサイエンス12_分類.pdf
jnlp
0
370
データサイエンス11_前処理.pdf
jnlp
0
500
Recurrent neural network based language model
jnlp
0
170
自然言語処理研究室 研究概要(2012年)
jnlp
0
160
自然言語処理研究室 研究概要(2013年)
jnlp
0
130
自然言語処理研究室 研究概要(2014年)
jnlp
0
150
自然言語処理研究室 研究概要(2015年)
jnlp
0
230
Other Decks in Research
See All in Research
Using our influence and power for patient safety
helenbevan
0
370
適応的スパムフィルタのための軽量な類似メッセージカウンタ / jsai2026-adaptive-spam-filter
monochromegane
0
4.2k
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
shunk031
4
1.1k
ScoreMatchingRiesz for Automatic Debiased Machine Learning and Policy Path Estimation with an Application to Japanese Monetary Policy Evaluation
masakat0
0
300
計算情報学研究室 (数理情報学第7研究室)2026
tomohirokoana
0
620
Research Engineerという仕事 / Research Engineering: Bridging Research and Business
chck
1
230
はじまりの クエスチョンブック —余暇と豊かさにあふれた社会とは?
culturaltransition
PRO
0
550
JICA QUEST 共創×革新プログラム Impact Report(海ノ向こうコーヒー)
ontheslope
0
160
Ghost in the 7‑Zip: The Shadow of Residential Proxies Creeping into Your Life
nttcom
0
1.5k
Sequences of Logits Reveal the Low Rank Structure of Language Models
sansantech
PRO
1
280
【中間報告】国会議員の立法・政策実務を支える環境を巡る現状と課題
polipoli
0
290
正規分布と最適化について
koide3
1
300
Featured
See All Featured
Exploring anti-patterns in Rails
aemeredith
3
440
VelocityConf: Rendering Performance Case Studies
addyosmani
333
25k
Leveraging LLMs for student feedback in introductory data science courses - posit::conf(2025)
minecr
1
310
Game over? The fight for quality and originality in the time of robots
wayneb77
1
220
実際に使うSQLの書き方 徹底解説 / pgcon21j-tutorial
soudai
PRO
201
75k
The Psychology of Web Performance [Beyond Tellerrand 2023]
tammyeverts
49
3.5k
Templates, Plugins, & Blocks: Oh My! Creating the theme that thinks of everything
marktimemedia
31
2.8k
How to train your dragon (web standard)
notwaldorf
97
6.7k
Exploring the relationship between traditional SERPs and Gen AI search
raygrieselhuber
PRO
2
4.1k
個人開発の失敗を避けるイケてる考え方 / tips for indie hackers
panda_program
123
22k
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
450
Agile Actions for Facilitating Distributed Teams - ADO2019
mkilby
0
220
Transcript
濃縮還元型文要約モデルの検討 池田諭史 牧野恵 山本和英 長岡技術科学大学 電気系 2006.7.28
背景 現在の文単位での要約 文より不要部の削除を行う 冗長部の削除 文の必要な部分を取り出し並べる 重要部分の抽出 人のように、より自然な要約文を作成したい ・・・イラクで行方不明になっていた
になっていた民間人ら・・・ ・・・イラクで行方不明の の民間人ら・・・
目的 人間が文要約を行う際 原文からの必要な単語の抽出 抽出した単語の並び換え 単語からの文の生成 上記の手順で行うことがある 自動要約でも同様の手法で行えないか
単語の抽出(濃縮) 単語群からの文の生成(還元)
提案手法(濃縮還元型要約) 人手で要約する際の手法を取り入れて要約 を行う 単語抽出部(濃縮) 原文から必要な単語を抽出する 抽出にはSVMを使用 文生成部(還元)
抽出した単語より要約文を生成 生成は機能語を補完することで行う
単語群の並べ替えについて 本来は文生成する前に単語の順を決定す る必要がある これを行うことにより、現在の自動要約手法で は出ないような原文に無い表現が作成可能に 本研究では問題の簡単化のために原文で の出現順で生成を行う
関連研究 文生成の先行研究 内元ら(2002) {国,政策,発足}のような3単語からの文の生成 池田ら(2006) 要約文で使われた単語を用いて、同じ意味の 文を生成 {安全,検査,簡素,化,する,方向,検討,する}
安全検査を簡素化する方向で検討する。
単語抽出部(1/2) 文を生成するのに必要な単語とは 人が文意を取るためには内容語が必要 速読する際に、内容語のみを読むことがある 要約文では形容詞、副詞は省略が多い 修飾節は省かれやすい 本研究における文生成に必要な単語
名詞 動詞
単語抽出部(2/2) SVMによる単語抽出 要約対を用意する 要約文に存在する原文の単語を正例 要約文に存在しない原文の単語を負例 素性 対象単語と前後各2単語の表層と品詞 TF(Term
Frequency) IDF(Inverse Document Frequency) カーネル 線形カーネル
文生成部(1/4) 単語群から文を生成する 生成は機能語を補完することで行う 文生成部の流れ 補完候補の出力 機能語の決定
文生成部(2/4) 補完候補の出力 補完候補の出力にはコーパスを用いる 「政府+(機能語)+要請」で出現する機能語 「政府要請」という形で出現する場合は ε (補完し ない)を補完候補に
補完候補がない場合は「政府+(機能語)」で探す {政府,要請,受ける}
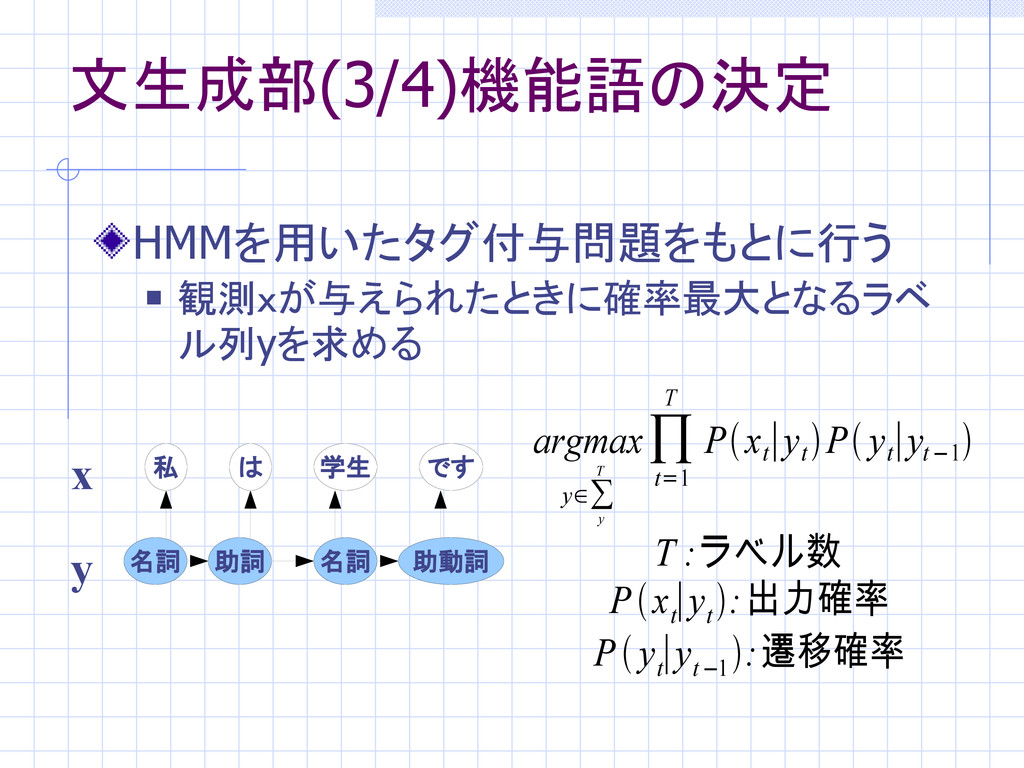
文生成部(3/4)機能語の決定 HMMを用いたタグ付与問題をもとに行う 観測xが与えられたときに確率最大となるラベ ル列yを求める 私 は 学生 です 名詞
助詞 名詞 助動詞 y x argmax y∈∑ y T ∏ t=1 T Px t ∣y t P y t ∣y t−1 T :ラベル数 Px t ∣y t :出力確率 P y t ∣y t−1 :遷移確率
文生成部(4/4)機能語の決定 HMMのタグ付与問題の 観測xを抽出した単語群とする ラベル列yを補完する機能語列 私 学生 y x
は です argmax y∈∑ y T ∏ t=1 T P y t ∣x t Px t1 ∣y t Py t ∣y t−1 T :ラベル数 P y t ∣x t :前方の連接確率 Px t1 ∣y t :後方の連接確率 P y t ∣y t−1 :遷移確率
評価実験 要約対 原文:NIKKEI NETのWebニュース記事 要約文:Nikkei-gooのメールサービスの記事 記事対応をとり、1文目を要約対とした
3300要約対 33分割の交差検定 連接確率及び補完候補の出力 日経新聞2000年度版
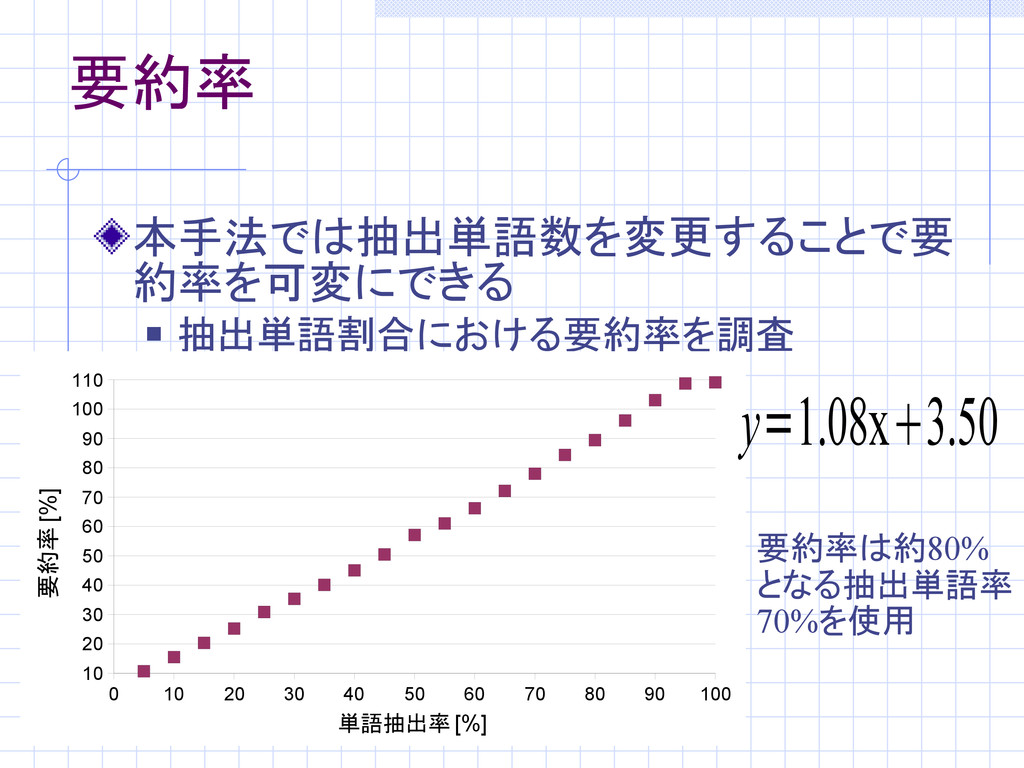
要約率 本手法では抽出単語数を変更することで要 約率を可変にできる 抽出単語割合における要約率を調査 要約率は約80% となる抽出単語率 70%を使用 0 10
20 30 40 50 60 70 80 90 100 10 20 30 40 50 60 70 80 90 100 110 単語抽出率 [%] 要約率 [%] y=1.08x3.50
人手による評価 100文を3人の被験者が独立に評価 人による揺れが大きい 約5割の文に対して意味が変わっているの で単語の抽出精度の向上が必要 正解とした評価者数 ≧1 ≧2 =3 可読性の評価
80% 36% 10% 意味同一性の評価 78% 45% 13%
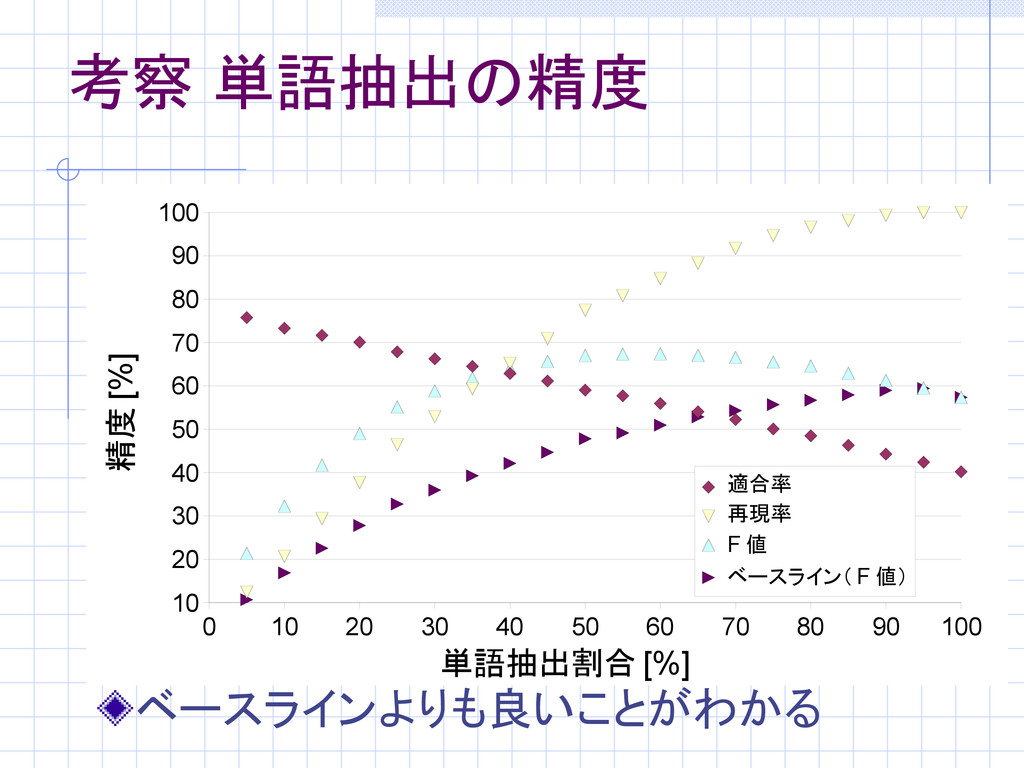
考察 単語抽出の精度 ベースラインよりも良いことがわかる 0 10 20 30 40 50 60
70 80 90 100 10 20 30 40 50 60 70 80 90 100 適合率 再現率 F 値 ベースライン( F 値) 単語抽出割合 [%] 精度 [%]
考察 人手で文生成 抽出した単語群を人手で文生成した 各被験者が文生成不可能とした文が約4割 単語抽出部の精度向上が必要 被験者 A B 文生成可能
意味同一性の評価 59文(/100文) 65文(/100文) 40文(/59文) 38文(/65文)
考察 人手で文生成不可能な例 「増やしする」→「増やす」で正解 本手法では出現形で動詞を使っているが活 用も考慮する必要がある 「する」をサ変名詞や前の単語とつなげて1つ の動詞とする A社は14日、1株当たりの年間配当金を15セント増やし、 同55セントにすると発表した。 ↓
{A社,14日,1株,当たり,年間,配当金,増やし,する,発表,し} ↓ A社は14日1株当たりの年間の配当金を 増やしすると発表した。
考察 「する」について 「(サ変名詞)+する」の「する」のみが単語抽 出部で抽出される 日本語が作れない 本手法でサ変名詞と「する」を分けて使った のは のような要約も考慮したためである。 「する」については特別な処理が必要である A社は14日、同業のB社を買収することで合意した。 ↓
A社は14日、B社の買収で合意した。
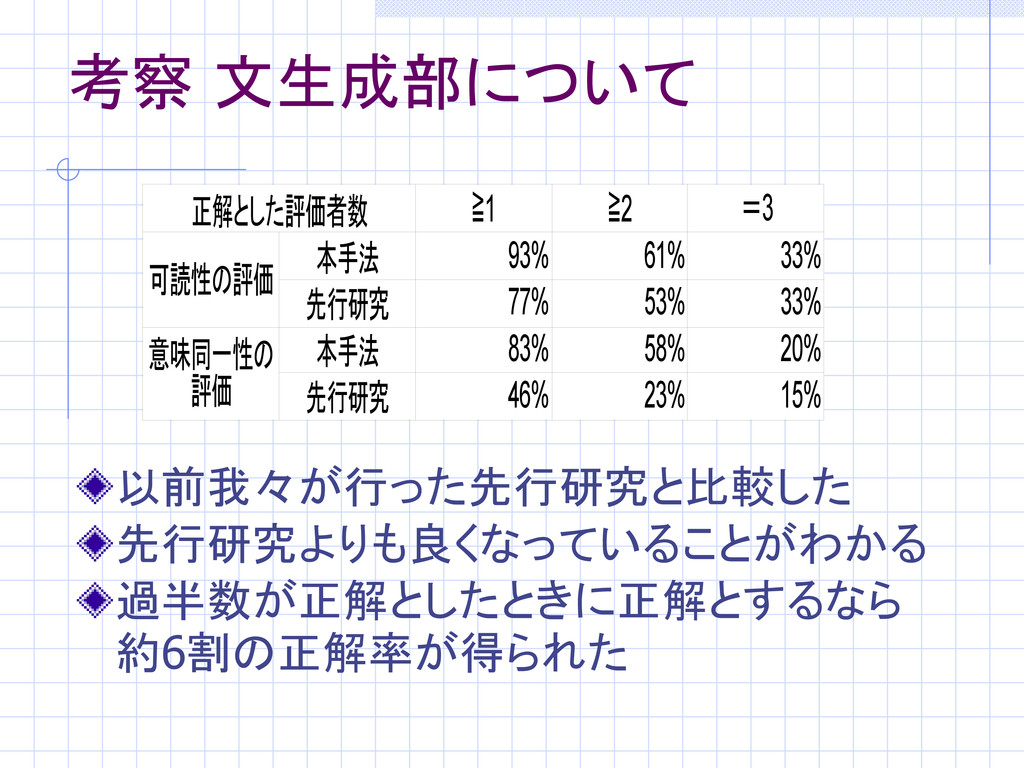
考察 文生成部について 以前我々が行った先行研究と比較した 先行研究よりも良くなっていることがわかる 過半数が正解としたときに正解とするなら 約6割の正解率が得られた 正解とした評価者数 1 ≧ 2
≧ 可読性の評価 本手法 93% 61% 33% 先行研究 77% 53% 33% 本手法 83% 58% 20% 先行研究 46% 23% 15% =3 意味同一性の 評価
考察 文生成時における単語数 単語数が増加すると 精度が下がる傾向がある 2-gramしか考慮していないため 大局的に間違った文でもスコアの低下が ない(助詞「の」の連続等) 人手だと精度が上がる傾向がある
単語群より得られる情報が多い 大局的に考えて生成が可能 本手法は単語数が少ない方が精度が良い
今後の課題 単語抽出部での「する」の処理 文生成部での大局的なスコアの導入 単語抽出後の単語の順序入れ替え 単語抽出部、文生成部相互に関係するよう なモデルの作成
まとめ 原文より単語を抜き出し、その単語から文 を生成することで要約するモデル(濃縮還元 モデル)の検討を行った。 目標とした要約文が生成された。 英下院で15日、イングランドとウェールズでの猟犬を使った キツネ狩りを禁止する法案が賛成多数で可決した。 ↓ 猟犬を使ったキツネ狩りを禁止する法案を可決した。
おわり
以下質疑応答用の説明スライド
先行研究との比較 堀ら(2002)との比較を行った 意味的な評価は本手法の方が優れている ROUGE-1 ROUGE-2 人手の評価 可読性 意味 本手法 0.62
0.43 36% 45% 先行研究 0.71 0.52 53% 21%
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}