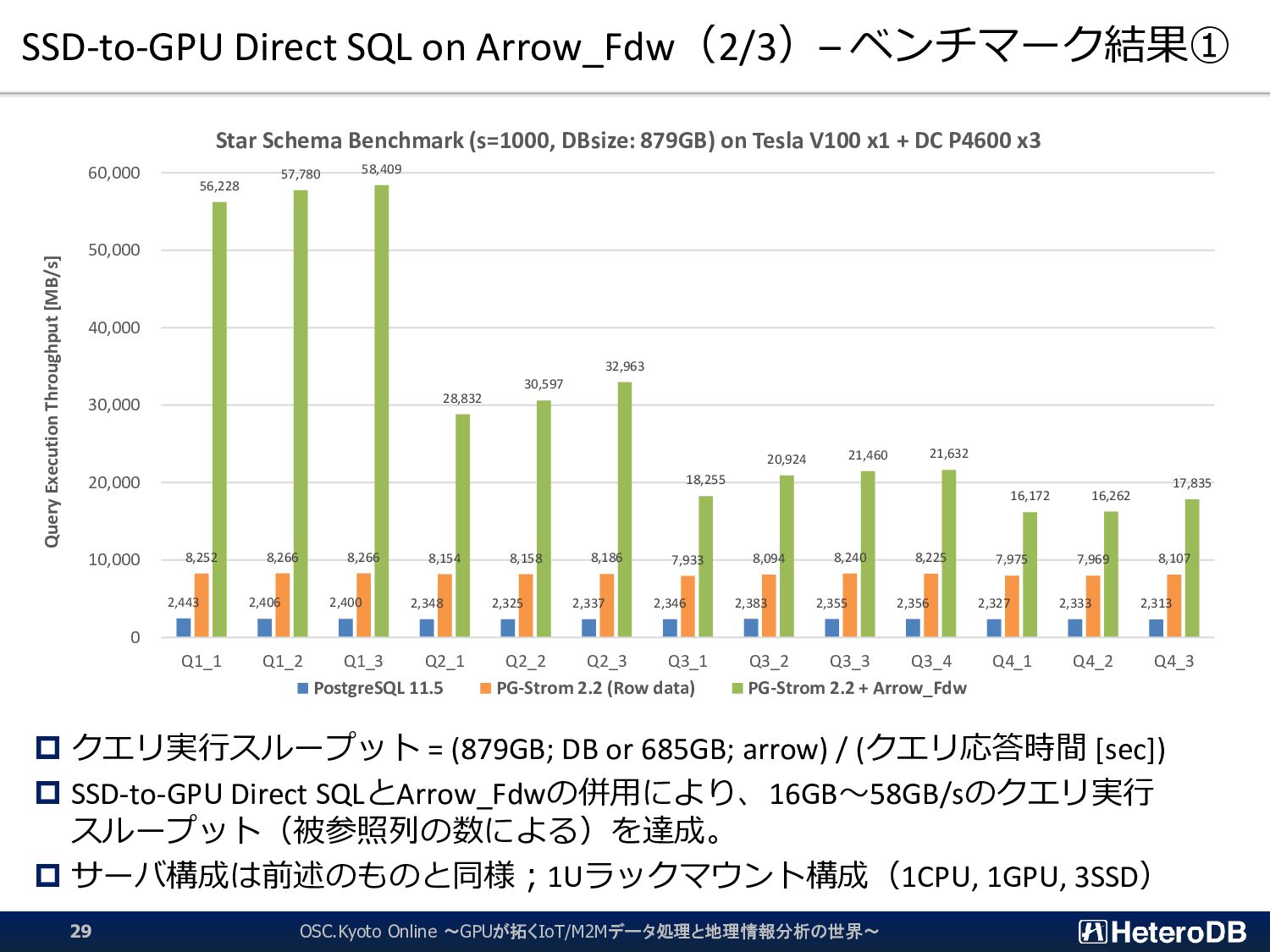
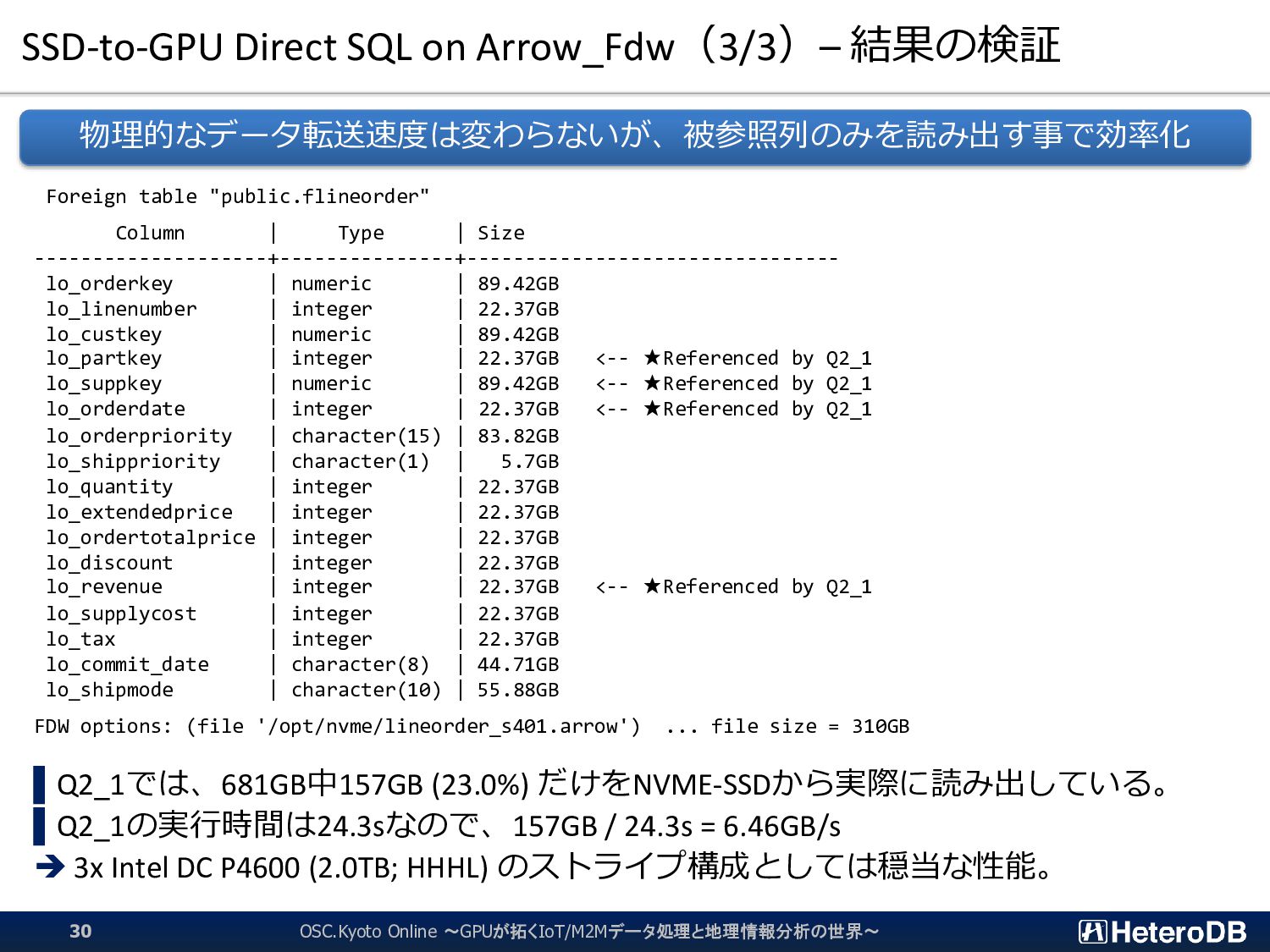
DB or 685GB; arrow) / (クエリ応答時間 [sec]) SSD-to-GPU Direct SQLとArrow_Fdwの併用により、16GB~58GB/sのクエリ実行 スループット(被参照列の数による)を達成。 サーバ構成は前述のものと同様;1Uラックマウント構成(1CPU, 1GPU, 3SSD) OSC.Kyoto Online ~GPUが拓くIoT/M2Mデータ処理と地理情報分析の世界~ 29 2,443 2,406 2,400 2,348 2,325 2,337 2,346 2,383 2,355 2,356 2,327 2,333 2,313 8,252 8,266 8,266 8,154 8,158 8,186 7,933 8,094 8,240 8,225 7,975 7,969 8,107 56,228 57,780 58,409 28,832 30,597 32,963 18,255 20,924 21,460 21,632 16,172 16,262 17,835 0 10,000 20,000 30,000 40,000 50,000 60,000 Q1_1 Q1_2 Q1_3 Q2_1 Q2_2 Q2_3 Q3_1 Q3_2 Q3_3 Q3_4 Q4_1 Q4_2 Q4_3 Query Execution Throughput [MB/s] Star Schema Benchmark (s=1000, DBsize: 879GB) on Tesla V100 x1 + DC P4600 x3 PostgreSQL 11.5 PG-Strom 2.2 (Row data) PG-Strom 2.2 + Arrow_Fdw
![GPUが拓くIoT/M2Mデータ処理と地理情報分析の世界 ~PG-Stromで作るデータ処理基盤~ HeteroDB,Inc Chief Architect & CEO KaiGai Kohei <[email protected]>](https://files.speakerdeck.com/presentations/53932e44f6204d6da81d70af33034ab2/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
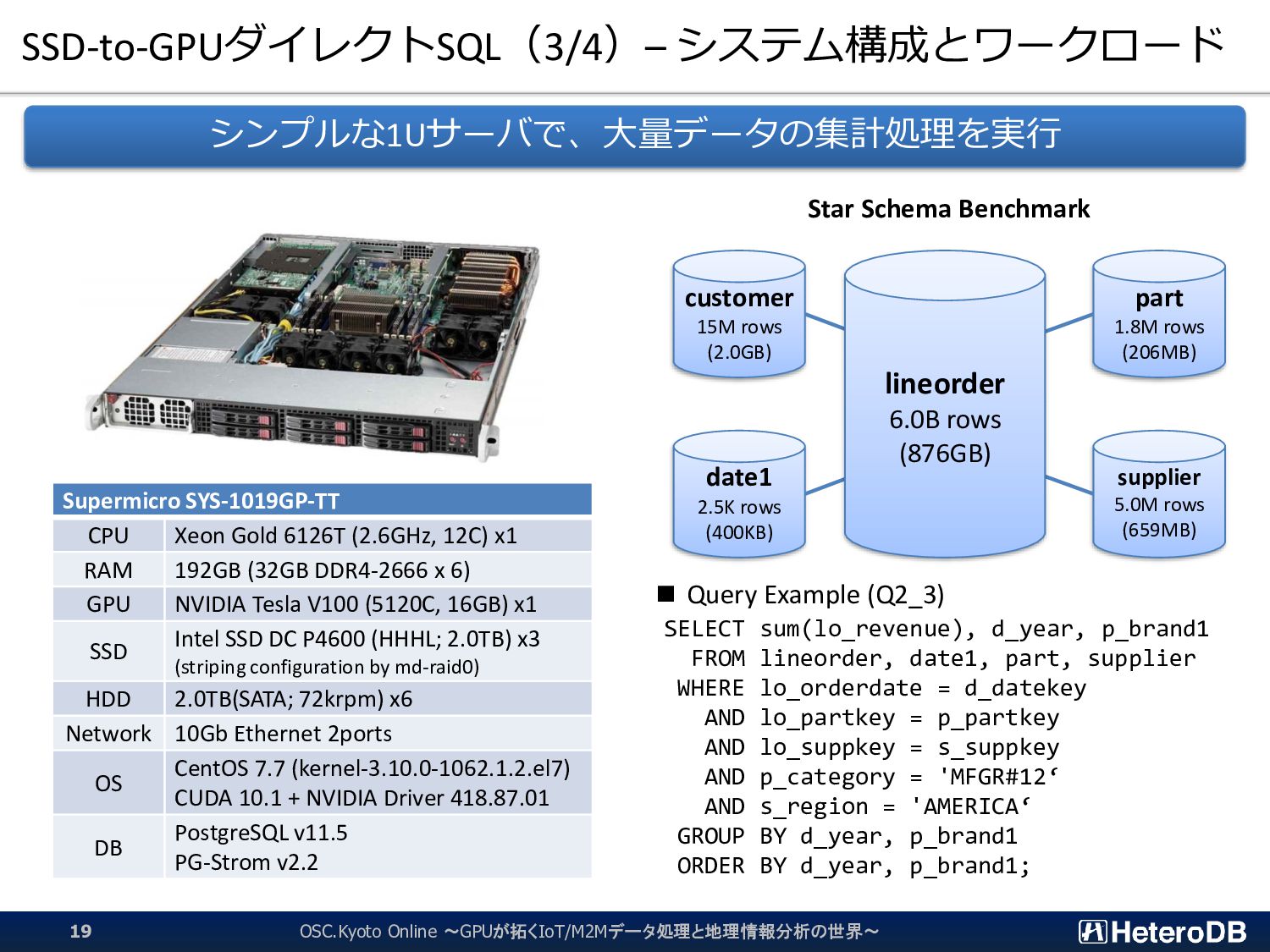{kind=link}
![SSD-to-GPUダイレクトSQL(4/4)– ベンチマーク結果 クエリ実行スループット = (879GB DB-size) / (クエリ応答時間 [sec])](https://files.speakerdeck.com/presentations/53932e44f6204d6da81d70af33034ab2/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
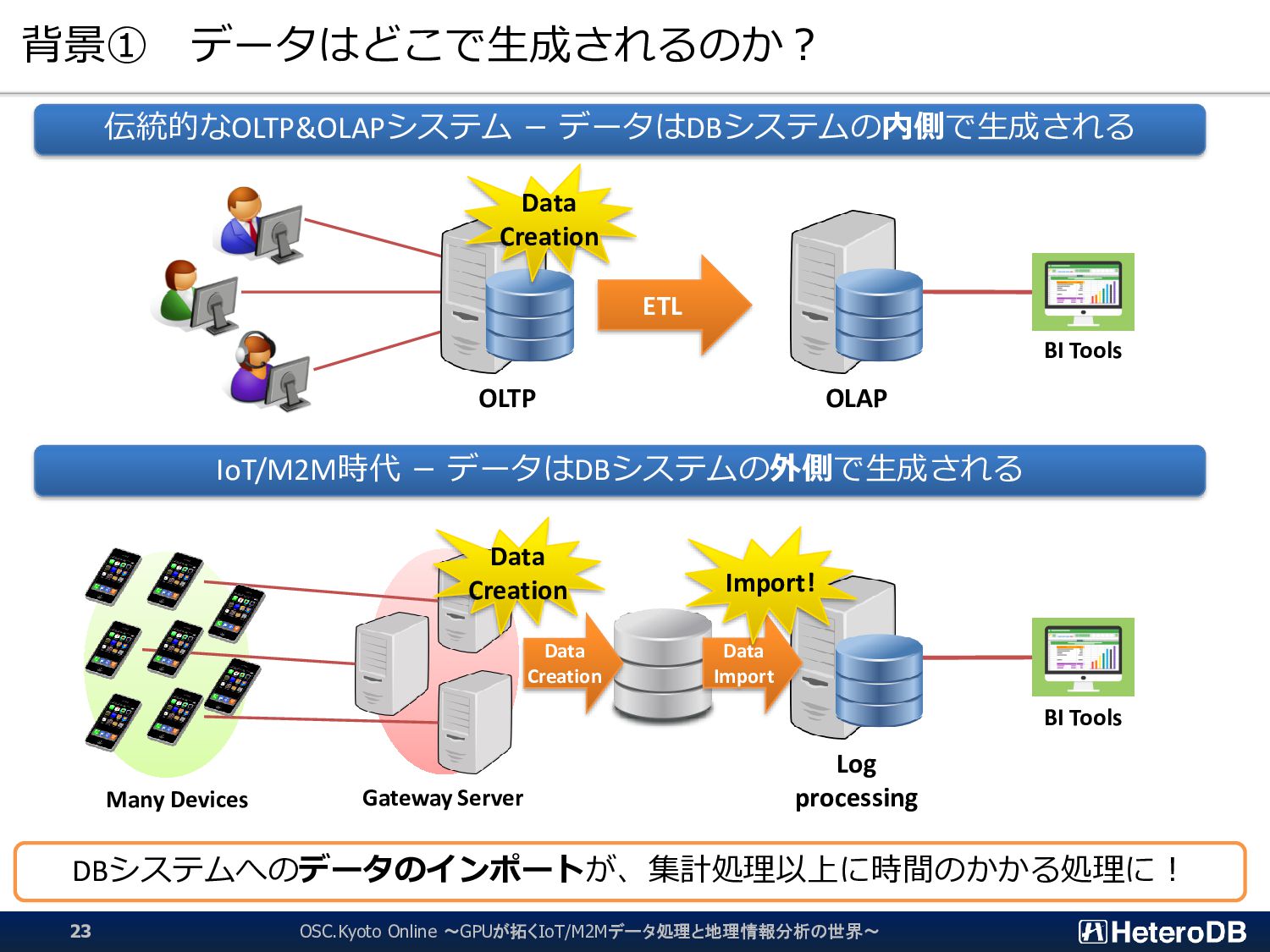{kind=link}
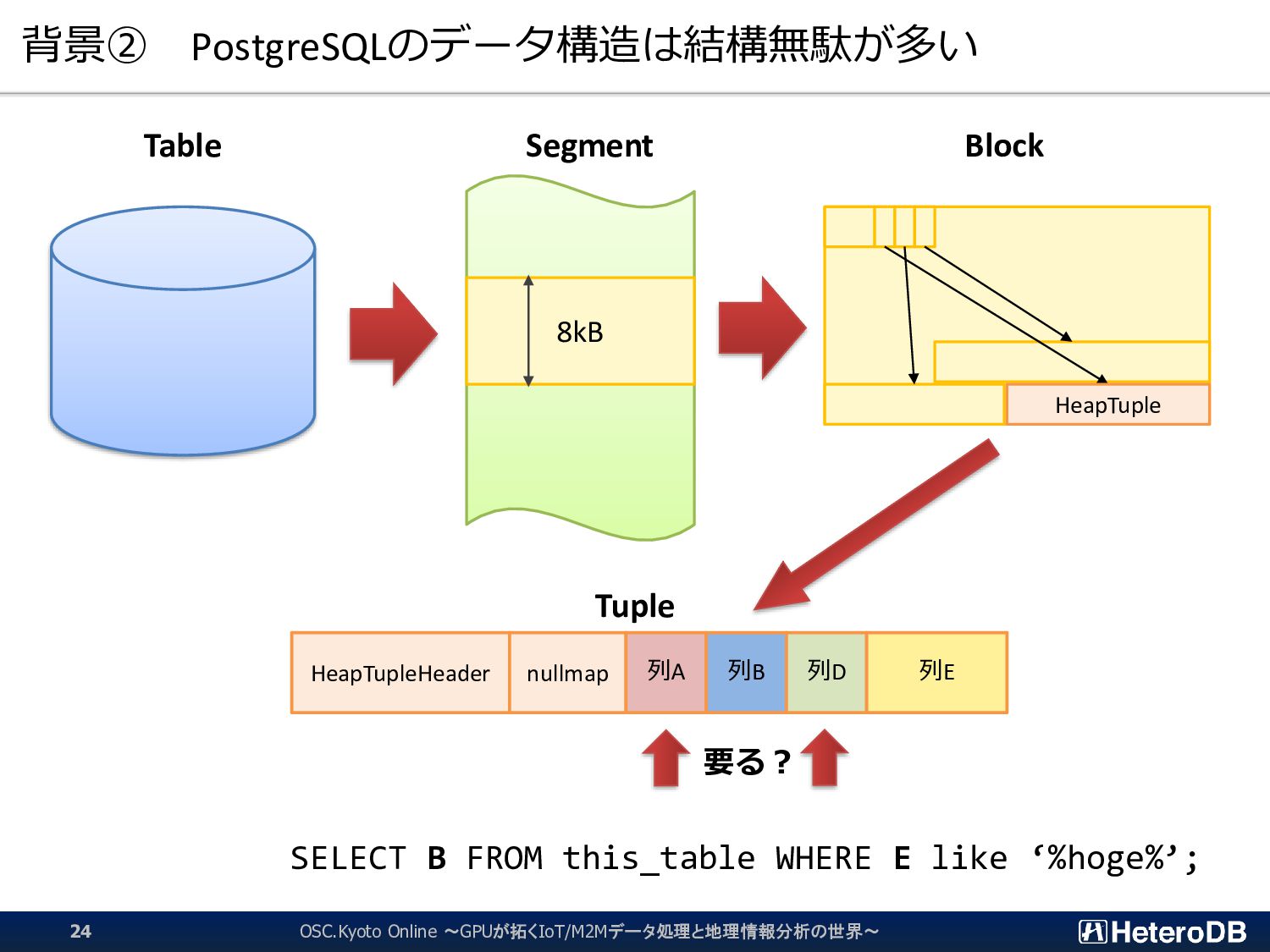{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
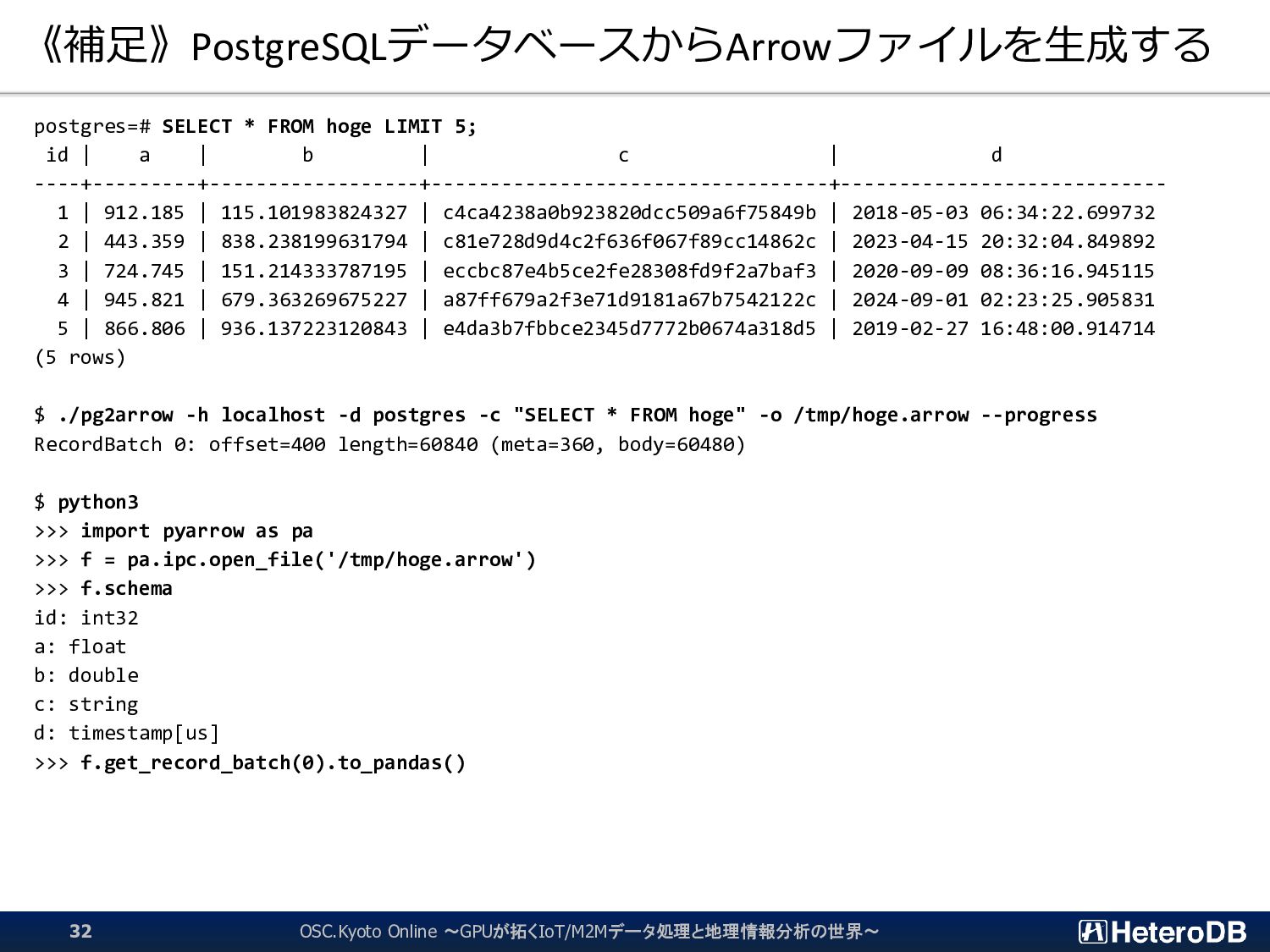
![《補足》PostgreSQLデータベースからArrowファイルを生成する ✓ 基本的な使い方は、-cで指定したSQLの実行結果を、 -oで指定したファイルに書き出す。 $ pg2arrow --help Usage: pg2arrow [OPTION]](https://files.speakerdeck.com/presentations/53932e44f6204d6da81d70af33034ab2/slide_30.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
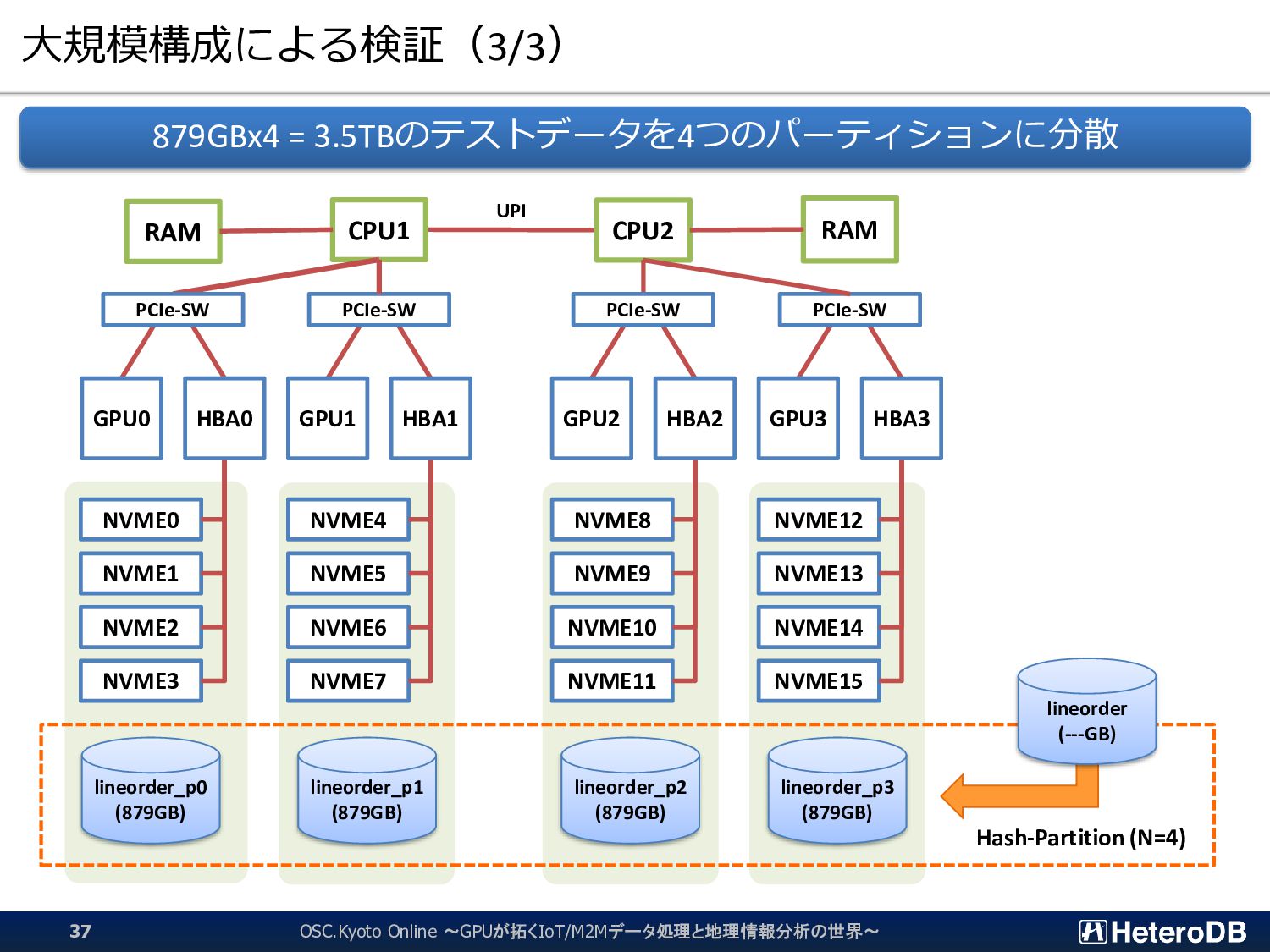{kind=link}
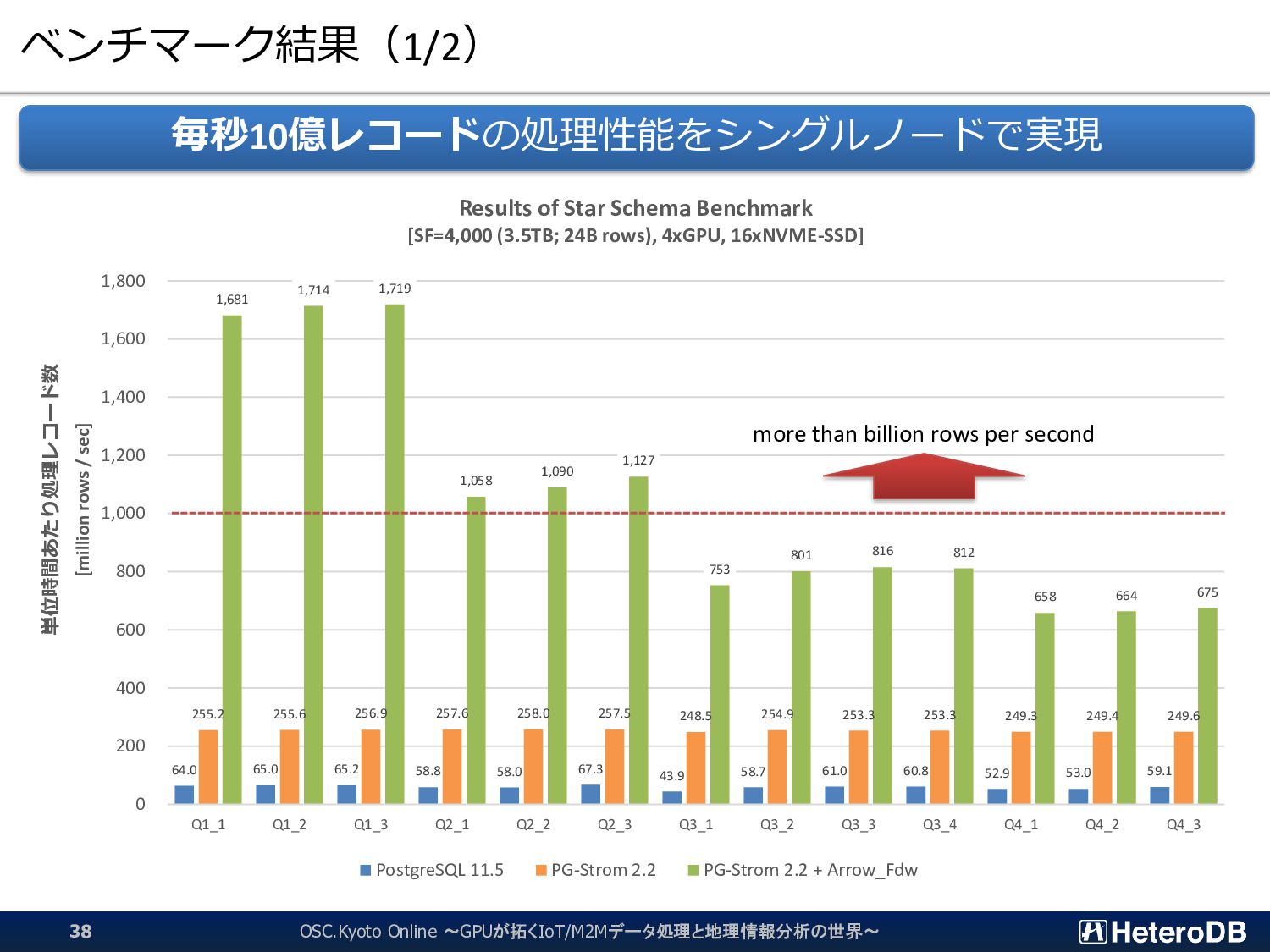{kind=link}
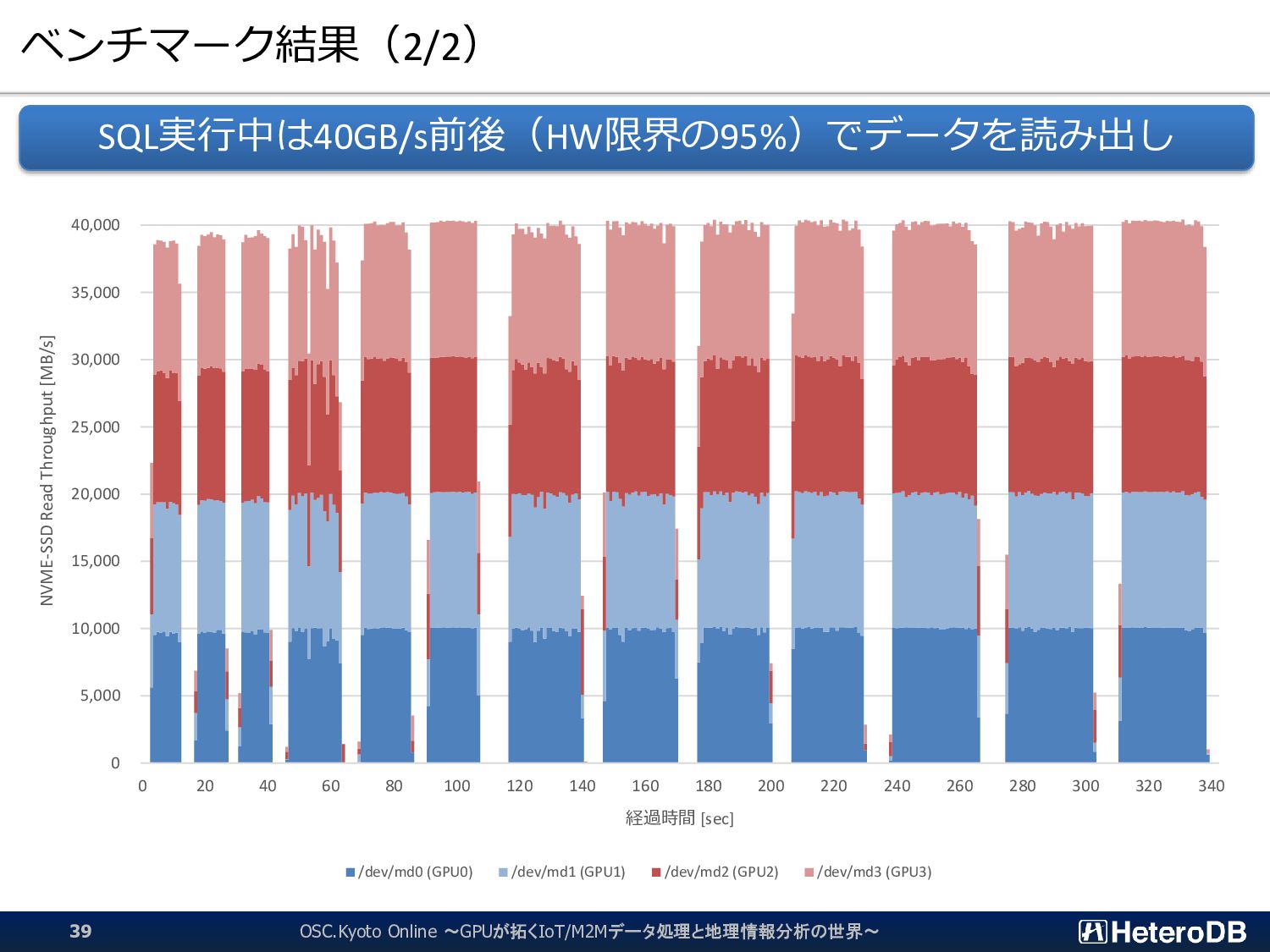{kind=link}
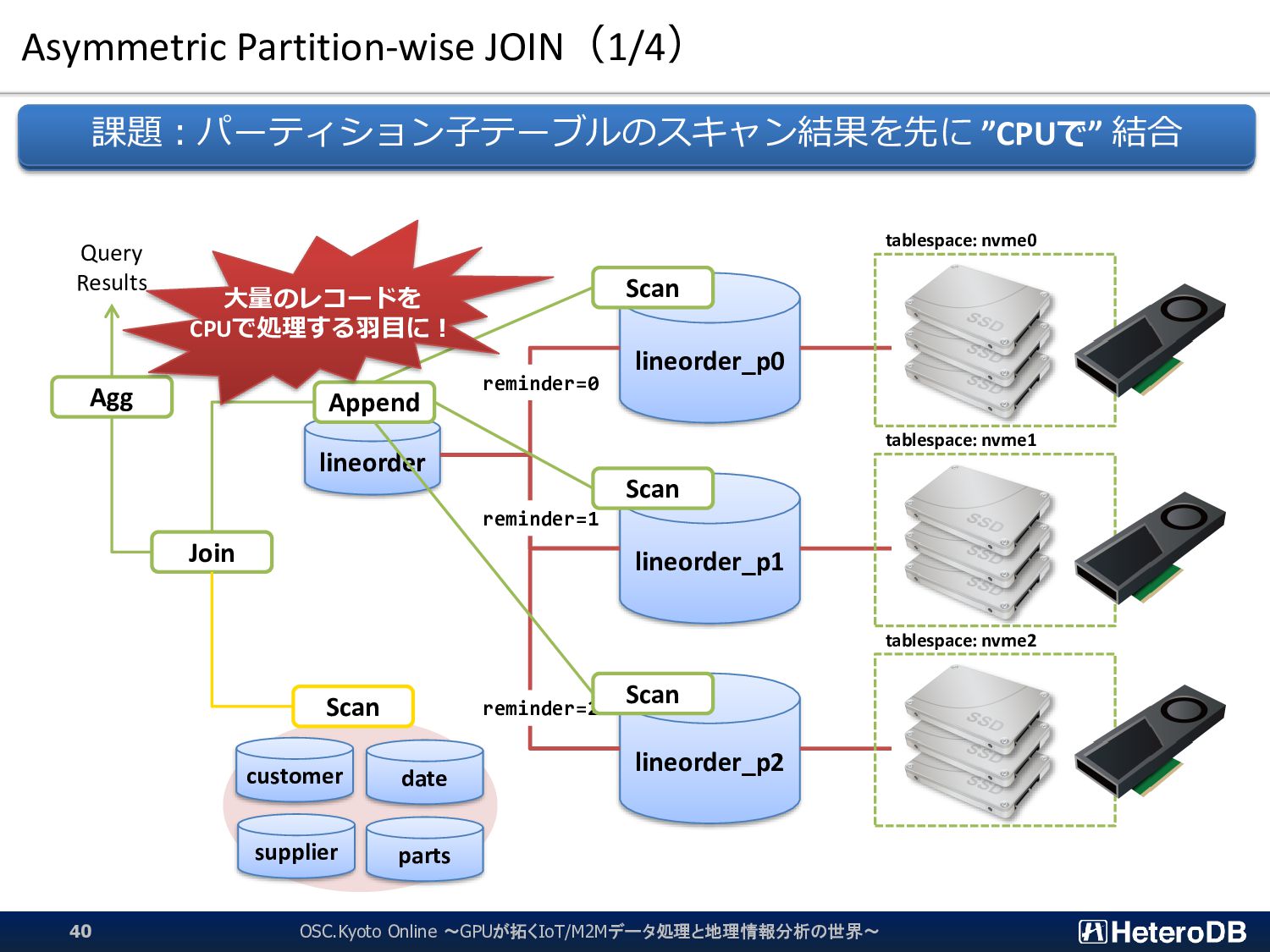{kind=link}
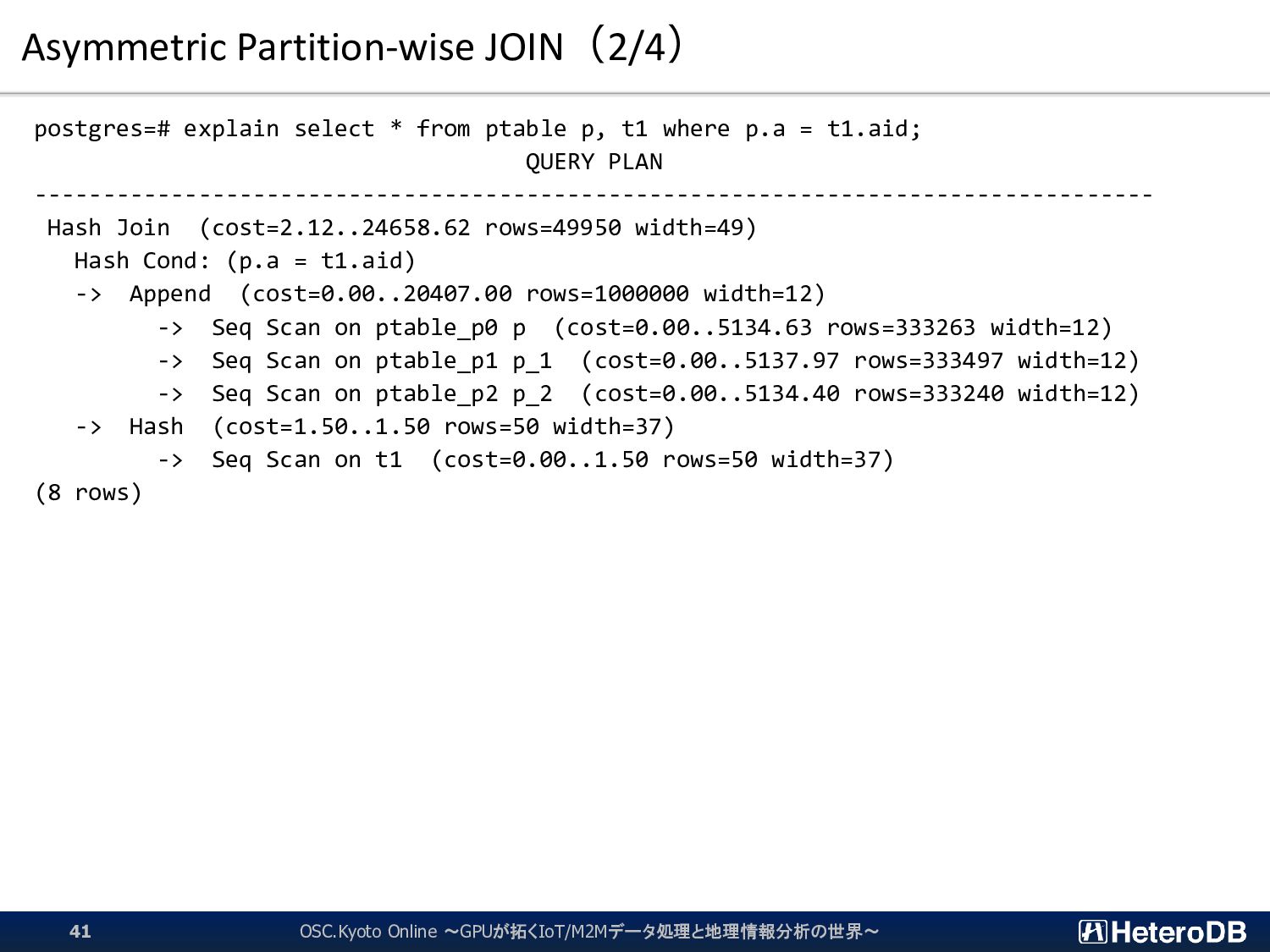{kind=link}
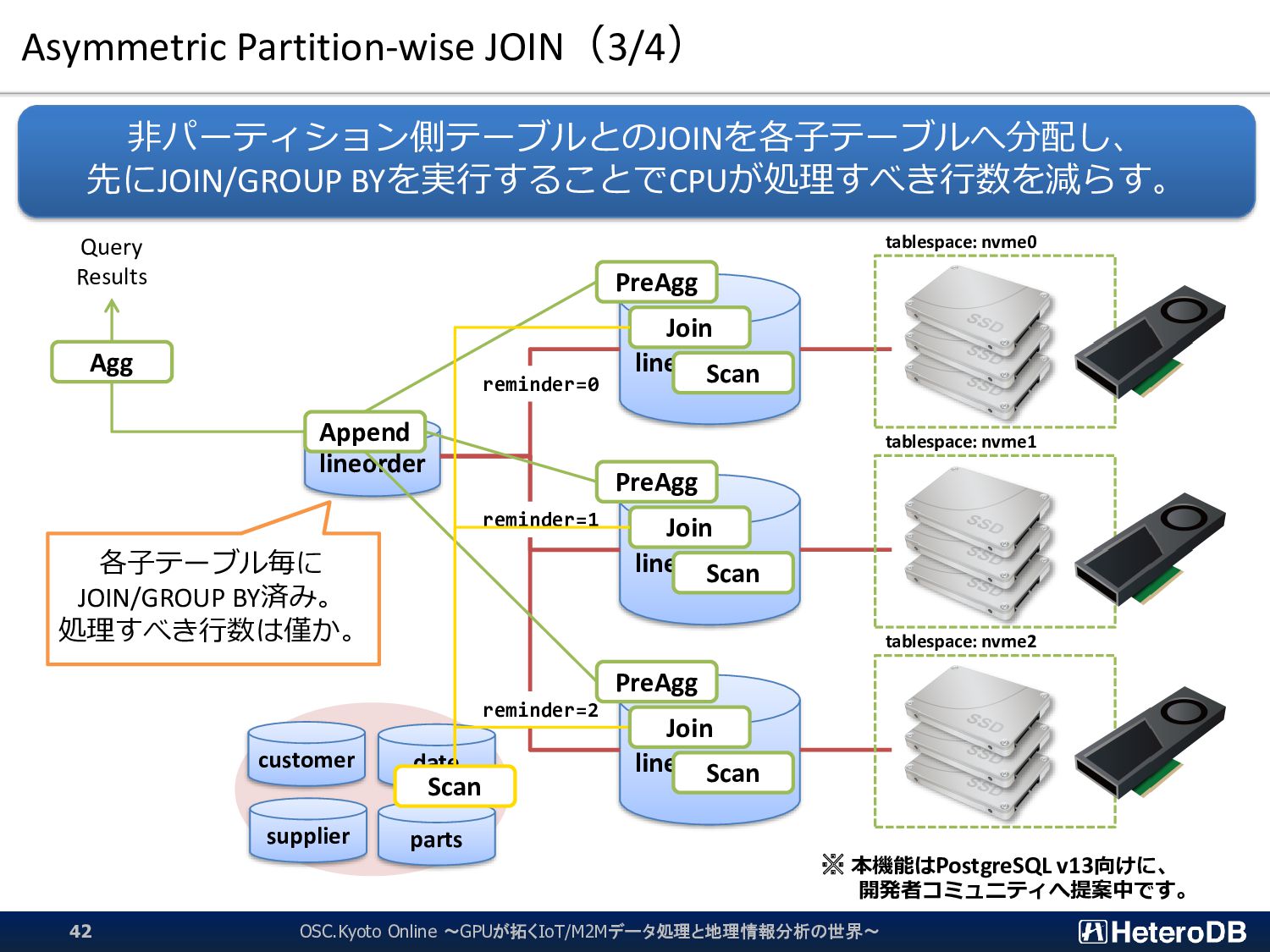{kind=link}
{kind=link}
{kind=link}
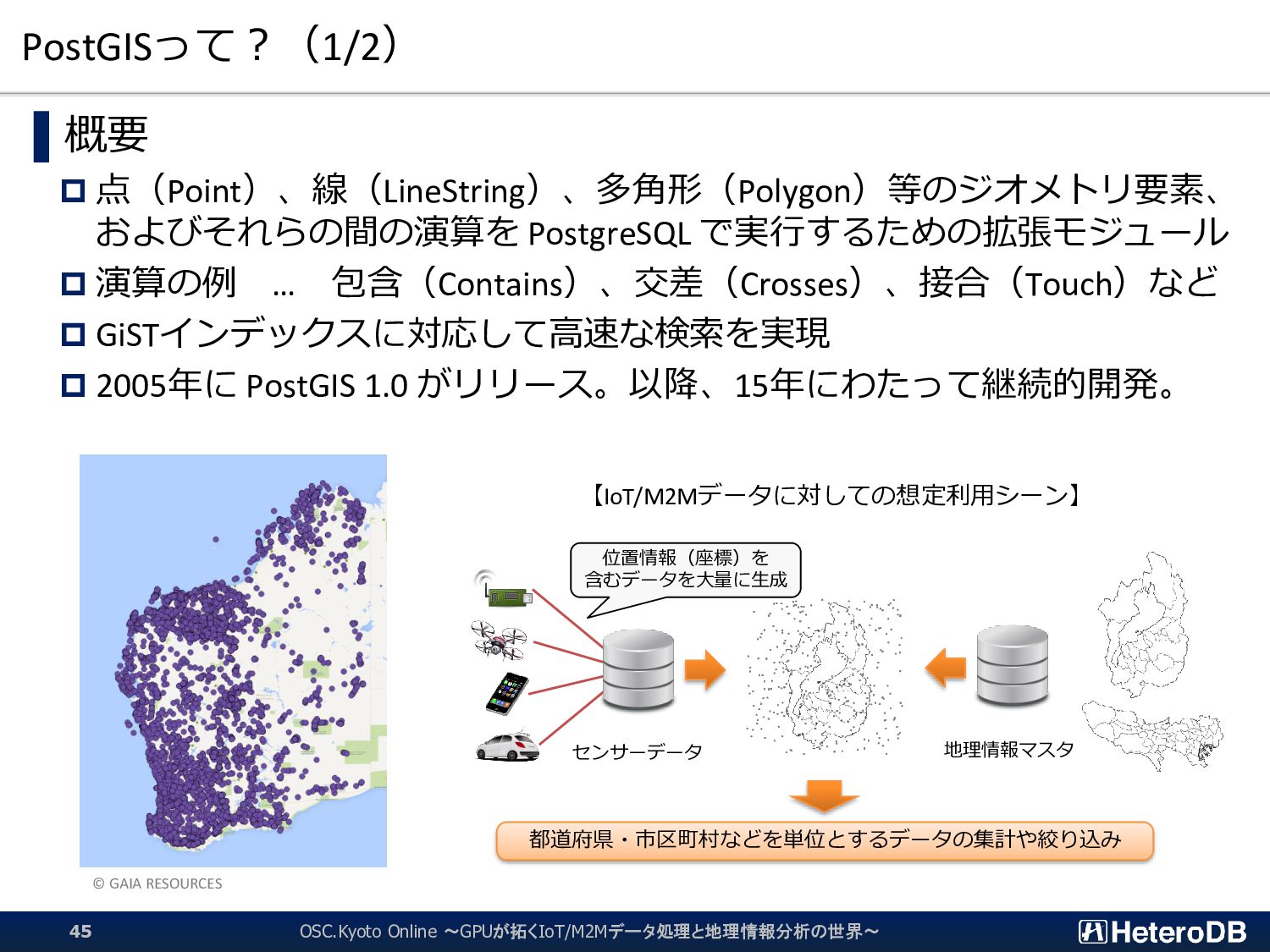{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
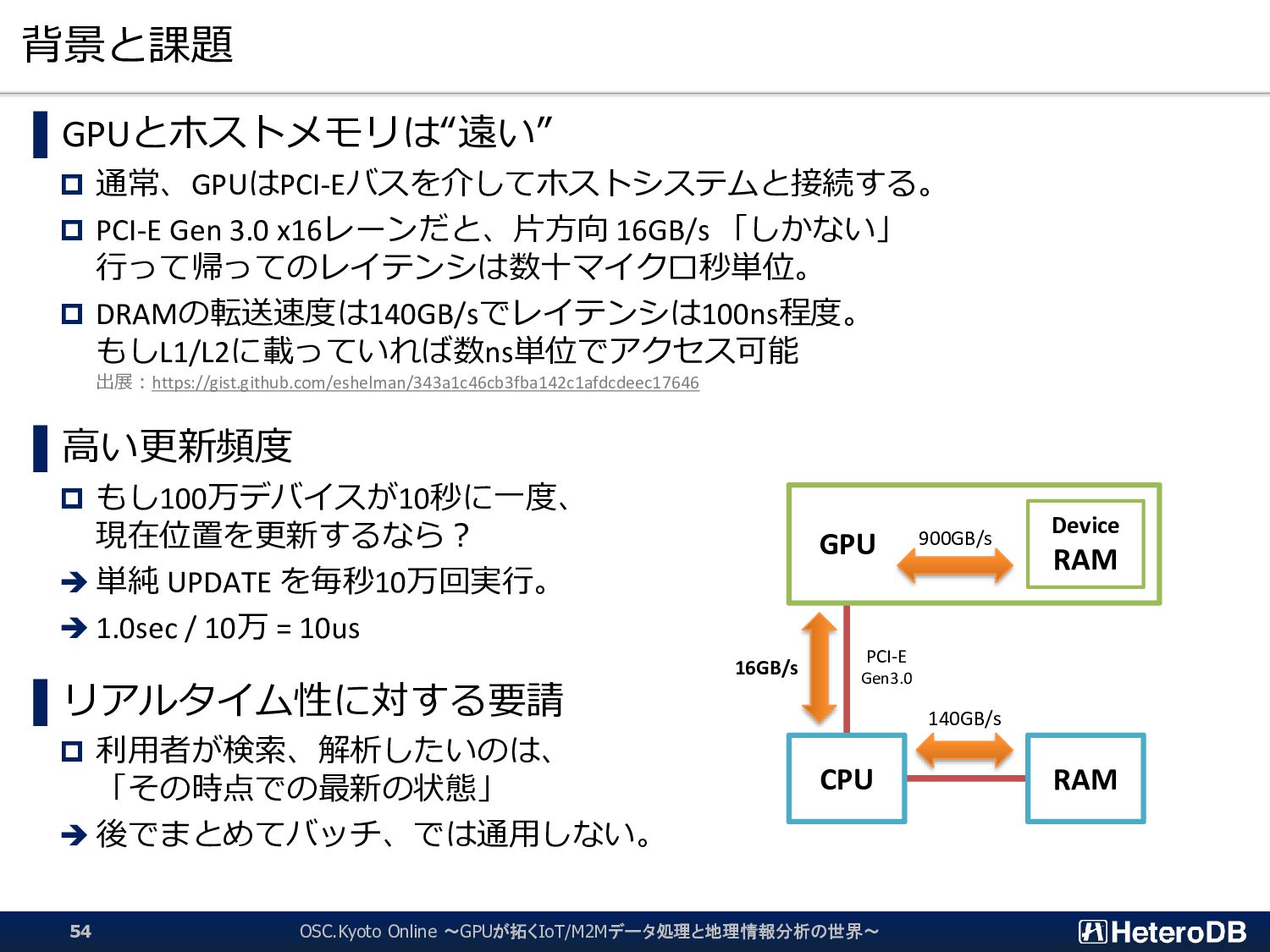{kind=link}
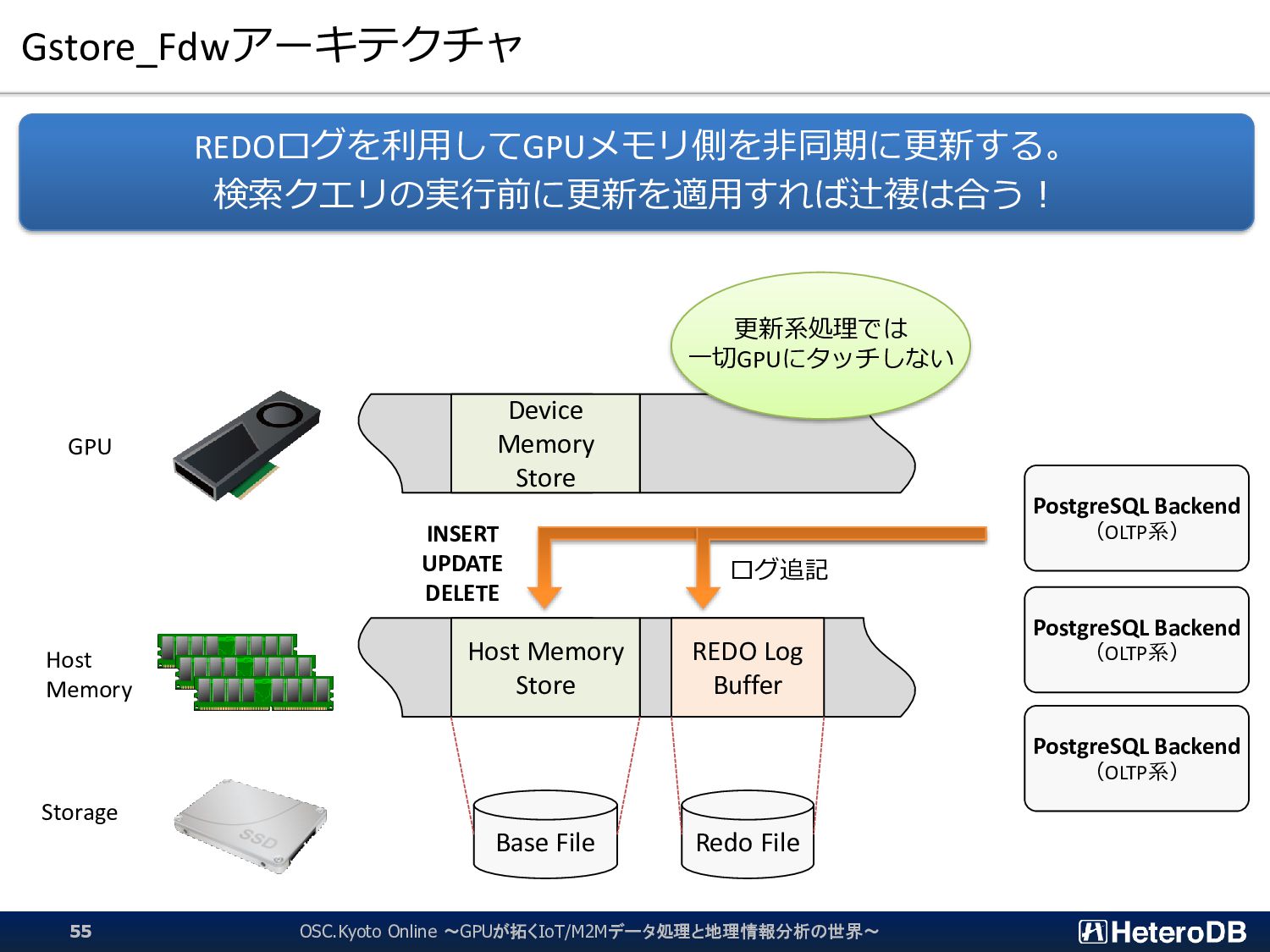{kind=link}
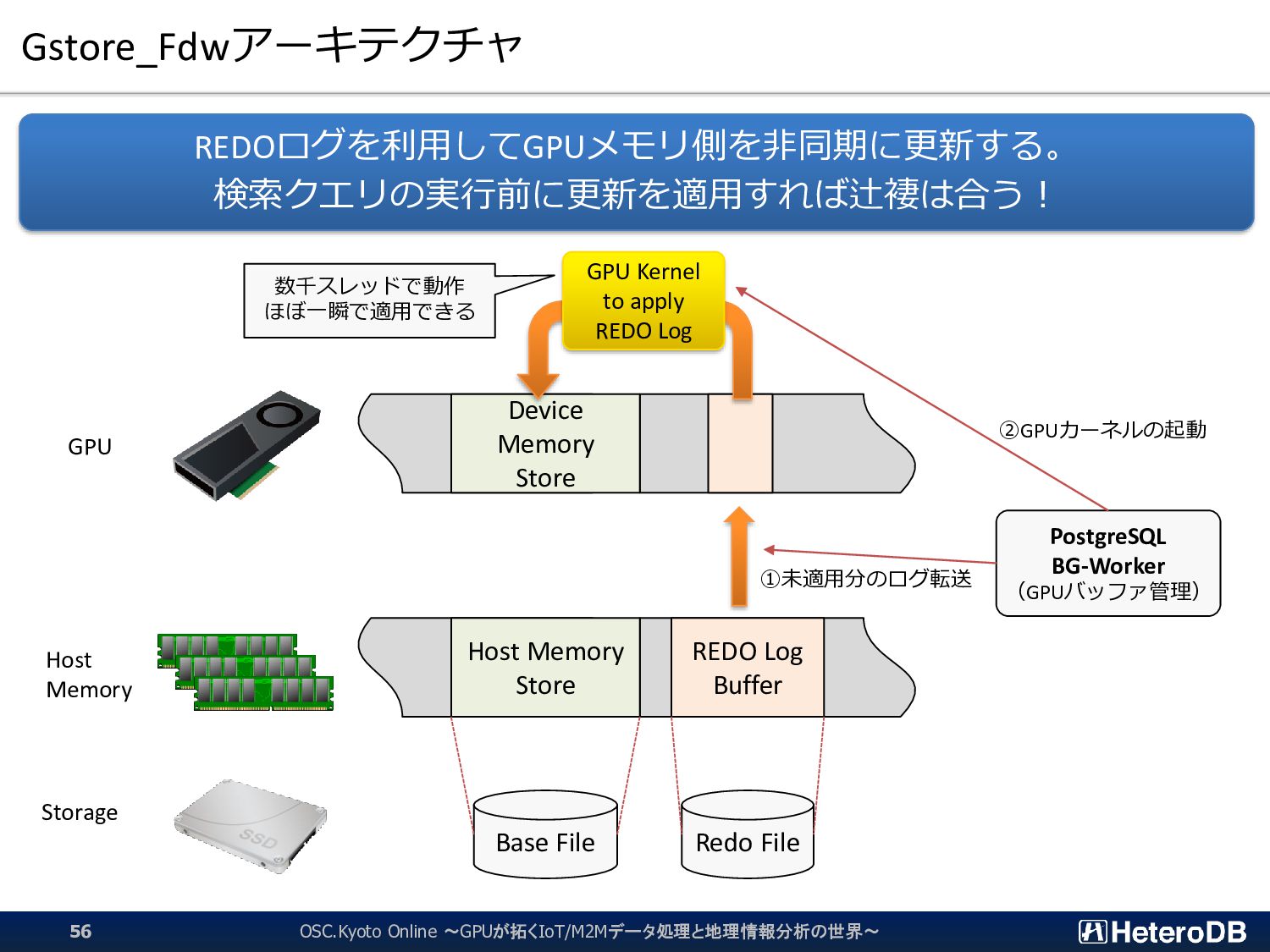{kind=link}
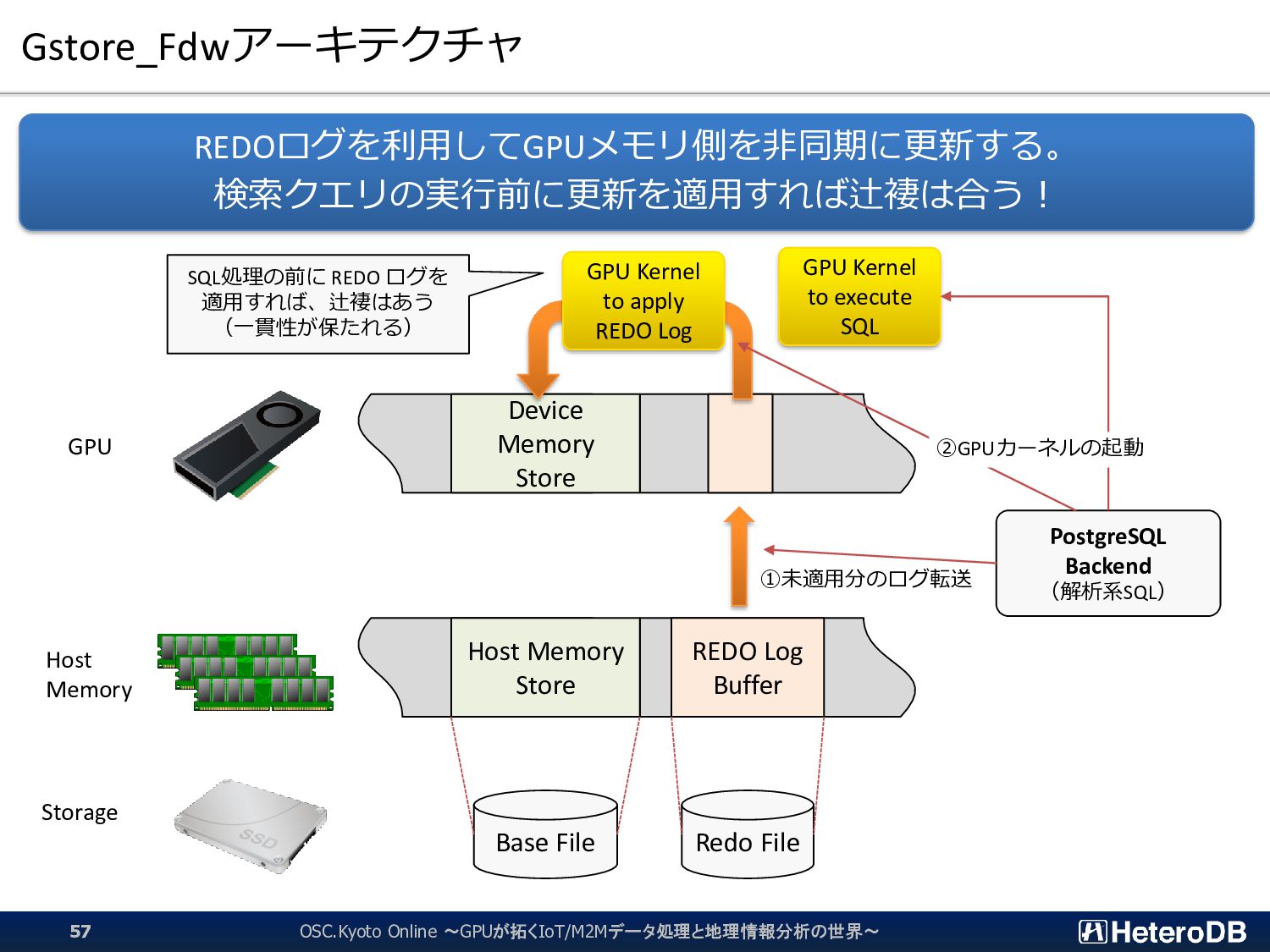{kind=link}
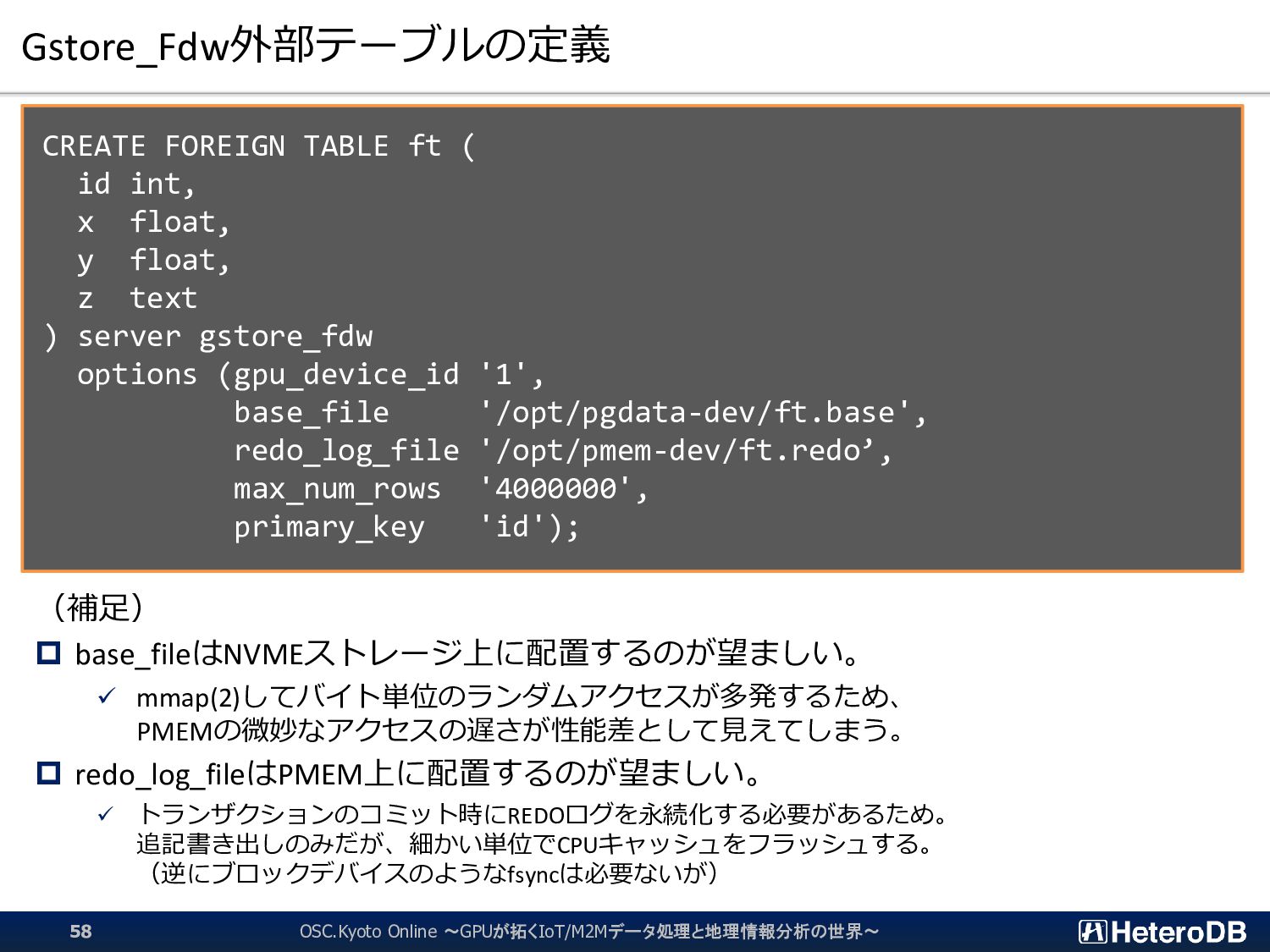{kind=link}
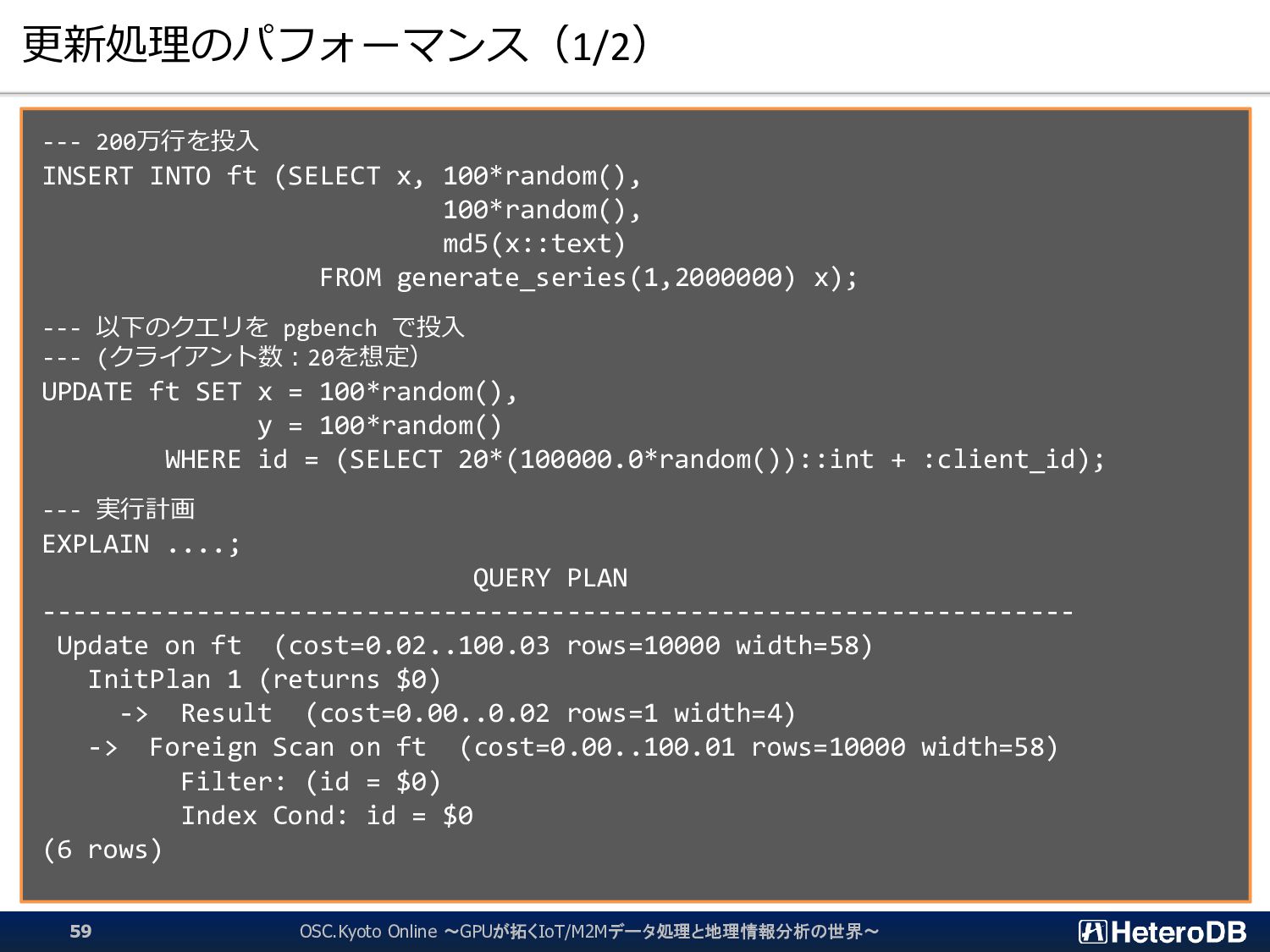{kind=link}
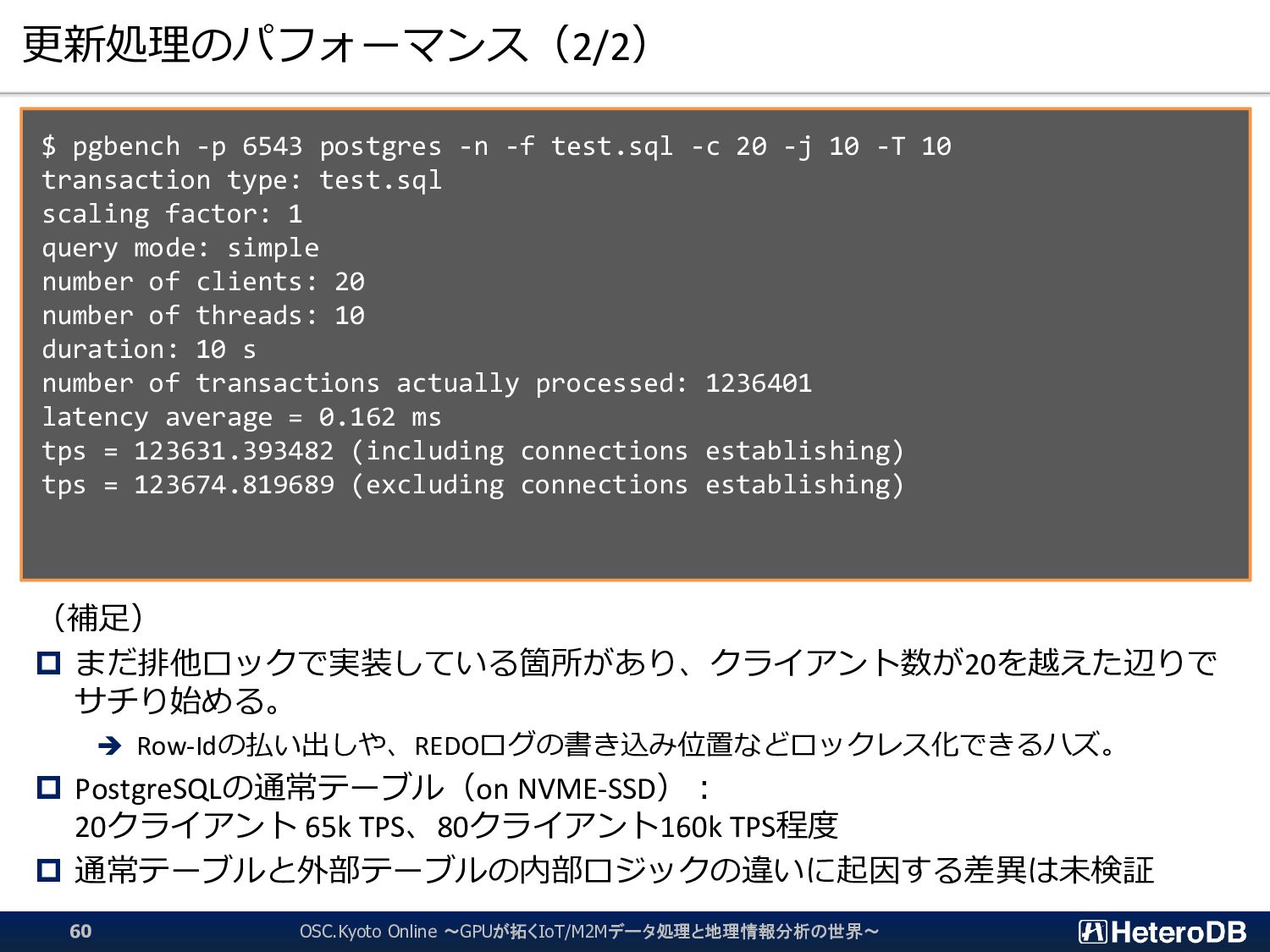{kind=link}
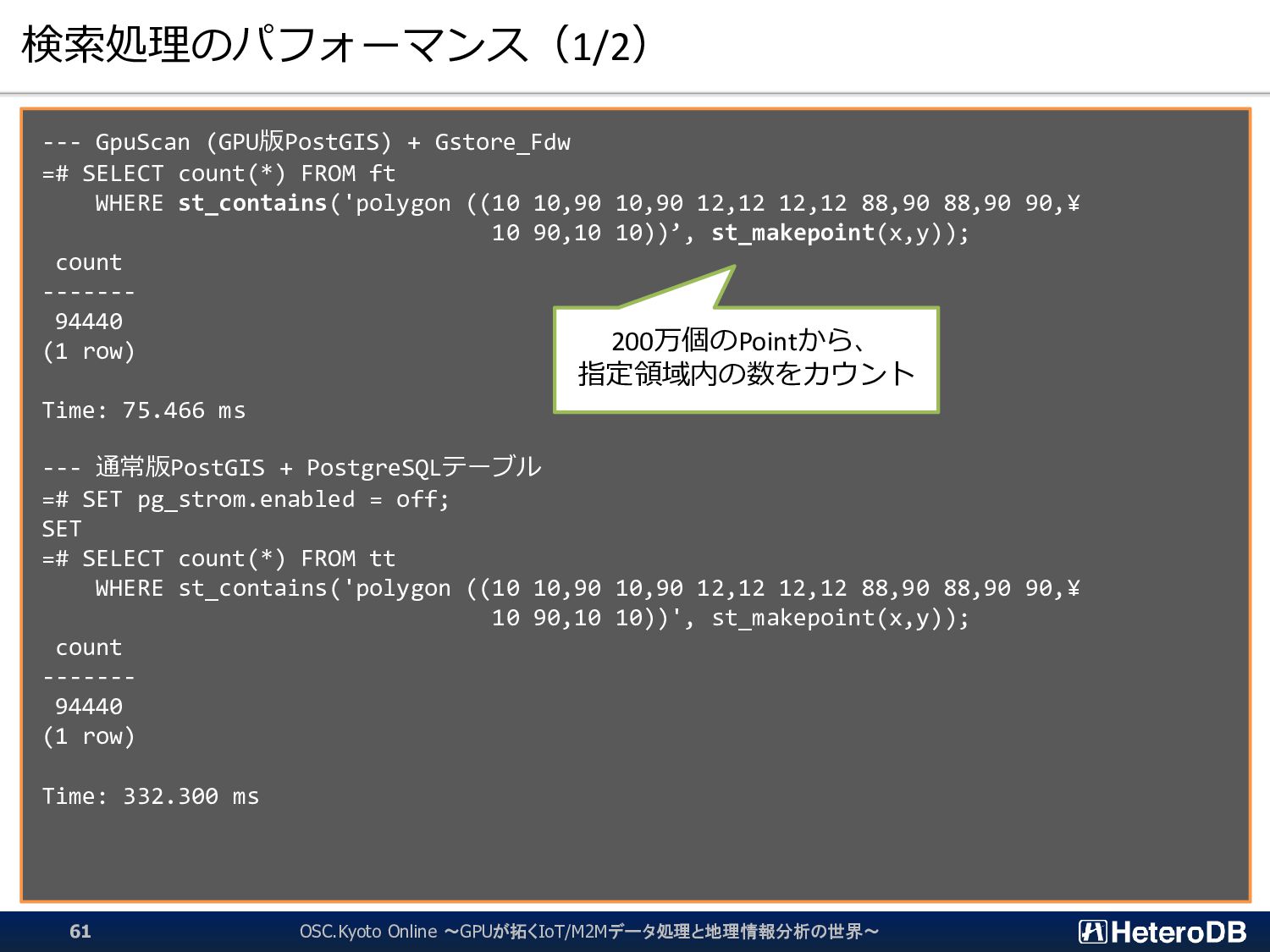{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}