Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
統計的機械翻訳における地名の汎化の影響
Search
自然言語処理研究室
March 31, 2009
Research
190
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
統計的機械翻訳における地名の汎化の影響
関 拓也, 山本 和英. 統計的機械翻訳における地名の汎化の影響. 言語処理学会第15回年次大会, pp.200-203 (2009.3)
自然言語処理研究室
March 31, 2009
More Decks by 自然言語処理研究室
See All by 自然言語処理研究室
データサイエンス14_システム.pdf
jnlp
0
410
データサイエンス13_解析.pdf
jnlp
0
530
データサイエンス12_分類.pdf
jnlp
0
370
データサイエンス11_前処理.pdf
jnlp
0
500
Recurrent neural network based language model
jnlp
0
170
自然言語処理研究室 研究概要(2012年)
jnlp
0
160
自然言語処理研究室 研究概要(2013年)
jnlp
0
130
自然言語処理研究室 研究概要(2014年)
jnlp
0
150
自然言語処理研究室 研究概要(2015年)
jnlp
0
230
Other Decks in Research
See All in Research
Φ-Sat-2のAutoEncoderによる情報圧縮系論文
satai
4
790
非試合日の野球場を楽しむためのARホームランボールキャッチ体験システムの開発 / EC79-miyazaki
yumulab
0
230
National high-resolution cropland classification of Japan with agricultural census information and multi-temporal multi-modality datasets
satai
3
300
Any-Optical-Model: A Universal Foundation Model for Optical Remote Sensing
satai
3
840
2026 東京科学大 情報通信系 研究室紹介 (大岡山)
icttitech
0
3.8k
SOTAのさらに先へ:厳しい推論制約下での高性能モデルのPost-Training
analokmaus
0
1.3k
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
shunk031
4
1.1k
Using our influence and power for patient safety
helenbevan
0
360
明日から使える!研究効率化ツール入門
matsui_528
13
7.3k
[IR Reading 2026春 論文紹介] LLM-based Listwise Reranking under the Effect of Positional Bias (ECIR 2026) /IR-Reading-2026-Spring
koheishinden
PRO
0
120
COFFEE-Japan PROJECT Impact Report(海ノ向こうコーヒー)
ontheslope
0
2k
言語モデルから言語について語る際に押さえておきたいこと
eumesy
PRO
5
2.3k
Featured
See All Featured
svc-hook: hooking system calls on ARM64 by binary rewriting
retrage
2
300
Raft: Consensus for Rubyists
vanstee
141
7.5k
Effective software design: The role of men in debugging patriarchy in IT @ Voxxed Days AMS
baasie
0
430
Utilizing Notion as your number one productivity tool
mfonobong
4
320
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
210
Efficient Content Optimization with Google Search Console & Apps Script
katarinadahlin
PRO
1
630
WENDY [Excerpt]
tessaabrams
11
38k
Visualizing Your Data: Incorporating Mongo into Loggly Infrastructure
mongodb
49
10k
Why Our Code Smells
bkeepers
PRO
340
58k
Marketing to machines
jonoalderson
1
5.5k
Git: the NoSQL Database
bkeepers
PRO
432
67k
WCS-LA-2024
lcolladotor
0
650
Transcript
統計的機械翻訳における 地名の汎化の影響 長岡技術科学大学 関 拓也 , 山本 和英
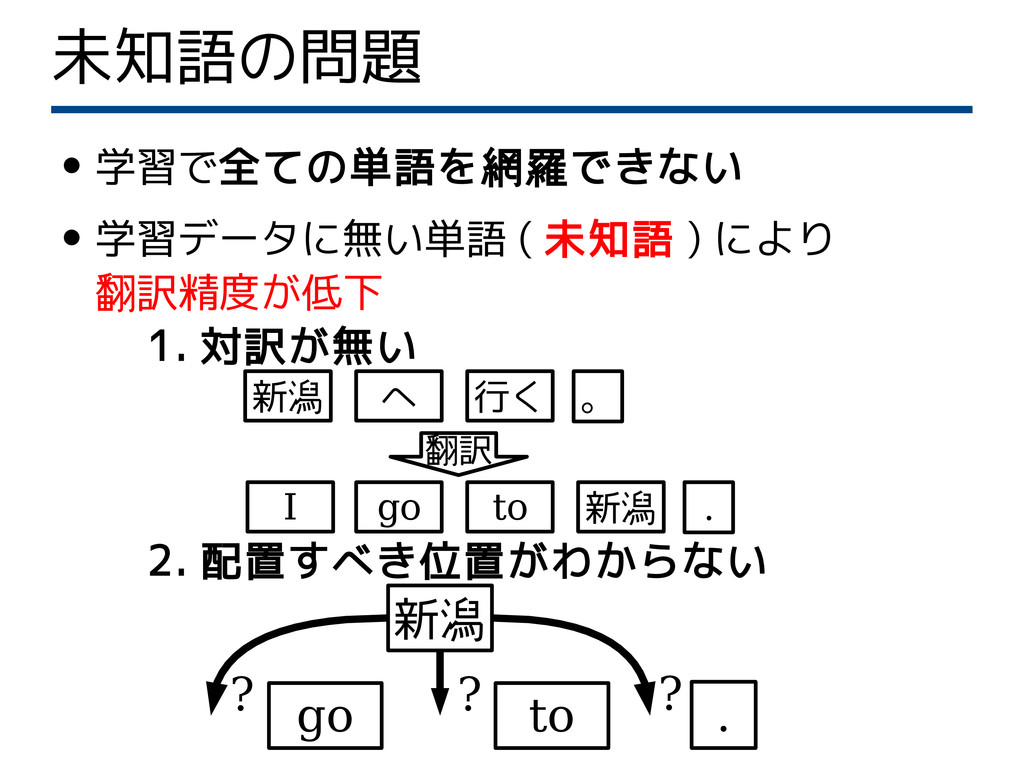
未知語の問題 • 学習で全ての単語を網羅できない • 学習データに無い単語 ( 未知語 ) により 翻訳精度が低下
1. 対訳が無い 2. 配置すべき位置がわからない 新潟 go to ? ? ? . go to . 新潟 新潟 へ 。 行く I 翻訳
目的及び既存手法 • 目的 未知の地名を含む文の翻訳精度改善 • 既存手法 ( 大熊ら [2007])
1) 未知の地名を学習データに 頻出する地名に置き換えて翻訳 2) 置き換えた地名を目的の地名に 置き換える
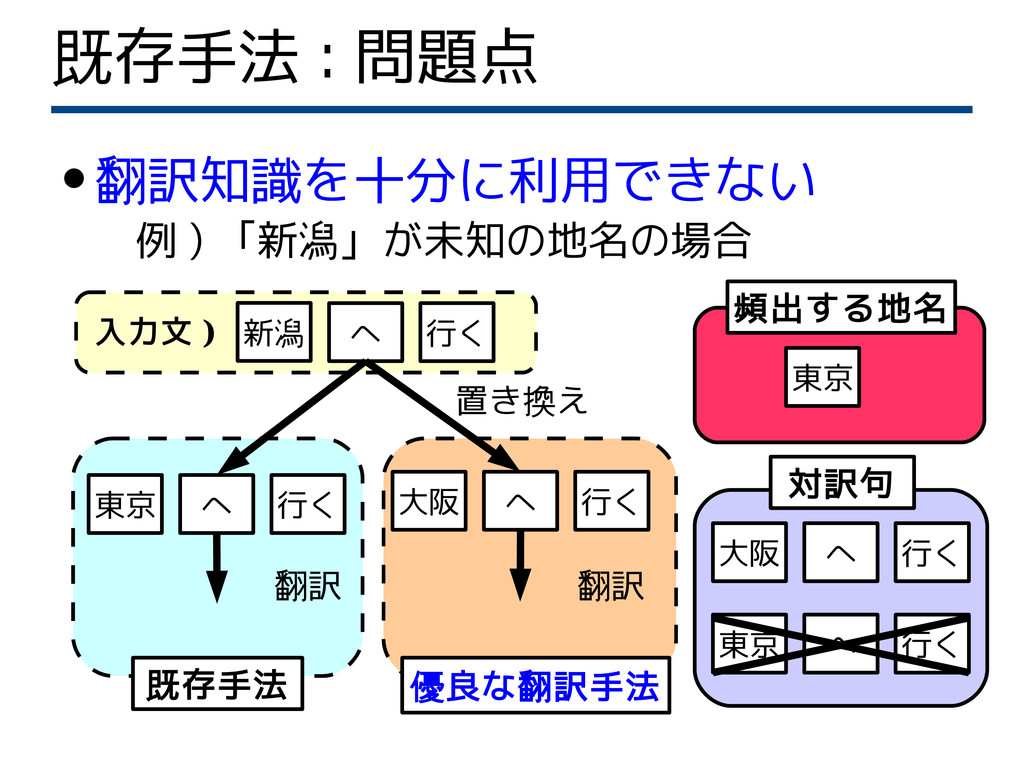
既存手法 : 問題点 • 翻訳知識を十分に利用できない 例 ) 「新潟」が未知の地名の場合 新潟
へ 行く 大阪 へ 行く 対訳句 置き換え 東京 頻出する地名 東京 へ 行く 翻訳 既存手法 大阪 へ 行く 翻訳 優良な翻訳手法 東京 へ 行く 入力文 )
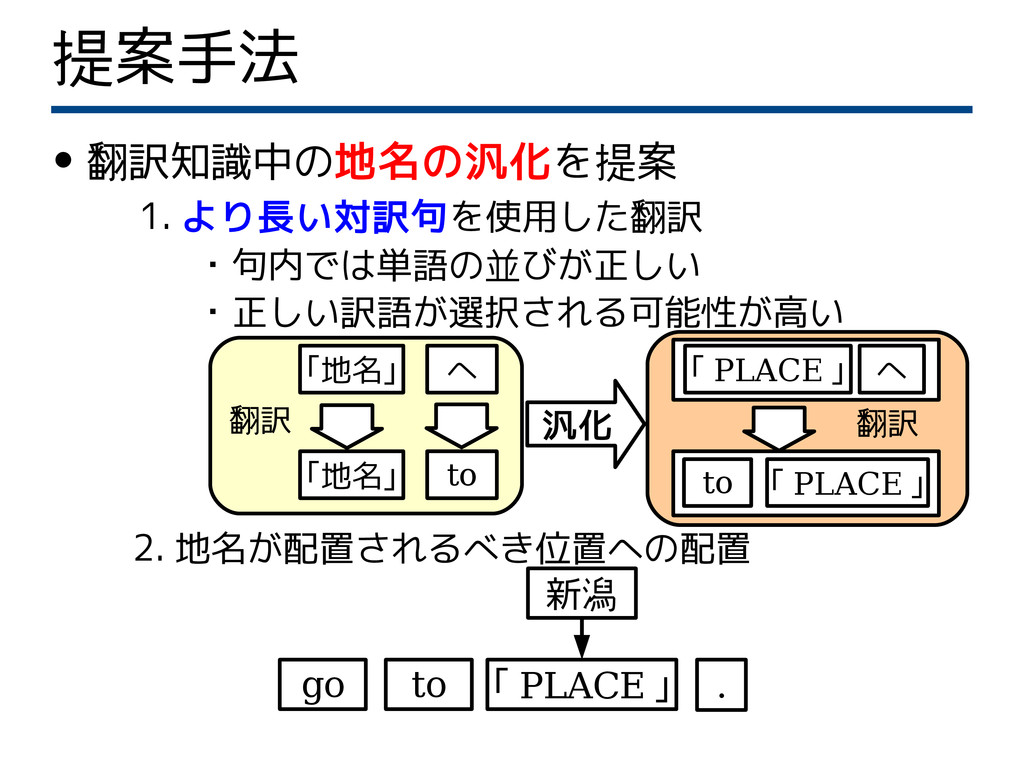
提案手法 • 翻訳知識中の地名の汎化を提案 1. より長い対訳句を使用した翻訳 ・句内では単語の並びが正しい ・正しい訳語が選択される可能性が高い
2. 地名が配置されるべき位置への配置 「 PLACE 」 go to . 新潟 「地名」 へ 汎化 「 PLACE 」 へ 翻訳 翻訳 「地名」 to 「 PLACE 」 to
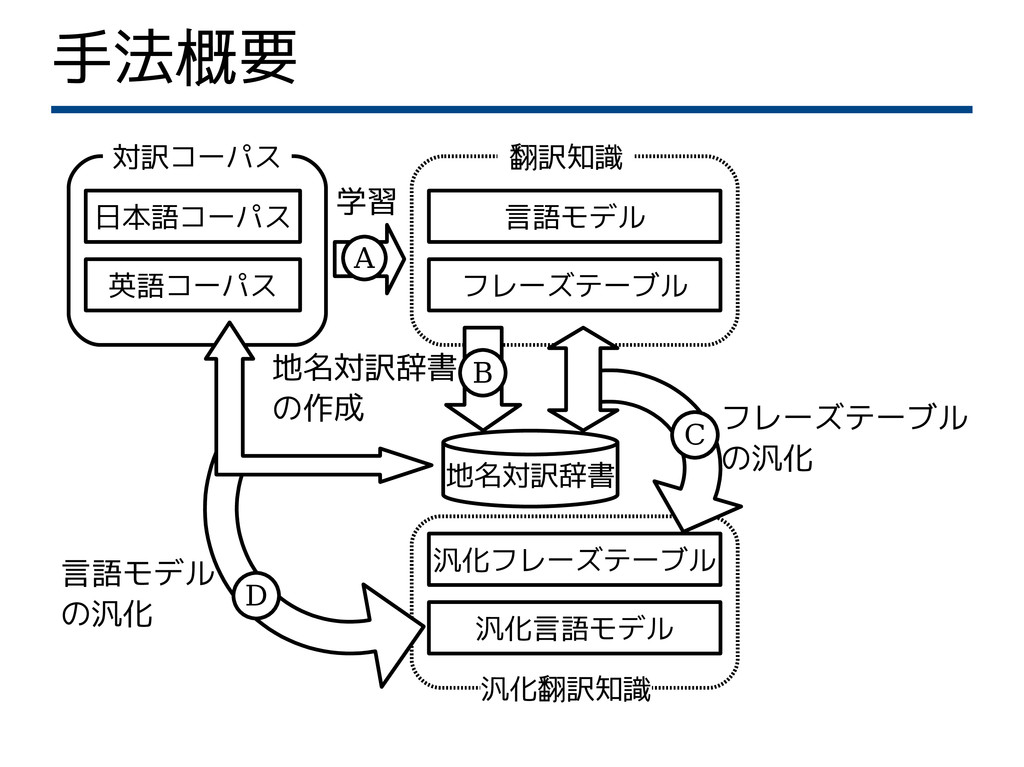
手法概要 汎化言語モデル 汎化フレーズテーブル フレーズテーブル 汎化翻訳知識 言語モデル 地名対訳辞書 翻訳知識 対訳コーパス 地名対訳辞書
の作成 英語コーパス フレーズテーブル の汎化 言語モデル の汎化 日本語コーパス 学習 A B C D
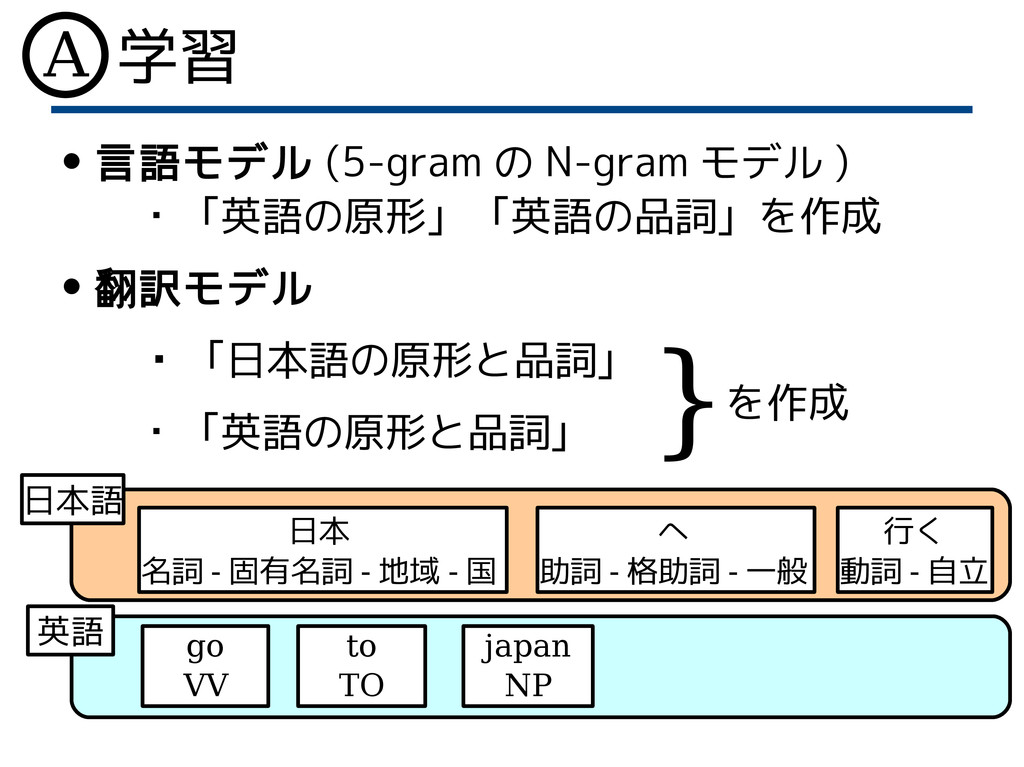
学習 • 言語モデル (5-gram の N-gram モデル ) ・「英語の原形」「英語の品詞」を作成
• 翻訳モデル ・「日本語の原形と品詞」 ・「英語の原形と品詞」 日本 名詞 - 固有名詞 - 地域 - 国 へ 助詞 - 格助詞 - 一般 行く 動詞 - 自立 go VV to TO japan NP 英語 日本語 }を作成 A
「地名対訳辞書」の作成 • フレーズテーブルを用いて作成 1. 「日本語 1 単語」 - 「英語 1
単語」対応 2. 日本語の品詞が ・「名詞 - 固有名詞 - 地域 - 一般」 ・「名詞 - 固有名詞 - 地域 - 国」 3. 英語の品詞が ・「 N( 名詞 ) 」 ・「 J( 形容詞 ) 」 4. 「日英方向」と「英日方向」の 翻訳確率の積が 0.01 以上 B
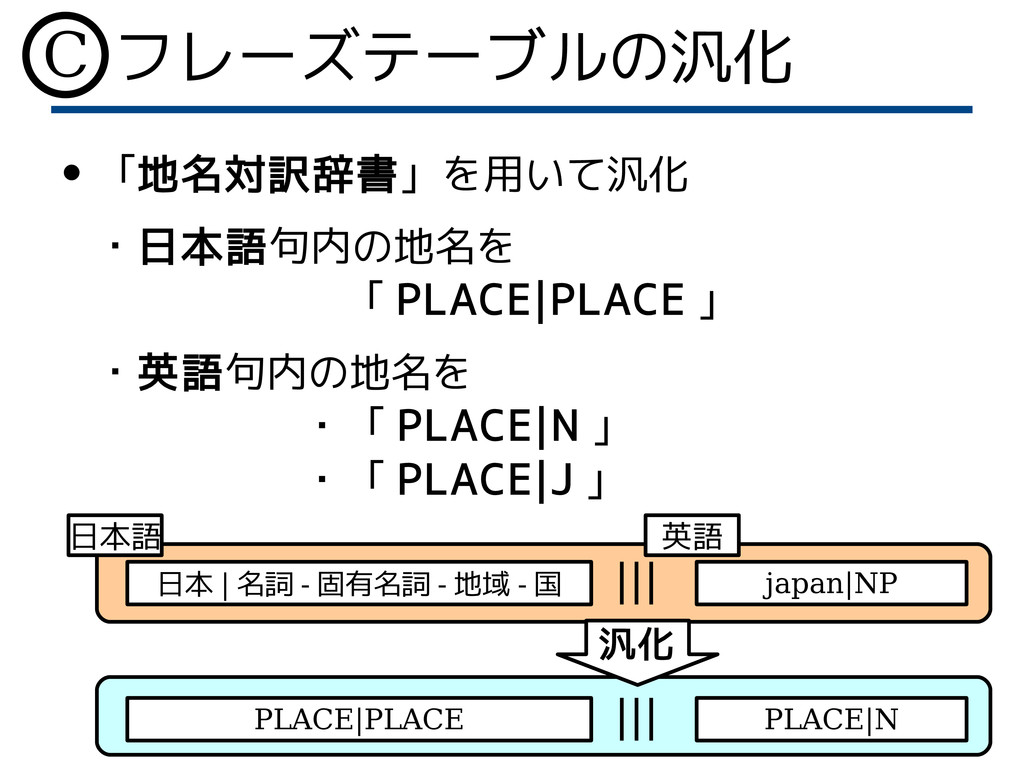
フレーズテーブルの汎化 • 「地名対訳辞書」を用いて汎化 ・日本語句内の地名を 「 PLACE|PLACE 」 ・英語句内の地名を ・「 PLACE|N
」 ・「 PLACE|J 」 日本 | 名詞 - 固有名詞 - 地域 - 国 japan|NP PLACE|PLACE PLACE|N 日本語 英語 汎化 C
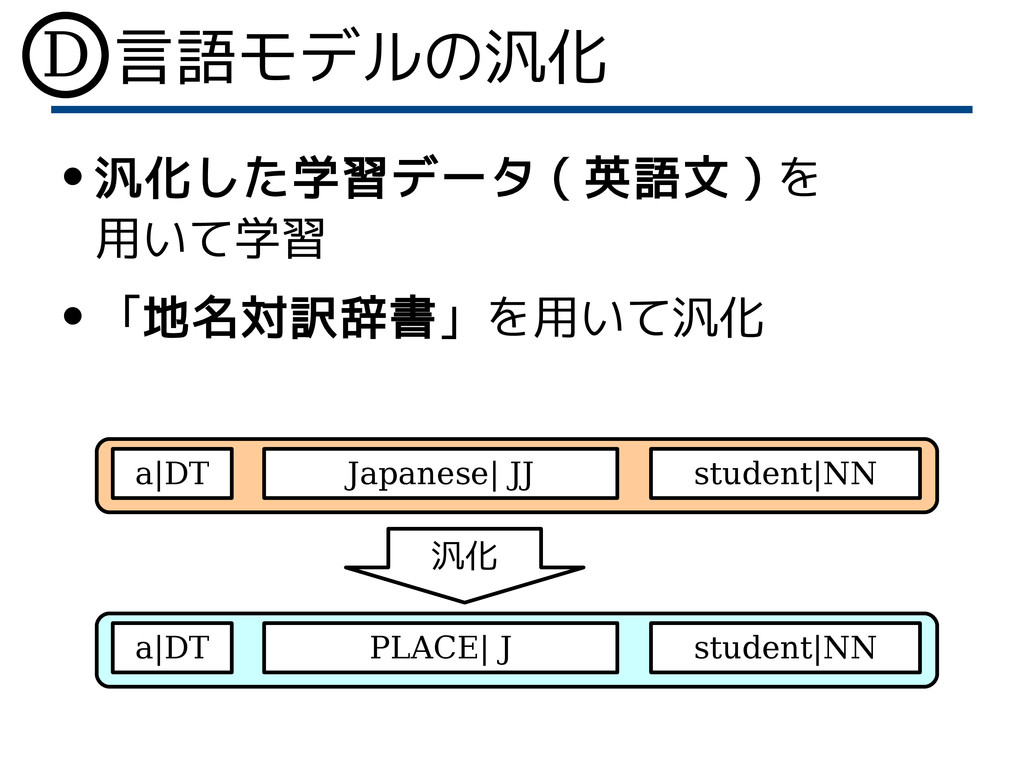
言語モデルの汎化 • 汎化した学習データ ( 英語文 ) を 用いて学習 • 「地名対訳辞書」を用いて汎化
Japanese| JJ student|NN a|DT 汎化 PLACE| J student|NN a|DT D
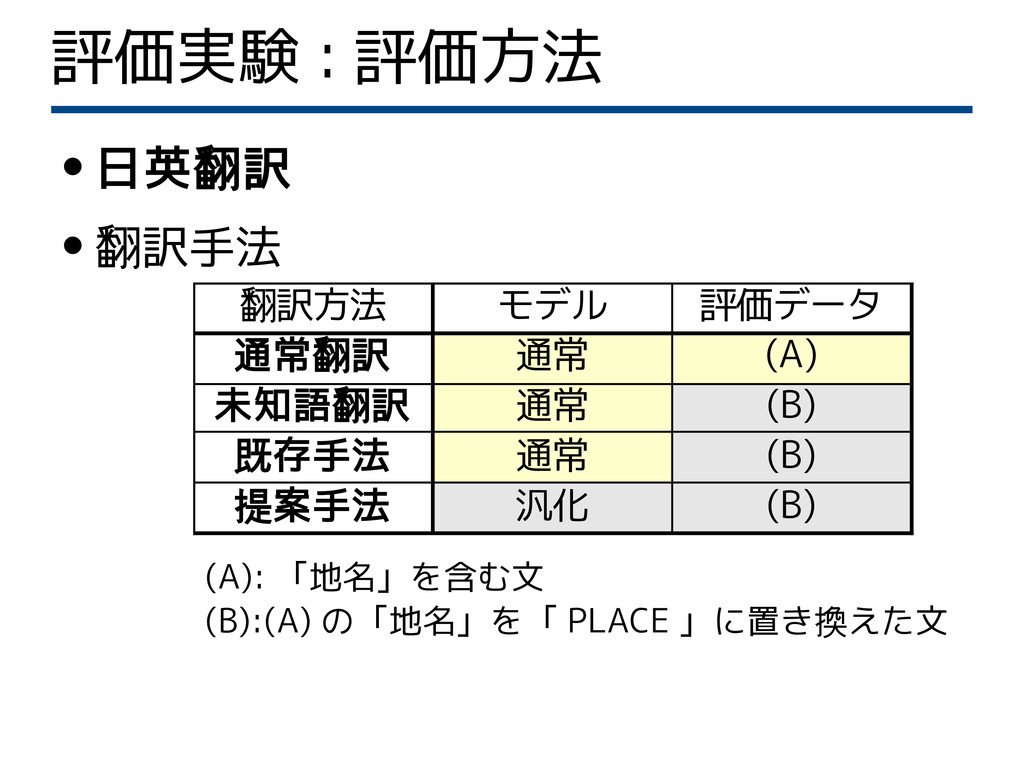
評価実験 : 評価方法 • 日英翻訳 • 翻訳手法 (A):
「地名」を含む文 (B):(A) の「地名」を「 PLACE 」に置き換えた文 翻訳方法 モデル 評価データ 通常翻訳 通常 (A) 未知語翻訳 通常 (B) 既存手法 通常 (B) 提案手法 汎化 (B)
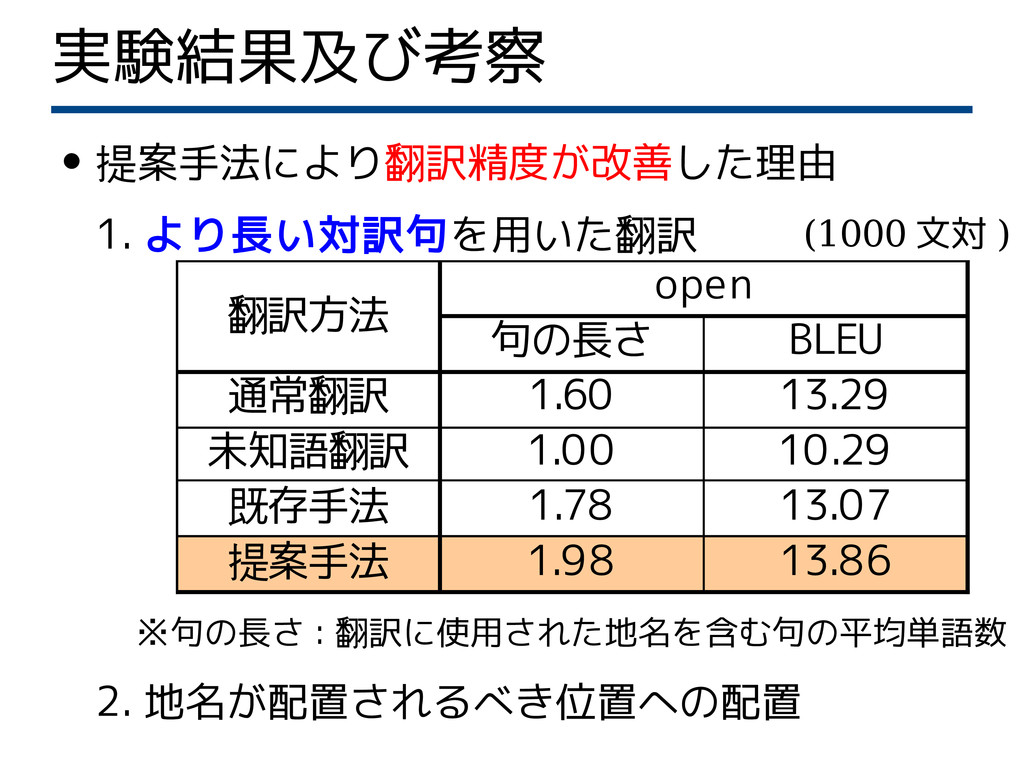
実験結果及び考察 • 提案手法により翻訳精度が改善した理由 1. より長い対訳句を用いた翻訳 ※句の長さ : 翻訳に使用された地名を含む句の平均単語数
2. 地名が配置されるべき位置への配置 (1000 文対 ) 翻訳方法 open 句の長さ BLEU 通常翻訳 1.60 13.29 未知語翻訳 1.00 10.29 既存手法 1.78 13.07 提案手法 1.98 13.86
考察:「地名対訳辞書」の問題 • 地名を含む対訳句の内 45.0% しか汎化できていない • 原因 ・学習データに頻出する
1 対多対訳の地名が未登録 例 ) 「ニューヨーク」 | 「 new york 」
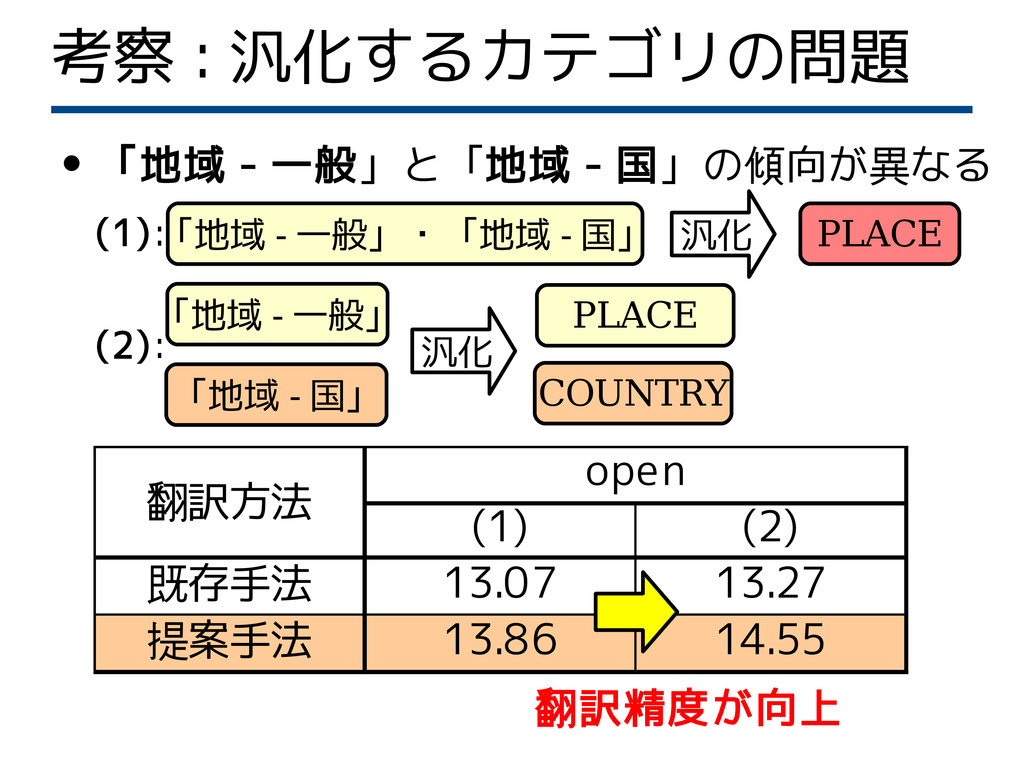
翻訳方法 open (1) (2) 既存手法 13.07 13.27 提案手法 13.86 14.55
考察 : 汎化するカテゴリの問題 • 「地域 - 一般」と「地域 - 国」の傾向が異なる (1): (2): 翻訳精度が向上 「地域 - 一般」・「地域 - 国」 「地域 - 一般」 汎化 PLACE 「地域 - 国」 汎化 COUNTRY PLACE
まとめ • 未知の地名を含む文の翻訳精度改善に有効 ・より長い句を用いた翻訳 ・地名が配置されるべき位置への配置 • 提案手法の改善のために ・「地名対訳辞書」の網羅性を上げる ・適切なカテゴリに単語を分け、 別々に汎化を行う
{kind=link}
{kind=link}
![目的及び既存手法 • 目的 未知の地名を含む文の翻訳精度改善 • 既存手法 ( 大熊ら [2007])](https://files.speakerdeck.com/presentations/23171210c6050130c09d7a88047019d1/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}